↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current large language models (LLMs) struggle with complex, multi-step reasoning problems, often failing to correct their own mistakes. Existing methods like prompt tuning have limited success in teaching LLMs to improve iteratively. This lack of sequential self-improvement hinders the development of robust AI agents capable of handling complex real-world tasks.
The paper introduces RISE (Recursive Introspection), a novel iterative fine-tuning approach. RISE frames single-turn prompt solving as a multi-turn Markov Decision Process, collecting training data via on-policy rollouts and reward-weighted regression. Experiments demonstrate RISE’s effectiveness in improving Llama2, Llama3, and Mistral models across reasoning benchmarks. The method often outperforms single-turn approaches with similar computational costs and importantly, enables monotonically increasing performance over multiple attempts.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach for enhancing the self-improvement capabilities of large language models (LLMs). This is a significant step toward creating more robust and reliable AI agents that can adapt and learn from their mistakes in real-time. The work also introduces new avenues for research on self-improvement techniques, prompting methods, and multi-turn data collection strategies for LLMs, potentially impacting various downstream applications.
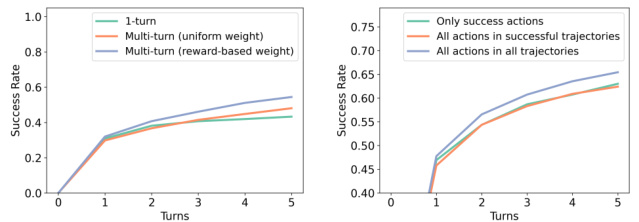
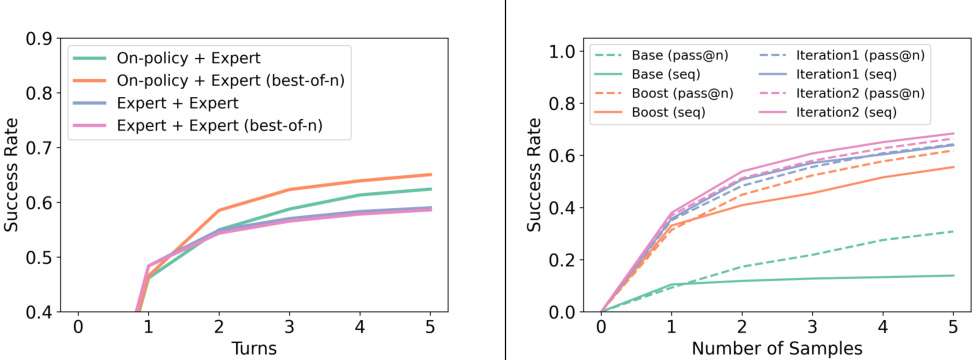
Visual Insights#
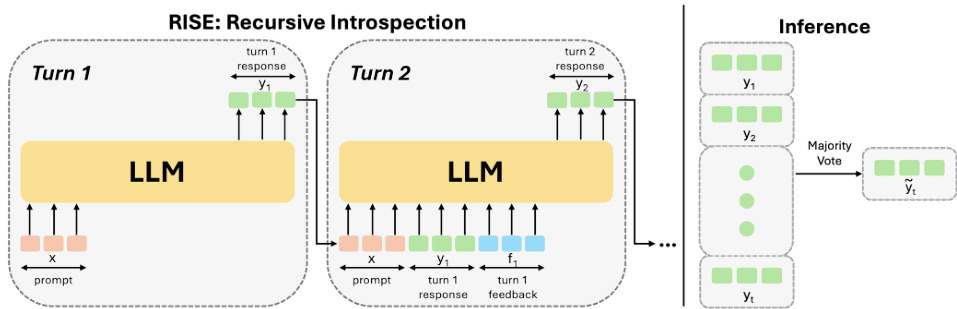
This figure illustrates the RISE (Recursive Introspection) model’s architecture and inference process. The model is trained iteratively using on-policy rollouts and a reward function. In each training iteration, the LLM produces a response, and the next iteration uses this previous response (and possibly additional feedback) to guide the next response. At inference time, the model generates multiple responses over several turns, and the final response is chosen using majority voting.
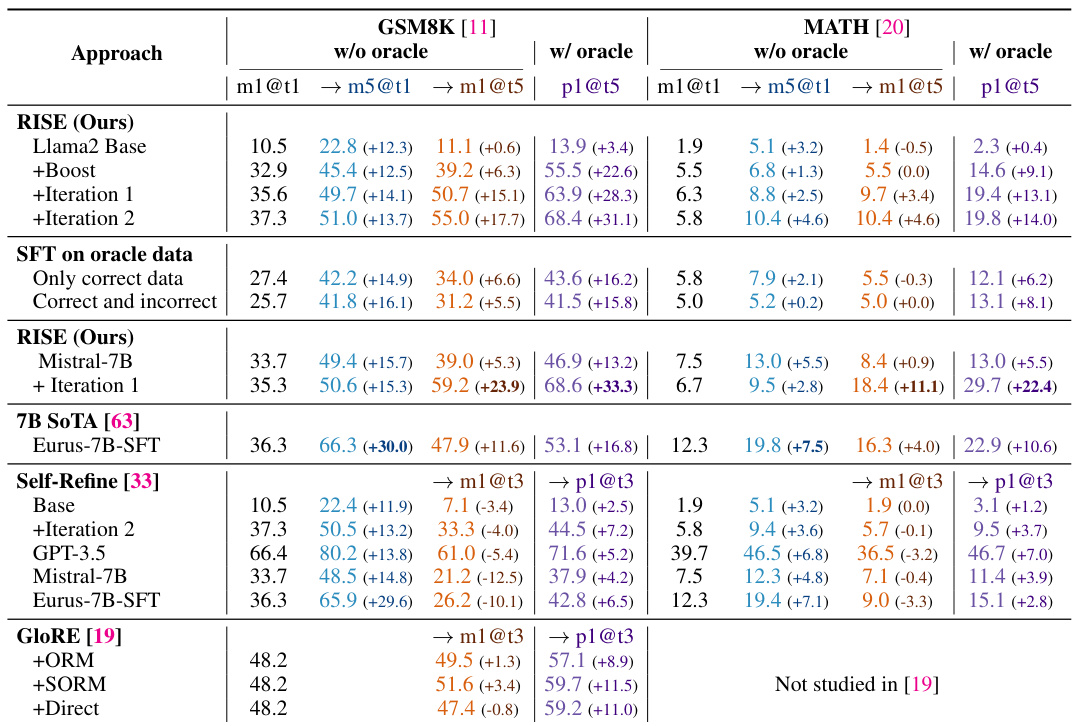
This table compares the performance of RISE against several baseline methods and other self-improvement approaches on two benchmark datasets (GSM8K and MATH). It shows the performance improvements achieved by RISE over multiple turns (5 turns), both with and without using an oracle for early termination. The table also highlights the impact of different base models and training strategies on the overall performance gains.
In-depth insights#
RISE: Recursive Introspection#
RISE: Recursive Introspection presents a novel approach to enhance the self-improvement capabilities of large language models (LLMs). The core idea revolves around iterative fine-tuning, where the model learns to refine its responses sequentially. Instead of relying on external feedback alone, RISE leverages the model’s own internal reasoning process, making it self-directed. This iterative process is framed as a Markov Decision Process (MDP), allowing for the systematic improvement of responses over multiple turns. A key innovation is the use of on-policy rollouts and carefully constructed training strategies to imbue the LLM with the ability to detect and correct its mistakes. The effectiveness of RISE is demonstrated through experiments on various LLMs and datasets, showcasing its ability to significantly outperform single-turn strategies. Self-distillation provides a valuable alternative, eliminating the need for external resources while still achieving notable improvement. This method’s potential is particularly evident in solving complex problems where initial attempts fail, underscoring its potential as a powerful tool for building more robust and capable LLMs.
Multi-turn MDP Formulation#
A multi-turn Markov Decision Process (MDP) formulation for language models elegantly captures the iterative nature of problem-solving. Each turn represents a state, encapsulating the current prompt, model’s history of attempts, and any environmental feedback received. The model’s response is treated as an action, transitioning the system to a new state based on the response’s correctness. Reward functions provide a simple mechanism to evaluate each action, typically assigning a high reward for correct responses and a low reward for incorrect ones. This structured approach allows the training process to learn from a sequence of decisions rather than just a single response, leading to significant improvements in test-time performance. By modeling the process as an MDP, the approach draws upon established reinforcement learning and dynamic programming methods, offering a principled and powerful framework for equipping language models with sequential self-correction capabilities.
Self-Improvement via RISE#
The concept of “Self-Improvement via RISE” centers on enabling large language models (LLMs) to iteratively refine their responses, effectively learning to self-correct. RISE (Recursive Introspection) achieves this by framing the single-turn problem-solving task as a multi-turn Markov Decision Process (MDP). This allows the model to learn a strategy for improvement through an iterative process. The approach leverages on-policy rollouts, creating training data by demonstrating how the model can improve its own responses. Crucially, RISE incorporates both high-quality and low-quality parts of these rollouts, avoiding biases towards only successful responses. The use of reward-weighted regression during fine-tuning helps reinforce desirable improvements. Experiments show significant performance gains across multiple LLMs, demonstrating the generalizability and effectiveness of RISE in fostering test-time self-improvement. The method’s strength lies in its ability to teach the model how to improve, rather than simply providing corrective examples, thereby enabling a more generalizable and robust self-correction ability.
RISE’s Limitations#
RISE, while demonstrating promising results in enabling language models to self-improve, has several limitations. The reliance on iterative fine-tuning can be computationally expensive, especially with larger models and multiple rounds of training. The approach’s effectiveness is heavily dependent on the quality of the base model, with improvements being more pronounced in more capable models. Data efficiency remains a concern, as the approach requires significant amounts of carefully constructed data. The inherent limitations of the base models also pose a challenge. While RISE teaches self-improvement strategies, the underlying biases and knowledge gaps in the base models will impact the ultimate quality of the improved responses. Generalization to unseen problems and out-of-distribution scenarios remains an open question; the study primarily focuses on existing benchmark datasets and further investigation is needed to assess its performance in real-world conditions. Finally, the reliance on a reward mechanism introduces the risk of reward hacking and the need for carefully designed reward functions to guide the self-improvement process effectively.
Future Research#
Future research directions stemming from this work on Recursive Introspection (RISE) could explore several key areas. Extending RISE to fully online settings would enhance its efficiency and allow for continuous adaptation. Investigating the impact of different reward functions and weighting strategies could further optimize the self-improvement process. Exploring the application of RISE to other tasks beyond mathematical reasoning, such as code generation and natural language tasks is essential. This would highlight RISE’s generalizability. Furthermore, a deeper investigation into the interplay between model capacity and the effectiveness of RISE is needed. This includes determining the conditions under which iterative self-improvement is most beneficial and exploring how to apply it to models with varying levels of capacity. Finally, rigorous analysis of the failure modes of RISE and methods to mitigate them is crucial, and addressing potential biases and ethical considerations that arise from equipping models with self-improvement capabilities requires further research.
More visual insights#
More on figures

This figure illustrates the transformation of single-turn question answering into a multi-turn Markov Decision Process (MDP). The left side shows the single-turn problem, where a query leads to a response, and if incorrect, a reward of 0 and a new state are given. This repeats until a correct answer is found. The right side depicts the multi-turn MDP data collection process. Data is collected by simulating multiple turns of the LLM attempting to answer the query. Improvement is achieved through either self-distillation (the model generating multiple responses, selecting the best) or distillation (using a more capable model). The improved responses and their rewards constitute the training data for RISE.

The figure illustrates the RISE (Recursive Introspection) model, which uses a multi-round training process on on-policy rollouts and a reward function to enable language models to improve their responses iteratively over multiple turns. During inference, the model generates several responses over multiple turns and then uses majority voting to determine the final response. This contrasts with standard single-turn methods, enabling the model to refine its answer over time and ultimately yield a better result.

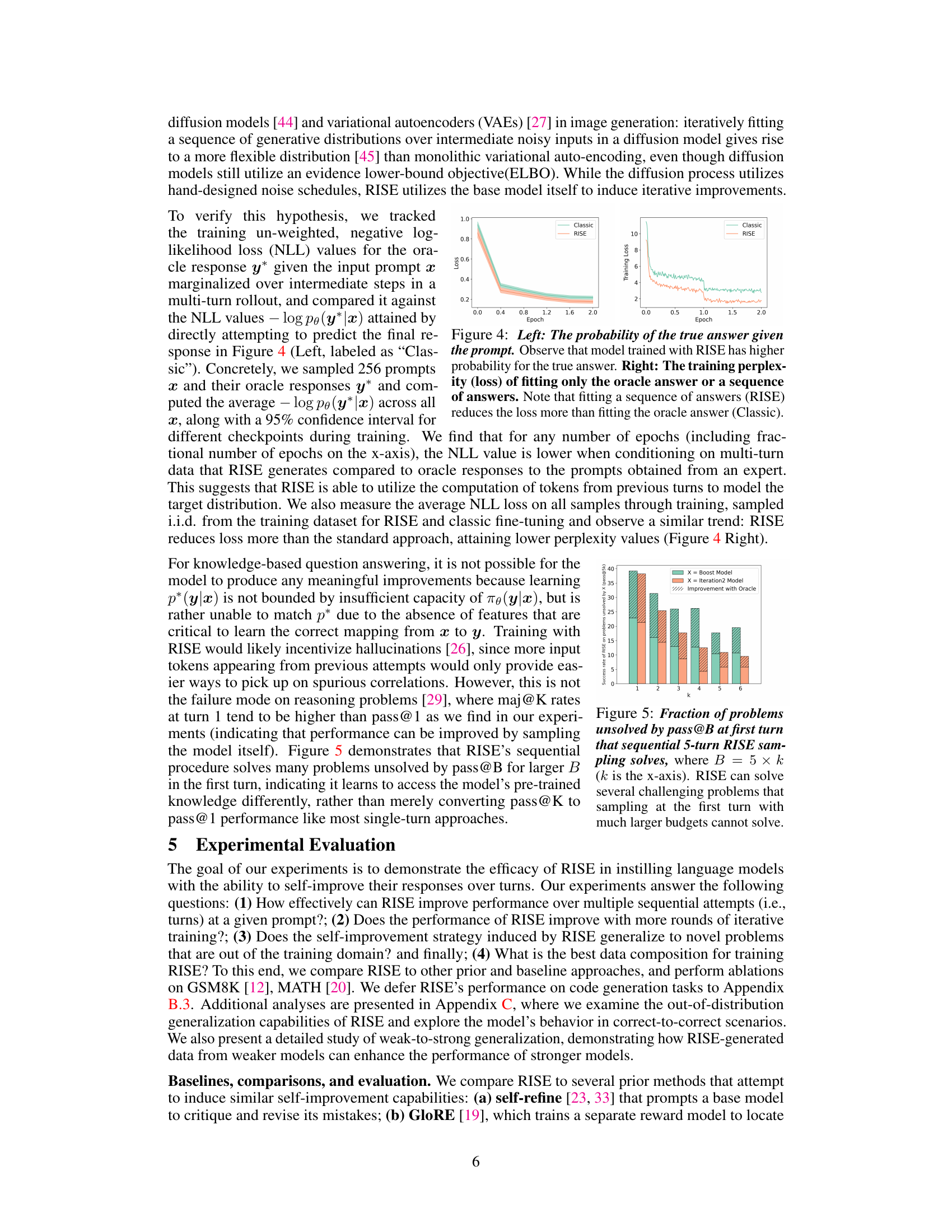
This figure shows the results of an experiment comparing two training methods: ‘Classic’ and ‘RISE’. The left panel shows the probability of the true answer given the input prompt for both methods. It demonstrates that the RISE model consistently achieves a higher probability of generating the correct answer. The right panel displays the training loss (perplexity) for both methods across epochs. Here, the reduction in loss is significantly lower for the classic method, indicating that the RISE method improves the model’s ability to fit the target distribution using a sequence of answers.

This figure shows the success rate of RISE on problems that could not be solved by sampling at the first turn with a larger budget (pass@B). The x-axis represents the number of turns (k) in a 5-turn RISE experiment, and the y-axis is the success rate. The bars show the success rates of the base model after boosting (‘Boost Model’) and after two iterations of RISE (‘Iteration2 Model’). The hatched bars illustrate the improvement achieved by using oracle feedback during the RISE iterations.
This figure illustrates the process of converting single-turn problems into multi-turn Markov Decision Processes (MDPs) and collecting training data for the RISE model. The left side shows the MDP formulation, where each state represents the prompt and interaction history, actions are LLM responses, and rewards indicate correctness. The right side details the data collection strategy using self-distillation (sampling multiple responses from the current model) or distillation (querying a stronger model) to generate improved responses and build the training dataset.

The figure illustrates the RISE (Recursive Introspection) model. It shows how the model iteratively improves its responses over multiple turns. In each turn, the model generates a response, and then uses this response (along with optional feedback) to inform the next turn’s response. Finally, at inference time, a majority voting mechanism is used to combine the responses from different turns to produce the final, improved output.
This figure illustrates the two inference modes of the RISE model: with and without oracle. The ‘with oracle’ mode allows the model to verify its answer against an external environment after each attempt and stop when it finds the correct answer. The ‘without oracle’ mode makes the model iteratively refine its answer multiple times and uses majority voting to combine candidate outputs from multiple turns to generate the final output. If the number of turns exceeds the training iterations, the model uses a sliding window of the most recent turns to avoid any distribution shift at test time.

This figure illustrates the RISE (Recursive Introspection) model. The model uses multiple rounds of training with on-policy rollouts and feedback from a reward function to learn how to iteratively improve its responses. During inference, it generates multiple responses over several turns, then employs majority voting to determine the final answer.
The figure illustrates the RISE (Recursive Introspection) framework. It shows a multi-turn training process where an LLM iteratively refines its responses based on feedback (either from a more capable model or self-evaluation) and a reward function. At inference time, a majority vote among the candidate responses from different turns determines the final output. The diagram visually represents the iterative refinement process, highlighting the key components of the RISE method, namely multi-turn training, on-policy rollouts, supervision, and majority voting.
More on tables
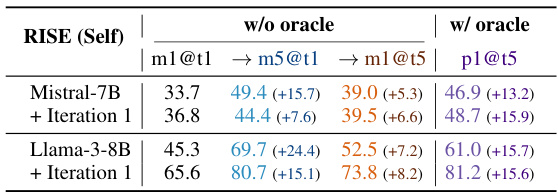
This table compares the performance of RISE against other state-of-the-art methods on two benchmark datasets, GSM8K and MATH. The table shows that RISE significantly improves performance over multiple turns compared to baselines and other self-improvement approaches. Notably, RISE’s improvement is more substantial when early termination with an oracle is not allowed, showcasing its effectiveness in test-time self-improvement.
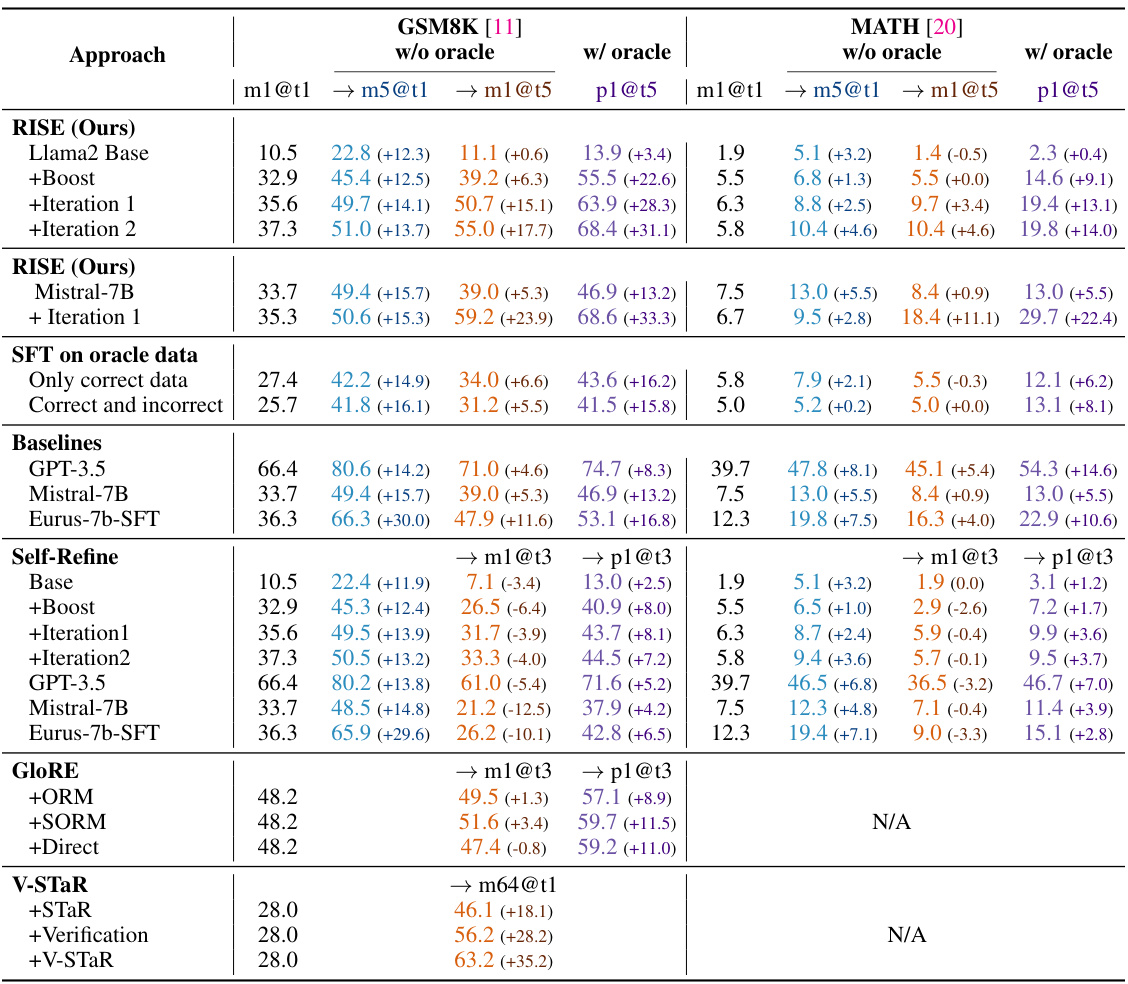
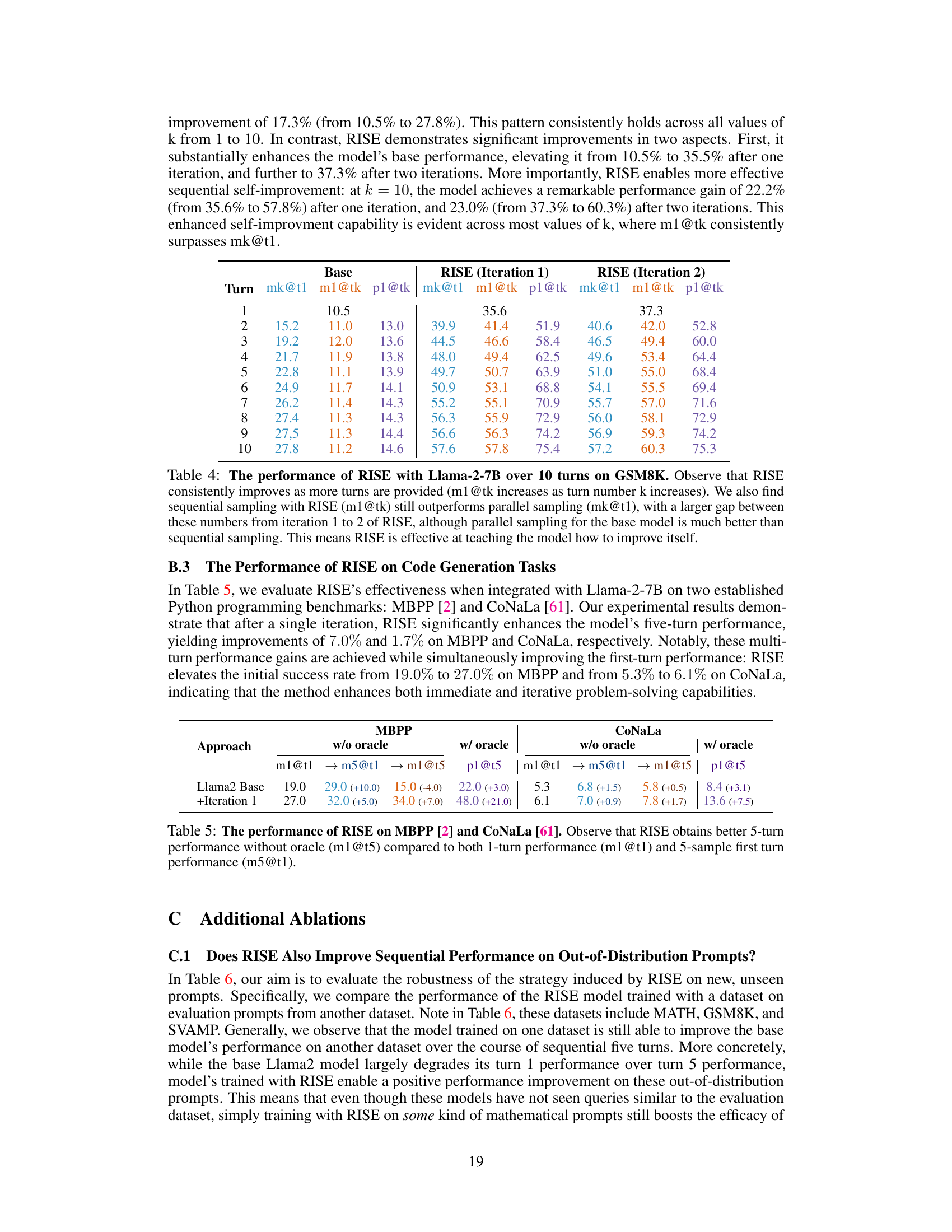
This table compares the performance of RISE against several baseline methods and other approaches on two datasets: GSM8K and MATH. The results show that RISE consistently outperforms other methods, particularly in multi-turn scenarios where the model iteratively refines its responses. The table also highlights the impact of using a more capable base model and the importance of the algorithmic design of RISE for achieving self-improvement.

This table compares the performance of RISE against several baseline methods and other state-of-the-art approaches on two benchmark datasets: GSM8K and MATH. The results show that RISE significantly improves the performance of language models over multiple sequential attempts, outperforming other methods, especially without oracle feedback. It also demonstrates that the improvements are more substantial when using a more capable base model and that simply fine-tuning on the same data used by RISE does not achieve similar results, highlighting the importance of RISE’s algorithmic design.

This table compares the performance of RISE against several baselines and other self-improvement methods across two datasets (GSM8K and MATH). The key finding is that RISE consistently shows significantly greater performance improvements over multiple turns compared to other approaches, especially when early termination using an oracle is not allowed. Furthermore, even when using a stronger base model, RISE still demonstrates improvements over other methods and achieves state-of-the-art performance in some cases. The results suggest that the algorithmic design choices in RISE are crucial for its success in enabling self-improvement.
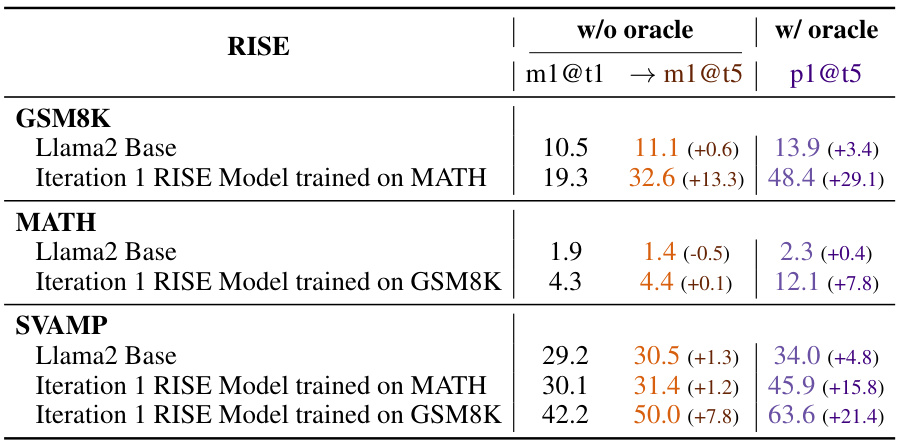
This table compares the performance of RISE against other state-of-the-art methods (Self-Refine, GLORE, V-STAR) and baselines on two benchmark datasets, GSM8K and MATH. It shows the improvement in performance (measured by m1@t1, m5@t1, m1@t5, and p1@t5 metrics) when using RISE with different base models (Llama2 and Mistral-7B) and different training iterations. The table highlights that RISE consistently outperforms other methods by achieving significant improvements across both datasets and different evaluation metrics, especially when multiple attempts are allowed. It also showcases the impact of using a stronger base model and the importance of RISE’s unique algorithm design.

This table compares the performance of RISE against several baseline and related methods on two benchmark datasets (GSM8K and MATH). It shows the accuracy of different models at solving problems in a single attempt (m1@t1 and m5@t1, representing the first turn performance with 1 and 5 samples respectively) and after multiple attempts (m1@t5, representing the accuracy of a single model after 5 iterations, and p1@t5, representing the performance when the model is allowed to terminate early with an oracle for a correct answer). The table highlights RISE’s significant performance improvement over multiple turns, especially in comparison to methods such as Self-Refine which show degraded performance, and GLORE which uses multiple models and still underperforms RISE. The results also demonstrate that using RISE with a stronger base model further enhances its effectiveness.
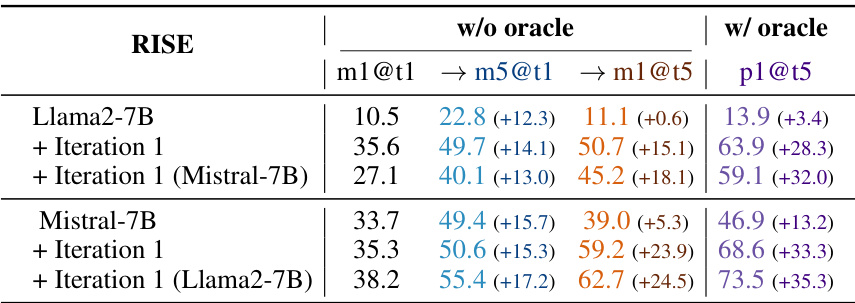
This table compares the performance of RISE against several baselines and other self-improvement methods on two datasets: GSM8K and MATH. The results show that RISE significantly outperforms the baselines and other methods in terms of improving model performance over multiple turns, especially when early termination with an oracle is not allowed. The table highlights the importance of RISE’s algorithmic design and demonstrates that its performance benefits are transferable to different base models.
This table compares the performance of RISE against several baselines and other self-improvement methods on two benchmark datasets, GSM8K and MATH. It shows the improvement in performance (percentage of correct answers) after one turn and five turns of reasoning, with and without the help of an oracle providing feedback. The table highlights that RISE significantly outperforms other methods in terms of multi-turn improvement, especially without oracle feedback. It also demonstrates that using a stronger base model with RISE leads to even greater improvements and that simply fine-tuning on the data generated by RISE is not enough to achieve similar results.

This table compares the performance of RISE against several baselines and other self-improvement methods on two datasets, GSM8K and MATH. The results demonstrate RISE’s superior performance, particularly its ability to significantly improve model performance over multiple turns (5 turns), especially when compared to methods like Self-Refine, which showed degraded performance without an oracle. The table also highlights the importance of RISE’s algorithmic design in achieving these results, as simply fine-tuning on the same data used by RISE didn’t produce similar improvements. The use of a stronger base model (Mistral-7B) further enhanced the performance gains with RISE.
Full paper#