↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current Multimodal Large Language Models (MLLMs) face challenges in scalability due to their reliance on extensive modal-specific pre-training and joint-modal fine-tuning. Expanding these models to incorporate new modalities requires substantial computational resources, hindering research progress. This limitation necessitates the development of more efficient and flexible training strategies for MLLMs.
This paper introduces PathWeave, a novel framework that tackles this scalability issue. PathWeave leverages continual learning principles and a unique Adapter-in-Adapter (AnA) architecture to enable incremental training of MLLMs. The AnA framework seamlessly integrates uni-modal and cross-modal adapters for efficient modality alignment and collaboration, reducing training burdens significantly. Experiments demonstrate that PathWeave achieves performance comparable to state-of-the-art MLLMs while concurrently reducing the parameter training burden by 98.73%, thereby showcasing its efficiency and scalability.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the significant computational burden of expanding Multimodal Large Language Models (MLLMs) to new modalities. PathWeave offers a novel, efficient incremental training strategy, reducing the need for extensive pre-training and joint-modal tuning, thus making MLLM development more scalable and accessible to researchers with limited resources. It opens avenues for continual learning in MLLMs, a crucial area for future research and development.
Visual Insights#
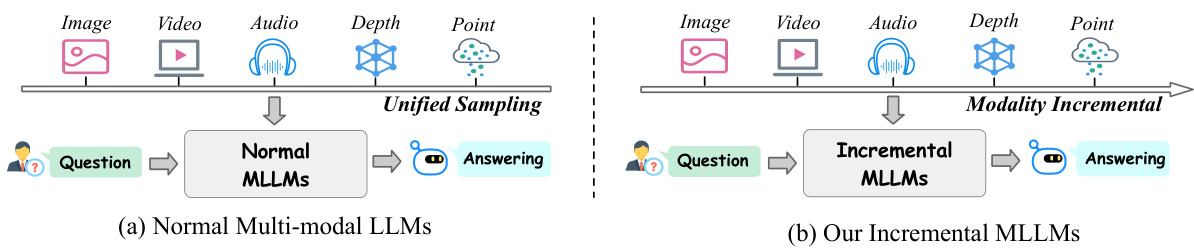
This figure compares two approaches for training multimodal large language models (MLLMs). (a) shows the traditional approach where all modalities are trained together using a unified sampling method. This requires a large joint dataset encompassing all modalities. (b) presents the proposed incremental approach, where each modality is learned sequentially. This requires only unimodal datasets for each modality, making it more efficient and scalable.

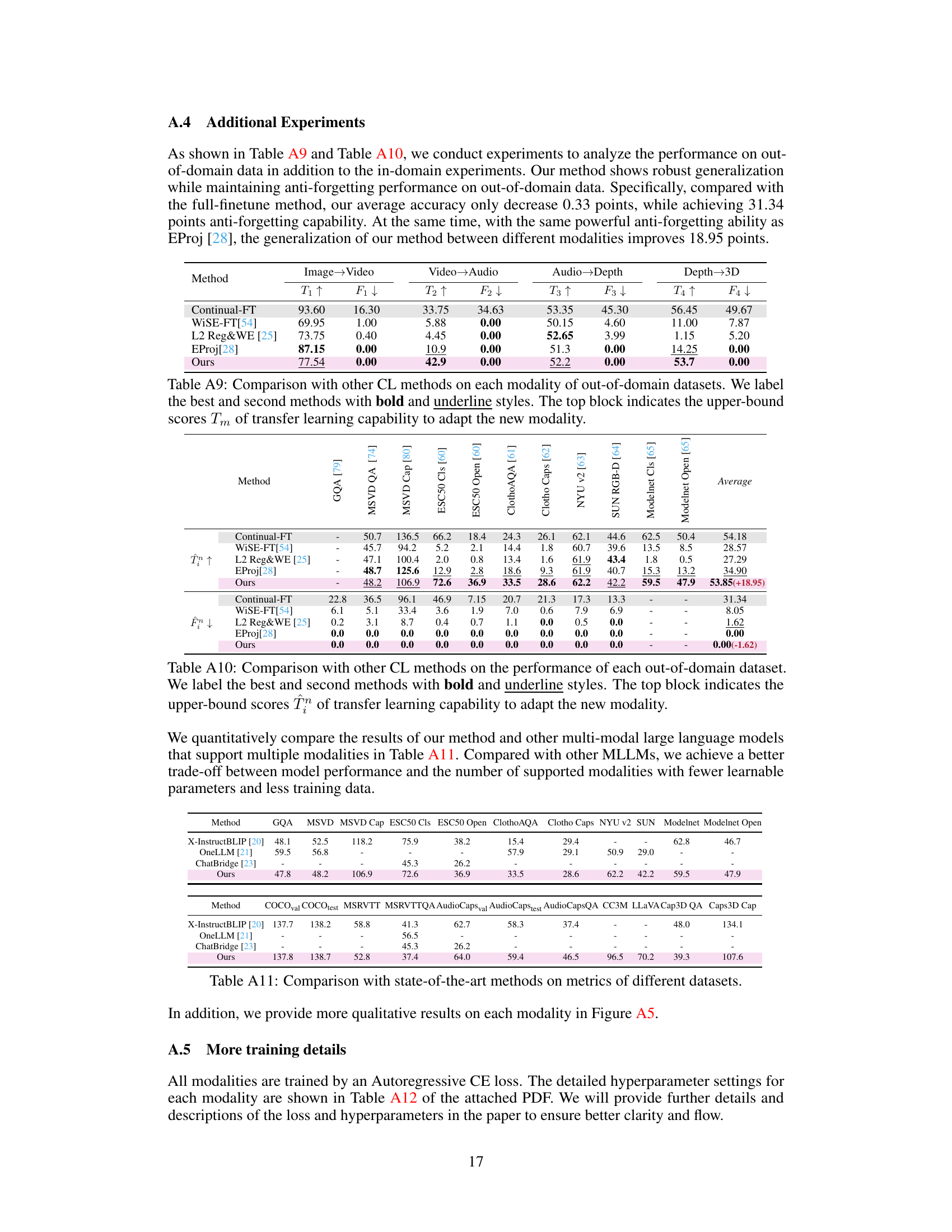
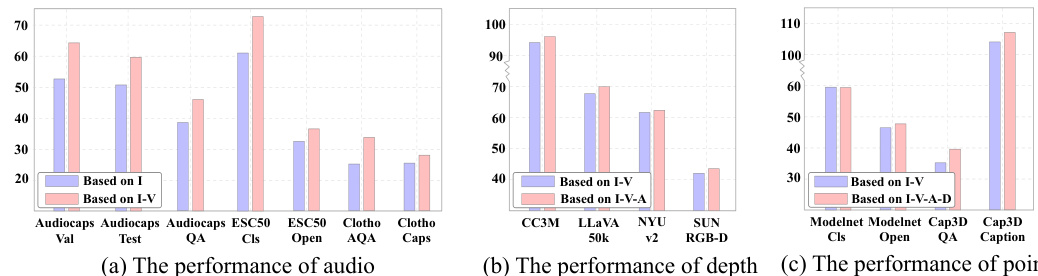
This table compares the performance of the proposed PathWeave method with other Continual Learning (CL) methods on five different modalities (image, video, audio, depth, and 3D point cloud). The metrics used are transfer learning capability (T) and forgetting rate (F) for each modality transition. The table highlights the superior performance of PathWeave in terms of both high transfer learning capability and low forgetting, particularly when transitioning to more complex modalities like audio and 3D point clouds.
In-depth insights#
Modal Pathway Evolv.#
The concept of ‘Modal Pathway Evolv.’ suggests a system capable of dynamically adapting and expanding its understanding across multiple modalities. This implies a framework that goes beyond simple multimodal fusion, instead embracing a more dynamic and evolutionary approach. A key aspect would be the ability to incrementally integrate new modalities without requiring extensive retraining on all existing data, thereby promoting scalability and efficiency. This might involve mechanisms such as modular architectures with adaptable components for each modality, allowing for the selective addition and refinement of capabilities. Furthermore, efficient knowledge transfer between modalities would be crucial, enabling the system to leverage previously learned information for faster and more effective learning in new domains. The focus on ’evolution’ implies a system capable of continuous learning and improvement, constantly refining its internal representations based on new experiences. This makes the ‘Modal Pathway Evolv.’ concept especially relevant for real-world applications where data is continuously evolving and new modalities emerge.
Adapter-in-Adapter#
The proposed Adapter-in-Adapter (AnA) framework offers a novel approach to continual learning in multimodal large language models (MLLMs) by enabling efficient integration of new modalities. Incremental learning is achieved without the computationally expensive process of joint-modal pre-training. AnA elegantly combines uni-modal adapters, which are trained on single-modality data and then frozen, with cross-modal adapters. These cross-modal adapters leverage the knowledge encoded in the uni-modal adapters, enhancing multimodal interaction and mitigating catastrophic forgetting. The integration of an MoE-based gating module further refines the process by dynamically weighting the contributions of each type of adapter. This design fosters flexibility in expanding the MLLM to new modalities and significantly reduces the parameter training burden. The framework’s effectiveness lies in its ability to seamlessly integrate new modalities while preserving previously acquired knowledge, demonstrating superior plasticity and memory stability during continual learning.
MCL Benchmark#
The heading ‘MCL Benchmark’ suggests a crucial contribution of the research paper: establishing a robust and standardized benchmark dataset for evaluating continual learning in multimodal scenarios. This benchmark’s significance lies in its ability to rigorously test the performance of multimodal large language models (MLLMs) as they incrementally learn new modalities. The dataset likely contains high-quality question-answering data from various modalities (e.g., image, audio, video, depth, point cloud), which allows for a comprehensive assessment of the model’s ability to not only learn new data but also to retain previously acquired knowledge. The design of the benchmark is key: it must be challenging enough to discriminate between different MLLM approaches, particularly regarding their ability to maintain performance on previously seen modalities (avoiding catastrophic forgetting) while simultaneously adapting to new ones. The authors probably discuss the metrics used to evaluate performance on the MCL Benchmark, emphasizing not only the accuracy of the model but also its robustness and ability to transfer knowledge between different modalities. This rigorous evaluation is essential for advancing the field of continual multimodal learning and driving the development of more efficient and robust MLLMs.
Continual Learning#
Continual learning, a significant area within machine learning, focuses on developing systems that can progressively acquire new knowledge without catastrophic forgetting of previously learned information. This is particularly challenging in the context of large multimodal models, as these models often require extensive retraining when new modalities are added. The paper explores this challenge by proposing a novel approach, PathWeave, that uses adapters to incrementally integrate new modalities, reducing the need for full model retraining and minimizing the impact of catastrophic forgetting. The framework’s emphasis on incremental learning and adaptive modality alignment represents a key advancement in handling the complexity of continually evolving multimodal data. The use of a pre-trained vision LLM as a foundation, upon which new modalities are seamlessly integrated, demonstrates an efficient and scalable method for expanding the capabilities of LLMs. The results showcase PathWeave’s strength in maintaining prior knowledge and quickly adapting to new modalities, which is crucial for effective continual learning. The introduction of adapters-in-adapters and an MoE-based gating mechanism further enhance modality interaction and plasticity, highlighting an innovative contribution to both continual learning and multimodal model development.
Future of MLLMs#
The future of Multimodal Large Language Models (MLLMs) is incredibly promising, driven by the need for enhanced understanding and reasoning across diverse modalities. Future research should focus on improving scalability and efficiency, addressing the computational cost of training and deploying these models. Continual learning is key to enabling MLLMs to evolve continually by learning from new modalities without the need for extensive retraining. Addressing the ethical implications of such powerful models will also be critical, including issues of bias, fairness, and potential misuse. Improving multimodal interaction is vital: better alignment and collaboration between different modalities will lead to more robust and contextually aware systems. Finally, developing standardized benchmarks and evaluation metrics for multimodal tasks will be essential for comparing progress and accelerating future development.
More visual insights#
More on figures
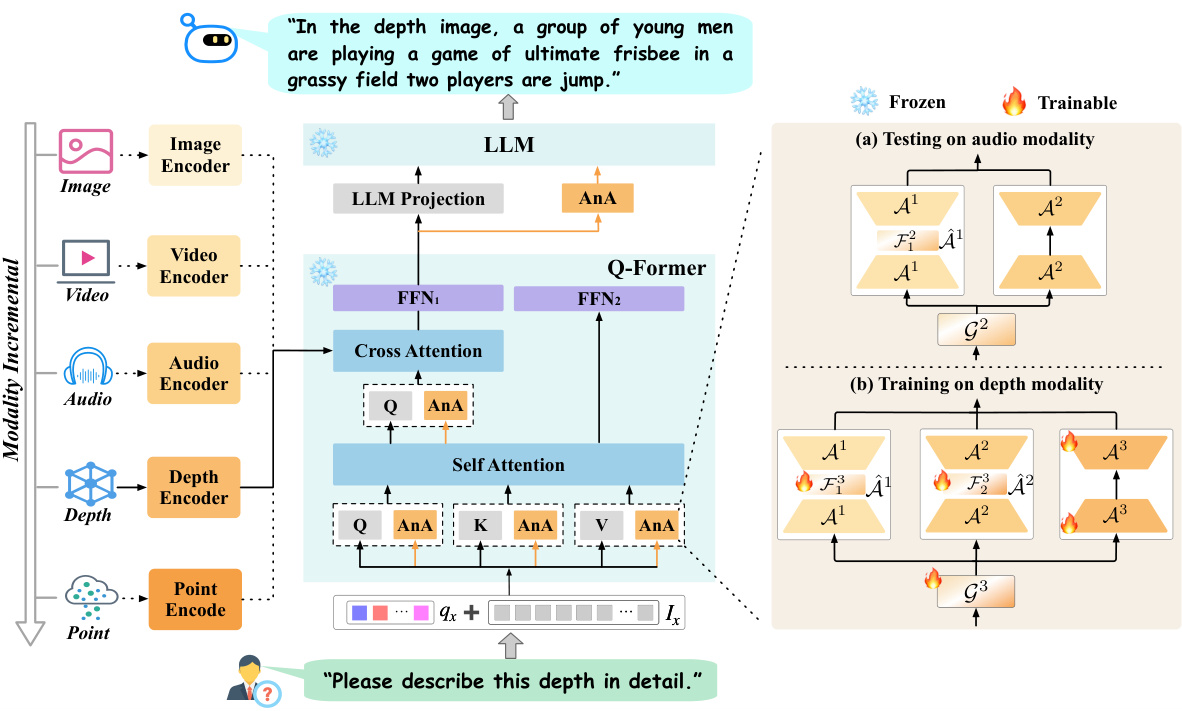
This figure illustrates the architecture of PathWeave, a framework for continually evolving Large Language Models (LLMs) on modality. It starts with a pre-trained vision LLM and incrementally adds new modalities using uni-modal data and a novel Adapter-in-Adapter (AnA) mechanism. AnA consists of uni-modal adapters (trained on single modality data and frozen after training), and cross-modal adapters (built upon the uni-modal adapters for better cross-modal interaction). A Mixture of Experts (MoE) gating mechanism further improves the interaction between modalities.
This figure illustrates the architecture of PathWeave, a framework for incrementally expanding multimodal large language models. It shows how a pre-trained vision LLM is used as a base, with new modalities added via adapter modules. Uni-modal adapters process single-modality data, while cross-modal adapters integrate information from previous modalities. A gating mechanism further refines the interaction between modalities.
This figure compares two approaches for training multimodal large language models (MLLMs). (a) shows the traditional method, which requires joint training with data from all modalities at once. This is computationally expensive and inefficient when adding new modalities. (b) illustrates the proposed incremental method, PathWeave, which learns each modality sequentially using uni-modal data. This incremental approach makes it more scalable and efficient to add new modalities to the model.

This figure compares two different approaches to multimodal large language models (MLLMs). (a) shows the traditional approach where all modalities (image, video, audio, etc.) are processed together using a unified sampling method. This requires large, joint-modal datasets for training, which is computationally expensive and limits scalability to new modalities. (b) shows the proposed incremental MLLM approach (PathWeave), which learns each modality sequentially using uni-modal data. This makes the model more flexible and scalable, as it doesn’t require massive joint-modal datasets to incorporate new modalities.
More on tables

This table compares the performance of the proposed PathWeave method with other Continual Learning (CL) methods on in-domain datasets across five modalities (Image, Video, Audio, Depth, and 3D). The metrics used evaluate the transfer learning capability (Tm) to adapt to new modalities and the forgetting rate (Fm) during continual learning. The table highlights the effectiveness of PathWeave in maintaining performance on previously learned modalities while adapting to new ones.

This table compares the proposed method (PathWeave) with other state-of-the-art multimodal large language models (MLLMs) in terms of training parameters, data requirements, training time, GPU usage, and performance on three multimodal question answering tasks (MSVD QA, Clotho Caps, and Modelnet Cls). The table shows that PathWeave achieves comparable performance with significantly fewer parameters and less training data, demonstrating its efficiency and scalability.

This ablation study investigates the impact of different components of the PathWeave framework on the performance of each modality. Specifically, it compares the full model (ours) against versions without the MoE-based gating module and without the in-adapter module. The results show the contributions of each component to the overall performance across various modalities. The best performing method for each modality is highlighted in bold, indicating the importance of the complete AnA framework.
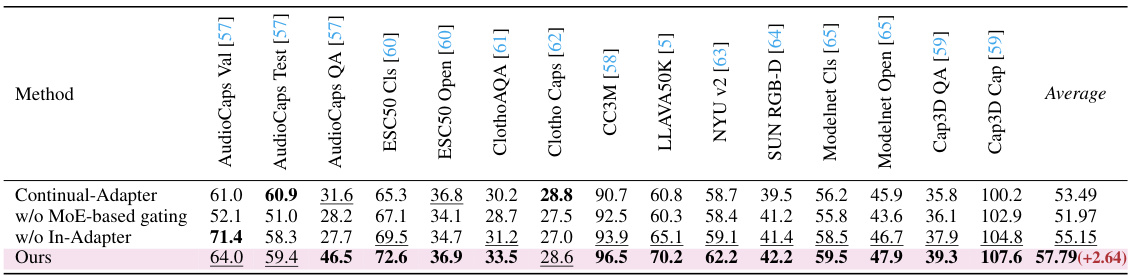
This table presents the ablation study results on the performance of different parts of the proposed method (PathWeave) across various modalities. It shows the impact of removing certain components, such as the MoE-based gating module or the In-Adapter, on the overall performance. By comparing the performance metrics across modalities with and without these components, the table highlights the effectiveness and contribution of each component in the PathWeave framework.

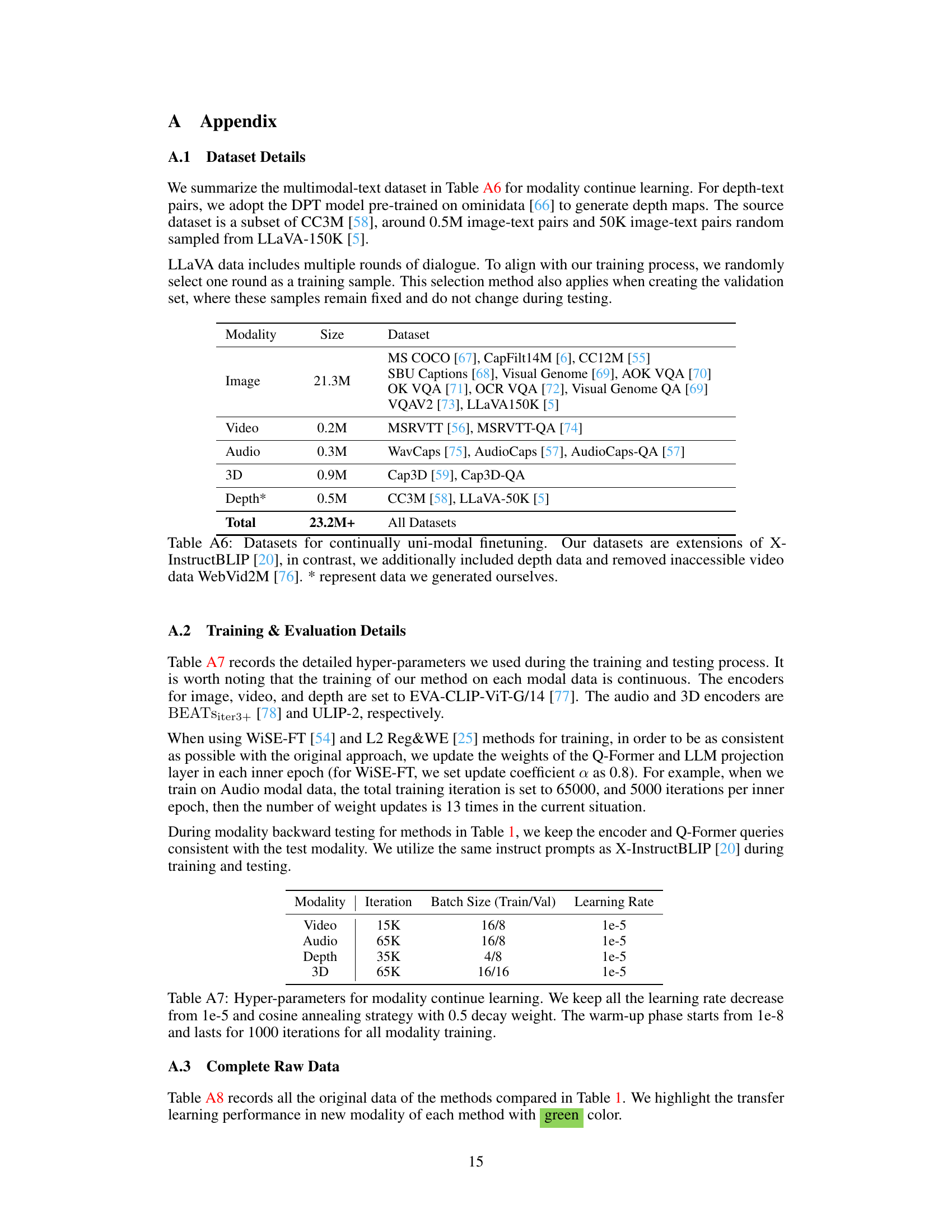
This table lists the datasets used for continual uni-modal fine-tuning in the PathWeave model. It details the size and source of each dataset for five modalities: image, video, audio, 3D, and depth. The datasets are primarily drawn from existing multimodal datasets, but with additions and modifications to suit the continual learning approach. Notably, depth data was added, and inaccessible WebVid2M video data was removed. The ‘*’ indicates datasets that were generated by the authors of the paper.
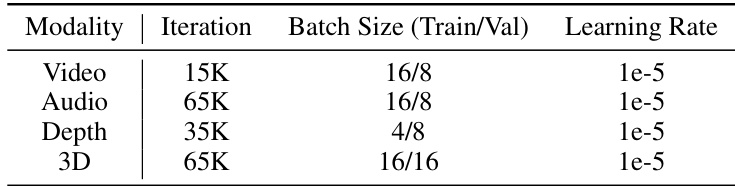
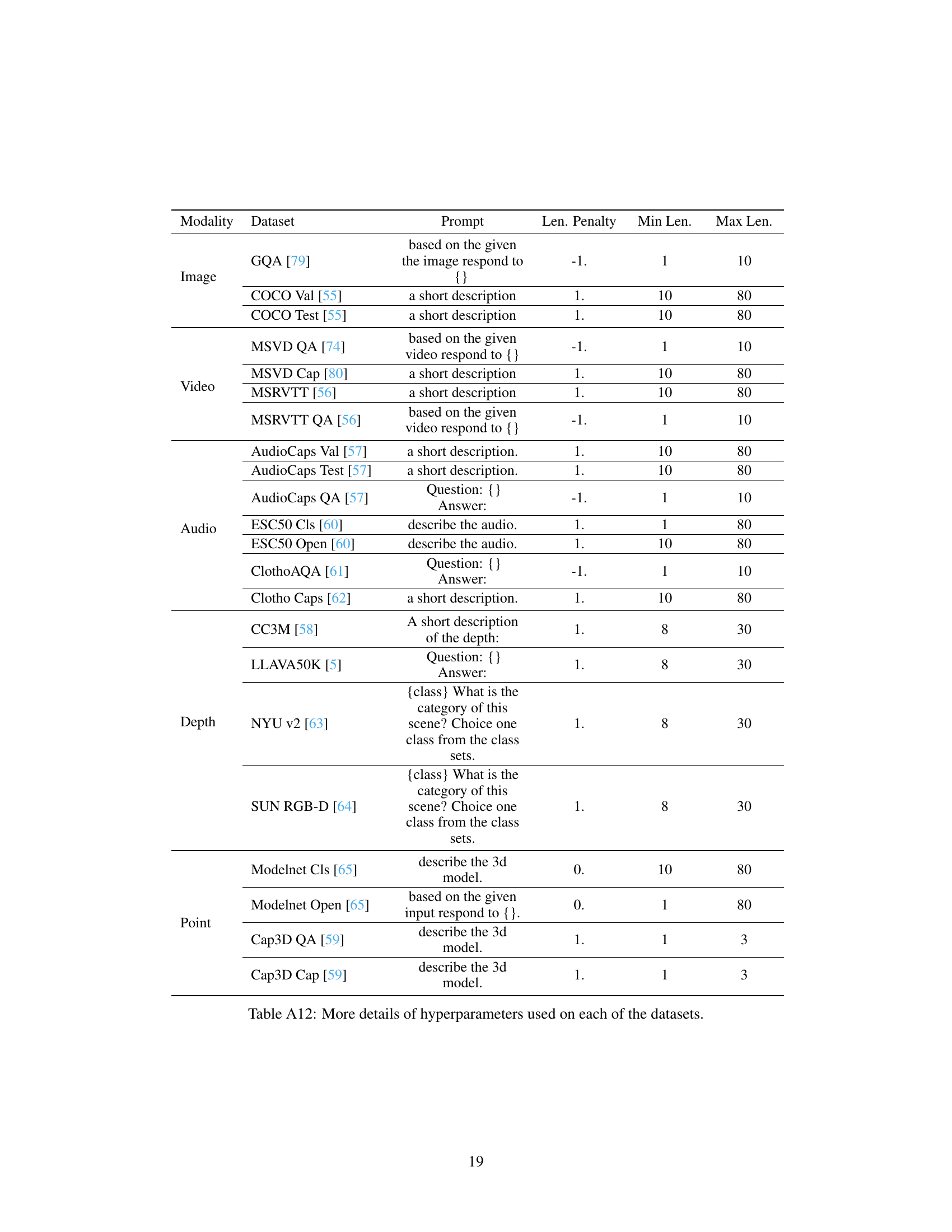
This table details the hyperparameters used during the training process for each modality in the Continual Learning of Modality (MCL) benchmark. It specifies the number of iterations, batch size (for training and validation), and learning rate for each modality (video, audio, depth, and 3D). The consistent hyperparameters across all modalities show that the authors maintained a uniform training approach to compare the results across different modalities.

This table compares the performance of the proposed PathWeave method against other continual learning (CL) methods on five different modalities (image, video, audio, depth, and 3D). The table shows the transfer learning capability (Tm) for each modality transition, indicating how well each method adapts to a new modality. Lower scores in the F columns represent less catastrophic forgetting, indicating better memory retention of previous modalities. The best and second-best performing methods are highlighted.

This table compares the performance of the proposed method (PathWeave) against other Continual Learning (CL) methods on five different modalities (image, video, audio, depth, and 3D). The metrics used are the transfer learning capability (Tm) and forgetting rate (Fm) for each modality transition. In-domain datasets are used for evaluation. The table highlights the best performing method for each transition using bold and underline formatting. The top row shows upper-bound scores representing the best possible transfer learning performance.

This table compares the performance of different continual learning (CL) methods on five different modalities (image, video, audio, depth, and 3D) using in-domain datasets. The table shows the transfer learning capability (Tm) and forgetting rate (Fm) for each method and modality. The top row indicates the upper bound performance of each modality, representing the best possible performance achievable using a transfer learning approach. Lower numbers in the forgetting rate (Fm) columns are better, indicating less catastrophic forgetting.
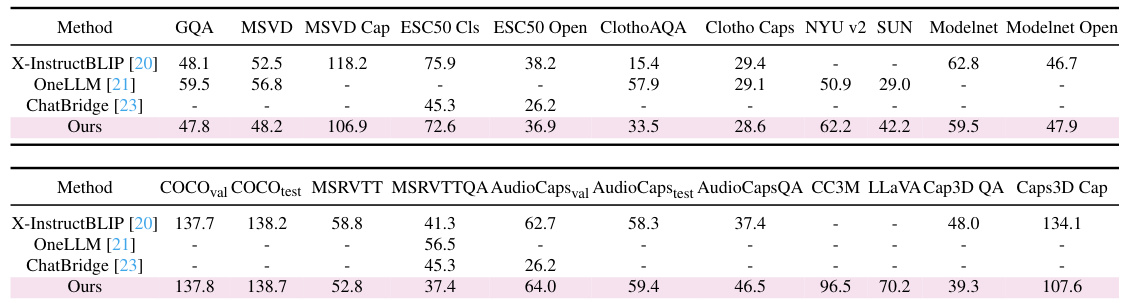
This table compares the performance of PathWeave against other continual learning methods on in-domain datasets across five modalities: image, video, audio, depth, and 3D point cloud. The metrics used are transfer learning capability (Tm) and forgetting rate (Fm) for each modality transition. The top row shows the upper bound performance achievable through full fine-tuning for each modality.

This table shows the detailed hyperparameter settings used for each dataset in the Continual Learning of Multi-Modality (MCL) benchmark. It provides specific prompt instructions, length penalties, minimum lengths, and maximum lengths for each modality and dataset, offering a more nuanced understanding of the experimental setup.
Full paper#