↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Vision-language models (VLMs) are rapidly advancing, but critical design decisions often lack justification. This hinders progress by making it hard to identify which choices improve performance. Many studies employ various designs without rigorously comparing them. This paper tackles this issue by performing a comprehensive evaluation of different VLM design choices and training methods.
The researchers developed Idefics2, an 8 billion parameter VLM, achieving state-of-the-art performance. They compared different architectures, pre-trained models, data, and training techniques. Key findings include the superiority of the fully autoregressive architecture over the cross-attention architecture, especially after modification for training stability, and that the quality of pre-trained unimodal backbones significantly impacts the resulting VLM’s performance. The researchers released Idefics2 (base, instructed, and chat versions) along with datasets to facilitate further research and development in the VLM community.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the lack of justification for design choices in vision-language models (VLMs). By systematically evaluating various design choices, it provides valuable insights for researchers, accelerating progress in the field and paving the way for more efficient and effective VLMs. The release of the Idefics2 model and datasets further contributes to community advancement.
Visual Insights#
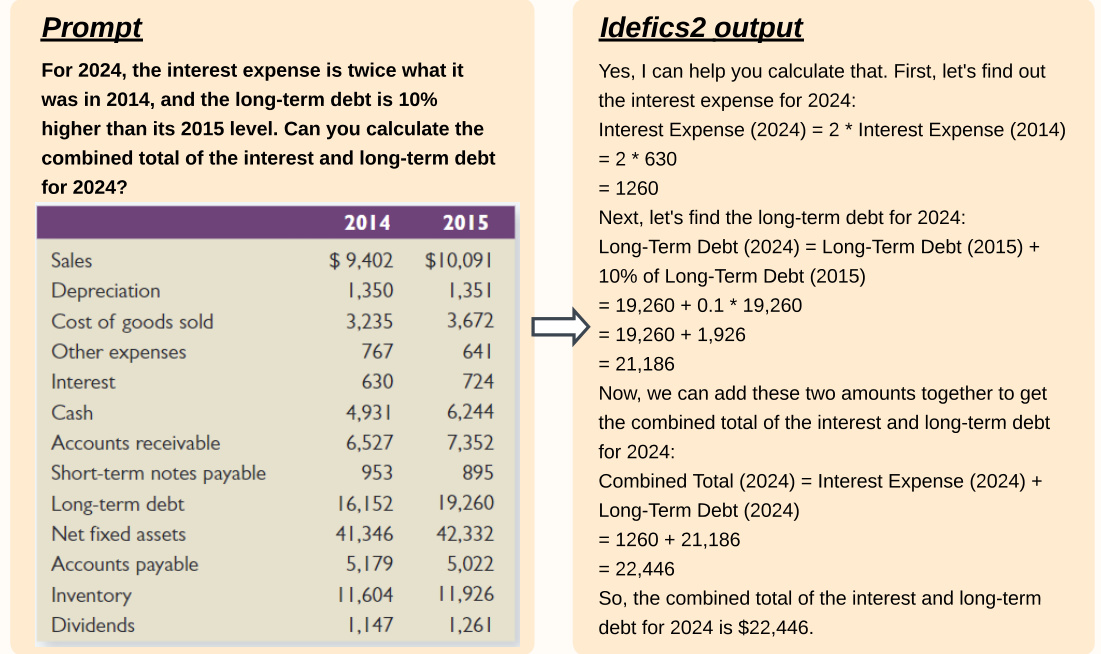
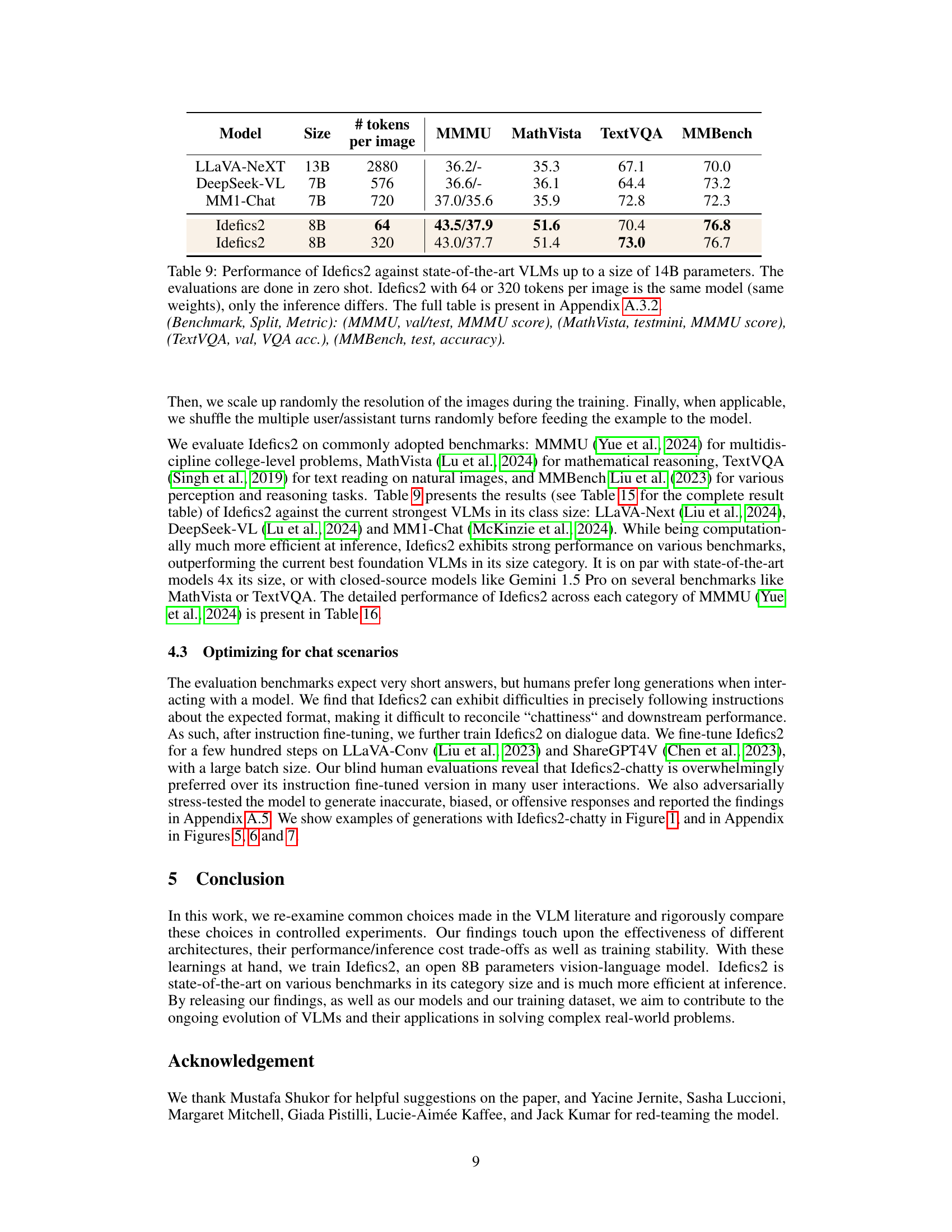
The figure shows a prompt in natural language, a table of financial data, and the Idefics2 model’s response. The prompt asks to calculate the combined total of interest and long-term debt for 2024, given that interest expense is double the 2014 value and long-term debt is 10% higher than in 2015. Idefics2 correctly answers the question by performing the calculations step by step, demonstrating its ability to understand and process numerical data presented in table format.
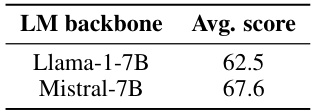
This table presents the results of an ablation study on the language model backbone used in a vision-language model. Two different language model backbones, Llama-1-7B and Mistral-7B, were compared. The average score on vision-language benchmarks is reported for each backbone, showing that Mistral-7B achieves a higher average score than Llama-1-7B, highlighting the impact of the choice of language model backbone on the model’s performance.
In-depth insights#
VLM Design Choices#
The research paper explores various Vision-Language Model (VLM) design choices, focusing on two key areas: architecture and training procedures. Regarding architecture, the study compares cross-attention and fully autoregressive approaches, highlighting the trade-offs between performance, parameter count, and inference efficiency. The fully autoregressive architecture shows superior performance when unimodal backbones are unfrozen, although it demands more sophisticated training methodologies to ensure stability. Concerning training procedures, the paper investigates the impact of pre-trained backbones, data augmentation strategies (e.g., using synthetic captions and image splitting), and multi-stage training techniques. Experimentation reveals that the choice of pre-trained language and vision models significantly affects VLM performance, while techniques like data augmentation allow for trading compute cost for enhanced downstream performance. These findings provide valuable insights into the key design decisions impacting VLM efficiency and effectiveness.
Idefics2 Architecture#
Idefics2’s architecture is a fully autoregressive model, meaning it processes both visual and textual inputs sequentially to predict the next token. This contrasts with cross-attention architectures that process both modalities concurrently. The choice of a fully autoregressive model prioritizes performance and efficiency, particularly for inference, although it requires modifications to the optimization process to ensure training stability. A significant component involves modality projection layers, which map the vision encoder’s outputs to the language model’s embedding space, effectively fusing visual and textual information. Perceiver-based pooling efficiently reduces the number of visual tokens, improving inference speed and performance without sacrificing downstream accuracy. The architecture’s flexibility allows for handling images of various sizes and aspect ratios, leading to further efficiency gains and improved performance on various multimodal benchmarks. This design demonstrates a balance between computational cost and strong performance on tasks requiring both visual understanding and natural language processing.
Multimodal Training#
Multimodal training in vision-language models (VLMs) focuses on effectively integrating visual and textual data during the training process to enhance the model’s ability to understand and generate multimodal content. Key strategies involve using datasets of image-text pairs, where models learn to associate visual features with textual descriptions. Different architectural choices influence how this integration is achieved, such as using cross-attention mechanisms to directly fuse visual and textual representations or employing fully autoregressive architectures where visual and textual data are concatenated and processed sequentially. The selection of pre-trained unimodal backbones (e.g., vision transformers, large language models) significantly affects the model’s performance, with better pre-trained models generally yielding better results. Training stability and efficiency are crucial aspects, as complex multimodal models can be computationally expensive and prone to training instability. Techniques like parameter-efficient fine-tuning (e.g., LoRA) help to mitigate these challenges and improve efficiency. Data quality is another important factor. Using high-quality image-text pairs and incorporating diverse data sources are important to improving model performance and reducing bias.
Efficiency Gains#
The research paper explores efficiency gains in vision-language models (VLMs) by focusing on reducing computational costs without sacrificing performance. A key finding is that using a learned pooling strategy, specifically a Perceiver resampler, significantly reduces the number of visual tokens needed to represent an image. This leads to a substantial decrease in both training and inference time. Furthermore, the authors demonstrate that preserving the original aspect ratio and resolution of images during processing eliminates the need for resizing, resulting in computational savings. This approach proves to be especially beneficial for tasks involving long text extraction. The trade-off between compute and performance is carefully examined; surprisingly, using more visual tokens doesn’t consistently correlate with improved performance. In addition to these optimizations, the study highlights the importance of choosing efficient training methods, such as Low-Rank Adaptation, to balance stability and computational costs. The overall goal is to create high-performing VLMs that are also resource-efficient.
Future of VLMs#
The future of Vision-Language Models (VLMs) is bright, driven by advancements in both computer vision and natural language processing. Improved model architectures, such as fully autoregressive models, promise enhanced performance and efficiency. Larger and more diverse datasets will be crucial, incorporating diverse image-text pairings, synthetic data, and data from various modalities. More effective training strategies, including multi-stage training and parameter-efficient fine-tuning, will be key to improving model scalability and reducing computational costs. Addressing inherent limitations, such as hallucinations and biases, is paramount; red-teaming and robust evaluation methods are essential. Finally, ethical considerations and responsible deployment must guide VLM development to ensure beneficial and inclusive societal impact. The evolution of VLMs will depend on the convergence of these factors, leading to increasingly sophisticated and useful applications across diverse fields.
More visual insights#
More on figures

This figure illustrates the architecture of Idefics2, a fully autoregressive vision-language model. The model takes image and text inputs. The image is first processed by a vision encoder, producing a sequence of hidden states. These states are then mapped and optionally pooled to the language model’s input space, creating visual tokens. These visual tokens are then concatenated with text embeddings, creating a combined sequence that is fed into the language model (LLM). The LLM predicts the output text tokens. The figure clearly shows the process of image encoding, modality projection (mapping visual features to the LLM’s space), pooling (optional reduction of visual tokens), and concatenation of visual and text tokens before processing with the language model.

This figure shows an example of Idefics2-base performing text transcription from a handwritten letter image. The prompt is to transcribe the content of the letter, and the model successfully transcribes it in a clean, readable format. This showcases the model’s ability to extract text information from images, even if it is handwritten and not perfectly clear.

This figure compares the performance of cross-attention and fully autoregressive architectures across three axes: the number of optimization steps, the number of images, and the number of text tokens. It shows that the fully autoregressive architecture with LoRA generally outperforms the cross-attention architecture across all three axes. The differences are visually apparent, showing a clear advantage for the fully autoregressive approach in terms of average score.

The figure shows an example of Idefics2-chatty’s ability to extract specific information from a resume and format the information into a JSON object. The prompt requests the name, email, current job, and education. The model correctly extracts this information from the provided resume image and structures the data into a well-formatted JSON output, demonstrating its capability for information extraction and structured data generation.

The figure shows an example of Idefics2-chatty’s ability to describe an image. The prompt is simply ‘Describe the image.’ The AI-generated image depicts a whimsical scene with three robot soldiers carrying large cannons shaped like bread rolls, positioned in front of the Eiffel Tower in Paris. The description provided by the model is detailed and accurate, demonstrating its capacity for image understanding and creative textual generation.

The figure shows a prompt asking what happens to fish if the number of pelicans increases. A diagram depicting a terrestrial and aquatic food chain is included in the prompt. The Idefics2 model’s response correctly explains that an increase in the pelican population would likely lead to a decrease in the fish population due to increased predation. The model also correctly points out the potential effects this would have on the ecosystem and other species that rely on fish for food.
More on tables
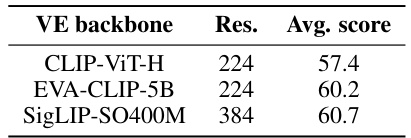
This table presents the results of an ablation study comparing the performance of different vision encoders when used in a vision-language model. The study keeps other aspects of the model (such as the language model and training procedures) constant. The goal is to isolate the impact of vision encoder choice on overall model performance, allowing for a direct comparison of the effects of different vision encoders.

The table presents the results of an ablation study comparing the performance of different language model backbones when used in a vision-language model. The study keeps other variables, like the vision backbone and training data, constant to isolate the impact of the language model choice on the average performance score across several vision-language benchmarks.
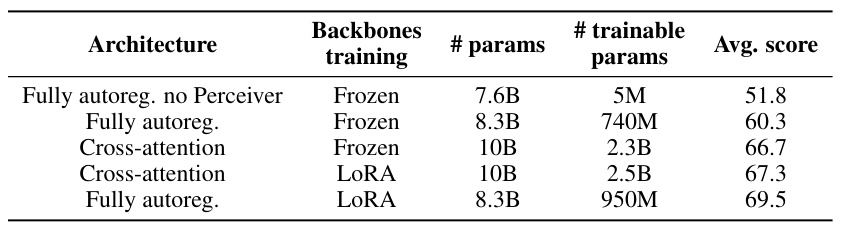
This table compares the performance of fully autoregressive and cross-attention architectures with different training methods (Frozen and LoRA). It shows that the fully autoregressive architecture, particularly when using LoRA, outperforms the cross-attention architecture in terms of average score, despite having fewer trainable parameters in some cases. This highlights the impact of architectural choices and training methods on vision-language model performance.

This table presents the results of an ablation study on different pooling strategies used in the vision encoder. The study compares the performance of using a Perceiver with 128 visual tokens versus a Perceiver with 64 visual tokens. The average score across multiple downstream benchmarks is reported for each configuration, demonstrating the impact of the number of visual tokens on model performance. The results show that reducing the number of visual tokens (from 128 to 64) using a Perceiver leads to a slight improvement in average performance.
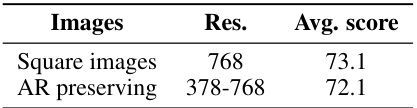
This table presents the ablation study results on the impact of preserving the original aspect ratio and image resolution on the model’s performance. It compares the average scores achieved when using square images (resized to a fixed resolution) versus when preserving the original aspect ratio and allowing variable resolutions (between 378 and 768 pixels). The results show a minor difference in average score, suggesting that maintaining the aspect ratio doesn’t significantly harm performance, which is beneficial for efficiency and handling diverse image formats.

This table presents the results of an ablation study comparing the use of synthetic captions versus alt-texts for training a vision-language model. The ‘Avg. score’ column shows the average performance of the model trained with each type of caption, indicating that synthetic captions lead to slightly better performance than alt-texts. This suggests that synthetic captions might be a more effective approach for training vision-language models, potentially due to factors such as greater quantity or consistency of data.
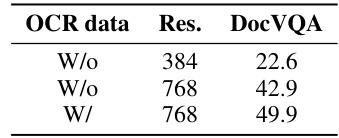
This table shows the results of an ablation study on the impact of using OCR data and different image resolutions on the performance of vision-language models for the DocVQA task. The model was pre-trained for 5,500 steps, and then fine-tuned for an additional 500 steps on the DocVQA dataset. The table compares three scenarios: (1) no OCR data and a resolution of 384 pixels, (2) no OCR data and a resolution of 768 pixels, and (3) OCR data included and a resolution of 768 pixels. The results show a clear improvement in DocVQA performance with higher resolution and the inclusion of OCR data.

This table compares the performance of Idefics2-base, a foundational vision-language model with 8 billion parameters, against other state-of-the-art base VLMs (Vision-Language Models). The comparison is based on four downstream benchmarks: VQAv2 (visual question answering), TextVQA (text in visual question answering), OKVQA (external knowledge visual question answering), and COCO (image captioning). The evaluation uses 8 random in-context examples and an open-ended setting for VQA tasks. The table highlights the model’s size (in billions of parameters), architecture (fully autoregressive or cross-attention), average number of visual tokens per image, and average scores on each benchmark.
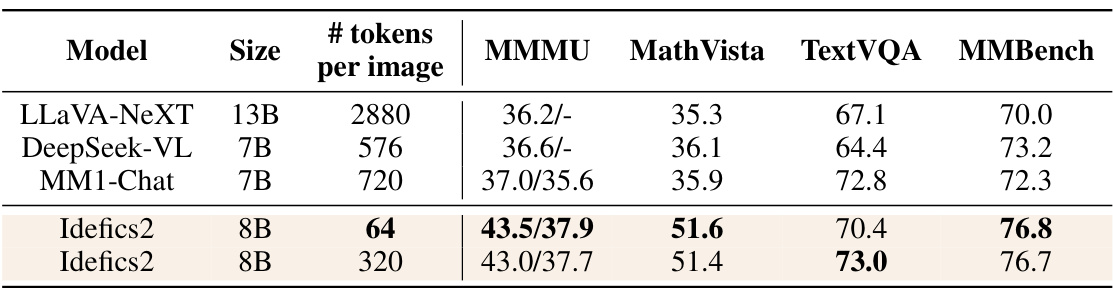
This table compares the performance of the Idefics2 model against other state-of-the-art Vision-Language Models (VLMs) on four different benchmarks: MMMU, MathVista, TextVQA, and MMBench. The comparison is done using zero-shot evaluation, meaning the models are not fine-tuned for any specific task before evaluation. Importantly, the table shows that Idefics2, even with a much smaller number of tokens per image (64 vs. hundreds or thousands for others), achieves state-of-the-art performance comparable to much larger models (up to 14B parameters). The results suggest that Idefics2’s efficient architecture contributes significantly to its performance.

This table presents the results of an ablation study on the vision encoder backbone used in the vision-language model. Three different vision encoders were compared: CLIP-ViT-H, EVA-CLIP-5B, and SigLIP-SO400M. The table shows the average score across four downstream benchmarks (VQAv2, OKVQA, TextVQA, and COCO) and the resolution of the image processed by each encoder. The results suggest that using a better pre-trained vision encoder improves the performance of the vision-language model.

This table shows the average scores achieved by three different vision-language connector methods: Linear Projection, Mapping Network, and Perceiver. The Perceiver method significantly outperforms the other two, indicating its effectiveness in fusing visual and textual information.
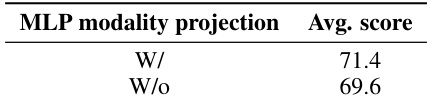
This table presents the ablation study on adding a Multilayer Perceptron (MLP) modality projection layer before the perceiver resampler in the model architecture. The experiment compares the model’s average performance with and without the MLP layer. The results demonstrate the impact of the MLP on the model’s overall performance, showing improvement when it is included. This highlights the effectiveness of the MLP in enhancing the fusion of visual and textual information.
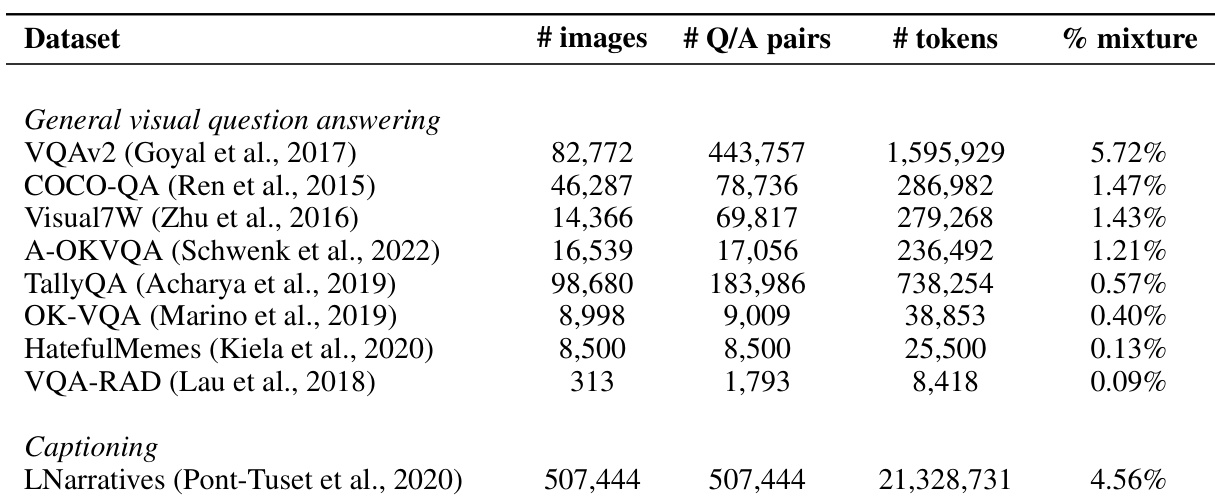
This table compares the performance of Idefics2-base, a foundational vision-language model with 8 billion parameters, against other state-of-the-art base vision-language models. The comparison is made across four different benchmarks evaluating various capabilities: VQAv2 (general visual question answering), TextVQA (OCR abilities), OKVQA (external knowledge usage), and COCO (image captioning). The evaluation uses 8 random in-context examples and an open-ended setting for VQA tasks. The table also indicates whether the models used a fully autoregressive (FA) or cross-attention (CA) architecture.
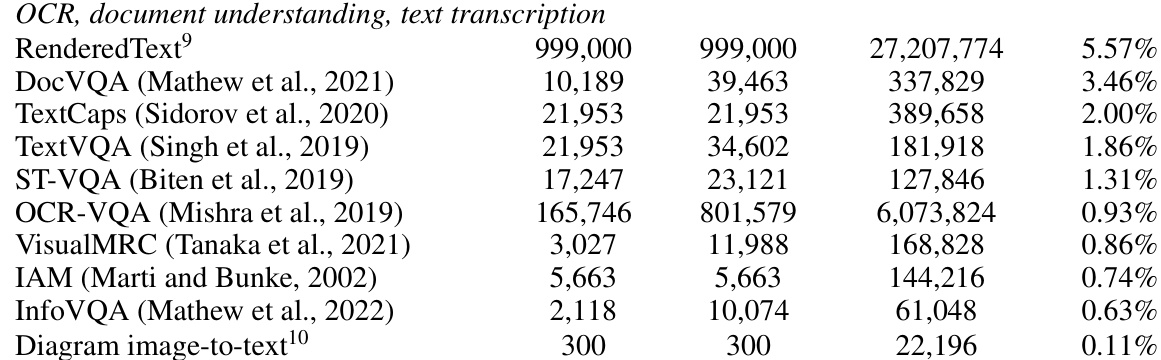
This table compares the performance of Idefics2-base, a foundational vision-language model, against other state-of-the-art base VLMs on four downstream benchmarks: VQAv2 (visual question answering), TextVQA (text VQA), OKVQA (external knowledge VQA), and COCO (captioning). The evaluation used 8 random in-context examples and an open-ended setting for VQA tasks. The table also indicates the model architecture (fully autoregressive or cross-attention) for each model.
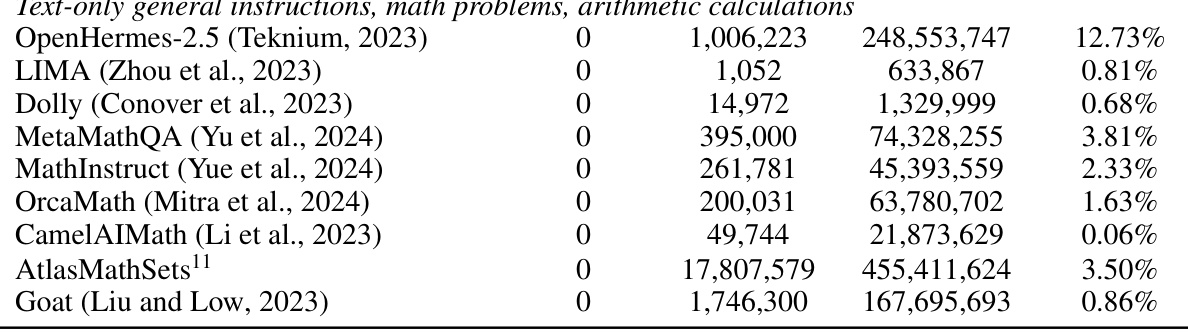
This table compares the performance of the Idefics2-base model to other state-of-the-art Vision-Language Models (VLMs) on four different benchmarks. The benchmarks assess different capabilities, including visual question answering (VQAv2, TextVQA, OKVQA), and image captioning (COCO). The table shows the average score for each model across the four benchmarks, considering the model size and the architecture (fully autoregressive or cross-attention). The number of visual tokens per image is also provided to help understand the compute cost.

This table compares the performance of the Idefics2-base model against other state-of-the-art baseline Vision-Language Models (VLMs) across four different benchmark datasets. The metrics used vary depending on the dataset (VQAv2 uses VQA accuracy, TextVQA uses VQA accuracy, OKVQA uses VQA accuracy, and COCO uses CIDEr). The evaluations were conducted using 8 random in-context examples, and an open-ended setting was used for the VQA tasks. The table also indicates whether each VLM used a fully autoregressive (FA) or cross-attention (CA) architecture.

This table compares the performance of the Idefics2 model against other state-of-the-art Vision-Language Models (VLMs) on several benchmark datasets. It highlights Idefics2’s performance in various tasks related to vision and language understanding, demonstrating its capabilities despite having a smaller parameter count than many of its competitors. The table also shows that varying the number of tokens per image (64 vs. 320) doesn’t significantly alter the model’s performance, demonstrating its efficiency.

This table compares the performance of the Idefics2-base model against other state-of-the-art Vision-Language Models (VLMs) on four benchmark tasks: VQAv2, TextVQA, OKVQA, and COCO. The benchmarks evaluate different capabilities, such as visual question answering, OCR abilities, external knowledge access, and image captioning. The table shows the average score for each model across the four benchmarks, considering the model size (in billions of parameters) and the architecture type (fully autoregressive or cross-attention). It also notes the number of visual tokens used per image, indicating a model’s efficiency.
Full paper#