↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-agent reinforcement learning (MARL) often results in communication protocols unintelligible to humans. This limits applications in real-world, ad-hoc teamwork scenarios. Existing approaches trying to align agent communication with human language face challenges due to the vast amount of data required for training and the inherent differences between human and machine languages.
The paper introduces LangGround, a novel computational pipeline leveraging Large Language Models (LLMs) to generate synthetic data grounding agent communication in natural language. LangGround aligns agent communication with human language through supervised learning from LLM-generated data and reinforcement learning signals from task environments. This approach enables human-interpretable communication, improves learning speed, and achieves zero-shot generalization to unseen scenarios. The results showcase the effectiveness of LangGround in various tasks, demonstrating that this innovative method bridges the gap between artificial and human communication for effective teamwork.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multi-agent reinforcement learning and human-computer interaction. It presents a novel approach to bridge the gap between artificial and human communication in collaborative tasks, opening new avenues for developing more effective and human-interpretable AI systems. The findings advance understanding of emergent communication in both artificial and human teams, which is relevant to various fields including robotics, human-computer interaction, and social sciences.
Visual Insights#
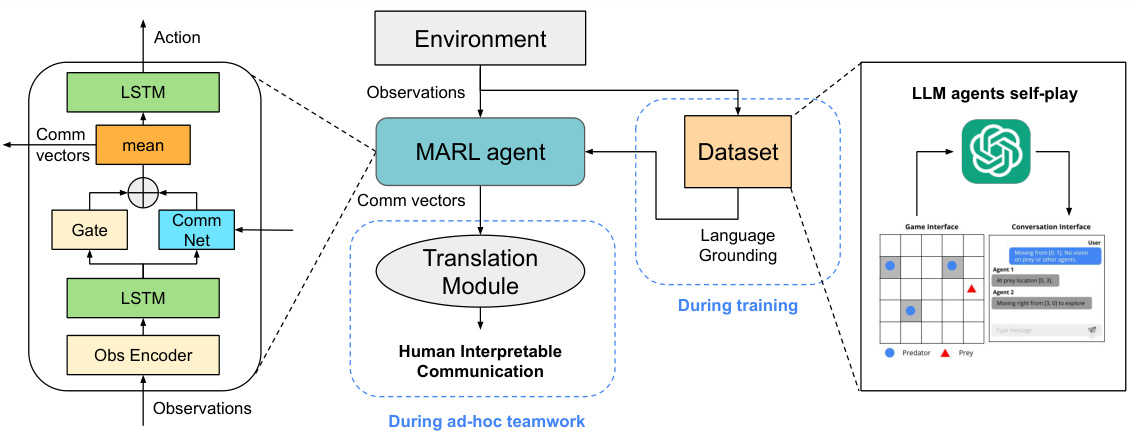
This figure illustrates the LangGround computational pipeline, which comprises three modules. The first module collects grounded communication from LLM agents. The second module aligns MARL communication with these language grounds. The third module translates aligned communication vectors into human-interpretable natural language messages using cosine similarity matching. The diagram visually depicts how these modules work together during both training and ad-hoc teamwork scenarios.
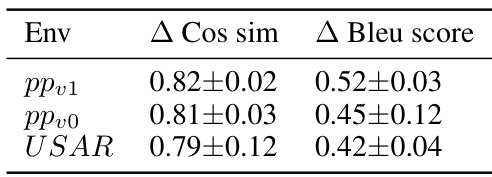
This table shows the improvement in cosine similarity and BLEU score achieved by LangGround compared to baselines without language grounding. Cosine similarity measures the alignment between agent communication vectors and word embeddings, while BLEU score assesses the similarity between agent messages and reference messages from a dataset of human-like communication.
In-depth insights#
LangGround Pipeline#
The LangGround pipeline ingeniously integrates Large Language Models (LLMs) with Multi-Agent Reinforcement Learning (MARL) to achieve human-interpretable communication in multi-agent systems. It leverages synthetic data generated by embodied LLMs engaged in collaborative tasks to ground agent communication within a natural language embedding space. This grounding process not only maintains task performance but also accelerates communication emergence. The pipeline’s innovative use of synthetic data bypasses the challenges of collecting large amounts of human-generated data for training. Furthermore, the learned communication protocols exhibit zero-shot generalization, facilitating ad-hoc teamwork with unseen teammates and novel task states, highlighting LangGround’s potential for bridging the gap between human and artificial collaboration.
LLM Communication#
The concept of “LLM Communication” in the context of multi-agent reinforcement learning (MARL) is a significant advancement, bridging the gap between human-interpretable language and artificial agent interaction. LLMs, pretrained on massive text datasets, provide a powerful framework for generating natural and contextually relevant communication. This contrasts with traditional MARL approaches that often rely on simplistic, non-human-readable communication protocols. By grounding agent communication in the LLM’s capabilities, the research aims to create more effective teamwork. However, challenges remain. LLMs can struggle with grounding their communication in the specific task environment, leading to what the paper calls ‘hallucinations’, where the generated language is not directly relevant to the task at hand. Synthetic data generated by LLMs is used to align the communication space of MARL agents with natural language, creating a form of supervised learning signal that guides protocol development. This approach shows promise but necessitates further investigation into robustness and the trade-off between task performance and communication interpretability. Ultimately, the goal is to build truly collaborative and human-understandable AI agents. Zero-shot generalization, where agents successfully interact with novel situations and partners, is a key focus, as it highlights the practical applicability of the proposed method for real-world scenarios.
MARL Alignment#
MARL alignment, in the context of multi-agent reinforcement learning and natural language, presents a significant challenge. Effective alignment necessitates bridging the gap between the communication protocols learned by MARL agents and human-understandable language. This requires careful consideration of various factors, including the design of reward functions to encourage human-interpretable communication, the selection of appropriate language models for grounding the agent’s communication, and the methods used to align the agent’s learned communication space with the semantic space of human language. Successful alignment could lead to more robust and interpretable multi-agent systems capable of seamless collaboration with humans in complex, real-world scenarios. However, this is an ongoing area of research; current solutions may face limitations such as data efficiency, generalization to unseen tasks, and the need for extensive fine-tuning. Future progress will likely depend on advances in both MARL and natural language processing, including the development of more sophisticated language models and more robust techniques for aligning different semantic spaces. Further work should explore methods to minimize the trade-off between task performance and communication interpretability, and address the challenges associated with zero-shot generalization and ad-hoc teamwork.
Zero-Shot Generalization#
Zero-shot generalization, the ability of a model to perform well on unseen tasks or data without explicit training, is a crucial aspect of robust AI. In the context of multi-agent reinforcement learning with natural language communication, zero-shot generalization means agents can successfully collaborate in novel scenarios with unfamiliar teammates and new task states. This capacity demonstrates a level of generalization beyond simple memorization. The success of zero-shot generalization is highly correlated with the quality of language grounding and the semantic alignment between agent communication and human language. A well-grounded communication system allows agents to leverage learned linguistic structures to interpret and respond to novel situations, effectively transferring knowledge from the training data to unseen circumstances. Therefore, achieving robust zero-shot generalization in this domain necessitates not only effective communication protocols but also a rich, human-like communication space that captures the nuances of teamwork. The paper’s evaluation of zero-shot performance in new task settings provides crucial insights into the effectiveness of language grounding and its impact on the robustness of the developed AI system. The results suggest that carefully constructed language grounding is a pivotal element in achieving high levels of zero-shot generalization in complex, collaborative, multi-agent environments. Future research should focus on scaling zero-shot capabilities to handle even more diverse and unpredictable conditions.
Ad-hoc Teamwork#
The research explores the concept of ad-hoc teamwork, focusing on how artificial agents can effectively collaborate with unseen teammates in dynamic, unplanned settings. This is crucial because it moves beyond traditional multi-agent systems where agents are pre-trained together, mimicking more realistic scenarios. The paper’s experimental design using diverse tasks and incorporating human-interpretable communication is a significant strength. The results demonstrate that LangGround, the proposed method, significantly improves performance in these situations, highlighting the importance of language grounding for effective ad-hoc teamwork. The experiments on various tasks showcase the generalizability of the approach and its applicability to complex scenarios. However, the reliance on synthetic data generated by LLMs raises questions regarding the transferability to real-world human-agent collaboration. Future work could address this limitation by incorporating more diverse data sources. Also, further investigation into the trade-offs between task performance and communication interpretability, especially in more challenging tasks, is warranted. The zero-shot generalization capabilities demonstrated are promising but require further exploration to fully understand their robustness. Overall, this work provides valuable insights into enabling human-like teamwork in artificial agents, but further refinements are necessary to bridge the gap to real-world applications.
More visual insights#
More on figures

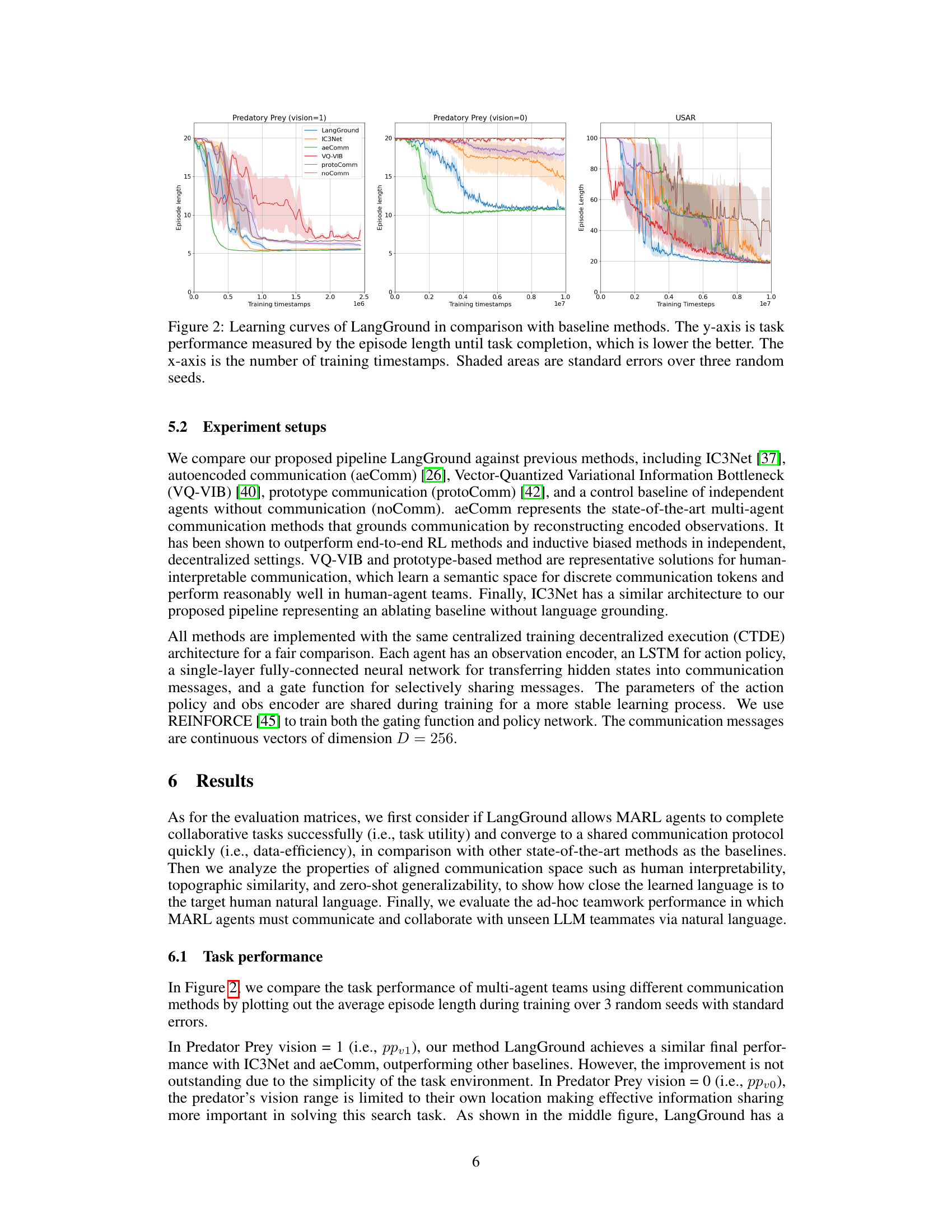
This figure shows the learning curves for LangGround and several baseline methods across three different multi-agent collaborative tasks: Predator Prey (vision=1), Predator Prey (vision=0), and Urban Search and Rescue (USAR). The y-axis represents the episode length, indicating the number of steps taken to complete the task (lower is better). The x-axis shows the number of training timestamps. The shaded regions represent standard errors across three independent runs with different random seeds. The figure allows for a comparison of LangGround’s performance against established methods in terms of learning speed and final task completion efficiency.

This figure visualizes the learned communication embedding space of agents in the Predator-Prey environment (ppvo variant). t-SNE is used to reduce dimensionality for visualization, and DBSCAN is used for clustering. Two clusters representing distinct agent observations are highlighted along with the corresponding natural language messages from the dataset D showing the alignment between the agent communication and the human language embedding space.
This figure displays the learning curves for LangGround and four baseline methods (IC3Net, aeComm, VQ-VIB, protoComm, and noComm) across three different multi-agent collaborative tasks: Predator Prey (vision=1), Predator Prey (vision=0), and Urban Search and Rescue (USAR). The y-axis represents task performance, specifically the episode length (number of timesteps) needed to complete the task; lower values indicate better performance. The x-axis shows the number of training timestamps. Shaded regions represent standard errors across three independent runs, providing a measure of the variability in performance.

This figure illustrates the LangGround pipeline, which consists of three main modules. The first module uses Large Language Models (LLMs) to generate synthetic data of human-like communication in collaborative tasks. The second module aligns the communication learned by multi-agent reinforcement learning (MARL) agents with the communication from the LLM agents. The third module translates the aligned communication vectors (from MARL) into natural language messages using cosine similarity.
This figure compares the learning curves of the proposed LangGround method against several baseline methods (IC3Net, aeComm, VQ-VIB, protoComm, and noComm) across three different multi-agent collaborative tasks: Predator Prey (with vision=1 and vision=0), and Urban Search and Rescue (USAR). The y-axis represents the episode length, indicating the number of steps taken to complete the task (lower is better), while the x-axis shows the number of training timestamps. Shaded regions represent the standard error across three different random seeds, providing a measure of variability in the results. The figure demonstrates LangGround’s performance relative to the baseline methods across various tasks and its convergence properties.
More on tables
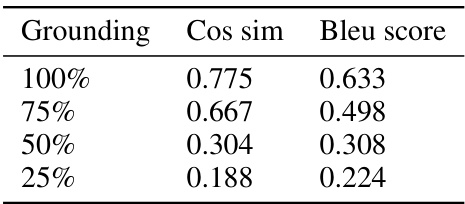
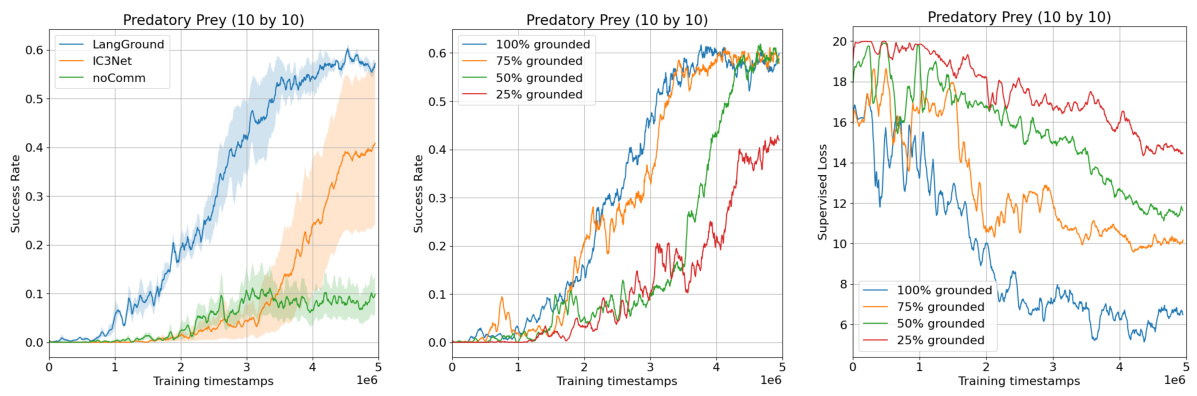
This table presents the results of evaluating the zero-shot generalization capabilities of the LangGround model on a larger Predator-Prey environment (10x10 grid). It shows the cosine similarity and BLEU scores achieved at varying levels of language grounding during training (25%, 50%, 75%, and 100%). Higher scores indicate better alignment between the learned agent communication and human language, demonstrating the model’s ability to generalize to unseen scenarios.

This table presents the results of a zero-shot generalizability test on the Predator Prey environment (ppvo). The test evaluates the ability of the LangGround agents to communicate about unseen states (prey locations) to their teammates. For each unseen prey location, the table shows the cosine similarity and BLEU score between the agent’s generated communication message and the reference messages from the dataset D (containing messages generated by LLMs). Example messages generated by the agents are also included to illustrate the quality of the generated communication.

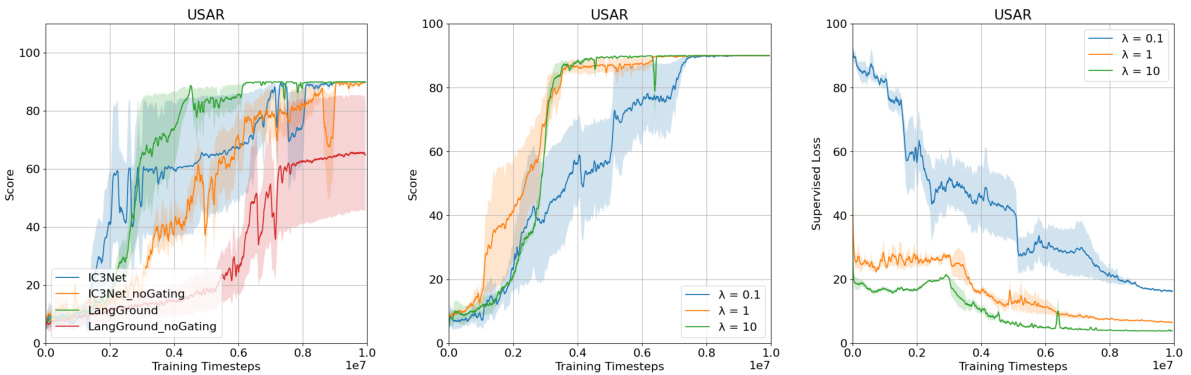
This table presents the results of the ad-hoc teamwork experiments, comparing the performance of different team compositions across three environments: Predator Prey (vision=1), Predator Prey (vision=0), and Urban Search and Rescue (USAR). The team compositions include: only LangGround agents, only LLMs, a mixed team of LangGround agents and LLMs, a mixed team of aeComm agents and LLMs, and a team with no communication (only LangGround agents or LLMs). The metric is the number of steps needed to complete the task, with lower values indicating better performance. LangGround is the proposed method in the paper. The results show that homogeneous teams (LangGround+LangGround or LLM+LLM) generally perform better than heterogeneous teams (LangGround+LLM), highlighting the importance of communication alignment and training for effective ad-hoc teamwork.
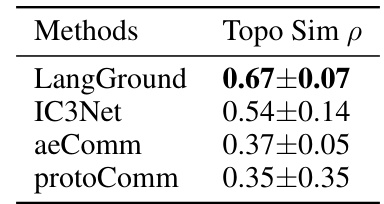
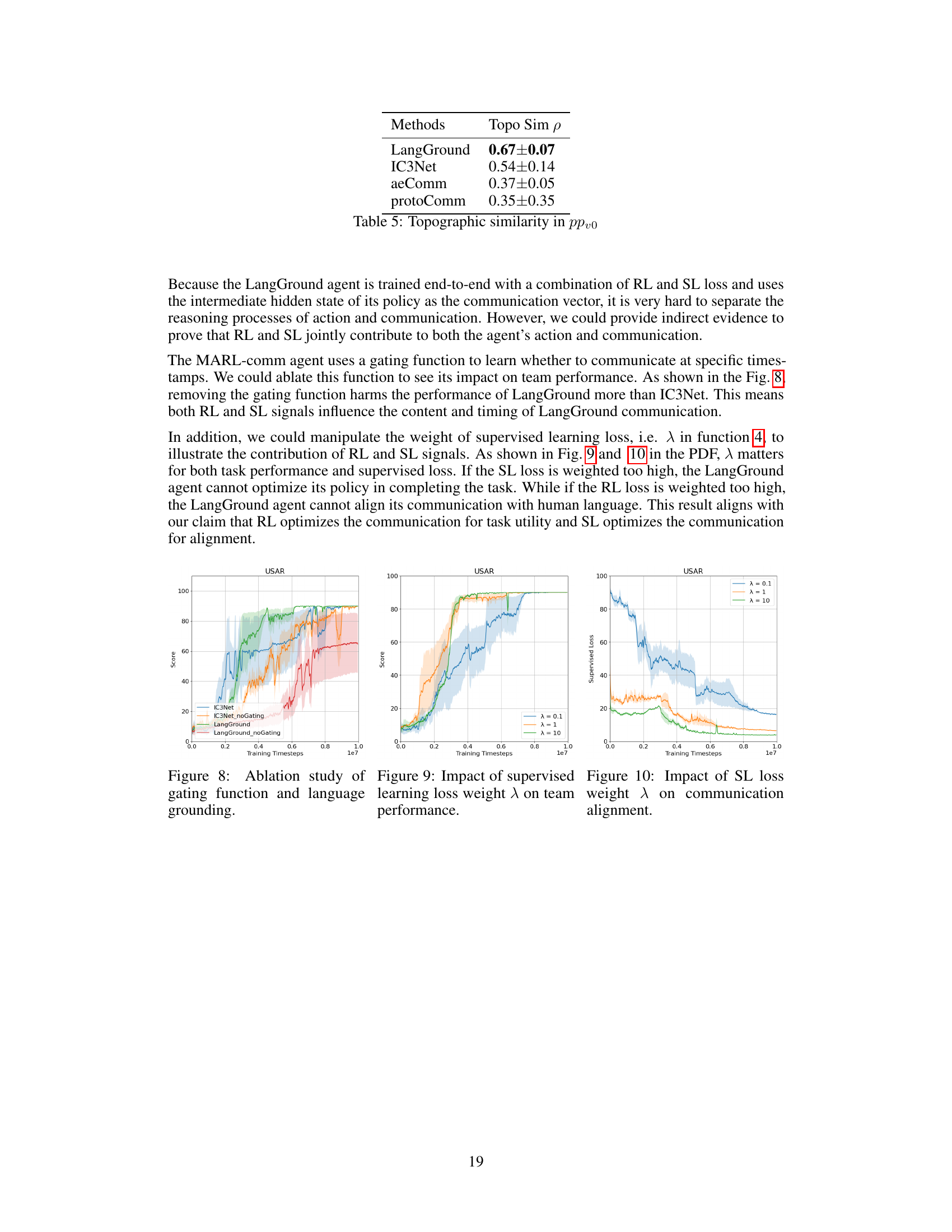
This table shows the topographic similarity (p) values for different multi-agent communication methods in the Predator-Prey environment (ppvo). Topographic similarity measures the correlation between distances in the observation space and distances in the communication space. A higher value indicates that agents generate similar communication messages for similar observations, which is a desirable property for communication effectiveness and generalizability.
Full paper#