TL;DR#
Developing effective assistive technologies for mobility-impaired individuals requires accurate forecasting of joint motion. However, obtaining sufficient data for training such models is difficult. Existing transfer learning methods struggle with the limited data available for each individual.
ReMAP tackles this by cleverly re-purposing models originally trained on able-bodied individuals. It uses a three-step process: 1) A foundation model trained on able-bodied data; 2) A mapping module uses network inversion and retrieval to adapt able-bodied data to the impaired individual; 3) A refurbishing module refines the adapted data to improve prediction accuracy. ReMAP demonstrated significant performance gains over baselines, particularly with limited data, showcasing its potential to enhance the development of assistive technologies.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel approach to address the challenge of motion forecasting for individuals with limb impairments. This is a significant hurdle in developing effective assistive technologies. The method’s data efficiency and performance improvements over existing methods make it particularly relevant for the assistive technology field, where data for impaired individuals is often scarce. It opens doors for future research on efficient model adaptation techniques and improved mobility solutions.
Visual Insights#
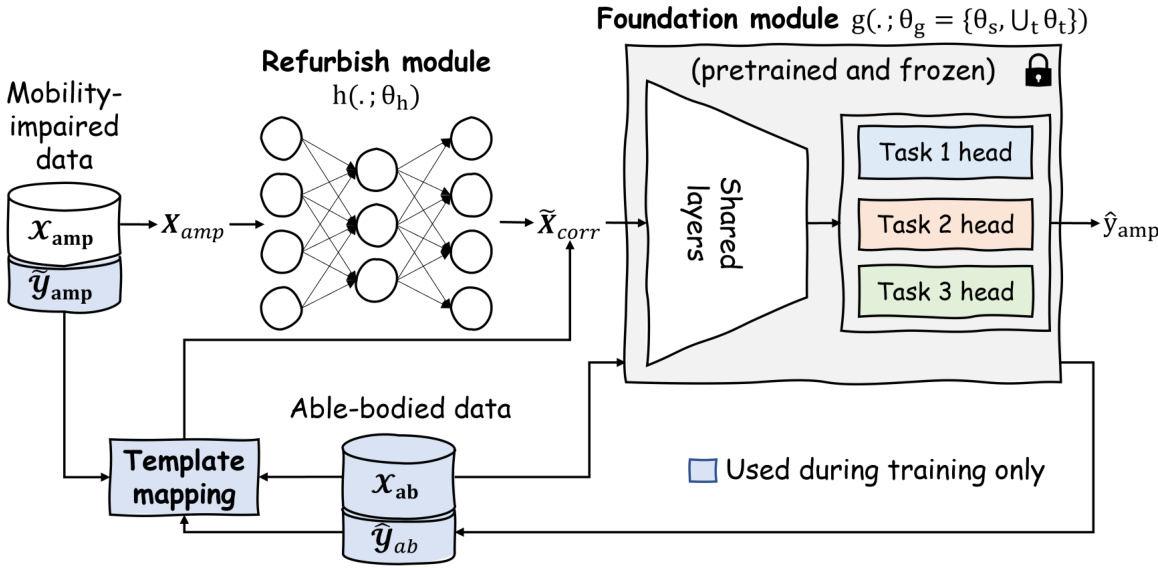
🔼 This figure illustrates the ReMAP architecture, showing how it adapts a model pretrained on able-bodied data to predict motion for individuals with mobility impairments. The ‘Refurbish module’ maps impaired inputs (Xamp) to corrected inputs (Xcorr) using a ‘Template mapping’ process which finds similar able-bodied data. These corrected inputs are then fed into the frozen ‘Foundation module’ which generates the predicted motion (ŷamp).
read the caption
Figure 1: Simplified architecture of the proposed ReMAP. The corrupt inputs Xamp from the individuals with mobility challenges are mapped to clean inputs Xcorr computed from able-bodied individuals, and the corrected inputs are used to produce the desired motion variables for the individuals with mobility challenges ŷamp using a frozen foundation module pretrained for able-bodied subjects.

🔼 This table presents the coefficient of determination (R2) values achieved using different training strategies for a training sample ratio of 0.1. It compares the performance of several approaches: cross-mapping, direct mapping, fine-tuning, nearest neighbor search, network inversion, target-based, and two hybrid methods (neighbor and inversion). The results are shown separately for models with task-shared and task-specific prediction heads. The R2 values represent the goodness of fit of the models and are presented with their standard deviations.
read the caption
Table 1: Coefficient of determination (R2) obtained with different training strategies for a train sample ratio of 0.1
In-depth insights#
ReMAP: Model Repurposing#
ReMAP, a model repurposing strategy, tackles the challenge of limited data in forecasting limb motion for impaired individuals. Instead of training new models from scratch, ReMAP cleverly adapts existing models trained on able-bodied data. This is achieved by using a combination of techniques such as network inversion to generate corrected inputs and retrieval-augmented mapping to identify the most similar able-bodied motion data. This approach avoids the computational cost and data requirements of training separate models for each impaired individual. The core innovation lies in its ability to reprogram pre-trained models for a new task (predicting motion in impaired limbs) without altering the model’s internal parameters, thus making it efficient and adaptable. The effectiveness of this methodology is demonstrated by its superior performance against conventional transfer learning and fine-tuning techniques, especially in low-data regimes. ReMAP’s efficiency and adaptability make it a promising method for advancing assistive technology and improving the quality of life for people with mobility impairments.
Network Inversion#
The concept of network inversion, as discussed in the context of the research paper, centers on refining neural network inputs to achieve desired outputs. This technique is particularly valuable when dealing with limited data, as seen in the application to mobility-impaired individuals. Instead of retraining or fine-tuning existing models, network inversion allows the adaptation of models trained on abundant able-bodied data to new, sparsely-sampled scenarios. This is achieved by iteratively adjusting the input until the network produces the desired outcome for the specific individual’s motion. The method’s efficacy hinges on its ability to effectively map impaired inputs onto analogous patterns within the able-bodied model’s input-output space, generating correction templates to bridge the gap. It is a powerful tool, but its success depends heavily on the quality and representativeness of the able-bodied data and the complexity of the mapping process. The approach is computationally intensive and its limitations include the potential for overfitting and sensitivity to noise. However, when coupled with retrieval-augmented mapping, this technique allows for efficient and accurate motion prediction, showcasing significant improvements over traditional approaches.
Retrieval-Augmented Mapping#
Retrieval-Augmented Mapping, in the context of this research paper, is a crucial technique that leverages the power of information retrieval to enhance the adaptability of pre-trained models. The core idea revolves around identifying the most relevant data points (from an able-bodied dataset) that best correlate with the desired outputs for limb-impaired individuals. Instead of training a model from scratch using scarce data from impaired individuals, this method smartly maps impaired individual inputs to corresponding able-bodied patterns. This mapping is not arbitrary but rather informed by a similarity search within the able-bodied dataset. This process effectively addresses the data scarcity problem inherent in working with patients who experience mobility limitations. The use of retrieved, relevant data makes the method particularly efficient and effective, especially when compared to traditional methods like fine-tuning, which demands substantial amounts of data for each individual case. It allows for a significant improvement in model adaptation with limited data while retaining efficiency and cost-effectiveness.
Motion Forecasting#
Motion forecasting, crucial for advanced assistive technologies like prostheses and orthoses, presents significant challenges due to the scarcity of data from impaired individuals. ReMAP, the proposed method, addresses this by repurposing models trained on able-bodied data. This innovative approach uses network inversion and retrieval-augmented mapping to adapt models without retraining, overcoming data limitations. The core idea is to map impaired individuals’ inputs to analogous able-bodied patterns, allowing the existing model to predict the necessary joint motion. Empirical studies demonstrate ReMAP’s significant improvements over conventional transfer learning, showcasing its potential to greatly enhance the efficacy of assistive technologies and improve the quality of life for individuals with limb impairments.
Adaptive Gait Prediction#
Adaptive gait prediction, a crucial aspect of advanced assistive technologies, focuses on accurately forecasting joint movements for individuals with mobility impairments. The challenge lies in the scarcity of reliable motion data for this population, hindering the development of effective personalized models. Current approaches often involve transfer learning or fine-tuning models trained on able-bodied individuals, but these methods may not fully capture the unique gait patterns of individuals with impairments. A promising avenue is neural model reprogramming, which repurposes existing models trained on larger datasets without parameter modification. This approach might involve network inversion techniques to map impaired inputs to able-bodied data representations and retrieval-augmented mapping to identify optimal input data for generating accurate predictions. The key advantage of this method lies in its data efficiency and adaptability, offering the potential to improve the quality of life for people with mobility impairments by creating more effective and personalized assistive devices. Future research should focus on expanding the range of impairments considered, enhancing the robustness of the reprogramming techniques, and integrating these predictions into real-time control systems for seamless interaction with assistive technologies.
More visual insights#
More on figures
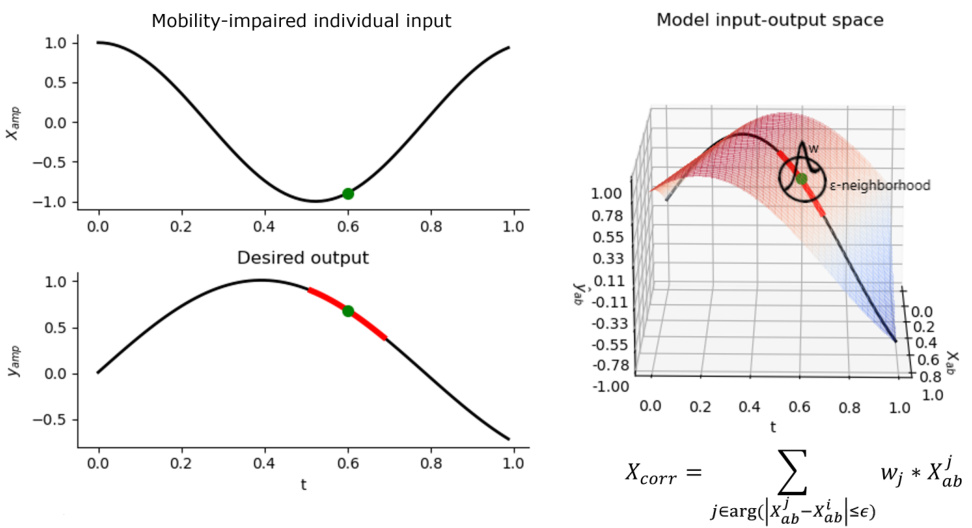
🔼 This figure illustrates how the correction input (Xcorr) for a mobility-impaired individual is calculated. It leverages the pre-trained able-bodied model’s input-output space. Instead of finding a single able-bodied input matching the desired output, it uses a sequence of outputs to find a more robust matching input. Finally, it averages the inputs within a small radius (epsilon-neighborhood) of the best match, weighting closer points more heavily.
read the caption
Figure 2: Illustration of computation of the correction input Xcorr corresponding to the k-th input sample Xamp of the mobility-impaired individual. The able-bodied input Xab that produces the most similar output as that of the desired mobility-impaired individual output yamp is searched in the input-output space of the trained able-bodied foundation module. Instead of searching based on a single desired motion variable yk, a sequence of values {yam, ...,yamp,...,yk+m} (marked by the red region in the lower left curve) is used and the able-bodied input Xab corresponding to the midpoint of the sequence is considered. Further, a neighborhood of radius e is considered around Xab and the correction input Xcorr is computed as a weighted sum of samples in this neighborhood with weights decreasing (linearly or exponentially) with increasing distance from the center Xab.

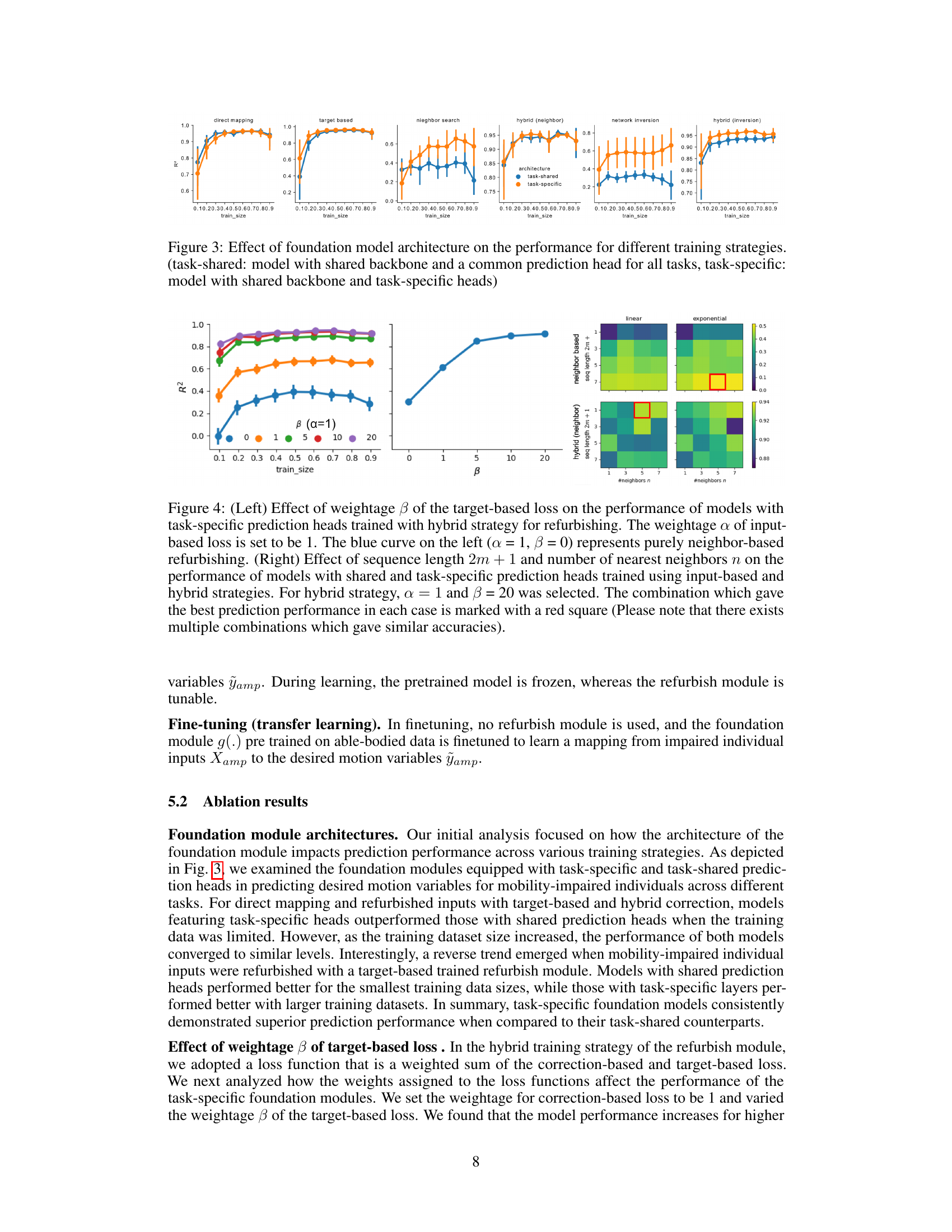
🔼 This figure compares the performance of models with different architectures (task-shared vs. task-specific) across various training strategies. Task-shared models use a single prediction head for all tasks, while task-specific models use separate heads for each task. The results show how the architecture interacts with different training methods (direct mapping, target-based, neighbor search, hybrid methods using both neighbor search and network inversion) and varying training dataset sizes, ultimately impacting the accuracy of motion prediction.
read the caption
Figure 3: Effect of foundation model architecture on the performance for different training strategies. (task-shared: model with shared backbone and a common prediction head for all tasks, task-specific: model with shared backbone and task-specific heads)

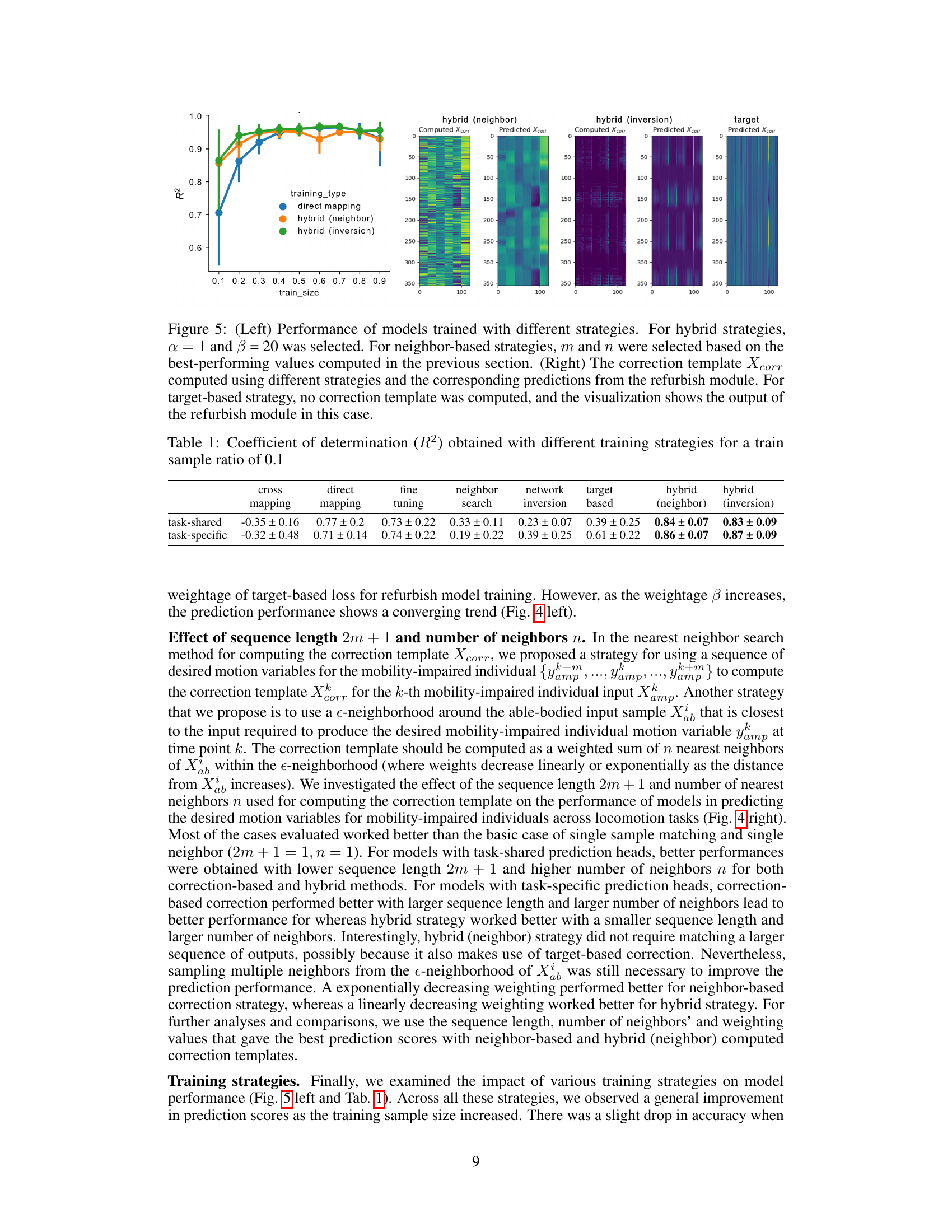
🔼 This figure analyzes the impact of different hyperparameters on the model’s performance. The left panel shows how the weighting of the target-based loss in the hybrid training strategy affects the performance, particularly for models with task-specific prediction heads. The right panel investigates the effect of sequence length and the number of nearest neighbors considered when computing correction templates using either neighbor-based or hybrid strategies. It highlights the optimal hyperparameter combinations for improved prediction accuracy.
read the caption
Figure 4: (Left) Effect of weightage β of the target-based loss on the performance of models with task-specific prediction heads trained with hybrid strategy for refurbishing. The weightage α of input-based loss is set to be 1. The blue curve on the left (α = 1, β = 0) represents purely neighbor-based refurbishing. (Right) Effect of sequence length 2m + 1 and number of nearest neighbors n on the performance of models with shared and task-specific prediction heads trained using input-based and hybrid strategies. For hybrid strategy, α = 1 and β = 20 was selected. The combination which gave the best prediction performance in each case is marked with a red square (Please note that there exists multiple combinations which gave similar accuracies).

🔼 This figure shows the performance comparison of different training strategies for the proposed ReMAP model in predicting motion for lower-limb impaired individuals. The left panel shows the R-squared values for three training strategies (direct mapping, hybrid (neighbor), hybrid (inversion)) across various training data sizes. The right panel visualizes the correction templates (Xcorr) and corresponding predictions from the refurbish module (Predicted Xcorr) for each of the training strategies, and also shows the actual target (Yamp) values.
read the caption
Figure 5: (Left) Performance of models trained with different strategies. For hybrid strategies, α = 1 and β = 20 was selected. For neighbor-based strategies, m and n were selected based on the best-performing values computed in the previous section. (Right) The correction template Xcorr computed using different strategies and the corresponding predictions from the refurbish module. For target-based strategy, no correction template was computed, and the visualization shows the output of the refurbish module in this case.
More on tables

🔼 This table presents the coefficient of determination (R2) values achieved using various training strategies on a dataset with a train sample ratio of 0.1. The different strategies compared include cross-mapping, direct-mapping, fine-tuning, neighbor search, network inversion, target-based, and hybrid approaches (both neighbor and inversion based). Results are shown separately for both task-shared and task-specific model architectures. This allows for a direct comparison of the performance of different model reprogramming methods under low data conditions.
read the caption
Table 1: Coefficient of determination (R2) obtained with different training strategies for a train sample ratio of 0.1

🔼 This table shows the R-squared values achieved by different training strategies (cross-mapping, direct mapping, fine-tuning, neighbor search, network inversion, target-based, hybrid (neighbor), hybrid (inversion)) when only 10% of the training data is used. The results are further broken down by whether a task-shared or task-specific architecture of the foundation module was used. R-squared is a statistical measure of how well the model fits the data, with higher values indicating a better fit.
read the caption
Table 1: Coefficient of determination (R2) obtained with different training strategies for a train sample ratio of 0.1

🔼 This table presents the coefficient of determination (R2) values achieved using various training strategies on a dataset with a training sample ratio of 0.1. The results compare different model architectures (task-shared vs. task-specific) and training approaches (cross-mapping, direct mapping, fine-tuning, neighbor search, network inversion, target-based, and hybrid methods). This allows for a comparison of the effectiveness of ReMAP against baseline methods in low-data regimes.
read the caption
Table 1: Coefficient of determination (R2) obtained with different training strategies for a train sample ratio of 0.1

🔼 This table presents the coefficient of determination (R2) values achieved using various training strategies with a train sample ratio of 0.1. The results are categorized by whether the foundation model used task-shared or task-specific prediction heads. It compares the performance of cross-mapping, direct mapping, fine-tuning, and the proposed ReMAP methods (using both neighbor search and network inversion), showcasing the effectiveness of the proposed approach, particularly in low-data regimes.
read the caption
Table 1: Coefficient of determination (R2) obtained with different training strategies for a train sample ratio of 0.1
Full paper#