↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models often struggle with the computational cost of scaling up. Sparse Mixture of Experts (SMoE) models aim to solve this by only activating a subset of expert networks for each input. However, SMoE suffers from low expert activation, meaning many experts remain unused, limiting the model’s potential. This leads to suboptimal performance and hinders scalability.
To overcome this, the researchers propose Multi-Head Mixture-of-Experts (MH-MoE). MH-MoE splits each input token into sub-tokens, assigning them to different expert networks in parallel. This approach ensures that most experts get activated, leading to denser expert utilization. Extensive experiments show that MH-MoE significantly improves expert activation, boosting performance and scalability compared to previous SMoE methods across various tasks and model sizes. MH-MoE demonstrates higher expert activation and better scalability, resulting in improved performance across diverse downstream tasks. Its simple design makes it easy to integrate into existing frameworks, furthering its potential impact on large model development.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models and Mixture-of-Experts models. It directly addresses the limitations of current SMoE architectures by proposing a novel Multi-Head Mixture-of-Experts (MH-MoE) method that significantly improves expert activation and scalability. The results demonstrate substantial performance gains across various tasks, highlighting the method’s potential for advancing large model development. Furthermore, MH-MOE’s simple and decoupled design makes it easily adaptable to existing frameworks, opening up new avenues for research in model efficiency and performance enhancement.
Visual Insights#
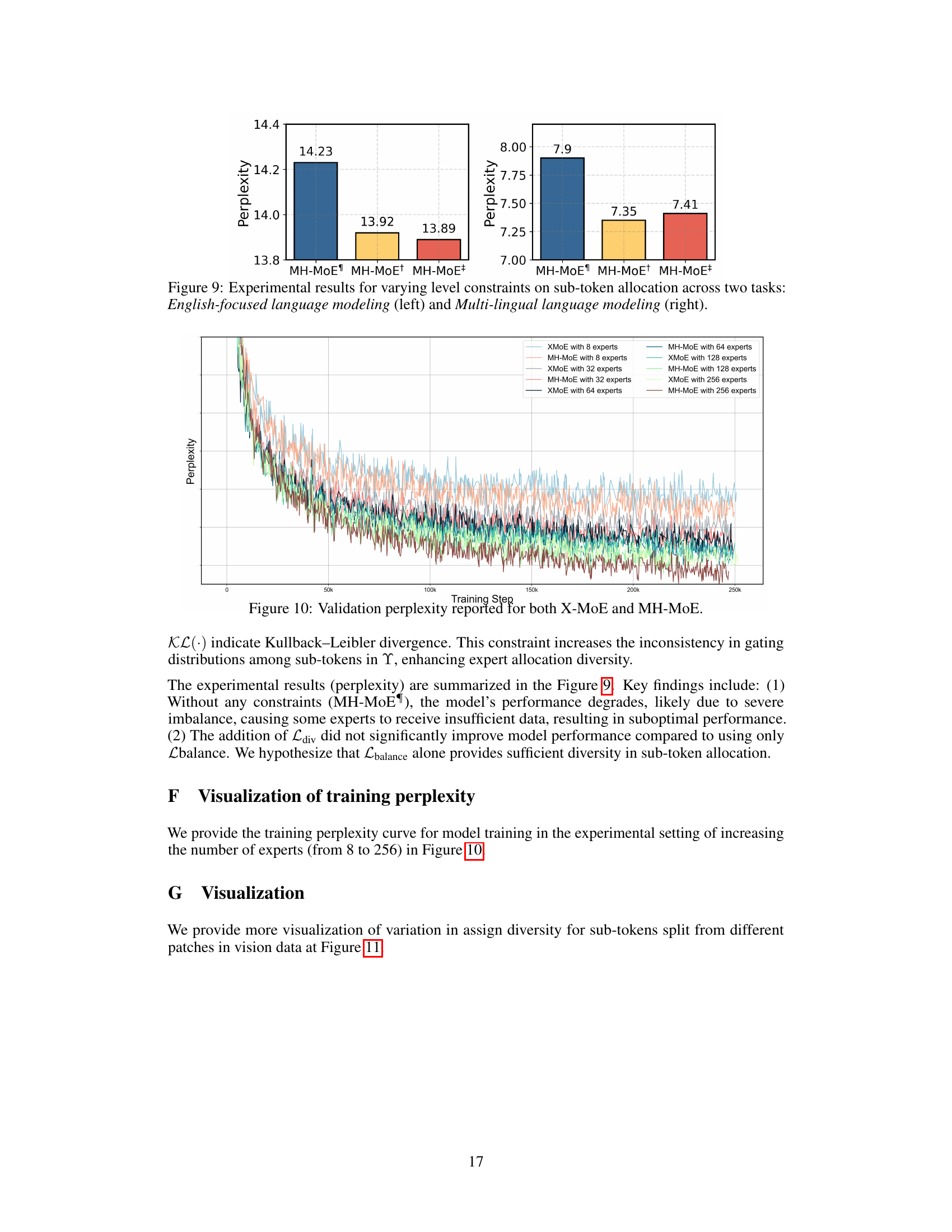
This figure shows the expert activation distribution in both SMoE and MH-MoE. Subfigure (a) compares the expert activation distribution of SMoE and MH-MoE on the XNLI corpus, highlighting that MH-MoE achieves significantly higher expert activation. Subfigure (b) illustrates how MH-MoE achieves a more fine-grained understanding of semantically rich image patches by distributing sub-tokens to a wider range of experts.

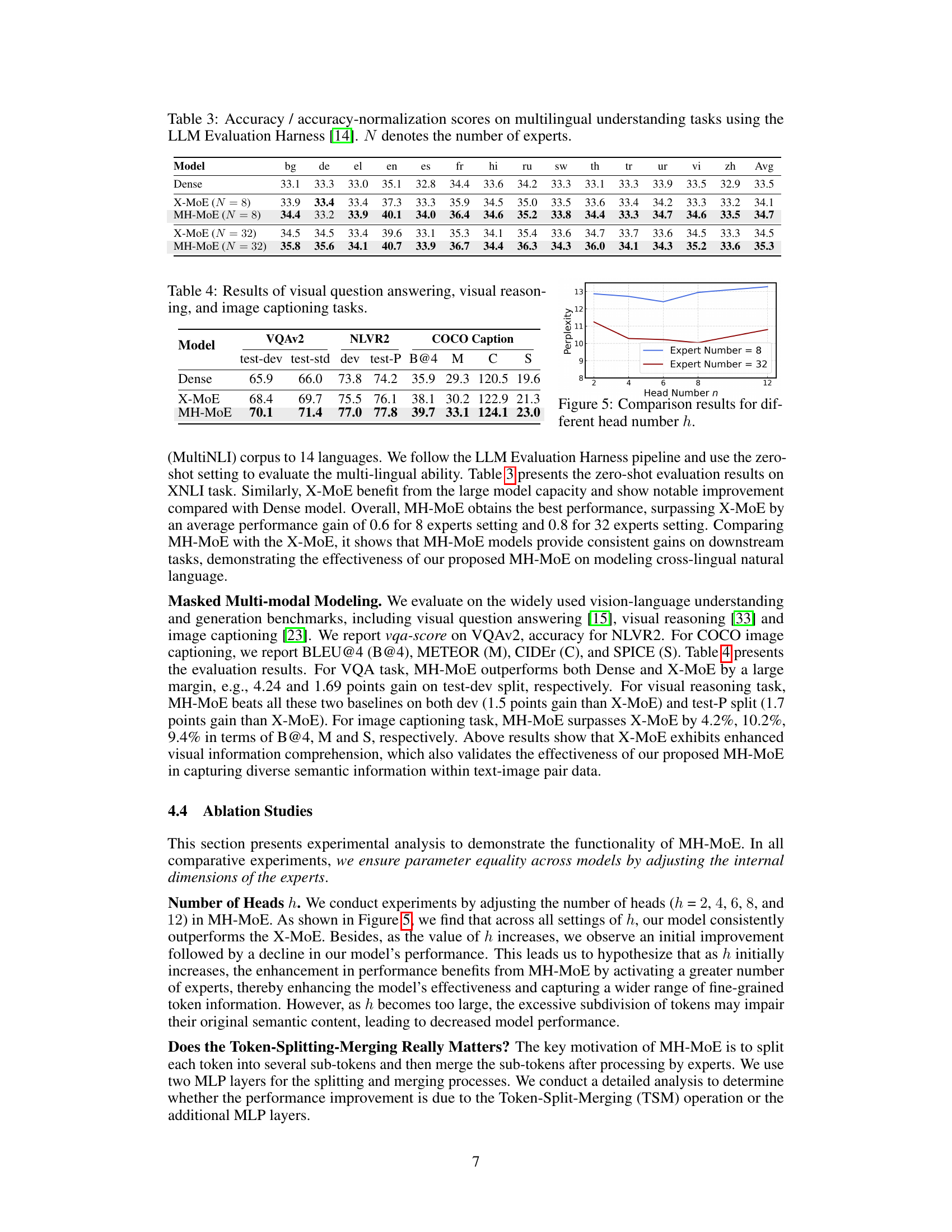
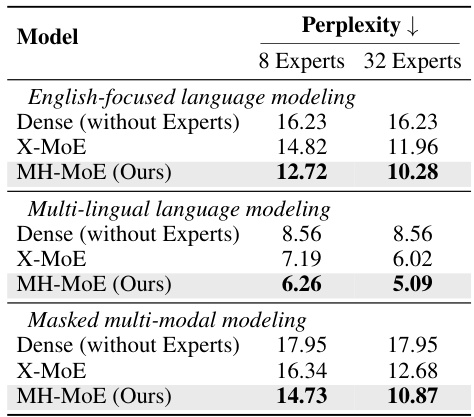
This table presents the results of several language understanding tasks using the LLM Evaluation Harness. The models compared are Dense, X-MoE (with 8 and 32 experts), and MH-MoE (with 8 and 32 experts). The performance is measured using accuracy and accuracy-normalized scores across multiple benchmarks including ARC-Challenge, ARC-Easy, RTE, BookQA, Winogrande, PiQA, BoolQ, HellaSwag, and TruthfulQA. The table shows the performance improvement achieved by MH-MoE over the baseline models (Dense and X-MoE).
In-depth insights#
MH-MoE: Sparsity Boost#
The heading “MH-MOE: Sparsity Boost” suggests a method to enhance the efficiency of Mixture-of-Experts (MoE) models. Standard MoE models suffer from low expert utilization, meaning only a small fraction of experts are actively used during training and inference. MH-MOE likely addresses this by improving expert activation, potentially through a multi-head mechanism that splits input tokens, enabling parallel processing by diverse experts. This approach aims to increase the overall sparsity of the model, making it more computationally efficient while maintaining or improving model performance. The “boost” implies a significant increase in the effective use of model parameters. This efficiency gain is crucial for scaling large-scale language models and other resource intensive tasks. Success depends on effectively balancing the computational cost of the multi-head mechanism with the benefits of increased expert utilization.
Sub-token Allocation#
The strategy of sub-token allocation, as employed in the Multi-Head Mixture-of-Experts (MH-MoE) model, is a crucial innovation enhancing expert utilization. Instead of routing whole tokens to single experts, MH-MoE cleverly splits each token into multiple sub-tokens. These sub-tokens are then independently assigned to different experts, allowing for parallel processing and a more granular representation of the input. This method is particularly beneficial for tokens carrying rich semantic information; these tokens are more likely to have their sub-tokens distributed among multiple experts, leading to a deeper contextual understanding. This contrasts with traditional SMoE approaches, which often suffer from low expert activation. The strategic distribution of sub-tokens improves scalability and model efficiency by promoting a more balanced utilization of experts. The design allows MH-MoE to seamlessly integrate with existing SMoE frameworks, further highlighting its practical applicability and potential for widespread adoption.
Scalability & Efficiency#
The research paper explores enhancing the scalability and efficiency of large language models. A core challenge addressed is the low expert activation issue inherent in sparse Mixture-of-Experts (MoE) models. The proposed Multi-Head Mixture-of-Experts (MH-MoE) architecture tackles this by splitting input tokens into sub-tokens and distributing them across multiple experts. This strategy significantly improves expert utilization, leading to denser activation and improved model performance. The method is shown to be easily integrated into existing MoE frameworks, implying significant practical implications. Further enhancing scalability, MH-MoE effectively leverages the capacity of large models without a proportionate increase in computational cost. Results across diverse pre-training tasks and model sizes demonstrate the effectiveness of this approach, highlighting its potential to unlock the full capabilities of even larger models, thus enhancing both efficiency and scalability.
Multi-Modal MH-MoE#
A Multi-Modal MH-MoE model would be a significant advancement in artificial intelligence, combining the strengths of Mixture-of-Experts (MoE) models with the multi-head attention mechanism and extending it to handle multiple modalities. The multi-head approach allows the model to process different aspects of the input data in parallel, improving efficiency and potentially leading to a deeper understanding. The integration of multiple modalities (e.g., text, images, audio) enables the model to learn richer and more nuanced representations. The use of MoE would allow for scaling the model’s capacity without a proportional increase in computational cost, making it more practical for real-world applications. However, challenges would remain, such as ensuring proper communication and interaction between experts, handling the sparsity of expert activations, and managing the computational complexity of the multi-modal integration.
Ablation Study Insights#
Ablation studies are crucial for isolating the impact of individual components within a complex model. In the context of a research paper focusing on a novel Multi-Head Mixture-of-Experts (MH-MoE) model, an ablation study would systematically remove or alter specific parts of the architecture to observe their effects on performance. For example, removing the multi-head layer and merge layer would test the contribution of the token splitting-merging mechanism to enhanced expert activation and finer-grained understanding. Similarly, varying the number of experts or the number of heads would assess the model’s scalability and sensitivity to hyperparameter choices. Analyzing the results across different downstream tasks (e.g., English language modeling, multi-lingual language modeling, masked multi-modality modeling) is key to understanding the generalizability of the MH-MoE’s improvements and revealing task-specific effects of each component. The ablation study should carefully control for the number of parameters across all variations to ensure fair comparisons and to pinpoint the specific architectural contributions rather than simply overall parameter scaling effects. The results could reveal which parts are most essential for the model’s success, thus guiding future model development and optimization. A thorough analysis would reveal whether the model’s performance gains stem from more efficient expert utilization or enhanced representational capacity.
More visual insights#
More on figures
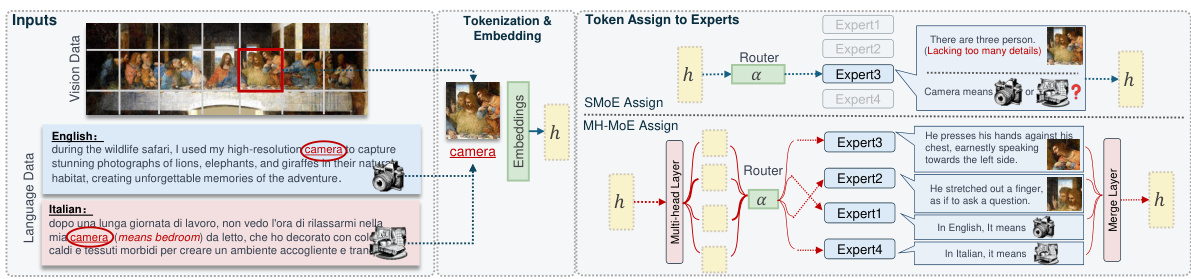
This figure illustrates the workflow of the Multi-Head Mixture-of-Experts (MH-MoE) model. It shows how input tokens (both vision and language data) are split into sub-tokens, which are then independently processed by different expert networks. The sub-tokens are assigned to experts based on their content (using a routing mechanism). This parallel processing improves the model’s ability to handle nuanced linguistic and visual information. Finally, the processed sub-tokens are merged to produce the final output. The example uses images with captions in English and Italian. Note that the experts are attending to different aspects of the image and different meanings of the word “camera” in the two languages.

This figure compares the architectures of a standard Sparse Mixture of Experts (SMoE) layer and the proposed Multi-Head Mixture of Experts (MH-MoE) layer. The SMoE architecture shows a single token being routed to a subset of expert networks based on routing scores. The MH-MoE architecture shows the input token being split into multiple sub-tokens, each independently routed to expert networks. A merging layer then combines the outputs of the experts into a single output vector for the next layer. The key difference is that MH-MoE uses a multi-head mechanism to improve expert utilization and capture information from different representation spaces.

The figure displays the perplexity curves during training for three pre-training tasks: English-focused language modeling, multi-lingual language modeling, and masked multi-modal modeling. Four model variations are compared: Dense (a traditional dense model), X-MoE (a standard sparse mixture-of-experts model), and MH-MoE with both 8 and 32 experts. The plots illustrate the performance of each model across different training steps. The results show that MH-MoE consistently achieves lower perplexity than the other models, indicating improved learning efficiency and better language representation. The perplexity decrease is also more pronounced in MH-MoE as the number of experts increases.

The figure shows the perplexity curves for three different pre-training tasks (English-focused language modeling, multi-lingual language modeling, and masked multi-modal modeling) across different training steps for three different models (Dense, X-MoE, and MH-MoE). It demonstrates the performance of MH-MoE compared to the baseline models across various pre-training tasks. The lower perplexity indicates better performance, which is shown consistently by MH-MoE in all tasks. It also shows the impact of increasing the number of experts from 8 to 32.

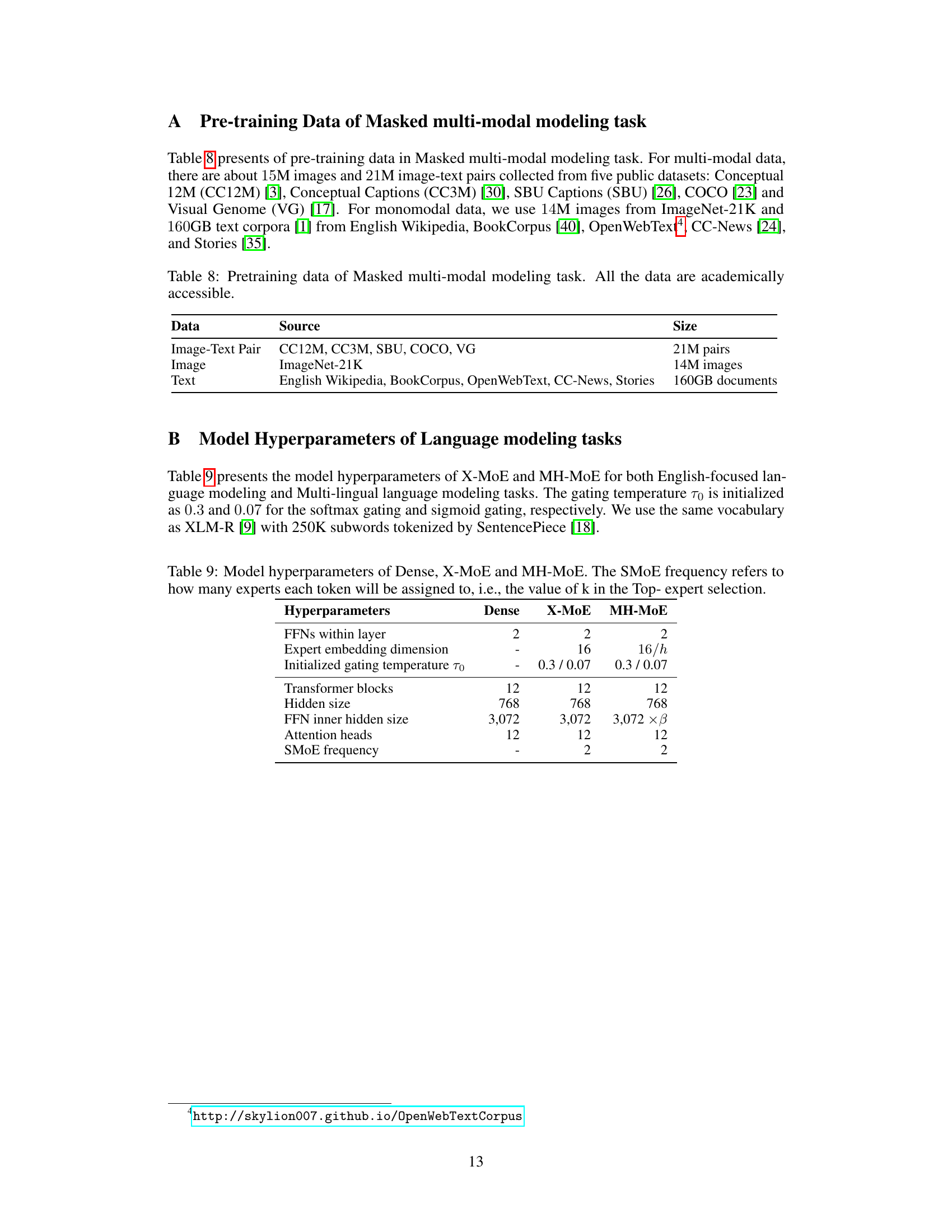
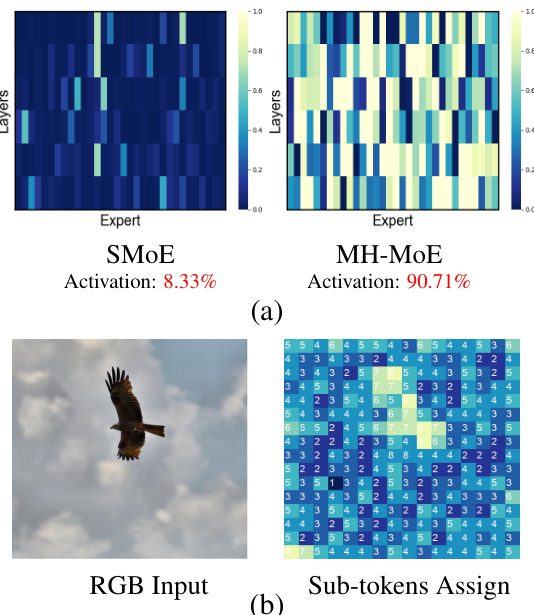
This figure compares the distribution of expert activation in X-MoE and MH-MoE models across different numbers of heads (h). It shows heatmaps representing the activation frequency of each expert across multiple layers for each model. The heatmaps visually demonstrate that MH-MoE achieves a more even distribution of expert activation compared to X-MoE, indicating a more efficient utilization of experts. The impact of increasing the number of heads (h) on expert activation is also illustrated.
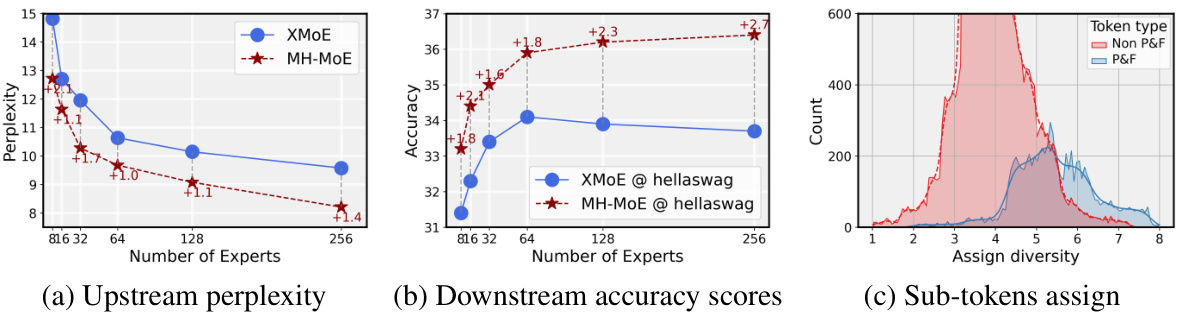
This figure presents a comparative analysis of X-MoE and MH-MoE across three key aspects: upstream training perplexity, downstream accuracy on the hellaswag task, and sub-token assignment diversity. Panel (a) shows that MH-MoE consistently achieves lower perplexity than X-MoE as the number of experts increases, demonstrating its superior training efficiency. Panel (b) illustrates that MH-MoE yields higher accuracy on the hellaswag task compared to X-MoE, highlighting its improved performance in downstream tasks. Lastly, panel (c) reveals that MH-MoE exhibits a greater diversity in sub-token assignment, distributing sub-tokens to a wider range of experts, especially for polysemous and false cognate tokens (P&F), indicating enhanced semantic understanding.

This figure shows the expert activation distribution in the standard SMoE model and the proposed MH-MoE model. Figure 1(a) compares the activation ratio of experts in each layer for both models on the XNLI corpus. It demonstrates that MH-MoE achieves significantly higher expert activation. Figure 1(b) illustrates that MH-MoE achieves a finer-grained understanding of semantically rich image patches by distributing sub-tokens from these patches to a more diverse set of experts, indicated by brighter colors in the image. This suggests that MH-MoE can better capture subtle differences in complex data through the use of multiple representation spaces across the experts.
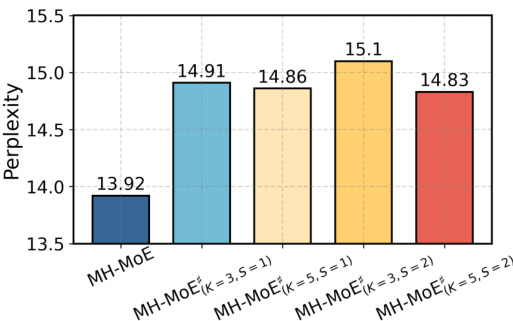
This figure compares the performance of different kernel sizes (K) and strides (S) used in a Conv1D layer for token splitting in the MH-MoE model. It shows that varying the kernel size and stride affects the model’s performance, measured by perplexity on a downstream task. The best performing configuration indicates that finding optimal parameters for token splitting is crucial for achieving the best results with MH-MoE.
The figure showcases the validation perplexity curves for Dense, X-MoE, and MH-MoE across three pre-training tasks (English-focused language modeling, multi-lingual language modeling, and masked multi-modal modeling). The curves show the perplexity over training steps for different model architectures and the number of experts used. MH-MoE consistently demonstrates lower perplexity than X-MoE and Dense models. The perplexity decreases as the number of experts increases for all models, highlighting improved model capability with more parameters.

This figure shows the validation perplexity curves for both X-MoE and MH-MoE models with varying numbers of experts (8, 32, 64, 128, 256) during the training process. It illustrates the performance of the models across different scales, allowing for a comparison of their learning efficiency and overall performance. The lower the perplexity, the better the model’s performance. The curves clearly show how MH-MoE consistently outperforms X-MoE across all scales and expert counts, demonstrating its improved learning efficiency. The results also demonstrate that increasing the number of experts generally leads to lower perplexity, highlighting the scalability of both models.

This figure shows two key aspects of the proposed Multi-Head Mixture-of-Experts (MH-MoE) model. (a) compares the expert activation distribution in MH-MoE and the standard Sparse Mixture-of-Experts (SMoE) model on the XNLI dataset. It highlights that MH-MoE achieves significantly higher expert activation (90.71% vs 8.33%), indicating better utilization of model capacity. (b) illustrates how MH-MoE processes semantically rich image patches by splitting tokens into sub-tokens and assigning them to multiple distinct experts. This allows for a more nuanced and granular understanding of semantic information within the image.
More on tables
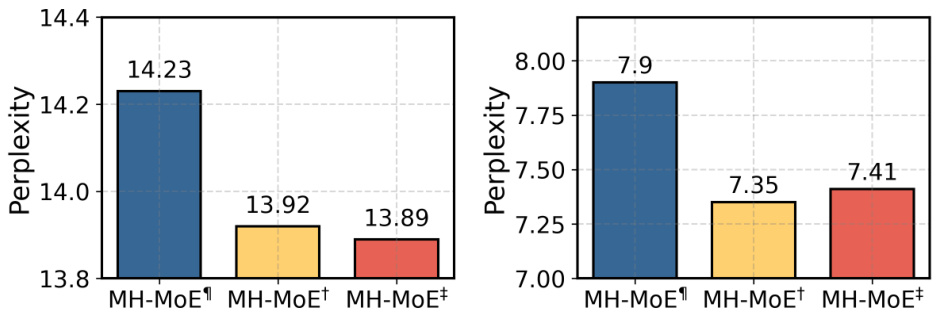
This table presents the results of the upstream perplexity evaluation for the English-focused language modeling, multi-lingual language modeling, and masked multi-modal modeling tasks. The perplexity, a measure of how well the model predicts the next word in a sequence, is reported for two different expert settings: 8 experts and 32 experts. Lower perplexity values indicate better model performance.

This table presents the results of multilingual understanding tasks evaluated using the LLM Evaluation Harness. It compares the performance of four different models: Dense, X-MoE (with 8 and 32 experts), and MH-MoE (with 8 and 32 experts). The performance is measured using accuracy and accuracy normalization scores across 14 different languages. The table shows how the proposed MH-MoE model outperforms other models, particularly when a larger number of experts are used.
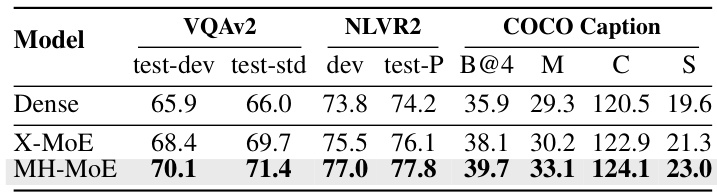
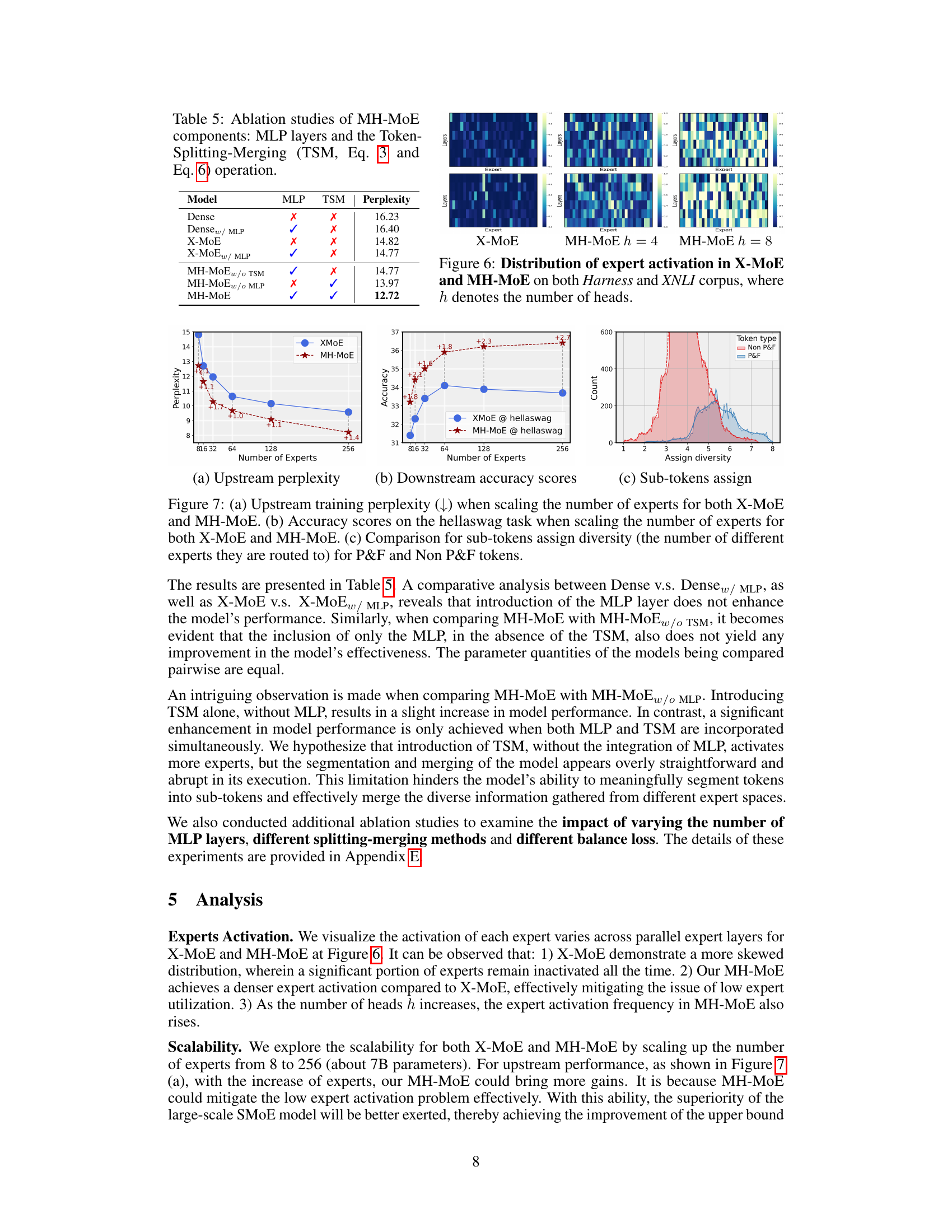
This table presents the performance of three different models (Dense, X-MoE, and MH-MoE) on three downstream tasks: Visual Question Answering (VQAv2), Numerical Visual Reasoning (NLVR2), and COCO Captioning. The results show the performance metrics for each model on the respective datasets, demonstrating the improvement achieved by MH-MoE over the baseline models.
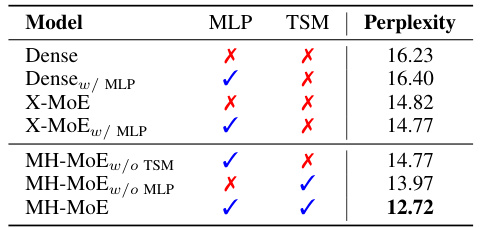
This table presents the results of ablation experiments conducted to analyze the impact of different components of the MH-MoE model on its performance. Specifically, it investigates the contributions of MLP layers and the Token-Splitting-Merging (TSM) operation. The table shows the perplexity achieved by different model variations: Dense (baseline without any MoE components), Dense with MLP layers, X-MoE (another MoE baseline without MH-MoE components), X-MoE with MLP layers, MH-MoE without TSM, MH-MoE without MLP layers, and the full MH-MoE model. The results highlight the individual and combined effects of the MLP layers and TSM on the model’s performance, indicating the importance of both for optimal results.
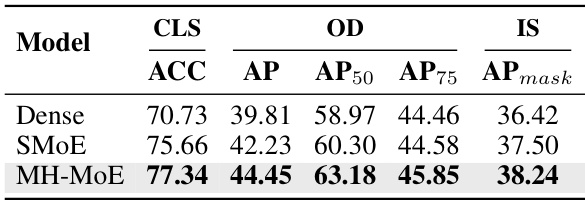
This table presents the performance comparison of three different models (Dense, SMoE, and MH-MoE) on three pure vision tasks: classification on ImageNet-1k, object detection, and instance segmentation on COCO. The number of experts used in the SMoE and MH-MoE models is 8. The metrics used for evaluation are accuracy (ACC) for classification and Average Precision (AP), AP at 50% IoU (AP50), AP at 75% IoU (AP75), and Average Precision for instance segmentation (APmask) for the detection and segmentation tasks.

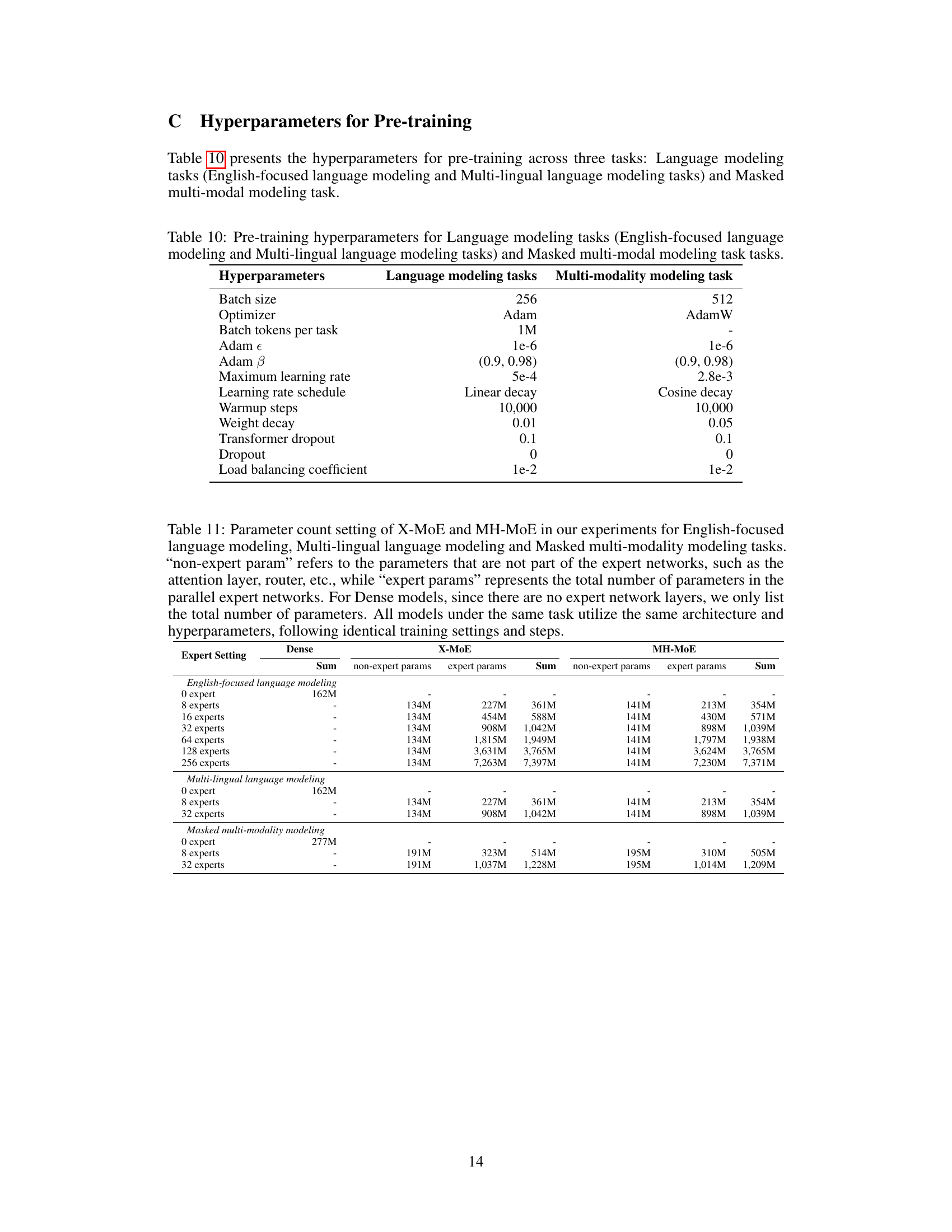
This table details the datasets used for pre-training the Masked Multi-modal model. It lists the type of data (Image-Text Pairs, Images, and Text), their respective sources (e.g., Conceptual Captions, ImageNet-21K, English Wikipedia), and their sizes (number of pairs, images, and total size in GB). All data sources are publicly available for academic use.
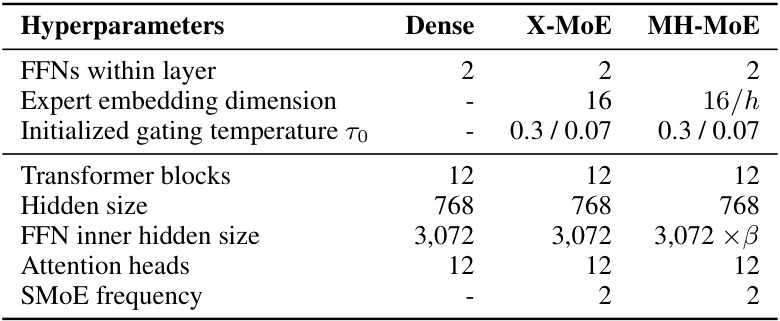
This table shows the hyperparameters used for three different model architectures: Dense, X-MoE, and MH-MoE. It details the settings for various aspects of the models, including the number of feed-forward networks (FFNs) within each layer, expert embedding dimensions, initialized gating temperature, number of transformer blocks, hidden size, FFN inner hidden size, number of attention heads, and the frequency with which sparse mixture-of-experts (SMoE) are activated.

This table details the hyperparameters used during the pre-training phase for three distinct tasks: English-focused language modeling, multi-lingual language modeling, and masked multi-modality modeling. For each task, it specifies settings such as batch size, optimizer, learning rate schedule, and other key training parameters. The differences in hyperparameters across tasks reflect the varying nature and requirements of each modeling approach.
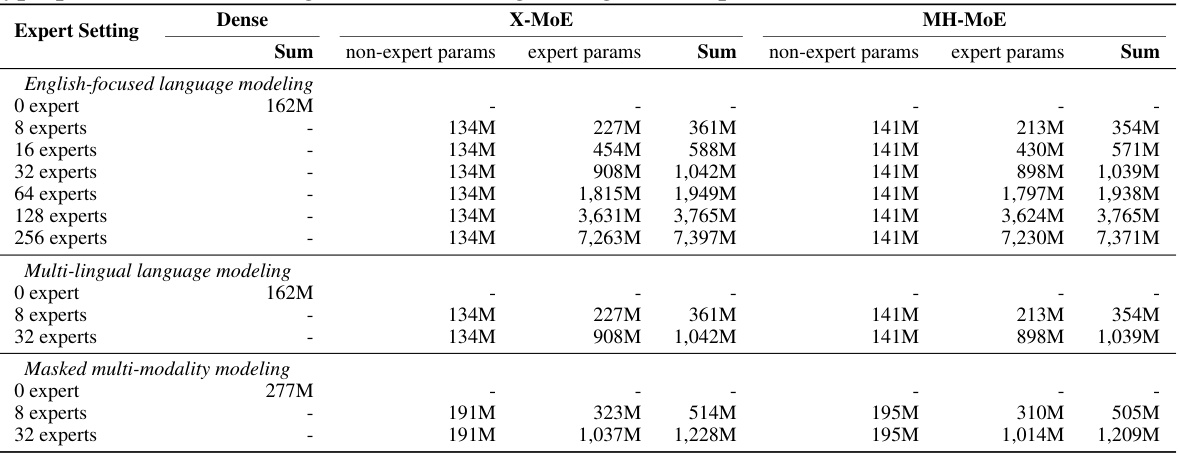
This table details the parameter counts for the Dense, X-MoE, and MH-MoE models across three pre-training tasks with varying numbers of experts. It breaks down the parameter counts into ’non-expert’ parameters (shared components) and ’expert’ parameters (those specific to each expert). The table highlights the impact of adding experts on the overall model size for each of the three tasks.
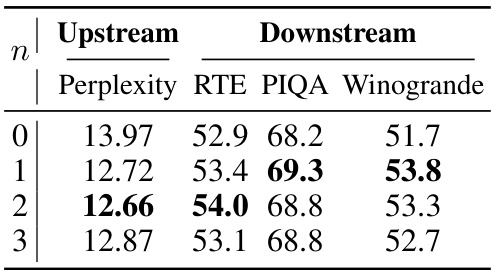
This table presents the results of experiments evaluating the impact of varying the number of MLP layers (n) on the model’s performance. The results are averaged over five runs to account for variations due to randomness in the training process. The table shows the upstream perplexity (a measure of the model’s performance on a language modeling task) and downstream performance on three different Natural Language Understanding (NLU) tasks: RTE, PIQA, and Winogrande. The aim is to determine if adding more MLP layers improves the model’s overall performance.
Full paper#