TL;DR#
Graph Neural Networks (GNNs) often struggle to generalize to unseen data. Current methods, such as in-context learning, have limitations in addressing dynamically changing environments and incorporating external knowledge effectively. This paper tackles these issues by developing a novel framework, RAGRAPH.
RAGRAPH uses a retrieval-augmented approach, integrating external graph data to enrich the learning context. It does so via a toy graph vector library, which captures key attributes of the data. During inference, RAGRAPH retrieves similar toy graphs and integrates this data to enhance model learning. Extensive experiments show that RAGRAPH significantly outperforms current state-of-the-art methods across various graph tasks, including node and graph classification, and link prediction, on both static and dynamic datasets. Importantly, it achieves this without needing task-specific fine-tuning, showcasing its high adaptability and robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework that significantly improves the generalization capabilities of Graph Neural Networks (GNNs) by leveraging external knowledge. This addresses a critical limitation of GNNs and opens new avenues for research in various fields.
Visual Insights#

🔼 This figure illustrates how Retrieval-Augmented Generation (RAG) works in three different domains: Natural Language Processing (NLP), Computer Vision (CV), and Graph Neural Networks (GNNs). In each case, a query is made, and RAG is used to retrieve relevant information to help answer the query. In NLP, this involves retrieving relevant text; in CV, it involves retrieving similar images; and in GNNs, it involves retrieving similar subgraphs. The figure shows how RAG can improve the accuracy and reliability of models in each domain by providing additional context.
read the caption
Figure 1: (a) RAG in NLP utilizes retrieval to enhance model responses, based on a query to retrieve related features (e.g., a tail, primarily feeds on mice) and answers (e.g., Cat). (b) In CV, RAG employs similar photo retrieval to enhance model comprehension, assisting in downstream tasks such as inpainting or image question answering. (c) For GNNs, RAG could leverage retrieval of similar historical subgraphs or scenarios to aid in graph-based tasks (e.g., recommendations or fraud detection).
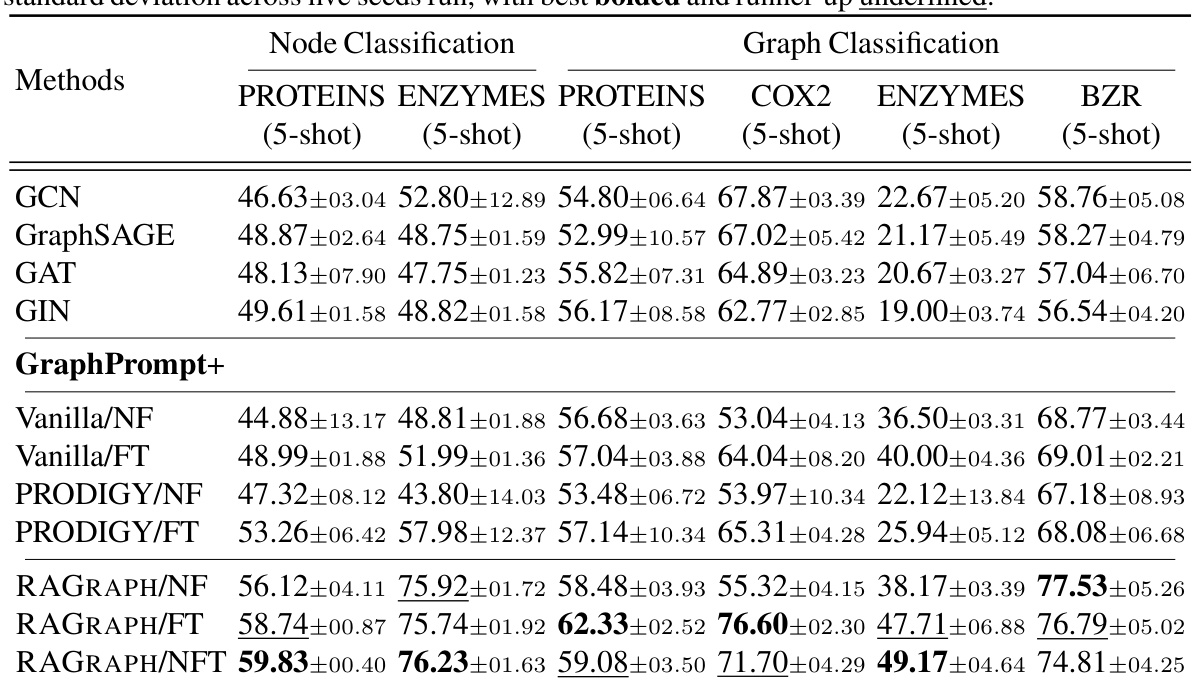
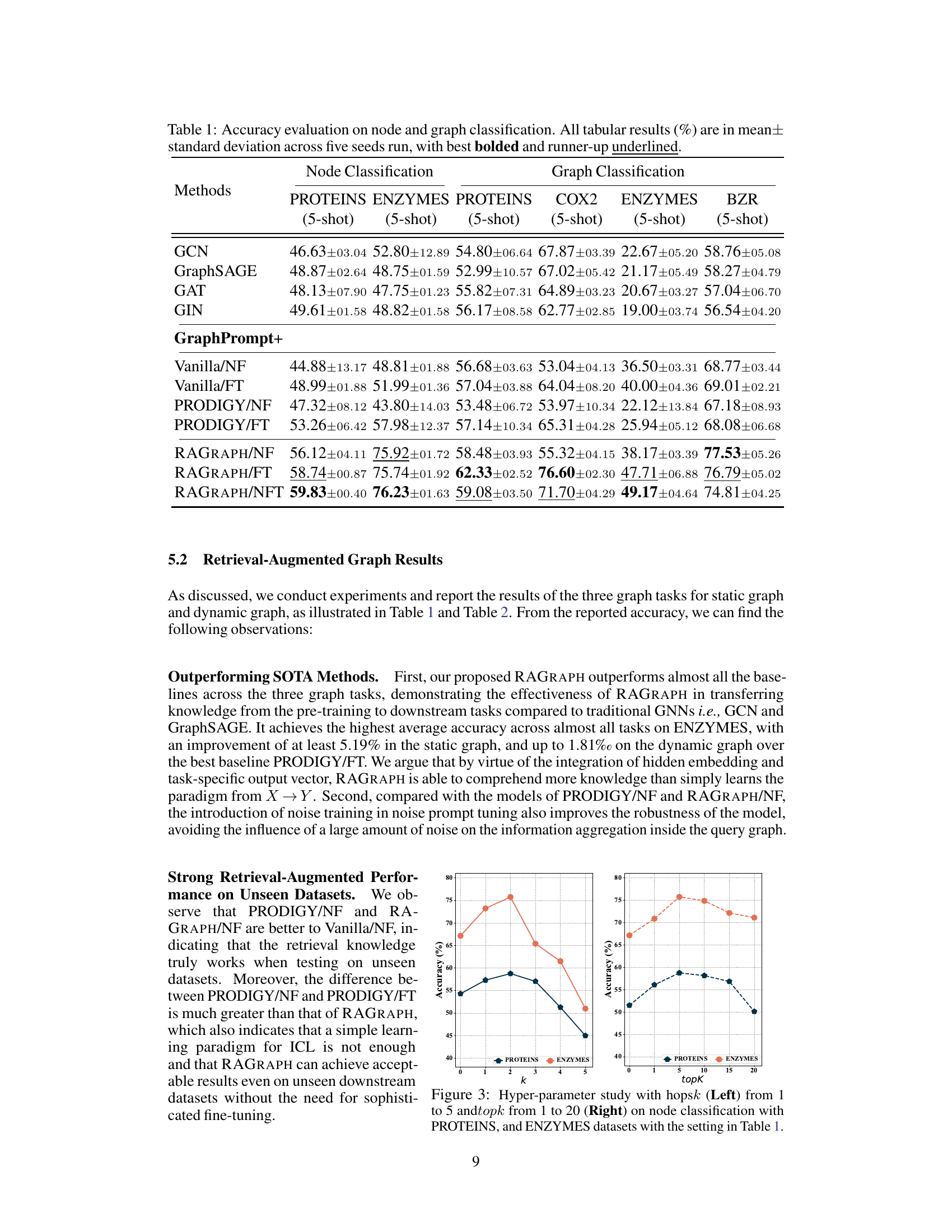
🔼 This table presents the accuracy results of node and graph classification tasks using different methods. The results are presented as mean ± standard deviation across five independent runs, with the best-performing method in each case highlighted in bold and the second-best underlined. The table compares several methods, including Graph Convolutional Networks (GCNs) and variations of the proposed RAGRAPH framework with different training and fine-tuning strategies.
read the caption
Table 1: Accuracy evaluation on node and graph classification. All tabular results (%) are in mean± standard deviation across five seeds run, with best bolded and runner-up underlined.
In-depth insights#
RAGraph Framework#
The RAGraph framework presents a novel approach to augmenting graph neural networks (GNNs) by integrating a retrieval-augmented generation (RAG) mechanism. This framework aims to improve GNN generalization to unseen graph data by incorporating external knowledge via a toy graph vector library. The core of RAGraph involves retrieving similar toy graphs based on key similarities, then using a message-passing mechanism to inject the retrieved features and labels into the learning process, effectively enriching the learning context. This dynamic retrieval process enables the model to adapt to various tasks and datasets without the need for task-specific fine-tuning, highlighting its robustness and adaptability. A key innovation lies in its unified approach to handling node-level, edge-level, and graph-level tasks, further enhancing its versatility. The framework incorporates techniques like inverse importance sampling and noise-based graph prompting tuning to address challenges such as long-tail knowledge bias and retrieval noise, enhancing the overall performance and robustness of RAGraph. Its significant improvement over existing methods in node classification, link prediction, and graph classification tasks across various datasets underscores its effectiveness.
Toy Graph Retrieval#
The concept of “Toy Graph Retrieval” introduces a novel approach to augmenting graph neural networks (GNNs) by leveraging external knowledge. The core idea involves creating a library of small, representative graphs, called “toy graphs,” which capture key features and task-specific information. During inference, the system retrieves the most similar toy graphs based on query graph characteristics, effectively providing a contextualized, enhanced learning environment. This retrieval mechanism is crucial for improving GNN generalizability to unseen data, as it allows the model to access relevant information beyond the limited scope of the training data. The efficiency and effectiveness of this approach depend heavily on several factors: the quality of the toy graph library, the design of the retrieval algorithm ensuring efficient similarity search and relevant toy graph identification, and the method of integrating retrieved information with the query graph’s own data. A key innovation could lie in how the retrieved information enhances existing pre-trained GNNs, possibly via novel prompt mechanisms or message-passing techniques that effectively bridge the gap between the toy graphs and the target graph. The success of toy graph retrieval would significantly depend on addressing challenges such as efficient and accurate similarity search within a potentially large toy graph library and the development of sophisticated integration methods that avoid information overload.
Knowledge Injection#
The concept of “Knowledge Injection” in a graph neural network (GNN) framework is intriguing. It suggests a mechanism to enhance a GNN’s learning process by incorporating external knowledge. This could involve augmenting the graph’s structure with additional nodes and edges representing external information or enriching node features with external data. Effective knowledge injection is crucial for improving the model’s generalizability and performance, particularly when dealing with unseen data or limited training samples. A key challenge lies in how to seamlessly integrate this external knowledge without disrupting the GNN’s inherent structure and learning mechanisms. This likely necessitates carefully designing a knowledge representation scheme compatible with the GNN’s architecture and choosing an appropriate injection method that avoids information overload or conflicts. The success of knowledge injection relies heavily on the quality and relevance of the injected knowledge. A robust framework would need to incorporate mechanisms to filter out noisy or irrelevant information. Furthermore, the effectiveness of this technique may depend on the specific task and dataset. Future work could explore various knowledge injection techniques and evaluate their impact on different GNN architectures and downstream tasks. Ultimately, successful knowledge injection promises to significantly advance the capabilities of GNNs in numerous real-world applications.
Experimental Results#
A thorough analysis of the ‘Experimental Results’ section would involve a critical examination of the methodology used, including the datasets selected, the evaluation metrics employed, and the comparison with relevant baselines. The choice of datasets is crucial, ensuring they represent the target domain accurately and sufficiently, considering aspects like size, diversity and potential biases. The selection and justification of evaluation metrics are equally significant; the metrics must align with the paper’s goals and be appropriate for the specific tasks. A robust comparison to state-of-the-art baselines is essential to establish the novelty and significance of the results. The analysis should also consider the statistical significance of the findings and any potential limitations or sources of error. Furthermore, attention should be paid to the presentation of results: are they clear, concise, and effectively communicated? Are the figures and tables well-designed and informative? A comprehensive evaluation requires exploring these points to assess the overall validity, reliability, and impact of the reported experimental results.
Future Research#
Future research directions for Retrieval-Augmented Graph Learning (RAGraph) could focus on several key areas. Scaling RAGraph to even larger graphs is crucial, as current methods might struggle with the computational cost of processing massive datasets. Investigating more efficient retrieval techniques, perhaps incorporating approximate nearest neighbor search or leveraging graph embeddings, would be beneficial. Extending RAGraph’s capabilities to handle different graph modalities beyond those explored in the paper (e.g., heterogeneous graphs, temporal graphs) would broaden its applicability. Exploring various prompt engineering strategies could also enhance performance. This includes investigating how to generate more effective prompts or how to incorporate external knowledge in a more nuanced way. Finally, thorough evaluation on more diverse and challenging datasets is necessary to fully assess RAGraph’s robustness and generalizability.
More visual insights#
More on figures
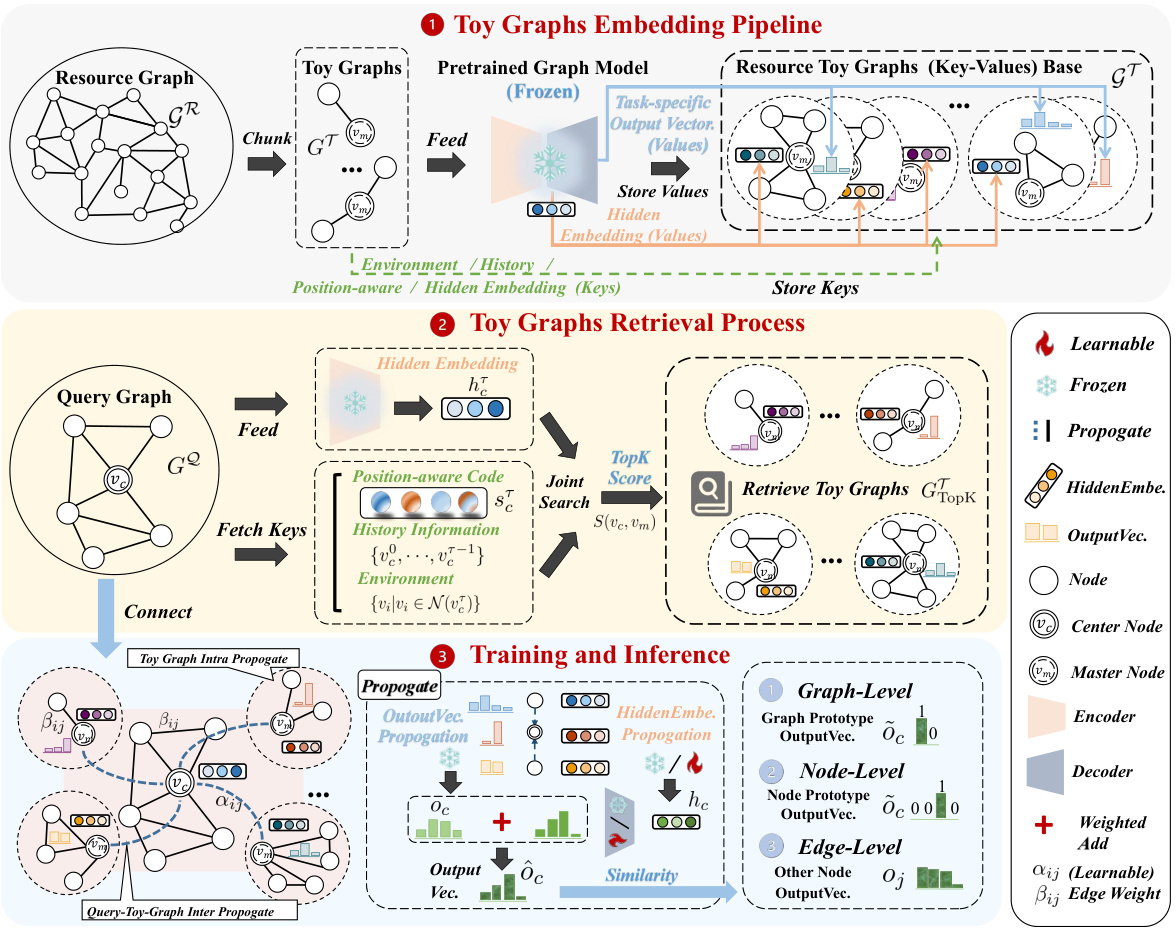
🔼 This figure illustrates the overall framework of RAGRAPH, a retrieval-augmented graph learning framework. It shows the process of constructing a toy graph database, retrieving relevant toy graphs based on a query graph, and then using those retrieved graphs to enhance the learning process of a pre-trained GNN model for improved performance on graph-level, node-level, and edge-level tasks.
read the caption
Figure 2: The overall framework of RAGRAPH. ● Given resource graph GR, we chunk it and augment toy graphs {GT}, and feed them into pre-trained GNNs to generate hidden embeddings via the encoder and task-specific output vectors via decoder, which are stored as values. Keys such as environment, history, position-aware, and hidden embeddings are stored to form the key-value database of toy graphs GT. For a given query graph Gº, the keys are fetched to retrieve the topK toy graphs Gropk from the database. Leveraging Gropk, intra- and inter-propagation are performed to propagate hidden embeddings and task-specific output vectors to pass retrieved knowledge to center node ve. Through a weighted fusion, the aggregated output is used to perform graph-, node- and edge-level tasks.

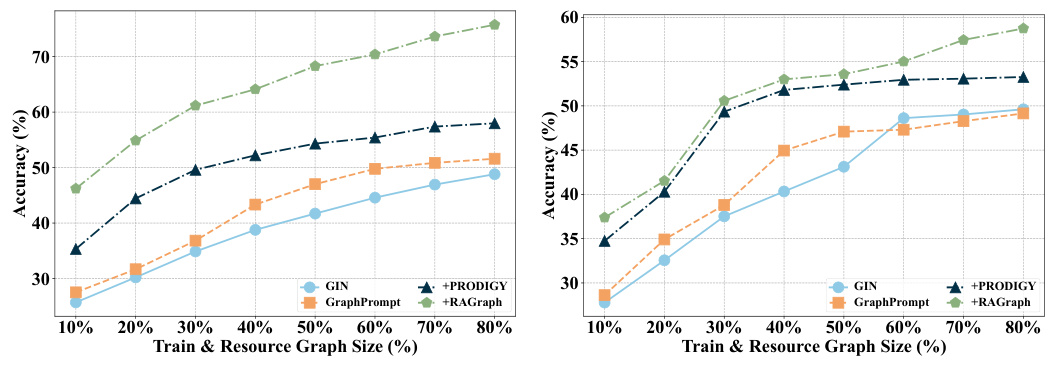
🔼 This figure shows the impact of varying the number of hops (k) in the toy graphs and the number of retrieved toy graphs (topk) on the accuracy of node classification. The left panel shows that accuracy initially increases with k, reaching a peak before decreasing as k becomes too large. The right panel shows that accuracy increases with topk, plateauing after a certain point. Both panels show results for two different datasets, PROTEINS and ENZYMES, highlighting the consistency of the results across different datasets.
read the caption
Figure 3: Hyper-parameter study with hopsk (Left) from 1 to 5 and topk from 1 to 20 (Right) on node classification with PROTEINS, and ENZYMES datasets with the setting in Table 1.
🔼 This figure illustrates the RAGRAPH framework. It shows how the resource graph is chunked into toy graphs, which are then embedded using pre-trained GNNs. The embeddings and task-specific output vectors are stored as key-value pairs. A query graph is then used to retrieve relevant toy graphs based on key similarity. Finally, the retrieved information is integrated using intra and inter-propagation mechanisms to produce the final output for various downstream tasks.
read the caption
Figure 2: The overall framework of RAGRAPH. ● Given resource graph GR, we chunk it and augment toy graphs {GT}, and feed them into pre-trained GNNs to generate hidden embeddings via the encoder and task-specific output vectors via decoder, which are stored as values. Keys such as environment, history, position-aware, and hidden embeddings are stored to form the key-value database of toy graphs GT. For a given query graph Gº, the keys are fetched to retrieve the topK toy graphs Gropk from the database. Leveraging Gropk, intra- and inter-propagation are performed to propagate hidden embeddings and task-specific output vectors to pass retrieved knowledge to center node ve. Through a weighted fusion, the aggregated output is used to perform graph-, node- and edge-level tasks.
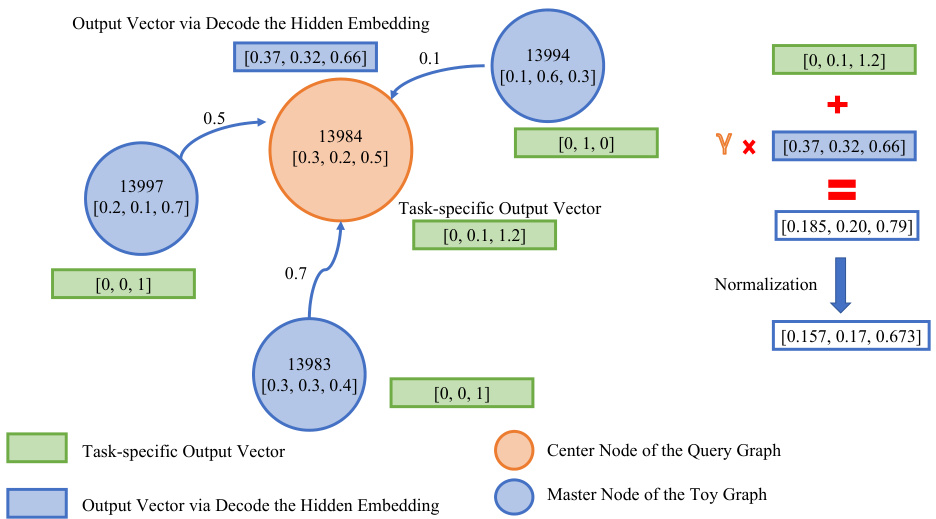
🔼 This figure shows a qualitative analysis of the toy graph retrieval process in RAGRAPH. It illustrates how the task-specific output vectors and hidden embeddings from retrieved toy graphs are propagated and combined to enhance the model’s output. The example demonstrates how RAGRAPH uses retrieved toy graphs with similar patterns to the query node’s to improve the accuracy of node classification by producing a refined output vector.
read the caption
Figure 5: Qualitative analyses of toy graphs retrieving – how 'generation' works.

🔼 This figure compares and contrasts the approaches of PRODIGY and RAGRAPH for graph learning. PRODIGY uses in-context learning (ICL) with static example graphs, learning a mapping from input features (X) to output labels (Y). RAGRAPH, on the other hand, incorporates Retrieval-Augmented Generation (RAG), using dynamic toy graphs to retrieve relevant knowledge (both X and Y) and inject it into the query graph. This illustrates RAGRAPH’s ability to handle dynamic data and integrate external information more effectively.
read the caption
Figure 6: Difference Illustration between PRODIGY and RAGRAPH.
More on tables

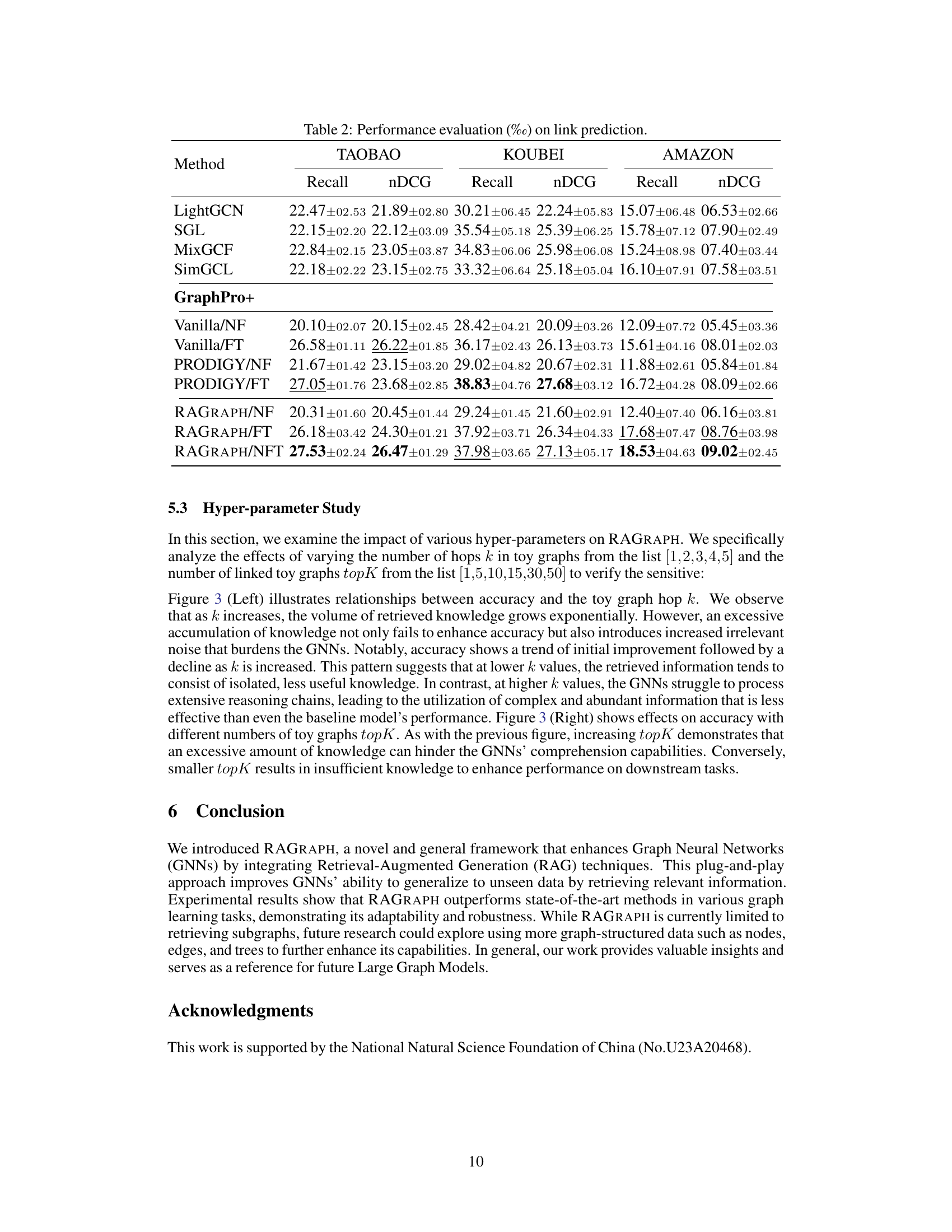
🔼 This table presents the performance of different methods on three link prediction datasets (TAOBAO, KOUBEI, and AMAZON). The performance is evaluated using two metrics: Recall and nDCG (Normalized Discounted Cumulative Gain). For each dataset, the table shows the average Recall and nDCG scores for each method, along with the standard deviation across multiple runs. The methods compared include baselines such as LightGCN, SGL, MixGCF, SimGCL, GraphPro+, and variations of the proposed RAGRAPH model (Vanilla/NF, Vanilla/FT, PRODIGY/NF, PRODIGY/FT, RAGRAPH/NF, RAGRAPH/FT, and RAGRAPH/NFT). The results provide a comparison of the proposed model’s performance against existing state-of-the-art methods on the link prediction task.
read the caption
Table 2: Performance evaluation (%) on link prediction.
🔼 This table presents the accuracy results for node and graph classification tasks across several datasets. Multiple methods are compared, including various versions of the proposed RAGRAPH framework (with and without fine-tuning, and with noise prompt tuning). The results are shown as mean ± standard deviation across five independent runs, highlighting the best performing method in bold and the second-best in underlined.
read the caption
Table 1: Accuracy evaluation on node and graph classification. All tabular results (%) are in mean±standard deviation across five seeds run, with best bolded and runner-up underlined.
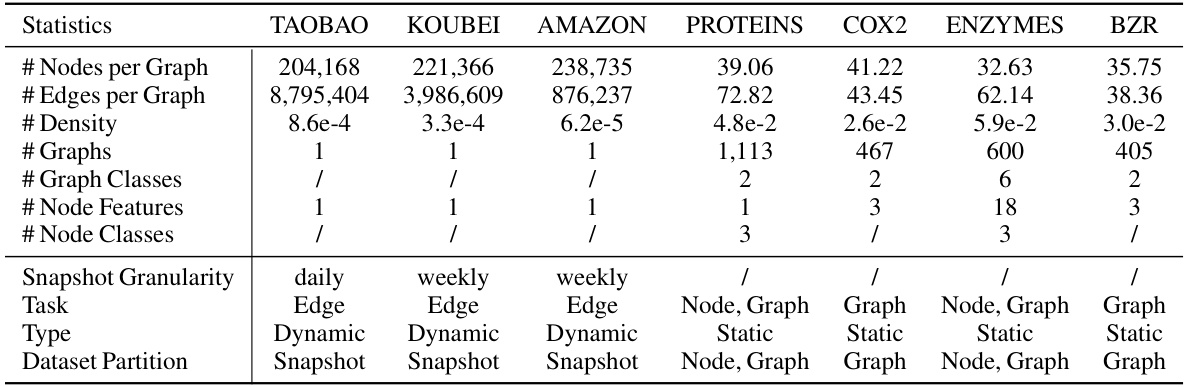
🔼 This table presents a comprehensive overview of the eight datasets used in the experiments, encompassing both static and dynamic graph datasets. For each dataset, it provides key statistics such as the number of nodes and edges per graph, graph density, the number of graphs, the number of classes for graph-level and node-level classification tasks, the number of node features, the number of node classes (if applicable), the snapshot granularity (for dynamic datasets), the type of task (node-level, edge-level, graph-level), the type of dataset (static or dynamic), and how the dataset is partitioned for training and testing.
read the caption
Table 4: Statistics of the experimental datasets and summary of datasets.

🔼 This table presents the accuracy results for node and graph classification tasks using various methods. The results are presented as the mean ± standard deviation across five separate runs with different random seeds. The best performing method for each task is highlighted in bold, while the second best is underlined. This allows for a comparison of the performance of different models across different datasets and tasks.
read the caption
Table 1: Accuracy evaluation on node and graph classification. All tabular results (%) are in mean± standard deviation across five seeds run, with best bolded and runner-up underlined.
Full paper#