↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Vision Transformers (ViTs) have shown remarkable success, but adapting pre-trained ViTs to new tasks is computationally expensive. Existing parameter-efficient fine-tuning (PEFT) methods focus on reducing parameters during training but largely ignore inference efficiency, limiting their practical applications. This paper addresses this issue.
The proposed method, Dynamic Tuning (DyT), tackles this by introducing a token dispatcher that selectively skips less important tokens during inference, thereby decreasing redundant computations. DyT achieves superior performance compared to existing PEFT methods across various tasks including image/video recognition and semantic segmentation, while using substantially fewer FLOPs. This demonstrates the method’s effectiveness in enhancing both parameter and inference efficiency, making it more suitable for deploying large ViT models on resource-constrained platforms.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of existing parameter-efficient fine-tuning (PEFT) methods for Vision Transformers (ViTs): their neglect of inference efficiency. By proposing Dynamic Tuning (DyT), the paper introduces a novel approach that enhances both parameter and inference efficiency, leading to significant performance improvements across diverse vision tasks while using fewer FLOPs. This has significant implications for deploying large ViT models on resource-constrained devices and opens new avenues for research in efficient model adaptation.
Visual Insights#
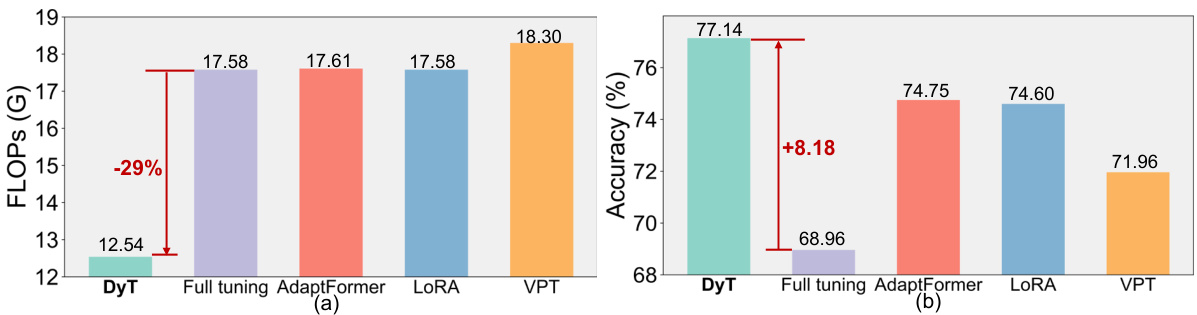
This figure compares the computational cost (FLOPs) and accuracy of different vision transformer (ViT) adaptation methods on the VTAB-1K benchmark. It shows that Dynamic Tuning (DyT) achieves superior accuracy while using significantly fewer FLOPs compared to full fine-tuning and other parameter-efficient fine-tuning (PEFT) methods like AdaptFormer, LoRA, and VPT.

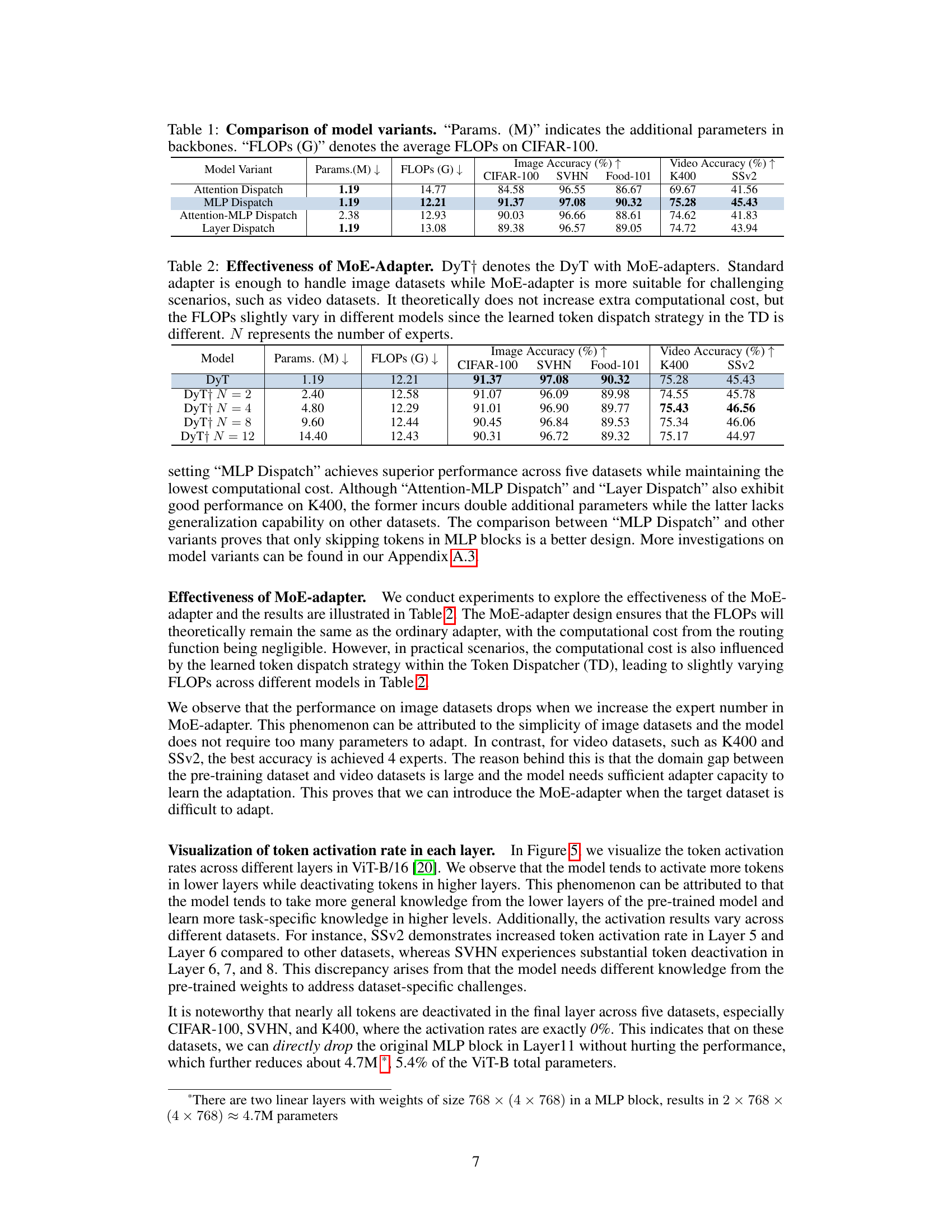
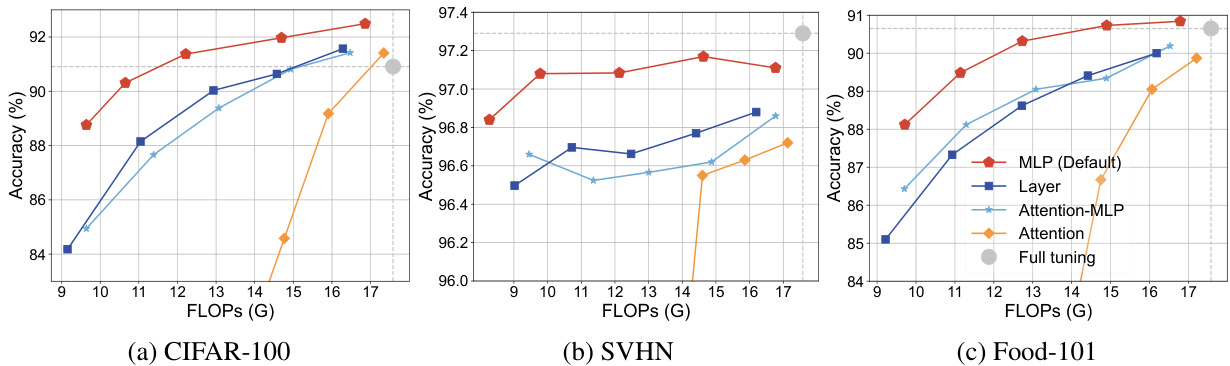
This table compares four different model variants of the Dynamic Tuning (DyT) method. The variants differ in where the token dispatcher is placed within the transformer block (Attention Dispatch, MLP Dispatch, Attention-MLP Dispatch, Layer Dispatch). The table shows the number of additional parameters (in millions), the average FLOPs (in billions) on the CIFAR-100 dataset, and the image and video classification accuracy on CIFAR-100, SVHN, Food-101, K400, and SSv2 datasets for each variant. This allows for a comparison of the efficiency and effectiveness tradeoffs of the different DyT designs.
In-depth insights#
ViT Adaptation#
Vision Transformer (ViT) adaptation methods aim to leverage the power of pre-trained ViTs for downstream tasks. Parameter-efficient fine-tuning (PEFT) techniques are crucial here, as they allow adaptation with minimal additional parameters, making them suitable for resource-constrained environments. However, inference efficiency is often overlooked. The paper emphasizes this duality, proposing Dynamic Tuning (DyT) to enhance both parameter and inference efficiency. DyT’s key innovation is a token dispatcher that dynamically skips less informative tokens, reducing computation. The design incorporates multiple variants and an enhanced MoE-based adapter, demonstrating strong performance across various visual tasks like image and video recognition. The results showcase significant improvements in inference speed, particularly beneficial when dealing with computationally intensive ViT models, highlighting the critical balance DyT achieves between adaptation effectiveness and resource efficiency.
Dynamic Tuning#
The concept of ‘Dynamic Tuning’ presents a novel approach to enhance the efficiency of Vision Transformers (ViTs). It addresses both parameter and inference efficiency, unlike many existing methods focusing solely on parameter reduction. The core idea involves a ’token dispatcher’ that selectively activates only the most informative tokens for processing within each transformer block, dynamically skipping less relevant computations during inference. This is particularly beneficial for computationally intensive models. The method further explores multiple design variants to optimize performance, including the placement of the lightweight adapter modules and the introduction of an enhanced adapter inspired by Mixture-of-Experts (MoE) for improved adaptation. Experimental results show superior performance compared to existing methods with significantly reduced FLOPs. The overall approach showcases a thoughtful integration of parameter and inference optimization for efficient ViT adaptation, highlighting its potential for broader real-world applications.
Inference Efficiency#
The concept of ‘Inference Efficiency’ in the context of Vision Transformers (ViTs) is crucial for real-world applications. Parameter-efficient fine-tuning (PEFT) methods have primarily focused on reducing the number of trainable parameters during adaptation, often neglecting the computational cost of inference. This limitation hinders the broader adoption of computationally expensive pre-trained ViT models, especially on resource-constrained devices. Therefore, enhancing inference efficiency is vital to make ViTs more practical. Techniques like token pruning and dynamic neural networks offer avenues for improving efficiency by selectively processing informative tokens and skipping redundant computations. A thoughtful approach that combines parameter and inference efficiency, such as Dynamic Tuning (DyT), is needed to fully realize the potential of ViTs across diverse visual tasks and applications. Dynamically selecting which tokens to process in each transformer block allows for significant FLOPs reduction without sacrificing accuracy, achieving superior performance compared to existing PEFT methods while evoking only a fraction of their computational resources.
MoE-Adapter#
The MoE-Adapter section presents a novel approach to enhance the capabilities of the adapter modules within the Dynamic Tuning framework. Standard adapters, while efficient, may struggle with complex downstream tasks, particularly when dealing with a large number of tokens, as in semantic segmentation. The MoE-adapter addresses this limitation by employing a mixture-of-experts mechanism. This allows the model to leverage multiple expert adapters, each specialized in a particular aspect of the task, improving overall model capacity and adaptability. A key innovation is the use of a routing layer which efficiently assigns tokens to the appropriate expert, avoiding a significant increase in computational cost. By dynamically routing tokens to the most suitable expert, the MoE-adapter enhances the expressiveness of the adapter, improving overall performance while maintaining efficiency. The introduction of the MoE-adapter demonstrates a thoughtful extension to the core Dynamic Tuning approach, offering a clear path for improved performance on more demanding tasks.
Future Works#
The “Future Works” section of a research paper on dynamic tuning for vision transformers would naturally explore extending the approach’s capabilities and addressing limitations. Scaling to even larger vision transformer models would be a critical next step, investigating how the token dispatcher and adapter mechanisms scale efficiently. Exploring applications beyond image classification is crucial, encompassing tasks like object detection, video understanding, and other modalities involving sequential data. Addressing the inherent trade-offs between parameter and inference efficiency warrants further study; optimizing the dynamic mechanism for minimal resource consumption across various hardware is key. Improving the robustness of the token selection process is vital, perhaps by incorporating more sophisticated attention mechanisms or incorporating uncertainty estimates. A comprehensive experimental evaluation on diverse datasets under various conditions would solidify findings. Finally, researching the compatibility and integration with other efficient fine-tuning techniques would create synergistic improvements and enhance the practical impact of this work.
More visual insights#
More on figures
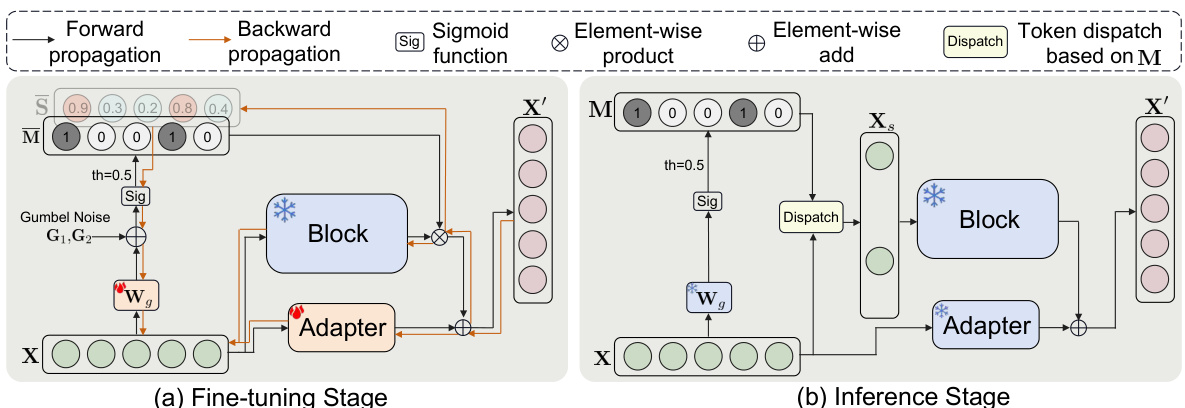
This figure illustrates the Dynamic Tuning (DyT) process during both fine-tuning and inference stages. The fine-tuning stage (a) uses Gumbel Noise to allow for end-to-end training of the token dispatcher (TD), which learns to create a mask (M) determining which tokens are activated and passed through the main transformer block. Deactivated tokens bypass the main block but are still processed by a lightweight adapter. During inference (b), the trained TD uses the mask (M) to directly select only the activated tokens for processing, skipping the main block for deactivated tokens and thereby reducing computation.

This figure shows four different model variants of Dynamic Tuning (DyT). Each variant applies the DyT token dispatch mechanism at a different level within the Transformer block. * Attn Dispatch: The token selection happens before the multi-head self-attention (Attn) block. * MLP Dispatch: Tokens are selected before the multi-layer perceptron (MLP) block. * Attn-MLP Dispatch: Token selection is performed before both Attn and MLP blocks. * Layer Dispatch: A single token dispatcher controls token activation/deactivation for the entire layer (Attn and MLP). The figure visually demonstrates how the token dispatcher (DyT) integrates into the Attn and MLP blocks in each variant.
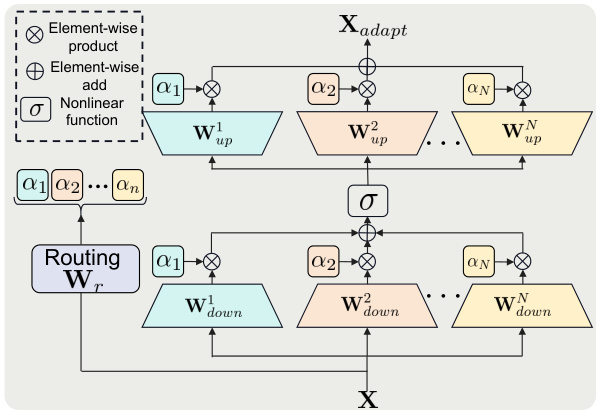
The MoE-adapter consists of a routing layer (Wr) that generates weights (α1, α2,…αN) for N adapter experts. Each expert has a down-project layer (Wdown) and an up-project layer (Wup). The input (X) is processed by each expert independently and the results are combined with corresponding weights. The output (Xadapt) is the weighted sum of the expert outputs.
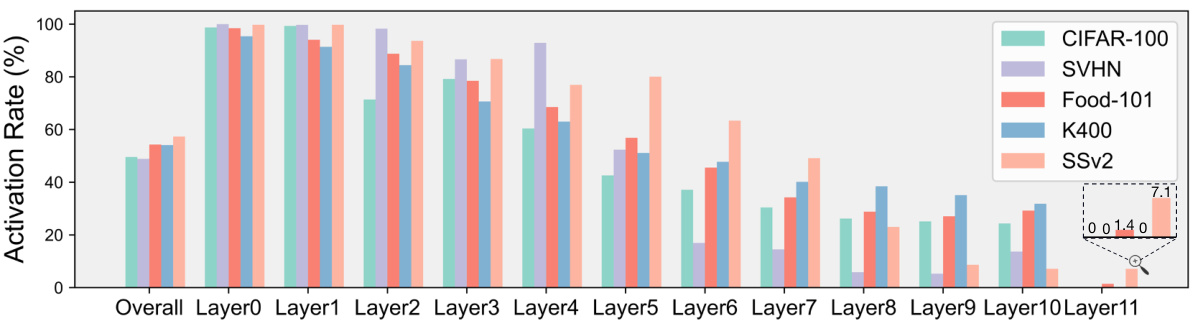
This figure visualizes the token activation rates across different layers of a ViT-B/16 model for various datasets. It shows how the model dynamically chooses to activate a subset of tokens in each layer during inference, with the activation rate varying across layers and datasets. The overall activation rate is around 50% when r=0.5, but the activation rate in the last layer (Layer11) is 0% for CIFAR-100, SVHN, and K400 datasets.

This figure visualizes how the token dispatcher in the Dynamic Tuning method identifies and activates informative tokens during fine-tuning. It shows two examples from the K400 dataset, highlighting which tokens (represented by blue patches) are deemed important and processed by the network. The visualization demonstrates the method’s ability to selectively process only essential tokens, improving efficiency by skipping less important ones.
This figure compares the FLOPs (floating-point operations) and accuracy of different ViT adaptation methods on the VTAB-1K benchmark. It shows that the proposed Dynamic Tuning (DyT) method achieves superior accuracy while using significantly fewer FLOPs compared to full fine-tuning and other parameter-efficient fine-tuning (PEFT) methods such as AdaptFormer, LoRA, and VPT. The results highlight DyT’s improvement in both parameter and inference efficiency.

This figure visualizes the tokens activated by the token dispatcher in different layers of the ViT-B/16 model for several video samples from the K400 dataset. The blue patches highlight the activated tokens. The results show that the model primarily activates tokens representing the main objects or actions within the scene, demonstrating the effectiveness of the token dispatcher in focusing on the most relevant information.

This figure visualizes which image tokens are activated by the model’s token dispatcher during the fine-tuning phase for various samples from the K400 dataset. Blue patches highlight the tokens selected for processing by the model. This visualization helps demonstrate that the token dispatcher effectively identifies and selects informative tokens, improving efficiency by skipping less important ones.
More on tables

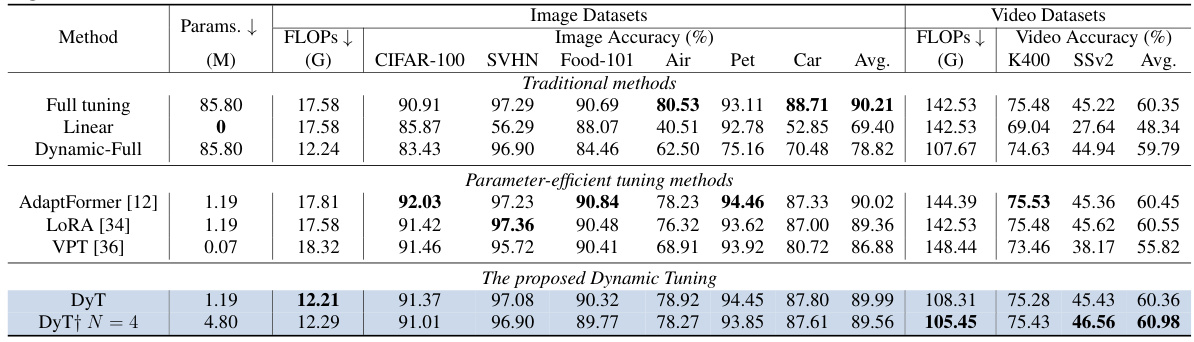
This table compares the performance of the Dynamic Tuning (DyT) model with and without the Mixture-of-Experts (MoE) adapter. It shows that while the standard DyT adapter is sufficient for image datasets, the MoE adapter provides a performance boost for more complex tasks such as video recognition. The computational cost remains largely unchanged, even though the FLOPs vary slightly between different configurations, due to variations in the token dispatch strategy during training. The number of experts (N) is a parameter adjusted in the MoE adapter configuration.
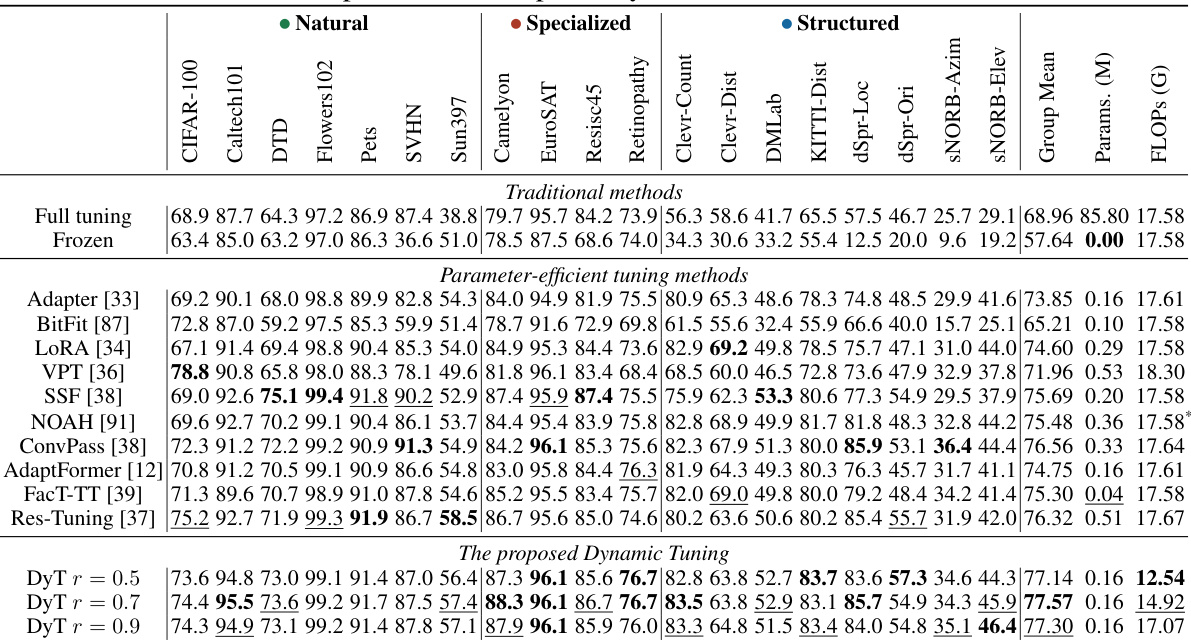
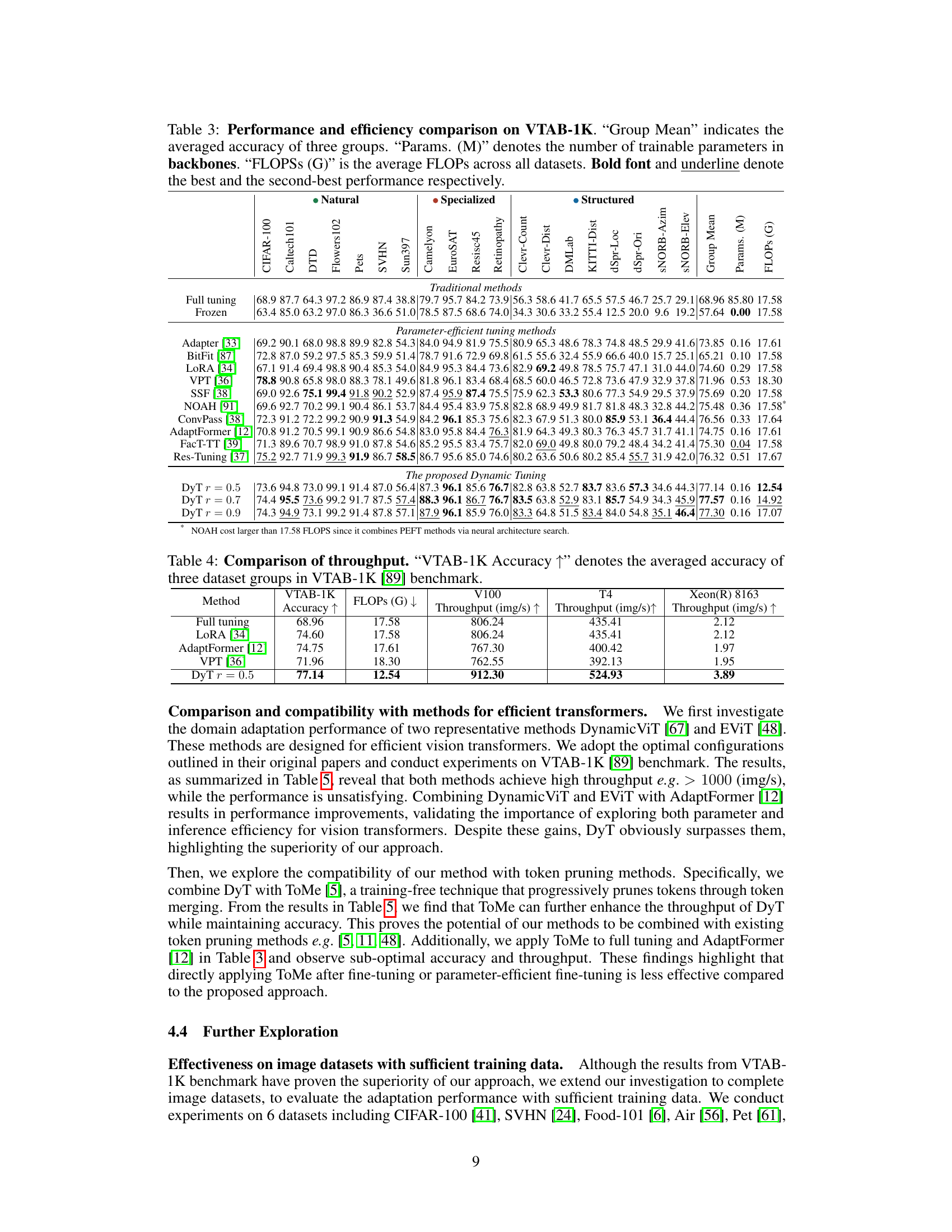
This table compares the performance and efficiency of Dynamic Tuning (DyT) against other parameter-efficient fine-tuning (PEFT) methods on the VTAB-1K benchmark. It shows the average accuracy across various visual tasks, the number of trainable parameters, and the average FLOPs (floating point operations) used. The best and second-best performing methods for each task are highlighted.

This table compares the inference throughput of different methods (full tuning, LoRA, AdaptFormer, VPT, and DyT) across three different hardware platforms: V100 GPU, T4 GPU, and Xeon(R) 8163 CPU. The throughput is measured in images per second (img/s). The table also shows the VTAB-1K accuracy and FLOPs (floating-point operations) for each method. It demonstrates the speed improvements achieved by DyT while maintaining high accuracy, showcasing its efficiency on various hardware.
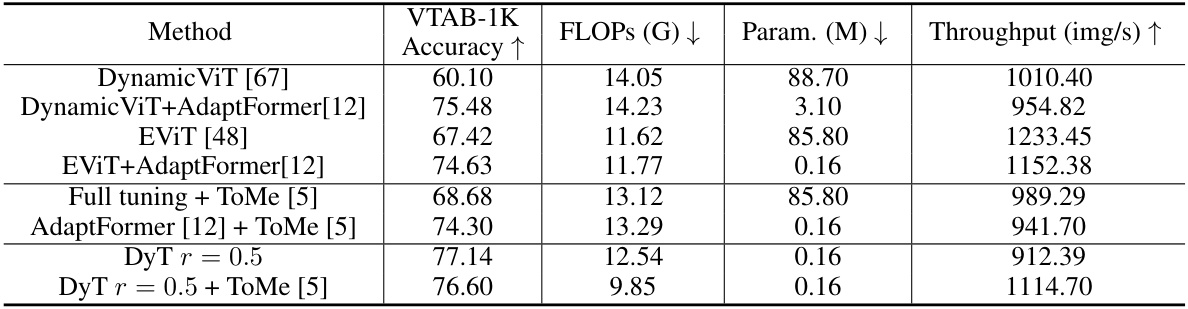
This table compares the performance and efficiency of Dynamic Tuning (DyT) against other efficient transformer methods, including DynamicViT, EViT, and AdaptFormer, with and without ToMe. It shows that DyT achieves superior performance with significantly fewer FLOPs (floating point operations) and comparable or even higher throughput (images per second). The results demonstrate DyT’s effectiveness in improving both parameter and inference efficiency for vision transformer adaptation.
This table compares four different model variants of the proposed Dynamic Tuning (DyT) method on image and video datasets. The variants differ in where the token dispatcher is applied (Attention, MLP, Attention-MLP, or Layer) and how tokens are skipped during processing. The table shows the number of additional parameters (in millions), the average FLOPs (in billions), and the accuracy achieved on various benchmark datasets (CIFAR-100, SVHN, Food-101, K400, and SSv2). The results show the impact of the different token dispatch strategies on model performance and efficiency.

This table compares four different model variants of the Dynamic Tuning (DyT) method. Each variant differs in where the token dispatch mechanism is applied within the Transformer blocks (Attention, MLP, Attention-MLP, and Layer). The table shows the number of additional parameters (in millions), the average FLOPs (in billions) on the CIFAR-100 dataset, and the image and video classification accuracy for several datasets (CIFAR-100, SVHN, Food-101, K400, SSv2). This allows for a comparison of the performance and efficiency tradeoffs of each model variant.

This table compares four different model variants of the proposed Dynamic Tuning (DyT) method for Vision Transformer (ViT) adaptation. The variants differ in where the token dispatcher is applied within the ViT’s architecture: before the attention block, before the MLP block, before both, or before the entire transformer layer. The table shows the number of additional parameters (in millions), the average FLOPs (in billions) on the CIFAR-100 dataset, and the image and video accuracy for five different datasets (CIFAR-100, SVHN, Food-101, K400, SSv2). This allows for a comparison of the efficiency and effectiveness of each variant.

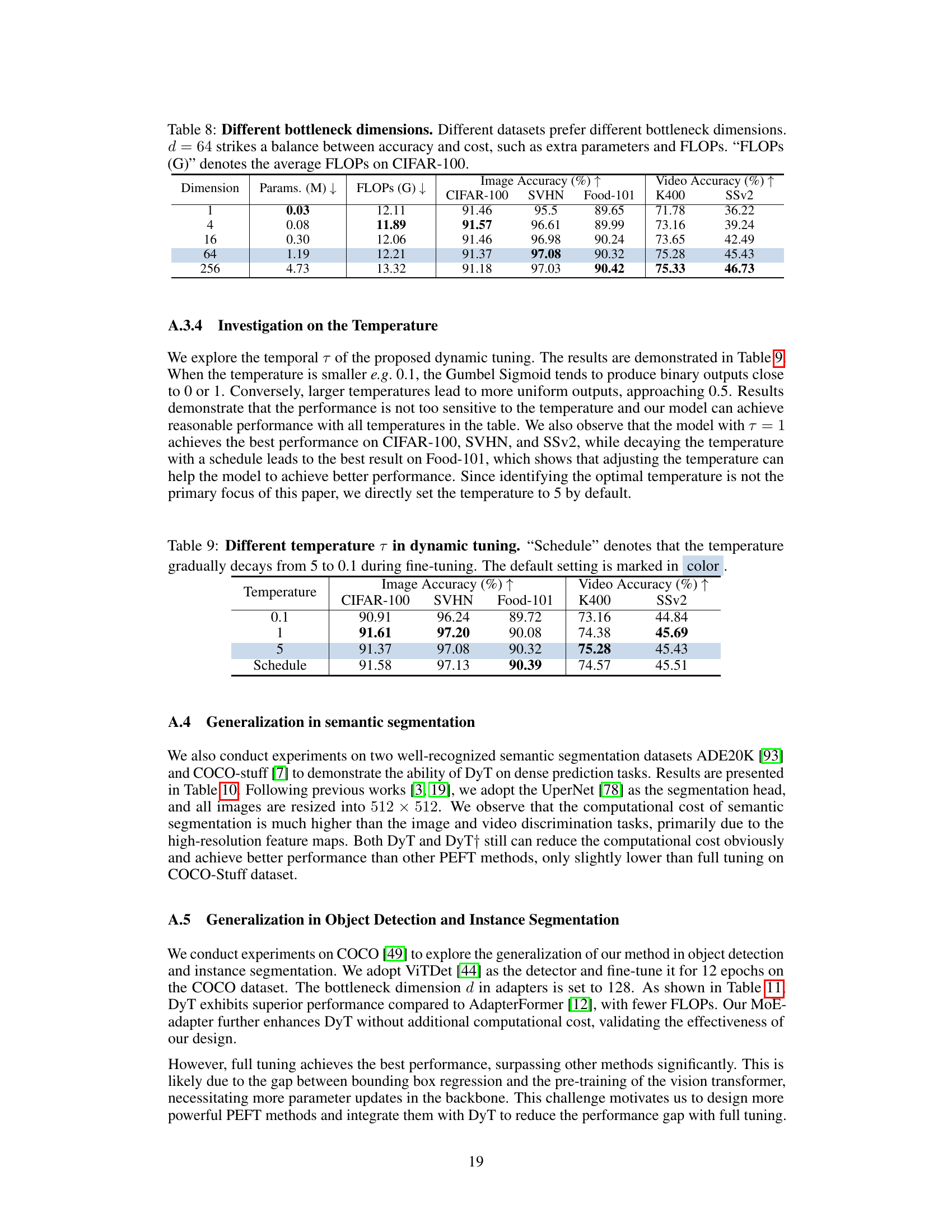
This table presents the results of experiments conducted to determine the optimal temperature parameter (τ) in the Gumbel-Sigmoid function used within the Dynamic Tuning method. It compares the model’s performance across various image and video datasets using different temperature schedules. The ‘Schedule’ row indicates that the temperature was reduced gradually from 5 to 0.1 throughout the training process. The best performance across all datasets is highlighted in color.

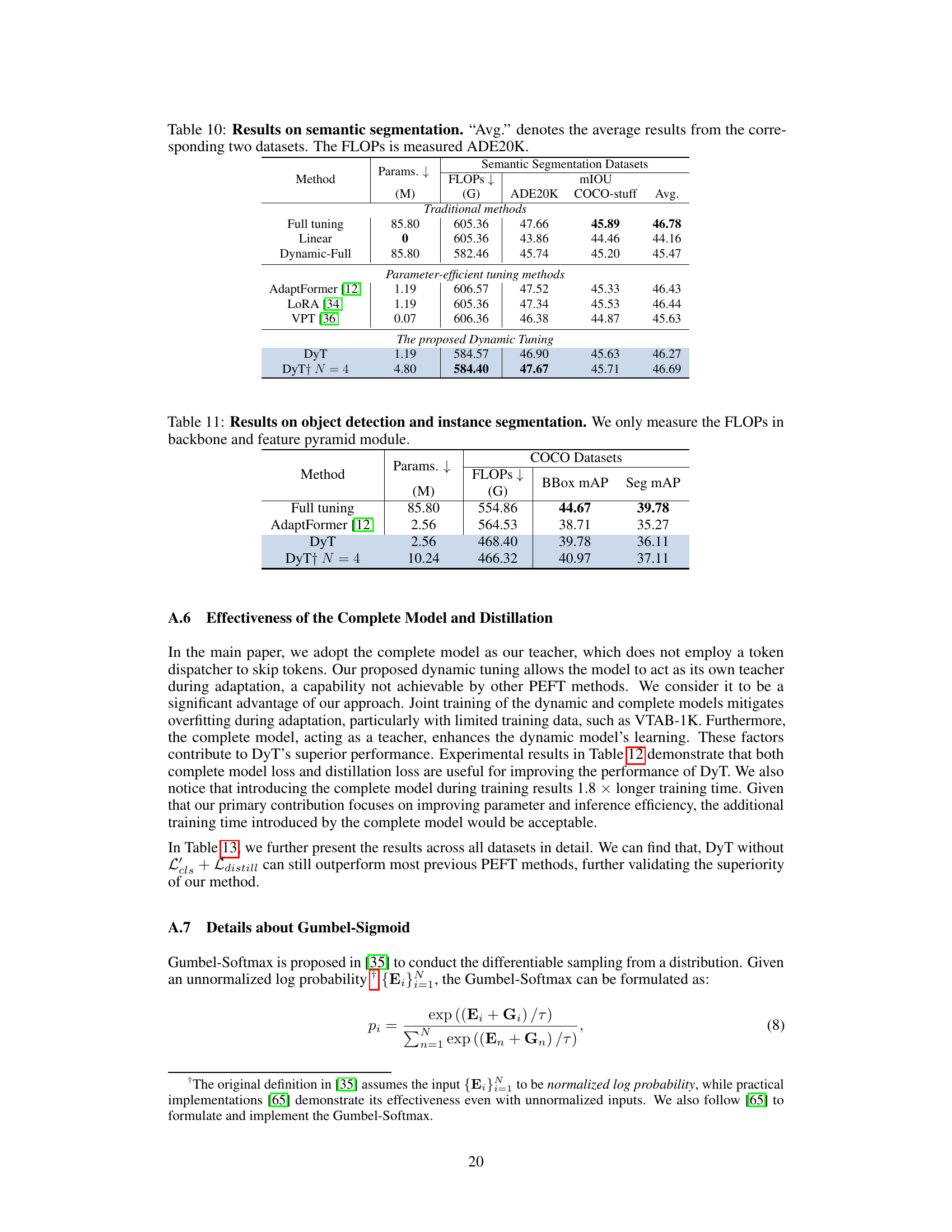
This table compares the performance of different methods on two semantic segmentation datasets: ADE20K and COCO-stuff. The metrics evaluated are mean Intersection over Union (mIOU) for ADE20K and COCO-stuff, and the average mIOU across both. The table also shows the number of trainable parameters (Params.) and Giga FLOPs (GFLOPs) for each method. The methods compared include Full tuning, Linear, Dynamic-Full, AdaptFormer, LoRA, VPT, and the proposed Dynamic Tuning (DyT) with and without the MoE-adapter. The results demonstrate that Dynamic Tuning achieves competitive performance while significantly reducing the number of parameters and FLOPs.

This table compares the performance of different methods for object detection and instance segmentation on the COCO dataset. It shows the number of trainable parameters, the GFLOPs (giga floating point operations), the mean Average Precision (mAP) for bounding boxes, and the mAP for segmentation masks. The methods compared include Full Tuning (as a baseline), AdaptFormer, DyT (Dynamic Tuning), and DyT with 4 MoE (Mixture-of-Experts) adapters. The table highlights that DyT and DyT+MoE achieve comparable or better performance to AdaptFormer while using significantly fewer FLOPs.

This table shows the ablation study of the loss functions used in Dynamic Tuning (DyT). It demonstrates that the complete model loss (L’cls) and the distillation loss (Ldistill) contribute positively to the model’s performance. Removing either one or both causes a decrease in the VTAB-1K accuracy. The training time also slightly increases when using the complete model, but the improvement in accuracy may justify the increased training cost.

This table compares the performance and efficiency of Dynamic Tuning (DyT) against other methods on the VTAB-1K benchmark. It shows the average accuracy across different subsets of VTAB-1K, the number of trainable parameters, and the FLOPs (floating point operations) for each method. The best and second-best performing methods are highlighted for each task. The table helps illustrate how DyT achieves superior performance and efficiency.
This table compares four different model variants of the Dynamic Tuning (DyT) method proposed in the paper. Each variant uses a different strategy for dynamically selecting tokens during processing within a transformer block (Attn, MLP, or a complete layer). The table shows the number of additional parameters (in millions), the average FLOPs (in billions) on the CIFAR-100 dataset, and the image and video accuracies on various datasets for each model variant. This allows for a comparison of the computational efficiency and performance trade-offs of different DyT configurations.
This table details the hyperparameters used for training video models on the Kinetics-400 and Something-Something V2 datasets. It specifies the optimizer, learning rate, weight decay, batch size, number of training epochs, image resizing strategy, crop size, learning rate schedule, frame sampling rate, use of mirroring and RandAugment, and the number of testing views used during evaluation.

This table compares the performance of different methods on two semantic segmentation datasets: ADE20K and COCO-stuff. The metrics shown include Mean Intersection over Union (mIOU) for ADE20K and COCO-stuff, and the average mIOU across both. The number of trainable parameters (Params. (M)) and GFLOPs are also given for each method. The methods compared include Full Tuning, Linear, Dynamic-Full, AdaptFormer, LoRA, VPT, and DyT (with and without the MoE-adapter).
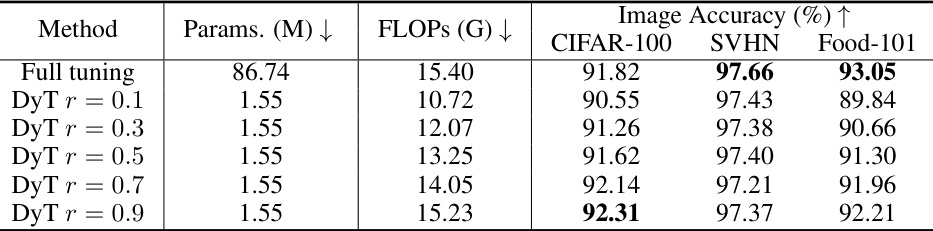
This table presents the results of scaling up the model size to ViT-L while using dynamic tuning. It compares the performance and efficiency of different activation rates (r) against the full tuning method across CIFAR-100, SVHN, and Food-101 datasets. The table shows the number of trainable parameters, FLOPs (floating-point operations), and image accuracy for each configuration. The bottleneck dimension (d) of the adapter is fixed at 64.
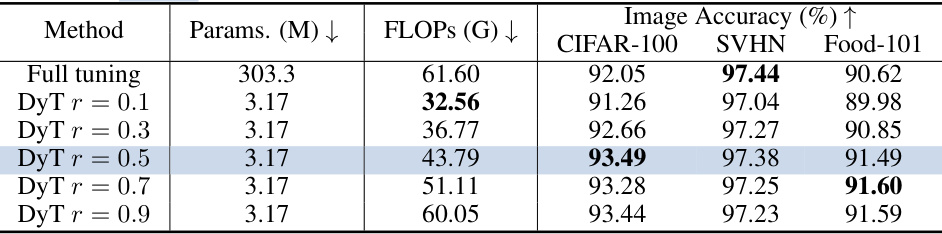
This table shows the impact of scaling up the model size to ViT-L while using the Dynamic Tuning method. It compares the performance and computational cost (FLOPs) of different activation rates (r) within the Dynamic Tuning approach against the performance of the fully tuned ViT-L model on three image classification datasets: CIFAR-100, SVHN, and Food-101. The table highlights that even with a significantly smaller number of trainable parameters, Dynamic Tuning achieves comparable or even better accuracy than full tuning, especially at lower FLOPs.

This table compares four different model variants of the proposed Dynamic Tuning (DyT) method. The variants differ in where the token dispatcher is applied within the transformer block (Attention, MLP, Attn-MLP, or Layer). The table shows the number of additional parameters (in millions), the average FLOPs (in billions) on the CIFAR-100 dataset, and the image and video classification accuracy for several benchmark datasets (CIFAR-100, SVHN, Food-101, K400, and SSv2). This allows for a comparison of performance and efficiency trade-offs among the different DyT variants.
Full paper#