TL;DR#
Reconstructing realistic 3D human models from images is crucial for various applications but faces challenges due to occlusions (people or objects blocking parts of the body). Current methods using parametric models struggle with geometric detail and handling misaligned models, while implicit function methods can struggle with inpainting occluded regions. This leads to inaccurate and incomplete 3D models.
The paper introduces MHCDIFF, which utilizes point cloud diffusion conditioned on probabilistic distributions of multiple plausible human body poses. This multi-hypothesis approach makes the model robust to occlusions and misalignments. By incorporating local features from several pose hypotheses and global features from the input image, MHCDIFF generates high-quality, pixel-aligned 3D human reconstructions. Experiments show that MHCDIFF outperforms existing state-of-the-art methods on datasets with both synthetic and real occlusions.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to 3D human reconstruction that is robust to occlusions, a persistent challenge in computer vision. Its use of point cloud diffusion and multi-hypothesis conditioning offers significant improvements over existing methods. This work is relevant to current research trends in both 3D reconstruction and diffusion models, and it opens new avenues for research in handling occlusions and uncertainty in image-based 3D modeling.
Visual Insights#

🔼 This figure shows the overall pipeline of the proposed method, MHCDIFF. It starts with a single input image depicting two people interacting, resulting in occlusions. The image is then segmented to isolate the individual people. Finally, MHCDIFF processes these segmented images to generate a 3D point cloud representation of each person. The generated point clouds accurately reflect the 3D shapes of the individuals, even in areas where occlusions were present in the input image.
read the caption
Figure 1: Image to 3D shape. From the segmented images, containing occlusion due to interaction, MHCDIFF reconstructs 3D human shapes as point clouds.

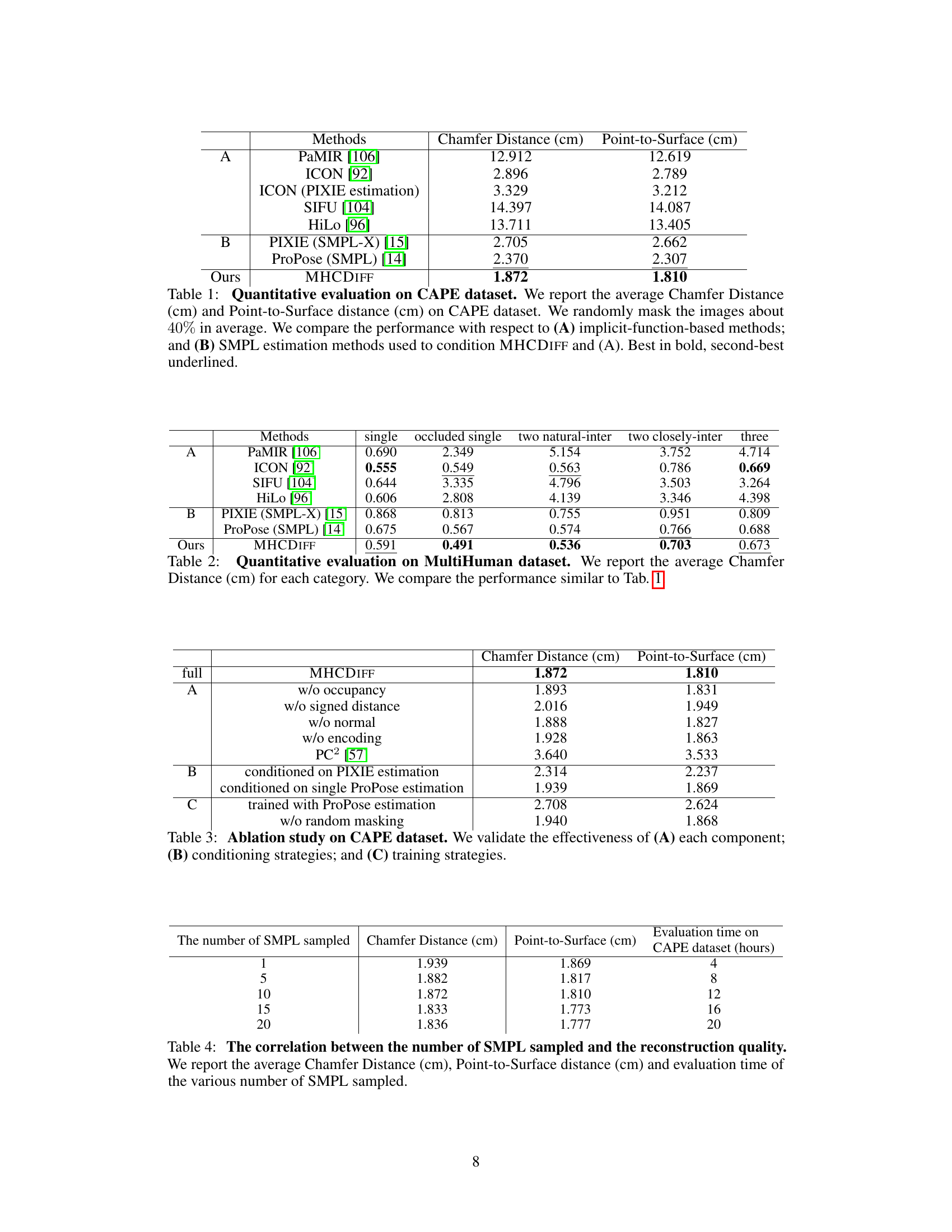
🔼 This table presents a quantitative comparison of the proposed MHCDIFF method against several state-of-the-art methods for 3D human reconstruction on the CAPE dataset. The evaluation metrics are Chamfer Distance and Point-to-Surface Distance, both measured in centimeters. The comparison is broken down into two parts: (A) a comparison with implicit function-based methods and (B) a comparison with different SMPL estimation methods used to condition the MHCDIFF approach. The results highlight the superior performance of MHCDIFF, particularly when considering its robustness to occlusions (40% average masking).
read the caption
Table 1: Quantitative evaluation on CAPE dataset. We report the average Chamfer Distance (cm) and Point-to-Surface distance (cm) on CAPE dataset. We randomly mask the images about 40% in average. We compare the performance with respect to (A) implicit-function-based methods; and (B) SMPL estimation methods used to condition MHCDIFF and (A). Best in bold, second-best underlined.
In-depth insights#
Occlusion Robustness#
Occlusion robustness is a critical aspect of 3D human reconstruction, especially in real-world scenarios. The presence of occlusions, whether from self-occlusion, interactions with objects, or other people, significantly impacts the accuracy of reconstruction methods. Parametric models, while providing a strong human body prior, often struggle with severe occlusions, often failing to generate accurate detailed shapes in occluded regions. Implicit function-based methods, while capable of handling some occlusions, can still be affected by misaligned parametric models and lack the ability to capture global consistency in the point cloud. Diffusion models, offer a promising solution by learning to inpaint occluded regions using global features and the denoising process. The key here is conditioning the diffusion process on multiple plausible hypotheses of the underlying body shape (e.g., SMPL models), which accounts for the uncertainty introduced by the occlusions. Multi-hypothesis conditioning, as a result, proves highly effective in increasing the robustness of the reconstruction process, as it allows the model to resolve ambiguities and generate more accurate complete shapes. The effectiveness of this strategy is particularly evident in the performance gains observed when compared to approaches relying on single SMPL hypotheses.
Diffusion Model#
Diffusion models, a class of generative models, are revolutionizing various fields by learning to gradually denoise random noise into the desired data distribution. This process, often described as a forward diffusion process and a reverse diffusion process, involves carefully designed noise schedules. The core idea lies in training a neural network to reverse the noising process, effectively learning the data distribution. This approach enables the generation of high-quality samples without relying on explicit density estimations or adversarial training. In the context of 3D human reconstruction, diffusion models offer a powerful way to handle occlusions and generate detailed, pixel-aligned shapes by leveraging probabilistic distributions and multi-hypotheses. By conditioning the diffusion process on features extracted from multiple plausible SMPL-X meshes, the model significantly improves its robustness to errors in the estimated pose and shape parameters. The ability to inpaint occluded regions and correct misaligned meshes showcases the versatility of diffusion models for complex 3D shape generation.
Multi-Hypothesis#
The concept of ‘Multi-Hypothesis’ in the context of 3D human reconstruction from occluded images tackles the inherent ambiguity and uncertainty introduced by occlusions. Instead of relying on a single, potentially inaccurate estimate of the human pose and shape (common in traditional parametric models), a multi-hypothesis approach generates multiple plausible hypotheses. Each hypothesis represents a different possible interpretation of the incomplete visual data. This strategy is crucial because occlusions can lead to significant ambiguities in the reconstruction process. By considering various hypotheses, the approach inherently handles uncertainty and misalignments that might arise from occluded regions, ultimately leading to a more robust and accurate 3D model. The strength lies in the aggregation or fusion of these hypotheses to produce a final output that leverages the strengths of each individual estimate while mitigating the weaknesses. It likely involves a mechanism to weigh or combine the hypotheses, potentially using confidence scores based on the quality of the individual estimates or other relevant factors. This approach makes the 3D reconstruction less sensitive to noisy or incomplete data, producing a result that reflects the combined knowledge from multiple potential solutions instead of a single, possibly flawed prediction.
Pixel-Aligned Detail#
The concept of “Pixel-Aligned Detail” in 3D human reconstruction signifies the accurate correspondence between points in a generated 3D model and their projected counterparts in a 2D image. This is crucial for creating realistic-looking models, particularly when dealing with complex details such as clothing folds or hair. Achieving pixel-aligned detail is challenging due to the inherent ambiguity in projecting 3D shapes onto a 2D plane. Methods that successfully capture pixel-aligned detail often rely on sophisticated techniques, such as incorporating detailed image features into the reconstruction process. This could involve utilizing techniques like implicit functions or diffusion models conditioned on high-resolution image features. Successful approaches generally combine strong 2D feature extraction with robust 3D modeling techniques to ensure the model accurately reflects the finer details present in the image, resulting in visually appealing and accurate 3D representations of humans.
Future Directions#
Future research could explore improving the efficiency of the diffusion model, perhaps through architectural innovations or more efficient sampling techniques. Addressing the computational cost, particularly for high-resolution models, is crucial for broader applicability. Expanding the dataset with more diverse clothing styles, body types, and interaction scenarios would enhance the model’s robustness and generalizability. Investigating alternative conditioning strategies beyond SMPL and image features could improve accuracy and handling of complex occlusions. This might involve exploring other implicit representations or incorporating additional modalities like depth or point clouds. A key area for advancement is handling extreme occlusions, where significant portions of the body are missing. This could involve developing more sophisticated inpainting techniques or leveraging advanced generative models to hallucinate missing information. Finally, evaluating the model’s performance on diverse real-world datasets and exploring applications beyond human reconstruction, such as virtual character creation or animation, are important future avenues.
More visual insights#
More on figures
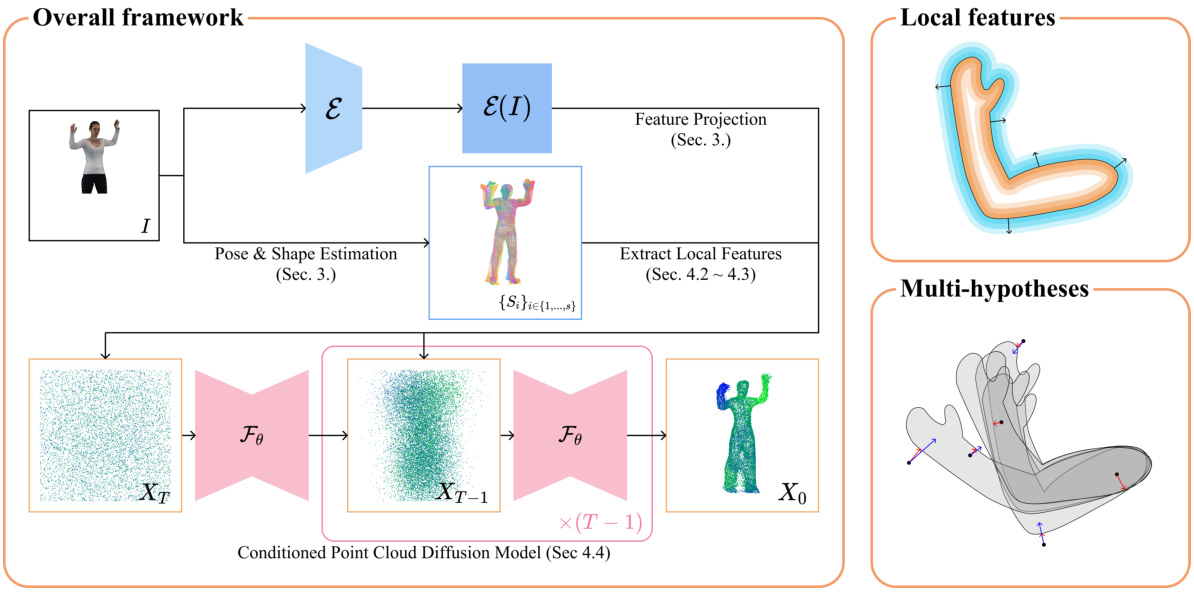
🔼 This figure shows the overall framework of MHCDIFF, a multi-hypotheses conditioned point cloud diffusion model for 3D human reconstruction from occluded images. It illustrates the process from input image to final 3D point cloud reconstruction, highlighting key components like 2D feature extraction, multiple SMPL mesh hypothesis generation, local feature extraction, and the conditioned diffusion process. The figure also details the local features (signed distance field and normals) and the multi-hypotheses conditioning strategy used.
read the caption
Figure 2: (Left) Overview of MHCDIFF. Given an occluded image I, MHCDIFF reconstructs 3D human shape as a point cloud. First, we extract the 2D feature map ε(I) and hypothesize pose and shape parameters of multiple plausible SMPL meshes {Si}i∈{1,...,s}. Our method consists of the conditioned point cloud diffusion model (Sec. 4.4). We project the 2D image features to capture details of the image (Sec. 3) and extract local features from multiple hypothesized SMPL meshes to leverage human body priors (Sec. 4.3) (Upper Right) The details of local features (Sec. 4.2). The signed distance field is visualized in positive and negative regions. The arrows indicate normal vectors n. (Lower Right) The details of multi-hypotheses (Sec. 4.3). We can consider the whole distribution during denoising process with the argmax i, and the denoising can be approximated by red arrows. However, it is sensitive to extreme samples of the distribution, so we condition the mean of occupancy values, which is visualized by transparency, and the denoising can be approximated by blue arrows.

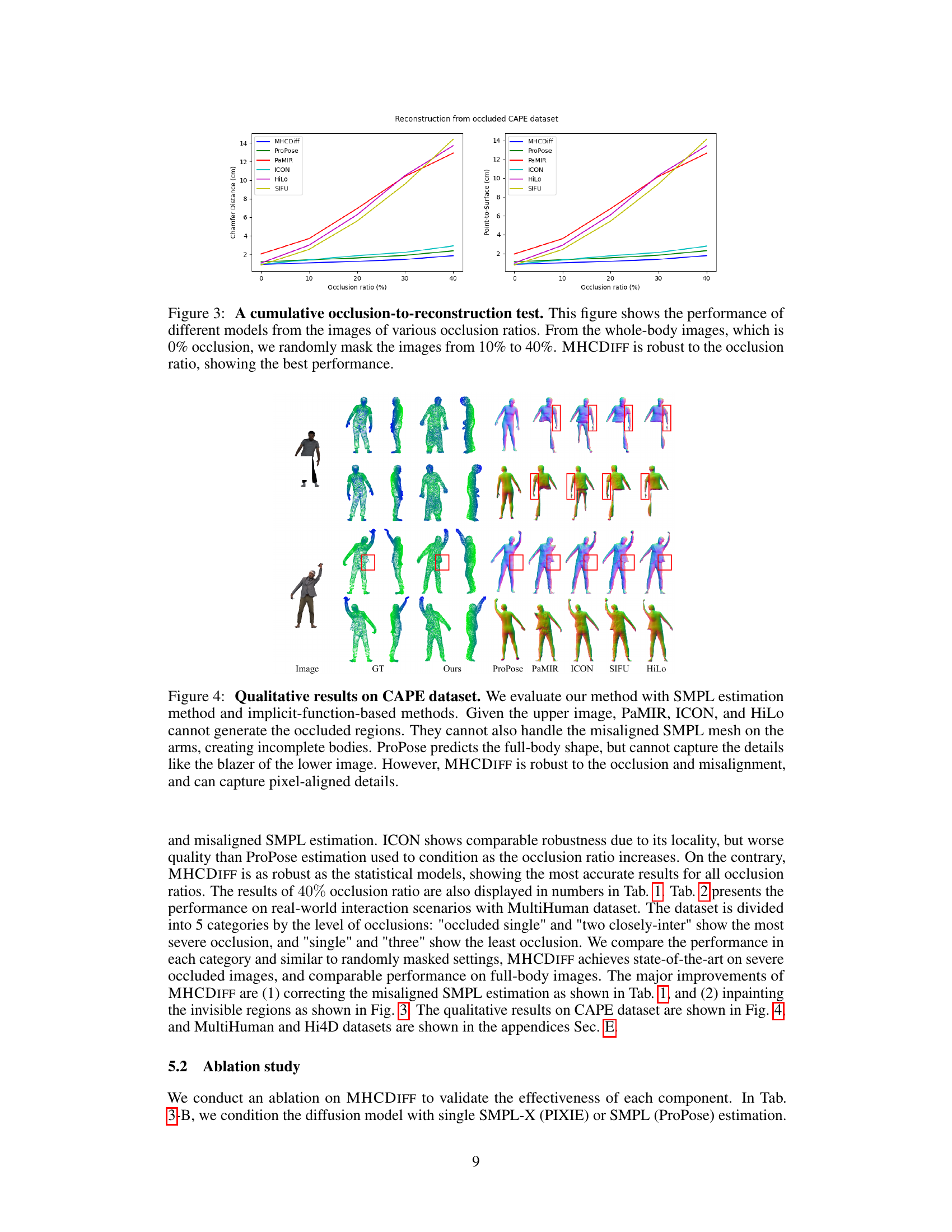
🔼 This figure presents a comparison of the performance of several methods for 3D human reconstruction in the presence of varying degrees of occlusion. The x-axis represents the percentage of occlusion in the input images (0% to 40%), while the y-axis shows the reconstruction error, measured using Chamfer Distance and Point-to-Surface Distance. The plot demonstrates that the proposed MHCDIFF method consistently outperforms other state-of-the-art techniques across all occlusion levels, highlighting its robustness to occlusions.
read the caption
Figure 3: A cumulative occlusion-to-reconstruction test. This figure shows the performance of different models from the images of various occlusion ratios. From the whole-body images, which is 0% occlusion, we randomly mask the images from 10% to 40%. MHCDIFF is robust to the occlusion ratio, showing the best performance.

🔼 This figure shows a qualitative comparison of different methods for 3D human reconstruction from occluded images on the CAPE dataset. The results demonstrate the superiority of MHCDIFF in handling occlusions and misaligned SMPL meshes, resulting in more complete and detailed reconstructions.
read the caption
Figure 4: Qualitative results on CAPE dataset. We evaluate our method with SMPL estimation method and implicit-function-based methods. Given the upper image, PaMIR, ICON, and HiLo cannot generate the occluded regions. They cannot also handle the misaligned SMPL mesh on the arms, creating incomplete bodies. ProPose predicts the full-body shape, but cannot capture the details like the blazer of the lower image. However, MHCDIFF is robust to the occlusion and misalignment, and can capture pixel-aligned details.

🔼 This figure shows the qualitative results of the MHCDIFF model on real-world images obtained from the internet. The images contain various occlusions due to human interactions or loose clothing. The figure compares the 3D reconstruction results of MHCDIFF against other state-of-the-art methods (ProPose, PaMIR, ICON, SIFU, and HiLo). The results demonstrate that MHCDIFF is capable of accurately reconstructing pixel-aligned 3D human shapes despite the occlusions and complex clothing styles. It is also robust to various levels of occlusion and interactions. Each column represents a different method, showing the input image, segmented images, and the corresponding 3D reconstruction.
read the caption
Figure 5: Qualitative results on in-the-wild images. Two images on the left show occlusions due to interactions, and the rightmost image shows loose clothes. From internet photos, we use [32] to segment images.

🔼 This figure compares the 3D human reconstruction results of MHCDIFF against several state-of-the-art methods on the CAPE dataset. The results demonstrate MHCDIFF’s superior ability to handle occlusions and misaligned SMPL meshes, producing more complete and detailed 3D human models, especially in areas with occlusions.
read the caption
Figure 4: Qualitative results on CAPE dataset. We evaluate our method with SMPL estimation method and implicit-function-based methods. Given the upper image, PaMIR, ICON, and HiLo cannot generate the occluded regions. They cannot also handle the misaligned SMPL mesh on the arms, creating incomplete bodies. ProPose predicts the full-body shape, but cannot capture the details like the blazer of the lower image. However, MHCDIFF is robust to the occlusion and misalignment, and can capture pixel-aligned details.

🔼 This figure shows qualitative results of 3D human reconstruction on the Hi4D dataset, which contains close human-human interactions with high-fidelity meshes. The input images are shown on the left side, along with their segmented versions. The reconstruction results from MHCDIFF and other baseline methods (ProPose, PaMIR, ICON, SIFU, HiLo) are displayed for comparison. This showcases MHCDIFF’s ability to handle complex interactions and occlusions, producing more complete and detailed 3D human shapes compared to the baselines.
read the caption
Figure 7: Qualitative results on Hi4D dataset.
More on tables

🔼 This table presents a quantitative comparison of different methods on the MultiHuman dataset. It shows the average Chamfer Distance (a common metric for evaluating 3D shape reconstruction accuracy) achieved by each method across various categories of occlusion levels. The categories represent different levels of occlusion complexity from a single occluded view to scenarios with two interacting humans, either naturally or closely interacting, up to three individuals. The results are compared against several state-of-the-art methods (PaMIR, ICON, SIFU, HiLo, PIXIE, and ProPose), highlighting the relative performance of MHCDIFF (the proposed method) across different occlusion conditions.
read the caption
Table 2: Quantitative evaluation on MultiHuman dataset. We report the average Chamfer Distance (cm) for each category. We compare the performance similar to Tab. 1.
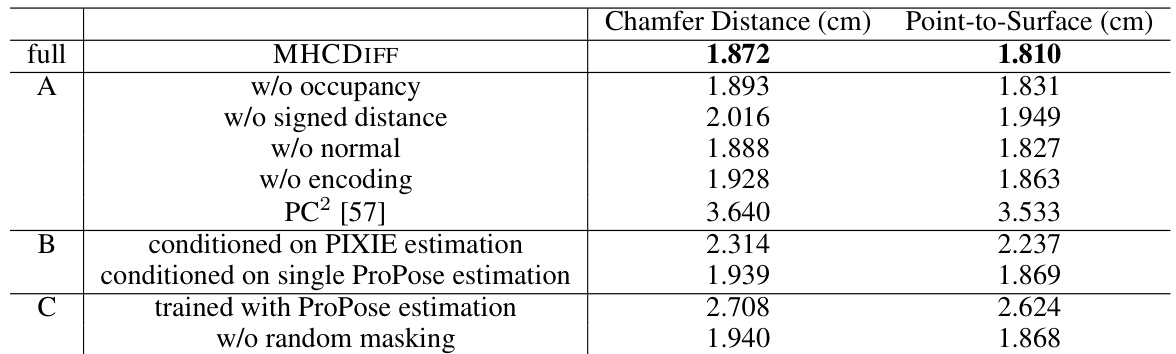
🔼 This table presents the ablation study conducted on the CAPE dataset to evaluate the contribution of different components of the MHCDIFF model. It shows the results with different components removed (occupancy, signed distance, normal, encoding), different conditioning strategies (PIXIE estimation, single ProPose estimation, ProPose training), and different training strategies (with and without random masking). The Chamfer Distance and Point-to-Surface distance metrics are used to assess the reconstruction quality.
read the caption
Table 3: Ablation study on CAPE dataset. We validate the effectiveness of (A) each component; (B) conditioning strategies; and (C) training strategies.

🔼 This table shows the impact of the number of SMPL (Skinned Multi-Person Linear Model) samples used in the multi-hypotheses conditioning mechanism of MHCDIFF on reconstruction quality and computational cost. As the number of SMPL samples increases, the Chamfer Distance and Point-to-Surface Distance initially decrease, suggesting improved accuracy. However, beyond a certain point (15 samples in this case), increasing the number of samples does not lead to further improvement and may even slightly decrease quality while significantly increasing the evaluation time. This indicates an optimal number of SMPL samples exists to balance accuracy and efficiency.
read the caption
Table 4: The correlation between the number of SMPL sampled and the reconstruction quality. We report the average Chamfer Distance (cm), Point-to-Surface distance (cm) and evaluation time of the various number of SMPL sampled.
Full paper#