TL;DR#
Current event-intensity asymmetric stereo systems struggle with limited datasets and poor generalization. Existing methods often overfit due to insufficient training data and lack diversity in the event domain. This limits their real-world applicability and hinders the development of robust 3D perception systems for dynamic environments.
This paper introduces Zero-shot Event-Intensity Asymmetric Stereo (ZEST), a novel framework that leverages off-the-shelf stereo and monocular depth estimation models pretrained on image datasets. ZEST uses visual prompting to align the representations of frames and events, eliminating the need for training on event data. A monocular cue-guided disparity refinement module further enhances robustness by incorporating monocular depth information. Extensive experiments show that ZEST outperforms existing methods in both zero-shot evaluation performance and generalization ability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and robotics because it presents a novel zero-shot approach to event-intensity asymmetric stereo matching, a challenging problem with limited datasets. This eliminates the need for extensive training data and enhances the generalization ability of stereo models, opening new avenues for research in dynamic 3D perception. The superior zero-shot performance and enhanced generalization achieved by the proposed method significantly advance the state-of-the-art in the field.
Visual Insights#
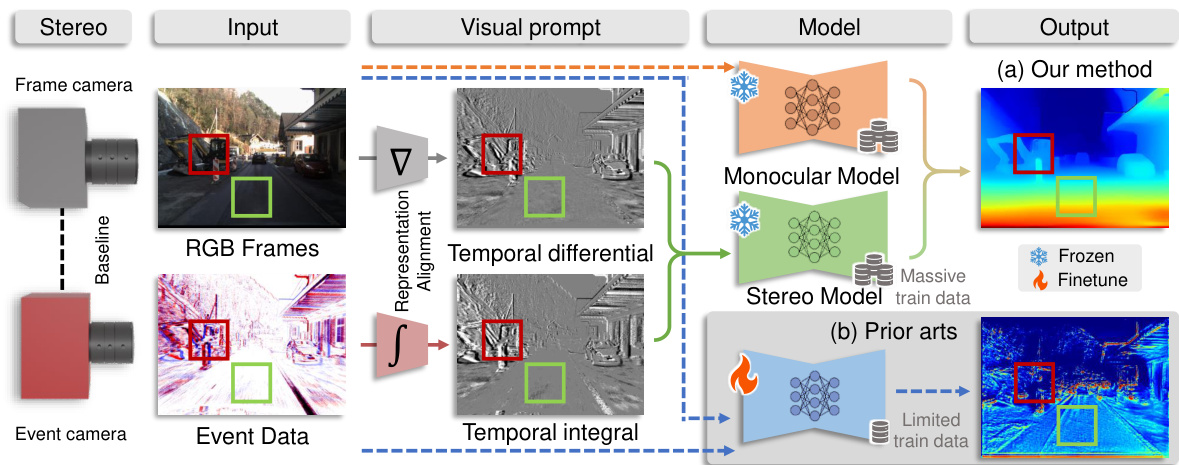
🔼 This figure illustrates the proposed Zero-shot Event-intensity asymmetric Stereo (ZEST) framework, comparing it to prior art methods. Panel (a) shows the ZEST approach using off-the-shelf models (with visual prompts) for stereo matching and monocular depth estimation. Panel (b) depicts traditional methods that require training with limited annotated data, highlighting the benefit of ZEST’s zero-shot approach. The diagram shows the inputs (frame and event cameras), processing steps (representation alignment, model inference), and output (disparity map).
read the caption
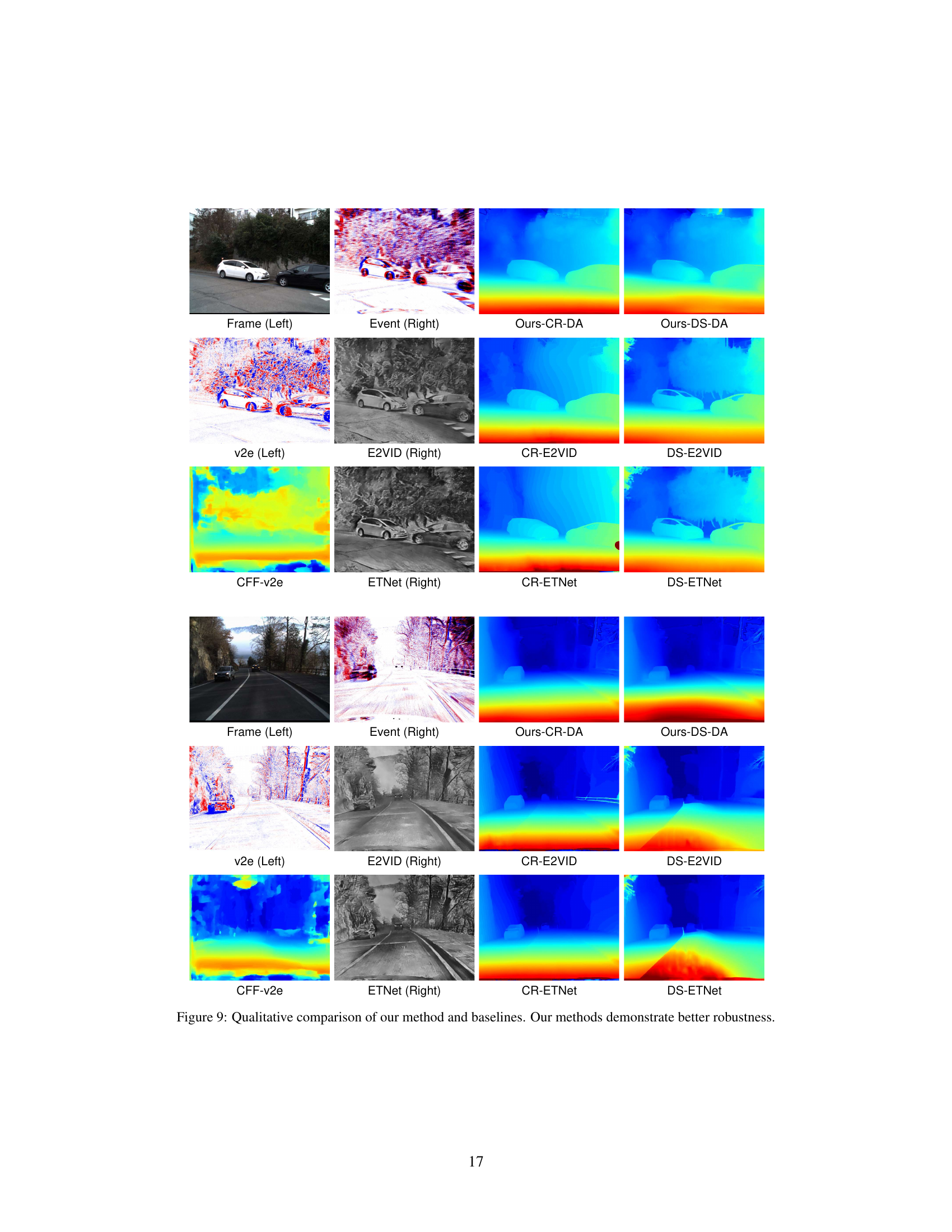
Figure 1: The proposed Zero-shot Event-intensity asymmetric STereo (ZEST) framework estimates disparity by finding correspondences between RGB frames and event data. (a) Our method conducts stereo matching by utilizing off-the-shelf stereo matching and monocular depth estimation models with frozen weights, and feeding them visual prompts tailored to the physical formulation of frames and events (temporal difference of frames and temporal integral of events, respectively). (b) In contrast, existing methods (e.g., [40]) that rely on training data with known ground truth disparities often suffer from limited annotated data availability, thus leading to unsatisfactory results.
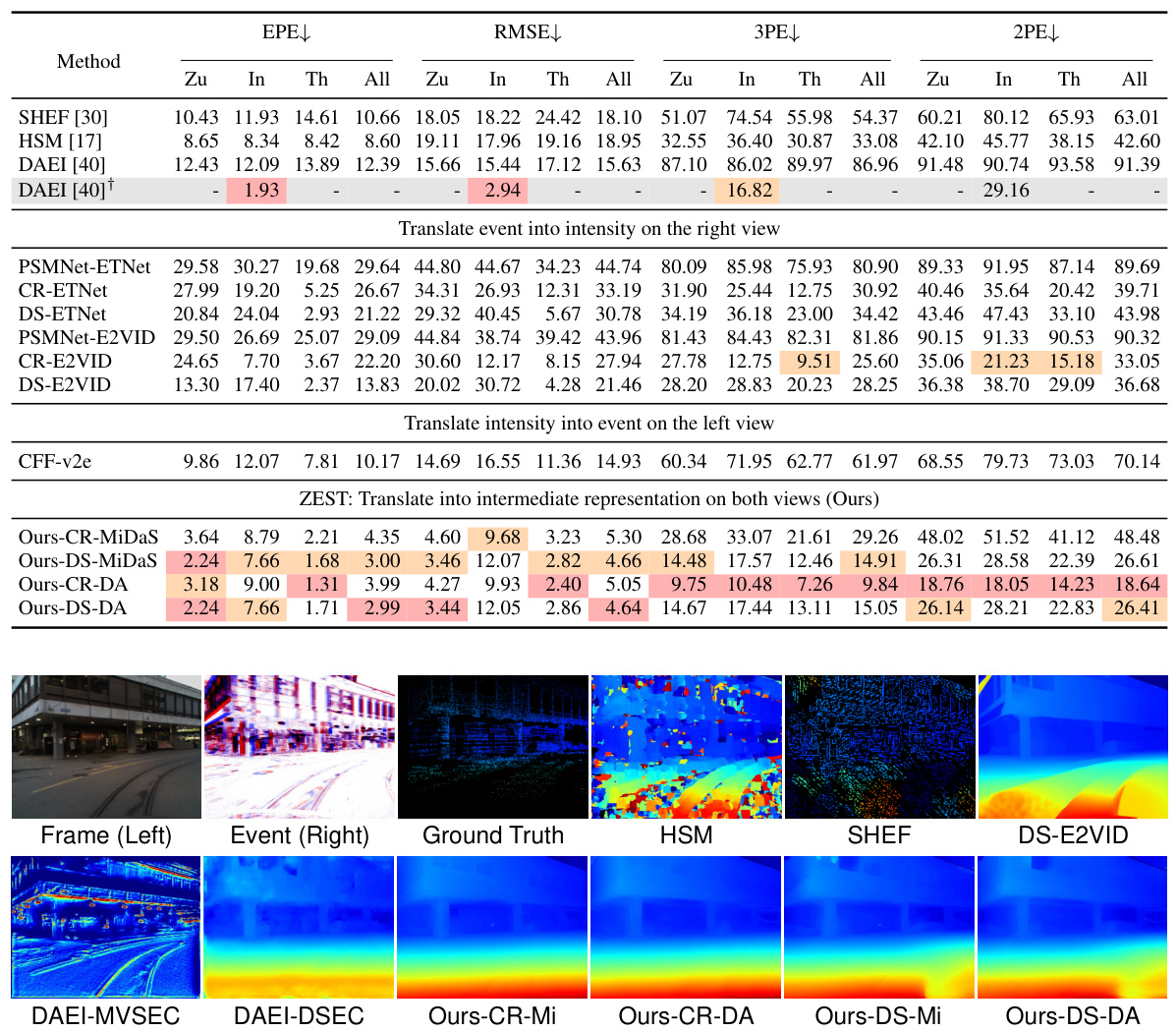
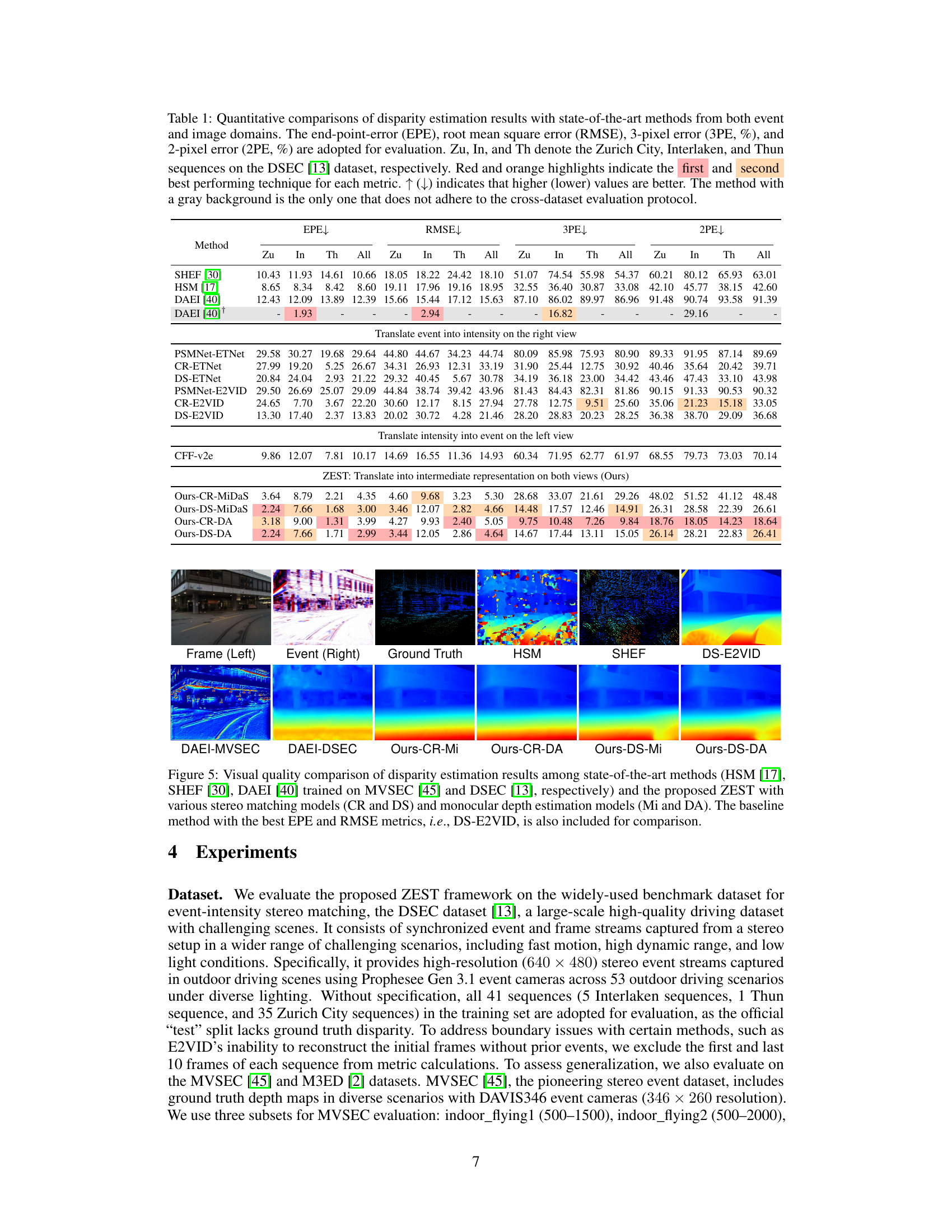
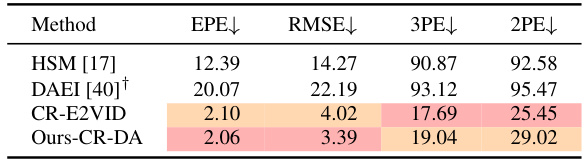
🔼 This table presents a quantitative comparison of the proposed ZEST method against several state-of-the-art approaches for disparity estimation using both event and image data. The comparison uses four metrics: End-Point Error (EPE), Root Mean Square Error (RMSE), 3-pixel error (3PE), and 2-pixel error (2PE). Results are shown for three different sequences from the DSEC dataset (Zurich City, Interlaken, and Thun) and overall across all sequences. The table highlights the best and second-best performing methods for each metric.
read the caption
Table 1: Quantitative comparisons of disparity estimation results with state-of-the-art methods from both event and image domains. The end-point-error (EPE), root mean square error (RMSE), 3-pixel error (3PE, %), and 2-pixel error (2PE, %) are adopted for evaluation. Zu, In, and Th denote the Zurich City, Interlaken, and Thun sequences on the DSEC [13] dataset, respectively. Red and orange highlights indicate the first and second best performing technique for each metric. ↑ (↓) indicates that higher (lower) values are better. The method with a gray background is the only one that does not adhere to the cross-dataset evaluation protocol.
In-depth insights#
Zero-Shot Stereo#
Zero-shot stereo, aiming to predict depth maps without model training on stereo datasets, presents a significant challenge in computer vision. It leverages the power of pre-trained models from other domains, such as image-based monocular depth estimation, transferring their knowledge to the stereo task. This approach addresses the limitations of traditional stereo methods, particularly their reliance on large, annotated stereo datasets which are often scarce and expensive to acquire. Zero-shot stereo offers the potential for greater generalization and adaptability, allowing for deployment in diverse scenarios with minimal or no task-specific fine-tuning. However, domain gaps between image and stereo data pose significant hurdles. Successfully bridging this gap requires creative strategies for aligning the representations, making effective use of the source model’s features, and robustly handling uncertainty. Further research should explore novel techniques to enhance the accuracy, efficiency, and robustness of zero-shot stereo, especially in scenarios with complex scenes, dynamic objects, and limited visual cues.
Visual Prompting#
The concept of “Visual Prompting” in the context of this research paper appears to be a novel technique for aligning the representations of images and event data from disparate sources. This is crucial because event cameras and frame cameras operate under fundamentally different principles, thus generating data with significant modality gaps. By creating a visual prompt, which could involve intermediate representations derived from both image and event data, the model can effectively bridge these differences, making it possible to utilize pre-trained models from the image domain for event-intensity asymmetric stereo matching, thus eliminating the need for extensive training data in the event domain. This approach dramatically improves the efficiency and generalizability of the stereo matching process, allowing it to adapt to a wider range of scenes and conditions. The effectiveness of this visual prompting technique underscores the power of leveraging prior knowledge from established image processing models, suggesting that similar approaches could be useful in other cross-modal tasks.
Monocular Cue#
In computer vision, especially in depth estimation, monocular cues refer to information derived from a single image to infer 3D structure. These cues are crucial because they provide depth information without relying on stereo vision or multiple viewpoints. Examples include texture gradients, shading, object size, and relative position. A monocular cue-guided disparity refinement module, as discussed in the provided text, leverages these cues to improve the accuracy and robustness of depth maps generated from stereo matching. It essentially uses information from a single camera view to correct inaccuracies or missing data in stereo-based depth estimations. This refinement step is especially helpful in regions with few or sparse features, making the depth estimations more complete and reliable. The efficacy of this technique underscores the value of integrating monocular cues with other methods to achieve more robust and accurate 3D scene understanding.
Generalization#
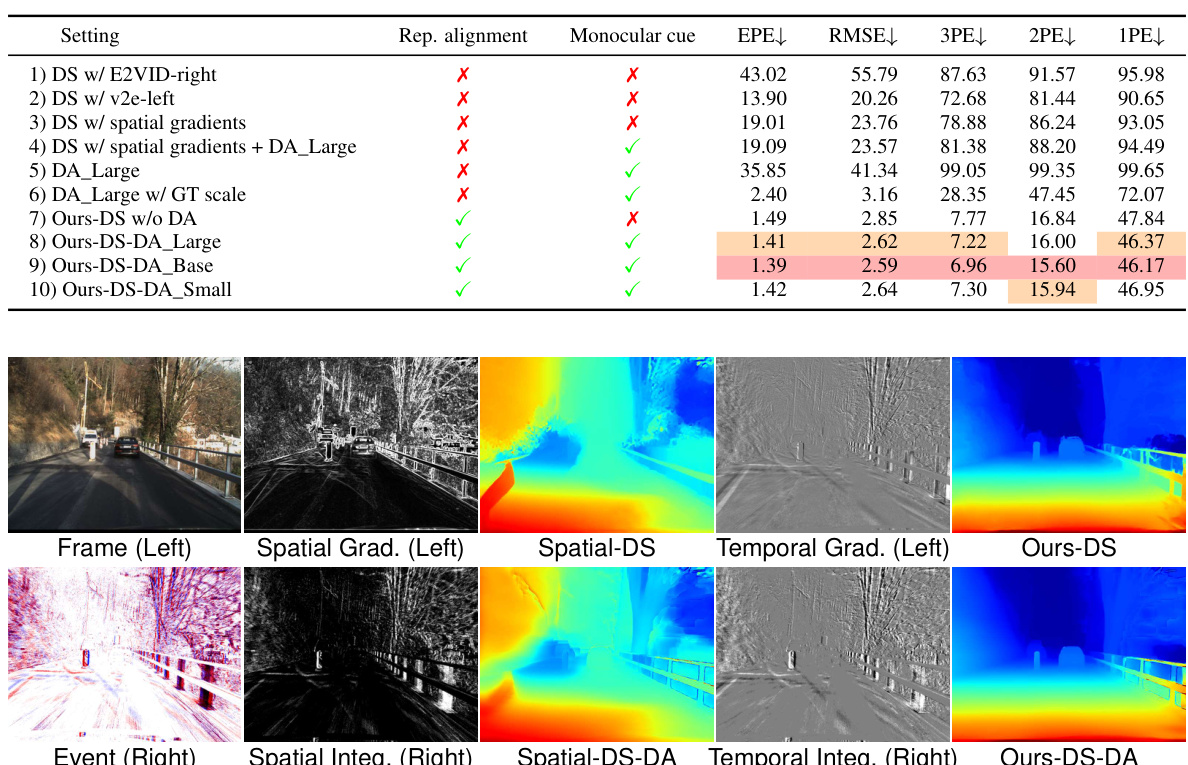
Generalization in machine learning models is a crucial aspect, especially when dealing with limited data. The paper tackles this by proposing a zero-shot approach, leveraging pre-trained models from the image domain to address the scarcity of event-based datasets. This strategy avoids overfitting and enhances generalization by utilizing a wealth of knowledge already learned from diverse image data. The visual prompting technique cleverly bridges the representation gap between image and event data, allowing for seamless integration with off-the-shelf models. Furthermore, a monocular cue-guided refinement module boosts robustness, particularly in challenging scenarios with sparse or textureless regions. The paper’s experimental results strongly demonstrate the method’s superior zero-shot performance and improved generalization compared to existing approaches, highlighting the potential of this innovative methodology for real-world applications. The emphasis on zero-shot learning and the utilization of readily available models are key strengths, promoting wider accessibility and applicability. However, further investigation is warranted into handling sparse data and noise more effectively to further enhance robustness and generalization.
Future Works#
Future work could explore several promising avenues. Improving the robustness of the representation alignment module is crucial, potentially through learning-based approaches or domain adaptation techniques to bridge the gap between event and frame data more effectively. Addressing the computational cost associated with using off-the-shelf image-domain models is also vital. This might involve exploring more efficient architectures or developing specialized lightweight models optimized for event-intensity data. Furthermore, investigating the effect of different monocular depth estimation models on the accuracy and robustness of disparity refinement is warranted, as is exploring models specifically trained on event data to improve performance in challenging scenes. Finally, expanding the dataset to include a broader range of challenging scenarios would strengthen the framework’s generalizability and enable more comprehensive evaluations.
More visual insights#
More on figures
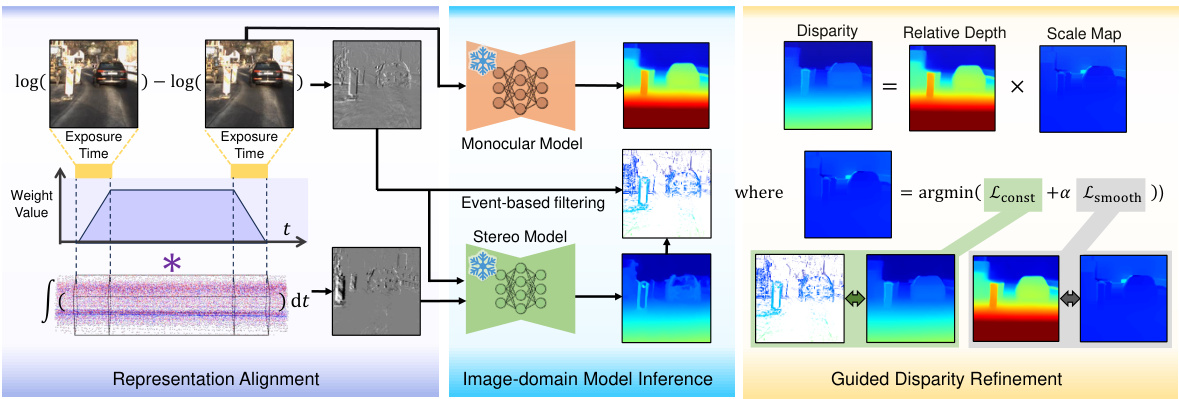
🔼 This figure illustrates the workflow of the Zero-shot Event-intensity asymmetric STereo (ZEST) framework. It consists of three main stages: Representation Alignment, Image-domain Model Inference, and Guided Disparity Refinement. In the first stage, the visual prompt is generated by aligning the representations of frames and events using a combination of temporal difference of frames and temporal integral of events. The resulting representation is then fed into an off-the-shelf stereo model to estimate the disparity map. Finally, a monocular cue-guided disparity refinement module is used to improve the accuracy of disparity map by minimizing the differences between the monocular depth estimation and binocular depth estimation. The output is a refined disparity map that is more robust to noisy and sparse event data.
read the caption
Figure 2: Overview of the proposed ZEST framework. The representation alignment module aligns frames and events, considering exposure time and event properties. This enables using an off-the-shelf stereo model to find correspondences. Disparity refinement then improves the estimates by minimizing differences between monocular depth prediction rescaled by an optimized scale map and binocular depth predictions, guided by event density confidence.

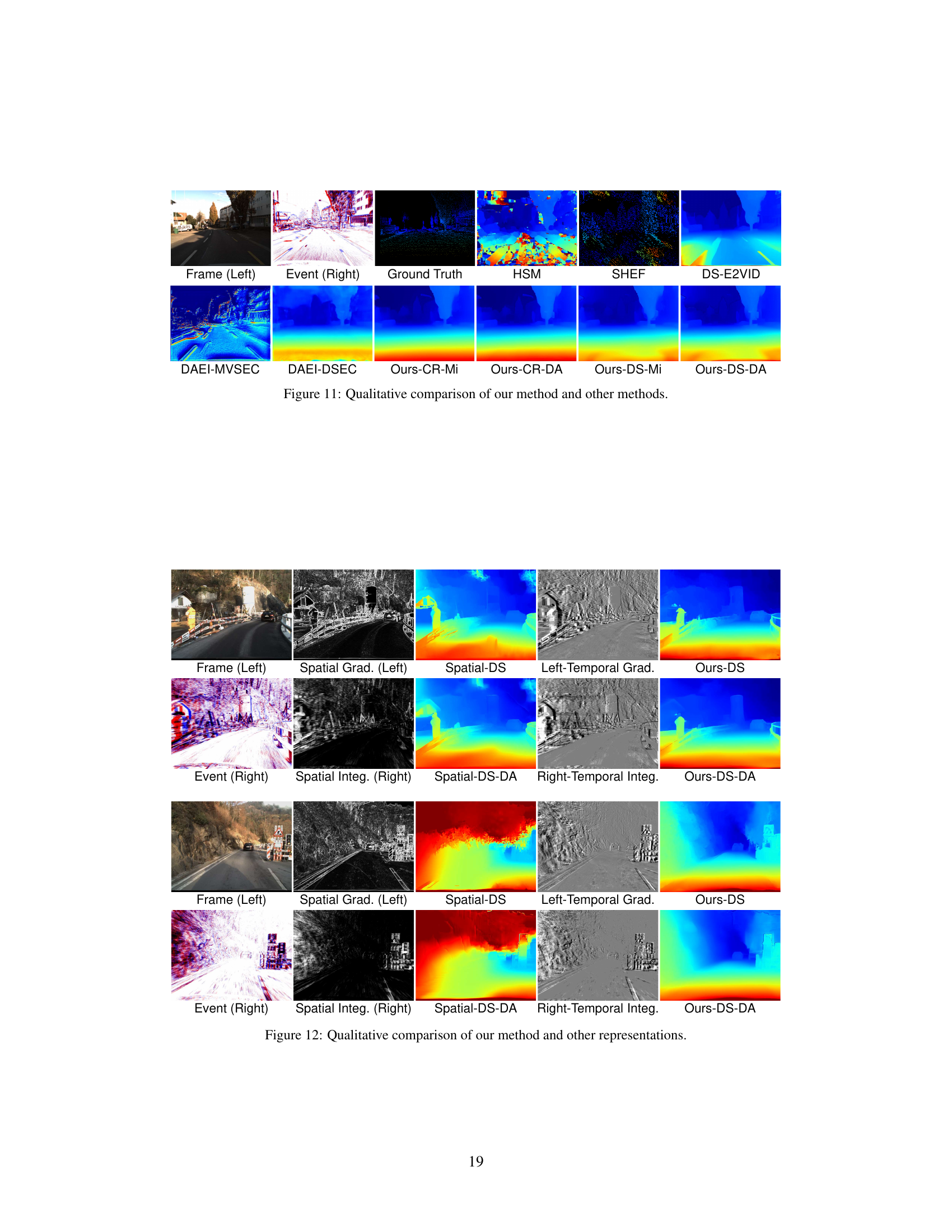
🔼 This figure compares the disparity map estimations of a stereo model ([16]) using different input representations: raw data, intensity-based representation ([26]), event-based representation ([15]), and the intermediate representation proposed by the authors. The goal is to illustrate how the proposed intermediate representation better bridges the appearance gap between frames and events, leading to improved stereo matching performance for event-intensity asymmetric stereo. The comparison highlights that aligning the modalities in an appropriate representation space improves the disparity map estimations.
read the caption
Figure 3: Visual comparisons of the disparity predicted by a stereo model [16] fed with inputs in the first two rows, which are aligned in the space of raw data, intensity (via [26]), events (via [15]), and intermediate (via the proposed method), respectively.

🔼 This figure shows several example results from the proposed ZEST model. Each row represents a different scene, and the images in each row demonstrate the model’s ability to generate accurate depth maps even under difficult conditions, including sparse event data, complex scenes with various textures, low light conditions, and high dynamic range scenes. This illustrates the model’s robustness and generalizability.
read the caption
Figure 4: From left to right, our model exhibits impressive generalization abilities across a broad spectrum of varied scenes, encompassing sparse event scenes, richly textured environments, dimly lit settings, close-range captures, and high dynamic range situations.
🔼 This figure illustrates the architecture of the proposed Zero-shot Event-intensity asymmetric STereo (ZEST) framework. It details the two main components: the representation alignment module and the disparity refinement module. The representation alignment module uses visual prompts, leveraging the physical relationship between frames and events (exposure time and event properties) to align their representations and allow for the use of off-the-shelf stereo models. The disparity refinement module then enhances the results by using a monocular depth estimation model to correct the disparities, guided by the event density. This refinement step helps to improve robustness, especially in regions with limited events.
read the caption
Figure 2: Overview of the proposed ZEST framework. The representation alignment module aligns frames and events, considering exposure time and event properties. This enables using an off-the-shelf stereo model to find correspondences. Disparity refinement then improves the estimates by minimizing differences between monocular depth prediction rescaled by an optimized scale map and binocular depth predictions, guided by event density confidence.
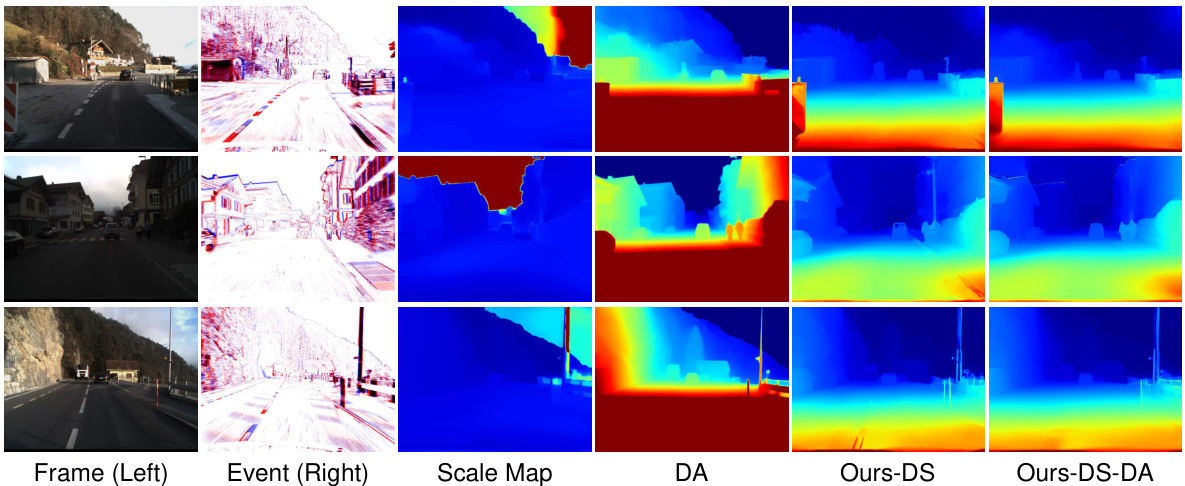
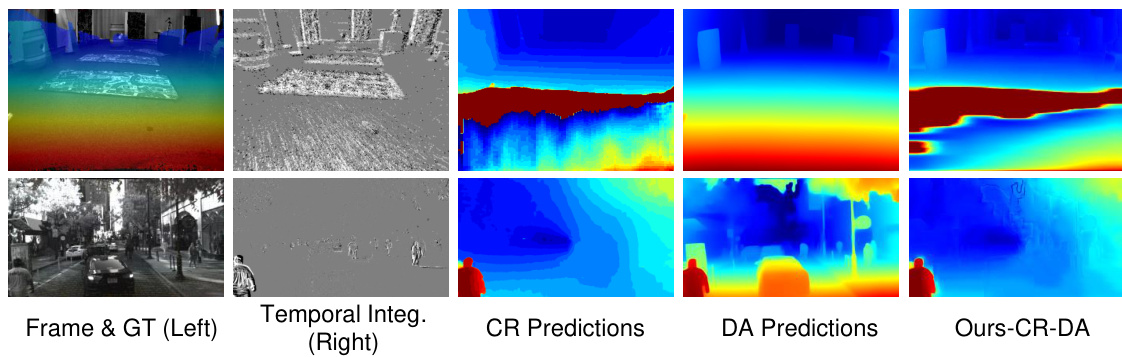
🔼 This figure compares the disparity maps generated by different methods. The input consists of left frames and right events. The ‘Scale Map’ shows the scaling factor calculated by the disparity refinement module. The ‘DA’ column shows disparity maps produced by the monocular depth estimation model alone. The ‘Ours-DS’ column displays disparity maps generated by the proposed method without the monocular cue-guided refinement module, while the ‘Ours-DS-DA’ column shows results when the refinement module is incorporated, combining both stereo matching and monocular depth information.
read the caption
Figure 7: Visual comparison of the effectiveness of the monocular cue-guided disparity refinement module. From left to right: input frames, input events, scale map results, disparity results from the monocular model DA alone, results from the proposed method without DA, and results with DA incorporated.
🔼 This figure illustrates the proposed Zero-shot Event-intensity asymmetric STereo (ZEST) framework, comparing it to prior art methods. It shows how ZEST uses pre-trained models and visual prompts to estimate disparity from frame and event data without additional training, unlike previous methods that require significant labeled data for training. (a) details the ZEST approach, using off-the-shelf models and visual prompts. (b) shows that prior art methods relied on training data with ground truth disparities, resulting in overfitting and poor generalization.
read the caption
Figure 1: The proposed Zero-shot Event-intensity asymmetric STereo (ZEST) framework estimates disparity by finding correspondences between RGB frames and event data. (a) Our method conducts stereo matching by utilizing off-the-shelf stereo matching and monocular depth estimation models with frozen weights, and feeding them visual prompts tailored to the physical formulation of frames and events (temporal difference of frames and temporal integral of events, respectively). (b) In contrast, existing methods (e.g., [40]) that rely on training data with known ground truth disparities often suffer from limited annotated data availability, thus leading to unsatisfactory results.
🔼 This figure shows a detailed overview of the proposed ZEST (Zero-shot Event-intensity asymmetric STereo) framework. The framework comprises two main modules: 1) Representation Alignment, which aligns the different representations of frames and events using a visual prompting technique considering exposure time and event properties. This allows the use of off-the-shelf stereo models. 2) Disparity Refinement, which enhances the disparity estimation by minimizing differences between monocular depth predictions (from foundation models) and binocular predictions. This is guided by event density confidence, improving robustness across static and dynamic regions. The alignment module’s output is fed into a stereo model, which produces the initial disparity map. This map is then further refined using the monocular cue-guided disparity refinement module. The final output is a refined disparity map.
read the caption
Figure 2: Overview of the proposed ZEST framework. The representation alignment module aligns frames and events, considering exposure time and event properties. This enables using an off-the-shelf stereo model to find correspondences. Disparity refinement then improves the estimates by minimizing differences between monocular depth prediction rescaled by an optimized scale map and binocular depth predictions, guided by event density confidence.
🔼 This figure illustrates the workflow of the Zero-shot Event-intensity asymmetric STereo (ZEST) framework, which consists of two main components: representation alignment and disparity refinement. The representation alignment module aligns the features of frames and events to enable using an off-the-shelf stereo model for correspondence finding, while the disparity refinement module improves the disparity estimates by incorporating monocular depth cues and minimizing the differences between monocular and binocular depth predictions, guided by the event density confidence.
read the caption
Figure 2: Overview of the proposed ZEST framework. The representation alignment module aligns frames and events, considering exposure time and event properties. This enables using an off-the-shelf stereo model to find correspondences. Disparity refinement then improves the estimates by minimizing differences between monocular depth prediction rescaled by an optimized scale map and binocular depth predictions, guided by event density confidence.

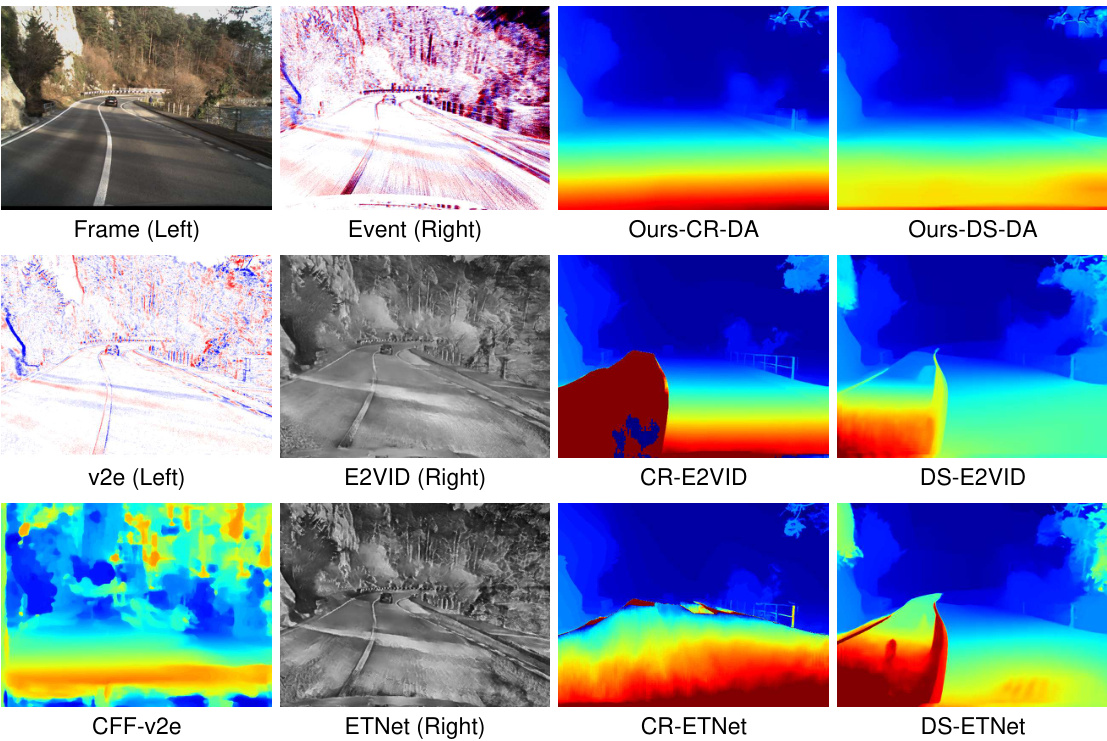
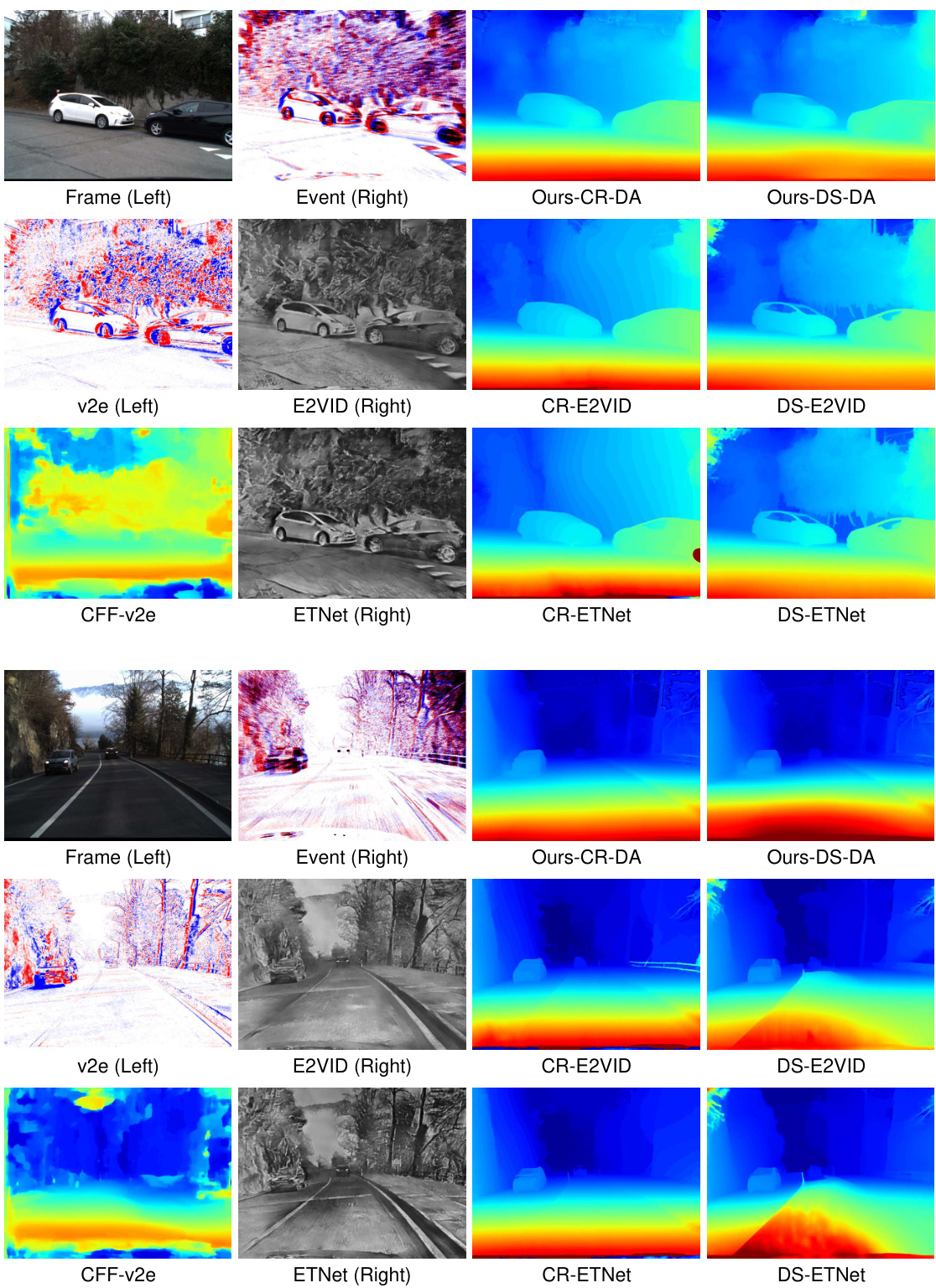
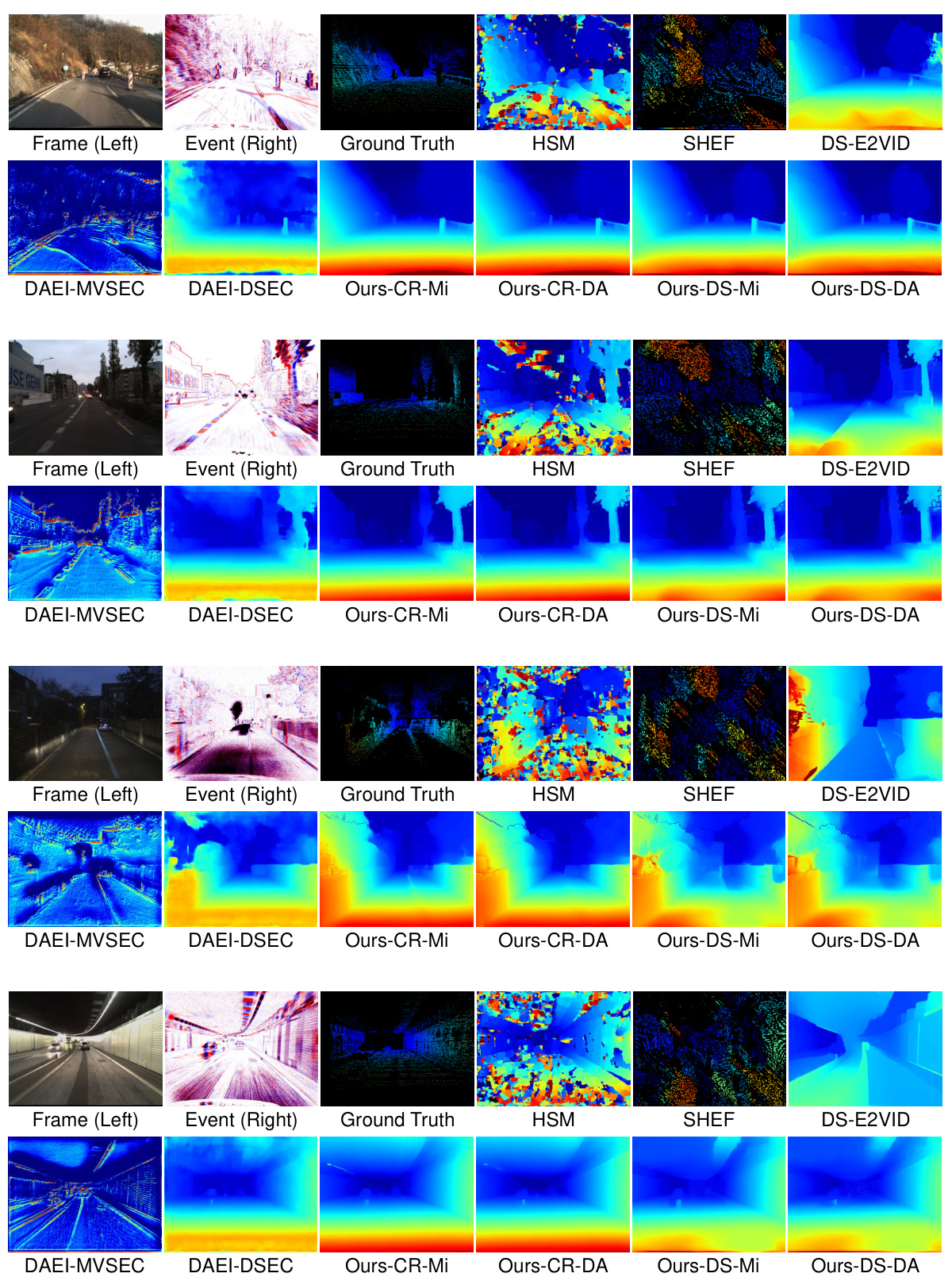
🔼 This figure compares the disparity maps generated by several state-of-the-art methods and the proposed ZEST method. It shows qualitative differences in disparity map quality, highlighting the superior performance of ZEST in terms of detail preservation and robustness. Different stereo and monocular models are used with ZEST to demonstrate the versatility of the approach.
read the caption
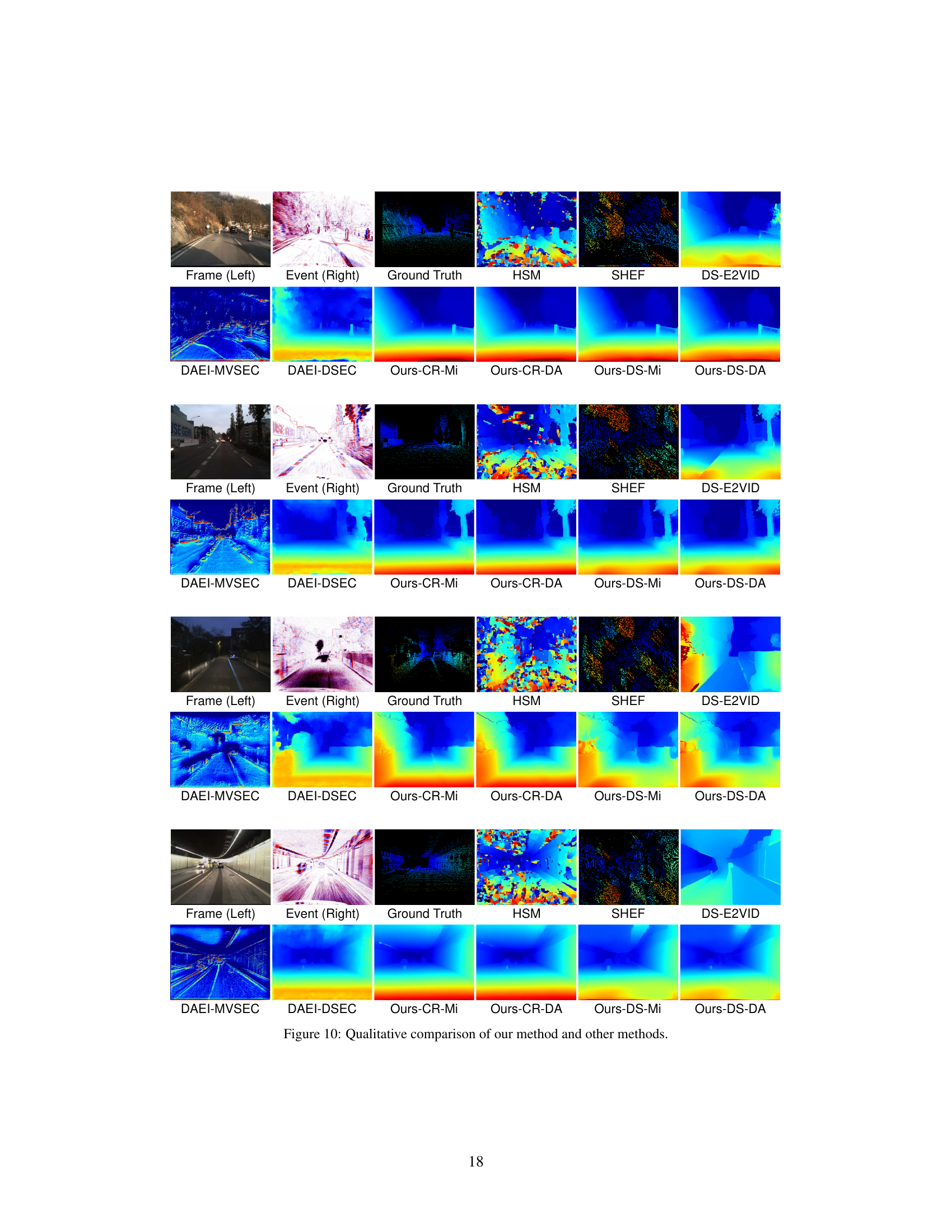
Figure 5: Visual quality comparison of disparity estimation results among state-of-the-art methods (HSM [17], SHEF [30], DAEI [40] trained on MVSEC [45] and DSEC [13], respectively) and the proposed ZEST with various stereo matching models (CR and DS) and monocular depth estimation models (Mi and DA). The baseline method with the best EPE and RMSE metrics, i.e., DS-E2VID, is also included for comparison.

🔼 This figure provides a detailed overview of the ZEST (Zero-shot Event-intensity asymmetric STereo) framework. It illustrates the two main components: representation alignment and disparity refinement. The representation alignment module handles the differences between frame and event data by creating an intermediate representation that leverages exposure time and event properties. This allows for the use of an off-the-shelf stereo model for finding correspondences between the frames and events. The disparity refinement module takes the results from the stereo model and refines them further, using a monocular depth estimation model and an optimized scale map to minimize discrepancies between monocular and binocular depth estimates. Event density is used to guide this refinement process, ensuring better results in regions with more event information.
read the caption
Figure 2: Overview of the proposed ZEST framework. The representation alignment module aligns frames and events, considering exposure time and event properties. This enables using an off-the-shelf stereo model to find correspondences. Disparity refinement then improves the estimates by minimizing differences between monocular depth prediction rescaled by an optimized scale map and binocular depth predictions, guided by event density confidence.
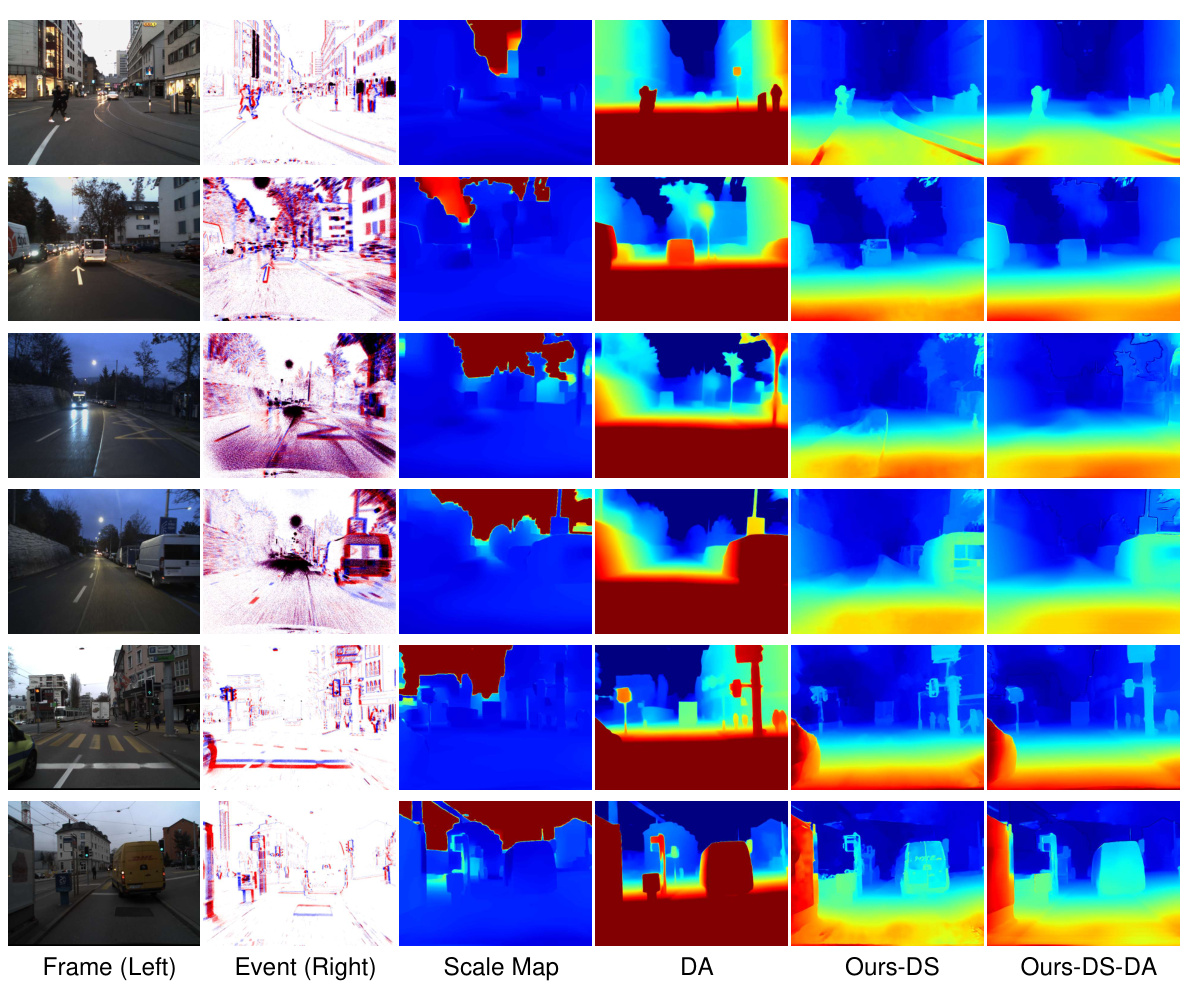
🔼 This figure shows a visual comparison of the disparity refinement module’s impact. It compares disparity maps generated using only the monocular depth estimation model (DA), the proposed method without the monocular cue refinement (Ours-DS), and the final result incorporating the monocular cue (Ours-DS-DA). The inputs (frames and events) are shown for context. The scale map visualization illustrates how the refinement process adjusts the disparity. The comparison allows one to see how the monocular cue helps to improve the disparity map’s accuracy, especially in regions with sparse events or low texture.
read the caption
Figure 7: Visual comparison of the effectiveness of the monocular cue-guided disparity refinement module. From left to right: input frames, input events, scale map results, disparity results from the monocular model DA alone, results from the proposed method without DA, and results with DA incorporated.

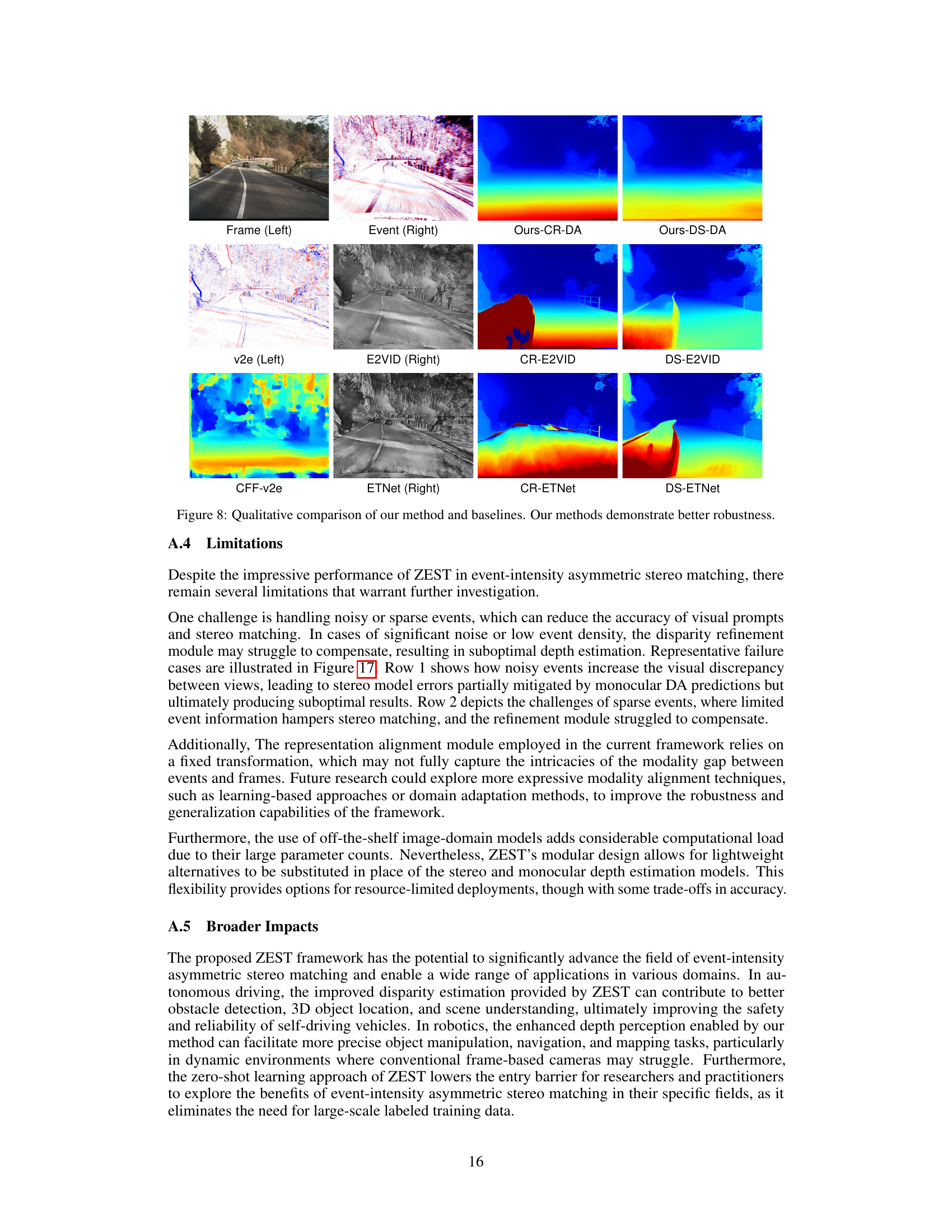
🔼 This figure showcases examples where the proposed ZEST method struggles to produce accurate disparity maps. The top row shows a scenario with noisy events, leading to discrepancies between the visual prompts and resulting in errors despite the disparity refinement module’s attempt at compensation. The bottom row illustrates challenges when sparse event data is encountered, insufficient information for reliable stereo matching and consequently, refinement struggles to improve the result.
read the caption
Figure 17: Examples of failure cases for the proposed method.

🔼 This figure showcases instances where the proposed ZEST framework’s performance is suboptimal. The top row illustrates a scene with significant noise in the event stream, leading to increased visual discrepancies and impacting the accuracy of visual prompts and stereo matching. The bottom row highlights another failure case where sparse events hinder stereo matching, and the refinement module struggles to fully compensate for the lack of reliable event correspondences. These examples emphasize the limitations of the ZEST method when dealing with noisy or sparse event data.
read the caption
Figure 17: Examples of failure cases for the proposed method.

🔼 This figure compares the disparity estimation results obtained using the proposed ZEST method with the ground truth disparities for real data from the MVSEC dataset. It shows the left frame and ground truth, the temporal gradient of the left frame, the event data from the right camera, the temporal integral of the event data from the right camera, and finally the disparity map produced by the proposed method. This visual comparison demonstrates the effectiveness of the ZEST framework in accurately estimating disparity from event and frame data.
read the caption
Figure 15: Comparison of disparity estimation results for real data from the MVSEC [45] dataset.
🔼 This figure shows examples where the proposed method, ZEST, struggles to produce accurate disparity maps. The top row showcases a scene with significant noise and sparse events, leading to inaccuracies in visual prompts and affecting the accuracy of stereo matching. The bottom row illustrates a scene with many textureless regions and sparse events, which makes establishing reliable correspondences challenging, hindering the performance of the stereo matching. Even with the refinement module, these challenges persist, leading to suboptimal depth estimation results.
read the caption
Figure 17: Examples of failure cases for the proposed method.
More on tables

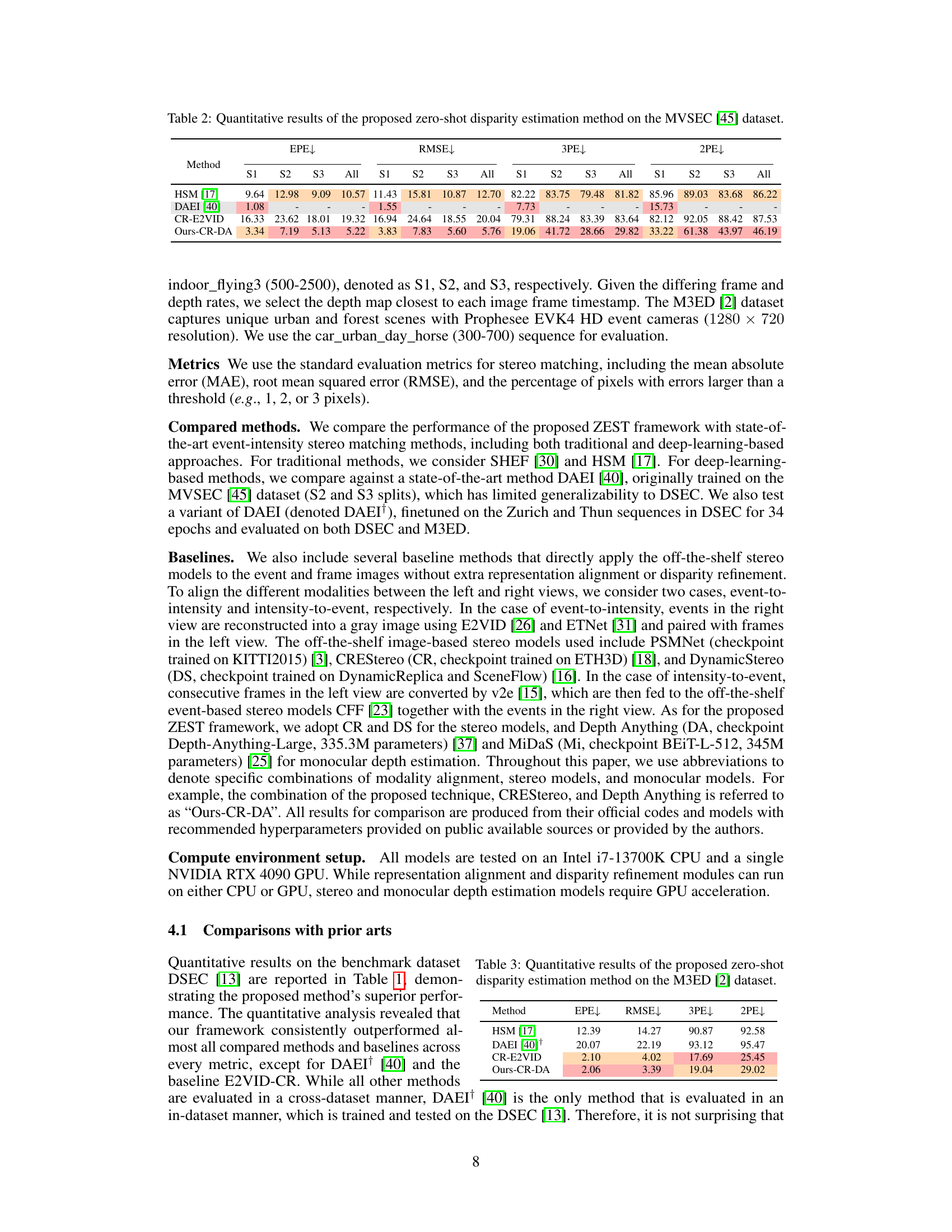
🔼 This table presents a quantitative comparison of the proposed zero-shot disparity estimation method’s performance on the MVSEC dataset. It compares the method against several state-of-the-art techniques, evaluating performance metrics such as endpoint error (EPE), root mean squared error (RMSE), 3-pixel error (3PE), and 2-pixel error (2PE) across three subsets (S1, S2, S3) of the dataset. The results highlight the method’s accuracy and generalization capabilities.
read the caption
Table 2: Quantitative results of the proposed zero-shot disparity estimation method on the MVSEC [45] dataset.
🔼 This table presents a quantitative comparison of the proposed zero-shot disparity estimation method’s performance on the M3ED dataset. It compares the method against several state-of-the-art techniques using metrics such as end-point error (EPE), root mean square error (RMSE), 3-pixel error (3PE), and 2-pixel error (2PE). Lower values are generally better for these metrics. The table highlights the proposed method’s performance relative to other approaches on this specific dataset.
read the caption
Table 3: Quantitative results of the proposed zero-shot disparity estimation method on the M3ED [2] dataset.
🔼 This table presents a quantitative comparison of the proposed ZEST method against several state-of-the-art techniques for disparity estimation using both event and image data. The evaluation metrics include End-Point Error (EPE), Root Mean Square Error (RMSE), 3-pixel error (3PE), and 2-pixel error (2PE). Results are shown for different datasets (Zurich City, Interlaken, and Thun sequences from the DSEC dataset). The table highlights the superior performance of the proposed method compared to others, especially considering its zero-shot capability.
read the caption
Table 1: Quantitative comparisons of disparity estimation results with state-of-the-art methods from both event and image domains. The end-point-error (EPE), root mean square error (RMSE), 3-pixel error (3PE, %), and 2-pixel error (2PE, %) are adopted for evaluation. Zu, In, and Th denote the Zurich City, Interlaken, and Thun sequences on the DSEC [13] dataset, respectively. Red and orange highlights indicate the first and second best performing technique for each metric. ↑ (↓) indicates that higher (lower) values are better. The method with a gray background is the only one that does not adhere to the cross-dataset evaluation protocol.
🔼 This table compares the performance of the proposed Zero-shot Event-intensity asymmetric STereo (ZEST) method against other state-of-the-art methods for disparity estimation. It uses four metrics (EPE, RMSE, 3PE, 2PE) to evaluate performance across three different sequences from the DSEC dataset and one combined metric across all three sequences. The table highlights the superior performance of the ZEST method, especially compared to methods that don’t use cross-dataset evaluation.
read the caption
Table 1: Quantitative comparisons of disparity estimation results with state-of-the-art methods from both event and image domains. The end-point-error (EPE), root mean square error (RMSE), 3-pixel error (3PE, %), and 2-pixel error (2PE, %) are adopted for evaluation. Zu, In, and Th denote the Zurich City, Interlaken, and Thun sequences on the DSEC [13] dataset, respectively. Red and orange highlights indicate the first and second best performing technique for each metric. ↑ (↓) indicates that higher (lower) values are better. The method with a gray background is the only one that does not adhere to the cross-dataset evaluation protocol.
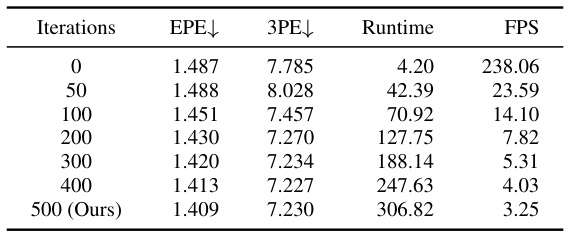
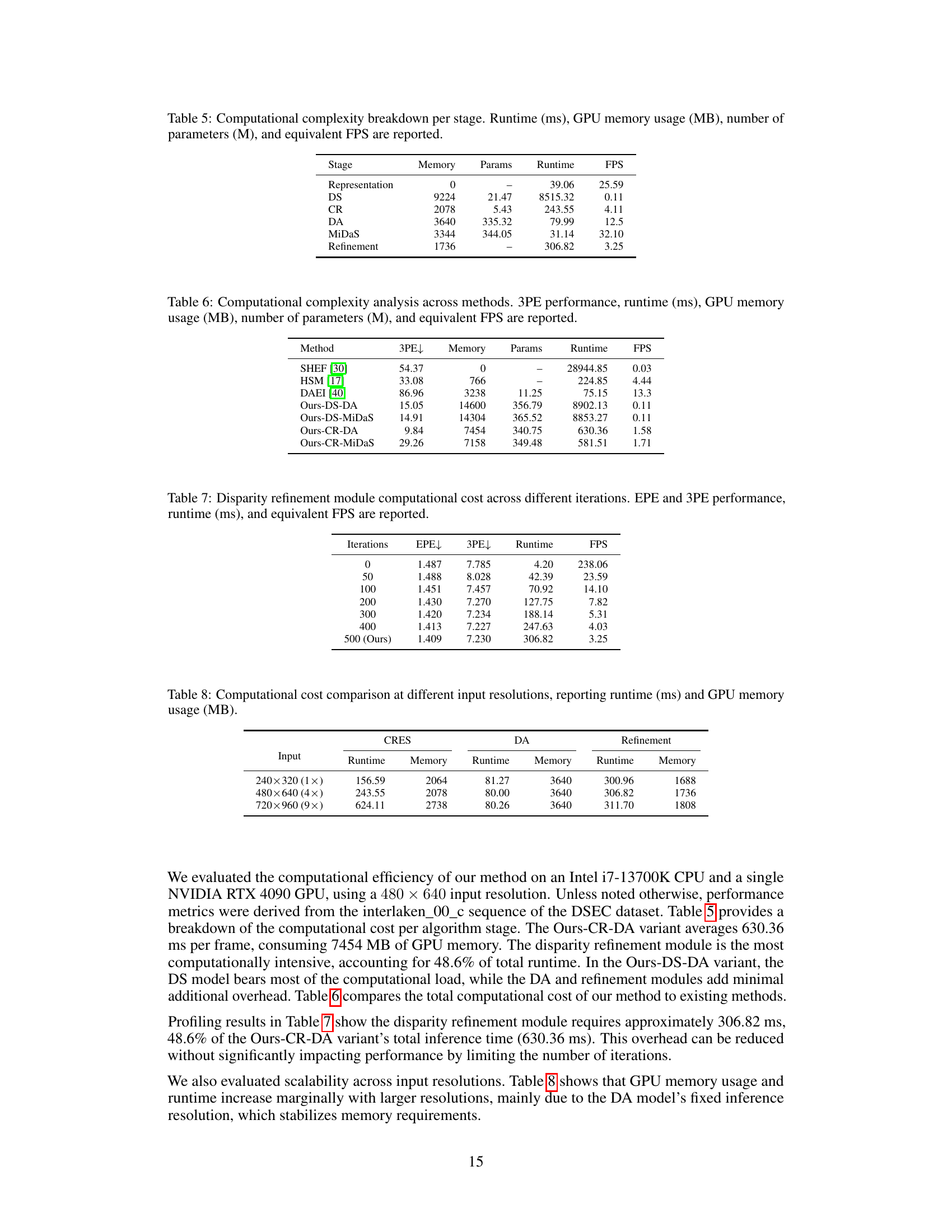
🔼 This table presents the computational cost of the disparity refinement module at various iteration numbers. It shows how the End Point Error (EPE), 3-Pixel Error (3PE), runtime in milliseconds (ms), and frames per second (FPS) change as the number of iterations increases. The final row represents the performance of the proposed Zero-shot Event-intensity asymmetric STereo (ZEST) framework after 500 iterations.
read the caption
Table 7: Disparity refinement module computational cost across different iterations. EPE and 3PE performance, runtime (ms), and equivalent FPS are reported.

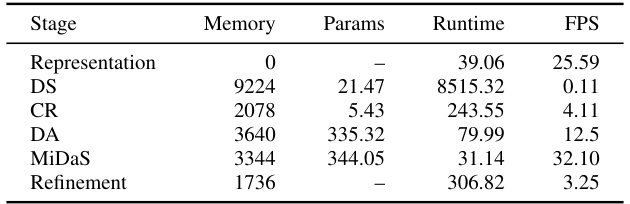
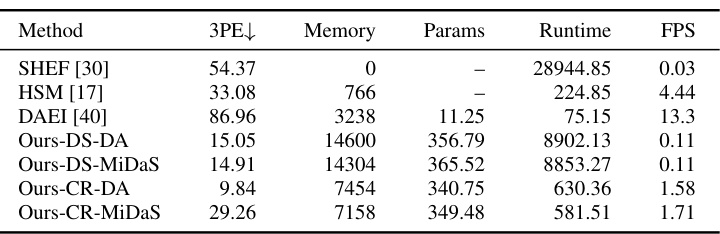
🔼 This table presents a breakdown of the computational complexity for each stage of the proposed ZEST framework. It shows the runtime in milliseconds (ms), GPU memory usage in megabytes (MB), the number of parameters in millions (M), and the equivalent frames per second (FPS) for each stage: Representation, Stereo Model (CR or DS), Monocular Depth Estimation Model (DA or MiDaS), and Refinement. This allows for a detailed analysis of the computational cost associated with each component of the system.
read the caption
Table 5: Computational complexity breakdown per stage. Runtime (ms), GPU memory usage (MB), number of parameters (M), and equivalent FPS are reported.
Full paper#