↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Person representation learning has been significantly challenged by general pre-training methods that neglect crucial person-related characteristics, leading to unsatisfactory performance in person-centric applications. Existing methods often fall short due to their reliance on instance-level analysis and global alignment between cross-modalities, overlooking critical person-specific information like fine-grained attributes and identities.
To overcome these limitations, this paper introduces PLIP, a novel language-image pre-training framework designed for person representation learning. It incorporates three carefully designed pretext tasks: Text-guided Image Colorization, Image-guided Attributes Prediction, and Identity-based Vision-Language Contrast. These tasks effectively capture fine-grained attributes, identities, and cross-modal relationships, resulting in more accurate and discriminative representations. Furthermore, the paper introduces SYNTH-PEDES, a large-scale synthetic dataset to support the pre-training. The results show that PLIP significantly outperforms existing methods in various person-centric tasks and demonstrates strong zero-shot and domain generalization capabilities.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on person representation learning. It introduces a novel pre-training framework, PLIP, along with a large-scale synthetic dataset, SYNTH-PEDES, significantly improving performance on various downstream tasks. This advances the field by addressing the limitations of existing general methods in person-centric applications and opens new avenues for research in zero-shot and domain generalization settings.
Visual Insights#

The figure illustrates the overall framework of the proposed PLIP model. It begins with the creation of a large-scale person dataset (SYNTH-PEDES). This dataset is used to pre-train a language-image model using three pretext tasks: Text-guided Image Colorization, Image-guided Attributes Prediction, and Identity-based Vision-Language Contrast. The resulting pre-trained model is then fine-tuned on various person-centric downstream tasks, including image-based and text-based person re-identification, person attribute recognition, person search, and human parsing.
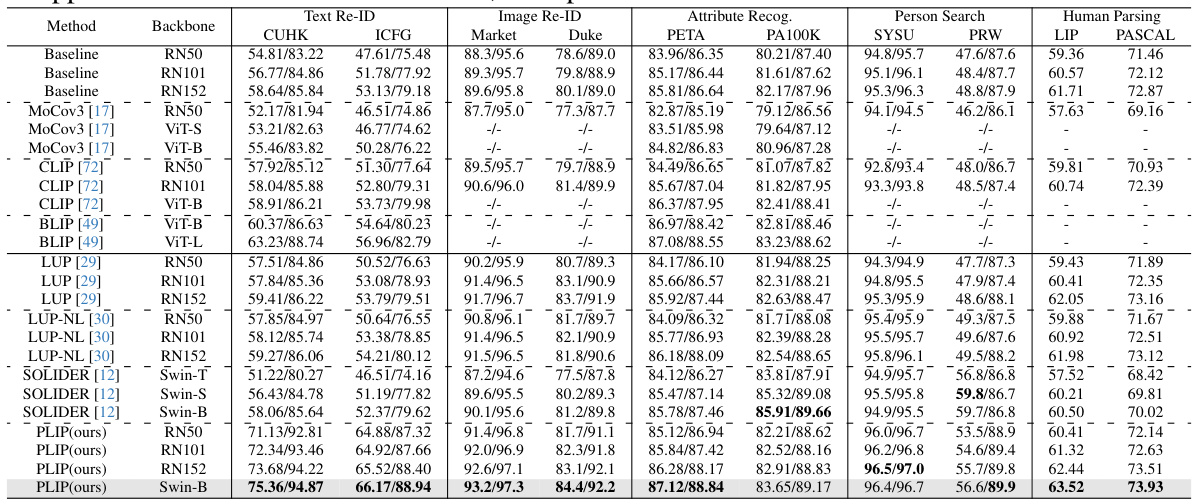
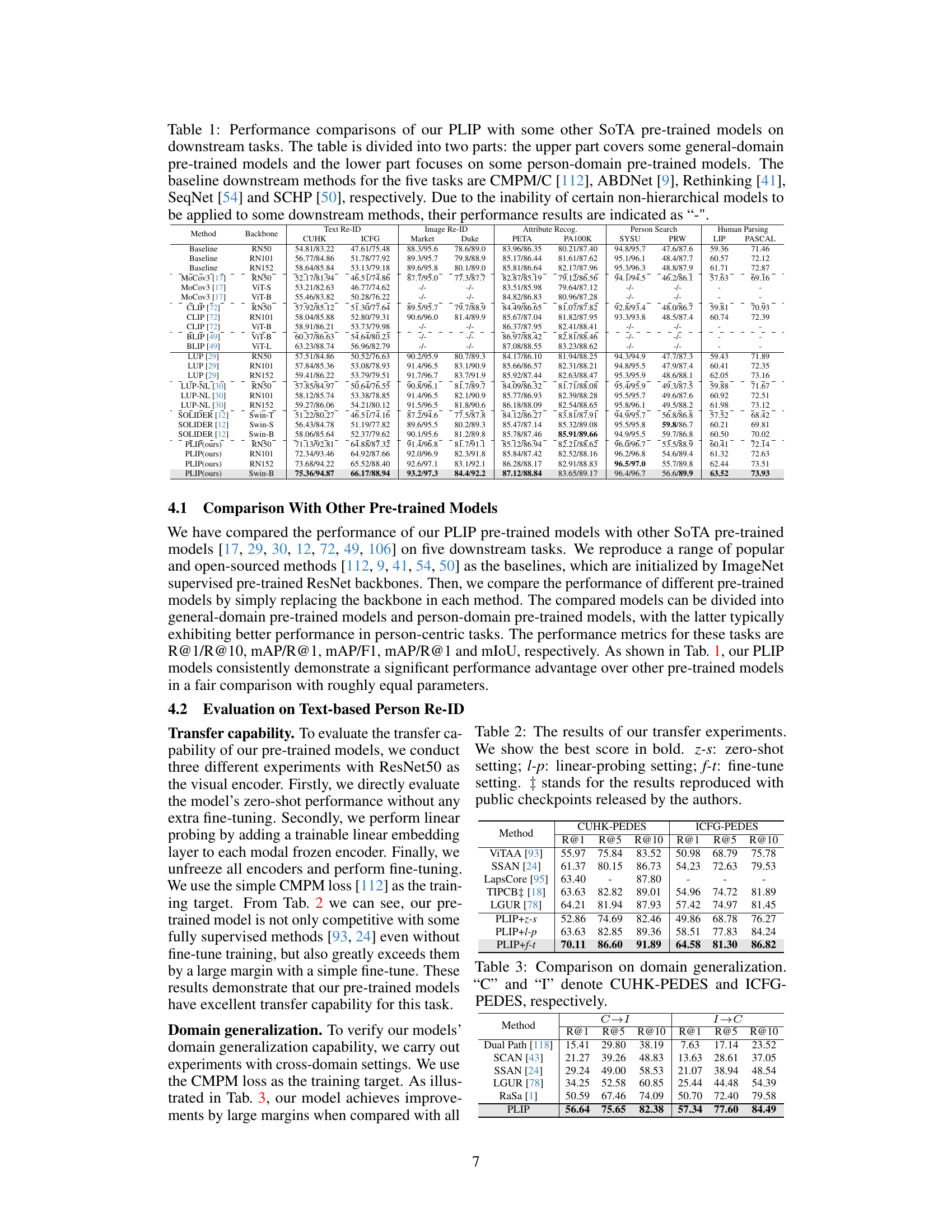
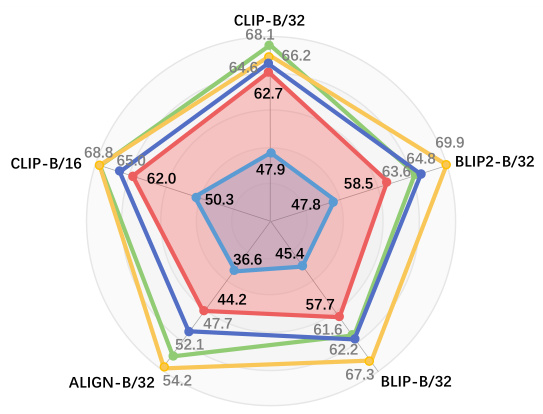
This table compares the performance of the proposed PLIP model with other state-of-the-art (SoTA) pre-trained models on five downstream person-centric tasks: text-based person re-identification, image-based person re-identification, attribute recognition, person search, and human parsing. The table is divided into two sections: one for general-domain pre-trained models and another for person-domain pre-trained models. Baseline methods for each task are listed along with the results. The ‘-’ indicates that some methods are not applicable to all tasks.
In-depth insights#
PLIP: Person Representation#
The heading ‘PLIP: Person Representation’ suggests a research paper focusing on a novel method, PLIP, for learning effective person representations. This likely involves using image and potentially textual data to create robust embeddings that capture person-specific characteristics. The approach likely surpasses general-purpose language-image pre-training methods by incorporating person-centric details like fine-grained attributes and identities, leading to improved performance on downstream tasks. A key innovation might be the pretext tasks designed to explicitly learn and leverage these crucial person characteristics, moving beyond simple global alignment of image-text pairs. The existence of a large-scale dataset, possibly synthetically generated, would be instrumental in training such a model, enabling it to learn rich representations with a high degree of generalizability. Ultimately, the expected outcome would be a significant advancement in performance for diverse person-centric applications such as person re-identification, attribute recognition, and person search. The use of a synthetic dataset suggests a focus on scalability and data availability.
Pre-training Framework#
The pre-training framework is a crucial component of the research paper, focusing on person representation learning using a novel language-image approach. The framework leverages three key pretext tasks: Text-guided Image Colorization, aiming to connect person-related image regions with textual descriptions; Image-guided Attributes Prediction, designed to extract fine-grained attributes from images and text; and Identity-based Vision-Language Contrast, focusing on cross-modal associations at the identity level for enhanced discriminative power. This multi-task framework is intended to address the limitations of existing general language-image pre-training methods that often struggle with person-centric tasks due to neglecting person-specific characteristics. The framework’s design is particularly innovative in its explicit handling of fine-grained attributes and identities, addressing the limitations of instance-level approaches used in prior works. The inclusion of three diverse pretext tasks, aimed at different aspects of person representation, is a strength of the design, suggesting a more comprehensive and robust model.
SYNTH-PEDES Dataset#
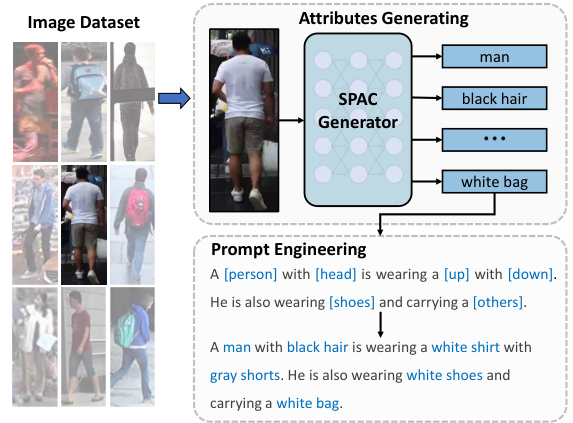
The SYNTH-PEDES dataset represents a substantial contribution to the field of person representation learning. Its large scale, encompassing 312,321 identities, 4,791,711 images, and 12,138,157 textual descriptions, directly addresses the scarcity of large-scale, high-quality image-text paired datasets for person-centric tasks. The methodology employed to create this dataset, using automatic captioning through the SPAC system, is innovative and offers a cost-effective solution to the data bottleneck. The diversification of textual descriptions for each image, coupled with the implementation of noise-filtering and data-distribution strategies, contributes to the high quality of the data. While the synthetic nature of the annotations introduces some limitations, the extensive evaluations comparing SYNTH-PEDES to manually-annotated datasets suggest competitive quality. The dataset’s availability will likely significantly accelerate research and development in the field.
Downstream Tasks#
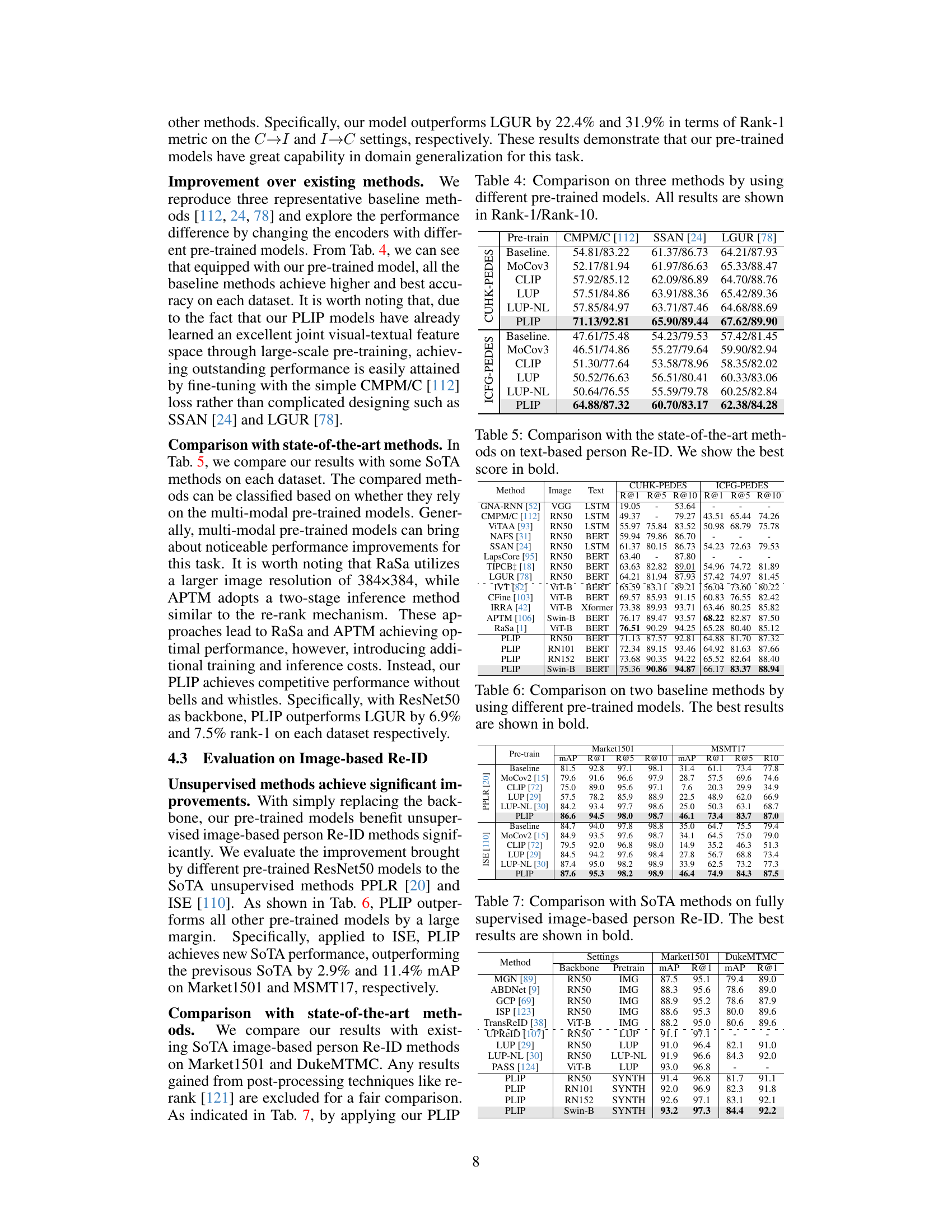
The ‘Downstream Tasks’ section of a research paper is crucial for demonstrating the practical applicability and effectiveness of a proposed model or method. It typically involves evaluating the model’s performance on a range of relevant tasks that directly benefit from the learned representations. These tasks often serve as benchmarks to compare the novel approach against existing state-of-the-art techniques. A comprehensive evaluation across diverse downstream tasks is essential to validate the model’s generalization ability, showcasing its robustness and versatility beyond the specific training data. The choice of downstream tasks is critical; they should be representative of real-world applications and should align with the core contributions of the research. Strong performance on these tasks underscores the model’s potential impact, offering a practical demonstration of its value. The results section should thoroughly analyze performance metrics for each task, providing detailed comparisons and insights into the model’s strengths and weaknesses. Any limitations or challenges encountered in the downstream tasks should be transparently discussed, contributing to a more robust and balanced assessment of the overall methodology.
Future of PLIP#
The future of PLIP (Language-Image Pre-training for Person Representation Learning) looks promising, given its strong performance in person-centric tasks. Future work could focus on enhancing its ability to handle more complex scenarios, such as diverse lighting conditions or occlusions, which currently limit its performance. Expanding the dataset SYNTH-PEDES to include more diverse demographics and clothing styles is crucial to improving generalization and mitigating bias. Investigating different pre-training methods or incorporating alternative modalities (e.g., depth or thermal data) could further improve performance. Exploring the application of PLIP in other domains beyond person re-identification, such as fine-grained person attribute recognition or person search, is also highly relevant. Finally, research into efficient training strategies for PLIP would be valuable given its computationally intensive nature, opening up possibilities for broader adoption and wider use cases.
More visual insights#
More on figures

This figure illustrates the PLIP framework, which incorporates three pretext tasks: text-guided image colorization (TIC), image-guided attributes prediction (IAP), and identity-based vision-language contrast (IVLC). The framework uses a dual-branch encoder structure (visual and textual encoders) to learn generic person representations. TIC aims to restore color to a grayscale person image using textual descriptions, helping the model learn relationships between image regions and textual phrases. IAP predicts masked attribute phrases in a description using color images, enabling understanding of key areas and semantic concepts. IVLC associates representations at the identity level, rather than the instance level, which is crucial for distinguishing different people. The whole process uses a combined loss to train the model, explicitly learning fine-grained and meaningful cross-modal associations.

This figure shows three sets of examples from the SYNTH-PEDES dataset. Each set contains three images of the same person with three different captions describing the person’s attributes and attire. The captions demonstrate the variety and detail of the automatically generated descriptions in SYNTH-PEDES.
This figure illustrates the overall architecture of the PLIP framework. It shows three main pretext tasks: Text-guided Image Colorization (TIC), Image-guided Attributes Prediction (IAP), and Identity-based Vision-Language Contrast (IVLC). The visual and textual encoders are shown, along with the specific processing steps for each task. TIC aims to restore color to a grayscale image guided by text. IAP predicts masked attribute phrases in a textual description using the corresponding image. IVLC links visual and textual representations at the identity level, rather than instance level. The figure demonstrates the dual-branch encoder structure and how the three tasks work together to learn generic and discriminative person representations.

This figure shows the results of a text-guided image colorization task. Multiple rows display the same grayscale person image, but each column represents a different colorization result based on changing a single color word in the corresponding textual description. This demonstrates how the model interprets and applies color information from the text to different image regions.

This figure illustrates the overall framework of the proposed PLIP model. The framework begins with constructing a large-scale dataset of image-text pairs. This dataset is then used to pre-train a language-image model using three different pretext tasks: Text-guided Image Colorization, Image-guided Attributes Prediction, and Identity-based Vision-Language Contrast. Finally, the pre-trained model is transferred to various downstream person-centric tasks such as image-based and text-based re-identification, attribute recognition, person search, and human parsing.
This figure illustrates the overall framework of the proposed PLIP model. It consists of three stages: 1) a large-scale dataset construction stage, where a large-scale person dataset with image-text pairs is created; 2) a language-image pre-training stage, where the language-image model is pre-trained using three pretext tasks; and 3) a downstream task transfer stage, where the pre-trained model is transferred to several person-centric downstream tasks for evaluation. The three pretext tasks are: Text-guided Image Colorization, Image-guided Attributes Prediction, and Identity-based Vision-Language Contrast.
This figure shows the overall architecture of the PLIP framework, which incorporates three pretext tasks: text-guided image colorization (TIC), image-guided attributes prediction (IAP), and identity-based vision-language contrast (IVLC). The visual and textual encoders process the input image and text respectively. The three pretext tasks work together to learn fine-grained and meaningful cross-modal associations for person representation learning. Each task’s processing steps are shown within the framework diagram.
This figure illustrates the PLIP framework, a novel language-image pre-training framework for person representation learning. It shows the three pretext tasks used: Text-guided Image Colorization (TIC), Image-guided Attributes Prediction (IAP), and Identity-based Vision-Language Contrast (IVLC). The framework uses a dual-branch encoder structure (visual and textual encoders) to learn generic person representations by jointly training on these three pretext tasks. The figure also highlights the process of feature extraction, fusion, and prediction for each task.
This figure illustrates the PLIP framework, showing the three pretext tasks used for pre-training: Text-guided Image Colorization (TIC), Image-guided Attributes Prediction (IAP), and Identity-based Vision-Language Contrast (IVLC). It shows the dual-branch encoder structure (visual and textual) and how the three tasks are integrated. The figure highlights the flow of information through the encoders and the fusion of visual and textual features for each task. The overall architecture is designed to learn fine-grained and meaningful cross-modal associations for person representation learning.

The figure provides a visual representation of the PLIP framework, highlighting its three main pretext tasks: text-guided image colorization (TIC), image-guided attribute prediction (IAP), and identity-based vision-language contrast (IVLC). It shows the dual-branch encoder structure of the model, how each pretext task works, and the flow of information between the visual and textual encoders. TIC focuses on restoring color information to grayscale images using textual descriptions. IAP focuses on predicting masked attribute words in the description based on the image. IVLC focuses on contrasting representations at the identity level instead of the instance level. The figure illustrates the overall architecture and the interconnections of the three pretext tasks.
The figure illustrates the PLIP framework, which incorporates three pretext tasks: text-guided image colorization (TIC), image-guided attributes prediction (IAP), and identity-based vision-language contrast (IVLC). TIC aims to restore color information in a grayscale image guided by text. IAP predicts masked attribute phrases in text descriptions given the corresponding image. IVLC aligns visual and textual representations at the identity level to learn more meaningful cross-modal associations. The framework consists of dual-branch encoders (visual and textual) and three pretext task modules. The output of the encoders, representing visual and textual features, is fused for cross-modal learning and downstream tasks.
More on tables
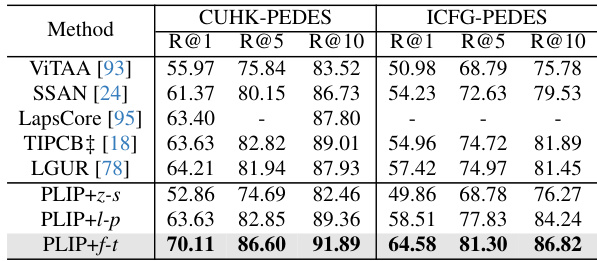
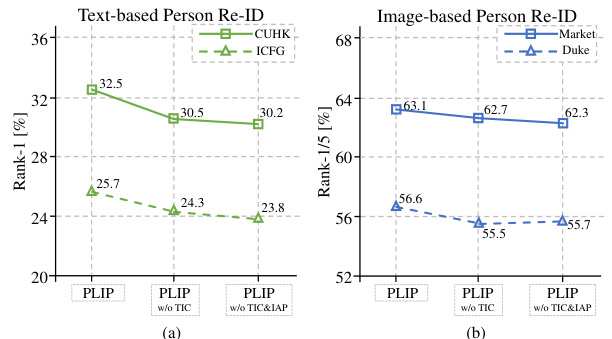
This table presents the results of transfer learning experiments for text-based person re-identification using different settings (zero-shot, linear probing, and fine-tuning). The table compares the performance of the proposed model (PLIP) against state-of-the-art methods (VITAA, SSAN, LapsCore, TIPCB, LGUR) on two benchmark datasets (CUHK-PEDES and ICFG-PEDES). The performance metrics used are Recall@1, Recall@5, and Recall@10.
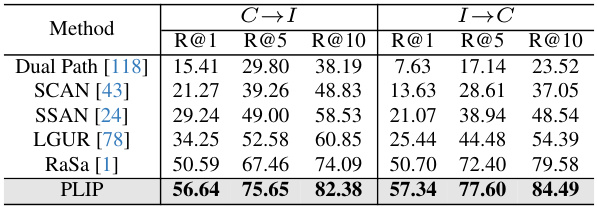
This table presents the results of a domain generalization experiment in text-based person re-identification. Two datasets, CUHK-PEDES (C) and ICFG-PEDES (I), were used. The experiment evaluates the performance of different models when transferring knowledge from one dataset to the other. The results show the Rank-1, Rank-5, and Rank-10 accuracy rates for each model in both cross-domain settings (C→I and I→C). The table highlights the performance of the proposed PLIP model compared to several existing state-of-the-art models.
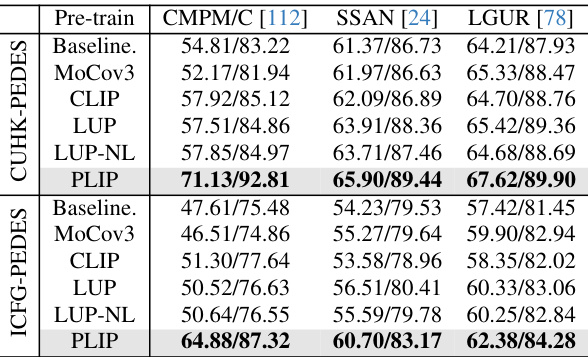
This table compares the performance of the proposed PLIP model against other state-of-the-art (SoTA) pre-trained models on five downstream person-centric tasks: image-based Re-ID, text-based Re-ID, attribute recognition, person search, and human parsing. The table is divided into two sections: the first showing general-domain pre-trained models and the second showing person-domain pre-trained models. Baseline methods for each task are also included, providing context for comparing the performance improvements achieved by using different pre-trained models. Note that some models’ results are marked with a ‘-’ due to incompatibility with certain downstream methods.

This table compares the performance of the proposed PLIP model against other state-of-the-art (SOTA) methods on the task of text-based person re-identification. It evaluates the models on two datasets: CUHK-PEDES and ICFG-PEDES. The table shows the results for various performance metrics including rank-1, rank-5, and rank-10 accuracy. The results highlight the superior performance of PLIP compared to existing methods.

This table compares the performance of the proposed PLIP model against other state-of-the-art (SoTA) methods on two widely used datasets for image-based person re-identification: Market1501 and DukeMTMC. The results showcase the improvements achieved by PLIP on both datasets. Note that results from post-processing techniques (like re-ranking) are excluded to maintain a fair comparison.
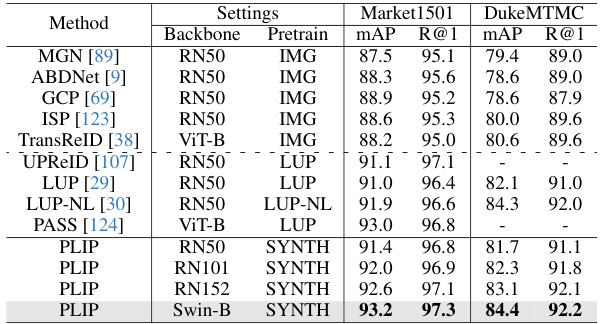
This table compares the performance of the proposed PLIP model against other state-of-the-art (SoTA) methods on two benchmark datasets for image-based person re-identification: Market1501 and DukeMTMC. The table shows the mAP (mean Average Precision) and Rank-1 accuracy for each method, broken down by backbone architecture (e.g., ResNet50, ViT-B, Swin-B) and pre-training method (IMG, LUP, LUP-NL, SYNTH). The results demonstrate that PLIP, particularly with Swin-B backbone and SYNTH pre-training, significantly outperforms SoTA methods.
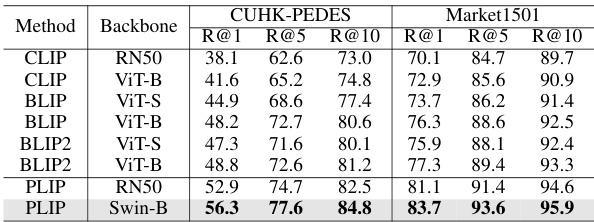
This table compares the performance of the proposed PLIP model with other state-of-the-art (SoTA) methods on text-based person re-identification. The comparison includes both methods that rely on multi-modal pre-trained models and methods that do not. The results are presented for different metrics (R@1, R@5, R@10) on multiple datasets (CUHK-PEDES and ICFG-PEDES). The table highlights that PLIP consistently outperforms other methods, especially those not using multi-modal pre-trained models.
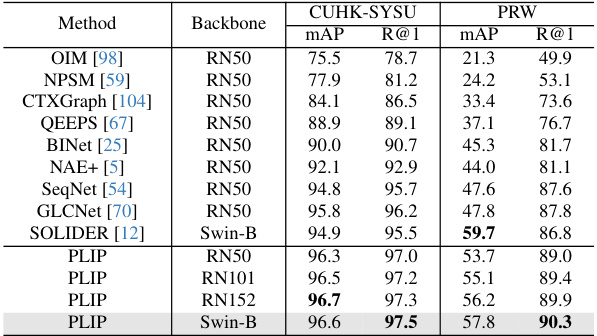
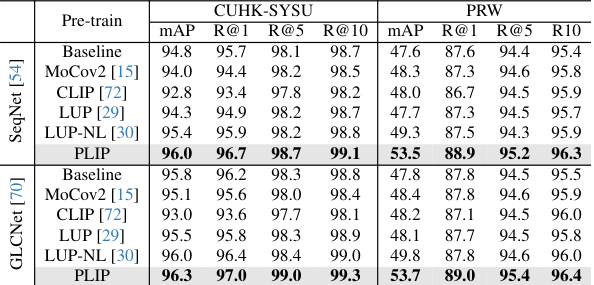
This table compares the performance of the proposed PLIP model against other state-of-the-art (SoTA) methods on two person search benchmark datasets: CUHK-SYSU and PRW. The results are shown for two metrics: mean Average Precision (mAP) and Rank@1. PLIP consistently outperforms prior SoTA methods, demonstrating its effectiveness for person search tasks.

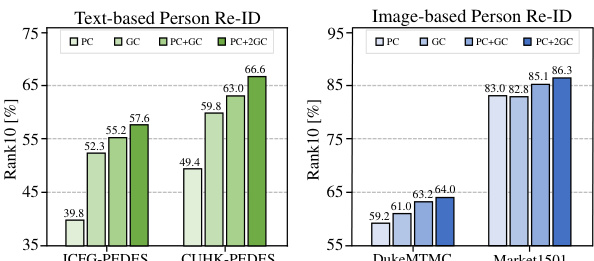
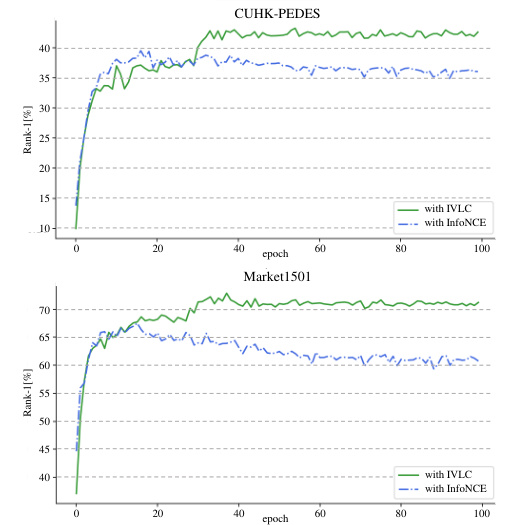
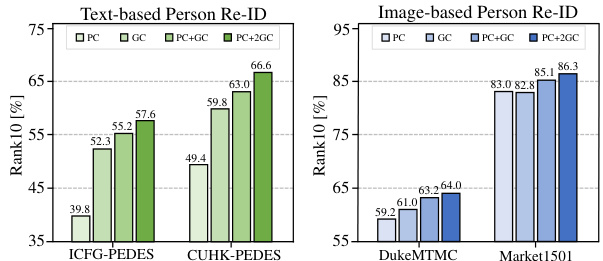
This ablation study investigates the individual and combined effects of the three pretext tasks (IVLC, TIC, and IAP) on the performance of the PLIP model. It shows the zero-shot performance (R@1, R@5, R@10) on the CUHK-PEDES and Market1501 datasets for different combinations of the pretext tasks, demonstrating their individual and combined contributions to the overall model performance.

This table compares the performance of the proposed PLIP model with other state-of-the-art (SoTA) pre-trained models on five downstream person-centric tasks: image-based Re-ID, text-based Re-ID, attribute recognition, person search, and human parsing. It’s divided into two sections: general-domain pre-trained models and person-domain pre-trained models. The baseline methods used for each task are also specified. Some models are not applicable to all tasks due to their hierarchical or non-hierarchical nature, indicated by a ‘-’ in the table.
This table compares the statistics of several existing person re-identification datasets, including the number of images, identities, descriptions, camera type, label type, labeling method, and crop size. It highlights that the proposed SYNTH-PEDES dataset is significantly larger than other datasets, containing a much greater number of images, identities, and textual descriptions, while not requiring manual annotation.

This table compares the performance of the proposed PLIP model with other state-of-the-art (SoTA) pre-trained models on five downstream person-centric tasks: image-based Re-ID, text-based Re-ID, attribute recognition, person search, and human parsing. The table is divided into two sections: general-domain pre-trained models and person-domain pre-trained models. For each task, baseline methods are listed, and the performance (e.g., mAP, Rank-1) of each pre-trained model is shown. Some baselines are not applicable to all models, resulting in ‘-’ entries.

This table presents the ablation study results on the impact of each pretext task (IVLC, TIC, IAP) in the proposed PLIP framework. It shows the performance (R@1, R@5, R@10) on two person re-identification benchmarks, CUHK-PEDES and Market1501, under different combinations of the pretext tasks. Row 1 shows results with only IVLC; Row 2 adds TIC; Row 3 adds IAP. Row 4 shows only using TIC and IAP, and Row 5 uses all three pretext tasks. This demonstrates the contribution of each component to the overall performance.

This table presents the results of a manual evaluation comparing the quality of the SYNTH-PEDES dataset to three other manually annotated datasets (CUHK-PEDES, ICFG-PEDES, RSTPReid) and one synthetic dataset (FineGPR-C). The evaluation used a five-point scale, assessing aspects like correctness and detail in the textual descriptions of images. SYNTH-PEDES demonstrates comparable quality to the manually annotated datasets, despite its significantly larger size, and outperforms the synthetic dataset.

This ablation study analyzes the impact of different choices in the training process of the PLIP model. Specifically, it investigates the effect of different training objectives for the IVLC and TIC pretext tasks, explores the influence of varying prediction difficulty levels (controlled by a function G(x)), and examines the impact of different pooling methods for combining visual and textual features. The results show the relative importance of each component and help to optimize the model’s performance.

This table presents the results of experiments conducted to find the optimal hyperparameters for the overall objective function used in the PLIP model. The objective function is a combination of three loss functions (IVLC, TIC, and IAP), and the table shows the performance (R@1, R@5, R@10) on the CUHK-PEDES and Market1501 datasets for various combinations of the hyperparameters λ₁ and λ₂. The results demonstrate the impact of different weighting schemes on the overall performance of the model, indicating that a particular combination yields the best performance.
This table compares the performance of the PLIP pre-trained model against other state-of-the-art (SoTA) pre-trained models on five downstream person-centric tasks: image-based re-identification, text-based re-identification, attribute recognition, person search, and human parsing. The table is divided into two sections: the first compares general-domain pre-trained models, and the second compares person-domain pre-trained models. Baseline methods for each task are listed, and the performance (metrics vary by task) of each model using different backbones (e.g., ResNet50, ResNet101, etc.) is shown. Dashes indicate when a model could not be applied to a particular task.

This table presents the results of domain generalization experiments for text-based person re-identification. The model’s performance is evaluated on two datasets, CUHK-PEDES (C) and ICFG-PEDES (I), with each model tested on both datasets as the target domain, given a source dataset for training. This assesses the model’s ability to generalize to unseen domains. The metrics used to evaluate performance are R@1, R@5, and R@10.

This table compares the performance of different pre-trained models (MoCov2, CLIP, LUP, LUP-NL, and PLIP) when used with two baseline person attribute recognition methods (Rethink and DeepMAR). It shows the improvement in mean accuracy (mA), accuracy (Acc), recall (Rec), and F1-score for both the PA100k and PETA datasets. The results demonstrate that the PLIP pre-trained model significantly improves the performance of both baseline methods.

This table compares the performance of the proposed PLIP model against other state-of-the-art (SoTA) methods on the task of human parsing. Two datasets are used for evaluation: LIP and PASCAL-Person-Part. The table shows the mean Intersection over Union (mIoU) metric, a common evaluation metric for semantic segmentation tasks like human parsing. Different backbone networks are used for the models. The results demonstrate that PLIP achieves competitive or superior performance compared to SoTA methods.
Full paper#