↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating high-quality images at various resolutions is a challenging task in AI. Existing transformer-based diffusion models suffer from high computational costs and limitations in handling varying resolutions and aspect ratios. Convolutional neural networks (CNNs) offer a more efficient alternative, but their ability to handle diverse resolutions needs improvement.
This paper introduces FlowDCN, a purely convolutional generative model designed for fast and efficient image generation at arbitrary resolutions. FlowDCN utilizes a novel group-wise multiscale deformable convolution block to enhance flexibility and resolution handling capabilities. Experiments demonstrate that FlowDCN achieves state-of-the-art FID scores on ImageNet benchmarks, outperforming transformer-based methods in both speed and visual quality. Furthermore, FlowDCN shows comparable performance in handling unseen resolutions. The work provides a promising solution for scalable and flexible image synthesis.
Key Takeaways#
Why does it matter?#
This paper is important because it presents FlowDCN, a novel and efficient model for arbitrary-resolution image generation that outperforms existing methods in terms of speed, scalability, and visual quality. Its purely convolutional design offers a compelling alternative to transformer-based approaches, opening new avenues for research in efficient and flexible image synthesis. The results are significant for researchers working on large-scale image generation and applications requiring high-resolution image synthesis.
Visual Insights#

This figure showcases the model’s ability to generate images at various resolutions. Four example images are shown, demonstrating that a single model can produce high-quality outputs regardless of aspect ratio or pixel dimensions. The images were all created using the same FlowDCN-XL/2 model trained with a 256x256 resolution ImageNet dataset and a Classifier Free Guidance (CFG) value of 4.0.

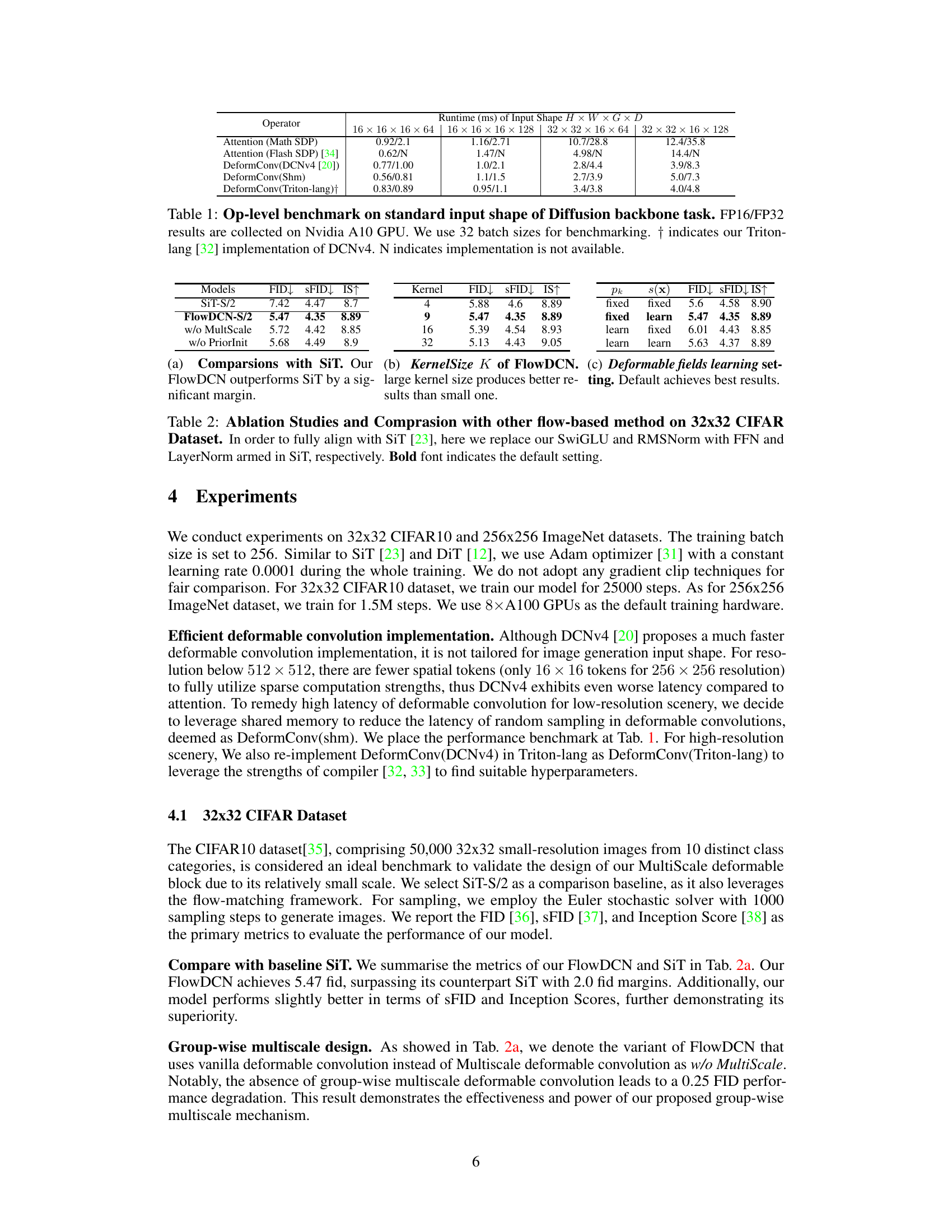
This table compares the runtime performance of different operators (Attention, Deformable Convolution) with various input shapes and precisions (FP16, FP32) on an Nvidia A10 GPU. It highlights the computational efficiency of different approaches for the diffusion model backbone task. The results show that Deformable Convolution using Triton-lang offers a good balance between speed and efficiency compared to other approaches.
In-depth insights#
FlowDCN’s Design#
FlowDCN’s design is centered around efficiency and scalability for arbitrary resolution image generation. It cleverly departs from transformer-based diffusion models by employing a purely convolutional architecture, specifically leveraging group-wise multiscale deformable convolutions. This choice directly addresses the quadratic complexity of attention mechanisms, resulting in linear time and memory complexity. The decoupling of scale and direction prediction within the deformable convolution block enhances flexibility and control over feature aggregation at multiple scales. This innovative block, combined with the use of SwiGLU and RMSNorm, contributes to improved visual quality and faster convergence. The design also incorporates a simple yet effective Scale Adjustment mechanism for seamless resolution extrapolation, enabling the generation of high-quality images at various resolutions using a single model. The overall architecture prioritizes computational efficiency without sacrificing image quality, positioning FlowDCN as a compelling alternative to existing methods.
Arbitrary Resolution#
The ability to generate images at arbitrary resolutions is a significant advancement in image synthesis. Traditional methods often struggle with scaling, requiring separate models or complex adaptations for different resolutions. This paper tackles this limitation by designing a model architecture that inherently handles varying resolutions efficiently. This is achieved through the use of convolutional neural networks, which naturally possess the capability to work with various input sizes. The model’s strength lies in its ability to extrapolate well to unseen resolutions, avoiding the need for retraining. The proposed approach contrasts with transformer-based methods that often suffer from quadratic computational complexity when dealing with larger resolutions. This makes the new model faster and more memory-efficient. The results demonstrate the model’s effectiveness in generating high-quality images at various resolutions, showcasing a clear improvement over existing methods in image synthesis.
MultiScale DCN#
The proposed MultiScale DCN is a novel architecture designed to enhance the capabilities of traditional deformable convolutional networks (DCNs) for image generation tasks, particularly focusing on handling arbitrary resolutions. It elegantly addresses limitations of standard DCNs by decoupling the deformable field into scale and direction components. This decoupling allows for more precise control over the receptive field, enabling the network to effectively aggregate features from both local and distant regions. A key innovation is the group-wise application of multiple scale priors, allowing different groups of convolutional filters to operate at different scales. This multi-scale approach is particularly beneficial for image generation, where preserving fine-grained details while capturing global context is crucial. The design allows efficient multi-scale feature aggregation, and enhanced flexibility in handling varying resolutions without the need for substantial architectural modifications or retraining. This design choice improves efficiency and potentially contributes to better performance, especially when handling diverse image resolutions. The effectiveness of this method is demonstrated through various experiments and comparisons with other approaches, showcasing its advantage in achieving superior results with improved efficiency.
Experimental Results#
A thorough analysis of the experimental results section requires examining the metrics used, the datasets employed, the comparisons made to existing methods, and the statistical significance of the findings. The choice of metrics directly impacts the interpretation of results; are they appropriate for the task? The datasets should be carefully evaluated for suitability and potential biases; are they representative and sufficiently large? Comparisons must be made to relevant, state-of-the-art baselines using identical evaluation protocols. Finally, and crucially, the results’ statistical significance needs assessment; are error bars provided, and do they indicate confidence in the results? Addressing these aspects offers a comprehensive evaluation of the experimental results’ validity and reliability.
Future Work#
The authors of the FlowDCN paper acknowledge several key areas for future work. Improving the efficiency of the deformable convolution backward pass is paramount, as current implementations lag behind attention mechanisms in training speed. Scaling the model to handle larger parameter sizes and higher resolutions will require substantial optimization, enabling even more detailed and high-fidelity image generation. Exploring alternative training techniques, such as those incorporating varied aspect ratios, is likely to further improve performance, especially in the context of arbitrary resolution generation. Finally, a thorough investigation into the limitations and potential biases inherent in their approach is necessary to ensure the responsible and ethical deployment of this technology. This future work roadmap suggests a clear path towards a more robust, efficient, and versatile image generation model.
More visual insights#
More on figures
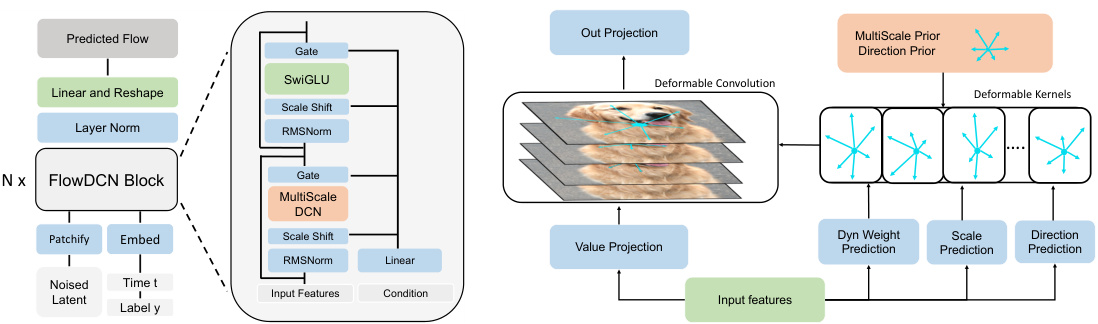
This figure shows the architecture of FlowDCN and its core component, the MultiScale DCN block. FlowDCN is a purely convolutional generative model consisting of stacked MultiScale DCN blocks and SwiGLU blocks, using RMSNorm for training stability. The MultiScale DCN block uses dynamic weights and scale/direction deformable fields predicted from input features, combined with priors to create deformable kernels. The block shows how the deformable kernels are used to extract features, highlighting the multiscale approach of the model. The diagram illustrates the flow of data through the model, from the input features (including noisy latent, time step t, and label y) to the final predicted flow.

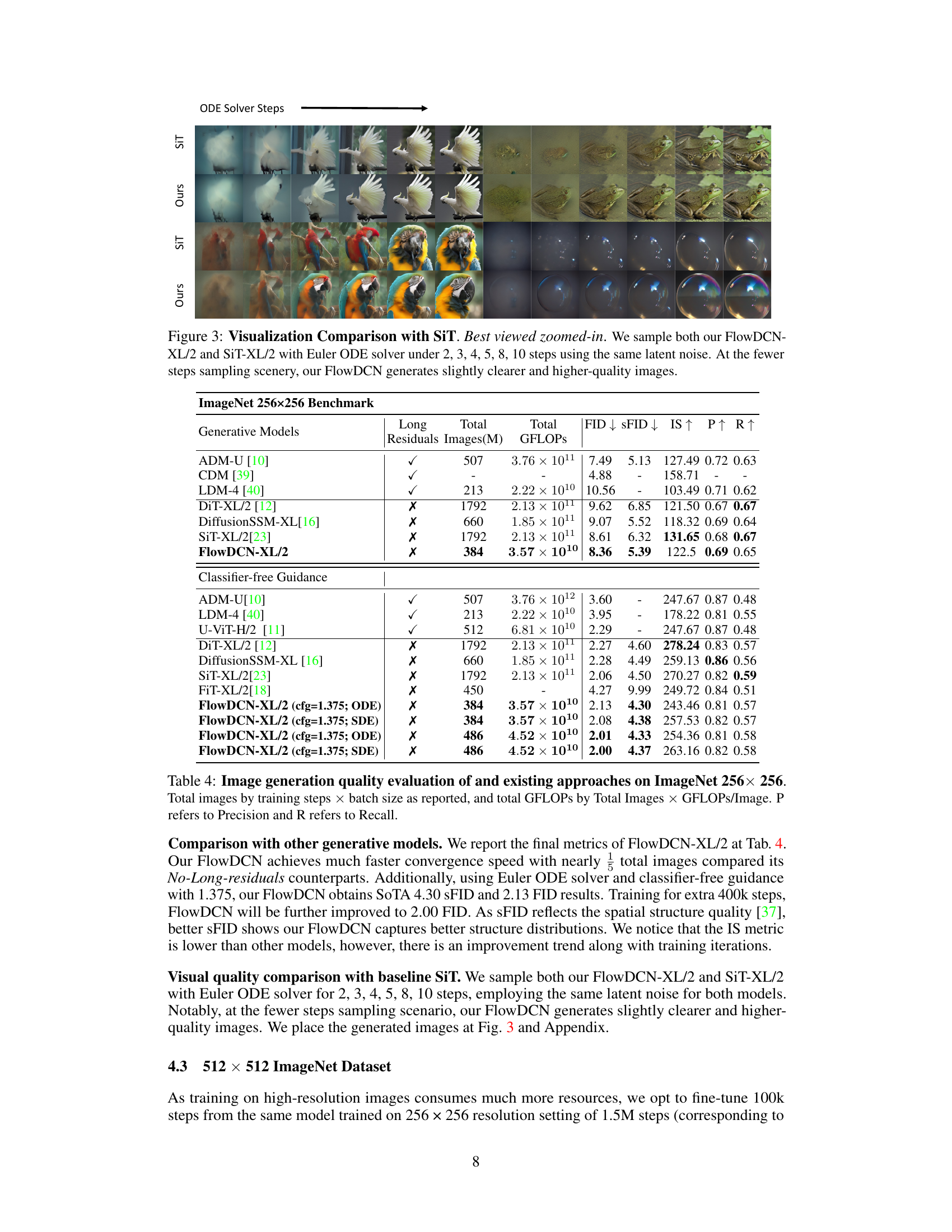
This figure compares the image generation results of FlowDCN-XL/2 and SiT-XL/2 models at different sampling steps (2, 3, 4, 5, 8, 10) using the Euler ODE solver. The same latent noise was used for both models. The images show that FlowDCN produces clearer and higher-quality images, especially at lower sampling step counts.

This figure compares image generation results with and without the proposed Smax Adjustment technique for arbitrary resolution. Three different image resolutions (512x512, 256x512, 512x256) are shown, with the left side demonstrating images generated using Smax Adjustment and the right side showing images generated without it. The use of the same latent noise and Euler SDE solver parameters highlights the impact of Smax Adjustment on image quality and consistency.
More on tables

This table presents ablation studies and a comparison of FlowDCN with other flow-based methods on the CIFAR-10 dataset. It shows the impact of different design choices in FlowDCN, such as using multi-scale deformable convolutions and the initialization of prior values. The comparison with SiT helps highlight FlowDCN’s performance improvement.
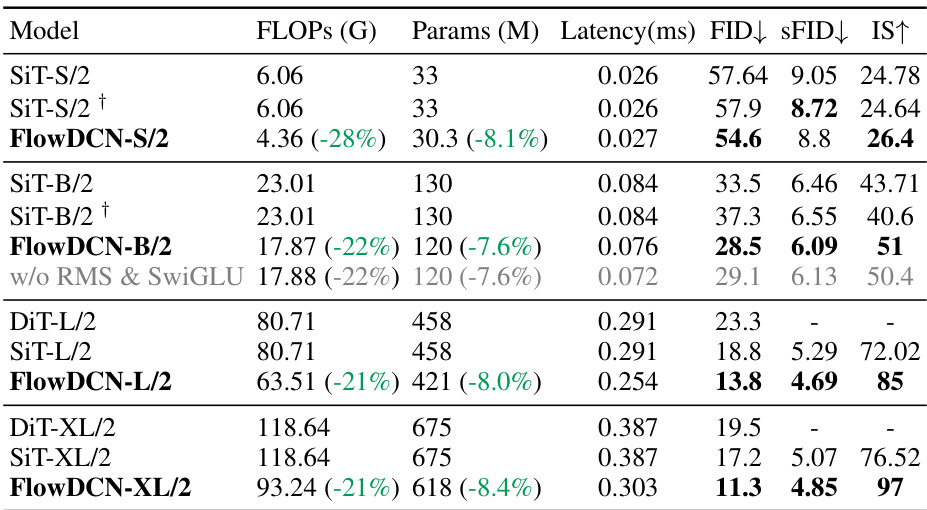
This table presents a comparison of image generation metrics (FLOPs, parameters, latency, FID, sFID, IS) for different models (SiT-S/2, SiT-S/2+, FlowDCN-S/2, SiT-B/2, SiT-B/2+, FlowDCN-B/2, w/o RMS & SwiGLU, DiT-L/2, SiT-L/2, FlowDCN-L/2, DiT-XL/2, SiT-XL/2, FlowDCN-XL/2) trained with 400k steps. It highlights FlowDCN’s superior performance in terms of FID, sFID, and IS while using significantly fewer FLOPs and parameters compared to the SiT and DiT models. The table also shows the impact of removing RMS and SwiGLU from the FlowDCN architecture.
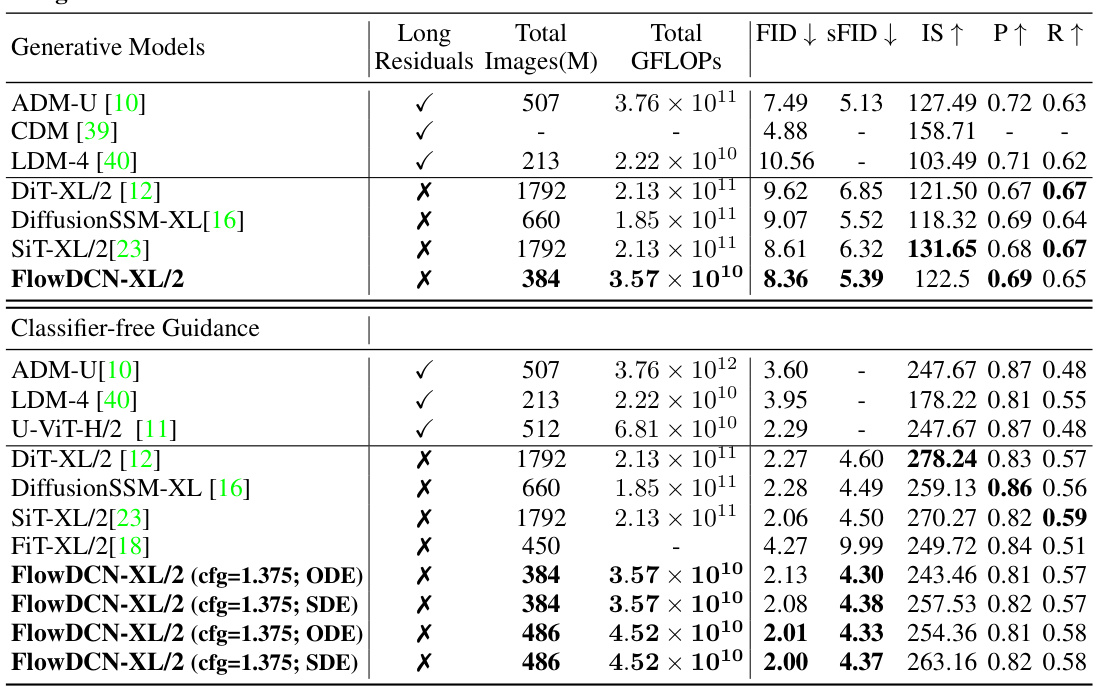
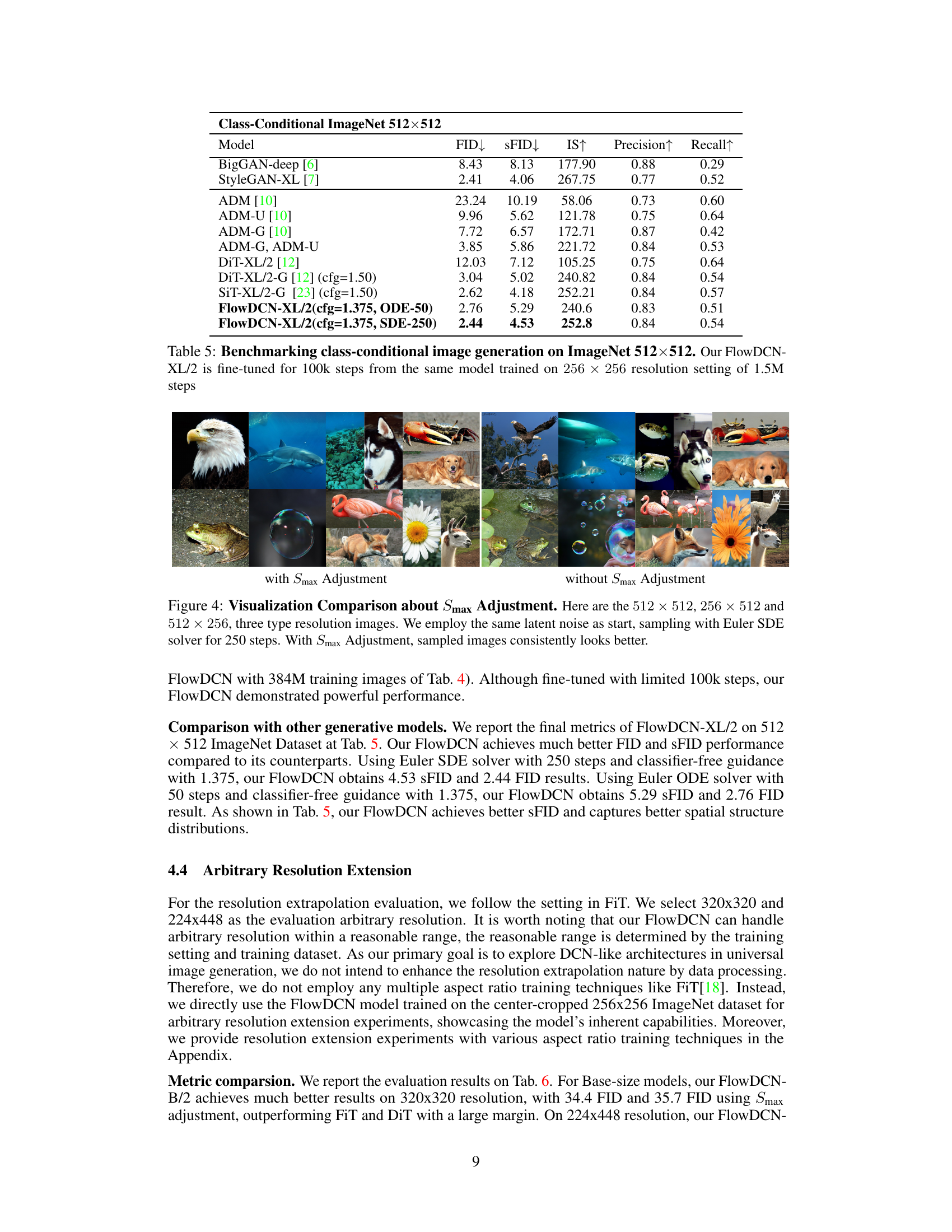
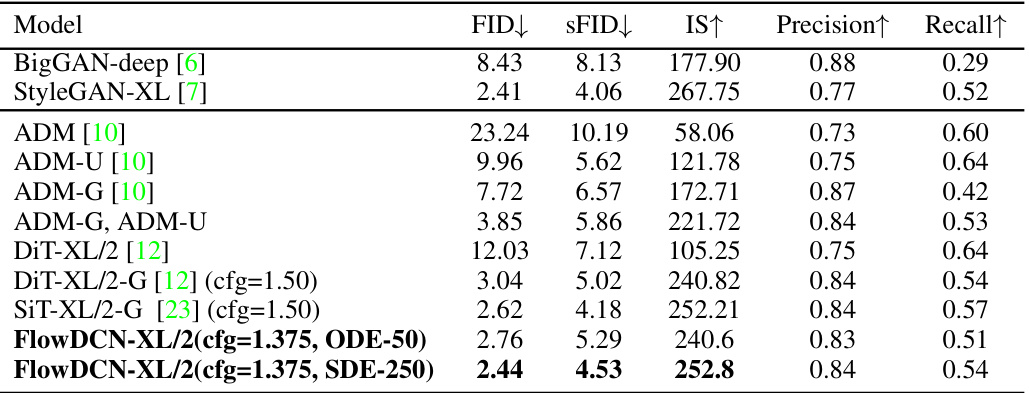
This table compares the performance of FlowDCN-XL/2 with other generative models on the ImageNet 256x256 benchmark. Metrics include FID, sFID, Inception Score (IS), Precision (P), and Recall (R). The table shows that FlowDCN-XL/2 achieves state-of-the-art results, particularly with classifier-free guidance, demonstrating superior image quality and efficiency compared to existing methods. The total number of images generated and total GFLOPS are also provided for each model, highlighting FlowDCN’s computational efficiency.
This table presents a comparison of the performance of various generative models on the ImageNet 512x512 dataset, focusing on class-conditional image generation. It shows FID, sFID, Inception Score (IS), Precision, and Recall for different models, including the authors’ FlowDCN-XL/2 model and several state-of-the-art baselines. The results highlight the performance of FlowDCN-XL/2 in comparison to other models.
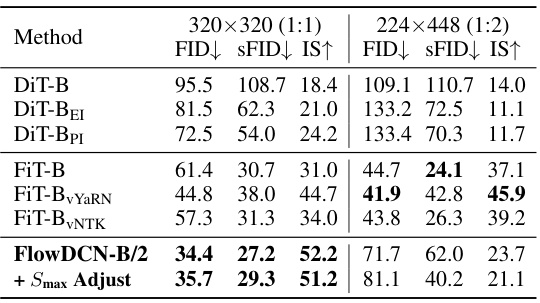
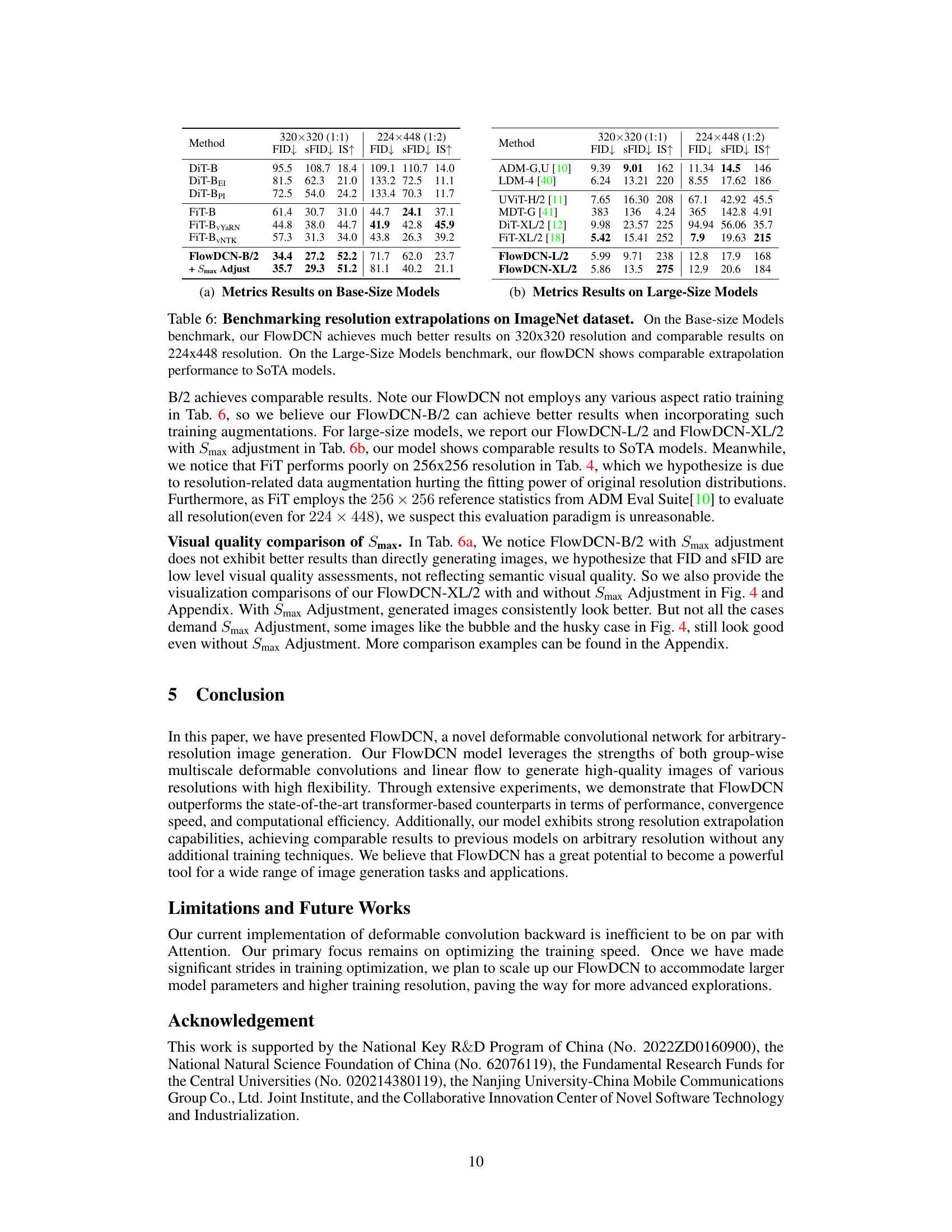
This table presents a comparison of different models’ performance on resolution extrapolation tasks for ImageNet. Two different resolutions are tested: 320x320 (1:1 aspect ratio) and 224x448 (1:2 aspect ratio). The models are evaluated using FID, sFID, and IS metrics. The table is split into two sections for base-size and large-size models. The FlowDCN model, with and without Smax adjustment, demonstrates competitive results against state-of-the-art (SoTA) models, particularly at the 320x320 resolution.
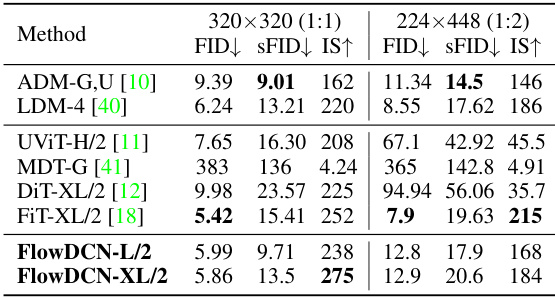
This table presents a comparison of different models’ performance on resolution extrapolation tasks using the ImageNet dataset. Two resolutions are tested: 320x320 and 224x448. The metrics used for comparison are FID (Fréchet Inception Distance), sFID (a variant of FID focusing on spatial structure), and IS (Inception Score). The table shows that FlowDCN achieves better or comparable results to state-of-the-art (SoTA) models, particularly for the 320x320 resolution. The results are broken down by model size (base and large).

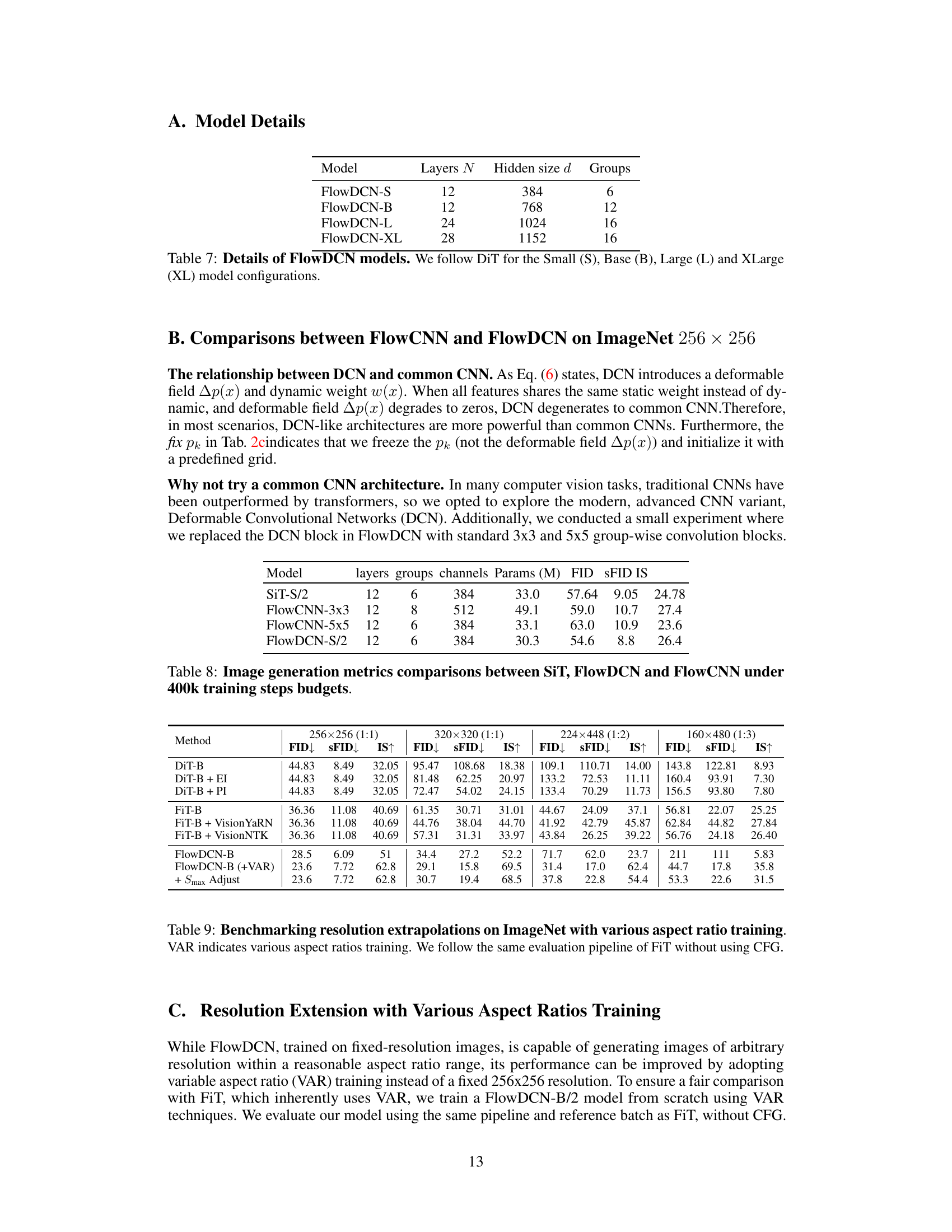
This table presents the architectural details of the FlowDCN models. It shows the number of layers (N), the hidden size (d), and the number of groups used in each of the four different sizes of FlowDCN models: Small, Base, Large, and XLarge. The naming and sizing conventions for these models are consistent with those used in the DiT model in the related work.
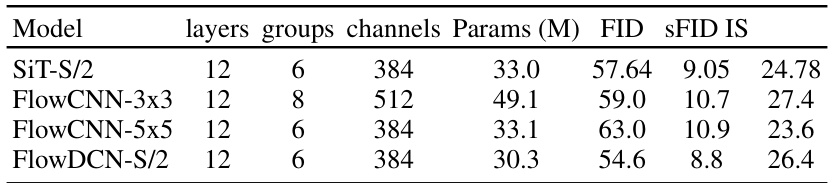
This table compares the performance of three different models: SiT-S/2, FlowCNN-3x3, FlowCNN-5x5, and FlowDCN-S/2 on the CIFAR-10 dataset. The metrics used for comparison are FID, sFID, and IS. All models were trained for 400k steps. The table shows that FlowDCN-S/2 outperforms both FlowCNN models and achieves comparable results to SiT-S/2 in terms of FID and sFID. This suggests that the use of deformable convolutions in FlowDCN can improve the performance of image generation models.
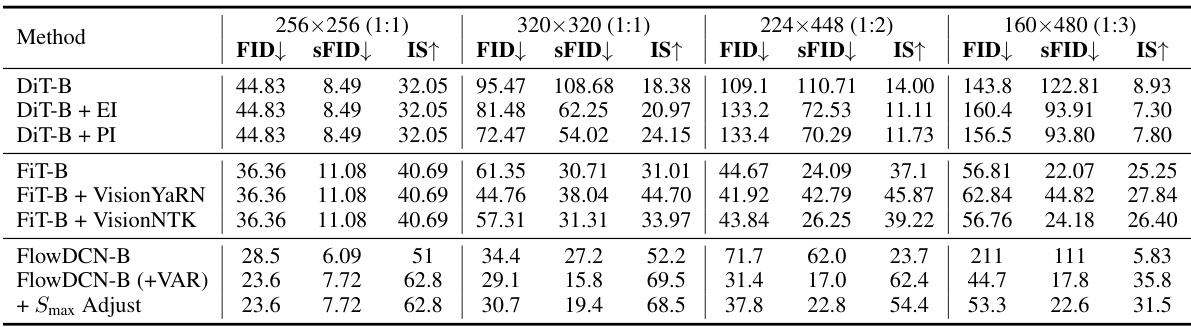
This table presents a comparison of the FID, sFID, and IS scores for different models on various resolutions of the ImageNet dataset. It highlights the performance of FlowDCN, comparing it against other state-of-the-art (SoTA) models and showcasing its ability to generate images with different aspect ratios, demonstrating its capability for arbitrary resolution image generation. The table is separated into base-size and large-size models and shows results for 320x320, 224x448, and 160x480 image resolutions.
Full paper#