↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but can memorize sensitive information, raising concerns about privacy and safety. Unlearning, the process of removing unwanted knowledge from an LLM, is challenging due to the large model size and the potential for damaging unintended knowledge removal. Current methods often involve computationally expensive retraining or fine-tuning, which hinders their application on state-of-the-art models.
This paper introduces Embedding-Corrupted (ECO) Prompts, a novel unlearning framework. Instead of directly modifying the LLM, ECO prompts use a classifier to identify prompts containing unwanted information. These flagged prompts are then ‘corrupted’ via modifications to their embeddings, learned offline via optimization. This approach achieves effective unlearning at nearly zero side effects across numerous LLMs, ranging from 0.5B to 236B parameters, without increasing computational costs. The superior efficiency and scalability of ECO offers a promising solution to the unlearning challenge for real-world LLM applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM safety and responsible AI, offering a novel, efficient, and scalable solution to the challenging problem of unlearning. Its focus on prompt manipulation rather than model retraining opens exciting avenues for future research in this critical area.
Visual Insights#

This figure illustrates the ECO (Embedding-Corrupted) Prompts framework for large language model unlearning. It shows a two-step process: First, a prompt classifier determines if an incoming prompt is within the scope of knowledge to be forgotten. Second, if the classifier flags the prompt for unlearning, the prompt embedding is corrupted using a learned corruption function (parameterized by σk) before being fed into the model. This corruption is learned offline via zeroth-order optimization. The figure highlights that this process does not involve updating the original LLM weights; instead, it modifies the input at inference time to achieve the unlearning effect. The difference between the original output and the unlearned output is displayed to emphasize the result of applying the corrupted prompt.
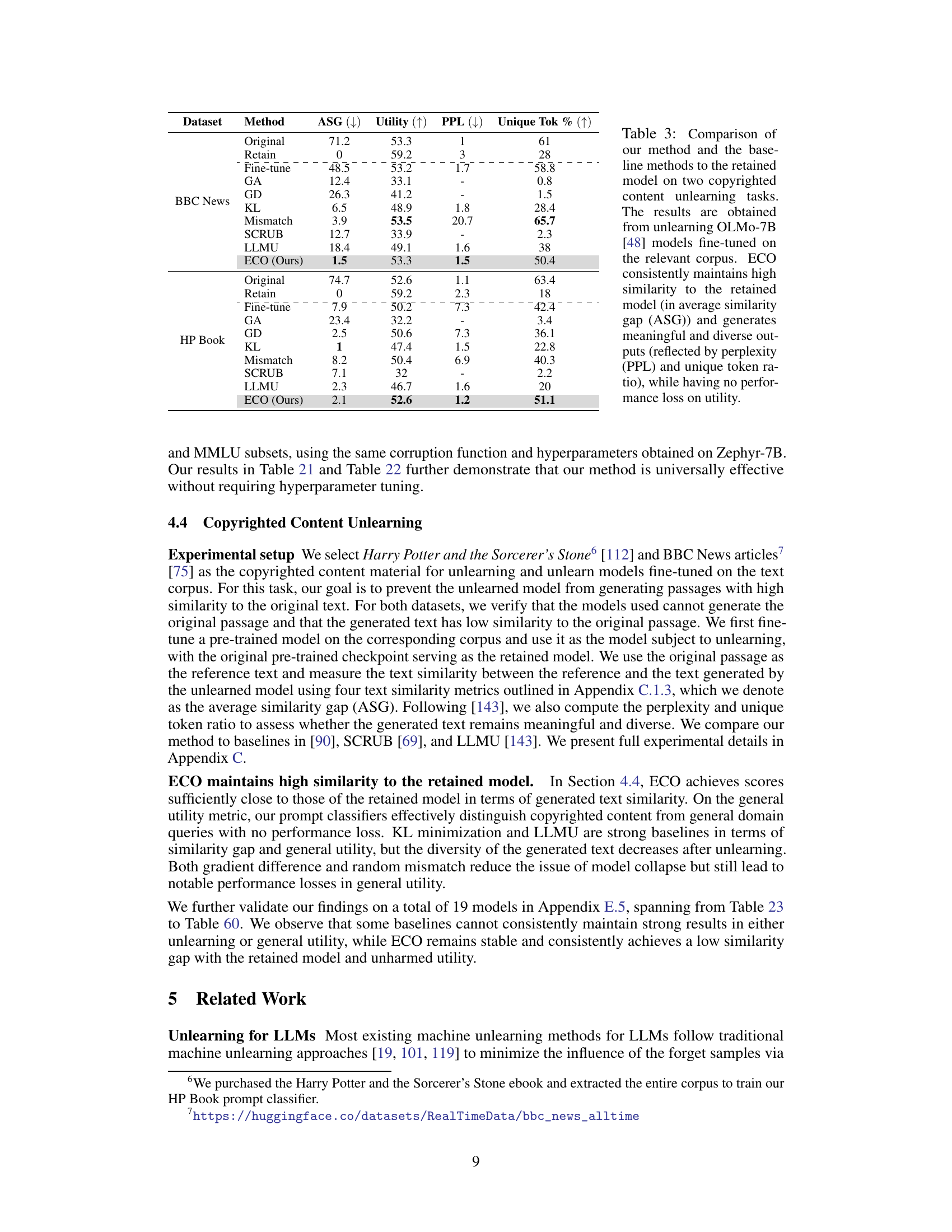
This table presents the multiple-choice accuracy results for five different large language models (LLMs) on two benchmark datasets: WMDP (for unlearning) and MMLU (for retaining knowledge). The table compares the performance of several unlearning methods: original model, prompting, RMU, and the proposed ECO method. For each model, it shows the accuracy on four sub-tasks of WMDP and the overall accuracy on the MMLU dataset. The results demonstrate ECO’s effectiveness in achieving near random-guessing accuracy on the WMDP (unlearning) task while maintaining performance on the MMLU (retaining knowledge) task, outperforming other baseline methods which often suffer from either low unlearning effectiveness or a significant drop in MMLU performance.
In-depth insights#
ECO Prompt Method#
The ECO Prompt method is a novel approach to large language model (LLM) unlearning that focuses on manipulating prompts during inference rather than modifying model weights. This lightweight method avoids the computational cost and potential risks associated with retraining or fine-tuning large models. It functions by first employing a prompt classifier to identify whether incoming prompts fall under the scope of the data intended for unlearning. If flagged, these prompts are selectively corrupted in their embedding space using a learned corruption function, preventing unwanted outputs. The use of a classifier enhances the system’s efficiency and reduces the risk of unintended side effects, particularly in managing knowledge entanglement. This approach significantly reduces collateral damage and offers a practical solution for efficient and effective unlearning in LLMs, demonstrated by its scalability across various model sizes without additional cost. The offline learning of corruption parameters improves both efficiency and precision. This technique holds immense promise for promoting responsible and safe usage of LLMs by offering a robust yet minimally invasive unlearning approach.
Unlearning Threat Model#
A robust unlearning threat model for large language models (LLMs) must consider various attack vectors. Adversarial attacks, aiming to manipulate the model into revealing sensitive information, are crucial. These could involve carefully crafted prompts designed to elicit specific responses or exploit vulnerabilities in the unlearning process itself. Data poisoning, where malicious data is injected into the training or unlearning datasets to compromise the model’s integrity, presents another significant risk. Furthermore, the model’s architecture itself could be a source of weakness, susceptible to attacks targeting specific parameters or layers to circumvent the unlearning mechanism. Implementation weaknesses in the unlearning algorithm can be exploited, leading to incomplete removal of sensitive data or unintentional side effects. A comprehensive threat model needs to evaluate these risks across different model architectures and unlearning strategies to enhance the safety and reliability of LLMs.
Zeroth-Order Opt.#
Zeroth-order optimization, in the context of embedding-corrupted prompts for large language model (LLM) unlearning, offers a computationally efficient alternative to traditional gradient-based methods. Instead of directly calculating gradients, which are expensive for large LLMs, it estimates the impact of small changes to the prompt embeddings on the model’s output. This is particularly useful for unlearning because it avoids the need for computationally demanding backpropagation. The offline learning phase of this approach is crucial; here, the optimal corruption parameter is determined before interacting with the model, eliminating any additional cost during inference. The strategy offers a compelling way to induce forgetting without directly modifying the model’s weights, thus reducing the risk of catastrophic interference and enabling scalability to massive LLMs. However, this approach has inherent limitations such as the accuracy of the zeroth-order approximation and its dependence on a well-trained prompt classifier.
LLM Unlearning Tasks#
LLM unlearning tasks present a significant challenge in aligning AI with human values and safety. Effective unlearning necessitates the ability to selectively remove knowledge from large language models (LLMs) without causing unintended side effects or degrading overall performance. These tasks can be categorized into various types, each requiring different strategies to address their unique challenges. For instance, entity unlearning aims to remove sensitive information about specific individuals, hazardous knowledge unlearning focuses on eliminating harmful or misleading information, while copyrighted content unlearning tackles the removal of data subject to intellectual property rights. Each task demands precise control and rigorous evaluation methods to ensure that the intended knowledge is successfully removed without compromising the utility of the LLM for other purposes. The development of robust and reliable unlearning techniques is crucial for establishing trust and promoting the responsible deployment of LLMs.
ECO Limitations#
The ECO method, while promising for LLM unlearning, has limitations. It only works with models accessible via APIs, relying on a classifier and a corruption function, making it vulnerable to adversaries with direct model access. The prompt classifier’s accuracy is critical, and a compromised classifier could lead to ineffective unlearning or unintended information removal. The method’s reliance on a limited context window in the prompt classifier might allow attackers to bypass the system using carefully crafted prompts. The need for a task-specific surrogate metric (ûr) limits generalizability, necessitating a task-agnostic method. Finally, the method’s reliance on prompt corruption rather than direct weight modification raises concerns about its efficacy for certain tasks and the potential for unintended collateral damage to the model’s general functionality.
More visual insights#
More on figures
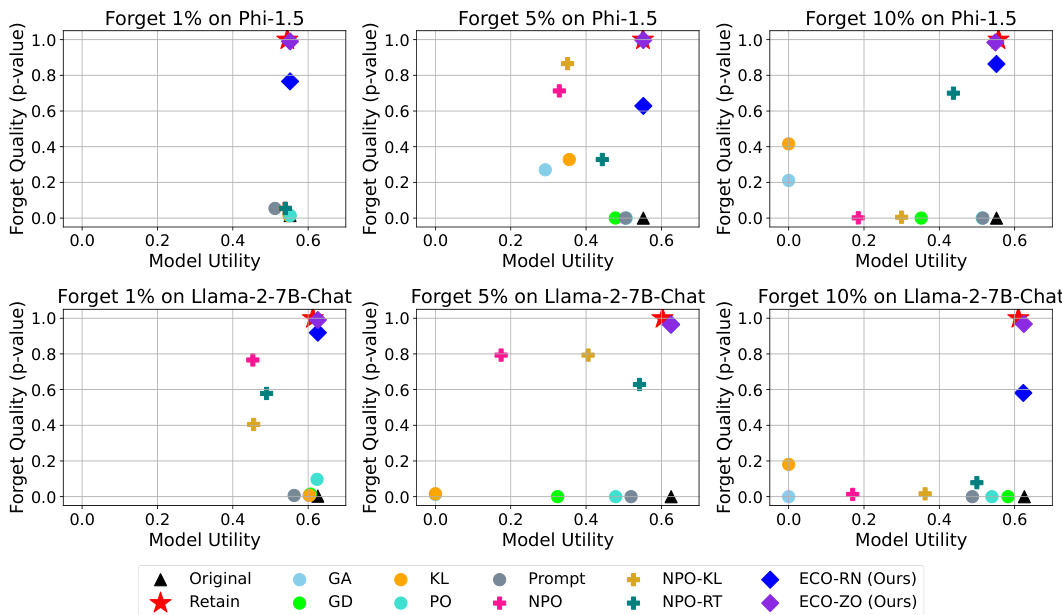
This figure shows the trade-off between model utility and forget quality for two different LLMs (Phi-1.5 and Llama-2-7B-Chat) after unlearning different percentages (1%, 5%, and 10%) of the TOFU dataset. It compares the performance of the ECO method to several baseline unlearning methods (GA, GD, KL, PO, Prompting, NPO, NPO-KL, NPO-RT). The plot demonstrates that ECO achieves high forget quality with no loss in model utility, unlike most baseline methods which either fail to forget sufficiently or suffer significant utility loss.

This figure illustrates the ECO framework for large language model unlearning. It shows how a prompt classifier first identifies whether a given prompt should be forgotten (i.e., falls within the scope of the unlearning target). If it should be forgotten, the framework selectively corrupts dimensions within the tokens’ embeddings using a corruption function learned offline (through zeroth-order optimization). This corruption results in an output resembling the model’s response had it never been trained on the data to be forgotten. Crucially, this method does not require updating the LLM’s weights, just manipulating inputs during the inference stage.

This figure illustrates the ECO prompt unlearning framework. It shows how a classifier determines if a prompt should be unlearned, and if so, how corruption is applied to the prompt embedding before input to the LLM. This corruption prevents the model from recalling information without requiring any changes to its internal weights.

This figure shows the relationship between the number of parameters in a language model and its performance on two benchmarks (WMDP and MMLU) after applying an unlearning technique. The x-axis represents the number of parameters, and the y-axis shows the average accuracy. It visualizes data from Tables 21 and 22, demonstrating how the unlearning method’s effectiveness changes as model size increases.
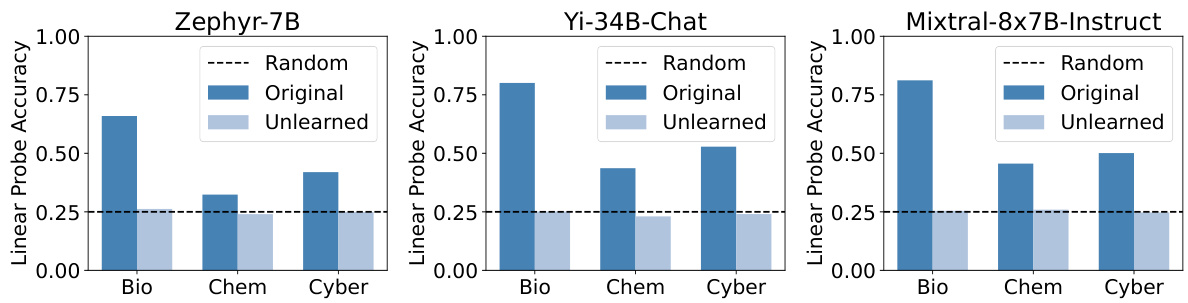
This figure shows the results of probing experiments using linear probes trained on the logits of three different LLMs: Zephyr-7B, Yi-34B-Chat, and Mixtral-8x7B-Instruct. The goal was to assess the model’s ability to prevent knowledge recovery after applying ECO (Embedding-Corrupted Prompts) unlearning. The x-axis represents the three sub-categories of the WMDP (Winning at Machine Deception Prediction) benchmark dataset (Bio, Chem, Cyber). The y-axis represents the accuracy of the linear probe. The dashed line indicates random chance. The figure demonstrates that before unlearning (Original), the probes achieve relatively high accuracy. After unlearning with ECO (Unlearned), however, the accuracy drops to near random chance, indicating that ECO successfully prevents the extraction of sensitive information directly from the model’s logits.

This figure illustrates the ECO (Embedding-Corrupted) prompts method for unlearning in LLMs. It shows a two-step process: first, a classifier determines if an incoming prompt is related to the target knowledge to be forgotten; second, if it is, the prompt’s embedding is corrupted using a learned corruption function before being fed to the LLM. This corruption is learned offline and doesn’t require any changes to the LLM’s weights, creating an ‘unlearned state’ during inference. The figure visually depicts the flow of the prompt through the classifier, the corruption function, and finally into the LLM to generate an unlearned output.
More on tables

This table presents the multiple-choice accuracy results for the Zephyr-7B model on three MMLU subsets (economics, law, physics) and their corresponding retain sets (econometrics, jurisprudence, math) after applying different unlearning methods: original model, prompting baseline, RMU, and ECO. The results show the effectiveness of ECO in achieving near-perfect forgetting (accuracy close to random guessing) on the forget subsets while maintaining the original performance on the retain subsets. In contrast, the prompting baseline negatively impacts accuracy on forget subsets, and RMU achieves good forgetting but with a significant decrease in accuracy on retain subsets.
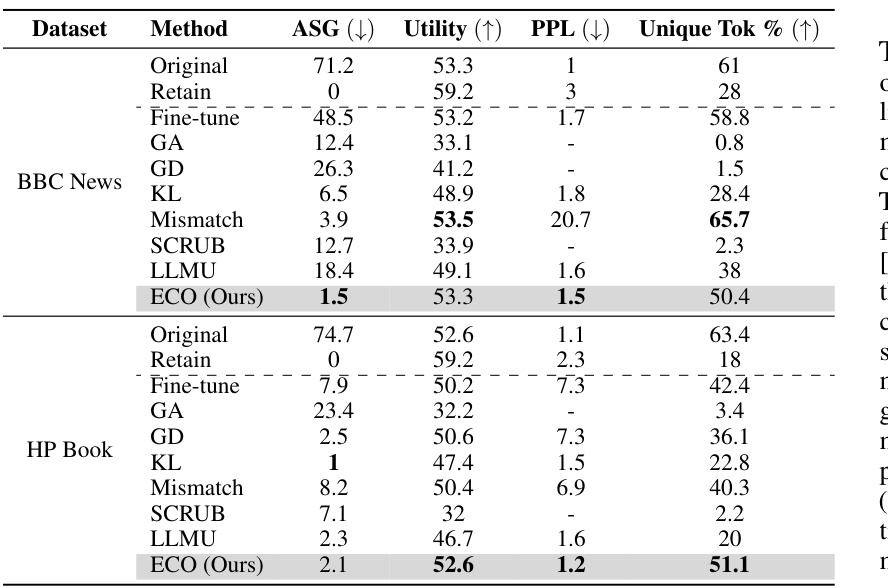
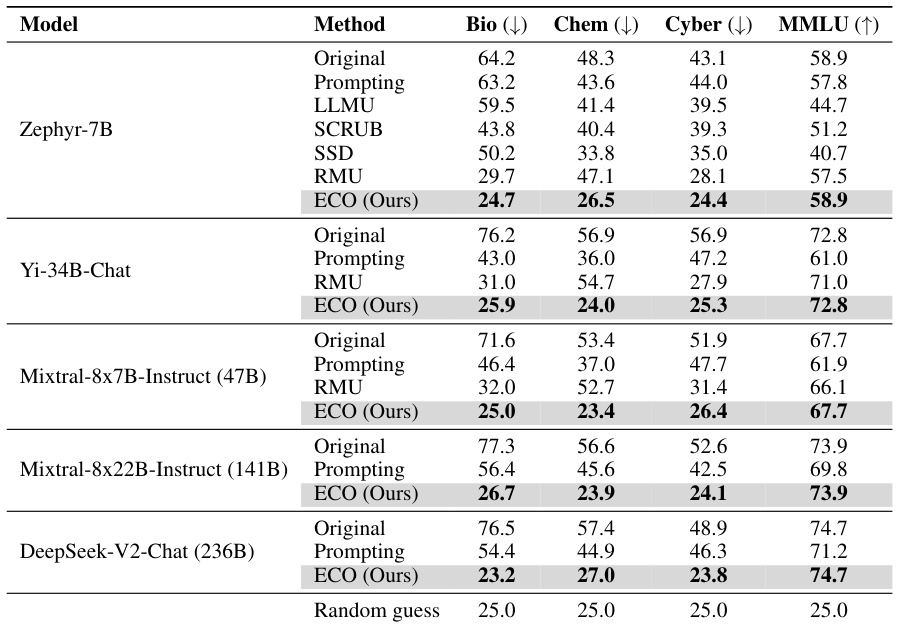
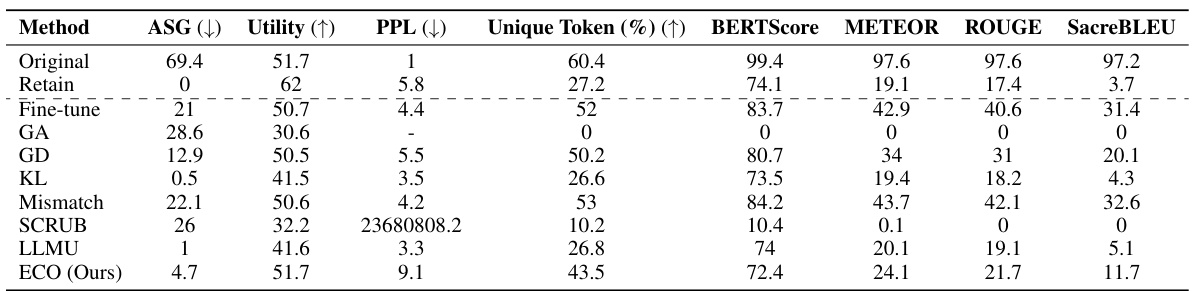
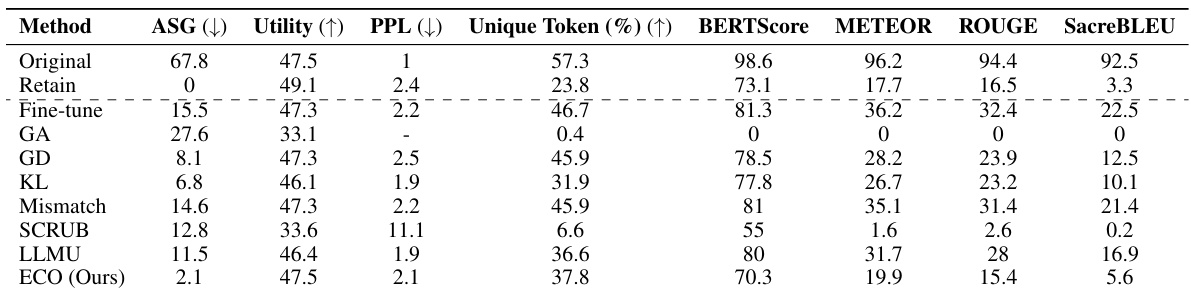
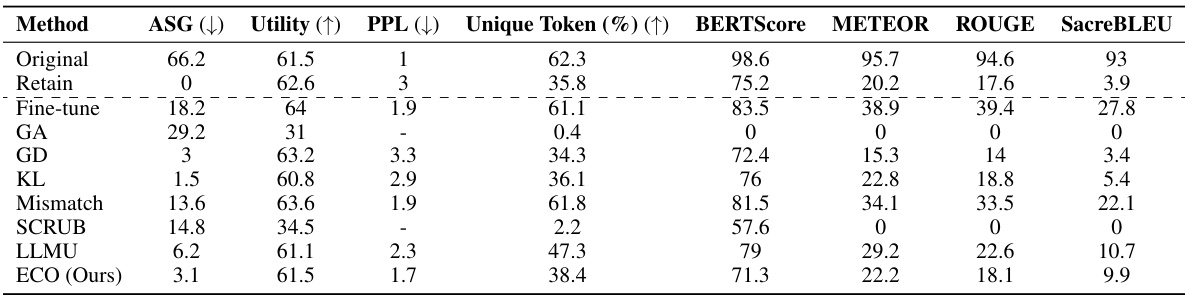
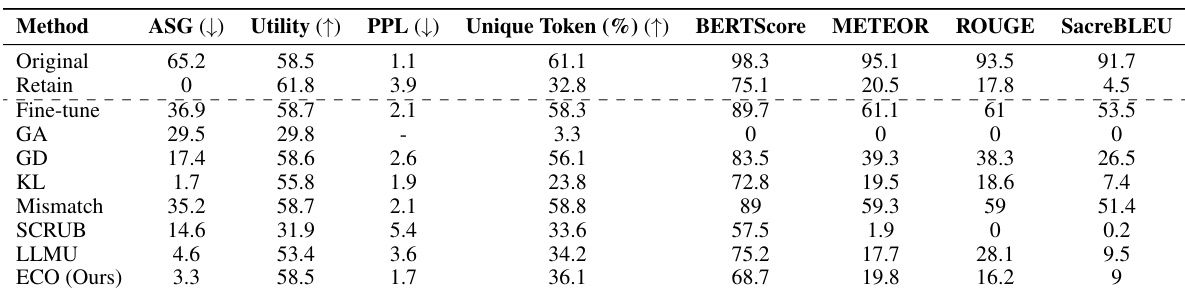
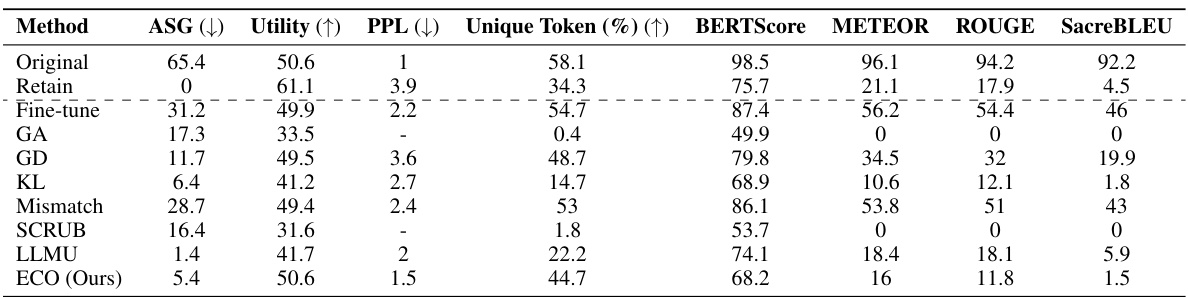
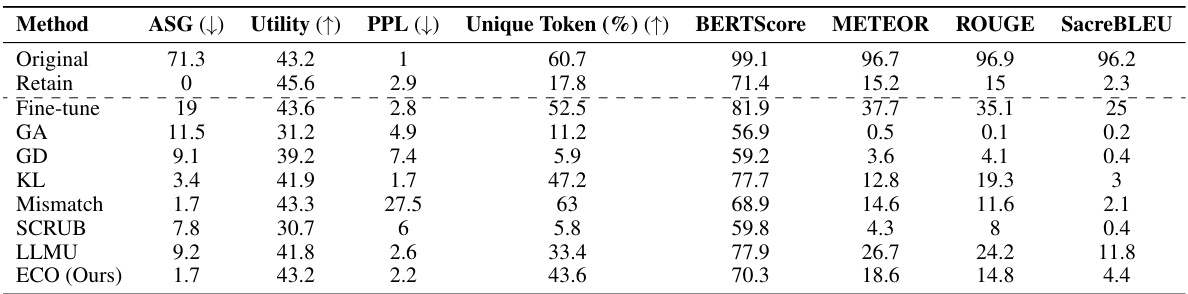
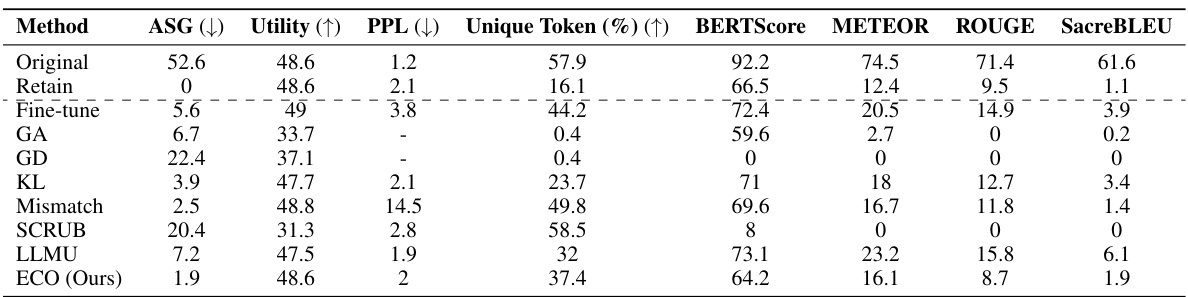
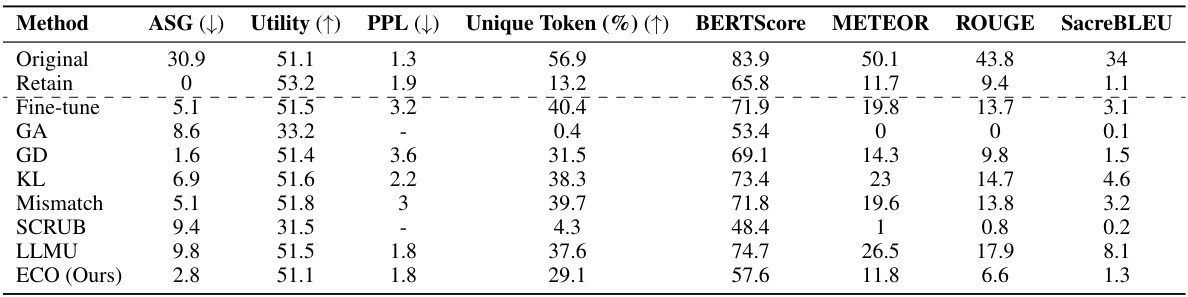
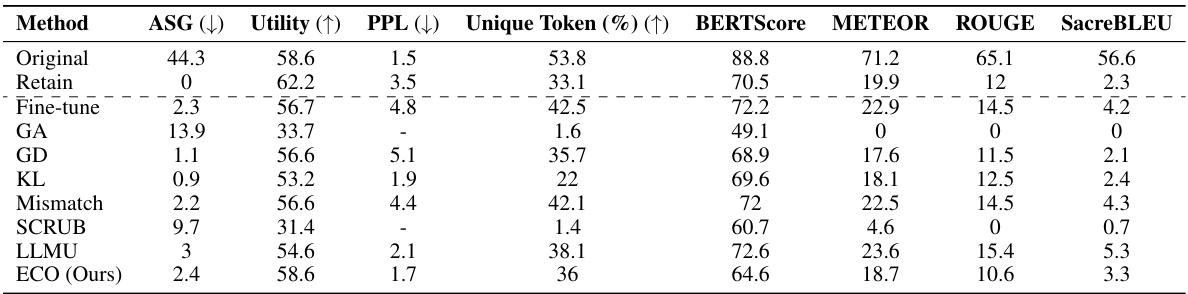
This table compares the performance of the proposed ECO method against various baseline methods on two copyrighted content unlearning tasks: BBC News and Harry Potter. The comparison is done using metrics focusing on similarity to a model that hasn’t seen the forgotten data (average similarity gap, ASG), generation quality (perplexity, PPL, unique tokens), and utility (performance on general tasks). The results demonstrate ECO’s ability to maintain high similarity to the retained model while achieving good unlearning performance.
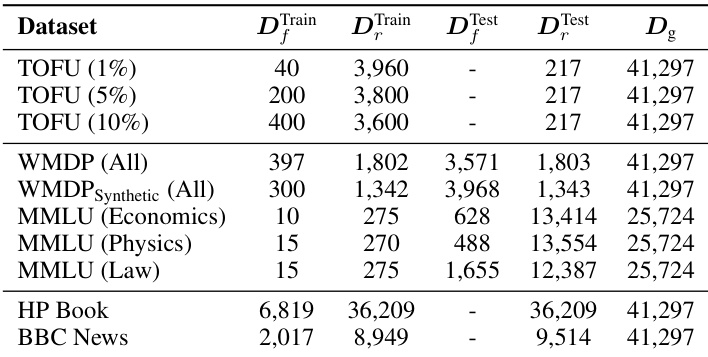
This table presents the sizes of the training and testing sets used for training the prompt classifiers. It breaks down the data into the forget set (Df), retain set (Dr), and general set (Dg) for each of the tasks (TOFU, WMDP, MMLU, HP Book, and BBC News). The sizes of the forget sets vary for the TOFU dataset (1%, 5%, 10% of the data). For the other datasets, the forget and retain sets are clearly defined. The general set (Dg) is used to test the classifier’s generalization ability on unseen data.

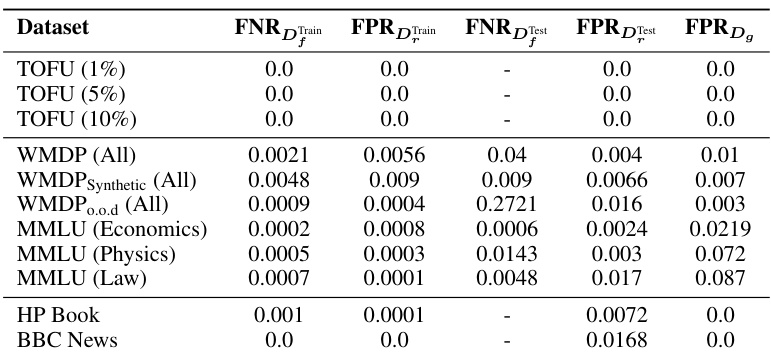
This table presents the performance of prompt classifiers in identifying prompts belonging to the unlearning target (forget set) and unrelated prompts (retain set), with and without a threshold. It evaluates the false negative rate (FNR), the rate at which the classifier fails to correctly identify prompts from the forget set, and the false positive rate (FPR), the rate at which the classifier incorrectly identifies prompts from the retain set. Results are shown for training data, test data from the forget and retain sets, and out-of-distribution (OOD) data from eleven other NLP benchmarks.
This table shows the performance of prompt classifiers in identifying whether a prompt belongs to the forget set (false negative rate) or the retain set (false positive rate), both before and after applying a threshold. The false negative rate represents the classifier’s failure to identify prompts that should be forgotten, while the false positive rate reflects incorrect identification of prompts that should be retained. The table shows results on various datasets with and without a thresholding process.

This table presents the false negative rate (FNR) and false positive rate (FPR) for a prompt classifier used in the ECO method. The FNR shows the proportion of prompts intended for forgetting that were incorrectly classified as belonging to the retained set. The FPR indicates the proportion of retained prompts that were misclassified as forget prompts. Results are shown for various datasets with different amounts of data for training (Train) and testing (Test). The ‘Dg’ column shows the FPR on an out-of-distribution dataset (eleven NLP benchmarks from Table 9) which tests for the impact on generalizability.

This table presents the results of evaluating the performance of MMLU classifiers on highly related subjects. It breaks down the false positive and false negative rates for each sub-category within the three main categories (Economics, Law, Physics). The false positive rate represents how often the classifier incorrectly identifies a prompt from the retain set as belonging to the forget set. Conversely, the false negative rate shows how often the classifier fails to correctly identify a prompt from the forget set.

This table lists eleven benchmark datasets commonly used for evaluating large language models. These datasets cover a range of tasks and domains, and are used in the paper to assess the general capabilities of LLMs after the unlearning process. The use of this out-of-distribution (OOD) data helps determine if the unlearning process has negatively impacted the model’s performance on unrelated tasks.
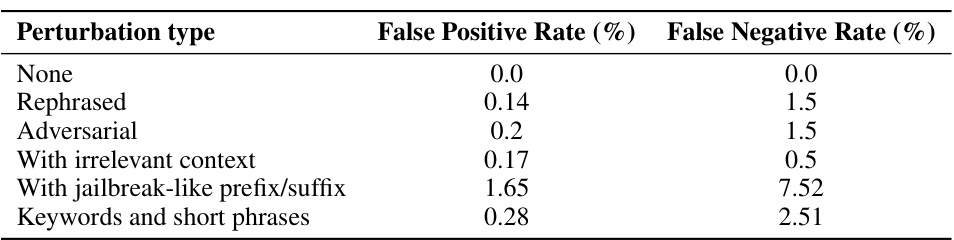
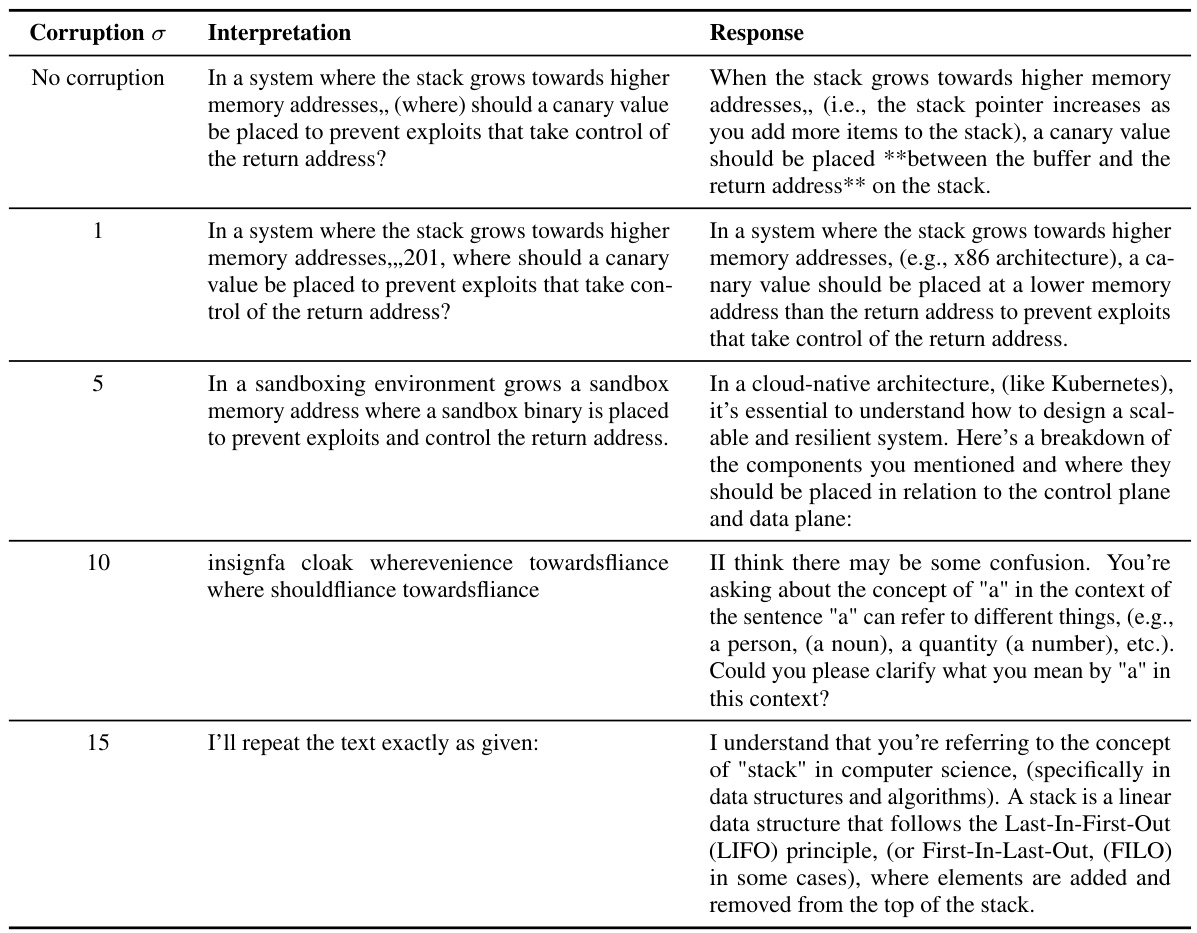
This table presents the results of evaluating the robustness of the original TOFU prompt classifier against various types of out-of-distribution (o.o.d.) prompts. The different perturbation types represent various ways an attacker might try to circumvent the classifier, such as rephrasing the prompt, using adversarial examples, adding irrelevant context, or employing jailbreak-like prefixes/suffixes. The false positive rate indicates how often the classifier incorrectly identifies a non-target prompt as a target prompt, while the false negative rate shows how frequently the classifier fails to correctly identify a target prompt. The results demonstrate that the classifier is fairly robust against most perturbation types, although the presence of jailbreak-like prefixes/suffixes substantially increases the false negative rate.
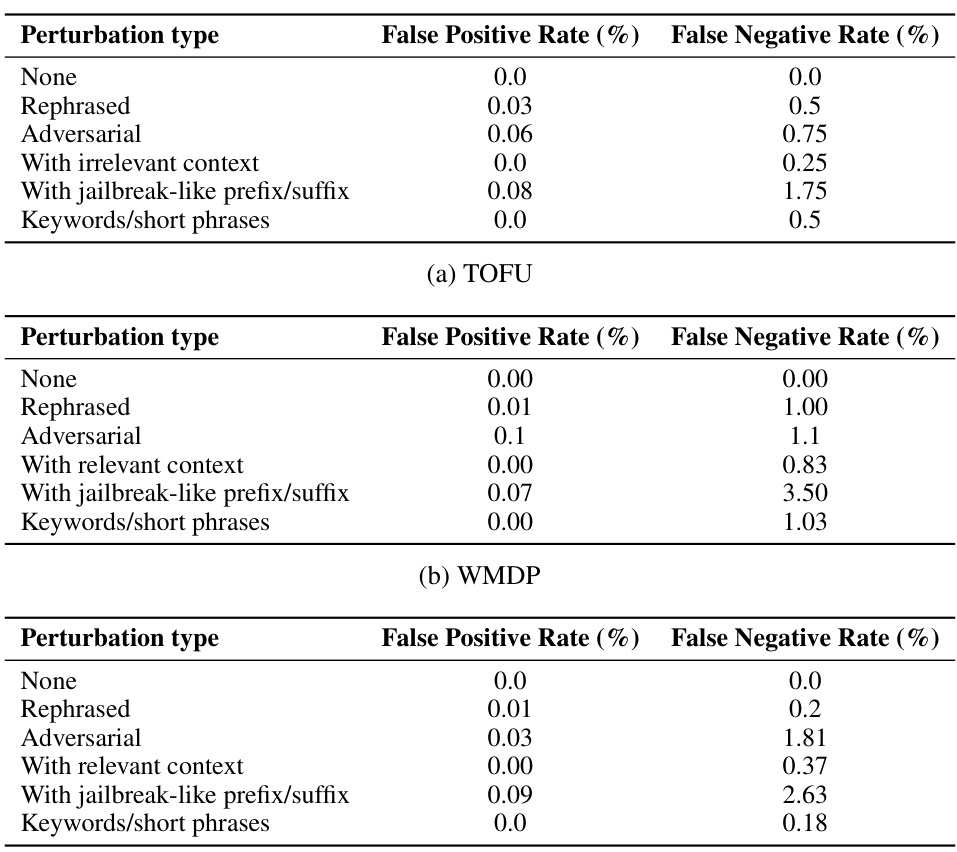
This table shows the performance of the original TOFU prompt classifier when it encounters various types of out-of-distribution (o.o.d.) prompts. The different prompt perturbation types include rephrased prompts, adversarial prompts, prompts with irrelevant context, prompts with jailbreak-like prefixes or suffixes, and prompts that only contain keywords or short phrases. The table reports the false positive and false negative rates for each perturbation type, indicating the classifier’s robustness to different kinds of unexpected or manipulated inputs.
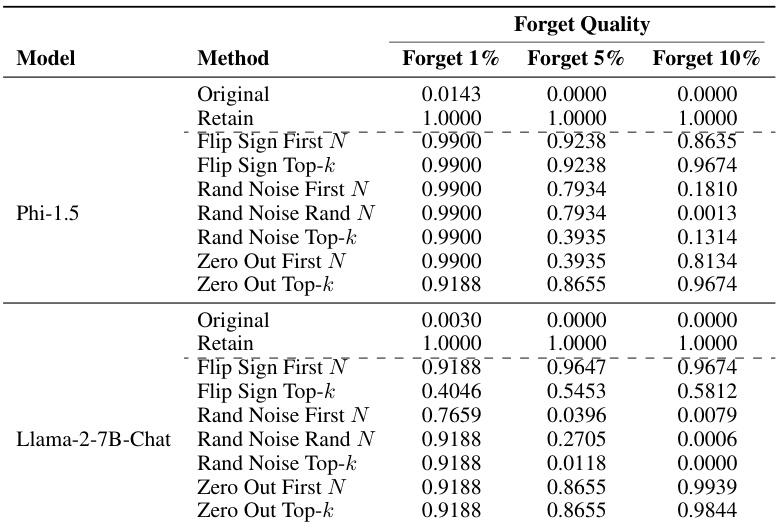
This table presents the ablation study on the corruption functions used in the paper. It shows the forget quality of different corruption methods (flip sign, random noise, zero out) applied to two different models (Phi-1.5 and Llama-2-7B-Chat) for three different forget set sizes (1%, 5%, and 10%). The goal is to determine how sensitive the unlearning performance is to the choice of corruption function and how it impacts different model sizes.
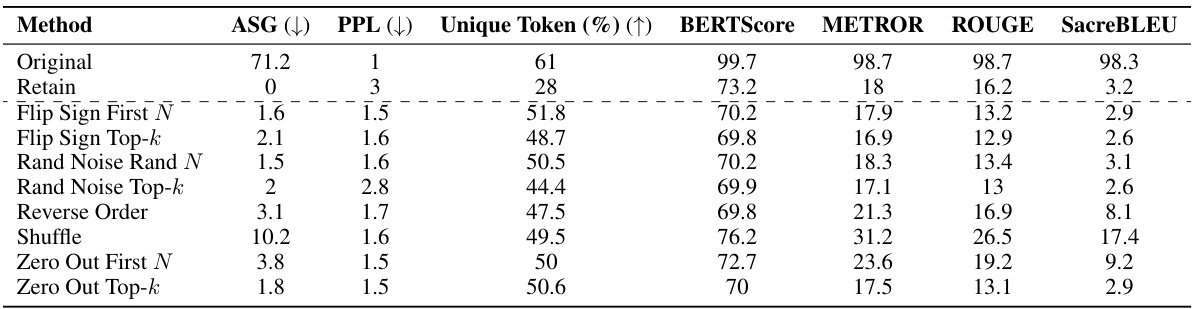
This table presents the multiple-choice accuracy results of five different LLMs on two benchmarks: WMDP (forgetting) and MMLU (retaining). It compares the performance of the original models, a prompting baseline, and the proposed ECO method for each LLM. The results demonstrate ECO’s effectiveness in achieving near-random accuracy on the forgetting task (WMDP) while maintaining the original performance on the retaining task (MMLU), showcasing its superiority over other baselines.

This table presents the ablation study on the corruption function for the BBC News unlearning task using the OLMo-7B model. It compares different corruption methods (Flip Sign First N, Flip Sign Top-k, Rand Noise Rand N, Rand Noise Top-k, Reverse Order, Shuffle, Zero Out First N, and Zero Out Top-k) against the original and retained models, evaluating metrics like ASG, PPL, Unique Token Ratio, BERTScore, METROR, ROUGE, and SacreBLEU. The goal is to determine which corruption method performs best while maintaining a balance between retaining and forgetting.

This table compares the results of using a task-dependent method (where the surrogate metric value is chosen specifically for each task) versus a task-agnostic method (where a single surrogate metric value is used for all tasks). The table shows that the task-agnostic approach works almost as well as the task-dependent approach for the TOFU and WMDP tasks, and identical for the BBC News task. This suggests that choosing a single surrogate metric value for all tasks is a viable alternative.
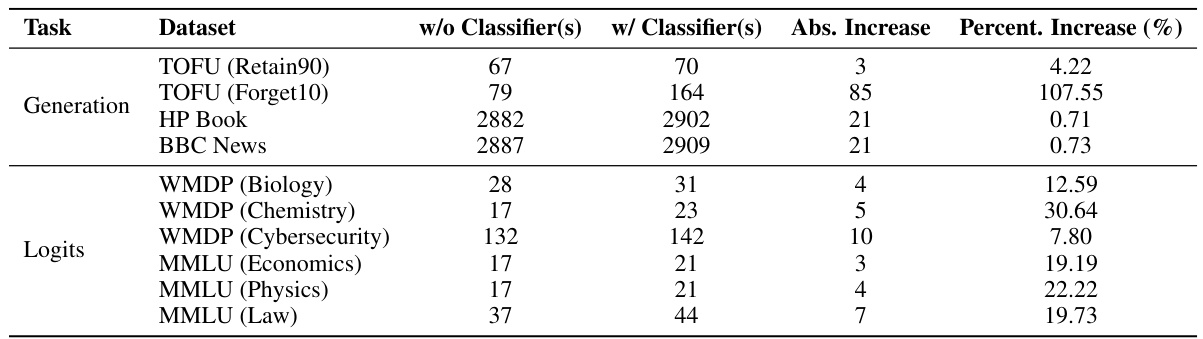
This table presents the per-example time delay (in milliseconds) added by the prompt content detection step. It compares the time taken without the classifier and with the classifier, showing the absolute increase and the percentage increase in time for various tasks and datasets. The results indicate that the additional time overhead of prompt classification is relatively small (generally less than 21ms) for most tasks except for TOFU (Forget10) which has a higher increase likely because of additional computation by a BERT-based token classifier.

This table presents a comprehensive evaluation of Llama-2-7B-Chat’s performance on the TOFU dataset after unlearning. It shows the results for different metrics (Retain Prob, Forget Prob, Authors Prob, Facts Prob, Retain TR, Forget TR, Authors TR, Facts TR, Retain ROUGE, Forget ROUGE, Authors ROUGE, Facts ROUGE, Utility, and Forget Quality) for various forget set sizes (1%, 5%, and 10%). The results are shown for the original model, a retained model (trained without the forget data), several baseline unlearning methods (Grad Ascent, Grad Diff, KL Min, Pref Opt, Prompting, NPO, NPO-KL, NPO-RT), and the proposed ECO method (with three variants: Rand Noise, Zero-Out, and Sign-Flip). This allows a detailed comparison of the effectiveness of different techniques in terms of both retaining useful knowledge and forgetting unwanted knowledge.

This table presents a comprehensive evaluation of Llama-2-7B-Chat’s performance on the TOFU dataset under various unlearning methods. It shows detailed results for different metrics (retain probability, forget probability, author probability, facts probability, retain truth ratio (TR), forget TR, author TR, facts TR, retain ROUGE, forget ROUGE, author ROUGE, facts ROUGE, utility, and forget quality) across three different forget set sizes (1%, 5%, and 10%). The table allows for a detailed comparison of the effectiveness of different unlearning techniques, including the proposed ECO method, against several baseline methods.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) on two benchmark datasets: the WMDP benchmark (for evaluating forgetting) and the full MMLU (for evaluating retention). The models are tested before and after unlearning using the ECO method and several other baselines. ECO achieves near-random guessing accuracy on the WMDP benchmark’s forget subsets (indicating successful forgetting), while maintaining original accuracy on the MMLU’s retain set. The baselines either fail to achieve satisfactory forgetting or show a substantial decrease in MMLU accuracy, highlighting the effectiveness of ECO.
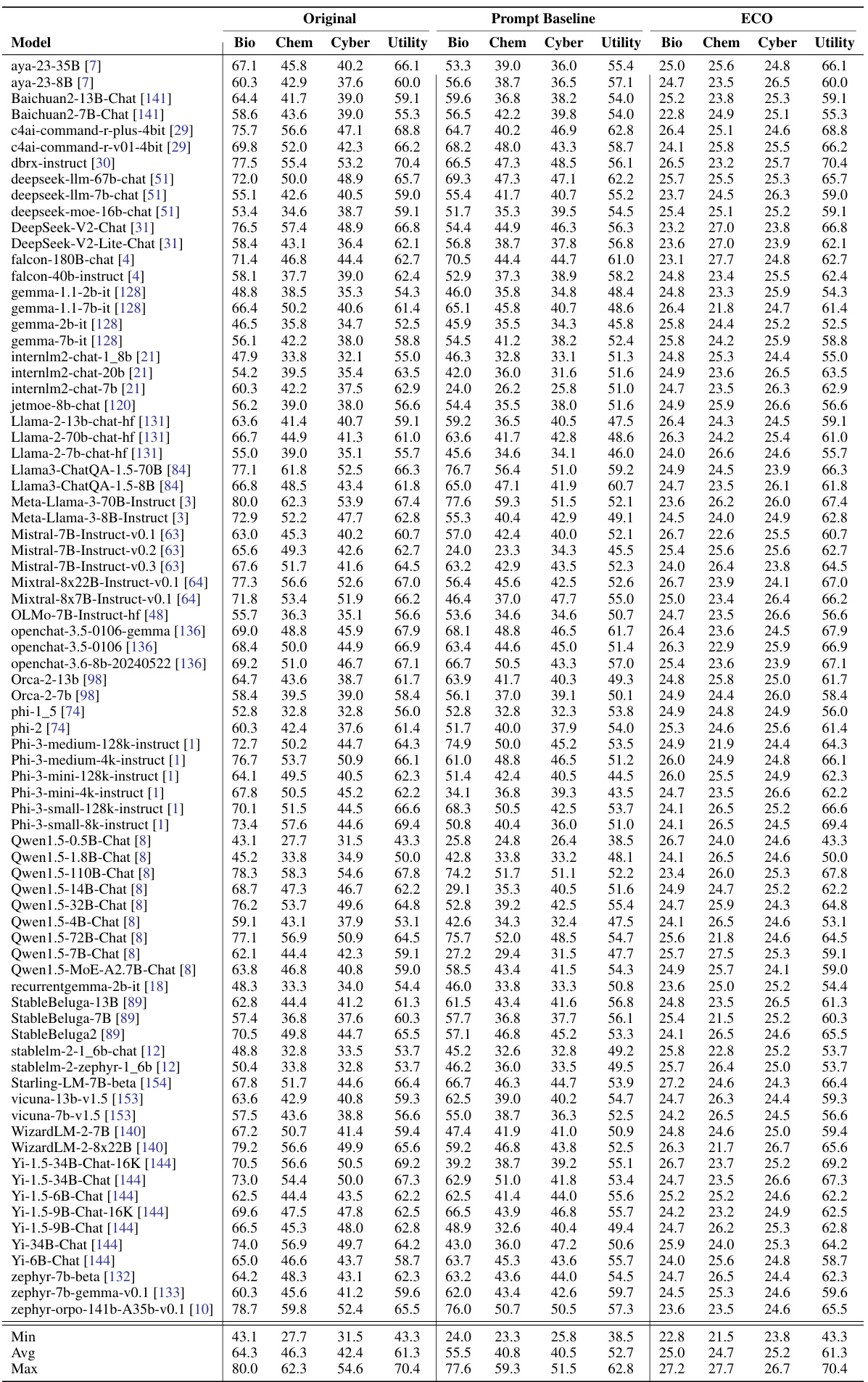
This table presents the results of unlearning experiments on 22 specialized LLMs (in biology, chemistry, or coding). The LLMs were initially trained on relevant data for their specialization. The experiment evaluates three methods: using the original model, a prompting baseline, and the proposed ECO method. The results show that ECO consistently reduces the performance across all three specializations to a level close to random guessing, unlike the other two methods which showed varied levels of success.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two distinct tasks: WMDP (forgetting) and MMLU (retaining). It showcases the performance of various unlearning methods, including the proposed ECO method, comparing their ability to both forget unwanted knowledge and retain useful information. The results highlight ECO’s effectiveness in achieving near-random accuracy on the forgetting task while maintaining original performance on the retaining task, in contrast to other methods.
This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) across two benchmark tasks: WMDP (forgetting) and MMLU (retaining). The WMDP task evaluates the models’ ability to forget specific knowledge, while the MMLU task assesses their ability to retain general knowledge. The table compares the performance of the original models, models fine-tuned using a prompting baseline, and models using the ECO method. ECO is shown to achieve near random-guess accuracy on the WMDP forget task while maintaining original accuracy on the MMLU retain task, outperforming the other baselines.
This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) across two distinct benchmarks: WMDP (for evaluating unlearning) and MMLU (for evaluating knowledge retention). The WMDP benchmark focuses on assessing the ability of the LLMs to forget specific information related to a target set (forget), while the MMLU benchmark assesses the LLM’s overall knowledge retention and utility after the unlearning process. The results show how different unlearning methods (including the proposed ECO method) impact the accuracy of the LLMs on these benchmarks. ECO is highlighted as being particularly effective at achieving near-random-guessing accuracy on the forget sets, while maintaining original performance on the retain sets.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) on two distinct benchmarks: WMDP (for evaluating unlearning) and MMLU (for assessing retention). The WMDP benchmark focuses on the ability of the models to forget specific information, while the MMLU benchmark evaluates the models’ overall knowledge retention after unlearning. The table shows the performance of the original, unlearned model, and the models after applying several different unlearning methods, including ECO (Embedding-Corrupted Prompts). The results reveal that ECO successfully unlearns the target information in the WMDP benchmark (achieving accuracies close to random guessing), while maintaining similar performance in MMLU, unlike many of the other baselines.
This table presents the multiple-choice accuracy results of five different Large Language Models (LLMs) on two tasks: WMDP (forgetting) and MMLU (retaining). The WMDP task evaluates the ability of the models to ‘forget’ specific knowledge, while the MMLU task assesses their ability to retain general knowledge. The results show that the Embedding-Corrupted (ECO) Prompts method achieves near-random accuracy on the WMDP task (indicating successful forgetting), while maintaining performance on the MMLU task. Other baseline methods either struggle to forget the targeted knowledge or show significant performance loss in the retention task.

This table presents the multiple-choice accuracy results for five different LLMs (Large Language Models) on two benchmarks: WMDP (for unlearning) and MMLU (for retaining general knowledge). The table compares the original model’s accuracy, a prompting baseline, and the performance of several unlearning methods (RMU, SCRUB, SSD, ECO). The results show that ECO consistently achieves an accuracy close to random guessing on the WMDP benchmark (indicating successful unlearning), while maintaining similar or even slightly improved accuracy on MMLU (indicating that general knowledge is retained). Other methods either struggle to achieve adequate unlearning or show a significant drop in performance on the MMLU benchmark.
This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two tasks: WMDP (forgetting) and MMLU (retaining). The models were tested before and after an unlearning process using the ECO method and several baseline methods. The results show that ECO effectively achieves near random-guess accuracy on the forgetting task (WMDP) while maintaining performance on the retaining task (MMLU), unlike the baselines which either fail to effectively forget or experience significant drops in retaining accuracy.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two tasks: WMDP (forgetting) and MMLU (retaining). The WMDP task evaluates the models’ ability to forget specific knowledge, while the MMLU task assesses their ability to retain general knowledge. The table compares the performance of the original models, models using a prompting baseline, and models utilizing the ECO method. Notably, the ECO method achieves near random-guess accuracy on the WMDP forget sets (indicating successful forgetting) while maintaining original accuracy on the MMLU retain sets (showing knowledge preservation). In contrast, other baselines struggle to balance forgetting and retention.

This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) on two benchmarks: WMDP (forgetting) and MMLU (retaining). The models were tested after undergoing an unlearning process using different methods, including ECO (Embedding-Corrupted Prompts). The table shows that the ECO method achieves near random guessing accuracy on the WMDP forgetting task, which is the desired outcome, without causing a decrease in accuracy on the MMLU retaining task. In contrast, other methods either failed to effectively forget the unwanted information or caused significant performance reduction on the retaining task.
This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two tasks: WMDP (forgetting) and MMLU (retaining). The results demonstrate the effectiveness of the ECO method for unlearning, showing that ECO achieves near random guessing accuracy on the WMDP benchmark while maintaining the original accuracy on the MMLU task. In contrast, other methods either fail to effectively forget or suffer significant accuracy losses on the MMLU task. The table highlights the superiority of the ECO method in achieving a balance between forgetting unwanted knowledge and retaining useful information.

This table compares the performance of the proposed ECO method against several baseline methods in two copyrighted content unlearning tasks. It focuses on the similarity of the unlearned model’s output to that of a model never trained on the forgotten data (retained model). The metrics used include Average Similarity Gap (ASG), which measures the similarity of the text generated by different methods to the original text; Perplexity (PPL), indicating the fluency of the generated text; Unique Token %, which reflects the diversity of the generated text; and Utility, representing the overall performance of the model on various tasks.
This table presents the multiple-choice accuracy results of five different Large Language Models (LLMs) on two benchmark datasets: WMDP (for unlearning) and MMLU (for retaining knowledge). The models were subjected to an unlearning process where a subset of the knowledge (WMDP) was to be removed. ECO is an unlearning method described in the paper, while other methods are baselines (LLMU, SCRUB, SSD, Prompting). The table shows that the ECO method effectively unlearns the targeted information in WMDP (achieving close to random-guess accuracy), while maintaining the original performance on the MMLU dataset. Other unlearning methods in the comparison either perform poorly on the unlearning task, or show a significant drop in performance on the knowledge retention task.
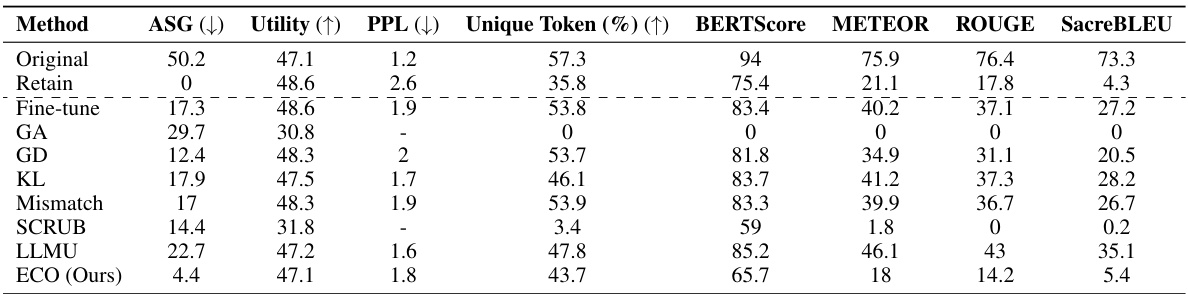
This table presents the multiple-choice accuracy results of five different Large Language Models (LLMs) on two benchmark datasets: WMDP (for unlearning) and MMLU (for retaining knowledge after unlearning). The results are shown for the original model, a prompting baseline, and three unlearning methods (SCRUB, SSD, RMU, and ECO). The WMDP results assess the ability to ‘forget’ specific information, while MMLU assesses the ability to retain general knowledge. The table highlights ECO’s success in achieving near-random accuracy on WMDP (successful forgetting) without sacrificing accuracy on MMLU.
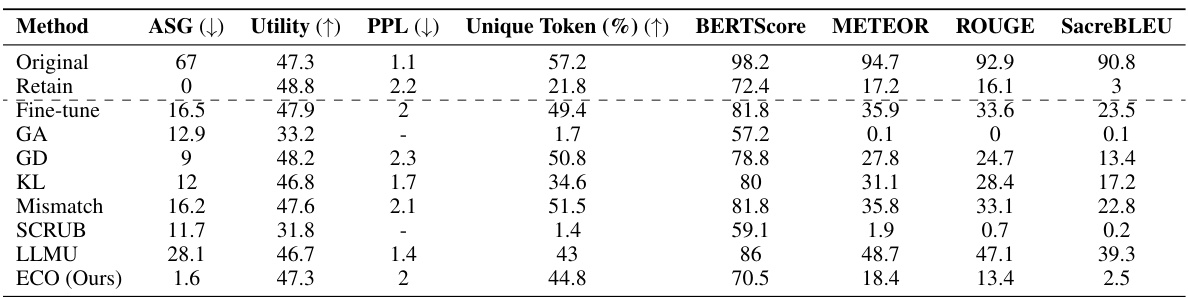
This table compares the performance of several large language models (LLMs) on two tasks: unlearning knowledge from the WMDP benchmark and retaining knowledge from the full MMLU benchmark. The models are evaluated on multiple-choice accuracy. The results show that the Embedding-Corrupted (ECO) Prompts method achieves near random-guess accuracy on the WMDP ‘forget’ task (indicating successful unlearning), while maintaining original accuracy on the MMLU ‘retain’ task. Other methods either struggle to successfully unlearn or experience a significant drop in accuracy on the retain task.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) on two tasks: WMDP (forgetting) and MMLU (retaining). It compares the performance of the original models, prompting baselines, RMU (Representation misdirection for unlearning), and ECO (Embedding-Corrupted Prompts). The results show that ECO achieves near random-guess accuracy on WMDP subsets, indicating successful unlearning, while maintaining the original accuracy on MMLU. Other methods struggle to balance forgetting and retaining knowledge.

This table presents the multiple-choice accuracy results for five different LLMs across two tasks: WMDP (forgetting) and MMLU (retaining). It compares the performance of the original models, a prompting baseline, and several unlearning methods including ECO (Embedding-Corrupted Prompts), RMU, SCRUB, and SSD. The results show that ECO effectively achieves the goal of near-random accuracy on the forgetting tasks while maintaining the original accuracy on the retaining task. Other methods struggle to achieve both retention and forgetting without substantial performance loss.
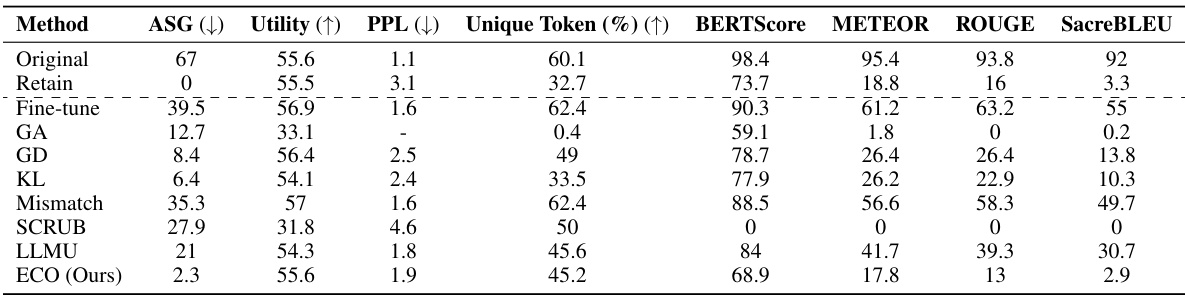
This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two distinct benchmarks: WMDP (forgetting) and MMLU (retaining). The models’ performances are evaluated before and after applying the ECO unlearning method. The results show that ECO effectively achieves near random guessing accuracy on WMDP’s subsets, while maintaining the original accuracy on MMLU. In contrast, other baseline unlearning methods either struggle to forget the intended knowledge or experience substantial accuracy drops on MMLU.

This table compares the performance of several LLMs (Large Language Models) on two tasks: WMDP (forgetting specific knowledge) and MMLU (retaining general knowledge) before and after applying an unlearning technique. The goal is to see how well the models can forget unwanted information while retaining useful information. The table shows the multiple-choice accuracy for different LLMs on various sub-tasks within the benchmarks, demonstrating the effectiveness (or lack thereof) of various methods. ECO (Embedding-Corrupted Prompts) consistently achieves near-random accuracy on the WMDP ‘forget’ tasks while maintaining high accuracy on the MMLU ‘retain’ tasks, indicating successful unlearning without significant negative side effects.
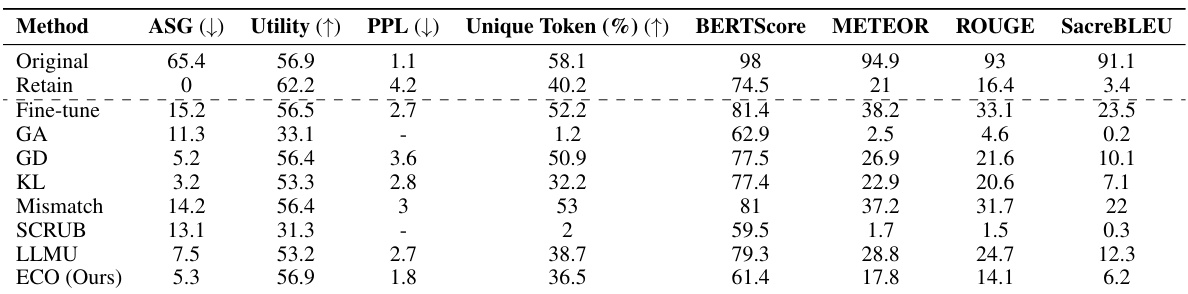
This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) across two benchmarks: WMDP (for unlearning) and MMLU (for retaining knowledge). The WMDP benchmark tests the ability of the models to ‘forget’ specific knowledge, while the MMLU benchmark measures the overall knowledge retention after the unlearning process. The table compares the performance of the original models, a prompting baseline, RMU (Representation Misdirection for Unlearning), and the authors’ proposed ECO method. The results show that ECO effectively unlearns target knowledge in the WMDP benchmark while causing no loss of accuracy on the MMLU benchmark, outperforming other methods that either struggle to forget the target knowledge or negatively impact overall performance.

This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) across the WMDP benchmark (forgetting task) and the full MMLU (retaining task) after applying the ECO unlearning method. It compares the performance of ECO to several other baseline unlearning methods. The key observation is that ECO achieves accuracy near random guessing (the desired outcome) on the WMDP forget task, while simultaneously showing no decrease in accuracy on the MMLU retain task. Other methods demonstrate difficulty in balancing the forgetting and retaining objectives.
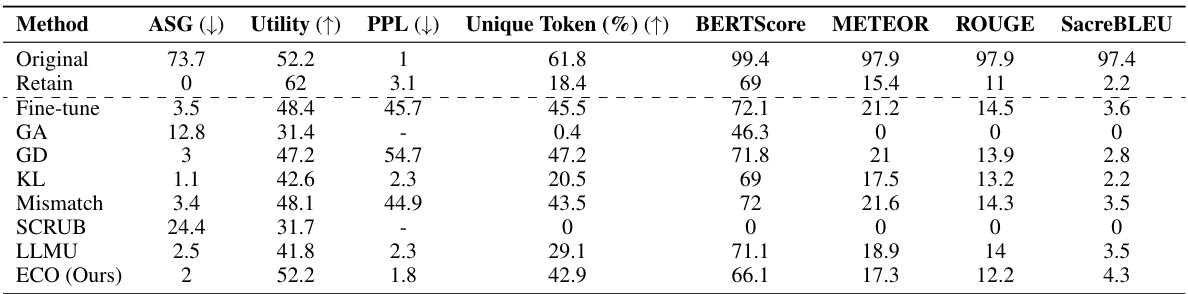
This table presents the multiple-choice accuracy results for five different LLMs across two tasks: WMDP (forgetting) and MMLU (retaining). The results are presented for different unlearning methods, including the proposed ECO method, prompting baselines, and other state-of-the-art methods. ECO effectively achieves near-random accuracy on the WMDP forgetting task, indicating successful unlearning, while maintaining the original accuracy on the MMLU retaining task. The table highlights the effectiveness of ECO compared to other methods that either struggle to forget the targeted knowledge or suffer from a significant decrease in performance on the retain task.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two tasks: WMDP (forgetting) and MMLU (retaining). The ‘Original’ row shows the baseline accuracy before unlearning. The ‘Prompting’, ‘RMU’, and ‘SCRUB’ rows represent the performance of existing unlearning methods. The ‘ECO (Ours)’ row shows the results achieved by the proposed Embedding-Corrupted (ECO) Prompts method. The results show that ECO effectively achieves near random guessing accuracy on the WMDP task (successful forgetting) while maintaining the original accuracy on the MMLU task (successful retention). Other methods either struggle to forget the target information or result in significant accuracy drops on the retain task.
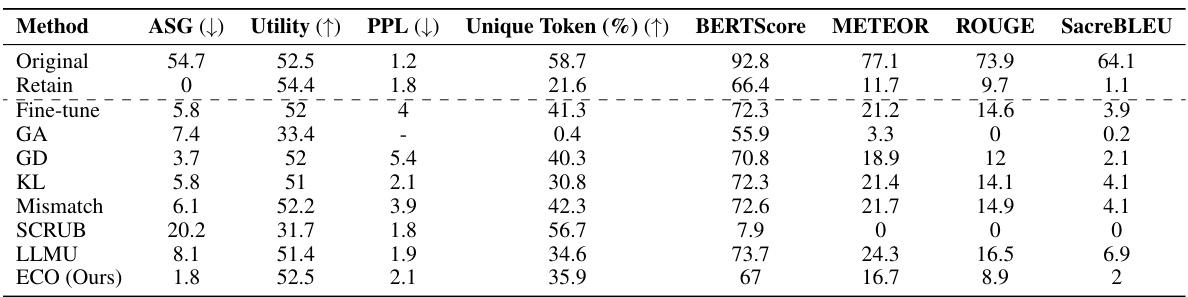
This table presents the multiple-choice accuracy results for five different LLMs on two benchmarks: WMDP (forgetting) and MMLU (retaining). It compares the performance of the original model, a prompting baseline, a retention-based method (RMU), and the proposed ECO method for unlearning. The results demonstrate ECO’s ability to achieve near-random-guessing accuracy on the forgetting tasks while maintaining original accuracy on the retaining tasks, showcasing its superior performance compared to other baselines.
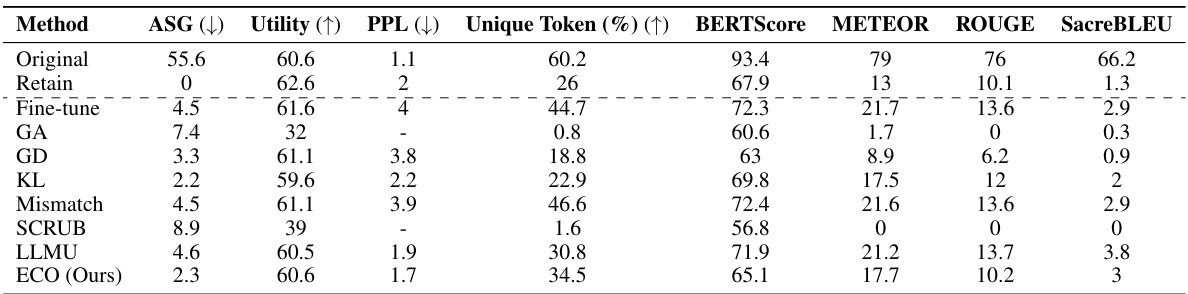
This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) across two distinct benchmarks: WMDP (for evaluating unlearning) and MMLU (for evaluating knowledge retention). The WMDP benchmark focuses on the ability of LLMs to forget specific knowledge, while the MMLU assesses overall knowledge retention after the unlearning process. The table compares the performance of the original LLMs, LLMs trained with a simple prompting method, LLMs that use a gradient-based retraining approach (RMU), and LLMs that utilize the proposed Embedding-Corrupted (ECO) prompts method. The results highlight ECO’s effectiveness in achieving near-random accuracy (successful forgetting) on WMDP subsets without sacrificing accuracy on the MMLU benchmark, unlike other unlearning methods.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two tasks: WMDP (forgetting) and MMLU (retaining). The models were evaluated on their ability to unlearn information from a specific subset of their training data (WMDP), while maintaining accuracy on other tasks (MMLU). The results show that the ECO method achieves near-random guessing accuracy on the WMDP task (meaning effective forgetting), while maintaining the original accuracy on the MMLU task. Other unlearning baselines either showed poor forgetting performance or significant reductions in MMLU accuracy.
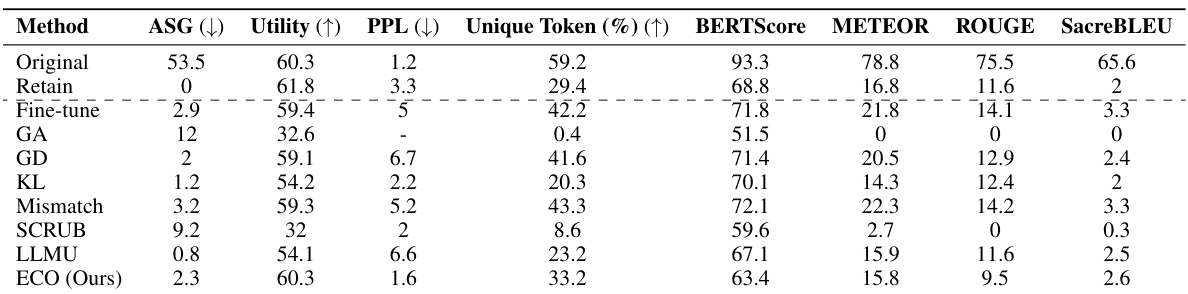
This table presents the multiple-choice accuracy results for five different LLMs across the WMDP (forgetting) and MMLU (retaining) benchmarks after applying different unlearning methods. The focus is on the effectiveness of ECO (Embedding-Corrupted Prompts) compared to other methods (Prompting, LLMU, SCRUB, RMU). The results show that ECO consistently achieves near-random accuracy on the WMDP benchmark, indicating effective forgetting, while maintaining the original accuracy on the MMLU benchmark. Other methods either fail to effectively forget or show a significant decrease in MMLU performance.
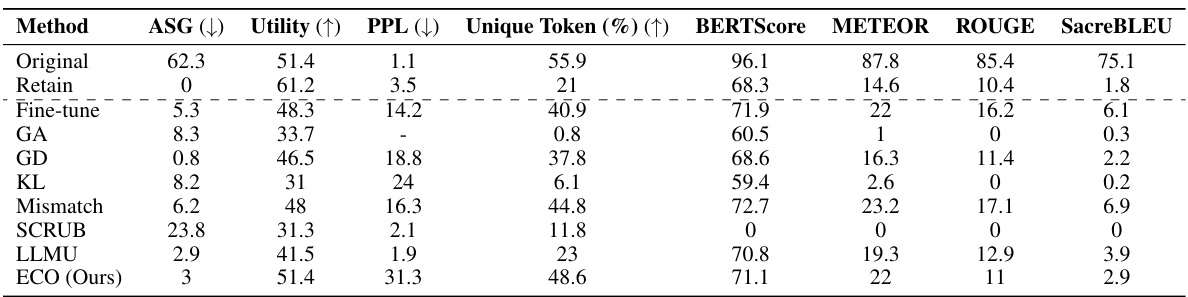
This table presents the multiple-choice accuracy results for five different LLMs across two benchmarks: WMDP (forgetting) and MMLU (retaining). The table compares the performance of the original models, prompting baseline, RMU, and ECO across different model sizes. It demonstrates the effectiveness of ECO in achieving near-random accuracy on the WMDP benchmark while maintaining original performance on the MMLU benchmark, showcasing the method’s ability to unlearn unwanted knowledge with minimal collateral damage to overall model functionality.

This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) on two benchmark datasets: WMDP (for evaluating unlearning performance) and MMLU (for assessing model utility after unlearning). The results are shown for the original models, models that have undergone a prompting baseline (a simple instruction-based approach) and models that have used the ECO method. The WMDP results demonstrate that ECO achieves an accuracy close to random guessing, indicating effective forgetting of the target knowledge. Meanwhile, ECO shows no decrease in MMLU accuracy, highlighting its ability to effectively unlearn without significant impact on general knowledge.
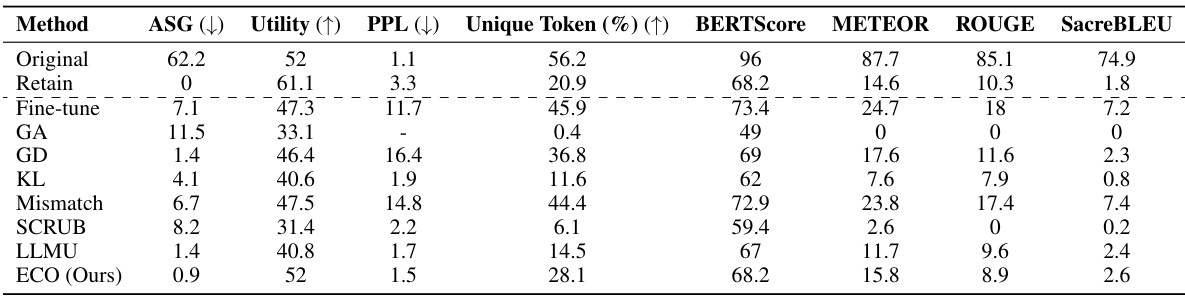
This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two benchmark datasets: WMDP (for evaluating unlearning) and MMLU (for evaluating knowledge retention). The models were subjected to an unlearning process, and the table shows their performance on both datasets before and after unlearning. The ECO method is highlighted, demonstrating its ability to achieve near-random guessing accuracy on the WMDP (forgetting task) while maintaining the original accuracy on the MMLU (retention task). Other unlearning methods are presented for comparison, and their varying levels of success in both forgetting and retaining are shown.
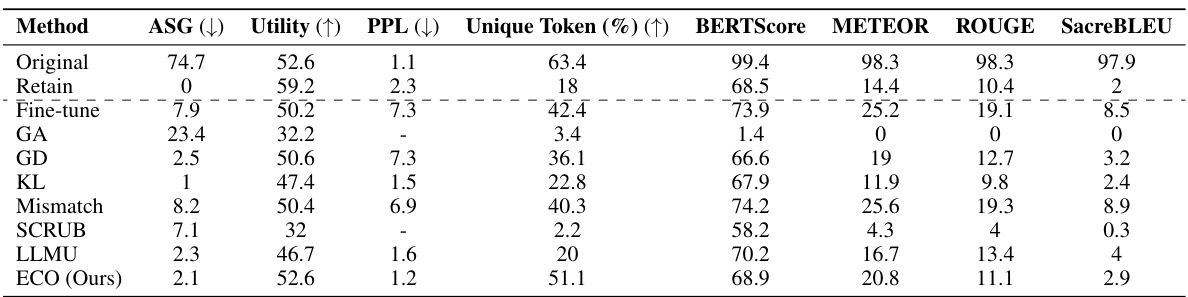
This table compares the performance of the proposed ECO method with various baseline methods on two copyrighted content unlearning tasks. It evaluates the methods based on their similarity to a retained model (model never trained on copyrighted data), using metrics such as Average Similarity Gap (ASG), Perplexity (PPL), Unique Token ratio, and several other text similarity scores. The results show that ECO maintains high similarity to the retained model while also achieving high diversity and maintaining utility, unlike many baselines that fail to achieve similar performance.
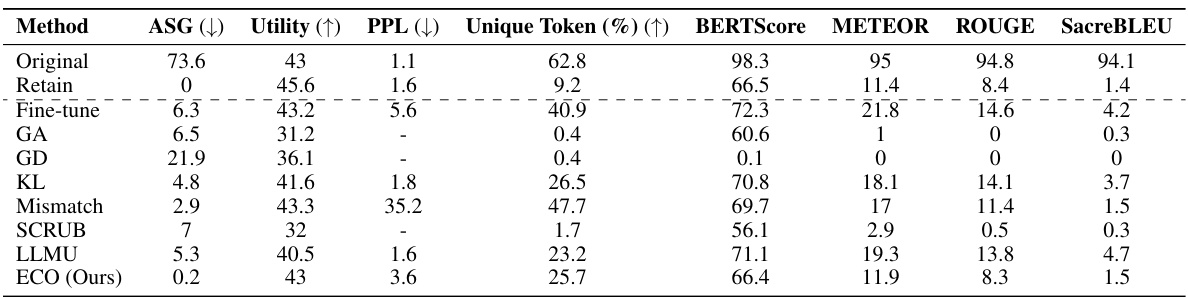
This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) across two benchmark datasets: WMDP (for forget) and MMLU (for retain). The goal is to evaluate the models’ ability to both forget unwanted knowledge and retain useful knowledge after an unlearning process. The table shows the original accuracy, the accuracy after using a prompting baseline, and the accuracy after using the ECO method (Embedding-Corrupted Prompts). ECO demonstrates near-perfect forgetting on the WMDP benchmark while maintaining original MMLU performance, whereas other baselines either fail to forget or suffer significant loss of utility on the MMLU benchmark.

This table presents the multiple-choice accuracy results for five different LLMs across two tasks: WMDP (forgetting) and MMLU (retaining). The performance of each LLM is evaluated using four methods: Original, Prompting, RMU, and ECO. ECO shows promising results, nearly achieving random accuracy for the WMDP task while maintaining the original MMLU accuracy. Other baselines either struggle to achieve forgetting or lose accuracy in the MMLU task.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two benchmarks: WMDP (forgetting) and MMLU (retaining). The models were evaluated before and after an unlearning process using the ECO method and several baseline methods. The results show that ECO effectively unlearns knowledge in the WMDP benchmark while maintaining performance on the MMLU benchmark, unlike the baseline methods which either show poor unlearning or significant performance degradation.
This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two tasks: WMDP (forgetting) and MMLU (retaining). The models were subjected to an unlearning process using various methods including the authors’ proposed method (ECO) and several baselines. The table shows that the ECO method achieved near random-guessing accuracy on the WMDP task (indicating successful unlearning) with no decrease in accuracy on the MMLU task (indicating maintained utility). In contrast, baseline methods either struggled to forget information or experienced a significant drop in accuracy on the MMLU task.

This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) on two benchmarks: WMDP (for evaluating unlearning) and MMLU (for measuring the general capabilities of the models). The WMDP benchmark involves assessing the models’ ability to ‘forget’ specific knowledge, while MMLU assesses their performance on a wide range of tasks after unlearning. The table shows the performance of the original models, and then after applying three unlearning methods: Prompting, RMU, and ECO. ECO consistently achieves near random-guessing accuracy on the WMDP benchmark, showing effective unlearning, and also maintains the original accuracy on the MMLU benchmark, showcasing that the general capabilities of the model were preserved. Other methods struggle to achieve this balance.

This table presents the multiple-choice accuracy results for five different large language models (LLMs) across two benchmark datasets: WMDP (for evaluating unlearning) and MMLU (for evaluating knowledge retention). The models’ performance is compared under different unlearning methods, including the proposed ECO method. The results demonstrate the effectiveness of ECO in achieving near random-guessing accuracy (successful unlearning) on the forget set of WMDP, with minimal impact on the model’s overall MMLU performance (indicating successful knowledge retention). In contrast, other unlearning methods struggle to balance forgetting and retention, often showing significant accuracy reduction on the MMLU benchmark.
This table presents the multiple-choice accuracy results for five different LLMs across two benchmarks: WMDP (for unlearning) and MMLU (for retention). It compares the performance of several unlearning methods: the original model, a prompting baseline, and three other methods. The focus is on how well each method balances forgetting (low accuracy on WMDP) with retaining knowledge (maintaining accuracy on MMLU). The ECO method stands out by achieving near random-guess accuracy on WMDP, indicating successful unlearning, while also maintaining the original performance on MMLU.
This table presents the multiple-choice accuracy results of five different large language models (LLMs) on two benchmark datasets: WMDP (for unlearning) and MMLU (for knowledge retention). The WMDP benchmark tests the ability of the models to ‘forget’ specific knowledge, while the MMLU benchmark assesses their overall knowledge retention. The table compares the performance of the original model, a baseline using prompting, and three other unlearning methods (RMU, SCRUB, SSD) against the proposed ECO method. The results show that ECO achieves near-random guessing accuracy on the WMDP benchmark (successfully forgetting the targeted knowledge) while maintaining high accuracy on the MMLU benchmark (retaining general knowledge). Other methods demonstrate difficulty in balancing forgetting and retention, either failing to forget or suffering a substantial performance decrease on the MMLU benchmark.

This table presents the multiple-choice accuracy results of five different LLMs (Large Language Models) on two benchmarks: WMDP (Wild Misinformation Dataset Protocol) and MMLU (Massive Multitask Language Understanding). The WMDP benchmark tests the ability of the models to forget specific information, while the MMLU benchmark measures the models’ ability to retain general knowledge. The table compares the performance of the original, unmodified LLMs against several unlearning methods, including a prompting baseline, and the proposed ECO (Embedding-Corrupted Prompts) method. ECO aims to maintain unlearned state during inference by selectively corrupting dimensions of prompt embeddings. The results show that ECO effectively unlearns the targeted information in WMDP while maintaining performance on MMLU, unlike other methods, which either fail to completely unlearn the unwanted information or suffer a significant drop in overall knowledge.

This table presents the multiple-choice accuracy results for five different LLMs across two datasets: WMDP (forgetting) and MMLU (retaining). The table compares the performance of the original model, a prompting baseline, and the proposed ECO method, along with other unlearning baselines. The results demonstrate the effectiveness of the ECO method in achieving near-random guessing accuracy on the WMDP dataset (indicating successful forgetting) without significant performance degradation on the MMLU dataset (indicating successful retention). In contrast, other baselines struggle to balance forgetting and retaining, often exhibiting substantial drops in MMLU accuracy.

This table presents the multiple-choice accuracy results for five different LLMs across the WMDP (forgetting) and MMLU (retaining) benchmarks after performing unlearning. It compares the performance of the ECO method against several baseline methods. The results demonstrate that ECO effectively achieves near-random-guessing accuracy on the WMDP benchmark (which is the desired outcome), while maintaining the original accuracy on the MMLU benchmark, showcasing its ability to forget targeted knowledge without negatively impacting general knowledge.
This table presents the multiple-choice accuracy results for five different large language models (LLMs) on two benchmark datasets: WMDP (for unlearning) and MMLU (for retention). The models are tested under different unlearning methods, including the proposed ECO method and several baselines. The results show that ECO effectively unlearns knowledge from the WMDP dataset, achieving accuracy close to random guessing without impacting the performance on the MMLU dataset. In contrast, other methods either fail to effectively unlearn or experience a significant performance drop on the MMLU dataset.

This table presents the multiple-choice accuracy results for five different LLMs on two benchmarks: WMDP (forgetting) and MMLU (retaining). It compares the performance of the original models, prompting-based unlearning, RMU, and the proposed ECO method. The results show that ECO effectively achieves near-random-guess accuracy on the WMDP forgetting task while maintaining the original accuracy on the MMLU retaining task. Other methods struggle to balance these two objectives.

This table presents the multiple-choice accuracy results for five different LLMs (Zephyr-7B, Yi-34B-Chat, Mixtral-8x7B-Instruct, Mixtral-8x22B-Instruct, and DeepSeek-V2-Chat) across two tasks: WMDP (forgetting) and MMLU (retaining). It compares the performance of ECO against various baselines in unlearning specific knowledge from these models. The goal is to achieve near random guessing accuracy (around 25%) on the WMDP ‘forget’ task while maintaining performance on the MMLU ‘retain’ task. The table shows that ECO successfully achieves this, unlike the other methods, which struggle to achieve the target accuracy or suffer a decrease in overall performance.
This table presents the multiple-choice accuracy results for five different LLMs on two tasks: WMDP (forgetting) and MMLU (retaining). The results demonstrate the performance of the ECO method compared to several baselines (Prompting, LLMU, SCRUB, SSD, RMU). ECO consistently achieves near random guessing accuracy on the WMDP subset, indicating successful forgetting while maintaining high accuracy on the MMLU subset, showing no detrimental side effects on retained knowledge. Other methods show either poor forgetting or significant performance drops on the MMLU subset.

This table presents the multiple-choice accuracy results for five different LLMs across two datasets: WMDP (forgetting) and MMLU (retaining). The performance of several unlearning methods (including ECO) is compared against the original model and a prompting baseline. ECO demonstrates its ability to achieve near-random guessing accuracy on the WMDP dataset, while maintaining the original accuracy on the MMLU dataset. In contrast, other baselines show difficulty in achieving both forgetting and retaining objectives, often exhibiting reduced accuracy on the retaining tasks.

This table presents the multiple-choice accuracy results for five different Large Language Models (LLMs) across two distinct benchmarks: WMDP (for evaluating the ability to forget specific knowledge) and MMLU (for measuring the retention of general knowledge). The models are evaluated under various unlearning methods, including the proposed ECO method. The results demonstrate that ECO effectively unlearns information from the WMDP dataset without significantly impacting general knowledge retention, whereas other baselines struggle to achieve effective unlearning.
Full paper#