↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) heavily rely on positional encoding to understand the context of words in a sentence. Rotary Position Embedding (RoPE) is a popular technique, and this paper investigates how it uses the positional information. A key challenge in training LLMs is the substantial computational cost, especially during fine-tuning, which adapts the model to specific tasks. This necessitates methods that minimize the number of parameters requiring adjustments while maintaining accuracy.
This research delves into RoPE’s inner workings by analyzing the angles between pairs of weight vectors in the query and key matrices. It reveals that the angle significantly influences how the model attends to words. Non-orthogonal pairs (angles far from 90 degrees) primarily focus on basic syntactic information, whereas nearly orthogonal pairs concentrate on high-level semantic information. This understanding forms the basis for a novel method, Angle-based Weight Masking (AWM), designed to optimize LLM fine-tuning. AWM selectively updates only the nearly orthogonal weight pairs, substantially decreasing the number of trainable parameters without sacrificing accuracy, thereby offering a significant improvement in computational efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel perspective on understanding how large language models (LLMs) utilize positional information, potentially leading to more efficient fine-tuning methods. By identifying and selectively modifying specific weight vectors within the query and key matrices, researchers can reduce computational costs and enhance model performance. This work is directly relevant to current research trends in parameter-efficient fine-tuning and provides new avenues for exploring the relationship between syntactic and semantic information processing in LLMs.
Visual Insights#
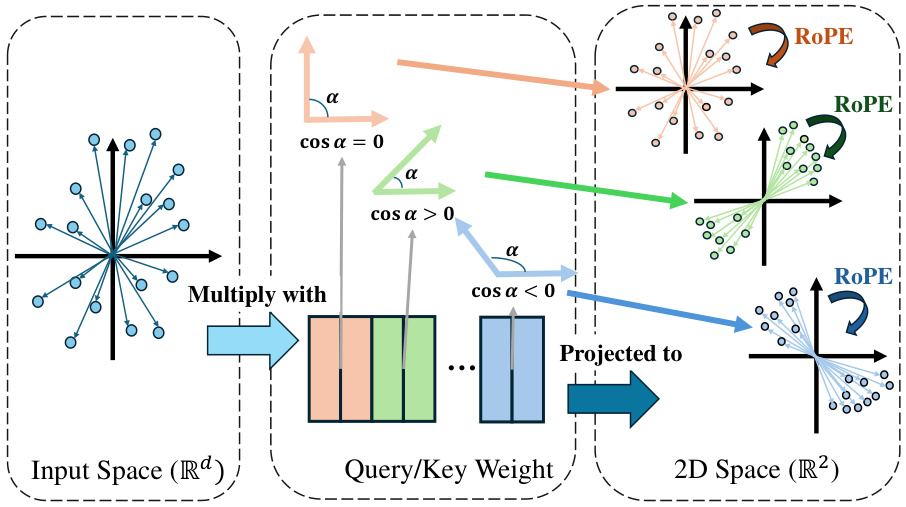
This figure illustrates how the angle between weight vector pairs in the query or key of the RoPE mechanism affects the attention mechanism in LLMs. The cosine similarity between the pairs determines how fixed the direction of the projected 2D vector is. A larger absolute cosine similarity means a more fixed direction and consequently, greater attention to certain relative positions, irrespective of the input. In contrast, smaller cosine similarity leads to a more flexible attention pattern.
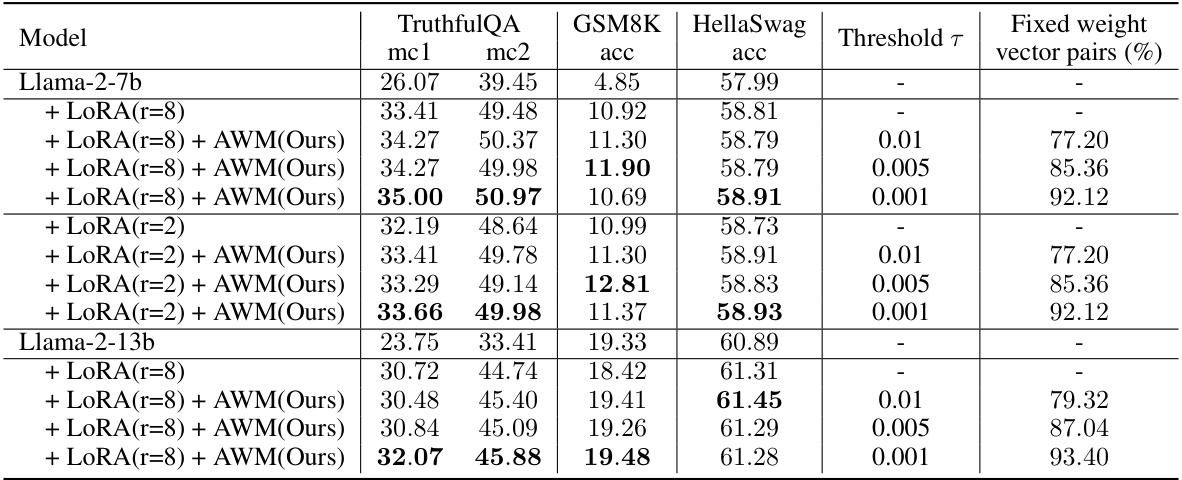
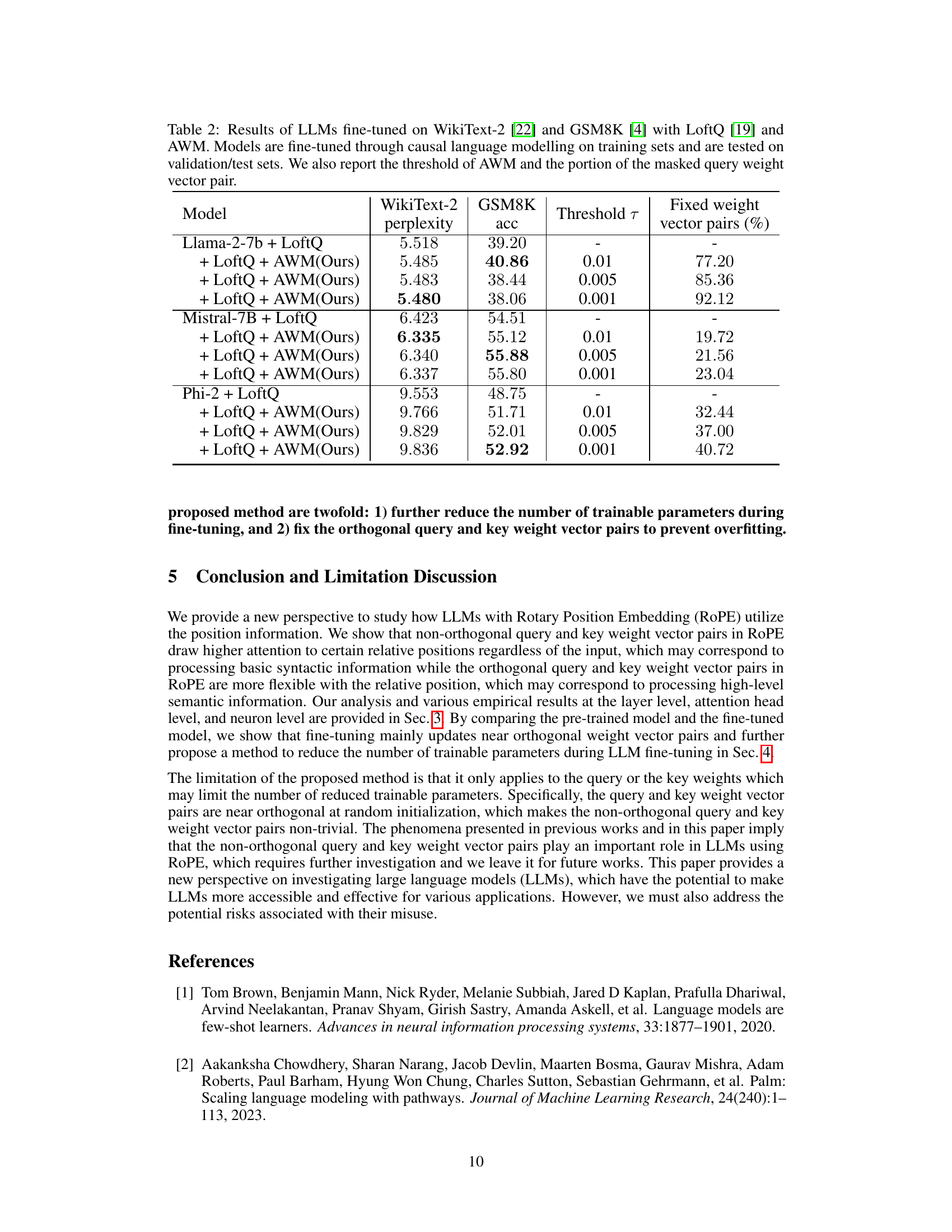
This table presents the results of fine-tuning Llama-2 using LoRA and the proposed Angle-based Weight Masking (AWM) method. It compares the performance of LoRA alone against LoRA combined with AWM across different thresholds. The performance is measured using three benchmarks: TruthfulQA, GSM8K, and HellaSwag. The table also shows the percentage of fixed weight vector pairs resulting from AWM at each threshold.
In-depth insights#
RoPE Weight Angles#
The concept of “RoPE Weight Angles” introduces a novel perspective on analyzing the internal workings of large language models (LLMs) that utilize Rotary Position Embeddings (RoPE). It posits that the angles between weight vector pairs within RoPE’s query and key matrices are not arbitrary but encode crucial information about how the model processes positional information. Non-orthogonal weight vector pairs, exhibiting large absolute cosine similarity, are hypothesized to correspond to basic syntactic information processing, showing less sensitivity to input variations. Conversely, nearly orthogonal weight vector pairs, with near-zero cosine similarity, are proposed to be associated with high-level semantic information processing, offering more flexibility in attention mechanisms. This framework provides a unique method for analyzing layer-wise and attention head-wise differences within LLMs and offers insights into how fine-tuning predominantly affects weight pairs handling semantic information, preserving basic syntactic processing already well-established during pre-training.
Syntactic vs. Semantic#
The dichotomy between syntactic and semantic processing in LLMs is a crucial area of investigation. While syntax concerns the grammatical structure and arrangement of words, semantics focuses on meaning and interpretation. This paper explores how different layers of LLMs might specialize in these areas. Shallow layers may prioritize local syntactic patterns, focusing on immediate word relationships to parse the grammatical structure. Deeper layers might focus more on semantic relationships, building a broader contextual understanding to derive meaning from entire sentences and paragraphs. This division of labor could be crucial to the LLM’s efficiency and understanding of complex language, allowing for incremental processing that starts with concrete rules and builds towards abstract concepts. However, this division isn’t necessarily strict, with some overlap and interaction between layers likely present. Further research should aim to quantify these distinctions, investigating how precisely syntactic and semantic information are processed and represented in each layer to fully grasp their interconnectedness and impact on overall comprehension.
Fine-tuning Efficiency#
Fine-tuning large language models (LLMs) is computationally expensive. This paper explores methods to improve efficiency, focusing on the role of rotary position embedding (RoPE). A key insight is that fine-tuning primarily affects weight vector pairs that are nearly orthogonal, suggesting these pairs are most involved in processing higher-level semantic information. This observation motivates a proposed method, Angle-based Weight Masking (AWM), which selectively masks or freezes the non-orthogonal weights during fine-tuning. This approach aims to reduce the number of trainable parameters without significantly sacrificing performance, thus improving efficiency. Experiments demonstrate the effectiveness of AWM in reducing fine-tuning overhead while maintaining or even slightly improving performance on various benchmarks. The work suggests a promising direction in parameter-efficient fine-tuning of LLMs by leveraging the inherent properties of RoPE and identifying which weight parameters are most crucial to adjust for improved performance on downstream tasks.
AWM: Parameter Reduction#
The proposed AWM (Angle-based Weight Masking) method offers a novel approach to parameter reduction in large language models (LLMs) fine-tuned with Rotary Position Embedding (RoPE). AWM leverages the observation that during fine-tuning, the primary changes occur in weight vector pairs with near-orthogonal angles, while those with large absolute cosine similarity remain relatively unchanged. This suggests that fine-tuning primarily affects high-level semantic information, leaving the basic syntactic information largely untouched. By identifying and fixing these stable, non-orthogonal weight pairs, AWM significantly reduces the number of trainable parameters without compromising performance, thus offering a more efficient fine-tuning strategy. The effectiveness of AWM is demonstrated experimentally, showcasing its ability to reduce overhead and maintain, or even improve, model performance on various tasks and datasets. Further research could explore the generalizability of this approach to different LLM architectures and position encoding methods.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the analysis to other positional encodings beyond RoPE would validate the generality of the findings regarding weight vector angles and their correlation with syntactic vs. semantic information processing. Investigating the impact of different architectural choices (e.g., the number of attention heads, the depth of the network) on the observed patterns would deepen our understanding. Developing more sophisticated methods for identifying and manipulating weight vectors based on their angular properties could lead to even more efficient fine-tuning strategies. A key area is investigating the causal relationship between the weight vector angles and the specific linguistic phenomena they influence, providing a more robust theoretical foundation. Finally, expanding the experimental evaluation to encompass a wider range of LLMs and downstream tasks will further strengthen the generalizability and practical significance of these insights. A deeper study into how the proposed method, Angle-based Weight Masking (AWM), interacts with other parameter-efficient fine-tuning techniques holds potential for significant improvements in LLM training efficiency.
More visual insights#
More on figures
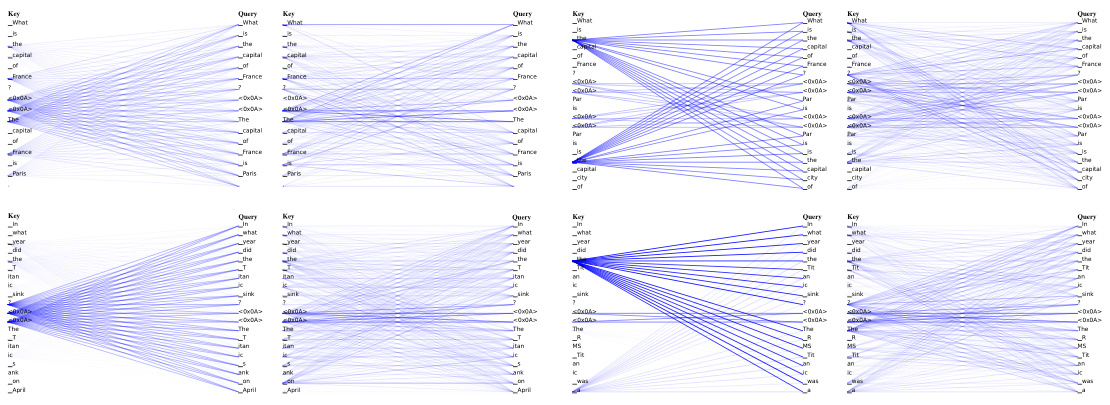
This figure visualizes attention patterns in the first layer of two LLMs (Llama-2-7b-chat and Mistral-7B-Instruct-v0.2) for the question ‘What is the capital of France?’ It compares attention heads with the highest average absolute cosine similarity (|cos a|) between weight vector pairs in RoPE to those with the lowest. Higher |cos a| values indicate attention focused on basic syntactic elements (prepositions, articles, etc.), while lower |cos a| values show attention on higher-level semantic information related to the meaning of the sentence. The visualization uses transparency to represent attention strength; darker lines mean stronger attention.

This figure displays the average absolute cosine similarity of query and key weight vector pairs across different layers of various LLMs. The plots show a consistent trend across all models: a significant decrease in cosine similarity after the initial few layers, followed by a relatively stable and low similarity for the remaining layers, before a slight increase at the very end. This suggests that different layers of LLMs focus on different aspects of information processing, potentially with early layers focusing on syntactic details and later layers on high-level semantic relations.

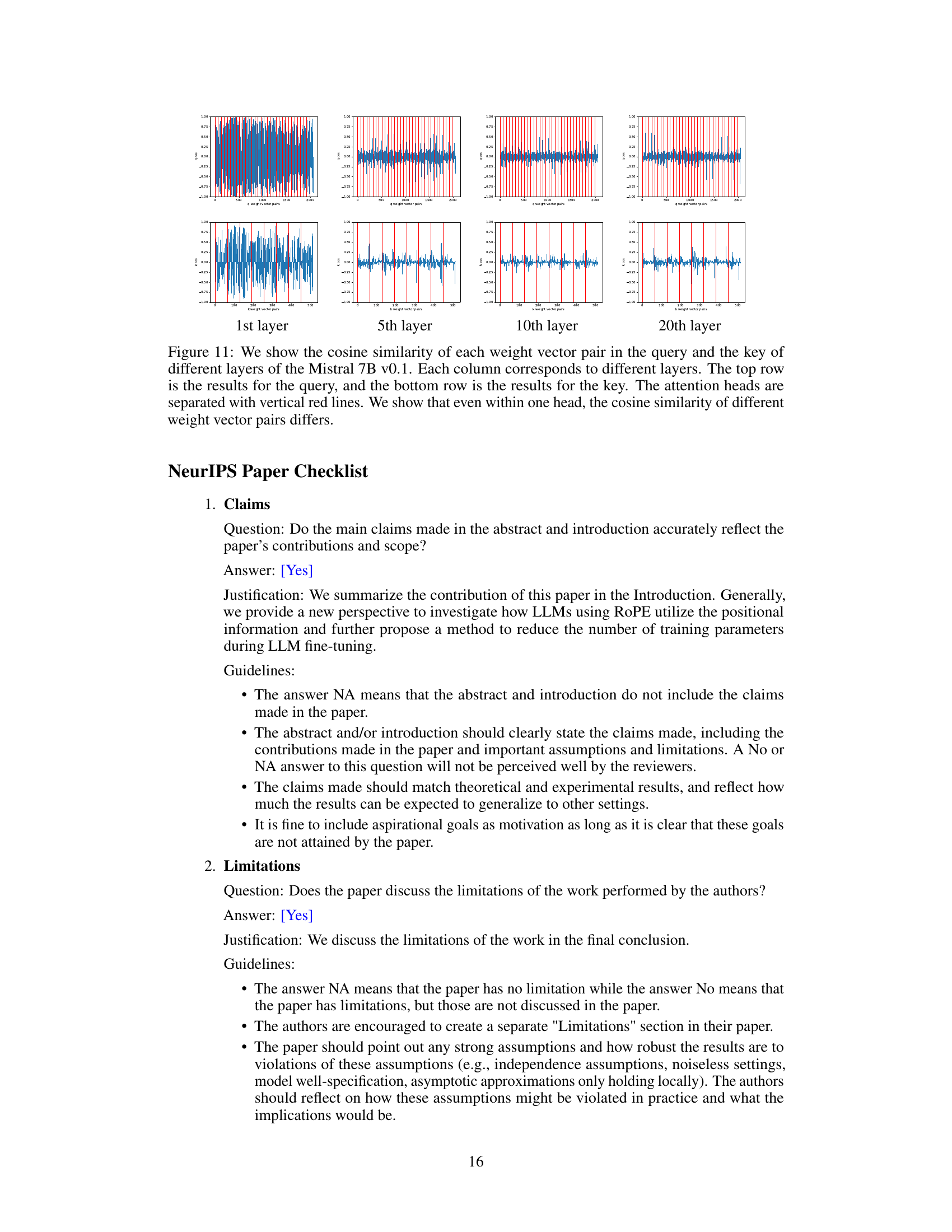
This figure visualizes the cosine similarity of weight vector pairs within the query and key components of the Llama2-7b model’s self-attention mechanism across different layers (1st, 5th, 10th, and 20th). Each column represents a layer, with the top row showing query vector pairs and the bottom row showing key vector pairs. Vertical red lines delineate individual attention heads. The visualization demonstrates the variability in cosine similarity, even within a single attention head, highlighting the diverse roles of different weight vector pairs in processing positional information.

This figure compares the base model Mistral-7B with its fine-tuned version, WizardLM-2, focusing on the cosine similarity between weight vector pairs in their query and key components. The scatter plots visualize this similarity, showing that fine-tuning primarily alters the angles between these pairs rather than significantly changing their magnitudes. Histograms illustrate the average L2 distance between weights in the base and fine-tuned models, confirming this observation and highlighting that changes are concentrated in nearly orthogonal vector pairs, especially in layers beyond the initial few. Appendix B offers further results.
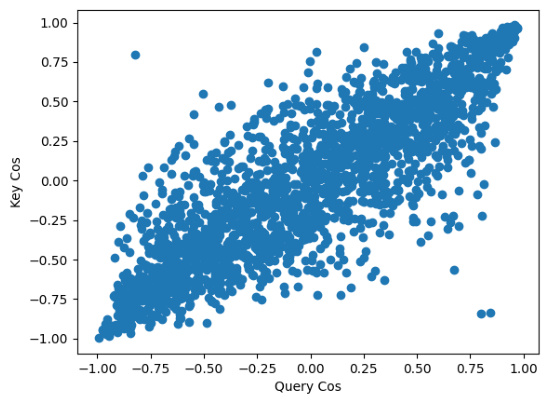
This figure shows the strong positive correlation between the cosine similarity of weight vector pairs in the query and key of the first layer of the Llama2-7b model. Each point represents a pair of weight vectors from the query and a corresponding pair from the key. The x-axis shows the cosine similarity for the query pair, and the y-axis displays the cosine similarity for the corresponding key pair. The strong positive correlation (Pearson’s r = 0.86) indicates a close relationship between how the query and key weight vectors are oriented, suggesting a coordinated role in processing positional information within the attention mechanism.

This figure shows the average L2 distance between the weight vector pairs in the query and key of different versions of LLMs across layers. The different lines represent different LLMs, comparing pre-trained models to their fine-tuned versions (e.g., Llama-2 vs. Alpaca-7b-chat). The observation highlights that fine-tuning primarily affects nearly orthogonal weight vector pairs, leading to a larger average distance in later layers.

This figure compares the base model Mistral-7B with its fine-tuned version, WizardLM-2, focusing on the cosine similarity and L2 weight distance between weight vector pairs. It shows that fine-tuning primarily alters the angles between weight vectors, particularly those that are nearly orthogonal, after the initial layers.
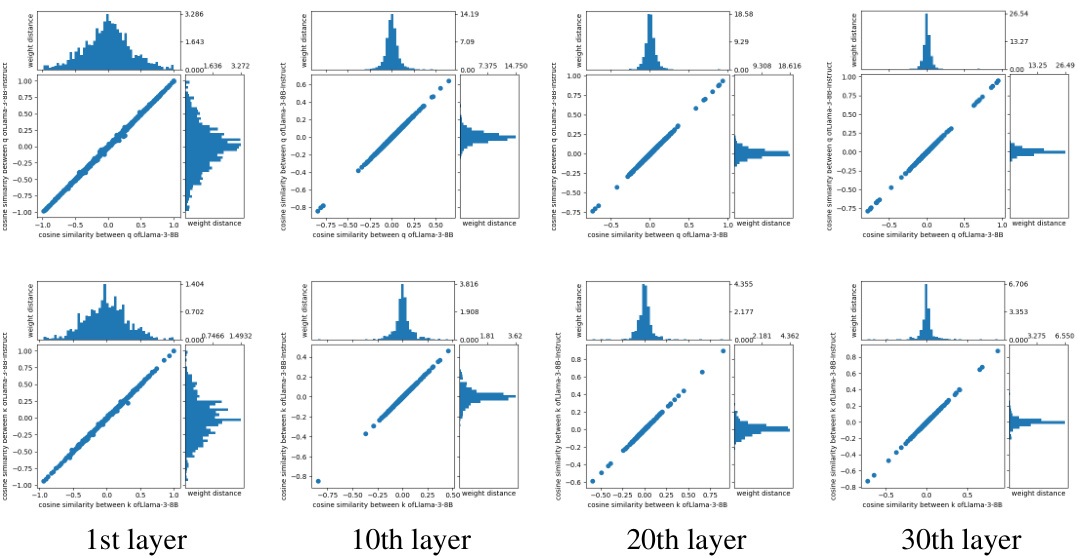
This figure compares the base model Mistral-7B with its fine-tuned version WizardLM-2, focusing on the changes in cosine similarity and L2 weight distance of weight vector pairs during fine-tuning. It shows that fine-tuning primarily affects the angles between nearly orthogonal weight vector pairs, especially in layers beyond the initial ones.

This figure visualizes attention patterns in the first layer of two LLMs (Llama-2-7b-chat and Mistral-7B-Instruct-v0.2) to show the relationship between the angle of weight vector pairs in RoPE and the attention focus. Attention heads with high average absolute cosine similarity (|cos a|) are shown to focus on basic syntactic information (e.g., prepositions, articles), while those with low |cos a| focus more on high-level semantics. Lower transparency indicates higher attention.

This figure visualizes the cosine similarity of weight vector pairs within the query and key components of the Llama2-7b model’s self-attention mechanism across different layers (1st, 5th, 10th, and 20th). Each column represents a layer, with the top row showing query results and the bottom row showing key results. Vertical red lines delineate individual attention heads. The visualization demonstrates that even within a single attention head, the cosine similarity varies significantly between different pairs of weight vectors.
Full paper#