↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
The rising availability of various sized Language Models (LLMs) presents a challenge: choosing the optimal model for a task while balancing cost and performance. Current model-switching approaches often rely on separate, trained routing models, which requires significant amounts of task-specific data and are unsuitable for black-box LM APIs. Additionally, self-verification mechanisms for assessing the reliability of LLM outputs are often noisy and unreliable.
AutoMix tackles these challenges with a two-pronged approach. First, it uses a novel few-shot self-verification method that leverages the context to estimate output accuracy without needing to train a separate model. Second, it employs a Partially Observable Markov Decision Process (POMDP) based router to make informed model selection decisions based on the confidence scores from self-verification. Experiments demonstrate that AutoMix consistently surpasses baselines, achieving significant cost reduction (over 50%) while maintaining comparable performance across diverse tasks and models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AutoMix, a novel and efficient approach to leverage the diverse range of large language models (LLMs) available. It addresses the critical issue of optimizing cost-performance tradeoffs in LLM usage, which is of significant practical relevance to many researchers and practitioners. AutoMix’s ability to operate on black-box APIs and learn robust policies from limited data opens exciting new research directions in resource-efficient LLM deployment. The method’s simplicity and potential for broad applicability across various LLM setups and tasks makes it highly impactful.
Visual Insights#
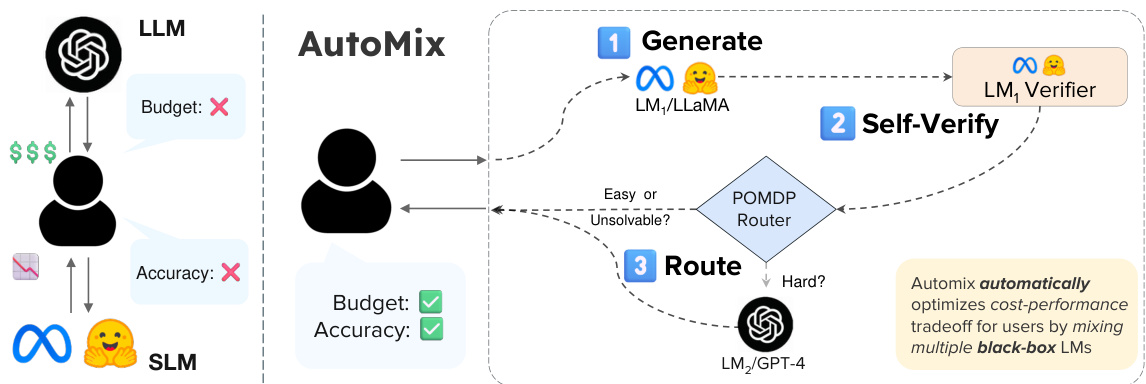
This figure illustrates the AutoMix framework’s workflow with two language models (a small model, SLM, and a large model, LLM). AutoMix routes queries to the appropriate model based on cost and accuracy, dynamically switching between them. The process involves three steps: (1) Generation: The SLM generates an initial response. (2) Self-Verification: The SLM verifies the accuracy of its own response. (3) Routing: A POMDP (Partially Observable Markov Decision Process) router uses the verification results to decide whether to send the query to the LLM (if the initial response is deemed unreliable) or to return the SLM’s response directly (if the initial response is considered sufficient). The cycle repeats for setups with more than two models.
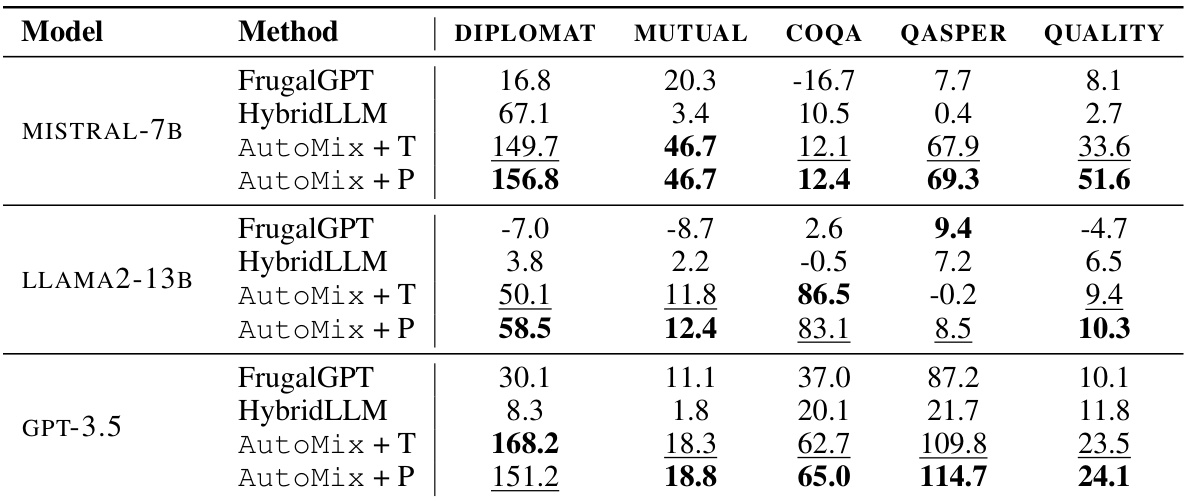
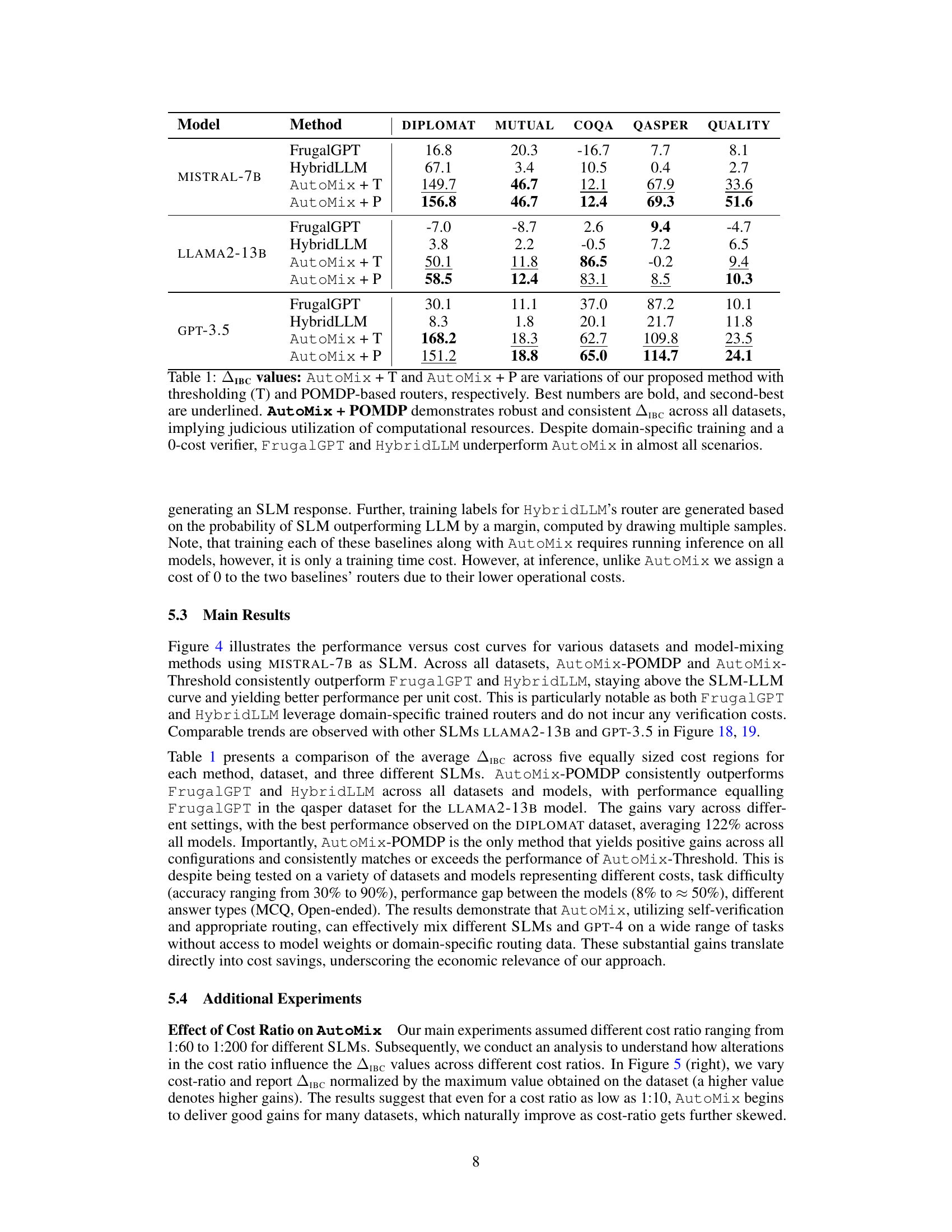
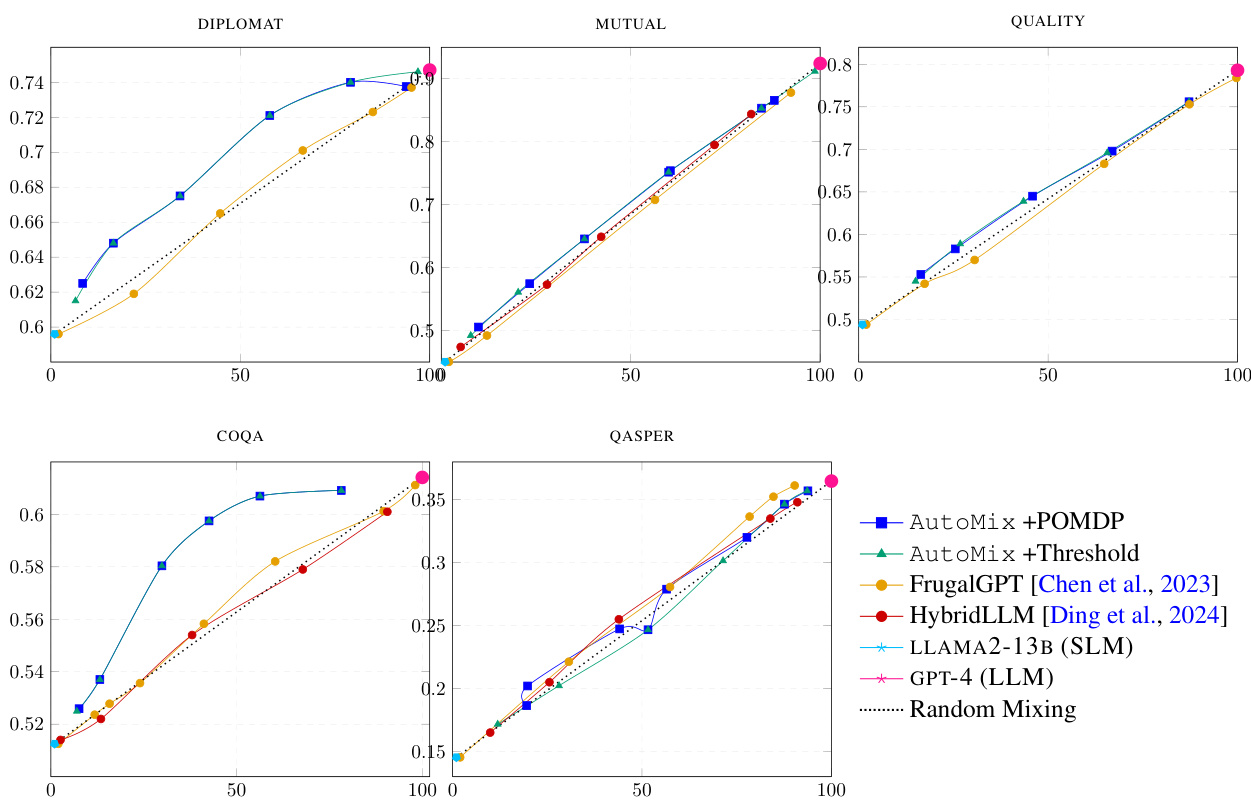
This table presents the Incremental Benefit per Cost (IBC) values for different model-mixing methods across five datasets and three different smaller language models (SLMs). It compares AutoMix (with thresholding and POMDP-based routers) against baselines FrugalGPT and HybridLLM. Higher AIBC values indicate better cost-performance tradeoffs. AutoMix consistently outperforms the baselines, showing improved efficiency in leveraging language models for various tasks.
In-depth insights#
AutoMix’s Core#
AutoMix’s core functionality revolves around strategic query routing to multiple language models (LMs) of varying sizes. This is achieved through a three-step process: (1) a smaller LM generates an initial answer; (2) a self-verification mechanism assesses the answer’s reliability using entailment; and (3) a Partially Observable Markov Decision Process (POMDP) based router selects an appropriately sized LM based on answer confidence. The novelty lies in its few-shot self-verification technique, which efficiently estimates reliability without extensive training, and the robust POMDP router which accounts for uncertainty in self-verification, dynamically optimizing cost-performance trade-offs. AutoMix’s approach avoids training separate routing models, leverages existing LLM APIs directly, and effectively handles challenging real-world tasks that are complex or potentially unsolvable. The combination of efficient self-verification and a principled router allows AutoMix to surpass conventional methods, reducing computational cost with comparable or better performance.
Few-Shot Verification#
The concept of ‘Few-Shot Verification’ in the context of large language models (LLMs) is a crucial advancement, addressing the challenge of evaluating LLM outputs without extensive training data. It leverages the inherent capabilities of LLMs for self-assessment, significantly reducing the need for large, task-specific verification datasets. This approach is particularly valuable when dealing with black-box models, where internal parameters are inaccessible, rendering traditional training methods impractical. The core idea involves using a small number of examples to ’teach’ the LLM how to evaluate its own responses. The success of this technique hinges on the design of effective prompting strategies that guide the LLM towards accurate self-evaluation. A key benefit is the reduction of computational costs associated with training separate verification models. However, a critical limitation is the potential for noise and inconsistency in the LLM’s self-assessments. This noise stems from the inherent limitations of LLMs in reasoning and the complexities of natural language understanding. Therefore, robust methods for mitigating this noise and ensuring reliable verification are necessary for practical applications. Future research should focus on improving prompt engineering techniques and developing more sophisticated mechanisms for handling the inherent uncertainty associated with few-shot self-evaluation.
POMDP Router#
The core of AutoMix lies in its novel POMDP router, a significant departure from traditional model-switching methods. Instead of relying on separate, trained routing models, AutoMix leverages a partially observable Markov decision process (POMDP) to dynamically select the optimal language model (LM) based on the noisy output of a self-verification mechanism. This inherent uncertainty in the self-verification process is directly addressed by the POMDP framework. The POMDP’s ability to handle uncertainty is crucial as the self-verification mechanism isn’t perfectly accurate. By modeling question difficulty as hidden states and using the self-verification confidence scores as noisy observations, the POMDP router learns a policy that effectively balances cost and quality. This results in a system that robustly adapts to different model combinations, cost ratios and even limited training data, exceeding the performance of prior approaches. The POMDP’s flexibility and ability to learn from limited data are key strengths, making it particularly well-suited for real-world applications with varying resource constraints. The router’s design effectively captures the trade-off between cost and performance inherent in utilizing LLMs of different sizes, making it a truly adaptive and efficient solution for managing complex language tasks.
Empirical Results#
An effective ‘Empirical Results’ section would meticulously detail experimental setup, including datasets, metrics, baselines, and parameter choices. It should then present the results clearly, using visualizations (graphs, tables) to highlight key findings. Statistical significance of the results needs clear reporting. The discussion should analyze the results in detail, explaining both expected and unexpected findings. Comparisons to baselines should be thorough and insightful, identifying whether improvements are statistically significant and practically relevant. The writing should be concise and focused, with a logical flow from experimental design to interpretation of results, enabling the reader to understand the implications and limitations of the findings.
Future Works#
Future work could explore several promising avenues. Extending AutoMix to handle more diverse LLM types and architectures beyond the current five would broaden its applicability and robustness. Investigating more sophisticated routing strategies, potentially incorporating reinforcement learning or other adaptive methods, could further optimize cost-performance trade-offs. A key area for improvement lies in enhancing the few-shot self-verification mechanism, perhaps by employing larger language models or external knowledge sources for more reliable confidence estimations. Finally, a comprehensive analysis of AutoMix’s performance across a wider range of tasks and datasets would solidify its capabilities and highlight potential limitations, guiding future refinements and development.
More visual insights#
More on figures

This figure illustrates the workflow of AutoMix using two language models (small and large). AutoMix makes use of a small model to generate an answer, then uses self-verification to assess the answer’s reliability before deciding whether to use a larger model to improve the answer. This process balances cost and accuracy, making it efficient and adaptable.

This figure shows an example of how AutoMix’s self-verification mechanism works. A smaller language model (LLAMA2-13B) generates an answer to a question (‘When did Shen Nong drink tea?’). The same model then acts as a verifier, comparing the generated answer (‘He took it in 1990.’) against the provided context. Because the context does not support the generated answer, the verifier correctly identifies it as incorrect.

The left panel shows the AutoMix algorithm’s flowchart. It details the process: generating an answer using a small language model (SLM), verifying the answer using self-verification, and then routing to a larger language model (LLM) if the verification result is below a threshold. The right panel displays a performance versus cost curve. It illustrates how different methods (e.g., using only SLM, only LLM, or a model-mixing method) perform concerning accuracy and cost. The slope of the line from SLM to a specific point on the curve represents the incremental benefit per cost (IBC). A positive IBC indicates that the method is cost-effective in enhancing performance.
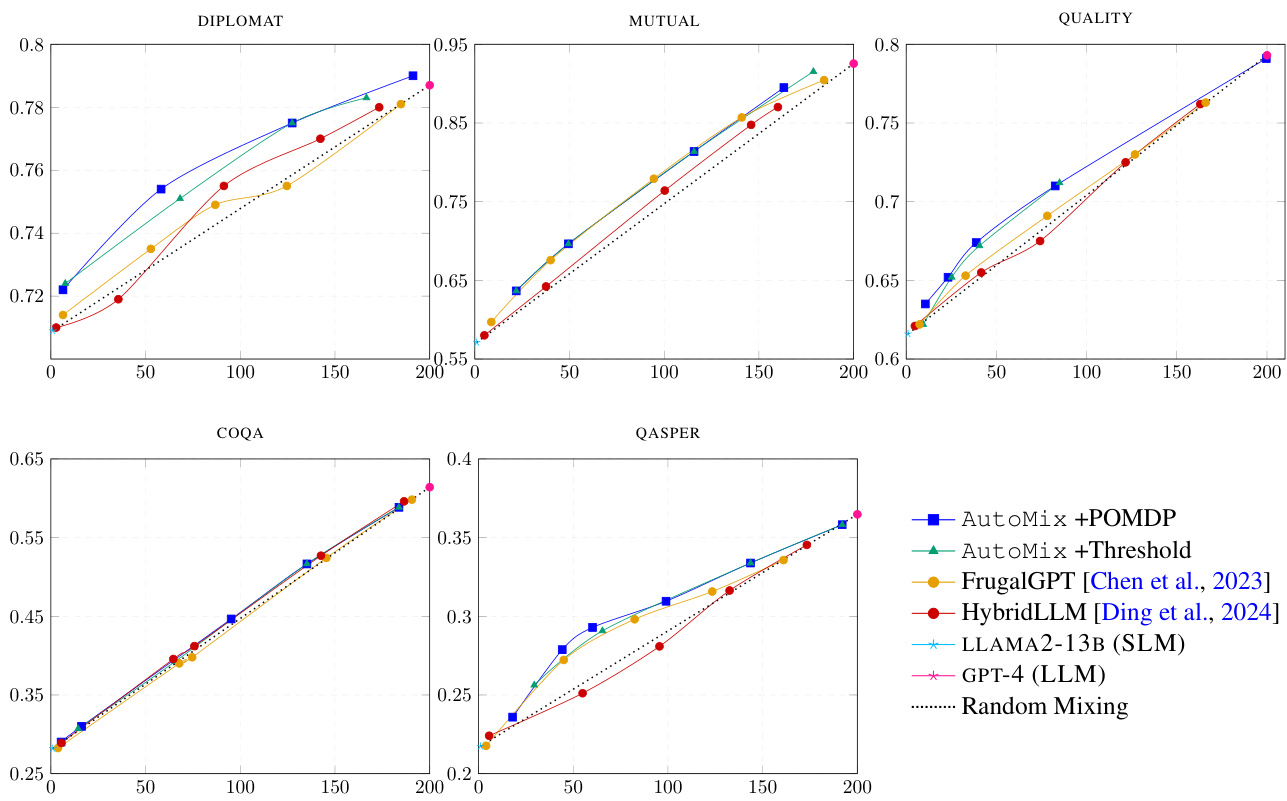
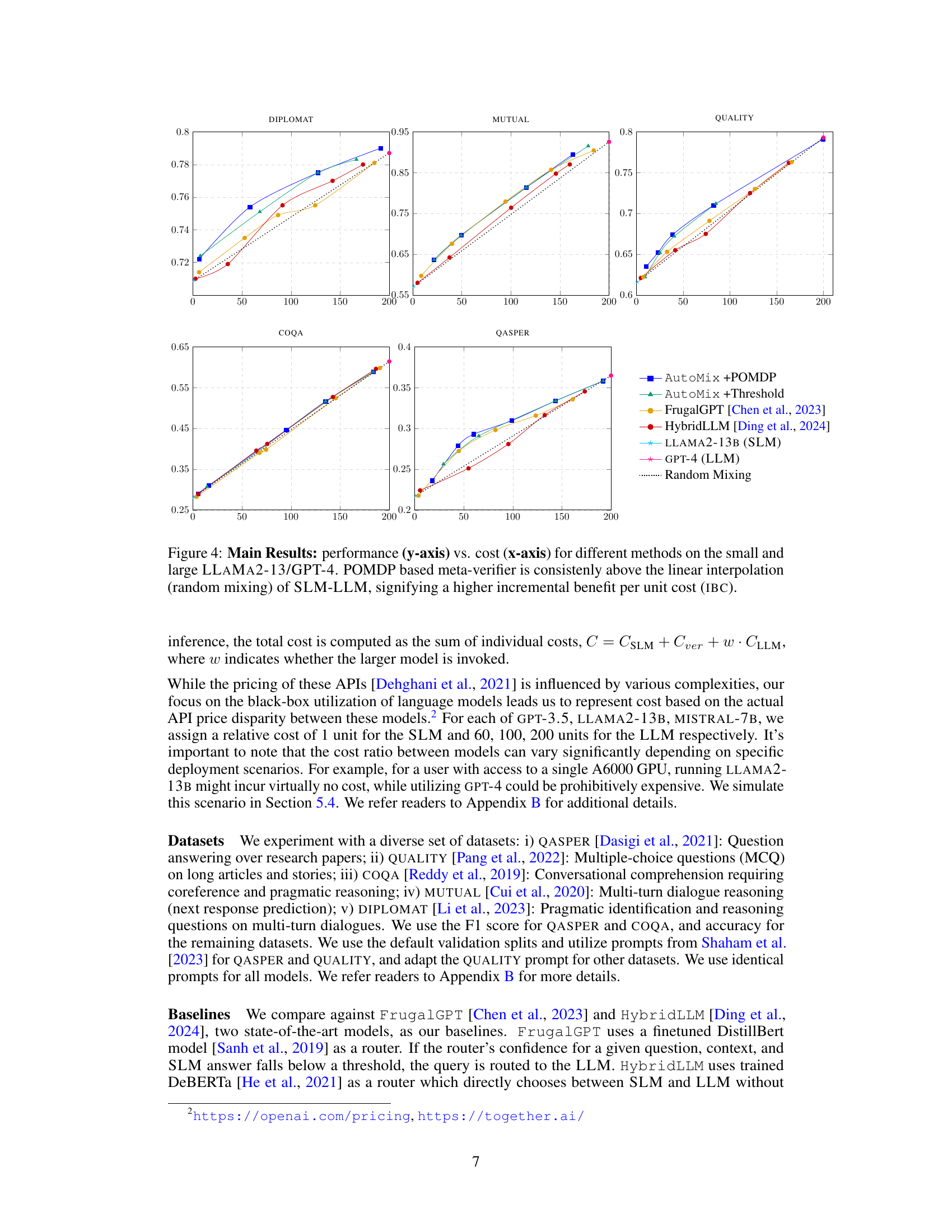
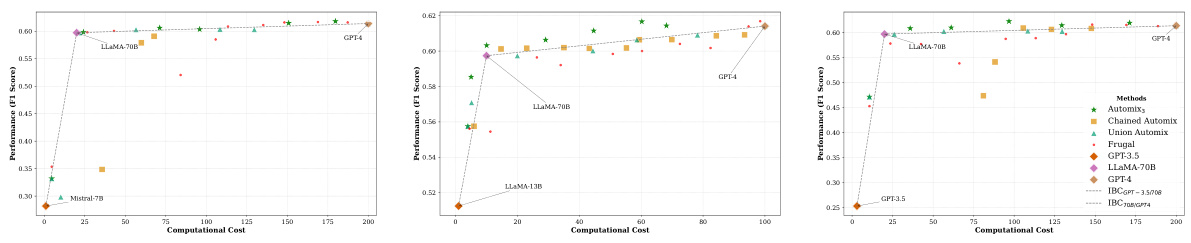
This figure presents the performance versus cost curves for various methods, comparing AutoMix (with POMDP and thresholding) against FrugalGPT, HybridLLM, and baselines (using only SLM or LLM). It demonstrates that AutoMix consistently surpasses baselines across multiple datasets, achieving better performance for a given cost or lower cost for comparable performance. The slope of the curves illustrates the incremental benefit per cost (IBC).
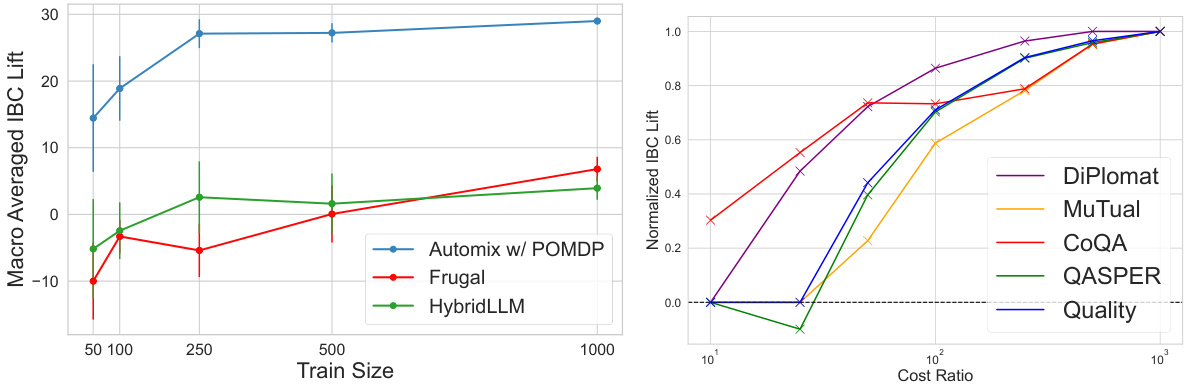
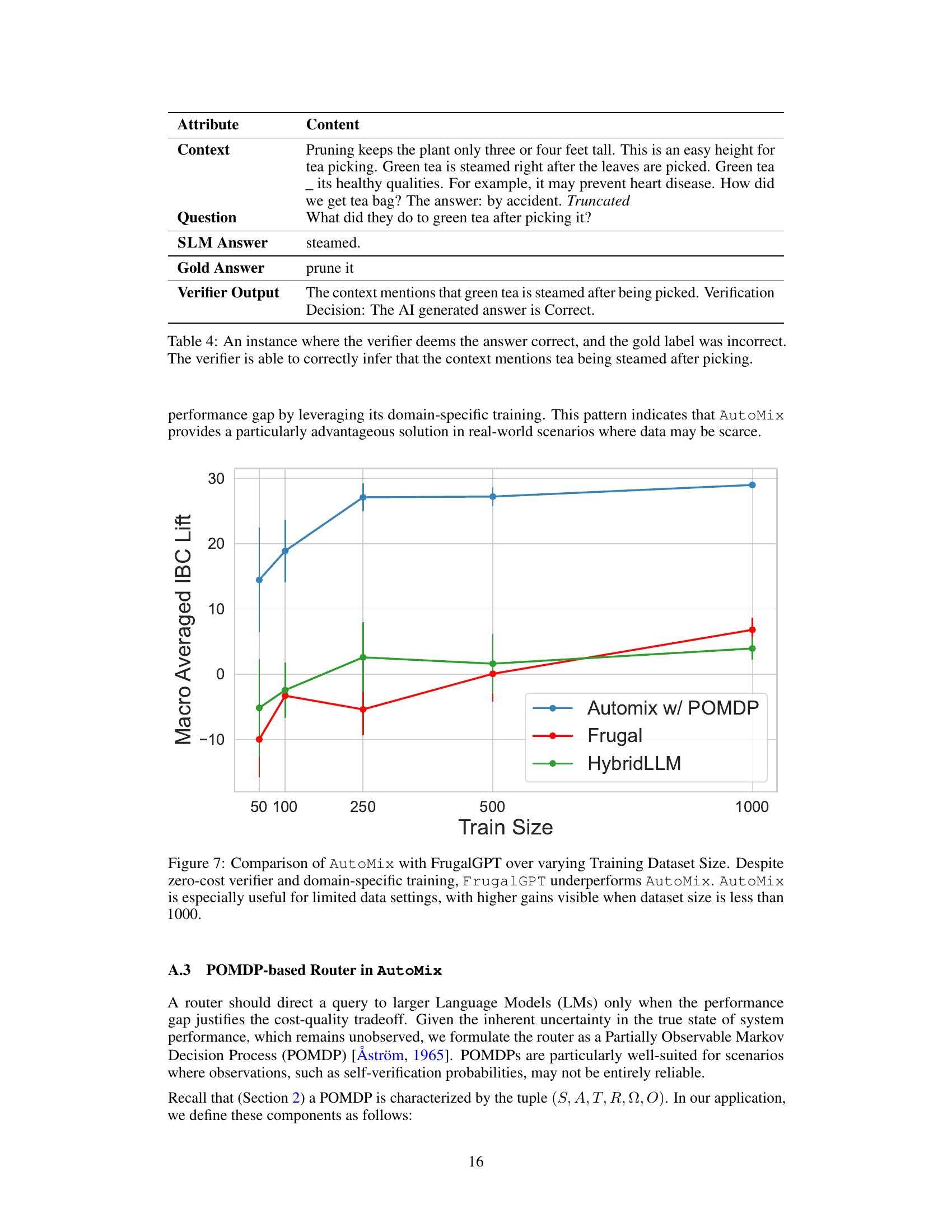
The left plot compares the performance of AutoMix against FrugalGPT and HybridLLM for different sizes of training data. It shows that AutoMix consistently outperforms the baselines, even with small datasets. The right plot shows the normalized AIBC (incremental benefit per cost) for different cost ratios between the large and small models. It demonstrates that AutoMix maintains its advantage across a range of cost ratios.
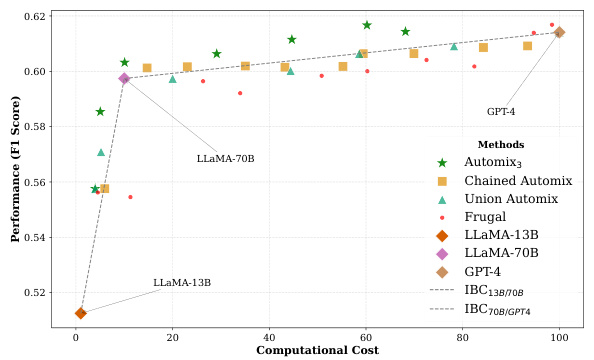
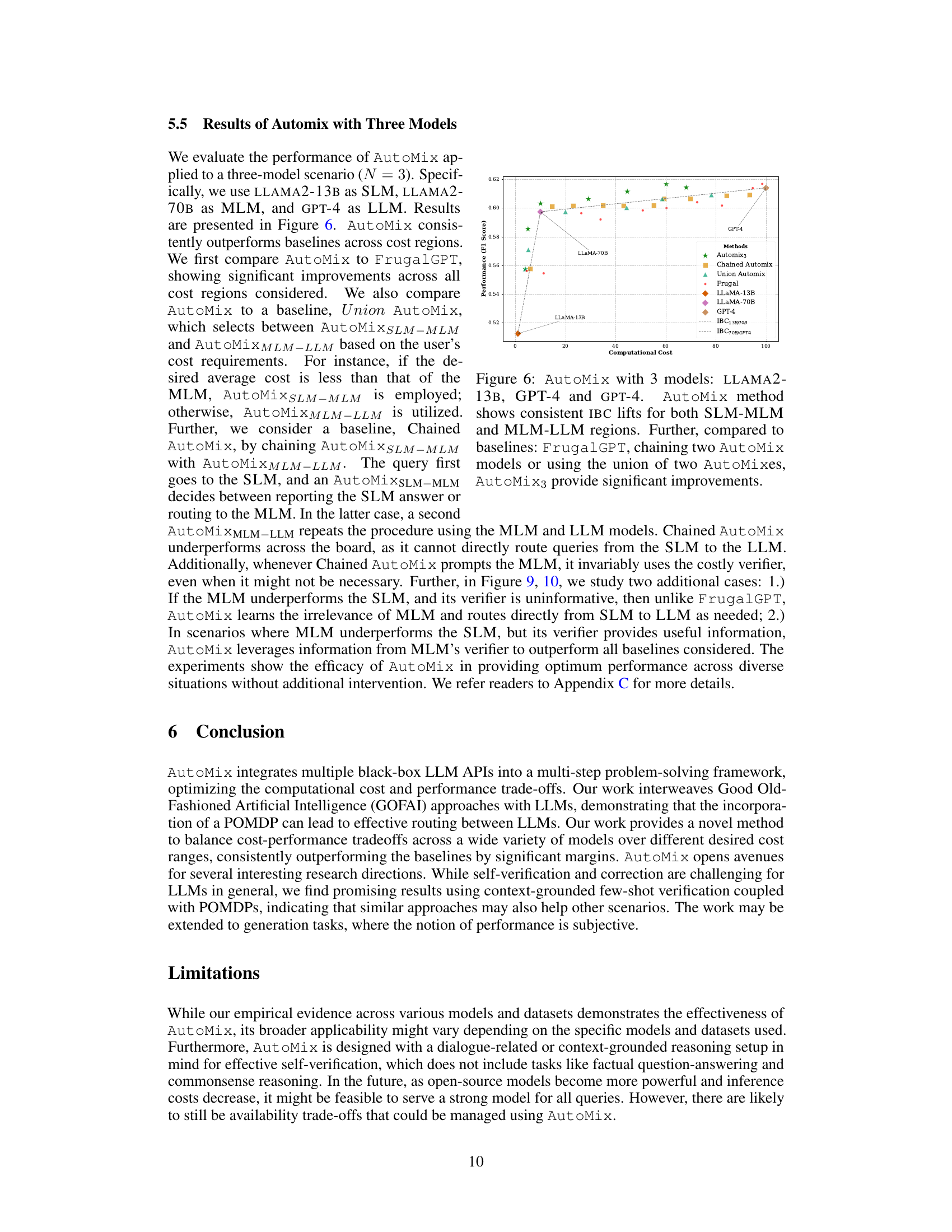
This figure compares AutoMix’s performance with three models (LLAMA2-13B, LLAMA2-70B, GPT-4) against baselines (FrugalGPT, Chained AutoMix, Union AutoMix). It shows AutoMix consistently outperforms on both cost regions (SLM-MLM and MLM-LLM) and demonstrates higher incremental benefit per cost (IBC).
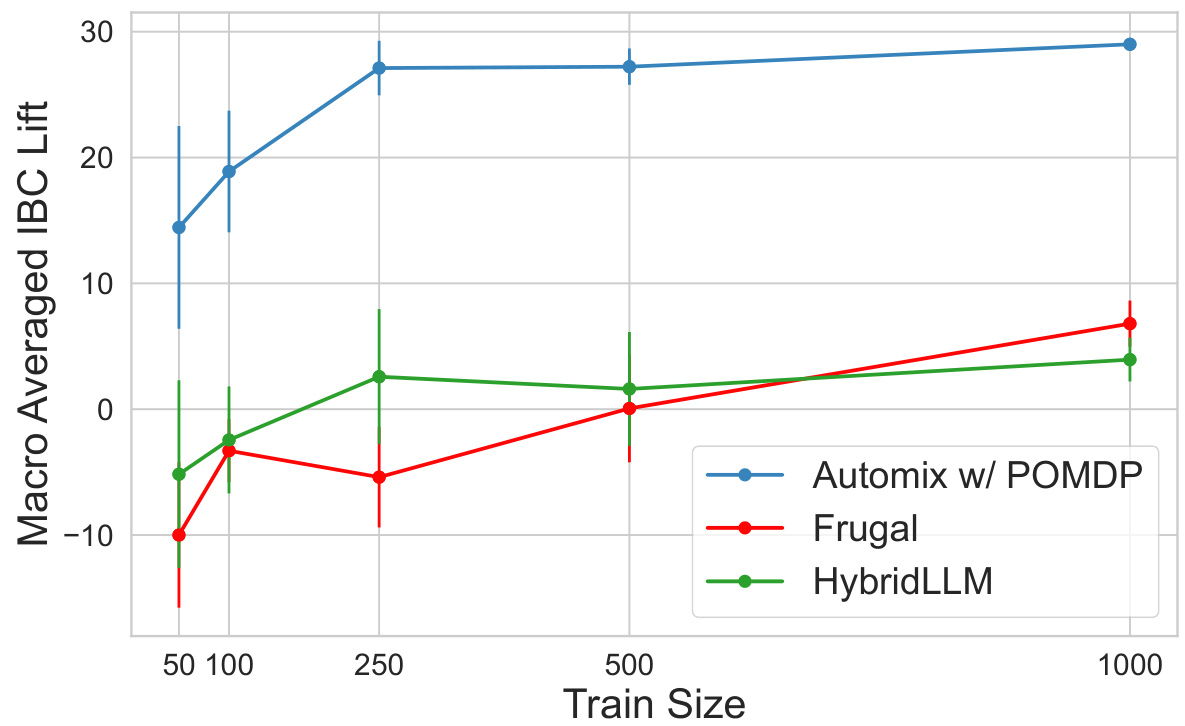
This figure compares the performance of AutoMix and two baseline methods (FrugalGPT and HybridLLM) across different training dataset sizes. It demonstrates that AutoMix consistently outperforms the baselines, especially when the training data is limited. The performance gap between AutoMix and the baselines becomes less pronounced as the training dataset size increases, highlighting AutoMix’s effectiveness in low-resource settings.

This figure shows the performance comparison between AutoMix and several baselines across different cost ranges using three language models (LLMs): LLAMA2-13B, LLAMA2-70B, and GPT-4. The x-axis represents computational cost, and the y-axis represents performance (F1 score). AutoMix consistently outperforms the baselines across the different cost ranges, indicating a better cost-performance trade-off. The baselines include FrugalGPT, Chained AutoMix, and Union AutoMix, each representing different strategies for combining the three models.

This figure shows the performance versus cost curves for different model-mixing methods using MISTRAL-7B as the smaller language model (SLM). AutoMix consistently outperforms baselines (FrugalGPT and HybridLLM), maintaining better performance per unit cost across all datasets. The POMDP-based meta-verifier consistently surpasses the linear interpolation of SLM-LLM, demonstrating improved incremental benefit per cost.

This figure shows the performance (y-axis, F1 score) vs. cost (x-axis, computational cost) for different methods using three models: LLAMA2-13B (SLM), LLAMA2-70B (MLM), and GPT-4 (LLM). AutoMix consistently outperforms baselines (FrugalGPT, Chained AutoMix, Union AutoMix) across all cost regions, demonstrating higher incremental benefit per cost (IBC). The consistent improvement suggests AutoMix effectively leverages the strengths of multiple models for optimal cost-performance balance.

This figure compares the cost-performance tradeoffs of different methods for question answering. The x-axis represents the computational cost, while the y-axis shows the performance (F1 score). The methods being compared include AutoMix with a POMDP-based router, AutoMix with a threshold-based router, FrugalGPT, HybridLLM, using only the small language model (SLM), using only the large language model (LLM), and random model selection. The figure demonstrates that AutoMix with the POMDP router consistently outperforms other methods, achieving higher performance at lower costs. The superior performance is highlighted by its curve lying above the linear interpolation between the SLM and LLM baselines, indicating a higher incremental benefit per cost (IBC).
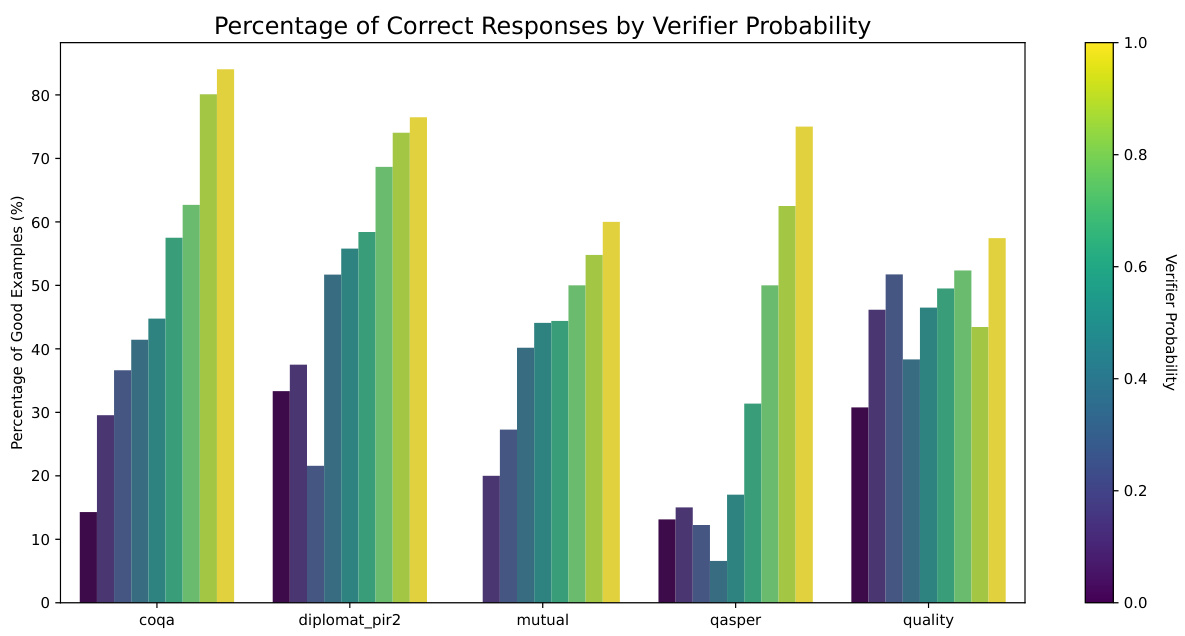
This figure shows the relationship between the verifier’s confidence (probability) in its assessment of an answer’s correctness and the actual correctness of the answer across multiple datasets. It demonstrates that higher verifier confidence generally correlates with higher accuracy, indicating the effectiveness of the self-verification process despite some noise. This is a key justification for using the verifier’s output as input for the POMDP routing algorithm.
This figure compares the performance and cost of different methods for question answering using two large language models (LLMs): LLAMA2-13B (smaller model) and GPT-4 (larger model). The x-axis represents the computational cost, and the y-axis represents the performance (likely accuracy or F1 score). The graph shows that AutoMix with a POMDP-based router consistently outperforms baselines and a random mixing strategy. This demonstrates that AutoMix effectively balances performance and cost by strategically routing queries to the appropriate model.
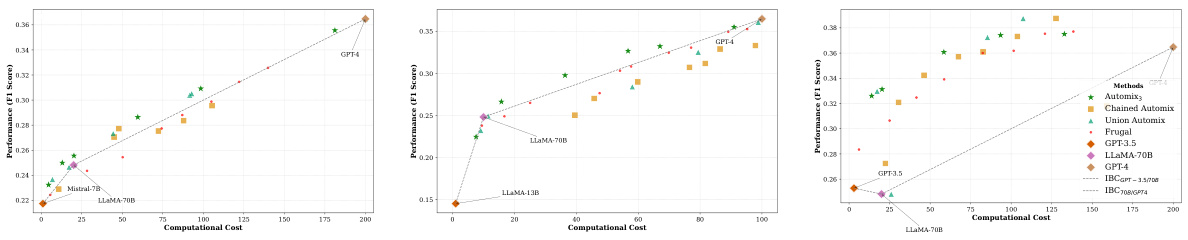
This figure demonstrates the performance of AutoMix with three language models (LLAMA2-13B, LLAMA2-70B, and GPT-4) across various computational costs. It compares AutoMix’s performance to several baselines: FrugalGPT, a chained AutoMix approach (sequentially applying AutoMix to smaller and then larger models), and a union AutoMix approach (selecting the best-performing of two AutoMix configurations). AutoMix consistently surpasses these baselines, showing a greater improvement in incremental benefit per cost (IBC) in both smaller and larger model usage scenarios.

This figure displays the performance versus cost curves for various model-mixing methods using MISTRAL-7B as the small language model (SLM) across five datasets. It shows AutoMix consistently outperforms baselines (FrugalGPT and HybridLLM) and demonstrates a higher incremental benefit per unit cost (IBC) compared to a baseline of simply using either a small or large language model. The POMDP-based meta-verifier in AutoMix is particularly effective.
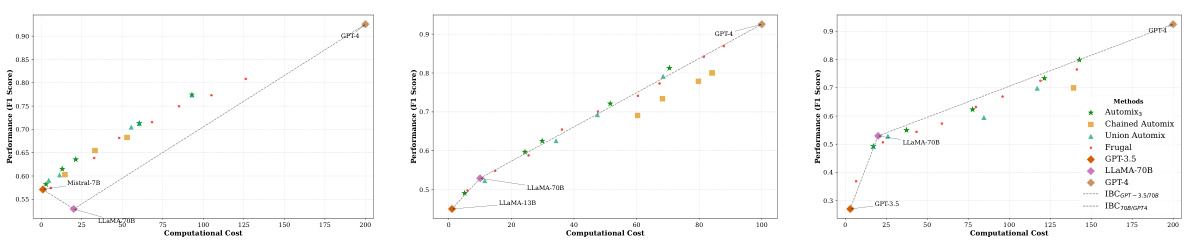
The figure compares the cost-performance tradeoffs of different methods for question answering using two language models (LLMs). The x-axis represents the computational cost, and the y-axis represents the performance (F1-score). The results show that AutoMix, using a POMDP-based router, consistently outperforms baselines, achieving better performance at lower costs compared to simply using a small or large LLM alone. The superior performance of AutoMix is highlighted by its steeper slope than the linear interpolation between the single small and large model results, demonstrating a greater incremental benefit per unit cost (IBC).
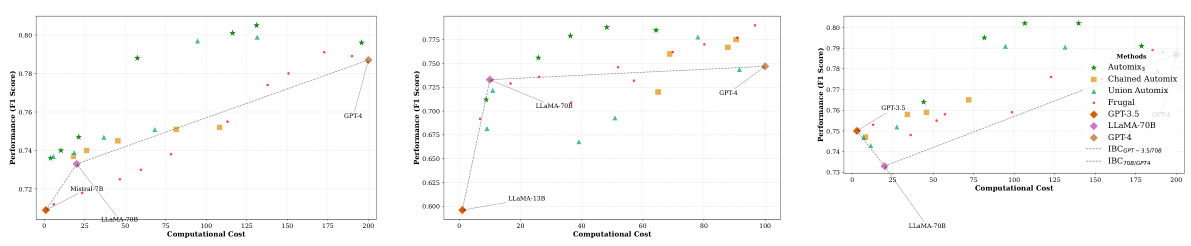
The figure compares different model-mixing methods on two LLMs (LLAMA2-13B and GPT-4), plotting performance against cost. AutoMix with the POMDP-based router consistently outperforms baselines and random mixing, demonstrating a steeper slope (higher incremental benefit per cost - IBC) indicating better cost-efficiency.
This figure compares different model-mixing methods’ performance against cost. AutoMix with the POMDP-based router consistently outperforms baselines and shows a steeper slope than the linear interpolation between the small and large language models (SLM and LLM), indicating higher incremental benefit per cost (IBC).
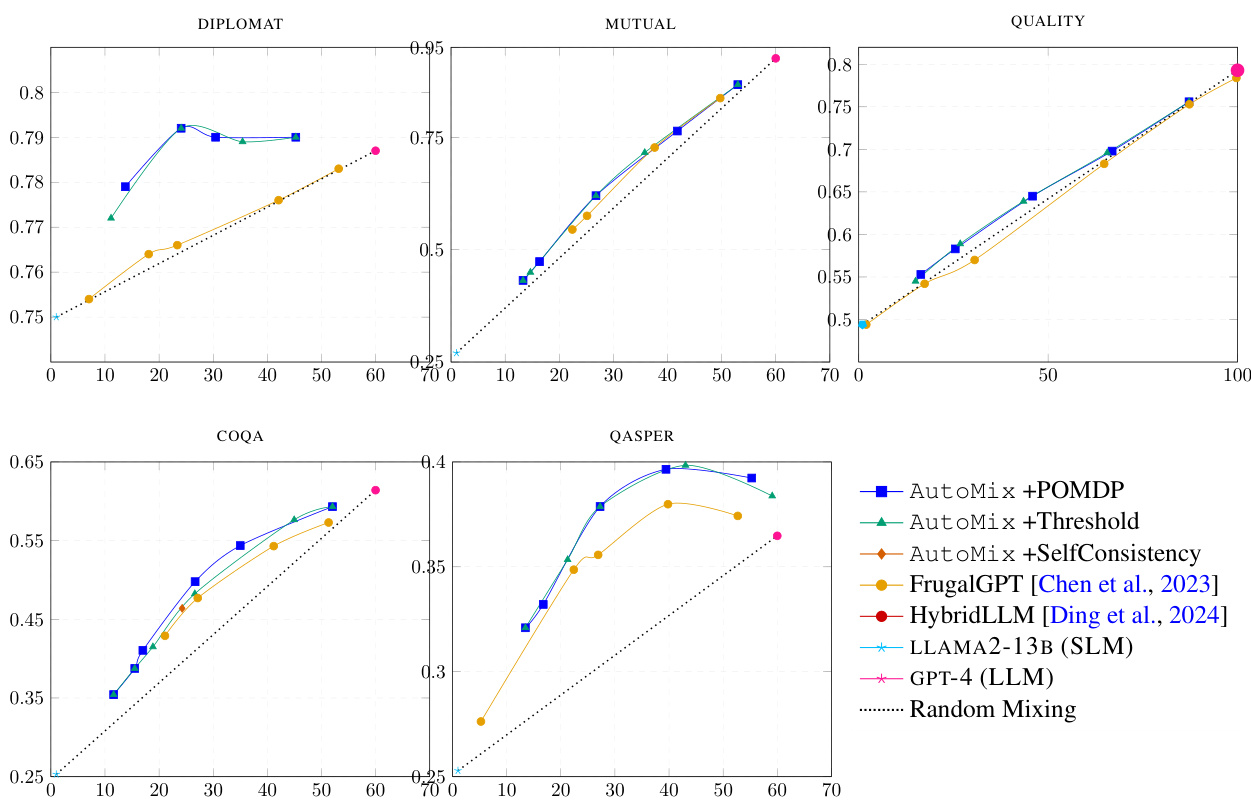
This figure compares the performance and cost of different methods (AutoMix with POMDP and thresholding, FrugalGPT, HybridLLM, using only the small language model (LLM), using only the large language model (LLM), and random mixing) on the LLAMA2-13B and GPT-4 language models. The y-axis represents performance, and the x-axis represents cost. The results show that AutoMix with POMDP consistently outperforms the other methods, achieving higher performance at a lower cost. The slope of the line connecting SLM and LLM points represents the incremental benefit per cost (IBC) baseline. AutoMix with POMDP consistently outperforms the baseline.
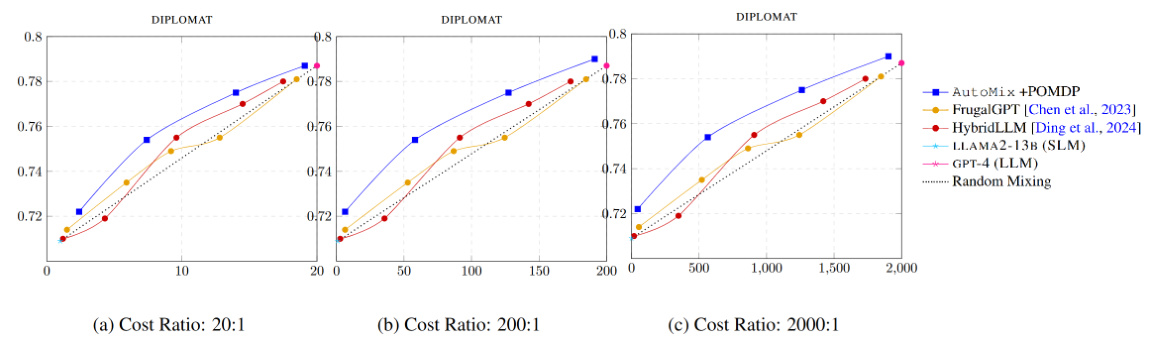
This figure compares the performance of AutoMix against FrugalGPT and HybridLLM across different cost ratios between the large language model (LLM) and the smaller language model (SLM). The x-axis represents the computational cost, and the y-axis represents the performance (F1-score) on the DIPLOMAT dataset. Three cost ratios (20:1, 200:1, and 2000:1) are shown, illustrating AutoMix’s consistent superior performance across various cost scenarios.

This figure shows the performance vs. cost curves for various methods on two language models (LLAMA2-13B and GPT-4). AutoMix using POMDP and thresholding methods consistently outperforms baselines and random model selection, demonstrating its efficiency in balancing cost and performance. The slope of each method’s curve shows the incremental benefit per unit cost (IBC).

This figure compares the cost-performance trade-offs of different model-mixing methods, including AutoMix with a POMDP-based router, against baselines. The results show that AutoMix consistently outperforms baselines by achieving better performance at a lower cost. The POMDP-based approach demonstrates a significantly better cost-performance trade-off than the linear interpolation of using only small or large language models.
More on tables

This table presents the incremental benefit per cost (IBC) values for different model-mixing methods across five datasets. It compares the performance of AutoMix (with thresholding and POMDP-based routing) against baselines like FrugalGPT and HybridLLM. Higher AIBC values indicate greater cost-effectiveness in enhancing model performance.

This table presents the Incremental Benefit per Cost (IBC) lift, which compares the efficiency of performance enhancement relative to the additional cost for different model-mixing methods (AutoMix with thresholding and POMDP, FrugalGPT, HybridLLM) across five datasets and three different base models (MISTRAL-7B, LLAMA2-13B, GPT-3.5). A positive lift indicates cost-effective performance improvements compared to the baseline of always using the large language model (LLM).

This table presents the results of comparing AutoMix’s performance with two baseline methods (FrugalGPT and HybridLLM) across five different datasets. The AIBC (Incremental Benefit per Cost) metric is used to assess the cost-effectiveness of each method, showing how much performance is gained relative to the additional cost incurred. AutoMix consistently outperforms the baselines, demonstrating its superior efficiency in using computational resources.

This table presents the results of the Incremental Benefit per Cost (IBC) metric for different model-mixing methods across five datasets and three language models. It compares AutoMix (with threshold and POMDP routing) against FrugalGPT and HybridLLM baselines. The AIBC metric shows how much more efficiently each method improves performance compared to simply using the larger model alone, considering the additional costs involved.

This table presents the results of an out-of-domain generalization experiment to evaluate the generalizability of AutoMix. The router was trained on one dataset and then evaluated on the remaining four datasets. This process was repeated for all five datasets. The table shows that AutoMix significantly outperforms both FrugalGPT and HybridLLM across all three language models (Mistral-7b, LLAMA-13b, and GPT-3.5) and five datasets.
Full paper#