TL;DR#
Current identity customization methods for text-to-image models either require extensive fine-tuning, impacting efficiency, or suffer from low ID fidelity and significant disruption of the original model’s functionality. Existing tuning-free approaches often compromise either ID fidelity or the ability to control other image aspects via prompts. This paper introduces PuLID, which tackles these issues.
PuLID leverages a novel contrastive alignment strategy within a “Lightning T2I” branch alongside a standard diffusion branch. This dual-branch approach employs contrastive and accurate ID loss functions to maintain ID fidelity while minimizing the alteration of original model behavior. Experiments demonstrate PuLID’s superior performance in ID fidelity, editability, and preservation of image elements such as background and lighting, compared to existing methods. The tuning-free nature and enhanced efficiency of PuLID make it highly valuable for practical applications and future research.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel tuning-free approach to identity (ID) customization in text-to-image generation, a significant challenge in the field. It addresses the limitations of existing methods by maintaining high ID fidelity while minimizing interference with the original model’s behavior. This work is relevant to current trends in AI personalization and opens new avenues for research into more efficient and effective ID customization techniques, paving the way for more sophisticated and versatile text-to-image models. Its contrastive alignment strategy and novel loss function offer valuable insights for researchers working on diffusion models and image generation.
Visual Insights#

🔼 This figure shows several examples of identity customization using different methods, including IPAdapter, InstantID, and the proposed PuLID method. Each column represents a different image prompt and style, and each row shows the results generated using a different technique. The ‘Input’ row shows the original image prompt. The goal is to show that PuLID (the authors’ method) generates images with high identity fidelity while retaining the style and other details of the original prompt better than competing methods. This illustrates the core contribution of the paper: a high-fidelity, tuning-free identity customization technique.
read the caption
Figure 1: We introduce PuLID, a tuning-free ID customization approach. PuLID maintains high ID fidelity while effectively reducing interference with the original model's behavior.

🔼 This table presents a quantitative comparison of the proposed PuLID method against three other state-of-the-art identity customization methods (PhotoMaker, IPAdapter, and InstantID). The comparison is done using two different datasets (DivID-120 and Unsplash-50) and three evaluation metrics: Face Similarity (Face Sim.), CLIP Text Similarity (CLIP-T), and CLIP Image Similarity (CLIP-I). Higher values for all metrics indicate better performance. The asterisk (*) next to PhotoMaker indicates that its results are presented for the SDXL-base model instead of SDXL-Lightning due to compatibility issues.
read the caption
Table 1: Quantitative comparisons. *We observed that PhotoMaker shows limited compatibility with SDXL-Lightning, hence, we compare its performance on SDXL-base in this table.
In-depth insights#
Tuning-Free ID Adapt#
Tuning-free ID adaptation methods in text-to-image generation aim to personalize models without the need for extensive fine-tuning on individual identities. This is crucial for efficiency and scalability. Existing approaches often rely on embedding identity features into pre-trained models via an adapter, using encoders like CLIP or face recognition networks. However, this often leads to style degradation or interference with the original model’s behavior, as the embedded identity information might conflict with other image aspects such as background, lighting, and composition. A key challenge is maintaining high ID fidelity while ensuring semantic consistency. Novel methods are needed to overcome the current limitations, potentially by introducing contrastive learning to align identity-specific features with other contextual information without disrupting the original model’s generative capacity. Careful attention to the loss functions is crucial. Using a more precise method for evaluating identity loss in a setting closer to the actual generation process could significantly improve results. The ability to customize and precisely control identity, while preserving semantic consistency across different attributes specified by the prompts, remains an open problem.
Contrastive Alignment#
The concept of “Contrastive Alignment” in the context of identity customization for text-to-image models presents a novel approach to enhancing ID fidelity while preserving the original model’s behavior. It leverages the power of contrastive learning by creating pairs of images: one with the identity (ID) embedded and one without. By aligning the feature representations of these pairs using a loss function, the model learns to insert the ID information without significantly altering other aspects of the image, such as style or background. This approach is particularly valuable because it addresses a critical challenge in ID customization: the tendency for ID insertion methods to disrupt the original model’s functionality or introduce unwanted stylistic artifacts. The contrastive alignment strategy ensures that only ID-related features are modified while maintaining the integrity of the original image’s elements. This is a significant improvement over previous methods that often lead to a trade-off between high ID fidelity and the preservation of original style. The use of a “Lightning T2I branch” further enhances the method’s effectiveness by providing high-quality images in a few steps, facilitating the accurate calculation of ID loss and alignment loss. This combined approach results in a tuning-free, efficient, and highly effective ID customization technique.
Lightning T2I Branch#
The Lightning T2I branch is a crucial innovation in PuLID, designed to address the limitations of conventional diffusion models in identity customization. By leveraging fast sampling techniques, it generates high-quality images from pure noise in a few steps, enabling more accurate ID loss optimization. This contrasts with standard diffusion methods that iteratively denoise from noisy samples, leading to less accurate ID loss due to noisy predictions. The branch’s key role is to generate a high-fidelity x0 (the original image) after ID insertion, which is then used to calculate an accurate ID loss. This minimizes disruption to the original model’s behavior, which conventional training often causes. The contrastive alignment loss further enhances this goal, by ensuring that the ID information is inserted without affecting the behavior of the original model; this is achieved by comparing features from paths with and without ID insertion. In essence, the Lightning T2I branch provides a refined approach to ID customization, leading to improved ID fidelity and reduced style degradation, and represents a significant advancement over existing methods.
ID Fidelity & Editability#
The concept of “ID Fidelity & Editability” in the context of text-to-image generation refers to the balance between accurately preserving the identity of a person or object in an image and the ability to modify or edit other aspects of that image. High ID fidelity means the generated image strongly resembles the target identity, while high editability implies that the system can easily change other features like background, style, or pose. A key challenge is that methods prioritizing high ID fidelity often sacrifice editability, and vice versa. This trade-off arises because strong constraints on identity features might limit the model’s flexibility to modify other aspects of the image. Therefore, a successful approach needs to cleverly handle these conflicting requirements, potentially using techniques like contrastive learning or careful loss function design to ensure identity preservation while maintaining the flexibility for generating diverse and coherent edits.
PuLID Limitations#
PuLID, while achieving impressive results in identity customization for text-to-image models, exhibits limitations primarily stemming from its reliance on a Lightning T2I branch and the inherent challenges of ID insertion in diffusion models. The Lightning T2I branch, while enabling precise ID loss calculation, increases computational cost and training time, potentially limiting scalability for large-scale deployments. The method’s success is heavily dependent on the quality of the initial ID embedding and the choice of the ID encoder. Suboptimal encoders could result in lower ID fidelity, undermining the approach’s effectiveness. Another concern is the potential for subtle image quality degradation resulting from the combined effects of ID loss optimization and the Lightning branch. While the alignment loss mitigates interference with the original model’s behavior, it doesn’t completely eliminate it; slight stylistic changes could still occur. Finally, the method’s reliance on specific base models (SDXL) and samplers (DPM++ 2M) limits its direct applicability to other models or inference techniques. Future research should focus on addressing these limitations to enhance PuLID’s robustness and generalizability across different models and frameworks.
More visual insights#
More on figures

🔼 This figure shows the PuLID framework, which consists of two branches: a conventional diffusion branch and a Lightning T2I branch. The conventional branch uses standard diffusion methods for image generation. The Lightning branch uses fast sampling to generate high-quality images from noise in a few steps, allowing for the calculation of accurate ID loss. A contrastive alignment loss is used to minimize interference with the original model’s behavior. The figure highlights how the ID is incorporated and how the loss functions help maintain ID fidelity while preserving the original model’s characteristics.
read the caption
Figure 2: Overview of PuLID framework. The upper half of the framework illustrates the conventional diffusion training process. The face extracted from the same image is employed as the ID condition Cid. The lower half of the framework demonstrates the Lightning T2I training branch introduced in this study. It leverages the recent fast sampling methods to iteratively denoise from pure noise to high-quality images in a few steps (4 in this paper). In this branch, we construct contrastive paths with and without ID injection and introduce an alignment loss to instruct the model on how to insert ID condition without disrupting the original model's behavior. As this branch can produce photo-realistic images, it implies that we can achieve a more accurate ID loss for optimization.

🔼 This figure visually explains the alignment loss function used in PuLID. Panel (a) shows how the alignment loss compares UNet features (Qt and Qtid) from two image generation paths (one with and one without ID embedding). Specifically, it uses textual features (K) to query the UNet features (Q) and calculates the correlation, aggregating Q based on this matrix. This aims to ensure that ID insertion doesn’t disrupt the model’s response to the prompt. The semantic alignment loss (Lalign-sem) is calculated based on the similarity of these responses, while the layout alignment loss (Lalign-layout) measures the difference between Qt and Qtid to maintain consistent layout. Panel (b) shows the effect of the alignment loss, demonstrating its effectiveness in mitigating the issue of ID information contaminating the model’s behavior by aligning UNet features, leading to improved ID insertion without disrupting the model’s original behavior.
read the caption
Figure 3: Illustration and Effect of the alignment loss.

🔼 This figure compares the image generation results of three different methods: IPAdapter, InstantID, and the proposed PuLID method. Each method is tested on several prompts with various styles and scenarios. The results show that PuLID maintains high ID (identity) fidelity while minimizing changes to the original image’s style, lighting, and layout compared to the other two methods. The consistent preservation of style, lighting, and layout demonstrates PuLID’s effectiveness and superior performance.
read the caption
Figure 4: Qualitative comparisons. T2I w/o ID represents the output generated by the original T2I model without inserting ID, which reflects the behavior of the original model. Our PuLID achieves higher ID fidelity while causing less disruption to the original model. As the disruption to the model is reduced, results generated by PuLID accurately reproduce the lighting (1st row), style (4th row), and even layout (5th row) of the original model. This unique advantage broadens the scope for a more flexible application of PuLID.

🔼 This figure shows a qualitative comparison of image generation results with and without the alignment loss (L_align). The left half demonstrates the impact of removing L_align, showing how the ID insertion disrupts the original model’s behavior. This disruption is evident in the inability of the prompt to precisely control style and orientation, and the tendency for the face to dominate the image layout. Conversely, the right half illustrates the improved image generation results obtained with the alignment loss (L_align), showcasing that it effectively mitigates this disruptive effect by enabling precise and style-consistent ID insertion without hindering prompt adherence.
read the caption
Figure 5: Qualitative comparison for ablation study on alignment loss.

🔼 This figure showcases the versatility of the PuLID model by demonstrating its ability to handle various image manipulation tasks. It shows examples of changing styles, combining identities (IP fusion), modifying accessories, altering contexts, editing attributes, converting images from non-photorealistic styles to photorealistic ones, and even mixing multiple identities. The key point is that all these high-quality results are achieved in only 4 steps using the SDXL-Lightning model, without the need for additional techniques like LoRA, highlighting the efficiency of the PuLID approach.
read the caption
Figure 6: More applications. Including style changes, IP fusion, accessory modification, recontextualization, attribute editing, transformation from non-photo-realistic domain to photo-realistic domain, and ID mixing. Note that all these high-quality images are generated in just 4 steps with SDXL-Lightning model, without the need for additional Lora.

🔼 This figure shows a qualitative comparison of the proposed PuLID method against two state-of-the-art baselines, InstantID and IPAdapter. The top row shows the input image and the prompts used, followed by the results from the base model without ID insertion (T2I w/o ID), InstantID, IPAdapter and finally, the proposed PuLID. Each column represents different editing tasks or styles applied to the same base input image. The results demonstrate that PuLID achieves higher identity fidelity while maintaining consistency in other aspects like lighting, composition, and style, compared to the other methods which show more style degradation or lower ID fidelity.
read the caption
Figure 4: Qualitative comparisons. T2I w/o ID represents the output generated by the original T2I model without inserting ID, which reflects the behavior of the original model. Our PuLID achieves higher ID fidelity while causing less disruption to the original model. As the disruption to the model is reduced, results generated by PuLID accurately reproduce the lighting (1st row), style (4th row), and even layout (5th row) of the original model. This unique advantage broadens the scope for a more flexible application of PuLID.

🔼 This figure compares the qualitative results of different methods for identity customization in text-to-image generation. The leftmost column shows the original image without any identity (ID) insertion. The following columns show results from InstantID, PuLID (the proposed method), and IPAdapter. Each method is tested using both SDXL-Lightning and SDXL-base models, resulting in two images per method. The comparison highlights PuLID’s ability to maintain higher ID fidelity while preserving the original model’s style, lighting, and layout.
read the caption
Figure 4: Qualitative comparisons. T2I w/o ID represents the output generated by the original T2I model without inserting ID, which reflects the behavior of the original model. Our PuLID achieves higher ID fidelity while causing less disruption to the original model. As the disruption to the model is reduced, results generated by PuLID accurately reproduce the lighting (1st row), style (4th row), and even layout (5th row) of the original model. This unique advantage broadens the scope for a more flexible application of PuLID.

🔼 This figure compares the image generation results of PuLID against two other methods and a baseline (original model). PuLID shows higher ID (identity) fidelity and less disruption to the original model’s style and layout compared to the other methods.
read the caption
Figure 4: Qualitative comparisons. T2I w/o ID represents the output generated by the original T2I model without inserting ID, which reflects the behavior of the original model. Our PuLID achieves higher ID fidelity while causing less disruption to the original model. As the disruption to the model is reduced, results generated by PuLID accurately reproduce the lighting (1st row), style (4th row), and even layout (5th row) of the original model. This unique advantage broadens the scope for a more flexible application of PuLID.

🔼 This figure shows the PuLID framework. The upper half shows a conventional diffusion process where the extracted face is used as the ID condition. The lower half shows the Lightning T2I branch which uses fast sampling methods to generate images from noise with a contrastive alignment loss to preserve the original model’s behavior while maintaining high ID fidelity.
read the caption
Figure 2: Overview of PuLID framework. The upper half of the framework illustrates the conventional diffusion training process. The face extracted from the same image is employed as the ID condition Cid. The lower half of the framework demonstrates the Lightning T2I training branch introduced in this study. It leverages the recent fast sampling methods to iteratively denoise from pure noise to high-quality images in a few steps (4 in this paper). In this branch, we construct contrastive paths with and without ID injection and introduce an alignment loss to instruct the model on how to insert ID condition without disrupting the original model's behavior. As this branch can produce photo-realistic images, it implies that we can achieve a more accurate ID loss for optimization.

🔼 This figure shows qualitative comparisons between the results of the original model, PuLID, InstantID, and IPAdapter. It highlights PuLID’s ability to maintain high ID fidelity while minimizing disruption to the original model’s behavior, preserving aspects like lighting, style, and layout. This contrasts with the other methods which may show style degradation or reduced editability.
read the caption
Figure 4: Qualitative comparisons. T2I w/o ID represents the output generated by the original T2I model without inserting ID, which reflects the behavior of the original model. Our PuLID achieves higher ID fidelity while causing less disruption to the original model. As the disruption to the model is reduced, results generated by PuLID accurately reproduce the lighting (1st row), style (4th row), and even layout (5th row) of the original model. This unique advantage broadens the scope for a more flexible application of PuLID.

🔼 This figure shows a qualitative comparison of PuLID against two other state-of-the-art methods, InstantID and IPAdapter. The comparison demonstrates that PuLID achieves higher identity (ID) fidelity while better preserving the original model’s behavior (e.g., style, lighting, and layout). The results suggest that PuLID’s ability to minimize interference with the original model makes it more versatile for various applications.
read the caption
Figure 4: Qualitative comparisons. T2I w/o ID represents the output generated by the original T2I model without inserting ID, which reflects the behavior of the original model. Our PuLID achieves higher ID fidelity while causing less disruption to the original model. As the disruption to the model is reduced, results generated by PuLID accurately reproduce the lighting (1st row), style (4th row), and even layout (5th row) of the original model. This unique advantage broadens the scope for a more flexible application of PuLID.
More on tables

🔼 This table presents a quantitative comparison of the model’s performance across three metrics (Face Sim, CLIP-T, and CLIP-I) under different ablation settings. It compares the baseline model to versions with only ID loss (naive and Stage2), and finally the full PuLID model (Stage3) which includes both ID loss and alignment loss. The results show the impact of each component on ID fidelity, prompt adherence and disruption to the original model.
read the caption
Table 2: Quantitative comparisons for ablation studies on ID loss and alignment loss.

🔼 This table presents a quantitative comparison of the proposed PuLID method against existing state-of-the-art methods (PhotoMaker, IPAdapter, and InstantID) using two different datasets, DivID-120 and Unsplash-50. The comparison metrics include Face Similarity (Face Sim.), CLIP Text Similarity (CLIP-T), and CLIP Image Similarity (CLIP-I). Higher scores indicate better performance. The asterisk (*) indicates PhotoMaker’s results were obtained on SDXL-base rather than SDXL-Lightning due to compatibility issues.
read the caption
Table 1: Quantitative comparisons. *We observed that PhotoMaker shows limited compatibility with SDXL-Lightning, hence, we compare its performance on SDXL-base in this table.

🔼 This table presents a quantitative comparison of the proposed PuLID model against several state-of-the-art (SOTA) methods for identity (ID) customization in text-to-image generation. The metrics used are Face Similarity (Face Sim.), CLIP Text Similarity (CLIP-T), and CLIP Image Similarity (CLIP-I). Higher scores are better, indicating higher ID fidelity, better prompt adherence and lower visual disruption after ID insertion respectively. The comparison includes results on two different datasets: DivID-120 and Unsplash-50. Note that PhotoMaker results are presented for SDXL-base due to compatibility issues with SDXL-Lightning.
read the caption
Table 1: Quantitative comparisons. *We observed that PhotoMaker shows limited compatibility with SDXL-Lightning, hence, we compare its performance on SDXL-base in this table.

🔼 This table presents a quantitative comparison of the training process using different fast sampling methods (Hyper-SD with 1 and 2 steps, and SDXL-Lightning with 4 and 8 steps) and the resulting inference steps. The metrics evaluated are Face Sim. (face similarity), CLIP-T (prompt adherence), and CLIP-I (image similarity). The results are shown separately for two datasets: DivID-120 and Unsplash-50. This allows for assessing the impact of the different sampling methods and number of inference steps on the overall quality and consistency of the generated images in terms of identity preservation, adherence to text prompts, and overall similarity to the original images.
read the caption
Table 5: Quantitative comparison of training with different fast sampling methods and inference steps.
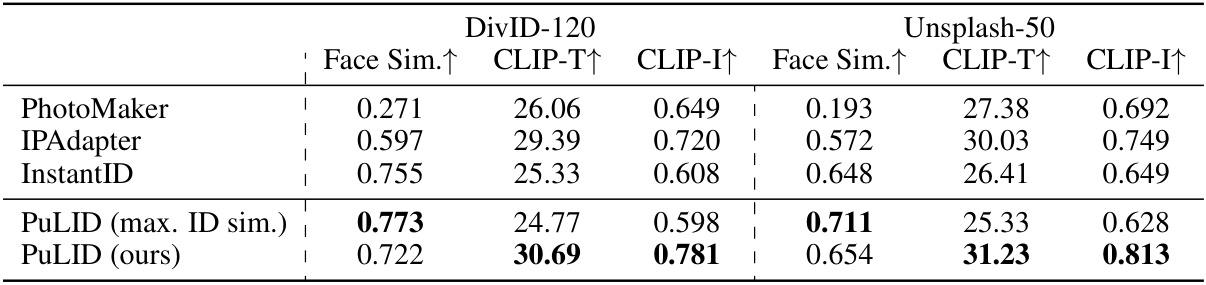
🔼 This table presents a quantitative comparison of the proposed PuLID model against several state-of-the-art (SOTA) methods for identity (ID) customization in text-to-image generation. The comparison uses two datasets: DivID-120 and Unsplash-50. For each method and dataset, the table reports three metrics: Face Sim (the similarity of generated faces to the ground truth, using CurricularFace embeddings); CLIP-T (how well the generated images adhere to the text prompt, using CLIP embeddings); and CLIP-I (the visual similarity between the images generated with and without ID insertion, also using CLIP embeddings). A higher score in Face Sim indicates better ID fidelity. Higher scores in CLIP-T and CLIP-I suggest better prompt adherence and lower disruption of the original model’s behavior, respectively. The asterisk (*) indicates that PhotoMaker’s performance is assessed using the SDXL-base model due to limited compatibility with SDXL-Lightning.
read the caption
Table 1: Quantitative comparisons. *We observed that PhotoMaker shows limited compatibility with SDXL-Lightning, hence, we compare its performance on SDXL-base in this table.

🔼 This table presents a quantitative comparison of PuLID against several state-of-the-art methods for identity customization in text-to-image generation. The comparison uses two datasets (DivID-120 and Unsplash-50) and three metrics: Face Sim. (Face Similarity), CLIP-T (Prompt Following Ability), and CLIP-I (Image Similarity to the original before ID insertion). Higher scores are better, indicating higher fidelity in ID reproduction, better compliance with the image prompts, and less disruptive change to the original image style.
read the caption
Table 1: Quantitative comparisons. *We observed that PhotoMaker shows limited compatibility with SDXL-Lightning, hence, we compare its performance on SDXL-base in this table.
Full paper#



















