TL;DR#
Meta-learning is crucial for training deep learning models with limited data, relying on prior knowledge from related tasks. However, existing methods often use limited prior distributions, such as Gaussians, which hinder performance with scarce data. This limitation motivates the search for more expressive priors that can better adapt to diverse tasks.
This paper proposes MetaNCoV, a novel meta-learning approach that utilizes a non-injective change-of-variable (NCoV) model to learn a data-driven prior. Unlike traditional methods with fixed priors, MetaNCoV’s data-driven approach dynamically adjusts its form to optimally fit the given tasks, resulting in enhanced expressiveness, particularly in high-dimensional spaces. Experimental results on three few-shot learning datasets validate its effectiveness in surpassing methods with pre-defined priors, demonstrating its strong capabilities when data is extremely limited.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in meta-learning and related fields because it introduces a novel approach to overcome the limitations of existing meta-learning methods. By using a data-driven prior, it shows significant improvements in few-shot learning tasks and paves the way for more expressive and adaptive models. This is especially relevant considering the increasing interest in few-shot learning and limited data scenarios.
Visual Insights#

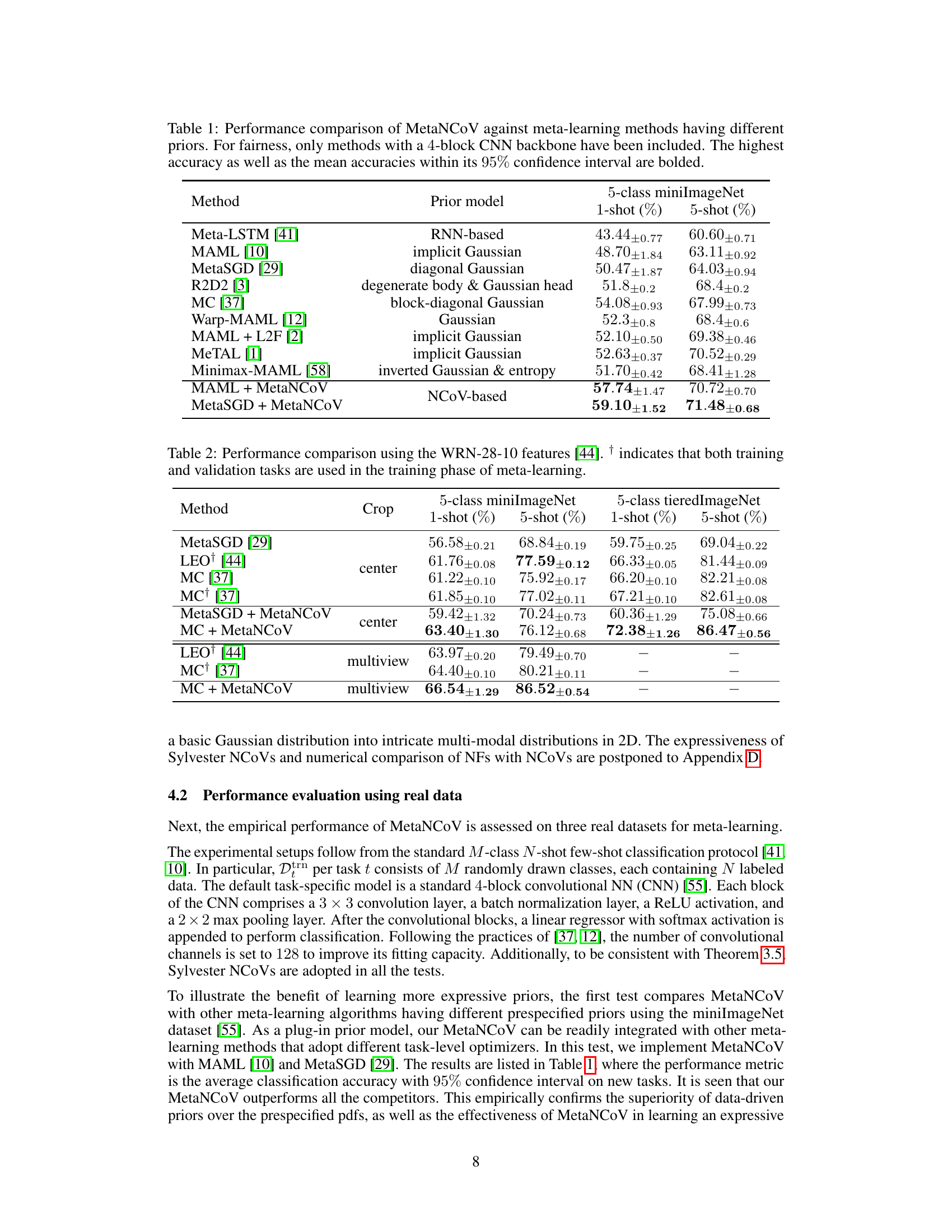
🔼 This figure shows how a standard Gaussian distribution is transformed into three different multi-modal target distributions using the Sylvester NCoVs. The top row displays the estimated pdfs obtained via Sylvester NCoVs, while the bottom row shows the ground truth pdfs. The results demonstrate that the Sylvester NCoVs can effectively approximate a wide range of pdfs, including those with multiple modes and complex shapes.
read the caption
Figure 1: Transforming a standard Gaussian pdf into multi-modal target pdfs using Sylvester NCoVs.
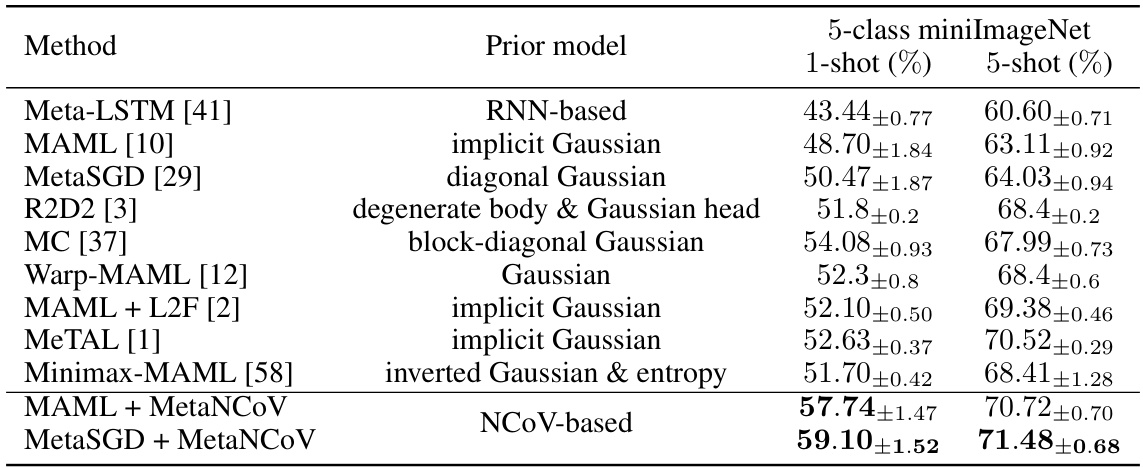
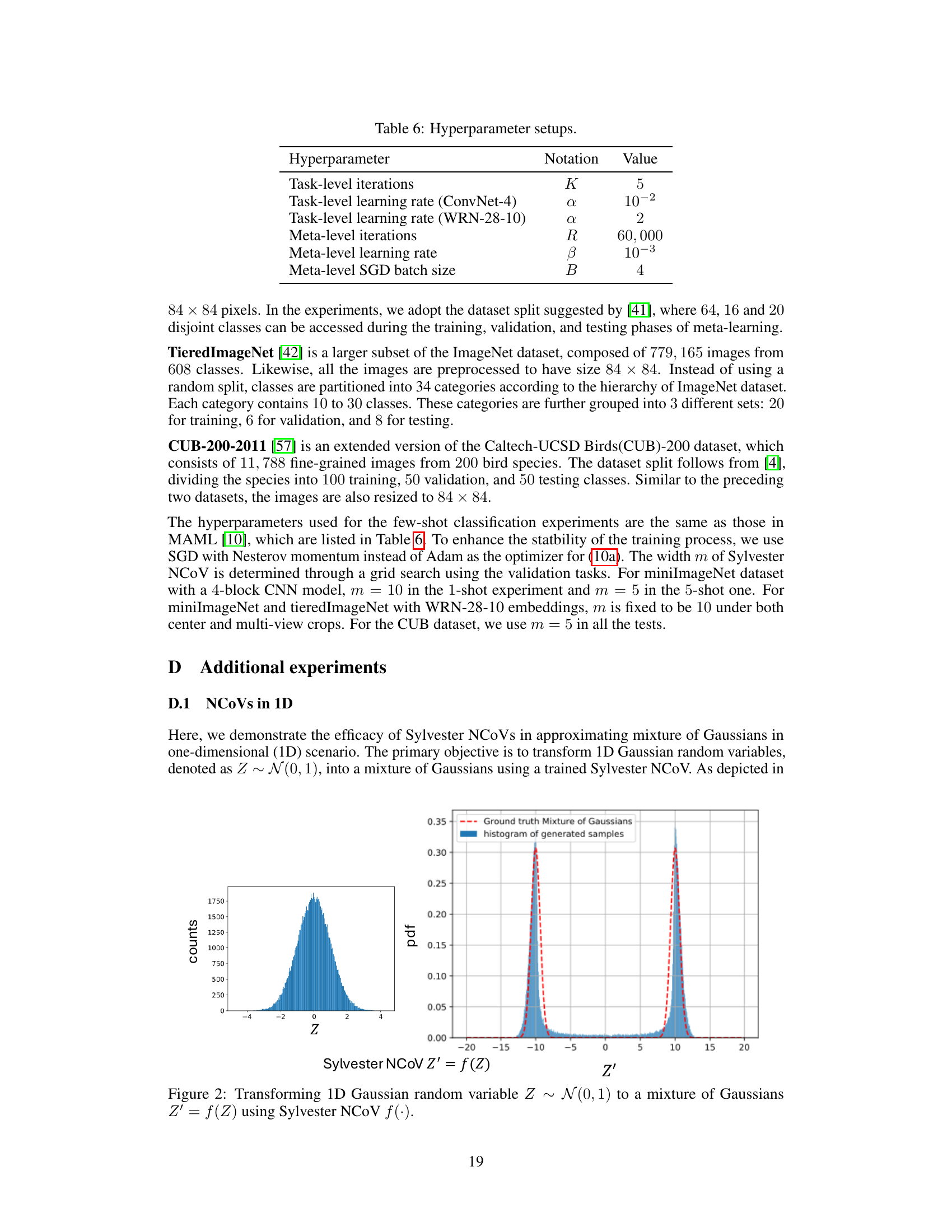
🔼 This table compares the performance of the proposed MetaNCoV method against other state-of-the-art meta-learning methods on the miniImageNet dataset. It focuses on methods using a 4-block CNN backbone for fair comparison. The table highlights the highest accuracy achieved and the average accuracy within a 95% confidence interval for both 1-shot and 5-shot learning scenarios. Different prior models used by each method are also listed.
read the caption
Table 1: Performance comparison of MetaNCoV against meta-learning methods having different priors. For fairness, only methods with a 4-block CNN backbone have been included. The highest accuracy as well as the mean accuracies within its 95% confidence interval are bolded.
In-depth insights#
Universal Priors#
The concept of “Universal Priors” in the context of meta-learning is intriguing. It suggests a prior probability distribution that is broadly applicable across a wide range of tasks, rather than task-specific priors. This approach seeks to capture underlying shared structure present in various tasks, thereby enhancing the efficiency and generalization capability of meta-learning models. The key advantage of universal priors is the potential for significant improvements in few-shot learning, where data is scarce, by leveraging knowledge obtained from related tasks. However, challenges remain in effectively learning and representing such priors, as they need to be expressive enough to capture a diverse set of task distributions. Data-driven approaches, as opposed to hand-crafted priors, offer promising solutions, but require careful consideration to prevent overfitting and ensure sufficient generalization. The ultimate success of universal priors hinges on striking a balance between expressiveness and generalizability, requiring sophisticated models and robust learning strategies.
NCoV’s Expressiveness#
The core of the paper revolves around the enhanced expressiveness of the Non-Injective Change of Variable (NCoV) model in approximating complex probability density functions (PDFs). Unlike traditional methods that rely on pre-selected, limited PDFs like Gaussians, NCoV’s non-injective nature allows it to dynamically adjust its form, effectively fitting a much wider range of distributions. This is particularly crucial in meta-learning scenarios with scarce data, where inflexible priors hinder model performance. The theoretical analysis provides a rigorous foundation, proving NCoV’s universal approximation capabilities. The ability to approximate even multi-modal or asymmetric PDFs contrasts sharply with the limitations of conventional methods, highlighting a substantial advancement in meta-learning prior design. Numerical experiments confirm NCoV’s superiority, showcasing its effectiveness in handling extremely limited data resources and outperforming existing meta-learning techniques across various datasets. This improvement is attributed to NCoV’s ability to capture intricate relationships within the data, providing a more accurate and informative prior for the learning process.
MetaNCoV Algorithm#
The heading ‘MetaNCoV Algorithm’ suggests a novel algorithm for meta-learning using a non-injective change of variables. The algorithm likely involves a bilevel optimization scheme, where the inner loop optimizes task-specific parameters and the outer loop refines a data-driven prior distribution. The use of a non-injective change of variables is crucial, allowing the algorithm to model a much wider range of prior distributions than traditional methods that rely on pre-defined priors like Gaussians. This enhanced flexibility is particularly beneficial for tasks with limited data. The algorithm’s effectiveness is likely validated by numerical experiments on benchmark few-shot learning datasets. The core innovation rests in the use of a data-driven prior to overcome limitations of pre-defined priors. Therefore, a detailed examination of the algorithm should focus on the specific implementation of the non-injective change-of-variable model, and how the prior is learned and incorporated into the meta-learning framework. The computational cost and scalability of the algorithm also warrant further investigation.
Empirical Superiority#
The concept of “Empirical Superiority” in a PDF research paper centers on demonstrating that a proposed method outperforms existing approaches. A strong demonstration requires rigorous experimentation and statistical analysis. The choice of datasets is critical, ensuring they are relevant to the problem and representative of real-world scenarios. Sufficient comparisons with state-of-the-art methods are necessary, using consistent evaluation metrics to avoid bias. Statistical significance testing is crucial to validate that observed improvements are not merely due to chance, and ideally, error bars should quantify the uncertainty. Ablation studies, systematically removing parts of the method, help isolate the contribution of specific components and further establish the source of the claimed superiority. Finally, clear visualization of results can greatly enhance understanding and impact. A well-supported “Empirical Superiority” section significantly strengthens a research paper’s overall contribution.
Future Research#
The paper’s “Future Research” section would ideally delve into several promising avenues. Extending the theoretical analysis to encompass a broader range of non-injective change-of-variable models beyond Sylvester NFs is crucial. Investigating the convergence properties of the MetaNCoV algorithm using different optimizers and analyzing its scalability under larger dataset conditions would greatly enhance the algorithm’s robustness and applicability. Exploring the applicability of the proposed NCoV model beyond meta-learning to other machine learning domains where flexible, data-driven prior information is beneficial, such as few-shot reinforcement learning or transfer learning, is warranted. Finally, a comprehensive exploration into mitigating the computational cost associated with high-dimensional pdf estimations within the NCoV framework could significantly improve its efficiency for real-world applications. These future research directions hold substantial potential for strengthening the work’s impact.
More visual insights#
More on figures

🔼 This figure showcases the capability of Sylvester Non-injective Change of Variables (NCoVs) in transforming a standard Gaussian probability density function (pdf) into various multi-modal target pdfs. The top row displays the estimated pdfs obtained using the Sylvester NCoV model, while the bottom row shows the corresponding target pdfs. Each column represents a different transformation, demonstrating the flexibility and expressiveness of the NCoV approach in approximating a wide range of pdf shapes, even with complex, multi-modal distributions.
read the caption
Figure 1: Transforming a standard Gaussian pdf into multi-modal target pdfs using Sylvester NCoVs.
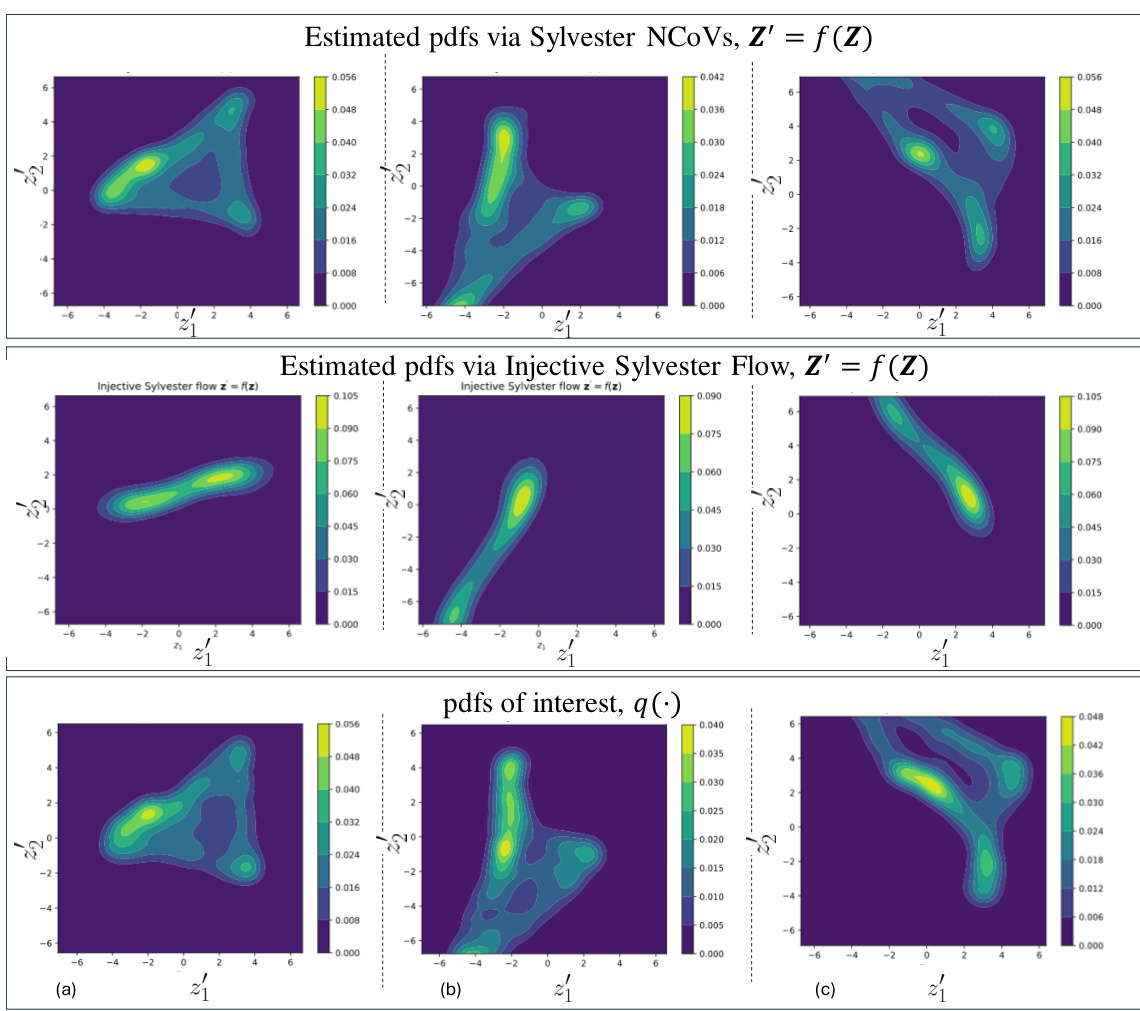
🔼 This figure compares the performance of the Non-injective Change of Variables (NCoVs) model and the Injective Sylvester Flow model on three 2D toy datasets. The first row shows the estimated probability density functions (pdfs) generated using Sylvester NCoVs. The second row shows the estimated pdfs generated by the Injective Sylvester Flow model. The third row displays the ground truth pdfs. This comparison demonstrates that the NCoVs model has greater expressiveness than the Injective Sylvester Flow model in learning complex 2D distributions, especially those with incomplete support.
read the caption
Figure 3: Comparison of NFs and NCoVs in learning 2D toy pdfs.

🔼 This figure compares the performance of non-injective Sylvester NCoVs and injective Sylvester NFs in learning a 4x4 checkerboard probability density function (pdf). The left panel shows the target checkerboard pdf. The middle panel displays the pdf learned by the non-injective Sylvester NCoV. The right panel shows the pdf learned by the injective Sylvester NF. The comparison highlights the superior ability of non-injective NCoVs to capture complex, non-smooth pdfs compared to their injective counterparts. The results demonstrate the improved fitting capacity of NCoVs in cases where the target distribution does not have full support.
read the caption
Figure 4: Learning a 4 × 4 checkerboard pdf with NFs and NCoVs.
More on tables
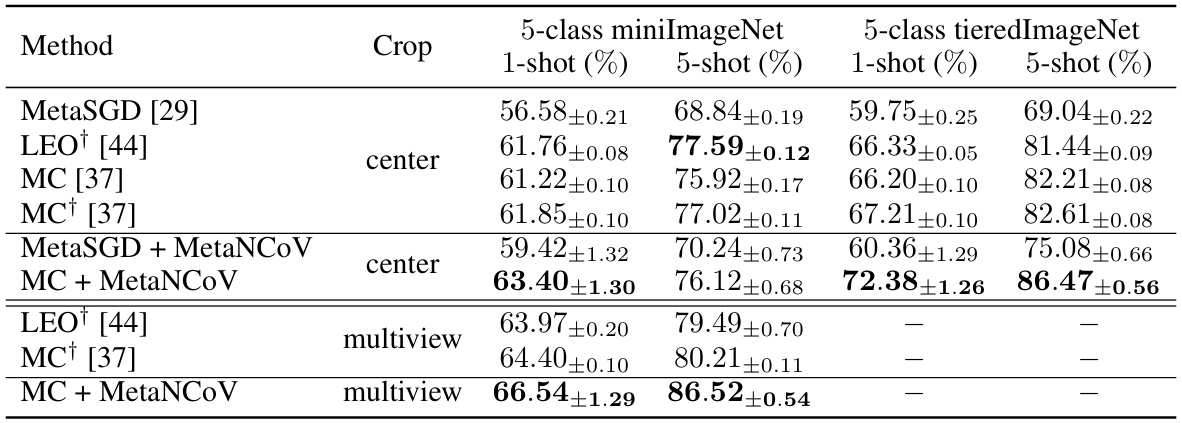
🔼 This table compares the performance of different meta-learning methods on the miniImageNet dataset using Wide ResNet-28-10 features. It shows the 1-shot and 5-shot accuracy for both training and validation sets, across different cropping strategies (center and multiview). The results highlight the impact of using both training and validation data during meta-learning.
read the caption
Table 2: Performance comparison using the WRN-28-10 features [44]. † indicates that both training and validation tasks are used in the training phase of meta-learning.

🔼 This table compares the performance of MetaNCoV against other meta-learning and metric-learning methods on the CUB-200-2011 dataset. The focus is on few-shot image classification with 1-shot and 5-shot settings. All methods use a 4-block CNN backbone for a fair comparison. The table highlights the accuracy (with 95% confidence intervals) achieved by each method. This dataset is particularly challenging because it involves fine-grained image recognition of bird species, requiring the model to learn complex high-level features. The results demonstrate how MetaNCoV performs compared to other approaches, particularly in low-data (1-shot) scenarios.
read the caption
Table 3: Performance comparison of MetaNCoV against meta-learning and metric-learning methods on the CUB-200-2011 dataset. For fairness, the backbone model is a 4-block CNN.
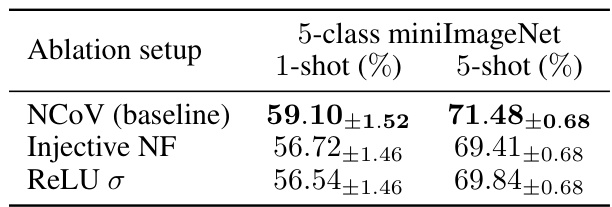
🔼 This ablation study investigates the impact of using non-injective change of variables (NCoVs) over injective ones and the impact of using ReLU activation in Sylvester NCoVs on the performance of the MetaNCoV algorithm. The results are reported as the average classification accuracy with 95% confidence interval on miniImageNet dataset for 1-shot and 5-shot settings.
read the caption
Table 4: Ablation tests for MetaNCoV.
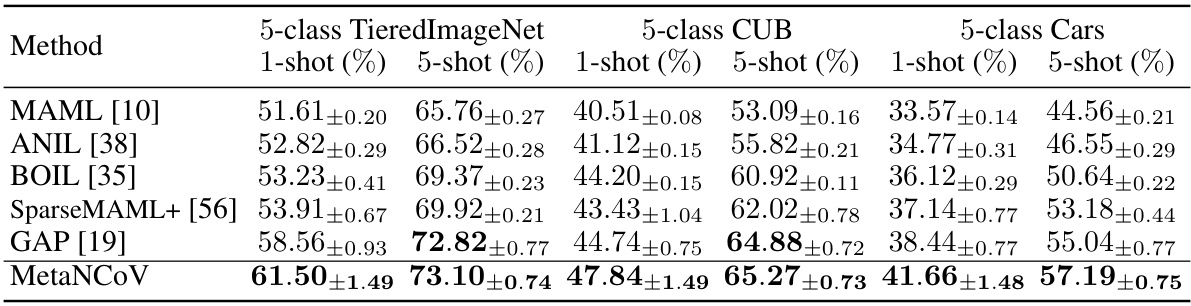
🔼 This table presents a comparison of the MetaNCoV algorithm’s performance against other meta-learning algorithms in a cross-domain few-shot learning setting. The prior models for all algorithms were trained on the miniImageNet dataset, and their performance was then evaluated on three different test datasets: TieredImageNet, CUB, and Cars. The table shows the 1-shot and 5-shot accuracy for each algorithm and dataset, highlighting MetaNCoV’s performance compared to existing methods in this challenging cross-domain scenario.
read the caption
Table 5: Performance comparison of MetaNCoV against meta-learning algorithms in cross-domain few-shot learning setups. The prior models are trained on miniImageNet and tested on three datasets.
🔼 This table compares the performance of the proposed MetaNCoV method against other existing meta-learning methods on the miniImageNet dataset. The comparison focuses on methods using a 4-block CNN backbone for fairness. The table highlights the highest accuracy achieved and the mean accuracy within a 95% confidence interval for both 1-shot and 5-shot learning scenarios, indicating the effectiveness of MetaNCoV with its novel prior.
read the caption
Table 1: Performance comparison of MetaNCoV against meta-learning methods having different priors. For fairness, only methods with a 4-block CNN backbone have been included. The highest accuracy as well as the mean accuracies within its 95% confidence interval are bolded.

🔼 This table compares the performance of the proposed MetaNCoV method with other state-of-the-art meta-learning methods on the miniImageNet dataset. The comparison focuses on methods using a 4-block CNN backbone for fairness, and considers various prior models (e.g., Gaussian, RNN-based, inverted Gaussian). The table highlights the superior performance of MetaNCoV, especially in terms of accuracy and the stability indicated by the confidence intervals.
read the caption
Table 1: Performance comparison of MetaNCoV against meta-learning methods having different priors. For fairness, only methods with a 4-block CNN backbone have been included. The highest accuracy as well as the mean accuracies within its 95% confidence interval are bolded.
🔼 This table compares the performance of the proposed MetaNCoV method against other state-of-the-art meta-learning methods on the miniImageNet dataset. It focuses on methods using a 4-block CNN backbone for a fair comparison. The table highlights the highest accuracy achieved and the mean accuracy within a 95% confidence interval for both 1-shot and 5-shot learning scenarios, showing the impact of different prior models on performance. MetaNCoV’s results are bolded to emphasize its superior performance.
read the caption
Table 1: Performance comparison of MetaNCoV against meta-learning methods having different priors. For fairness, only methods with a 4-block CNN backbone have been included. The highest accuracy as well as the mean accuracies within its 95% confidence interval are bolded.
Full paper#