↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Egocentric human-object interaction (HOI) understanding is crucial for many applications, but existing methods struggle with incomplete observations inherent in egocentric views. These methods often fail to accurately capture the where of interaction within 3D space, leading to ambiguity. This paper tackles this challenge by focusing on the spatial understanding of egocentric HOI.
EgoChoir, the proposed framework, tackles this problem by integrating visual appearance, head motion, and 3D object information to infer 3D interaction regions. It utilizes a parallel cross-attention mechanism with gradient modulation, allowing it to adapt to various scenarios. The effectiveness of EgoChoir is demonstrated through extensive experiments on a new dataset of egocentric videos with detailed 3D annotations of human contact and object affordance. This dataset is a valuable resource for future research.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical need in egocentric human-object interaction (HOI) understanding by focusing on the spatial aspect of interactions. It introduces EgoChoir, a novel framework for accurately capturing 3D interaction regions from egocentric videos, which is crucial for applications like AR/VR and embodied AI. The paper’s detailed methodology, dataset, and extensive evaluation provide a solid foundation for future research, opening new avenues for improving the effectiveness and robustness of egocentric HOI understanding in various scenarios. The dataset presented also serves as a valuable resource for researchers.
Visual Insights#
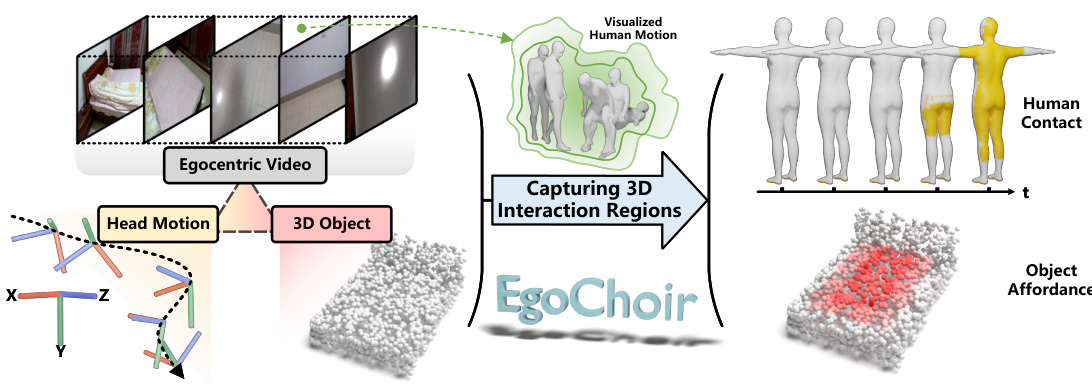
This figure illustrates the overall process of EgoChoir, a framework for capturing 3D human-object interaction regions from egocentric views. It starts with egocentric video frames and head motion data obtained from a head-mounted device. This is combined with a 3D model of the object involved in the interaction. EgoChoir then processes this information to generate a 3D representation of the interaction, highlighting both the areas of human contact with the object and the affordances (possible uses) of the object. Notably, while head motion is displayed for visualization purposes, it is not directly used in the calculations by EgoChoir.

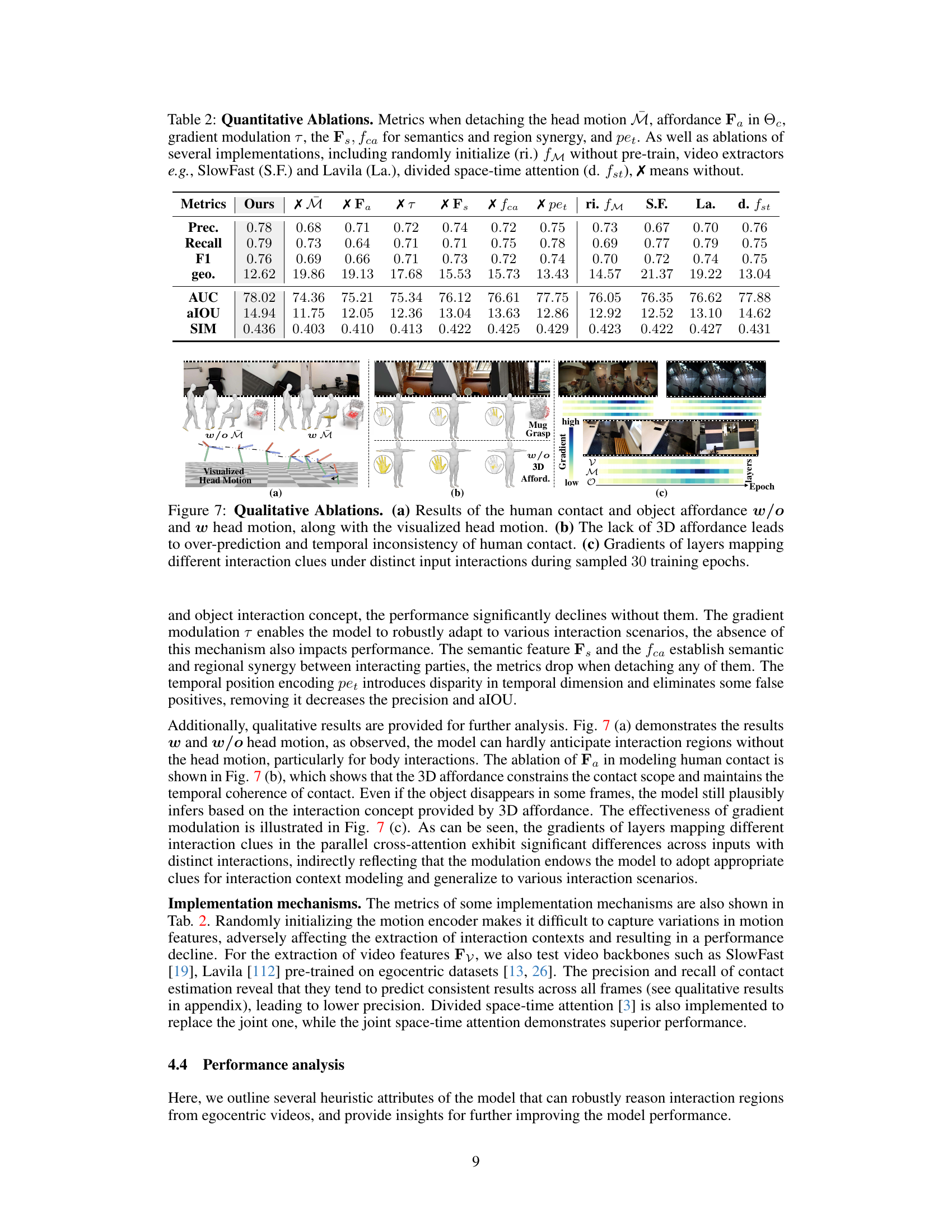
This table presents a quantitative comparison of the proposed EgoChoir method against several baseline methods for estimating human contact and object affordance in egocentric videos. It shows the precision, recall, F1-score, and geodesic error for human contact, and the AUC, aIOU, and SIM scores for object affordance. The best performing method for each metric is highlighted.
In-depth insights#
Egocentric HOI#
Egocentric Human-Object Interaction (HOI) presents a unique challenge in computer vision due to the inherent limitations of the first-person perspective. Unlike exocentric views, egocentric viewpoints offer incomplete visual information, often obscuring parts of the human and object involved in the interaction. This limitation makes it difficult to accurately identify and segment the 3D interaction regions, which are crucial for understanding the scene’s dynamics and context. EgoChoir, presented in the paper, directly tackles these difficulties by cleverly integrating visual appearance, head motion, and 3D object data. This multi-modal approach allows the system to overcome the inherent ambiguities present in egocentric views, leading to more robust and accurate 3D interaction region estimations. The innovative use of head motion is particularly noteworthy. It provides valuable contextual clues about the subject’s intentions and helps disambiguate situations where only partial visual information is available. Moreover, the introduction of a gradient modulation technique enhances the model’s adaptability to various egocentric scenarios, ensuring consistent performance despite differences in the visibility of interaction components. The paper also highlights the contribution of a new egocentric video dataset which allows for benchmarking and further research into this under-explored area of computer vision.
3D Interaction#
The concept of “3D Interaction” in a research paper likely delves into the spatial aspects of interactions between agents and objects within a three-dimensional environment. A thorough exploration would involve methodologies for capturing and representing 3D interaction data, potentially using sensor fusion techniques (e.g., combining visual and depth information). Analysis might involve defining quantitative metrics to measure interaction strength, reach, and spatial extent, possibly employing geometric primitives or voxel-based representations. The work would likely address the challenges of handling occlusions and incomplete observations common in egocentric or dynamic scenarios. It may also explore different interaction types, such as contact, proximity, or manipulation, and how they’re characterized in 3D space. Finally, a strong analysis would investigate the application of 3D interaction understanding in areas such as robotics, augmented reality, or human-computer interaction.
EgoChoir Model#
The EgoChoir model presents a novel framework for understanding egocentric human-object interaction by harmonizing visual appearance, head motion, and 3D object information. Its key innovation lies in the parallel cross-attention mechanism, which cleverly integrates these diverse modalities to concurrently infer 3D human contact and object affordance. This approach tackles the ambiguity inherent in egocentric views, where interacting parties may be partially or fully occluded, by leveraging complementary information streams to form a comprehensive understanding of the interaction. Gradient modulation further enhances the model’s adaptability to various egocentric scenarios, allowing it to effectively weight different clues based on their relevance. The model’s effectiveness is demonstrated through extensive experiments on a newly collected egocentric video dataset, showcasing its superiority over existing methods in capturing 3D interaction regions. The dataset itself is a significant contribution, providing a valuable resource for future research in egocentric HOI understanding. However, future work could focus on addressing limitations related to temporal accuracy and generalization to entirely unseen interaction types.
Dataset & Results#
A robust research paper necessitates a thorough discussion of the dataset and results. The dataset section should detail the data’s source, characteristics (size, diversity, biases), and any preprocessing steps. Clear methodology for data collection and annotation is crucial, ensuring reproducibility. The results section should present key findings using appropriate visualizations and statistical analysis. Quantitative metrics and their significance must be explicitly defined, including error bars for demonstrating confidence. Furthermore, it is essential to discuss the limitations of the study and any potential biases present in the dataset or methodology. Qualitative analysis, such as illustrative examples and visualisations of model output, should complement the quantitative results to provide a holistic understanding of the paper’s contribution. Finally, a strong research paper will connect the findings back to the original research question, highlighting the implications and future research directions.
Future Work#
The EgoChoir framework, while effective, presents opportunities for future advancements. Improving the handling of occluded interaction regions is crucial; the current reliance on visual appearance and head motion struggles when interacting parties are out of sight. Integrating more robust 3D scene understanding, possibly using depth sensors or point cloud data, would enhance robustness. Exploring the use of whole-body motion instead of just head movements offers a richer source of interaction clues. This would likely require more sophisticated pose estimation techniques. Additionally, while the paper demonstrates effectiveness on a specific dataset, further investigation into generalizability across diverse egocentric interaction scenarios and object categories is needed. Expanding the dataset with greater diversity in interaction types, environments, and objects would strengthen the model’s robustness and allow for more comprehensive evaluation. Finally, exploring more efficient training methodologies would be beneficial, as the current approach is computationally intensive. The integration of active learning techniques or more efficient attention mechanisms could significantly reduce training time and resource requirements.
More visual insights#
More on figures

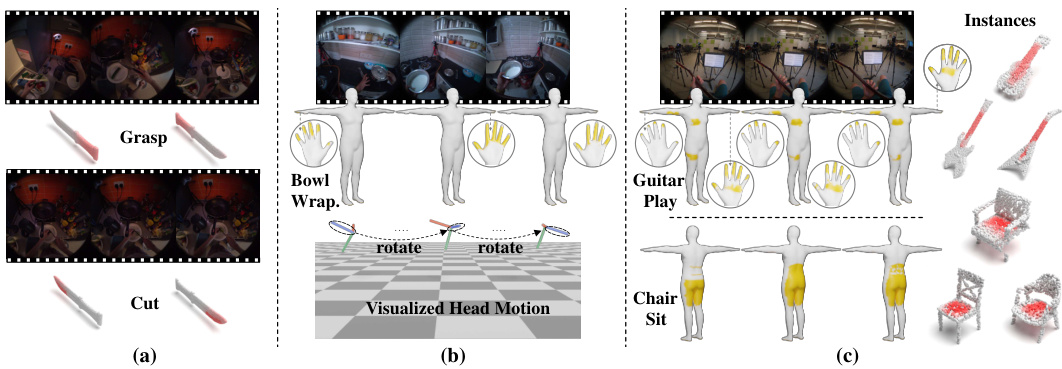
This figure illustrates the core concept of EgoChoir. It shows how human intention, represented by head movements and visual appearance, combined with an object’s structure and function (its interaction concept), creates a mental model of the interaction. This mental model, called the ‘interaction body image,’ allows the human to anticipate and envision where the interaction will occur in 3D space, even if parts of the interaction are not directly visible in the egocentric view.
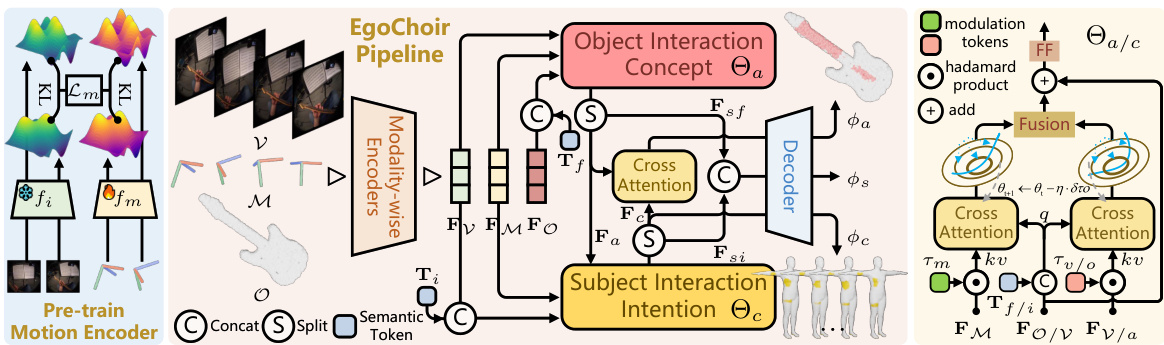
This figure shows the architecture of the EgoChoir model. The pipeline begins with modality-wise encoders processing egocentric video frames (V), head motion (M), and 3D object data (O). A pre-trained motion encoder minimizes the distance between visual and motion disparities. These features are then used to infer the object interaction concept and subject intention. Parallel cross-attention mechanisms, modulated by tokens, are used to model object affordance and human contact. The final outputs are temporal dense human contact, 3D object affordance, and interaction category.

This figure shows the architecture of the EgoChoir model. It consists of three modality-wise encoders (visual, motion, and object), a parallel cross-attention module for extracting object affordance and subject intention, and a decoder for generating 3D human contact and object affordance. The motion encoder is pretrained to align visual and motion disparities. The cross-attention module uses gradient modulation to adapt to different scenarios. The decoder combines semantic information with spatial information to produce final predictions.
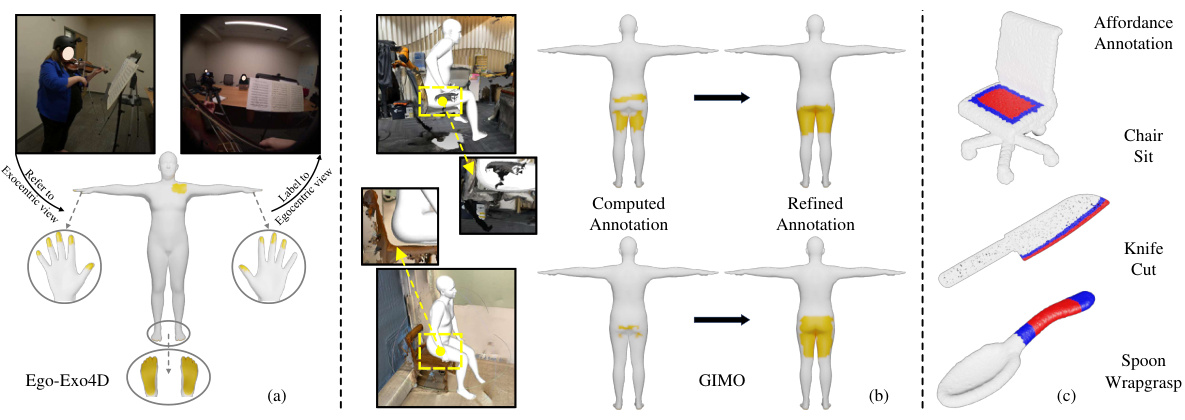
This figure shows the annotation process of 3D human contact and object affordance used in the paper. (a) shows manual annotation of contact for Ego-Exo4D dataset using exocentric views. (b) shows the process of contact annotation for GIMO dataset, starting with automated calculations and followed by manual refinement due to limitations of automated methods. (c) illustrates the annotation of 3D object affordance, differentiating between high probability interaction regions (red) and adjacent regions where interaction might propagate (blue).
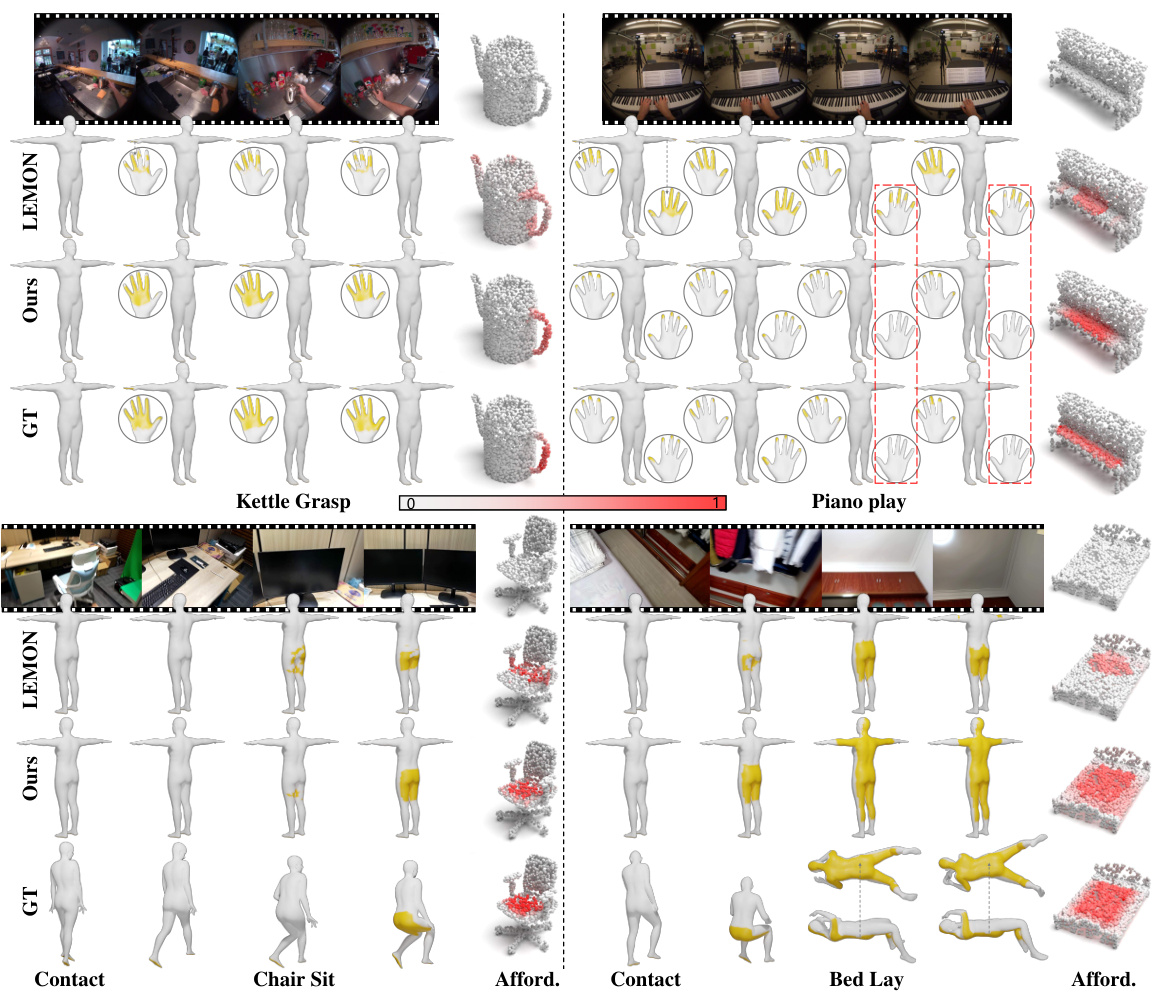
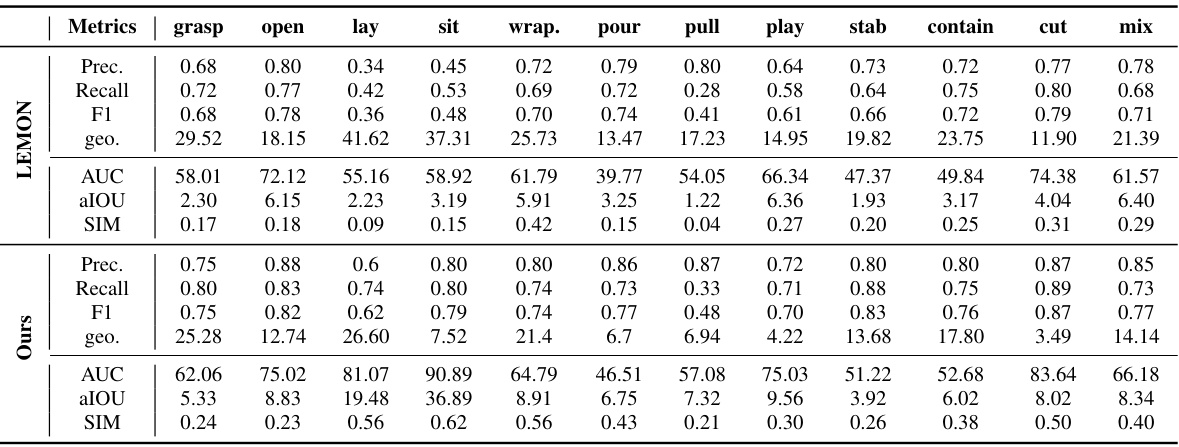
This figure displays qualitative results comparing ground truth (GT), LEMON method, and the proposed EgoChoir method’s performance on estimating human contact and object affordance. The visualizations use yellow for contact vertices and a gradient of red (depth indicating probability) for 3D object affordance. The bottom row provides intuitive visualizations of body interactions on posed humans from GIMO [113] dataset for easier understanding.
This figure illustrates the pipeline of the EgoChoir method. It starts with modality-wise feature extraction (visual, motion, and object features). The motion encoder is pre-trained to correlate visual and motion discrepancies. Then, it uses parallel cross-attention with gradient modulation to model object affordance and human contact based on the object interaction concept and subject intention. Finally, a decoder combines these results to output the 3D human contact, object affordance, and interaction category.
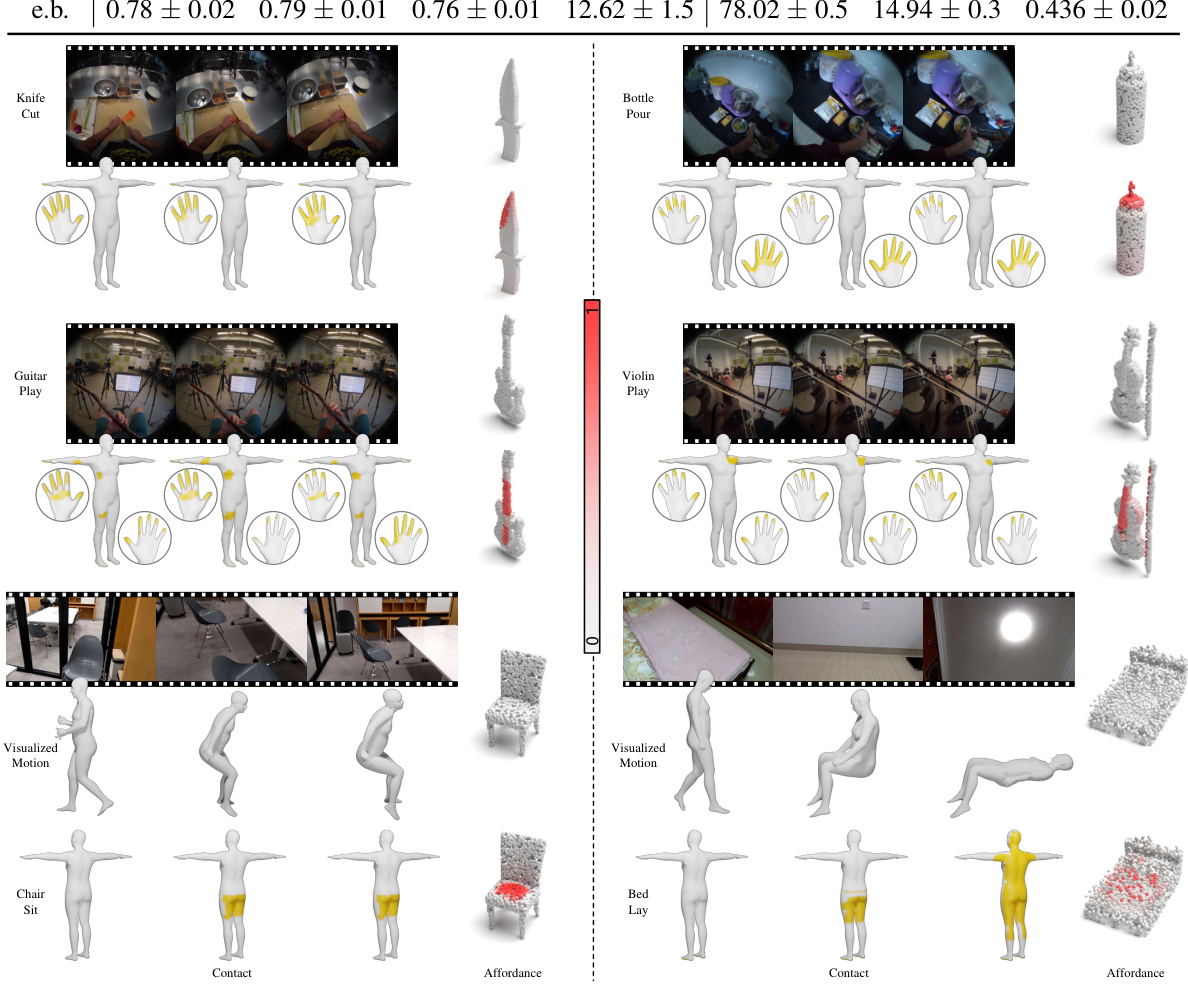
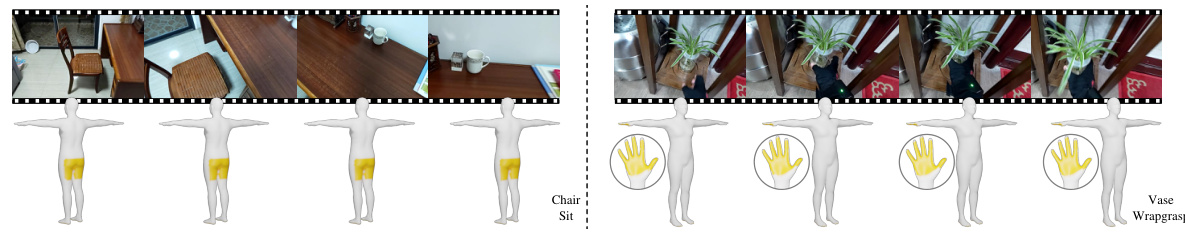
This figure displays qualitative results of the EgoChoir model’s performance on human contact and object affordance prediction for various egocentric interactions. The ground truth (GT) is shown alongside the model’s predictions, which visually demonstrates the model’s ability to accurately locate human contact points and estimate object affordances. In particular, the figure showcases the model’s effectiveness in scenarios where the human and object’s interaction may be partially or fully obscured from view. The affordance’s probability is shown as a color gradient, where darker red indicates a higher probability of affordance. Also, for better visualization, the ground truth body contact for body interactions are shown as 3D posed human bodies from GIMO dataset.
This figure shows the annotation process for 3D human contact and object affordance used in the EgoChoir paper. (a) demonstrates manual contact annotation in Ego-Exo4D dataset, while (b) displays the process for GIMO, highlighting both automated calculations and manual refinement for improved accuracy. Finally, (c) illustrates the annotation of object affordance, distinguishing between high-probability interaction regions (red) and adjacent, potentially usable areas (blue).
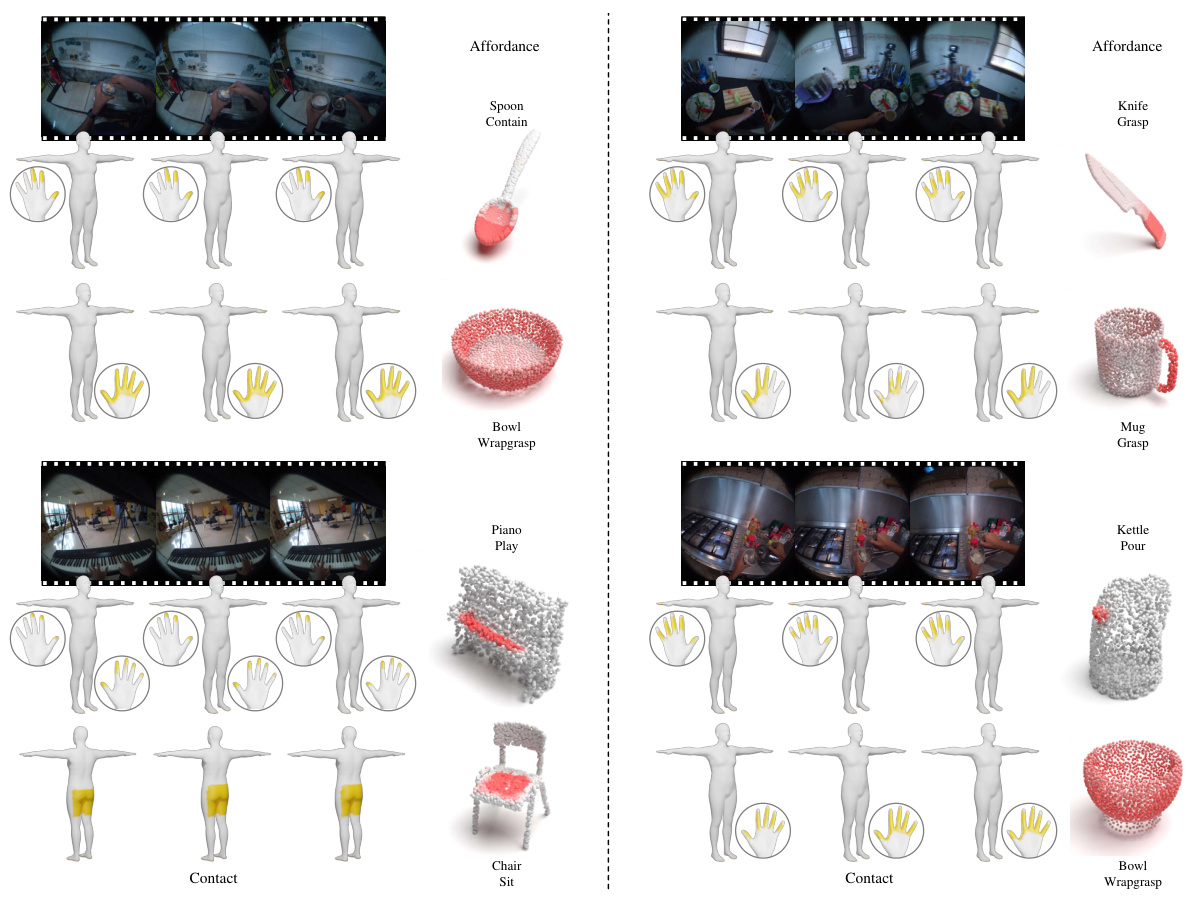
This figure displays qualitative results comparing the model’s predictions (Ours) with ground truth (GT) and LEMON results for human contact and object affordance on several egocentric interactions. Contact points are shown in yellow on the human body model. Object affordance is shown in red, with the intensity of the red color representing the probability of affordance. The bottom row shows ground truth contact displayed on a human body model to improve understanding. Video results are available in the supplementary material.
More on tables
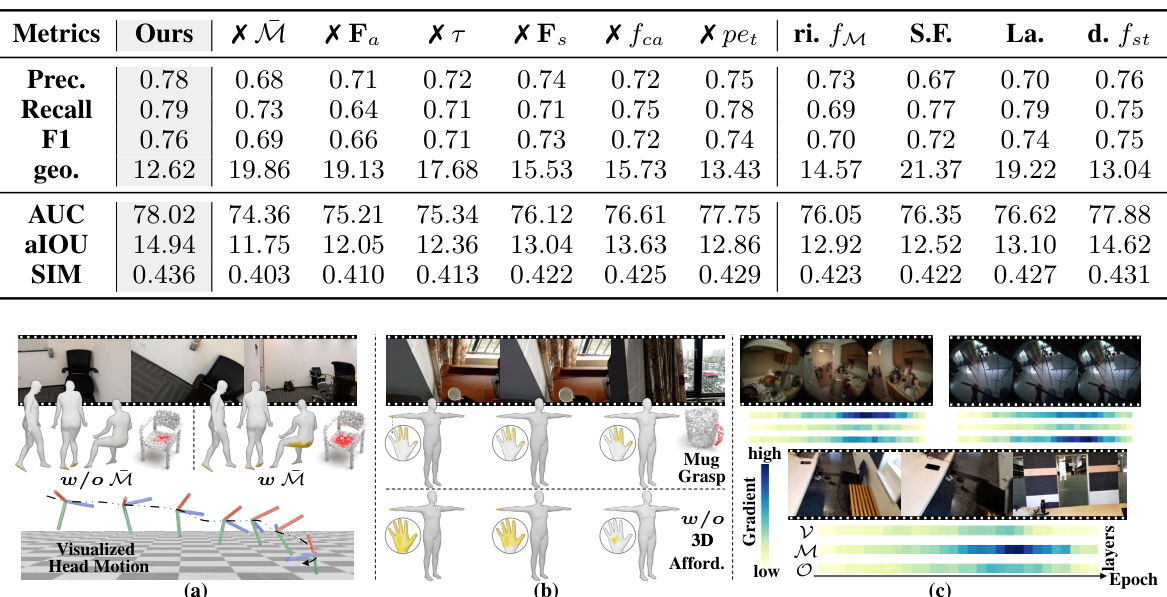
This table presents a quantitative comparison of the proposed EgoChoir method against several baseline methods for estimating human contact and object affordance in egocentric videos. Metrics such as precision, recall, F1-score, geodesic error (geometric distance), AUC (Area Under the Curve), aIOU (Average Intersection over Union), and SIM (Similarity) are used to evaluate performance. The best results for each metric are highlighted, along with the percentage improvement compared to the first baseline method.

This table presents the quantitative results of the proposed method when using whole-body motion instead of head motion. It compares metrics (Precision, Recall, F1-score, geodesic error, AUC, aIOU, and SIM) achieved using whole-body motion to those achieved with the original method which used head motion. This comparison allows assessment of the impact of the change in motion data on the model’s performance.
This table presents a quantitative comparison of the proposed EgoChoir method against several baseline methods for the tasks of human contact and object affordance estimation. Metrics such as precision, recall, F1-score, geodesic error (in centimeters), AUC (Area Under the Curve), aIOU (Average Intersection over Union), and SIM (Similarity) are used to evaluate performance on both tasks. The best results achieved by each method are highlighted, and the relative improvement over the first baseline method (BSTRO) is shown. This allows for a direct comparison of the effectiveness of EgoChoir against existing approaches in the field.
This table presents a quantitative comparison of the proposed EgoChoir method against several baseline methods for the tasks of human contact and object affordance estimation. It shows precision, recall, F1-score, and geodesic error for human contact, and AUC, aIOU, and SIM scores for object affordance. The best performing method for each metric is highlighted.
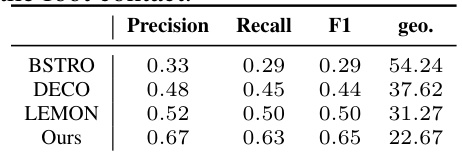
This table shows the results of an ablation study where foot contact is removed from the dataset. The metrics Precision, Recall, F1-score, and geodesic error are compared for four different methods (BSTRO, DECO, LEMON, and the proposed ‘Ours’ method) to evaluate the impact of removing foot contact on the accuracy of human contact estimation. The results indicate that removing foot contact improves the performance of the models across the board, highlighting that foot contact alone does not necessarily indicate an accurate or comprehensive representation of interaction.

This table presents ablation study results focusing on the training method of the motion encoder (fm), the way to calculate the relative head pose (M or M’), and the decoding method for the contact feature (Fc). It compares the performance metrics (Precision, Recall, F1, geodesic error, AUC, aIOU, and SIM) under different settings and also includes the error bars of EgoChoir’s main results as a reference.
Full paper#