↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current rationale extraction methods often struggle with spurious features—data points statistically correlated with the label but not causally related. These features hinder the identification of true causal rationales by methods such as those based on Maximum Mutual Information (MMI). Existing solutions using penalty-based methods offer only limited improvement.
This paper proposes a novel criterion, Maximizing Remaining Discrepancy (MRD), that effectively sidesteps this issue. Instead of focusing on the selected rationales, MRD focuses on the remaining data after rationale removal. It leverages the observation that removing either spurious features or plain noise does not alter the conditional distribution of remaining components relative to the label. This allows the model to treat both spurious features and noise identically, greatly simplifying the optimization problem. Empirical results show consistent improvements in rationale quality across diverse datasets, demonstrating the effectiveness of MRD.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the widely used MMI criterion in explainable AI, a significant advancement in the field. By introducing a novel approach that treats spurious features as noise, it improves rationale quality and simplifies the loss landscape, leading to more robust and reliable results. This opens avenues for improving model interpretability and developing more trustworthy AI systems.
Visual Insights#
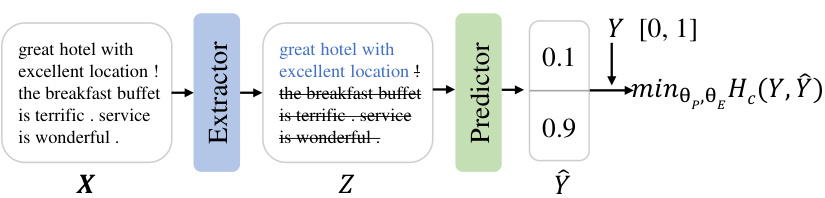
This figure illustrates the Rationalizing Neural Predictions (RNP) framework, a model-agnostic rationalization approach. The input text (X) is processed by an extractor that selects a subset of the most informative words (Z), called the rationale. This rationale is then used by a predictor to make a prediction (Ŷ) of the target variable (Y). The goal is to train the extractor and predictor cooperatively to maximize prediction accuracy, guided by the maximum mutual information (MMI) criterion.
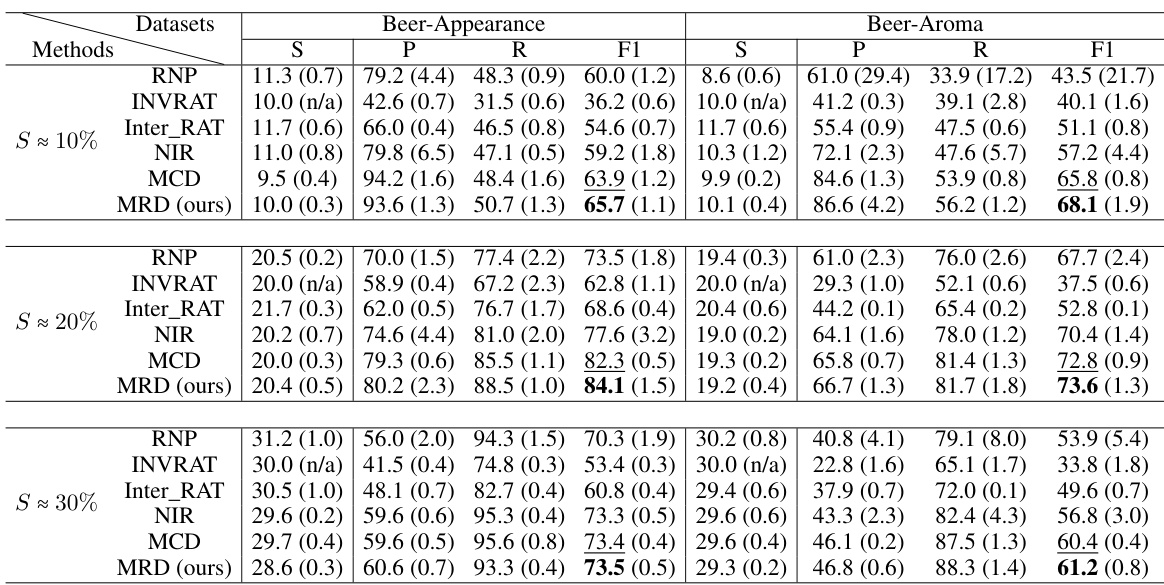
This table presents the performance of different rationale extraction methods (RNP, INVRAT, Inter_RAT, NIR, MCD, and MRD) on two datasets: Beer-Appearance and Beer-Aroma. The results are shown for three different sparsity levels (approximately 10%, 20%, and 30%) of selected rationales. The metrics reported are sparsity (S), precision (P), recall (R), and F1-score (F1). Standard deviations are included in parentheses. The table demonstrates the improved performance of the MRD method compared to other methods.
In-depth insights#
Spurious Correlation#
Spurious correlations, where variables appear related but lack a causal link, pose a significant challenge in various fields, especially in machine learning and AI. These misleading correlations can arise from confounding variables, impacting model accuracy and interpretability. Understanding the presence and impact of spurious correlations is crucial for building robust and reliable AI systems. Methods to mitigate this issue include careful data cleaning, feature engineering to isolate causal effects, and the development of algorithms less sensitive to spurious patterns. Addressing spurious correlations directly influences model fairness and generalizability, improving the trust and reliability of AI outcomes. Failing to account for spurious correlations can lead to inaccurate inferences and biased decision-making based on flawed associations. The identification and management of spurious correlations are thus essential steps in constructing high-quality, ethical AI systems.
MMI limitations#
The core limitation of the Maximum Mutual Information (MMI) criterion in rationale extraction lies in its susceptibility to spurious correlations. MMI prioritizes high mutual information between the rationale and the label, often inadvertently selecting features that are statistically correlated but not causally related to the prediction. This is particularly problematic in datasets rich in spurious features, where the model struggles to differentiate between genuinely informative and misleading signals. Penalty-based methods attempt to mitigate this by adding supplementary objectives penalizing spurious features; however, they require careful tuning of penalty weights. An improperly balanced penalty can either be ineffective in suppressing spurious features or overly strong, hindering the identification of causal rationales. The fundamental flaw is that these approaches still rely on MMI as the primary objective, merely attempting to correct its inherent weakness instead of replacing it entirely. Therefore, a more robust approach is needed to address the root cause of MMI’s limitations, rather than relying on imperfect corrections.
MRD Criterion#
The Maximizing Remaining Discrepancy (MRD) criterion offers a novel approach to rationale extraction by focusing on the remaining input after rationale selection. Instead of directly maximizing mutual information between the rationale and the label, MRD maximizes the discrepancy between the conditional distribution of the label given the full input and that given the remaining input after removing a potential rationale. This subtle shift in perspective is crucial because it effectively treats spurious features as equivalent to noise. By ignoring the information provided by potentially spurious rationales, the MRD criterion simplifies the loss landscape and prevents the model from being misled by spurious correlations. This fundamentally differs from penalty-based methods that attempt to correct the shortcomings of the Maximum Mutual Information (MMI) criterion by adding penalization terms. MRD’s elegance lies in its simplicity and theoretical grounding in d-separation, ensuring focus on causal features while robustly handling noise and spurious information. The effectiveness of MRD is validated through experiments demonstrating improved rationale quality compared to existing MMI-based and penalty methods. This approach promises a more reliable and interpretable method for extracting crucial rationales, especially in datasets with a high density of spurious features.
Empirical Evaluation#
An effective empirical evaluation section should robustly demonstrate the proposed method’s capabilities. It needs to clearly define the metrics used to assess performance, justifying their relevance to the research question. The chosen datasets should be representative and diverse, ideally including both standard benchmarks and potentially challenging scenarios to fully showcase the model’s strengths and limitations. A strong evaluation will include a thorough comparison against state-of-the-art baselines, ensuring a fair comparison and transparent reporting of results. Statistical significance testing should be employed to validate the observed improvements are not due to chance. Finally, the analysis needs to be insightful, going beyond simply reporting numbers; it should interpret the findings in light of the theoretical contributions, explaining any unexpected results and providing a balanced discussion of the overall implications.
Future Works#
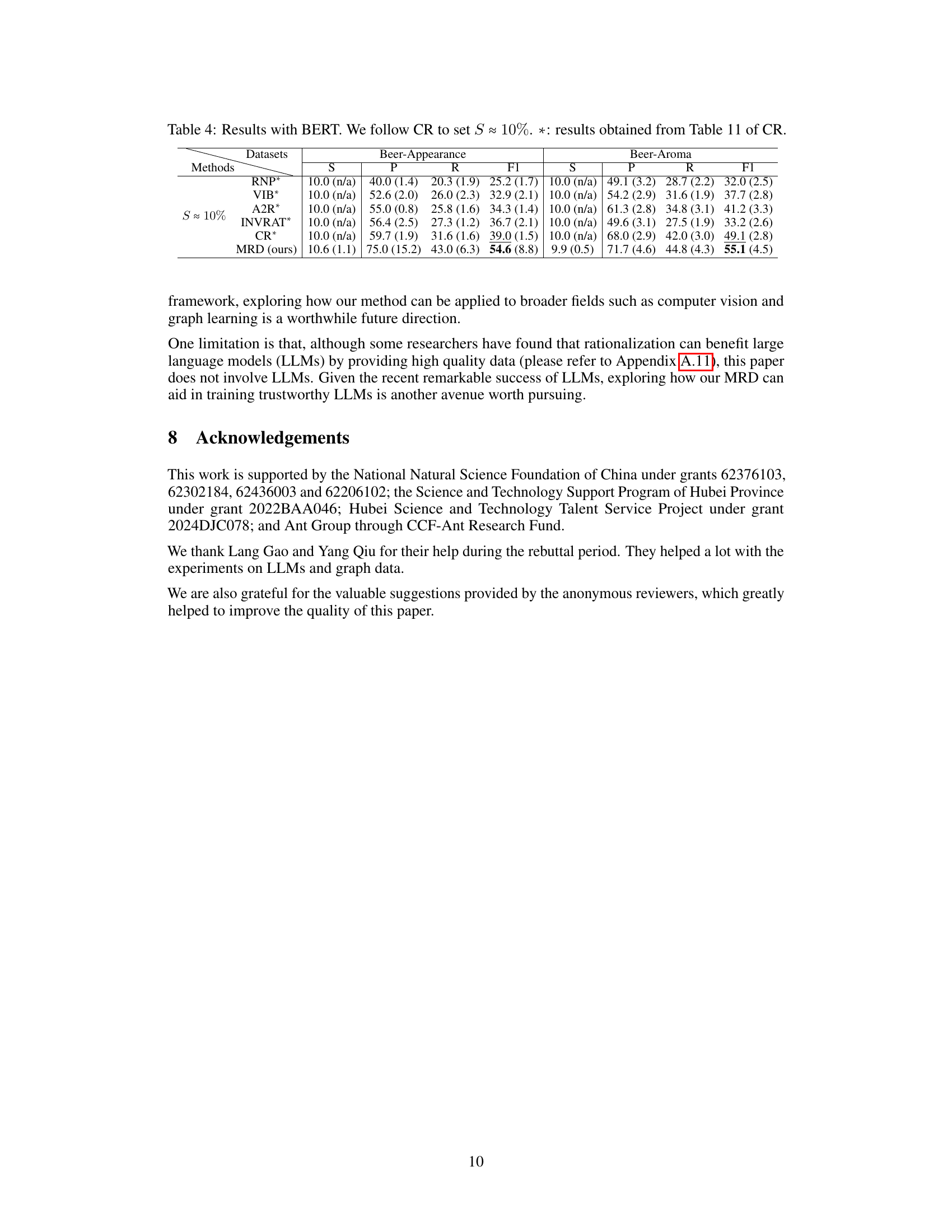
The paper’s core contribution is introducing the MRD criterion, which addresses the limitations of MMI in rationale extraction by treating spurious features as noise. Future work could explore the extension of MRD to other domains beyond NLP, such as computer vision and graph learning, leveraging its potential for improved explainability in various contexts. Investigating the robustness of MRD under different data distributions and noise levels would further solidify its practical applicability. Additionally, exploring the theoretical connections between MRD and causal inference more deeply could provide a stronger theoretical foundation. Combining MRD with other techniques for enhancing the interpretability of models, such as attention mechanisms or counterfactual analysis, is another promising direction. Finally, a direct comparison against approaches using LLMs would allow for an evaluation of MRD’s efficacy in the context of larger-scale language models and the broader landscape of explainable AI research.
More visual insights#
More on figures

This figure illustrates how penalty-based methods, which aim to improve the efficiency of searching causal rationales by penalizing spurious features, can result in various outcomes depending on the penalty’s strength. The x-axis represents the extractor’s parameter θ, while the y-axis represents the loss L. Four scenarios are shown: (a) under-penalty, where the penalty is insufficient to prevent the extractor from being drawn to spurious features (S); (b) no penalty, where the extractor is equally likely to select noise (N) or spurious features; (c) appropriate penalty, where the loss landscape is optimized for selecting the causal rationale (C); and (d) over-penalty, where the penalty dominates the loss function, reducing the ability of the MMI criterion to distinguish between noise and causal features.
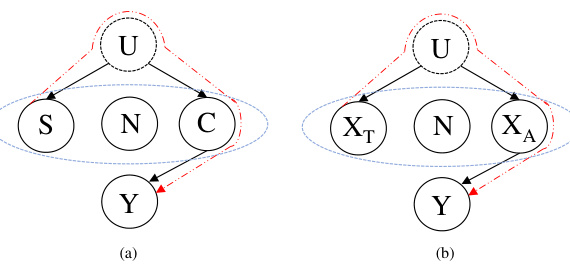
This figure illustrates two probabilistic graphical models representing data generation processes. (a) shows a general model with unobservable confounders U influencing both spurious features S and causal features C, which in turn affect the label Y. (b) illustrates the model for Beer-Appearance dataset, specifically. Here, XT and XA represent Taste and Appearance features. XA is a direct cause of Y, but XT is correlated with Y due to a backdoor path via the confounder U (e.g., brand reputation). This example highlights the challenge of spurious correlations in rationale extraction, where XT might be mistaken for a causal feature.

This figure illustrates the architecture of the Maximizing Remaining Discrepancy (MRD) method proposed in the paper. It shows how the model works to approximate two distributions: P(Y|X) and P(Y|X-Z). The model consists of an extractor that takes the input X and outputs a rationale Z and the remaining part X-Z. Two predictors share parameters to approximate P(Y|X) and P(Y|X-Z). The loss function is based on minimizing the KL divergence between the approximated and true distributions, thereby focusing on maximizing the remaining discrepancy after removing the rationale candidate from the full input.

This figure illustrates how different penalty strategies in the loss function affect the search for causal rationales when spurious features exist. Panel (a) shows an under-penalty scenario where the penalty term is too weak, resulting in the gradient descent algorithm potentially being drawn toward spurious features instead of causal ones. Panel (b) shows the unpenalized case (vanilla MMI), where the gradient may move toward either causal or spurious features. Panel (c) depicts an appropriate penalty scenario where the penalty term is balanced with the MMI criterion, leading to efficient identification of causal rationales. Panel (d) demonstrates an over-penalty scenario, where the penalty dominates the loss function, causing the gradient to potentially prioritize noise over causal features. The figure effectively demonstrates how the balance of penalty terms affects performance.
More on tables
This table presents the performance of various rationale extraction methods (RNP, INVRAT, Inter_RAT, NIR, MCD, and MRD) on two datasets: Beer-Appearance and Beer-Aroma. The results are shown for different levels of rationale sparsity (S ≈ 10%, S ≈ 20%, S ≈ 30%), measuring precision (P), recall (R), F1-score (F1), and sparsity (S). The table allows for comparison of the proposed MRD method against existing state-of-the-art techniques in terms of rationale quality.

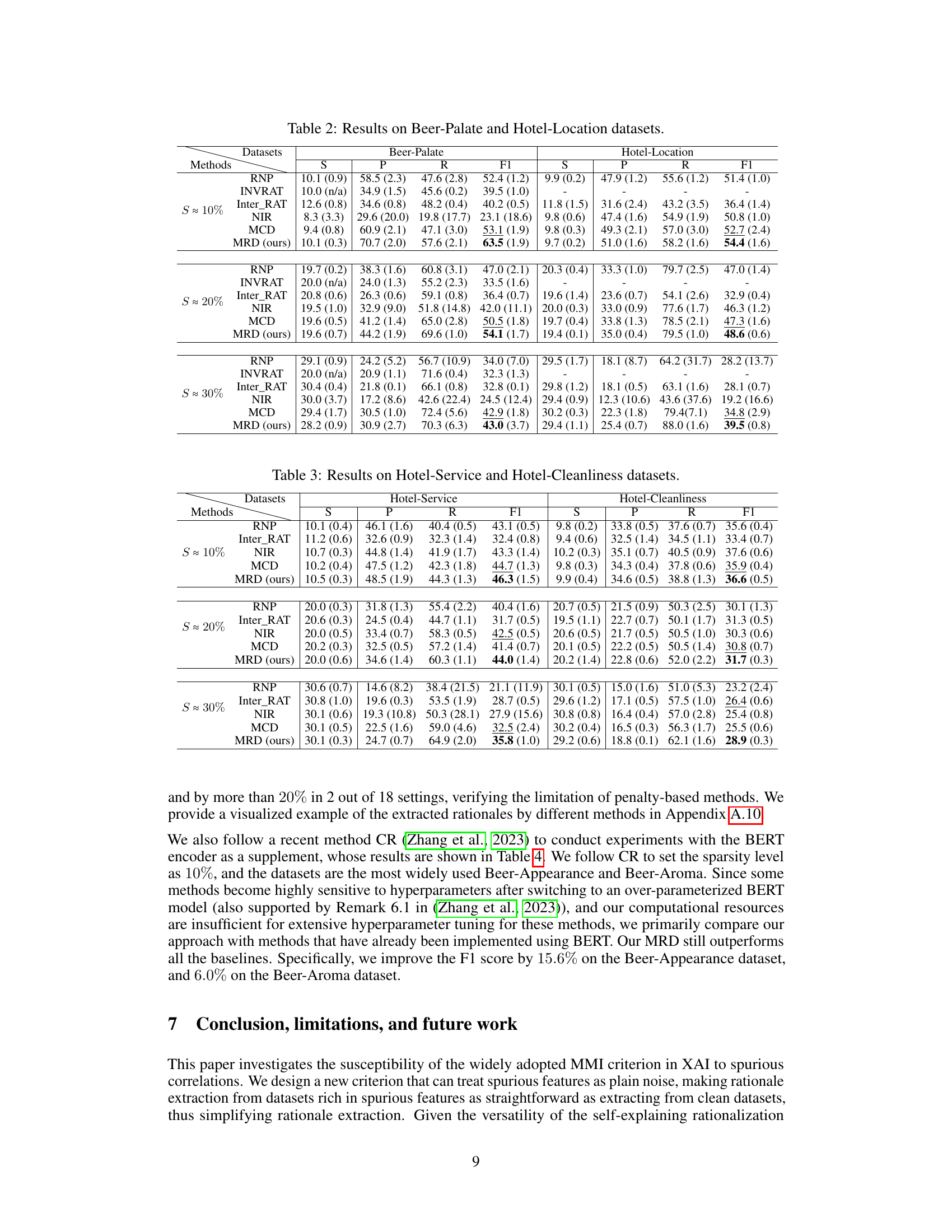
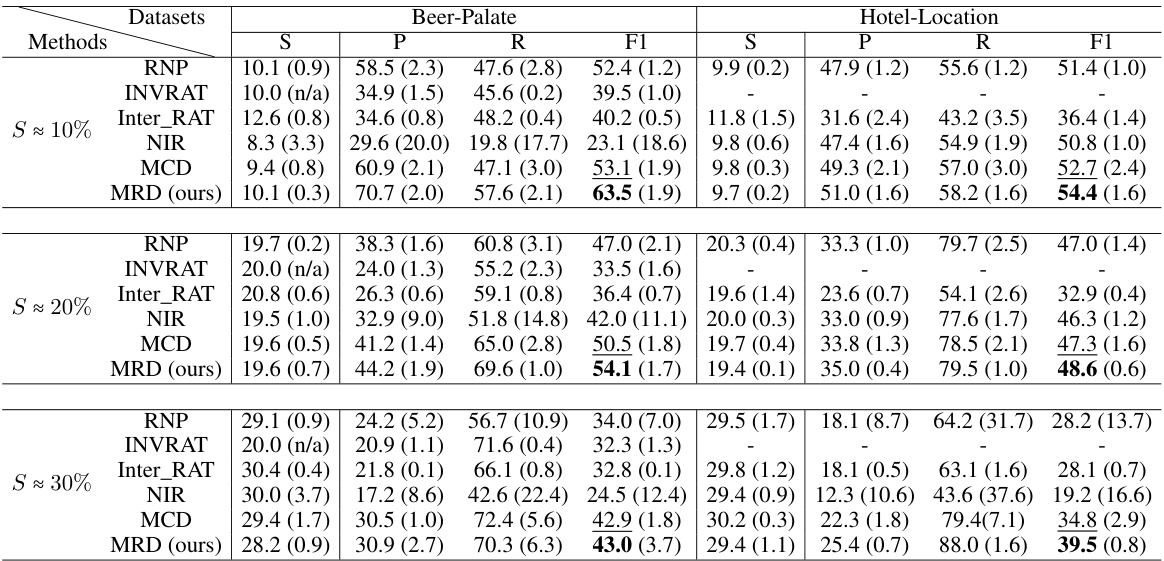
This table presents the performance of different rationale extraction methods on two datasets: Beer-Palate and Hotel-Location. The results are broken down by different levels of rationale sparsity (S ≈ 10%, S ≈ 20%, S ≈ 30%) and include precision (P), recall (R), F1-score (F1), and average sparsity (S). The table allows for comparison of the effectiveness of various methods in extracting relevant rationales across different sparsity levels and datasets.

This table presents the results of experiments using BERT as the encoder. It compares the performance of the proposed MRD method against several baseline methods (RNP, VIB, A2R, INVRAT, CR) on two datasets: Beer-Appearance and Beer-Aroma. The rationale sparsity (S) is fixed at approximately 10%. The results show the average performance (with standard deviation in parentheses) of each method across five random seeds in terms of sparsity (S), precision (P), recall (R), and F1-score (F1). The results marked with an asterisk (*) are taken directly from a previous study (CR).
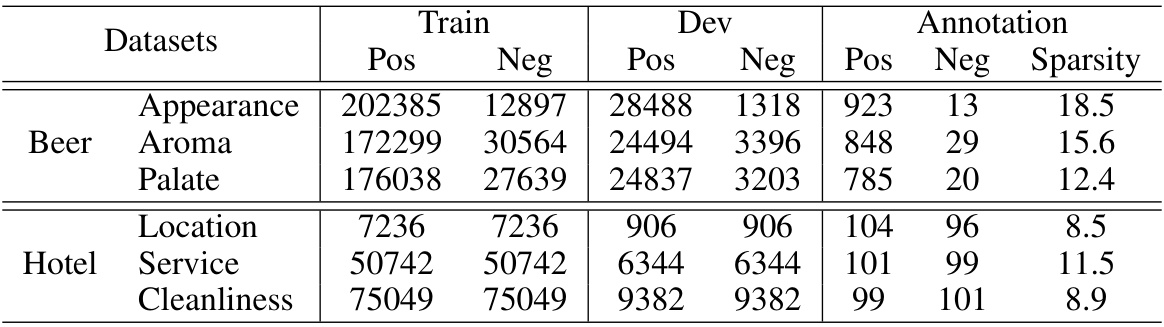
This table presents the number of positive and negative samples in the training, development, and annotation sets for each dataset used in the paper. It also indicates the number of positive and negative examples used for annotation, and the sparsity level (percentage of selected tokens) for each dataset. The datasets are categorized into Beer (Appearance, Aroma, Palate) and Hotel (Location, Service, Cleanliness).
Full paper#