↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many machine learning models use the highest predicted probability as a confidence score. However, this score is often poorly calibrated, especially when there are many possible classes. This is a serious problem for applications where trust is crucial, such as self-driving cars or medical diagnosis. Current methods either don’t scale well to many classes or overfit available data.
This paper introduces a novel technique called Top-versus-All (TvA) to address this. TvA recasts the multi-class calibration problem as a single binary classification problem—predicting whether a prediction is correct or not. By doing so, standard calibration methods can be applied more efficiently, overcoming previous limitations. The authors show that this improves several established calibration methods and achieves state-of-the-art results in various image and text classification tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on confidence calibration in machine learning, particularly for multi-class classification problems. It addresses a significant limitation of existing methods by proposing a novel and efficient approach. This work opens up new avenues for improving the reliability and trustworthiness of AI systems, which is essential for their deployment in real-world scenarios, especially safety-critical ones.
Visual Insights#

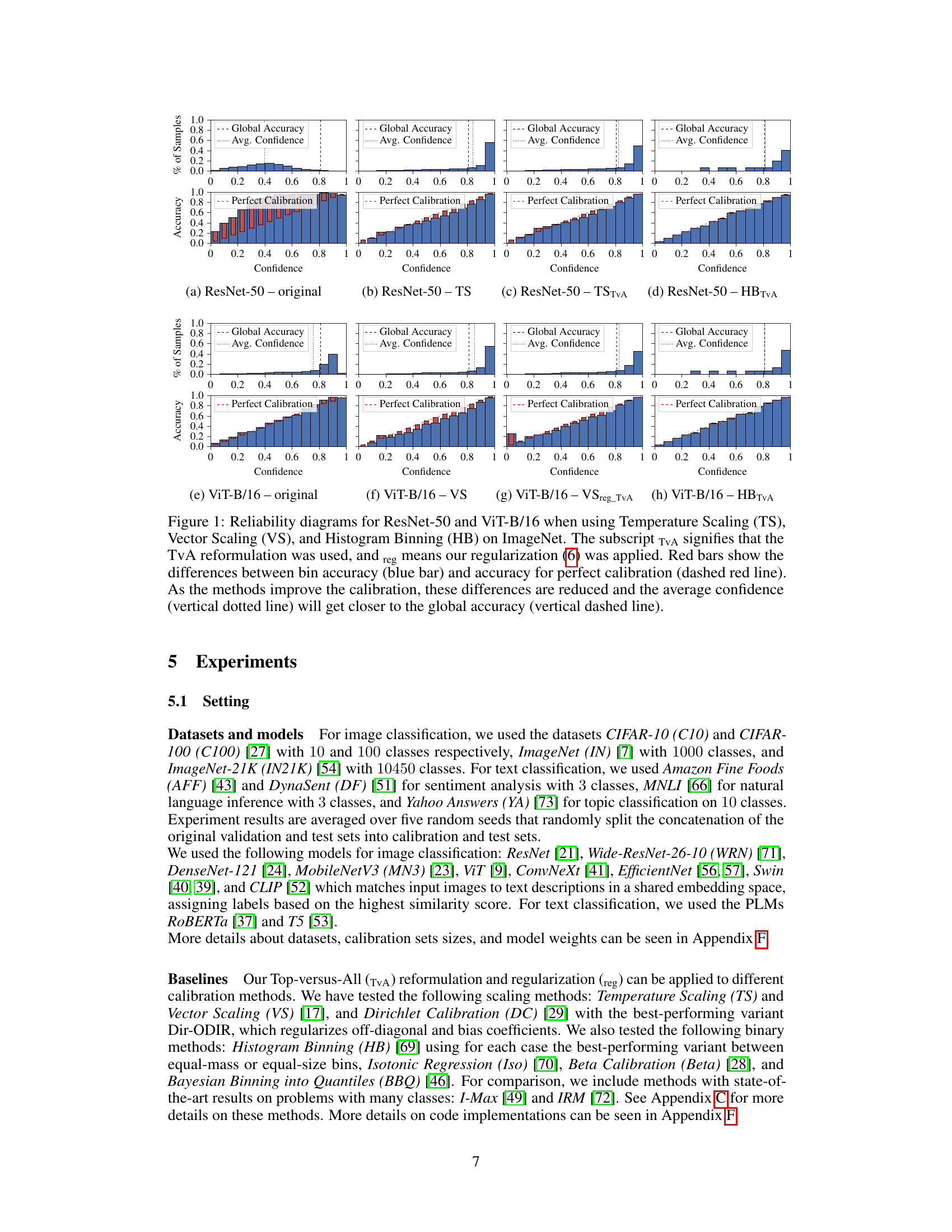
This figure shows reliability diagrams for two different models (ResNet-50 and ViT-B/16) trained on the ImageNet dataset, using several calibration methods (Temperature Scaling, Vector Scaling, and Histogram Binning). Each diagram displays the relationship between predicted confidence and the actual accuracy for each confidence bin. The effect of the Top-versus-All (TvA) approach and a regularization technique are shown by comparing the results with and without these methods. The goal is to visually demonstrate how well the calibrated confidence scores reflect the actual probability of a correct prediction.
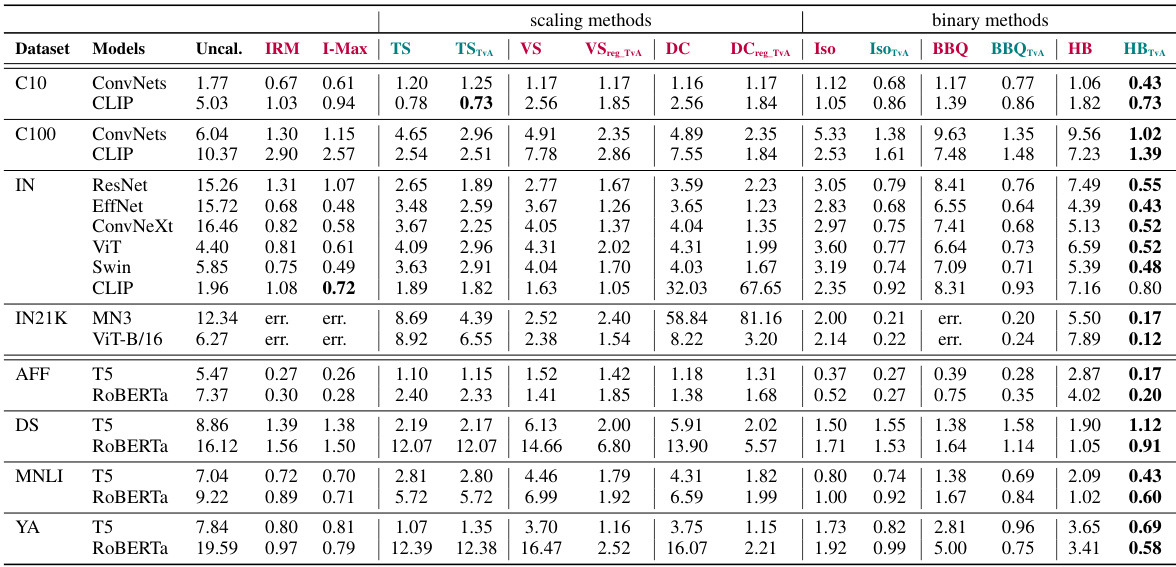
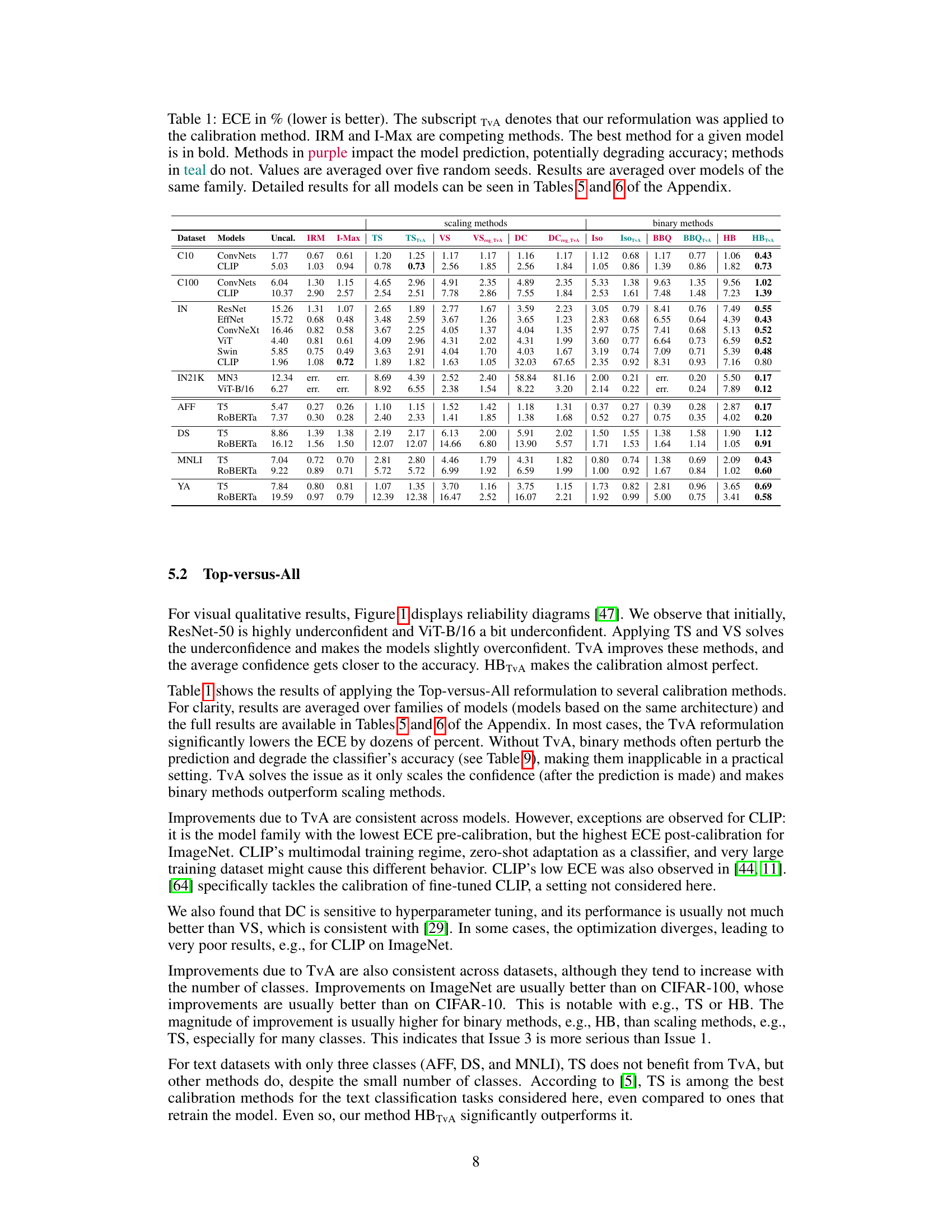
This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. It compares the performance of the proposed Top-versus-All (TvA) approach against standard methods and two competing methods (IRM and I-Max). The table highlights the best performing method for each model and indicates which methods may negatively impact model accuracy. Detailed results for individual models are referenced in the Appendix.
In-depth insights#
Multiclass Calib.#
Multiclass calibration presents a significant challenge in machine learning, as it aims to ensure that predicted probabilities accurately reflect the likelihood of a model’s classification accuracy across multiple classes. Standard approaches often struggle with high-dimensional data and numerous classes. This is because of issues such as data imbalance in one-vs-rest methods, the overfitting tendencies of some scaling methods, and the limitations of cross-entropy loss in directly decreasing confidence in incorrect predictions. The Top-versus-All (TvA) approach offers a novel solution by transforming the multiclass problem into a single binary classification problem, focusing on the prediction’s correctness rather than individual class probabilities. This elegant reformulation allows for more effective use of existing calibration methods, significantly improving performance without requiring complex adaptations. TvA addresses the limitations of previous approaches by mitigating overfitting, utilizing balanced datasets, and leveraging the efficiency of binary cross-entropy loss. This results in more accurate uncertainty quantification, paving the way for enhanced decision-making in critical applications where reliability and trustworthiness are paramount.
TvA Approach#
The Top-versus-All (TvA) approach presents a novel reformulation of the multiclass confidence calibration problem. Instead of calibrating each class independently, TvA transforms the problem into a single binary classification task: predicting whether the classifier’s prediction is correct or not. This simplification offers several key advantages. First, it resolves issues of imbalanced datasets and scalability that plague traditional One-versus-All methods, especially in high-dimensional settings with numerous classes. Second, TvA allows for more efficient utilization of existing binary calibration methods, streamlining the process and reducing computational complexity. By focusing solely on the maximum predicted probability (confidence), TvA avoids unnecessary computations and overfitting. Moreover, TvA enhances the performance of scaling methods by improving gradient efficiency, leading to better calibration. The results demonstrate TvA’s ability to improve calibration significantly across various datasets and model architectures, highlighting its potential as a valuable tool for enhancing the reliability of multiclass classifiers.
Scaling Methods#
Scaling methods, in the context of confidence calibration, aim to improve the accuracy of predicted probabilities by applying a scaling transformation to the logits (pre-softmax values) of a neural network. Temperature scaling, a prominent example, uses a single scaling factor to adjust all logits, offering simplicity and efficiency. However, more sophisticated methods like vector scaling allow for class-specific scaling, providing potentially greater calibration accuracy but at the cost of increased model complexity and the risk of overfitting, especially with high-dimensional data or numerous classes. The choice of scaling method often involves a trade-off between calibration performance and computational cost, along with the risk of overfitting which necessitates careful consideration of regularization techniques or alternative calibration strategies. Effective scaling methods enhance predictive reliability, which is crucial for high-stakes applications where decision-making depends heavily on well-calibrated confidence scores.
Binary Methods#
The concept of “Binary Methods” in the context of multi-class classification calibration is a powerful technique to address the limitations of traditional approaches. Transforming a multi-class problem into a series of binary problems simplifies the calibration process significantly. This is especially beneficial when dealing with high-dimensional data and numerous classes, where traditional methods often struggle with computational cost and overfitting. Binary methods offer a more efficient way to calibrate confidence scores, focusing on the crucial binary decision: “correct” or “incorrect.” While there are some inherent challenges such as handling imbalanced datasets and maintaining the ranking of class probabilities after calibration, the streamlined nature of binary approaches opens up opportunities for faster and more accurate calibration. However, it is important to note that successful implementation requires careful consideration of dataset imbalances and selection of appropriate calibration methods. Ultimately, the choice between scaling and binary approaches depends on the specific characteristics of the dataset and desired performance metrics.
Future Work#
Future research directions stemming from this confidence calibration work could involve exploring more sophisticated multiclass-to-binary transformations beyond the Top-versus-All approach. Investigating alternative binary problem formulations that might better capture the nuances of multiclass uncertainty is crucial. Furthermore, extending the Top-versus-All approach to other calibration methods beyond scaling and binary methods would broaden its applicability and potential impact. A particularly promising avenue lies in combining the Top-versus-All framework with existing advanced calibration techniques like Bayesian methods or ensemble methods to potentially achieve even better calibration results. Finally, the impact of the proposed methodology should be studied in various real-world applications. Rigorous testing in safety-critical domains will assess the reliability of TvA in high-stakes scenarios, while analysis of its performance on imbalanced datasets is needed for widespread adoption.
More visual insights#
More on figures

This figure displays reliability diagrams for two different models, ResNet-50 and ViT-B/16, trained on the ImageNet dataset. It showcases the impact of various calibration methods (Temperature Scaling, Vector Scaling, and Histogram Binning) with and without the Top-versus-All (TvA) reformulation and regularization. Each diagram shows the relationship between predicted confidence and actual accuracy across different confidence intervals. The red bars represent the difference between the accuracy within a confidence interval and the ideal accuracy (perfect calibration). The goal is to minimize the height of these red bars, indicating better calibration. The vertical dotted line represents the average confidence, which ideally should approach the global accuracy (dashed line) as calibration improves.
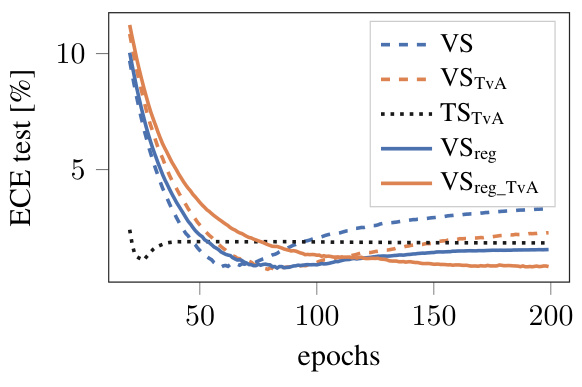
This figure shows reliability diagrams for two different model architectures (ResNet-50 and ViT-B/16) trained on the ImageNet dataset. Reliability diagrams plot the relationship between predicted confidence and the actual accuracy. The plots illustrate the impact of different calibration methods (Temperature Scaling, Vector Scaling, and Histogram Binning) and the Top-versus-All (TvA) approach, with and without regularization. Perfect calibration is represented by the dashed red line. The closer the plotted line is to this line, the better the calibration. The red bars highlight the differences between bin accuracy and average confidence within each confidence bin.

This figure presents reliability diagrams for ResNet-50 and ViT-B/16 models on the ImageNet dataset. It compares several calibration methods: Temperature Scaling (TS), Vector Scaling (VS), and Histogram Binning (HB), both with and without the Top-versus-All (TvA) reformulation and regularization. The diagrams visualize the relationship between confidence (x-axis) and accuracy (y-axis), illustrating how well the predicted confidence score reflects the true probability of correctness. The red bars represent the calibration error (difference between accuracy and confidence within each bin). The aim is for the red bars to shrink, indicating improved calibration, and for the average confidence to closely match the overall accuracy.

This figure displays reliability diagrams for two different models (ResNet-50 and ViT-B/16) trained on the ImageNet dataset. It compares the performance of several calibration methods (Temperature Scaling, Vector Scaling, and Histogram Binning) with and without the Top-versus-All (TvA) reformulation and regularization. Each subplot shows the relationship between confidence and accuracy for a specific method, illustrating how well the predicted confidence reflects the actual probability of a correct classification. The red bars represent the difference between bin accuracy and perfect calibration, providing a visual measure of the calibration error. As calibration improves, the red bars decrease, and the average confidence approaches the global accuracy.
More on tables

This table presents the Expected Calibration Error (ECE) for various image and text classification models, comparing different calibration methods. The ECE measures how well a model’s confidence estimates match its actual accuracy. Lower ECE values indicate better calibration. The table shows ECE values for uncalibrated models, models calibrated using the Top-versus-All (TvA) approach, and other competitive methods like IRM and I-Max. The best-performing method for each model is highlighted. Color-coding indicates whether a method affects the model’s prediction accuracy.
This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image and text classification models. It compares the performance of the proposed Top-versus-All (TvA) approach with several existing methods (including IRM and I-Max). The best-performing method for each model is highlighted. The table also indicates whether a method affects model prediction accuracy (purple) or not (teal), and provides averages over multiple random seeds and model families for clarity. More detailed results are available in the appendix.

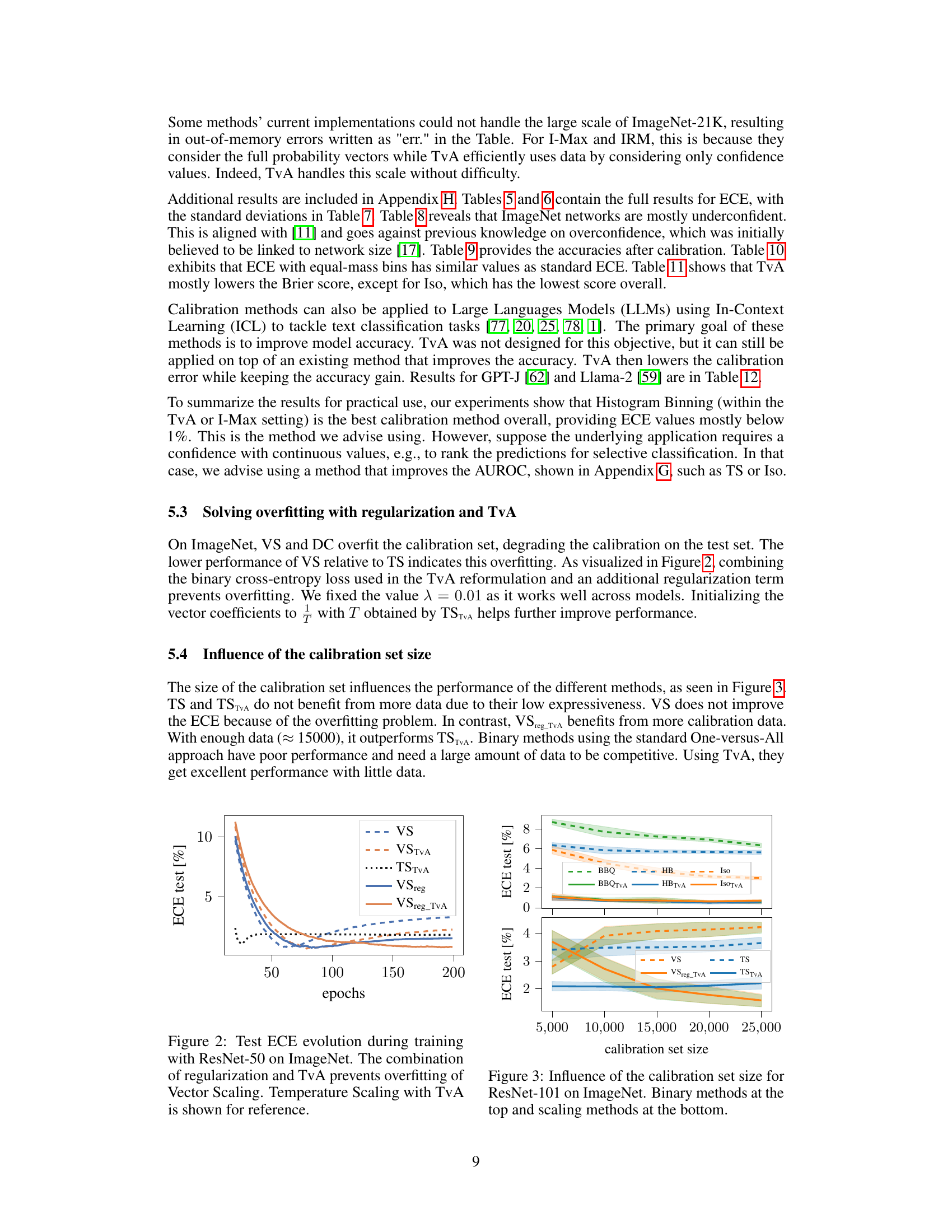
This table presents the computation time required for different calibration methods on the ImageNet dataset using a single NVIDIA V100 GPU. The preprocessing time, encompassing the calculation of model logits for all calibration examples, is also shown. The table highlights that post-hoc calibration methods generally require significantly less computation time compared to the training of classifiers.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. The ECE measures the difference between a model’s confidence in its predictions and its accuracy. Lower ECE values indicate better calibration. The table compares the performance of standard methods with the proposed Top-versus-All (TvA) approach, highlighting improvements achieved by TvA across a range of models and datasets. It also includes results from competing methods (IRM and I-Max). Color coding distinguishes methods that affect model accuracy from those that do not. The full results are available in the Appendix.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. The ECE measures the difference between a model’s confidence and its accuracy. Lower ECE values indicate better calibration. The table shows the results for uncalibrated models, as well as several calibration methods, including the proposed Top-versus-All (TvA) approach. It highlights the best-performing method for each model and dataset and indicates whether methods affect prediction accuracy. Detailed results are available in the appendix.
This table presents the Expected Calibration Error (ECE) for various image and text classification models and calibration methods. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against several baseline calibration methods (Temperature Scaling, Vector Scaling, Histogram Binning, etc.) and two competing methods (IRM and I-Max). Results are averaged across five random seeds and grouped by model family (e.g., ResNet, EfficientNet). Methods that may affect model accuracy are highlighted.

This table presents the Expected Calibration Error (ECE) for various multi-class classification models and calibration methods. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against several existing calibration methods (Temperature Scaling, Vector Scaling, Dirichlet Calibration, Histogram Binning, etc.) and two competing methods (IRM and I-Max). Results are averaged across multiple runs with different random seeds, and also averaged across models of the same architectural family (e.g., different sizes of ResNet). The best performing method for each model is highlighted in bold. Color-coding indicates whether a method affects the model’s prediction accuracy (purple) or not (teal). For more detailed results, the reader is referred to Tables 5 and 6 in the Appendix.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image classification models and datasets. It compares the performance of the proposed Top-versus-All (TvA) approach to existing methods (Temperature Scaling, Vector Scaling, Dirichlet Calibration, Histogram Binning, Isotonic Regression, Beta Calibration, Bayesian Binning into Quantiles, I-Max, and IRM). The table highlights the impact of TvA on different model families (ConvNets, CLIP) and datasets (CIFAR-10, CIFAR-100, ImageNet, ImageNet-21K), showing improvements and indicating whether a method affects model prediction accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. Lower ECE values indicate better calibration. The table compares the performance of the Top-versus-All (TvA) approach against standard methods and two competing methods, IRM and I-Max. It highlights which methods are accuracy-preserving and which might negatively impact accuracy. Results are averaged across multiple random seeds and model families for a more robust comparison. More detailed results are available in the Appendix.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against standard methods and two competing approaches (IRM and I-Max). It also highlights the impact of the TvA method on model accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models on various datasets. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach with standard methods and two competing approaches (IRM and I-Max). The impact of the TVA approach on model accuracy is also indicated via color-coding.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image and text classification datasets and models. The ECE, a metric of calibration quality, measures the discrepancy between a model’s confidence and its accuracy. Lower ECE values indicate better calibration. The table shows ECE values for uncalibrated models, two competing state-of-the-art multiclass calibration methods (IRM and I-Max), and several calibration methods enhanced by the proposed Top-versus-All (TvA) approach. The effect of TvA on the models is highlighted through color-coding: purple indicates that the method may impact the model’s prediction accuracy, while teal indicates that it likely does not. The table is averaged over five different random seeds to improve reliability.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. The ECE measures the difference between a model’s confidence and its accuracy. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against other established methods. The color-coding helps to identify if a method impacts the model’s accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against standard methods and other state-of-the-art techniques (IRM and I-Max). The results are averaged over five random seeds and grouped by model family for easier comparison. Methods are color-coded to show whether they affect model accuracy.

This table presents the Expected Calibration Error (ECE) for various image and text classification models and calibration methods. Lower ECE values indicate better calibration. The table compares the performance of several calibration methods, including those enhanced by the proposed Top-versus-All (TvA) approach, to standard baselines and competing methods (IRM and I-Max). Methods that potentially affect model accuracy are highlighted in purple, while those that don’t are in teal. Results are averages over five random seeds and grouped by model family for better readability. Detailed per-model results are found in the Appendix.

This table presents the Expected Calibration Error (ECE) for various multiclass classification models and calibration methods. The ECE measures the difference between the model’s confidence and its accuracy. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach with other state-of-the-art methods (IRM, I-Max) across several datasets and model architectures. The table highlights which methods (colored purple and teal) do and do not affect a model’s prediction accuracy. Results are averaged over five different random seed runs and grouped by model families for better interpretability.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models on several image and text classification datasets. The ECE, a metric measuring calibration quality, is shown in percentage, with lower values indicating better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against existing methods (IRM, I-Max), standard scaling methods (TS, VS, DC), and standard binary methods (Iso, BBQ, HB). The impact of TvA on different calibration methods is demonstrated, and the best performing method for each model is highlighted. Methods impacting model prediction accuracy are color-coded (purple). Detailed results for individual models are referenced in the Appendix.

This table presents the Expected Calibration Error (ECE) for various image and text classification models and calibration methods. It compares the standard calibration methods against the proposed Top-versus-All (TvA) approach. The ECE values represent how well a model’s confidence scores match its accuracy. Lower values indicate better calibration. The table highlights which methods improve calibration and whether they affect the model’s prediction accuracy, as indicated by the color-coding.

This table presents the Expected Calibration Error (ECE) for various models and calibration methods. Lower ECE values indicate better calibration. The table compares the performance of the Top-versus-All (TvA) approach to other calibration methods, including IRM and I-Max. The best-performing method for each model is highlighted in bold. Note that some methods can negatively impact model accuracy (purple), while others do not (teal). The results are averages over five random seeds and multiple models within the same family, with complete results in the Appendix.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against existing methods, including IRM and I-Max. The best-performing method for each model is highlighted. The table also notes whether a method may negatively affect model accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models on various datasets. The ECE measures the discrepancy between a model’s predicted confidence and its accuracy. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach with standard techniques and two competing methods (IRM and I-Max). The best performing method for each model is highlighted. Methods that may negatively affect model accuracy are indicated.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models on various datasets. The ECE is a metric measuring the calibration quality. Lower ECE values indicate better calibration. The table compares the performance of the proposed ‘Top-versus-All’ (TvA) approach against several standard calibration methods and two state-of-the-art methods (IRM and I-Max). The color-coding highlights methods that may affect model prediction accuracy.

This table presents the Expected Calibration Error (ECE) for various models and calibration methods. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against several baseline and competing methods (IRM and I-Max). The best performing method for each model is highlighted in bold. The color-coding indicates whether a method affects model prediction accuracy (purple) or not (teal). Averages are calculated over five random seeds and across models within the same family.
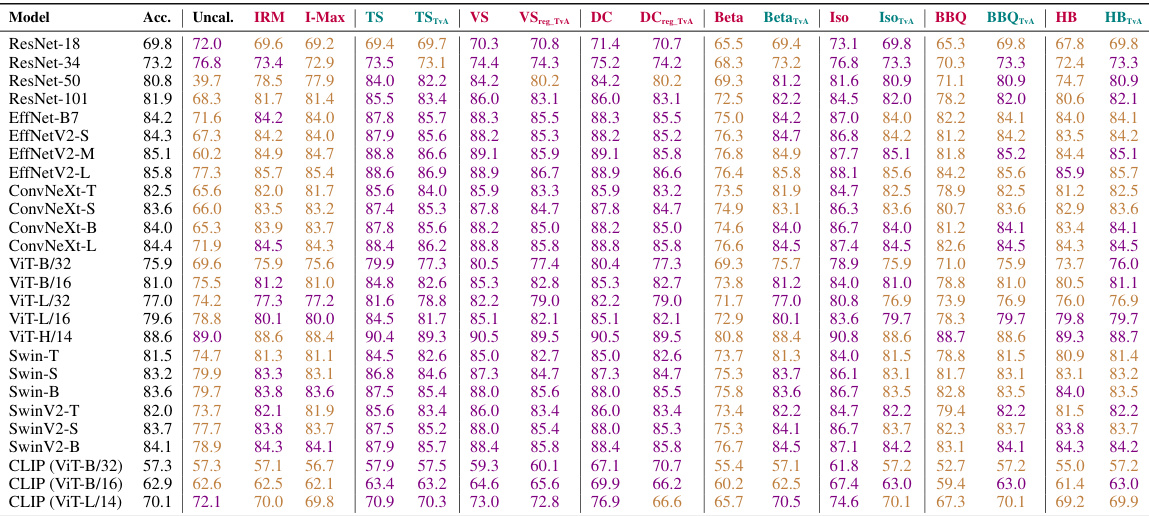
This table presents the Expected Calibration Error (ECE) for various image and text classification models and calibration methods. It compares the performance of the proposed Top-versus-All (TvA) approach against other state-of-the-art methods (IRM and I-Max), including standard scaling and binary calibration techniques. The table highlights the effectiveness of TvA in improving calibration, particularly for models with a large number of classes. Lower ECE values indicate better calibration. Methods are categorized by color to indicate whether they affect model accuracy.

This table presents the Expected Calibration Error (ECE) in percentage for various image and text classification models. Lower ECE values indicate better calibration. The table compares the performance of several calibration methods, including the proposed Top-versus-All (TvA) approach, against existing methods (IRM and I-Max). The best performing method for each model is highlighted in bold. Methods that might negatively impact model accuracy are indicated in purple, while those that preserve accuracy are in teal. Results are averaged across five random seeds and across models within the same family (e.g., all ResNet models). Detailed results for all individual models are available in the Appendix.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models on several datasets. It shows ECE values for uncalibrated models, as well as results after applying several calibration methods (including IRM and I-Max, competing methods), with and without the Top-versus-All (TvA) reformulation proposed in the paper. The table highlights which methods are best suited to each model, distinguishing between methods that may impact model accuracy and those that do not.

This table presents the Expected Calibration Error (ECE) in percentage for various calibration methods applied to different models and datasets. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against existing methods, including IRM and I-Max. The best performing method for each model is highlighted in bold. Note that some methods may impact model prediction accuracy (purple), while others do not (teal). Results are averaged across five different random seeds and grouped by model family.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image classification models on several datasets. The ECE is a metric for evaluating the calibration of a classifier, measuring the difference between a model’s confidence in its predictions and its actual accuracy. The table compares the performance of different calibration methods, both standard ones and ones modified using the Top-versus-All (TvA) approach introduced in the paper. The best performing method for each model is highlighted in bold. Methods that may affect the model’s prediction accuracy are indicated in purple, while those that do not are in teal. The average performance across models within the same family is reported. For more detailed results, refer to Tables 5 and 6 in the Appendix.

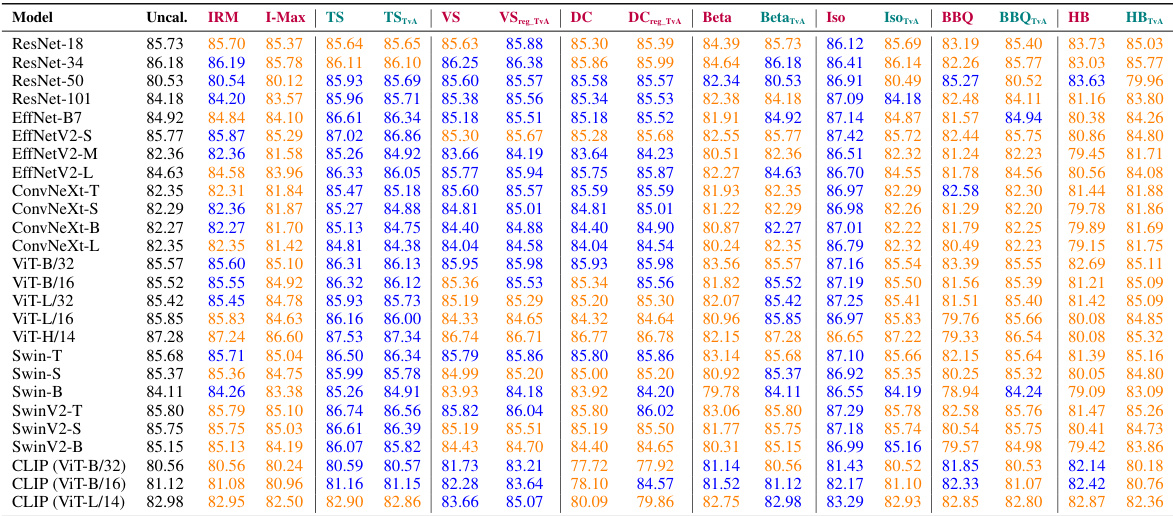
This table presents the Area Under the Receiver Operating Characteristic curve (AUROC) for various models and datasets, comparing different calibration methods. The AUROC is a measure of a classifier’s ability to distinguish between classes, and higher values indicate better performance. The table highlights the impact of different calibration techniques (including the authors’ proposed Top-versus-All approach) on the overall accuracy of the model. The colors indicate whether a method improves or decreases the AUROC compared to the uncalibrated model.

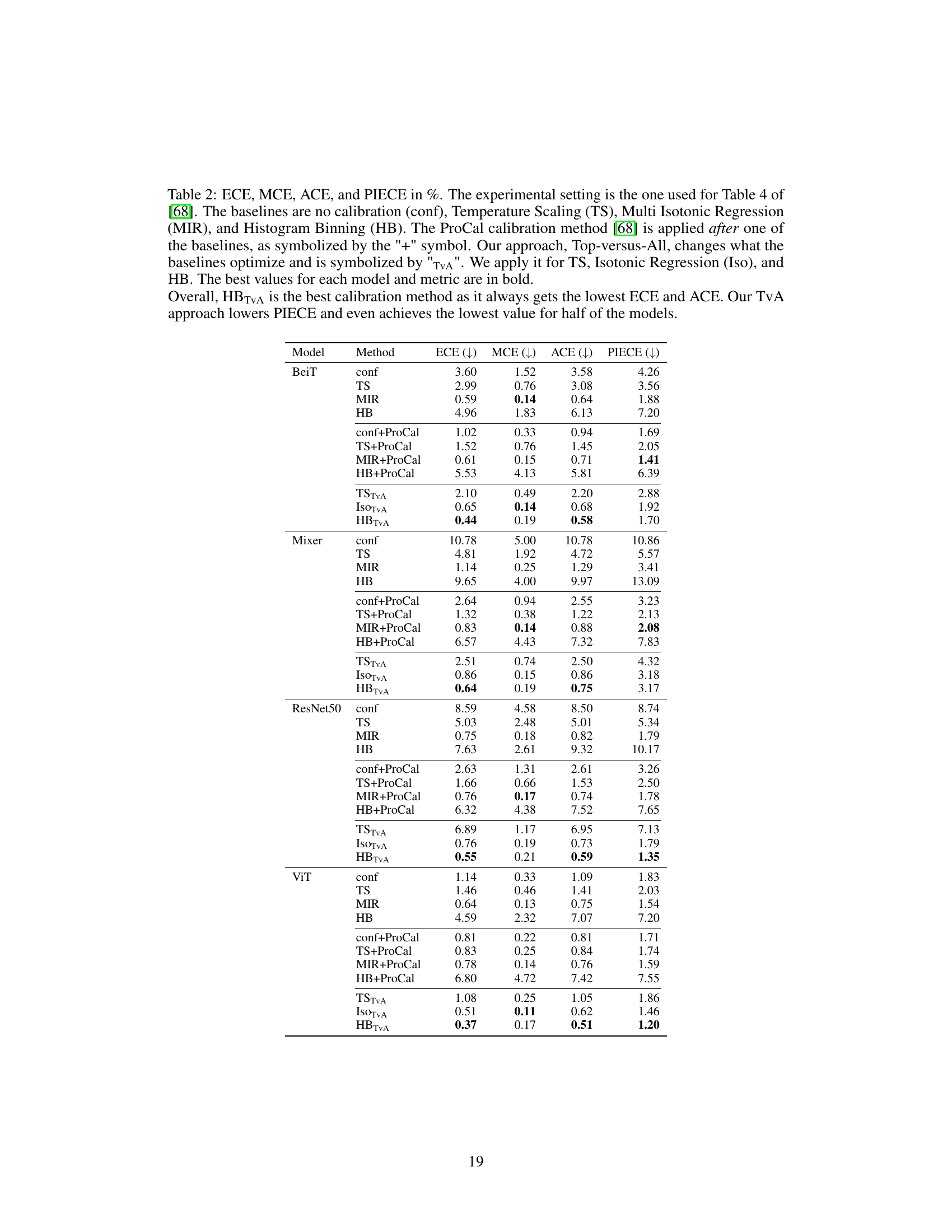
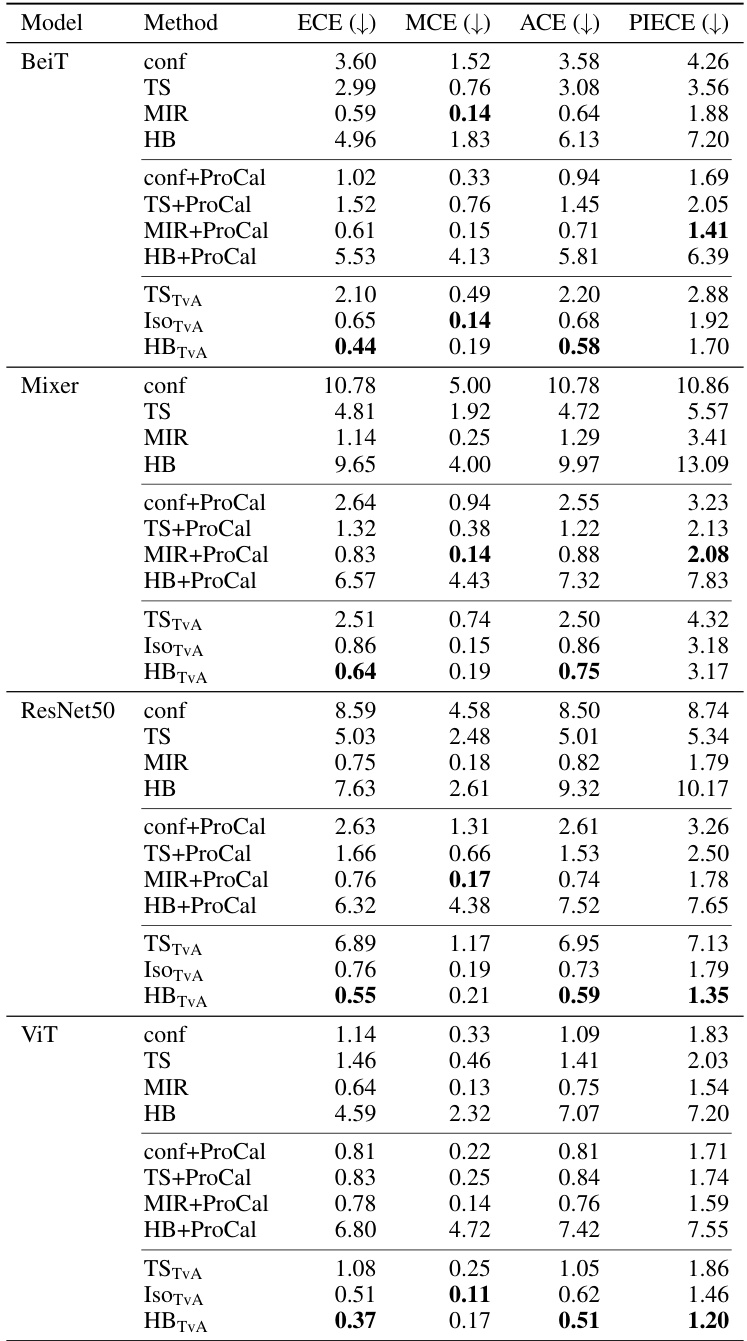
This table presents the Expected Calibration Error (ECE) for various image and text classification models, with and without the Top-versus-All (TvA) calibration method. It compares the performance of TvA against other multiclass calibration methods (IRM, I-Max, Temperature Scaling, Vector Scaling, Dirichlet Calibration, Histogram Binning, Isotonic Regression, Beta Calibration, Bayesian Binning into Quantiles) across several datasets (CIFAR-10, CIFAR-100, ImageNet, ImageNet-21K, Amazon Fine Foods, DynaSent, MNLI, Yahoo Answers). Lower ECE values indicate better calibration. The table highlights that the TvA approach generally improves the performance of existing calibration methods, especially for models with many classes. Methods are colored to show if they potentially affect model accuracy.

This table presents the Expected Calibration Error (ECE) for various image and text classification models with and without the Top-versus-All (TvA) calibration method. It compares the performance of TvA with other state-of-the-art multi-class calibration techniques. Lower ECE values indicate better calibration. The table highlights the improvement of TVa for many models, particularly in reducing the ECE. The color coding helps to visually distinguish methods that affect model accuracy from those that do not.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image and text classification datasets and models. The ECE measures the calibration error of a classifier’s confidence scores. Lower ECE values indicate better calibration. The table shows the ECE for uncalibrated models and various post-processing calibration techniques, including the authors’ proposed Top-versus-All (TvA) approach and two competing methods (IRM and I-Max). The results are averaged over five random seeds for each model and also over models within the same family (e.g., different ResNet variants). The best performing method for each model is highlighted in bold. Color coding indicates whether a method alters the original model predictions (purple) or not (teal). Detailed results for all models are available in the Appendix.

This table presents the Expected Calibration Error (ECE) in percentage for various models and calibration methods. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against existing methods (IRM, I-Max) and different calibration techniques (Temperature Scaling, Vector Scaling, Dirichlet Calibration, Histogram Binning, etc.). The best-performing method for each model is highlighted, and the impact of the calibration method on the model’s prediction accuracy is indicated by color-coding.

This table presents the Expected Calibration Error (ECE) for various multi-class classification models and calibration methods. The ECE measures the difference between the model’s confidence and its accuracy. Lower ECE values indicate better calibration. The table compares the performance of several existing calibration methods and a new approach proposed by the authors (Top-versus-All, indicated by the subscript ‘TVA’). It also includes results from two competing methods, I-Max and IRM. The table highlights which methods improve calibration without negatively affecting model accuracy. Results are averaged across multiple random seeds and similar model architectures.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image classification datasets and models. The ECE measures the difference between a model’s confidence and its accuracy. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against other methods and highlights the best-performing method for each model. The use of TVA is denoted by a subscript. Methods that might negatively affect model accuracy are highlighted in purple, while those that don’t are shown in teal. The table averages results over five runs with different random seeds, and also averages over models of the same family (e.g., different sizes of ResNet). More details are available in the Appendix.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image classification models and datasets. The ECE measures how well a model’s confidence scores reflect the true probability of correctness. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against standard calibration methods and other state-of-the-art techniques. It highlights the impact of the TvA reformulation on various calibration methods and shows the best-performing method for each model. It also notes whether a particular method negatively impacted model accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models. Lower ECE values are better, indicating better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against several existing methods, including IRM and I-Max. The best-performing method for each model is highlighted in bold. Methods that might negatively affect model accuracy are indicated in purple, while those that preserve accuracy are in teal. The results are averages over five independent runs with different random seeds.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image and text classification models. The ECE values show how well-calibrated the confidence scores are. Lower ECE values indicate better calibration. The table compares the performance of the standard calibration methods against the Top-versus-All (TvA) approach, and two competing methods (IRM and I-Max). The best-performing method for each model is highlighted in bold. The color-coding helps to distinguish methods that might negatively impact model accuracy (purple) from those that don’t (teal). The results are averaged over five different random seeds for each model and across models within the same family (e.g., different ResNet versions).

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image and text classification models and datasets. The ECE values are shown, with lower values indicating better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach with other state-of-the-art methods (IRM and I-Max). The best performing method for each model is highlighted in bold, and color-coding is used to distinguish methods that may affect the model’s predictive accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. The ECE measures the difference between a model’s confidence and its accuracy, with lower values indicating better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against several existing methods, including IRM and I-Max. It shows the ECE for both the original methods and those modified by using the TvA approach. Note the color coding to indicate whether a method affects prediction accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models on various datasets. The ECE is a metric measuring calibration accuracy. Lower ECE values indicate better calibration. The table highlights the improvement achieved by the Top-versus-All (TvA) approach, showing that it significantly improves the performance of various existing methods.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models on multiple datasets. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against existing methods (IRM, I-Max) and standard techniques (Temperature Scaling, Vector Scaling, etc.). The color-coding helps to quickly identify methods that may negatively impact model accuracy. Detailed results for each model are available in the Appendix.

This table presents the Expected Calibration Error (ECE) for various image and text classification models and calibration methods. The ECE measures the miscalibration of a model’s confidence scores. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against several baseline and state-of-the-art calibration methods across different datasets and model architectures. Methods are categorized by whether they affect the model’s predictions (purple) or not (teal). Results are averages over five random seeds and model families for improved readability.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image and text classification models. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against several baseline methods, including Temperature Scaling (TS), Vector Scaling (VS), Histogram Binning (HB), and others. It also includes results for competing methods IRM and I-Max. Methods are color-coded to indicate whether they affect model prediction accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image classification datasets (CIFAR-10, CIFAR-100, ImageNet, ImageNet-21k) and text classification datasets (Amazon Fine Foods, DynaSent, MNLI, Yahoo Answers). It compares the performance of the proposed Top-versus-All (TvA) approach against existing methods like Temperature Scaling, Vector Scaling, and several binary calibration methods. The table highlights the effectiveness of TvA in reducing ECE and indicates which methods are accuracy-preserving. The best-performing method for each model is highlighted in bold, and color-coding distinguishes methods that may negatively impact accuracy from those that do not.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different image and text classification models and datasets. The ECE values are shown in percentages, with lower values indicating better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against several baseline methods, including Temperature Scaling (TS), Vector Scaling (VS), Histogram Binning (HB), Isotonic Regression (Iso), Beta Calibration (Beta), Bayesian Binning into Quantiles (BBQ), and two competing methods (IRM and I-Max). The best-performing method for each model is highlighted in bold. Methods are colored to indicate whether they directly impact model prediction accuracy (purple) or not (teal). Averages are shown for both model families and individual models. Detailed results for all models can be found in Appendix Tables 5 and 6.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against existing methods (IRM, I-Max) and standard techniques (Temperature Scaling, Vector Scaling, Histogram Binning etc.). It highlights which methods improve calibration without negatively impacting the model’s accuracy, indicating the effectiveness of the TvA approach in improving calibration performance.
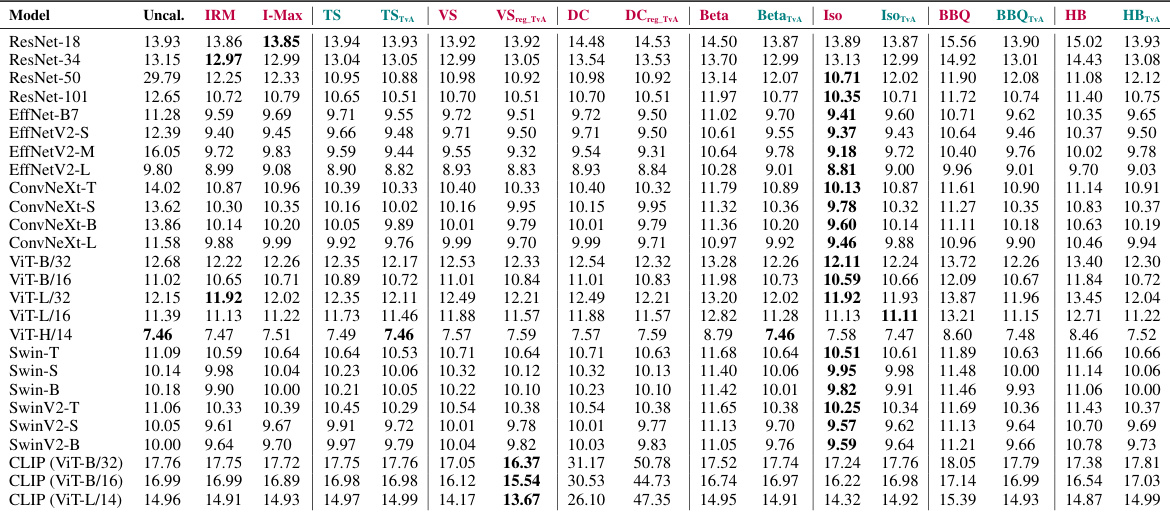
This table presents the Expected Calibration Error (ECE) for various multi-class classification models and calibration methods. The ECE is a measure of how well a model’s predicted confidence scores match the model’s actual accuracy. Lower ECE values indicate better calibration. The table compares the performance of the proposed ‘Top-versus-All’ (TvA) approach against existing state-of-the-art methods (IRM and I-Max), and standard calibration techniques (Temperature Scaling, Vector Scaling, Dirichlet Calibration, Histogram Binning, Isotonic Regression, Beta Calibration, and Bayesian Binning into Quantiles). The impact of the TvA approach on the accuracy of the model is also indicated using color-coding (purple for negative impacts, teal for no significant impacts). Results are averaged across multiple datasets and model families for better generalization.

This table presents the Expected Calibration Error (ECE) for various models and calibration methods. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach against existing methods (IRM, I-Max) and other calibration techniques (Temperature Scaling, Vector Scaling, etc.). The table highlights the improvement achieved by the TvA approach, especially for models with many classes. Methods that potentially affect the model’s accuracy are highlighted.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. The ECE metric measures the calibration quality of a classifier. Lower ECE values indicate better calibration. The table compares the performance of the proposed Top-versus-All (TvA) approach with other existing methods, highlighting the best-performing method for each model. Note that some methods (purple) may affect model prediction accuracy, while others (teal) do not. The results are averages over multiple random seeds and model families for better generalization. More detailed results are available in the Appendix.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. It compares the performance of the proposed Top-versus-All (TvA) approach against standard methods (TS, VS, DC, HB, Iso, BBQ) and competing methods (IRM, I-Max). Lower ECE values indicate better calibration. The table highlights which methods improve accuracy and which ones don’t.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to multiple image and text classification datasets and pre-trained models. The ECE, which quantifies the calibration error, is presented for each model and method, both with and without the Top-versus-All (TvA) reformulation introduced in the paper. The table helps compare the effectiveness of different calibration techniques across various models and datasets, showing which methods yield the best calibration performance. The color-coding highlights methods that either preserve or negatively impact model accuracy.

This table presents the Expected Calibration Error (ECE) for various calibration methods applied to multiple image and text classification datasets. The ECE values represent the calibration performance, with lower numbers indicating better calibration. The table compares several calibration methods, including the proposed Top-versus-All (TvA) approach and two competing state-of-the-art methods (IRM and I-Max). The results are averaged across five different random seeds and model families to provide a robust comparison across models. Methods impacting model prediction accuracy are highlighted in purple and those that preserve accuracy in teal.
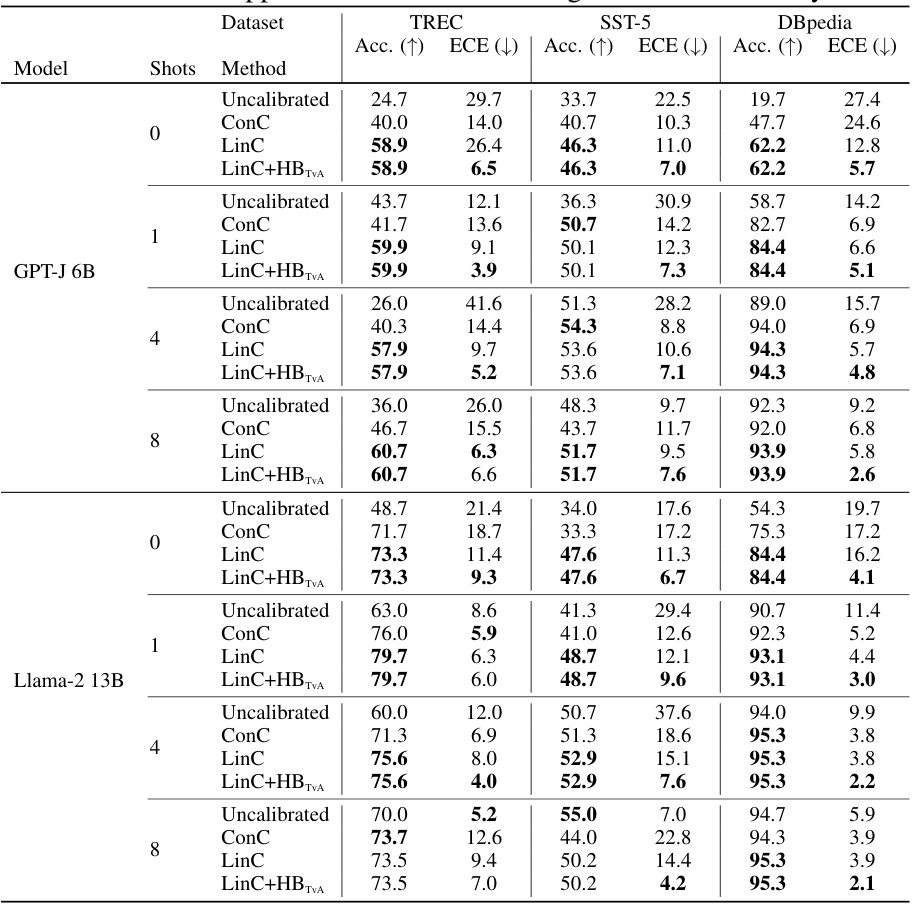
This table presents the Expected Calibration Error (ECE) for various calibration methods applied to different models and datasets. The ECE measures how well the model’s confidence scores reflect the true probability of correctness. Lower ECE values indicate better calibration. The table compares several post-hoc calibration techniques (Temperature Scaling, Vector Scaling, Histogram Binning, etc.) against two competing multiclass methods (IRM and I-Max) and shows the effectiveness of a new Top-versus-All approach in improving existing calibration techniques. Results are averages over multiple runs and model families. Note that some methods can negatively impact the model’s accuracy, which is indicated by color-coding in the table.
Full paper#