↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world control systems suffer from intermittent interactions due to communication problems or task constraints. This makes it difficult for standard reinforcement learning (RL) algorithms, which assume continuous interactions, to learn effective policies. The paper addresses this by introducing the intermittent control Markov decision process (MDP), a new model that explicitly accounts for these intermittent interactions. Existing RL methods struggle in such discontinuous settings, leading to performance degradation or failure.
The proposed solution, Multi-step Action Representation (MARS), tackles this challenge by transforming the problem into a latent space where a sequence of future actions are generated and encoded efficiently. This approach overcomes the limitations of directly generating multiple actions in the original action space, making the RL process more stable and effective. Experimental results on simulated and real-world robotic grasping tasks demonstrate the superiority of MARS in handling intermittent interactions.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the critical yet under-researched problem of intermittent control in reinforcement learning. It offers a novel solution (MARS) that significantly improves the efficiency and performance of RL algorithms in real-world scenarios with unreliable interactions, opening new avenues for applying RL to complex robotics and other domains affected by communication delays or disruptions. The plugin method also increases the flexibility of existing RL algorithms.
Visual Insights#
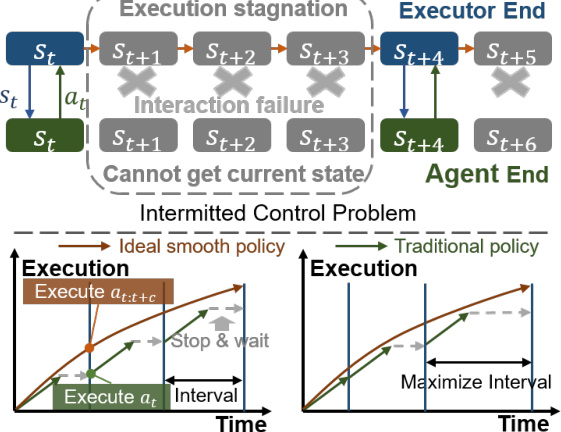
The figure illustrates the intermittent control problem where interactions between the decision maker and the executor are discontinuous due to various interruptions. The top part shows a bidirectional communication blockage, where the agent cannot acquire the state sent by the executor and cannot transmit actions to the executor within a period of time step. The bottom part illustrates two types of intermittent interactions: a fixed interaction interval, and a random interaction interval. The figure also shows that for both cases, smooth and robust control can be achieved by generating a sequence of actions in advance for the next c states based on the current state.

This table presents the performance comparison of four different methods on a real-world robot arm grasping task. The methods include MARS + TD3-BC, Multistep + TD3-BC, Dense obs + TD3-BC, and Vanilla TD3-BC. The performance is evaluated based on three metrics: Motion Smooth Ratio (MSR), Grasp Success Rate (GSR), and Declutter Rate (DR). The results show that MARS + TD3-BC outperforms the other methods in all three metrics.
In-depth insights#
Intermittent Control#
Intermittent control systems present a unique challenge in reinforcement learning due to the unpredictable nature of interactions between the decision-making agent and the environment. The core problem is the absence of continuous feedback, leading to sparse rewards and difficulties in learning an effective policy. Traditional methods often struggle because they assume consistent state observations and action execution. This paper addresses this by introducing an Intermittent Control Markov Decision Process (MDP) framework, explicitly modeling the discontinuous interaction pattern. A crucial contribution is the Multi-step Action Representation (MARS), which cleverly addresses the challenge of representing multiple future actions efficiently, by encoding them into a compact latent space. This approach not only improves the learning efficiency but also enables smoother and more natural motion control in scenarios where instantaneous reactions aren’t always feasible. The experimental results demonstrate the effectiveness of MARS across various simulation and real-world robotic tasks, highlighting its potential for practical applications in areas susceptible to communication interruptions and time-consuming control processes. MARS is presented as a general plugin module, compatible with diverse reinforcement learning algorithms, showcasing its flexibility and broad applicability.
MARS Framework#
The MARS framework, designed to address intermittent control problems in reinforcement learning, presents a novel approach to multi-step action representation. It tackles the challenge of learning effective policies when interactions with the environment are intermittent, encoding sequences of actions into a compact latent space via a conditional Variational Autoencoder (c-VAE). This latent space is structured to simplify the decision-making process, promoting efficient exploration and exploitation. Key to MARS’s success is the incorporation of two modules: a scale-conditioned action encoding that segments the latent space based on action transition magnitude and a dynamic-aware component that uses environmental dynamics prediction to enhance the semantic smoothness of the latent action space. Ultimately, MARS provides a flexible plugin method, compatible with various model-free reinforcement learning algorithms, demonstrably enhancing performance in simulations and real-world robotic tasks.
Empirical Results#
The empirical results section of a research paper is crucial for validating the claims and hypotheses presented earlier. A strong empirical results section will clearly present the data, using appropriate visualizations like graphs and tables. It’s vital to show statistical significance, using methods like t-tests or ANOVA, to demonstrate the reliability of findings and avoid spurious correlations. Benchmarking against existing methods is also essential to establish the novelty and effectiveness of the proposed approach. Furthermore, the discussion should interpret the results in light of previous research, highlighting agreement, disagreement, and potential reasons for such differences. Limitations of the empirical study should be acknowledged, including factors such as sample size, generalizability, or potential biases, to provide a comprehensive and balanced overview. Finally, the results must directly support the paper’s conclusions, demonstrating a clear link between the data and the findings presented in the abstract and introduction.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In this context, it would likely involve evaluating the performance of the proposed MARS framework after disabling key features like the action transition scale and the dynamic state prediction module. By comparing results against the full model and variants with only one module disabled, the study would isolate the impact of each component on factors like learning efficiency and final performance. Positive results would support claims about the importance and effectiveness of these design choices. Negative results, however, would need careful interpretation. It is important to consider what specific performance metrics are utilized in the ablation study. Furthermore, a visualization of the latent action space using techniques like t-SNE may be beneficial, providing insights into how the learned representation changes with the removal of each component and illustrating the degree of structure maintained. The ablation study’s ultimate goal is to demonstrate the synergistic interactions between the components, proving that the MARS model’s efficacy stems from the combination of all parts, rather than individual elements.
Future Work#
Future research directions stemming from this intermittent control framework could explore several promising avenues. Extending MARS to handle even longer sequences of actions would be valuable, perhaps by integrating more advanced sequence modeling techniques like transformers. Another key area is improving the robustness and adaptability of MARS to diverse real-world scenarios, such as those with noisy or unreliable observations. This might involve developing more sophisticated methods for handling uncertainty and incorporating techniques from robust control theory. Furthermore, exploring MARS’s potential in conjunction with other reinforcement learning paradigms, like hierarchical reinforcement learning, could lead to substantial performance improvements in complex, multi-step tasks. Finally, applying this framework to different robotic manipulation tasks and other real-world applications beyond grasping offers exciting possibilities, showcasing its broad applicability and practical impact. Investigating theoretical properties and limitations of MARS within the broader context of reinforcement learning is also crucial, furthering understanding and leading to potential refinements and improvements.
More visual insights#
More on figures
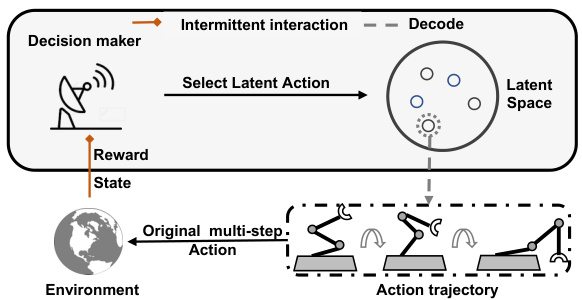
The figure illustrates the MARS framework’s architecture. It begins with a decision maker (agent) receiving intermittent state and reward information from the environment. The decision maker uses this information to select a latent action in a compact latent action space. This latent action is then decoded into a sequence of original multi-step actions, which is then sent to the environment to be executed. The resulting action trajectory represents the agent’s actions within the environment across multiple time steps, despite the intermittent communication.

The figure provides a conceptual overview of the Multi-step Action Representation (MARS) framework. It illustrates the process of how MARS encodes a sequence of actions from the original action space into a compact latent space and how this latent space representation is used in conjunction with a reinforcement learning (RL) policy to generate effective actions for intermittent control tasks. The left side depicts the MARS framework, showing the encoder mapping the original multi-step action and state information into a compact latent representation. The decoder then reconstructs the original multi-step actions from the latent representation. The right side depicts the interaction with the environment, with the RL policy selecting latent actions that are decoded into original actions to be executed in the environment.

This figure compares the performance of four different methods (Frameskip-TD3, MARS-TD3, Multistep-TD3, and Perfect-TD3) on six simulated robotic control tasks across different interaction delays. The x-axis represents the number of environment steps, and the y-axis represents the average episode reward. Each line shows the average reward over eight runs, with shaded regions indicating the standard deviation. The figure demonstrates the superior performance of MARS-TD3 in handling intermittent interactions compared to the other methods. The Perfect-TD3 line serves as a benchmark showing optimal performance in a non-intermittent setting.

This figure shows the four steps involved in a single grasp process within each interaction interval in a robotic arm grasping task. Step 1 initializes the manipulator to a specified position. Step 2 shows the robot moving to a designated location for observation using a camera. Step 3 depicts the robot grasping an object based on the observation. Finally, Step 4 shows the robot moving the grasped object to a designated box.
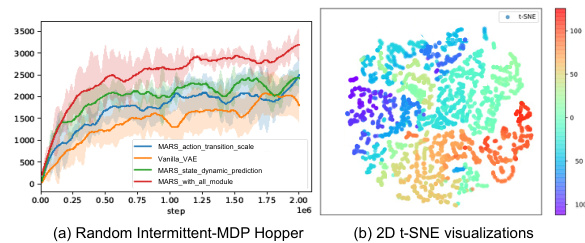
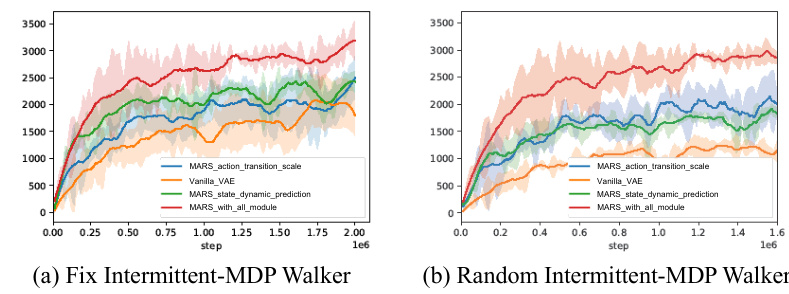
This figure compares the performance of different reinforcement learning methods on simulated remote NPC control tasks with random interaction intervals. Four different Mujoco environments (Hopper, Ant, Walker, HalfCheetah) and two maze environments (Maze-medium, Maze-hard) are used. The x-axis represents the number of environment steps, and the y-axis represents the average episode reward. Each line represents a different method: MARS-TD3, Multistep-TD3, Frameskip-TD3, and Perfect-TD3. MARS-TD3 consistently outperforms the other methods across all environments. The shaded area around each line shows the standard deviation, indicating the variability in performance across multiple runs. The results suggest that MARS-TD3 is more robust and efficient in handling the challenges of intermittent control.

This figure compares the performance of four different methods in simulated remote NPC control tasks with random interaction intervals. The methods compared are Frameskip-TD3, MARS-TD3, Multistep-TD3, and Perfect-TD3. The x-axis represents the number of environment steps, and the y-axis represents the average episode reward. Each line represents the average reward over 8 runs, with shaded areas indicating the standard deviation. The figure shows that MARS-TD3 consistently outperforms the other methods across all four simulated tasks (Hopper, Ant, Walker, and HalfCheetah).

This figure compares the performance of four different methods in six simulated remote NPC control tasks with random interaction intervals. The x-axis represents the number of environment steps, and the y-axis represents the average episode reward. Each line shows the performance of a specific method (Frameskip-TD3, MARS-TD3, Multistep-TD3, and Perfect-TD3). The shaded area around each line indicates the standard deviation over 8 runs. The figure demonstrates MARS-TD3 generally outperforms other methods in these tasks.
This figure compares the performance of four different methods in simulated remote NPC control tasks with random interaction intervals. The x-axis represents the number of environment steps, and the y-axis represents the average episode reward. Four methods are compared: Frameskip-TD3, MARS-TD3, Multistep-TD3, and Perfect-TD3. Each line represents the average reward over 8 runs, and the shaded area represents the standard deviation. The figure shows that MARS-TD3 consistently outperforms the other methods, demonstrating its effectiveness in handling intermittent interactions.

The figure compares the performance of different reinforcement learning methods in simulated remote NPC control tasks with random interaction intervals. The x-axis shows the number of environment steps, and the y-axis shows the average episode reward. Four different Mujoco environments (Hopper, Ant, Walker, HalfCheetah) and two maze environments (Maze-medium, Maze-hard) are evaluated. Each line represents the average reward obtained by a particular method (Frameskip-TD3, MARS-TD3, Multistep-TD3, Perfect-TD3), and the shaded area indicates the standard deviation across eight independent runs. This visualization helps understand how MARS-TD3 performs compared to other baselines in handling tasks with intermittent interactions.
More on tables
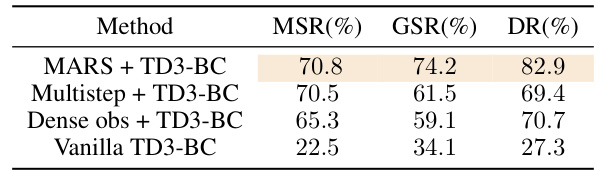
This table presents the performance comparison of four different methods for a robot arm grasping task. The methods are MARS + TD3-BC, Multistep + TD3-BC, Dense obs + TD3-BC, and Vanilla TD3-BC. The table shows the Motion Smooth Ratio (MSR), Grasp Success Rate (GSR), and Declutter Rate (DR) for each method. MARS + TD3-BC shows the best performance across all three metrics.

This table details the network architecture used for different Deep Reinforcement Learning (DRL) methods in the paper. It specifies the layers, dimensions, and activation functions for both the actor and critic networks. The actor network outputs latent actions and a transition scale, while the critic network estimates the Q-value. The table provides a structured overview of the neural network components used in the experiments.

This table details the architecture of the Multi-step Action Representation (MARS) model. It breaks down the network structure into components: Conditional Encoder Network and Conditional Decoder, Prediction Network. Each component is further divided into layers, specifying the type of layer (Fully Connected), activation function (ReLU, None, Tanh), and dimension of the layer’s input or output. The table provides a clear overview of the model’s architecture, showing the flow of information and the transformations performed at each step. The dimensions specified help in understanding the complexity and scale of the model.

This table presents a comparison of the hyperparameters used in different reinforcement learning algorithms across various experiments. It shows the settings for actor learning rate, critic learning rate, representation model learning rate, discount factor, batch size, and buffer size for Frameskip-TD3, Multistep-TD3, MARS-PPO, MARS-TD3, and MARS-DDPG. Notably, the representation model learning rate is ‘None’ for the first two algorithms as they do not utilize a representation model.

This table compares the performance of model-based reinforcement learning (MBRL) and model-free reinforcement learning (MFRL) methods on intermittent control tasks. It shows that MARS-TD3, a model-free approach, outperforms the model-based methods (TD-MPC and Dreamer-v2) across different intermittent task scenarios (fixed and random interruptions in Ant and Hopper environments). The results highlight the limitations of model-based methods in handling the accumulation of errors from the dynamic model prediction in multi-step decision making.

This table shows the results of applying MARS to three popular reinforcement learning algorithms (PPO, DDPG, TD3) on three random interaction interval tasks (Maze hard, Hopper, Walker). The maximum interaction interval used was 8. Each entry in the table shows the MARS algorithm’s score and the difference between its score and the score obtained with a perfect, dense interaction baseline (i.e. no intermittent control problem). An upward-pointing arrow indicates that MARS outperformed the baseline, and a downward-pointing arrow indicates it underperformed. All scores are averages over 5 runs.

This table compares the performance of model-based reinforcement learning (MBRL) and model-free reinforcement learning (MFRL) methods on intermittent control tasks. It shows the average reward achieved by TD-MPC, Dreamer-v2, a multi-step TD3, and MARS-TD3 on Ant and Hopper environments under both fixed and random intermittent interaction settings. The results demonstrate that the model-free approach (MARS-TD3) significantly outperforms the model-based methods.
Full paper#



















