↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for evaluating automatically generated medical reports from X-ray images suffer from several limitations. Existing metrics either focus solely on textual similarity, ignoring clinical aspects or concentrate only on a single clinical aspect (the pathology), neglecting other vital factors, leading to an inaccurate assessment. This often results in a mismatch between automated evaluation and the clinical judgment of radiologists. These limitations hinder the progress in developing robust and reliable AI-powered systems for medical report generation.
This paper proposes VLScore, a novel image-aware evaluation metric. VLScore measures the similarity between radiology reports by considering the corresponding image. The metric is shown to achieve strong alignment with radiologists’ judgments and surpasses traditional methods in accuracy. The paper further introduces a new dataset with targeted perturbations to highlight existing metric weaknesses and provide a clear framework for analysis. The findings demonstrate that VLScore provides a more comprehensive and clinically relevant assessment of generated reports. The enhanced accuracy and insights provided by VLScore will significantly advance the field, enabling more robust evaluation of medical report generation models and ultimately improving AI-powered healthcare.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in medical image analysis and report generation. It addresses the critical need for improved evaluation metrics, offering a novel approach that considers both textual and visual aspects. The proposed VLScore metric and dataset will significantly impact future research, enabling more robust and reliable evaluations of generated reports. This work promotes better alignment between automated methods and clinical judgment, leading to advancements in AI-powered healthcare.
Visual Insights#

This figure showcases a comparison between the proposed VLScore metric and existing metrics (B-4, BERTScore, CheXbert, RadGraph) in evaluating the similarity of generated radiology reports. Two scenarios are presented: (a) Reports with the same findings but different wording, and (b) Reports with very similar wording but a critical difference in location. The figure demonstrates VLScore’s ability to account for image context, leading to more accurate similarity assessments than text-only based metrics.

This table presents the Kendall rank correlation coefficients (τ) between different evaluation metrics and radiologists’ judgments on the ReXVal dataset. It compares the performance of several existing metrics (BLEU, METEOR, ROUGE-L, BERTScore, CheXpert, CheXbert, and RadGraph F1) with the proposed VLScore metric. Higher Kendall τ values indicate stronger agreement with radiologists’ assessments.
In-depth insights#
Visual-Textual Metric#
A visual-textual metric for evaluating generated medical reports offers a significant advancement over traditional methods. By integrating both visual and textual information, it overcomes limitations of existing metrics which focus solely on textual similarity or isolated clinical aspects. This integrated approach is crucial because it directly assesses how well the generated report reflects the content of the corresponding medical image, a key element often overlooked. The metric’s strength lies in its ability to capture nuanced similarities and differences, penalizing significant errors (e.g., missing diagnoses) while remaining robust to less critical variations. This enhanced sensitivity provides a more accurate and reliable evaluation, better aligning with human expert judgments. The development of a dataset featuring controlled perturbations further validates the metric’s effectiveness and highlights its advantages in uncovering subtle yet important errors in generated reports. Ultimately, a visual-textual metric offers a more comprehensive and clinically relevant evaluation framework, improving the quality and reliability of automatic medical report generation.
Report Generation#
The research paper section on report generation would likely delve into the methods for automatically creating medical reports from medical images, such as X-rays. It would probably cover different approaches to multimodal learning, integrating visual and textual information. A key aspect would be the evaluation metrics used to assess the quality of the generated reports, likely including metrics that consider both language coherence and clinical accuracy. Challenges in report generation, like handling variations in medical terminology and report structure, would be addressed. There would also likely be a discussion of datasets used for training and evaluation. A strong focus on model architectures, possibly including deep learning models like transformers or convolutional neural networks, would be expected. Finally, the paper would likely discuss the potential benefits and limitations of automatic report generation, focusing on improvements in efficiency and potential risks associated with automation in a clinical setting.
Dataset Perturbations#
The effectiveness of automatic medical report generation models hinges on robust evaluation metrics. A key aspect of creating such metrics is understanding how models behave under various conditions. Dataset perturbations, therefore, are crucial. By deliberately introducing controlled modifications to existing datasets, researchers can systematically probe the strengths and weaknesses of different metrics. These perturbations might involve removing key sentences describing pathologies, altering words signifying location or severity of findings, or even replacing clinically relevant phrases with non-informative words. Analyzing metric performance across these perturbed datasets reveals crucial insights into their sensitivity to clinically significant versus insignificant changes. A well-designed perturbation strategy can highlight whether a metric prioritizes surface-level textual similarity or captures the deeper clinical meaning of a report, thereby guiding the development of more robust and reliable evaluation approaches. This approach significantly enhances the validation process by creating a comprehensive framework to assess the practical applicability of automatic report generation models in real-world scenarios.
Ablation Experiments#
Ablation experiments systematically remove components of a model to assess their individual contributions. In the context of a medical report generation model, this might involve removing specific modules (e.g., visual feature extraction, attention mechanisms, language model components). By observing the impact of each removal on the overall performance (measured, for example, by BLEU score or a clinical accuracy metric), researchers can gain insights into the relative importance of different model parts. For instance, if removing the visual feature extraction leads to a drastic drop in performance, it highlights the model’s strong reliance on image data for report generation. Conversely, a minor performance change after removing a specific module might indicate redundancy or less crucial role in the generation process. Well-designed ablation studies are crucial for understanding the internal workings of complex models, providing valuable information for model improvement and interpretation. They also help determine whether the model’s success stems from a synergistic interaction of components, or if individual modules dominate the output. A comprehensive ablation study should vary the removal techniques and examine a range of performance metrics to offer a reliable analysis. This provides a deeper understanding of the model’s functioning, which can’t be solely achieved by examining the overall performance alone.
Clinical Significance#
Clinical significance in medical research assesses the relevance and impact of findings on patient care and health outcomes. It moves beyond statistical significance, focusing on whether results can translate into real-world improvements. A clinically significant study demonstrates that an intervention, treatment, or diagnostic tool has a noticeable and meaningful effect on patient health, such as improved survival rates, reduced symptom severity, or enhanced quality of life. Factors such as the magnitude of the effect, its duration, and its impact on patients’ daily functioning all contribute to clinical significance. Establishing clinical significance often requires larger sample sizes and longer follow-up periods than are needed for statistical significance alone. In the context of a medical report generation model, clinical significance would be measured by assessing the impact of improved report quality on diagnostic accuracy, treatment decisions, and patient outcomes. For example, a model that reliably identifies subtle but crucial findings missed by human reviewers would demonstrate significant clinical impact. Therefore, while technical benchmarks such as BLEU or ROUGE scores might assess report generation quality, only a thorough evaluation of downstream effects on patient care could prove the true clinical significance of such a model. This requires rigorous clinical validation and integration with real-world clinical workflows.
More visual insights#
More on tables

This table presents the results of an experiment on a perturbed dataset designed to evaluate the sensitivity of different metrics to the removal of either significant (pathology-related) or insignificant sentences from medical reports. The results show that NLG metrics are not sensitive to this type of perturbation, while CE metrics and the proposed VLScore metric show higher sensitivity, with VLScore demonstrating the highest sensitivity to the removal of pathology-related sentences.
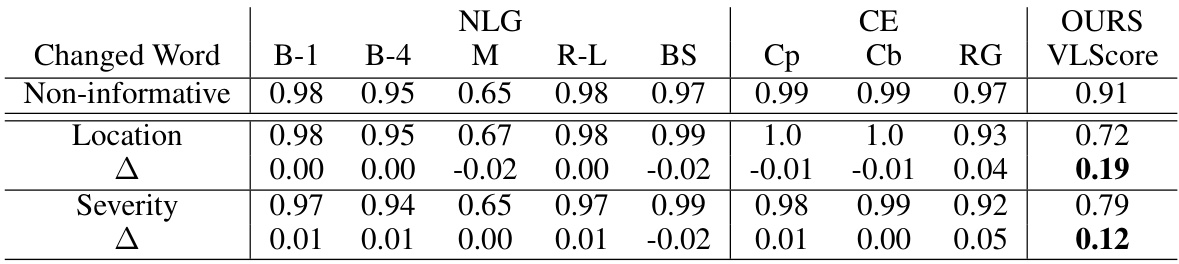
This table presents the results of an ablation study on a perturbed dataset, focusing on the impact of modifying different types of words (descriptive vs. non-informative) in medical reports. It compares several metrics’ sensitivity to these changes. The results demonstrate that the proposed VLScore metric is more sensitive to clinically significant changes, while others show less sensitivity and give high scores even when crucial clinical information is altered.

This table presents the results of an ablation study comparing different similarity measurement methods for evaluating the quality of generated medical reports. The methods compared are cosine similarity, minimal bounding sphere, image-centered cosine similarity, and the proposed triangle area method. The evaluation metric used is Kendall’s τ, which measures the correlation between the similarity rankings produced by each method and the rankings provided by radiologists. The results show that the proposed triangle area method achieves the highest correlation with radiologists’ judgments.

This table presents the results of an ablation study comparing different vision-language embedding models used to create the shared space for the proposed VLScore metric. The models are evaluated based on their Kendall’s Tau correlation with radiologist judgments on the ReXVal dataset. The table shows that LIMITR achieves the highest correlation, suggesting it’s the most effective model for this specific application.
Full paper#