TL;DR#
Makeup transfer, applying diverse makeup styles to facial images, faces challenges due to a lack of paired training data and variations in makeup style effects. Existing methods often synthesize suboptimal pseudo ground truths which leads to low fidelity. This paper aims to overcome these issues.
To address these challenges, the researchers propose a novel self-supervised hierarchical makeup transfer (SHMT) method using latent diffusion models. SHMT decomposes texture details hierarchically and reconstructs the image, eliminating the need for pseudo-paired data and allowing for flexible control over content preservation based on makeup style complexity. An Iterative Dual Alignment (IDA) module further refines alignment during the denoising process. This approach proves highly effective in achieving superior makeup fidelity and transfer realism.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel self-supervised approach to makeup transfer, addressing the limitations of existing methods that rely on imprecise pseudo-paired data. Its hierarchical texture decomposition and iterative dual alignment module significantly improve makeup fidelity and adaptability to diverse styles. The use of latent diffusion models offers a computationally efficient and high-quality solution, opening up new avenues for research in unsupervised image-to-image translation and related applications.
Visual Insights#

🔼 This figure highlights two key challenges in makeup transfer. The left panel (a) shows how existing methods using histogram matching or geometric distortion create suboptimal pseudo-paired training data, leading to inaccuracies. The right panel (b) demonstrates the ambiguity in handling source content details (like freckles or eyelashes) – these details should be preserved in simple makeup but discarded in complex makeup styles. The figure visually contrasts the results of previous methods with the proposed SHMT method, showcasing its superior ability to handle both challenges.
read the caption
Figure 1: Illustration of two main difficulties in the makeup transfer task. (a) Due to the absence of paired data, previous methods utilize histogram matching or geometric distortion to synthesize sub-optimal pseudo-paired data, which inevitably misguide the model training. (b) Some source content details should be preserved in simple makeup styles but be removed in complex ones.
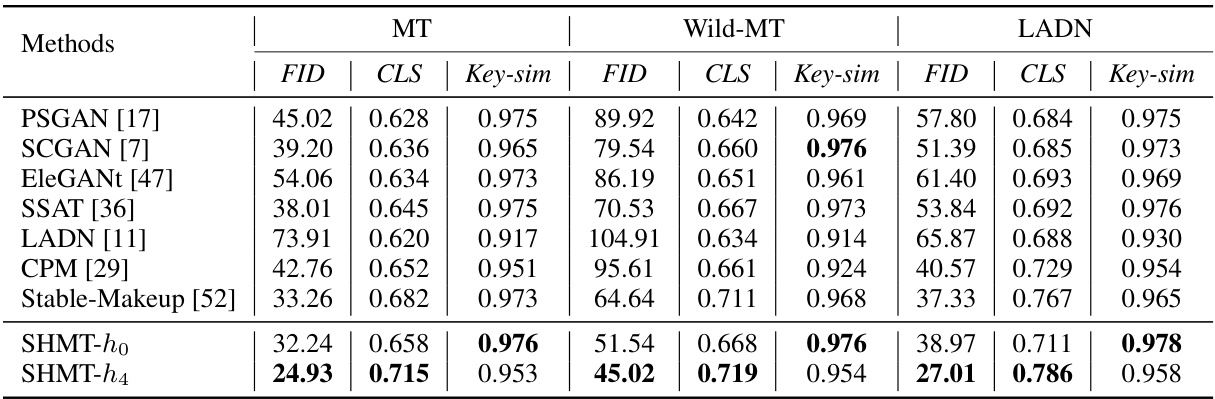
🔼 This table presents a quantitative comparison of different makeup transfer methods across three datasets: MT, Wild-MT, and LADN. The metrics used are FID (Frechet Inception Distance), CLS (cosine similarity of CLS tokens), and Key-sim (cosine similarity of keys). Lower FID scores indicate better image realism, while higher CLS and Key-sim scores suggest better makeup fidelity and content preservation respectively. The results demonstrate the performance of various GAN-based methods and the proposed SHMT method under different conditions.
read the caption
Table 1: Quantitative results of FID, CLS and Key-sim on the MT, Wild-MT and LADN datasets.
In-depth insights#
Self-Supervised Xfer#
Self-supervised transfer learning methods represent a significant advancement in various machine learning domains. By eliminating the need for large, meticulously labeled datasets, these methods leverage the inherent structure and redundancies within unlabeled data to train models effectively. This approach offers several advantages, including reduced annotation costs and the ability to address tasks where labeled data is scarce or expensive. However, effective self-supervised training relies heavily on carefully designed pretext tasks that encourage the model to learn meaningful representations. The success of these methods hinges on the ability to create informative pretext tasks that are both challenging enough to promote learning yet simple enough to avoid overfitting or model collapse. Future research directions might explore more sophisticated pretext tasks, enhanced model architectures designed for self-supervised learning, and improved evaluation metrics to accurately assess the performance of these models across a wider range of tasks and datasets.
Hierarchical Makeup#
The concept of “Hierarchical Makeup” in the context of makeup transfer suggests a multi-resolution approach to applying makeup. Instead of treating makeup as a monolithic entity, it is broken down into distinct levels of detail. This hierarchical representation could involve a Laplacian pyramid, decomposing makeup into high-frequency (fine details like eyeliner) and low-frequency (coarse features like blush) components. This allows for more flexible control over the makeup transfer process. For instance, the model could selectively transfer only the coarse features for a natural look or include all levels for a more dramatic transformation. The advantage is that it would handle the diversity of makeup styles more effectively than methods that apply makeup uniformly. This strategy potentially avoids issues with detail loss or artifacts in transferring intricate styles.
Latent Diffusion#
Latent diffusion models represent a significant advancement in generative modeling. They cleverly operate in a latent space, a compressed representation of the data, reducing computational costs and improving efficiency compared to working directly with high-dimensional image data. This approach allows for the generation of high-resolution images with remarkable detail. By strategically incorporating noise and then reversing the process via a diffusion model, these models can capture intricate details and produce realistic results. Self-supervised learning further enhances their power, eliminating the need for large paired datasets, typically a significant limitation in other generative models. This makes latent diffusion models particularly attractive for applications like makeup transfer, where paired data is scarce, enabling the generation of realistic and diverse makeup styles while preserving the original facial features.
Iterative Alignment#
Iterative alignment, in the context of makeup transfer or similar image manipulation tasks, presents a powerful approach to address the challenge of aligning different image representations. The core idea is to refine the alignment between a content representation (e.g., a face image without makeup) and a style representation (e.g., a makeup style) iteratively. This is typically achieved using a feedback loop where an initial alignment is generated, evaluated, and then refined. The iterative process helps to gradually correct discrepancies, especially those arising from domain differences between the content and style. This is particularly useful when dealing with high-frequency details or complex transformations, where a single-step alignment is likely to be insufficient. The success of this method hinges on the choice of alignment metric, the refinement strategy, and the overall framework that incorporates the iterations effectively. By dynamically adjusting parameters in each iteration, iterative alignment techniques enable high-fidelity results and robustness to variations in input. This approach could be extended to other image-to-image translation tasks where precise content-style alignment is crucial, potentially achieving superior performance compared to methods using only a single alignment step.
Makeup Style Control#
The heading ‘Makeup Style Control’ suggests a system capable of manipulating the makeup’s appearance in a targeted manner. This implies functionalities beyond simple application or removal, potentially offering precise control over various attributes. Such a system could allow users to adjust the intensity of makeup, blend different styles, modify specific features, or even create entirely new styles by combining existing ones. The level of control could range from global adjustments, affecting the overall makeup intensity across the face, to highly localized modifications, focusing on individual facial features. Real-time manipulation would be an advanced feature, providing immediate feedback and allowing for iterative refinements. The core challenge would lie in developing robust algorithms that understand and accurately represent the complex interplay of various makeup components and their effect on facial features.
More visual insights#
More on figures

🔼 This figure demonstrates the flexibility of the proposed SHMT method in handling different makeup styles. It shows that the method can either preserve or discard source content details (like freckles or eyelashes) depending on the complexity of the makeup style in the reference image. Simple makeup styles retain the original details, while complex styles allow for their removal or modification. This adaptability is a key advantage over previous methods which typically struggle to handle the diversity of makeup styles and their varied effects on the face.
read the caption
Figure 2: In addition to color matching, our approach allows flexible control to preserve or discard texture details for various makeup styles, without changing the facial shape.

🔼 This figure illustrates the framework of the Self-supervised Hierarchical Makeup Transfer (SHMT) method. It shows how a facial image is decomposed into three components: background, makeup, and content. The makeup transfer process is simulated by reconstructing the original image from these components. Hierarchical texture details are used to handle different makeup styles, and an Iterative Dual Alignment (IDA) module dynamically adjusts the injection condition during the denoising process to correct alignment errors.
read the caption
Figure 3: The framework of SHMT. A facial image I is decomposed into background area Ibg, makeup representation Im, and content representation (I3d, hi). The makeup transfer procedure is simulated by reconstructing the original image from these components. Hierarchical texture details hi are constructed to respond to different makeup styles. In each denoising step t, IDA draws on the noisy intermediate result Ît to dynamically adjust the injection condition to correct alignment errors.

🔼 This figure presents a qualitative comparison of the proposed SHMT model against several GAN-based baselines on simple makeup transfer tasks. Each row shows the source image, reference image with makeup, and the results generated by each method (PSGAN, SCGAN, EleGANt, SSAT, LADN, CPM, and SHMT-ho). The comparison highlights the superior performance of SHMT in maintaining high fidelity makeup transfer while preserving source image details, especially when compared to the GAN-based alternatives which often introduce artifacts or fail to accurately reproduce the makeup style.
read the caption
Figure 4: Qualitative comparison with GAN-based baselines on simple makeup styles.

🔼 This figure presents a qualitative comparison of the proposed SHMT model against several GAN-based baselines on simple makeup styles. It shows the source image, the reference image with makeup, and the results generated by each method. This allows for a visual comparison of the realism, fidelity, and content preservation capabilities of each approach on simpler makeup applications.
read the caption
Figure 4: Qualitative comparison with GAN-based baselines on simple makeup styles.

🔼 This figure presents a qualitative comparison of the proposed SHMT model and the Stable-Makeup method on simple makeup styles. It shows the source images, reference images with simple makeup, results from the Stable-Makeup method, and results from the SHMT-ho model. The comparison highlights the improvements in makeup fidelity and preservation of source image content details achieved by the SHMT method. Specifically, SHMT-ho shows better results in terms of realistic makeup appearance and preservation of source image features.
read the caption
Figure 6: Qualitative comparison with the Stable-Makeup baseline on simple makeup styles.

🔼 This figure shows a qualitative comparison of the proposed SHMT method and the Stable-Makeup baseline on complex makeup styles. It visually demonstrates the ability of each method to transfer complex makeup styles from a reference image to a source image. The results show that SHMT-h4 achieves a higher level of fidelity in transferring the details of the complex makeup. The Stable-Makeup method, while generating realistic images, demonstrates some difficulty in accurately rendering the finer details of the more complex makeup styles.
read the caption
Figure 7: Qualitative comparison with the Stable-Makeup baseline on complex makeup styles.
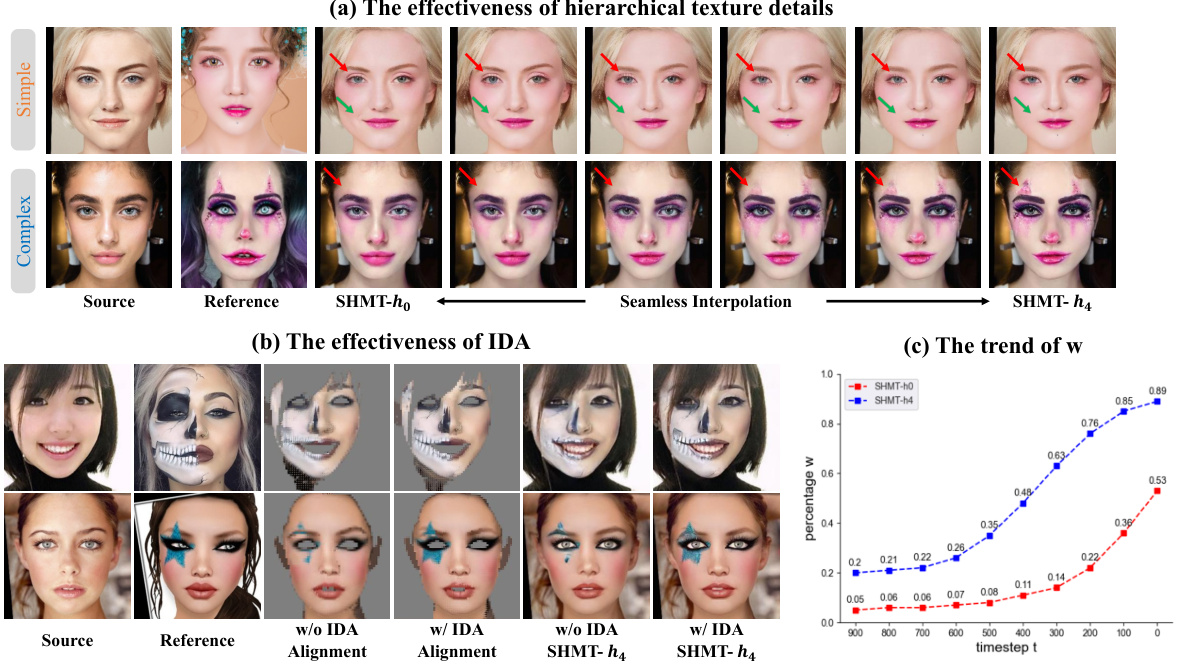
🔼 This figure presents ablation studies to demonstrate the effectiveness of the proposed modules in the SHMT model. Subfigure (a) shows the impact of using different hierarchical texture details (ho to h4) on makeup transfer results for both simple and complex makeup styles. It illustrates how the model transitions from preserving source image details (ho) to primarily transferring reference makeup details (h4). Seamless interpolation between these extremes is also demonstrated. Subfigure (b) compares results with and without the Iterative Dual Alignment (IDA) module, highlighting its role in correcting alignment errors between content and makeup representations. Subfigure (c) plots the trend of the weight (w) assigned to each alignment prediction (zm and zm) over different timesteps (t) in the IDA module, for both ho and h4 texture details. This illustrates how the model dynamically adjusts the weighting during the denoising process to achieve better alignment.
read the caption
Figure 8: Ablation studies of each proposed module to validate its effectiveness. Zoomed-in view for a better comparison.

🔼 This figure demonstrates the robustness and generalization capabilities of the SHMT-h0 model. The left side (a) shows results on faces with varying age, gender, poses, and expressions, showcasing the model’s ability to handle diverse input variations. The right side (b) showcases generalization to different artistic styles. SHMT-h0 successfully transfers makeup styles to these diverse input images, highlighting the model’s adaptability and robustness.
read the caption
Figure 9: The robustness and generalization ability of the model SHMT-ho in various scenarios.

🔼 This figure shows qualitative results of the SHMT model using different levels of texture detail in the Laplacian pyramid decomposition. It demonstrates how the model’s ability to transfer high-frequency details from the reference image changes as the resolution of the texture details decreases. With finer details (SHMT-h0), the model preserves more source image texture. As the texture detail becomes coarser (SHMT-h4), the model transfers more high-frequency details from the reference image, resulting in a more faithful recreation of complex makeup styles. This illustrates the model’s flexible control over detail preservation.
read the caption
Figure 10: Qualitative results of models equipped with different texture details under complex makeup styles. As the texture goes from fine to coarse, the model gradually tends to transfer high-frequency texture details from the reference images.

🔼 This figure compares the makeup transfer results of the proposed method SHMT against those of InstantStyle, another style transfer method. The results demonstrate SHMT’s superior ability to accurately transfer makeup while preserving the source image’s content. InstantStyle, in contrast, exhibits a more generalized style transfer, altering the source content more significantly and failing to accurately reproduce the reference image’s makeup style.
read the caption
Figure 11: Qualitative comparison of our method SHMT with the style transfer method InstantStyle.

🔼 This figure shows the results of global makeup style interpolation using two different reference images. The first row displays the results when only one reference image is used, while the second row shows a series of results obtained by linearly interpolating between the two reference images, showcasing the gradual transition in makeup styles.
read the caption
Figure 12: The illustration of global makeup interpolation. The first row is the result of a single reference image, the second row is the result of two reference images.

🔼 This figure shows the results of local makeup interpolation. The first row demonstrates the control of lipstick makeup style, while the second row shows the control of eye shadow makeup style. The interpolation gradually changes from the style of the first reference image to the second reference image. This demonstrates the ability of the SHMT method to perform local makeup transfer and style interpolation.
read the caption
Figure 13: The illustration of local makeup interpolation. The first row is lipstick control, the second row is eye shadow control.

🔼 This figure demonstrates the ability of the SHMT model to either preserve or change the skin tone during makeup transfer. The top row shows a seamless interpolation between preserving the original skin tone and changing it to match the reference image. The bottom row shows the results where the original skin tone is preserved.
read the caption
Figure 14: By default, our method transfers makeup to change the skin tone. Optionally, the local makeup transfer operation can preserve the original skin tone, and the local makeup interpolation can smoothly generate intermediate results.

🔼 This figure presents a qualitative comparison of makeup transfer results from various GAN-based methods on simple makeup styles. It visually shows the source image, the reference makeup image, and the results produced by PSGAN, SCGAN, EleGANt, SSAT, LADN, CPM, and the proposed SHMT method. The purpose is to illustrate the differences in realism, makeup fidelity, and content preservation between different methods. By comparing the results, one can assess the strengths and weaknesses of each approach in handling simple makeup styles.
read the caption
Figure 4: Qualitative comparison with GAN-based baselines on simple makeup styles.

🔼 This figure shows a qualitative comparison of various makeup transfer methods on complex makeup styles. It visually demonstrates the performance of different approaches, highlighting their ability to transfer makeup accurately and realistically while preserving the source image’s content. The results illustrate the strengths and weaknesses of each method in handling intricate makeup details and variations in style.
read the caption
Figure 16: More qualitative results of different methods in complex makeup styles.

🔼 This figure shows the limitations of the SHMT method caused by inaccurate face parsing. The face parsing model sometimes misidentifies high-frequency makeup details (especially around the forehead) as hair and assigns them to the background. This leads to performance degradation in the makeup transfer results, as seen in the comparison between the reference images and the SHMT-h4 outputs.
read the caption
Figure 17: Limitations of our approach. The face parsing model often marks high-frequency makeup styles in the forehead area as hair and segments them into the background area, resulting in performance degradation.
More on tables

🔼 This table presents a quantitative comparison of the proposed SHMT model against other state-of-the-art makeup transfer methods across three different datasets: MT, Wild-MT, and LADN. The comparison is based on three evaluation metrics: Fréchet Inception Distance (FID), which measures the realism of the generated images; CLS (class token), which measures makeup fidelity; and Key-sim (key similarity), which measures content preservation of the source image. Lower FID values indicate higher realism, while higher CLS and Key-sim values represent better fidelity and content preservation, respectively.
read the caption
Table 1: Quantitative results of FID, CLS and Key-sim on the MT, Wild-MT and LADN datasets.

🔼 This table presents the quantitative results obtained from evaluating several versions of the SHMT model on the LADN dataset. Each model version uses a different level of hierarchical texture detail (from ho to h4), representing varying degrees of high-frequency information. The results are shown for three metrics: FID (Fréchet Inception Distance), CLS (cosine similarity of CLS token), and Key-sim (cosine similarity of Key-sim). The table demonstrates a trade-off between preserving source image content (Key-sim) and achieving high makeup fidelity (CLS, FID), with finer details (ho) leading to better content preservation and coarser details (h4) resulting in superior makeup quality.
read the caption
Table 4: The quantitative results of our models equipped with different texture details on the LADN dataset.
Full paper#



















