TL;DR#
Current open-vocabulary 3D object detection models heavily rely on expensive LiDAR data, hindering scalability and cost-effectiveness. This paper tackles this limitation by introducing OVM3D-Det, a novel framework that trains detectors using only RGB images. The existing methods are limited by the high cost and imprecise boxes estimated from noisy point clouds. This approach challenges the reliance on LiDAR data, making 3D object detection more accessible and efficient.
OVM3D-Det addresses the challenges by introducing two key innovations: adaptive pseudo-LiDAR erosion to filter artifacts from noisy data and bounding box refinement using large language model priors. These techniques significantly improve the precision of pseudo-LiDAR generated labels. Experiments show that OVM3D-Det surpasses existing baselines by a significant margin, showcasing the power of RGB-only training for open-vocabulary 3D object detection. This opens up possibilities for training 3D detectors using the wealth of readily available RGB images.
Key Takeaways#
Why does it matter?#
This paper is important because it presents OVM3D-Det, a novel framework for open-vocabulary monocular 3D object detection that significantly outperforms existing methods by using only RGB images for training. This approach addresses the high cost and scalability issues of existing point cloud-based methods, opening new avenues for research and applications in autonomous driving and robotics. The introduction of adaptive pseudo-LiDAR erosion and bounding box refinement techniques are particularly valuable contributions.
Visual Insights#
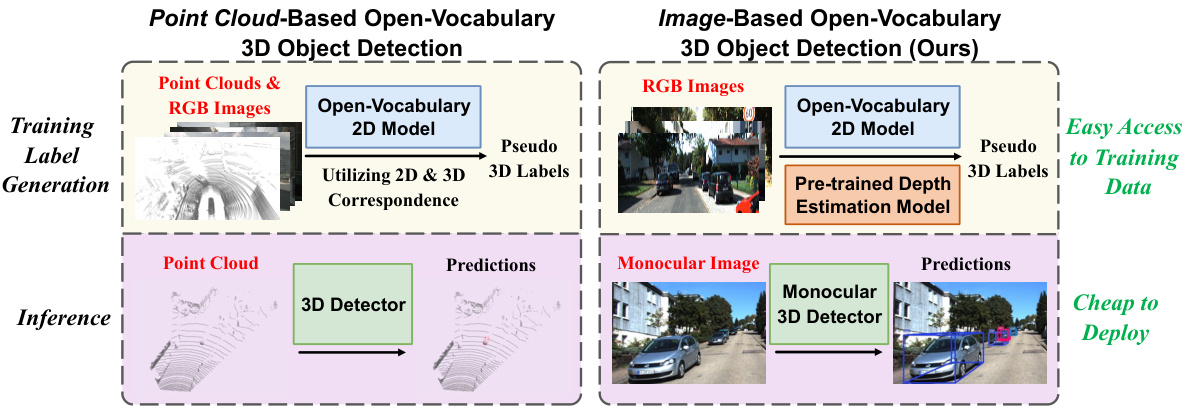
🔼 This figure compares point cloud-based and image-based open-vocabulary 3D object detection methods. The main difference lies in the data used for training and inference. Point cloud-based methods require both point cloud and image data, making them expensive to deploy due to the need for LiDAR. In contrast, the proposed image-based method uses only RGB images, making it more cost-effective and scalable. The figure clearly illustrates the differences in training and inference stages for both approaches.
read the caption
Figure 1: Comparison between point cloud-based and image-based open-vocabulary 3D object detection methods. During training, point cloud-based approaches require corresponding point cloud and image data to derive pseudo labels, while image-based methods can leverage large-scale image data and the most advanced depth estimation models for pseudo-label generation. During inference, point cloud-based methods necessitate expensive LiDAR or other 3D sensors for deployment, whereas image-based approaches only require a camera.
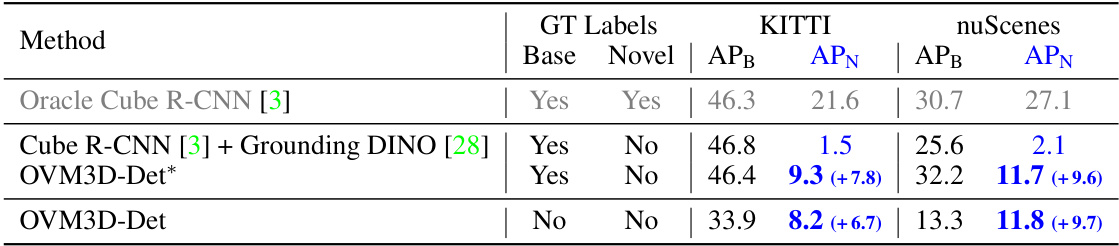
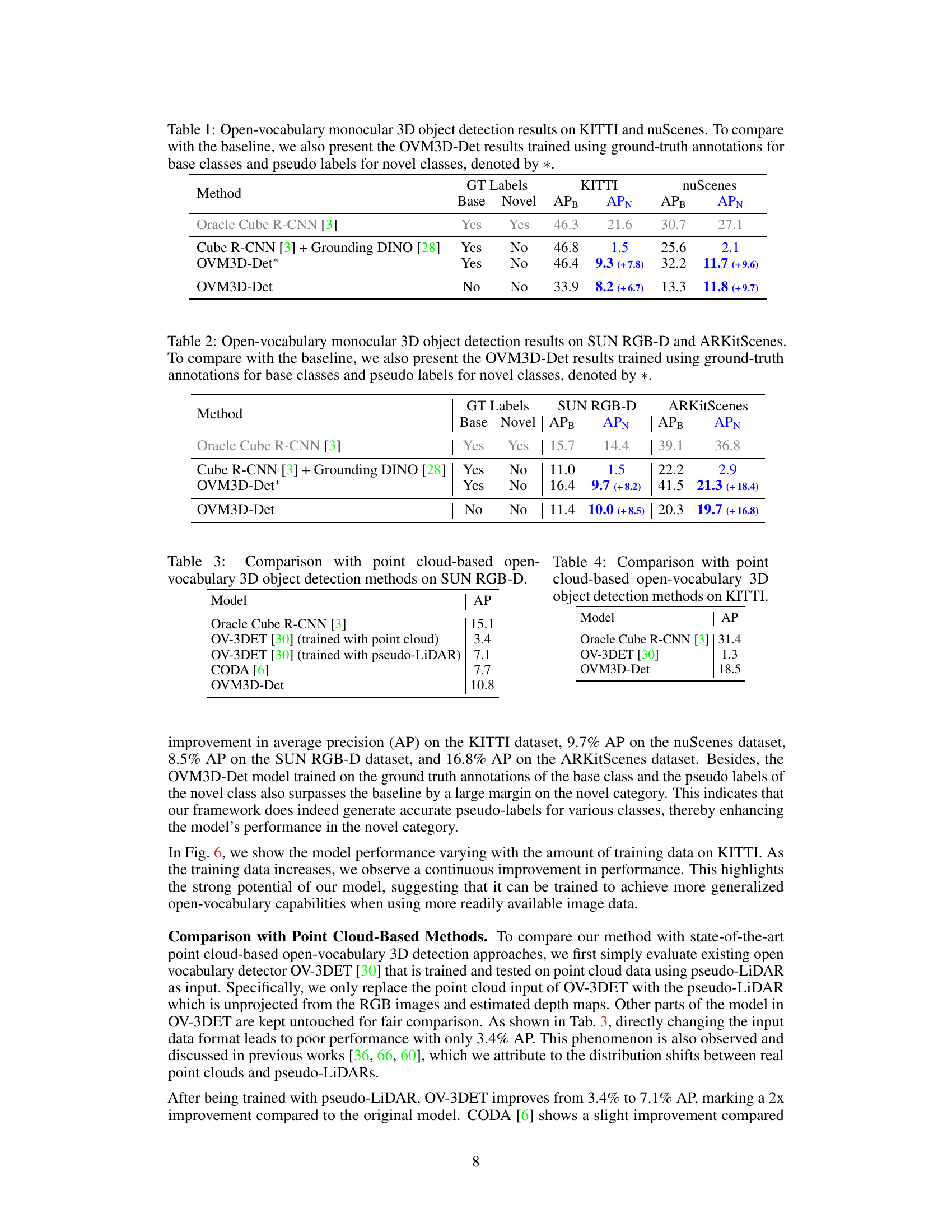
🔼 This table presents a comparison of open-vocabulary monocular 3D object detection results on the KITTI and nuScenes datasets. It shows the performance of different methods, including an oracle model trained with full ground truth labels, a model using Grounding DINO for novel class prediction, and the proposed OVM3D-Det model with and without ground truth labels for base classes. The APB and APN columns represent the average precision for base classes and novel classes, respectively. The numbers in parentheses indicate the improvement in APN achieved by OVM3D-Det compared to the baselines.
read the caption
Table 1: Open-vocabulary monocular 3D object detection results on KITTI and nuScenes. To compare with the baseline, we also present the OVM3D-Det results trained using ground-truth annotations for base classes and pseudo labels for novel classes, denoted by *.
In-depth insights#
Open-Vocab 3D#
The concept of “Open-Vocab 3D” signifies a significant advancement in 3D object detection, moving beyond the limitations of traditional methods. Existing approaches often rely on predefined object categories, restricting their applicability to novel or unseen objects. Open-Vocab 3D aims to address this by enabling models to detect and classify objects without prior knowledge of their specific class. This requires the model to generalize to new categories based on features and relationships rather than relying on labeled training data for each object. The challenge lies in developing robust feature representations that allow for generalized object recognition. This could involve incorporating semantic information, leveraging large-scale datasets with diverse objects, or combining various data modalities. While promising, challenges persist around accurate bounding box generation, handling occlusions and varying object scales. Success depends on developing more effective methods for pseudo-labeling, adaptive learning, and leveraging large language models to improve robustness and generalizability. Ultimately, Open-Vocab 3D has the potential to revolutionize various applications, such as autonomous driving and robotics, by enabling systems to dynamically adapt and recognize objects without extensive retraining.
RGB-Only Training#
The concept of “RGB-Only Training” in the context of 3D object detection represents a significant advancement by enabling the training of accurate 3D detectors using only RGB images, eliminating the need for expensive and often unavailable 3D data like LiDAR point clouds. This approach is particularly impactful given the abundance of RGB image data compared to 3D datasets. A key challenge is the inherent ambiguity of depth information in 2D images. This necessitates the use of innovative techniques such as pseudo-LiDAR generation and refinement methods to create high-quality pseudo 3D labels from RGB data. The success of RGB-only training hinges on these methods’ ability to accurately estimate object depth and dimensions, overcoming noise and occlusion issues. The use of large language models for refining bounding boxes based on prior knowledge further improves the accuracy and robustness of this technique. Overall, RGB-only training offers a cost-effective and scalable solution for 3D object detection, paving the way for broader applications and accessibility, especially in open-vocabulary scenarios.
Pseudo-LiDAR#
The concept of Pseudo-LiDAR is a crucial innovation in monocular 3D object detection, offering a cost-effective alternative to the use of expensive LiDAR sensors. By leveraging readily available RGB images and depth estimation models, Pseudo-LiDAR generates a point cloud representation of the scene. This approach significantly reduces reliance on expensive hardware, thereby enhancing scalability and democratizing access to 3D object detection research. However, noise and inaccuracies inherent in depth estimation can significantly affect the quality of the Pseudo-LiDAR point cloud. The resulting imprecision in the generated point cloud can impact downstream tasks like 3D bounding box generation and object recognition. Addressing this challenge necessitates techniques like adaptive erosion to remove noise and artifact points, and sophisticated methods to improve the accuracy of 3D bounding boxes. The success of Pseudo-LiDAR hinges on the accuracy of the depth estimation model, highlighting the need for further research into robust and accurate depth estimation techniques for improved 3D object detection performance.
LLM-Enhanced Boxes#
The concept of “LLM-Enhanced Boxes” in the context of 3D object detection from monocular images presents a novel approach to refining the accuracy of automatically generated 3D bounding boxes. The core idea is leveraging the knowledge embedded within large language models (LLMs) to improve the precision and reliability of these boxes, which are often prone to errors due to noisy pseudo-LiDAR data. This enhancement is crucial because inaccurate bounding boxes can significantly impact the performance of the 3D object detection model. The LLM acts as a source of prior knowledge about object dimensions and shapes, providing contextual information not readily available in the visual data. By querying the LLM with object class information, the system obtains realistic size ranges, which are then used to assess and refine the automatically generated bounding boxes. This process effectively addresses issues like underestimation or overestimation of box dimensions, thereby improving the overall quality of the training data and, ultimately, improving the detection accuracy. A key advantage is the ability to handle partially occluded or poorly defined objects, where the LLM’s understanding can compensate for missing visual information. The integration of LLMs thus offers a powerful method for improving the accuracy and robustness of 3D object detection from monocular images, particularly in open-vocabulary settings where the system needs to detect objects it has never seen before.
Future Directions#
Future research could explore several avenues to enhance the capabilities of open-vocabulary monocular 3D object detection. Improving depth estimation remains crucial, as inaccuracies directly impact the quality of pseudo-LiDAR data and subsequent 3D bounding box generation. Investigating more robust depth estimation techniques, potentially incorporating multi-modal cues or leveraging advanced techniques like neural radiance fields, is warranted. Additionally, enhancing the pseudo-LiDAR generation process is key. Methods to reduce noise and handle occlusions more effectively, such as incorporating geometric constraints or employing more sophisticated filtering methods, deserve attention. Developing more effective methods for open-vocabulary 3D bounding box refinement using LLMs is also important. This might involve exploring alternative prompting strategies, integrating knowledge bases, or utilizing advanced methods from computer vision to better reason about object size and shape. Finally, extending the framework to handle dynamic scenes is essential for real-world applications. This would require incorporating temporal information and addressing challenges of object motion and tracking.
More visual insights#
More on figures

🔼 This figure compares LiDAR data with pseudo-LiDAR data generated from a single RGB image and a depth estimation model. It highlights the density advantage of pseudo-LiDAR but emphasizes its significant noise compared to the ground truth LiDAR data. The red boxes show regions with the most prominent noise artifacts in the pseudo-LiDAR data, demonstrating its unsuitability for direct 3D bounding box generation. This illustrates a key challenge addressed by the paper’s proposed method.
read the caption
Figure 2: Comparison between LiDAR data and pseudo-LiDAR. Although pseudo-LiDAR is much denser than LiDAR, it is highly noisy (as highlighted in the red boxes), making it inadequate for directly generating accurate 3D bounding boxes.

🔼 This figure shows the overall framework of the OVM3D-Det model, which is a novel open-vocabulary monocular 3D object detection framework. The framework consists of five main steps: 1. Pseudo-LiDAR Generation: generating pseudo-LiDAR point clouds from RGB images using a depth estimation model and an open-vocabulary 2D detector. 2. Adaptive Pseudo-LiDAR Erosion: removing artifacts and noises from the pseudo-LiDAR using an adaptive erosion process based on object size. 3. Box Orientation Estimation: estimating the ground plane and using principal component analysis to determine the orientation of 3D bounding boxes. 4. Bounding Box Search: tightly fitting a bounding box around the pseudo-LiDAR points and using object priors from large language models to refine the bounding box if necessary. 5. Training: training the monocular 3D object detector using the refined pseudo labels.
read the caption
Figure 3: The overall framework of OVM3D-Det. Step 1: Generate per-instance pseudo-LiDAR. Step2: Apply an adaptive erosion process to remove artifacts and noises. Step 3: Estimate the orientation. Step 4: Tightly fit a box and utilize object priors to assess the estimated box; if deemed unreasonable, search for the optimal box. Step 5: Train the model with pseudo labels.

🔼 This figure illustrates the two loss functions used in the bounding box search process. (a) shows the ray tracing loss, which calculates the distance between each LiDAR point and the nearest intersection point between the proposal box and the camera ray. (b) shows the point ratio loss, which calculates the ratio of points inside the box to the total number of points. These two loss functions are combined to select the best-fitting proposal box.
read the caption
Figure 4: Ray tracing loss and point ratio loss.

🔼 This figure shows some qualitative results of the proposed OVM3D-Det model on SUN RGB-D and KITTI datasets. The images display 3D bounding boxes around detected objects with their class labels. This visually demonstrates the model’s ability to perform open-vocabulary 3D object detection in both indoor (SUN RGB-D) and outdoor (KITTI) scenes.
read the caption
Figure 5: Qualitative results on SUN RGB-D and KITTI.
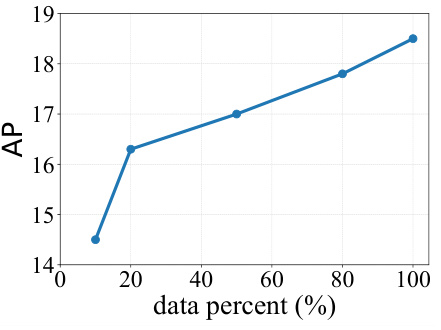
🔼 This figure shows the impact of the amount of training data used on the model’s performance. The x-axis represents the percentage of training data used, and the y-axis represents the average precision (AP) achieved by the model. The plot shows a clear upward trend, indicating that as more training data is used, the model’s performance improves consistently.
read the caption
Figure 6: Effect of training data. As the volume of training data grows, we consistently see performance improvements.
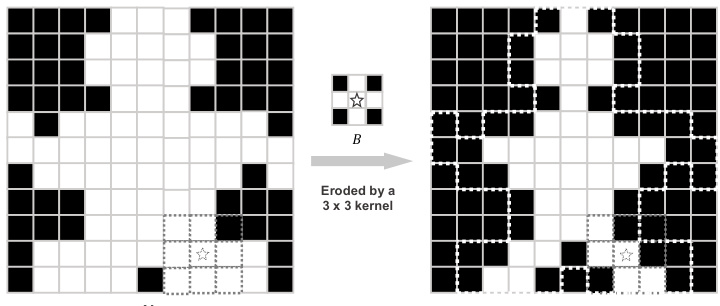
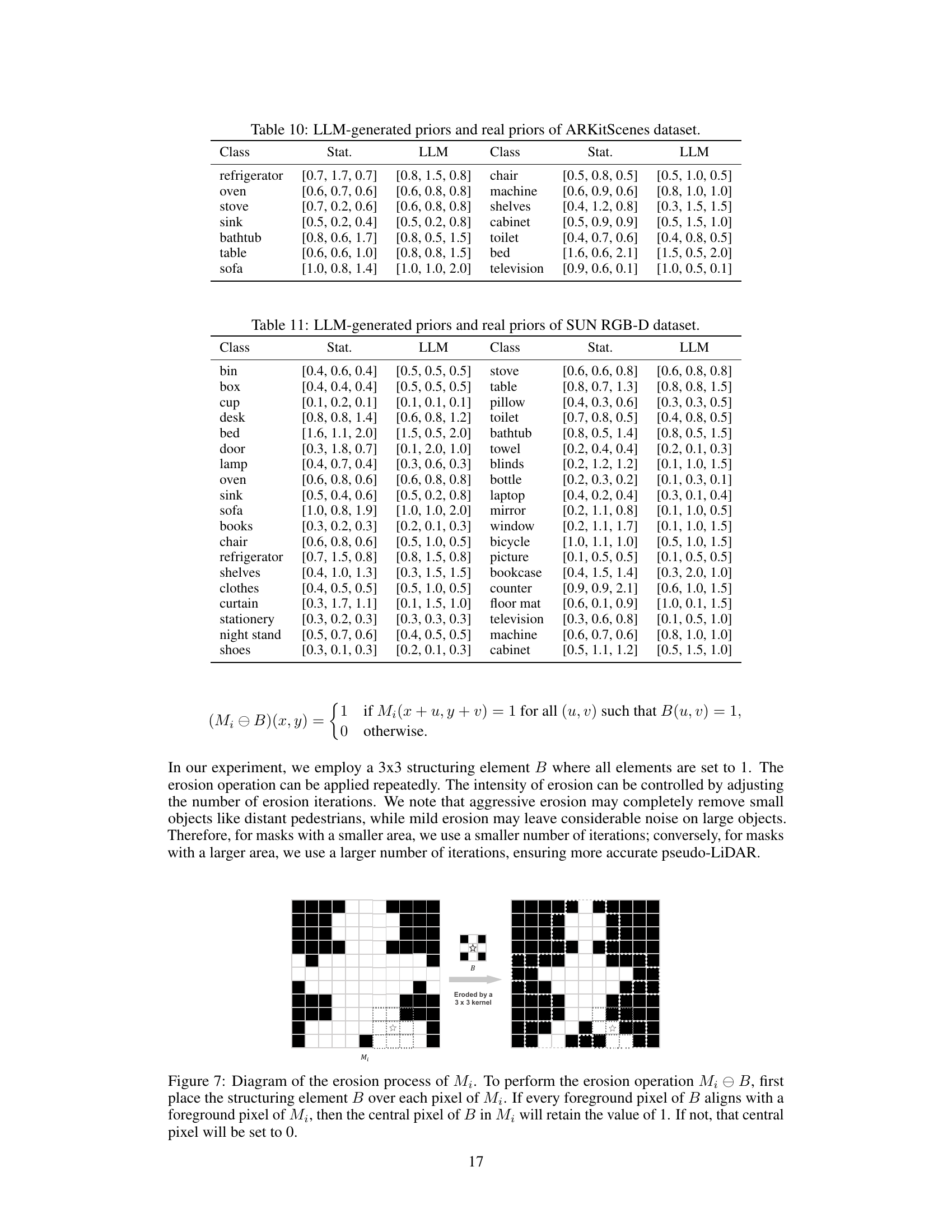
🔼 This figure shows an example of image erosion using a 3x3 kernel. Image erosion is a morphological operation that shrinks or wears away the boundaries of foreground objects in a binary image. The figure illustrates how the erosion process works by showing how a 3x3 kernel is applied to the original binary image (left) to produce an eroded image (right). The result is a smaller, smoother image with less noise at the edges of objects.
read the caption
Figure 7: Diagram of the erosion process of Mi. To perform the erosion operation Mi → B, first place the structuring element B over each pixel of Mi. If every foreground pixel of B aligns with a foreground pixel of Mi, then the central pixel of B in Mi will retain the value of 1. If not, that central pixel will be set to 0.

🔼 This figure shows qualitative results of the proposed OVM3D-Det model on SUN RGB-D and KITTI datasets. The images display the model’s ability to detect and localize objects of various types and sizes in both indoor and outdoor scenes. The model successfully identifies and draws bounding boxes around objects such as cars, trucks, and pedestrians. This demonstrates the model’s capability in open-vocabulary 3D object detection.
read the caption
Figure 5: Qualitative results on SUN RGB-D and KITTI.
More on tables
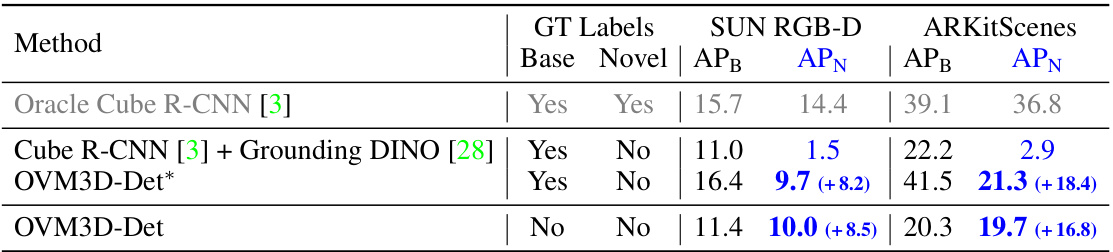
🔼 This table presents the results of open-vocabulary monocular 3D object detection on SUN RGB-D and ARKitScenes datasets. It compares the performance of four different methods: 1. Oracle Cube R-CNN: Uses ground truth labels for both base and novel classes, serving as an upper bound on performance. 2. Cube R-CNN + Grounding DINO: Uses ground truth labels for base classes and leverages Grounding DINO for novel class prediction. 3. OVM3D-Det:* Uses ground truth labels for base classes and pseudo labels for novel classes, serving as an intermediate comparison point for the proposed method. 4. OVM3D-Det: Uses only pseudo labels generated by the proposed method, reflecting its fully unsupervised nature. The table shows Average Precision (AP) values for both base (B) and novel (N) classes on each dataset, highlighting the performance gain of OVM3D-Det compared to baselines, especially for novel categories.
read the caption
Table 2: Open-vocabulary monocular 3D object detection results on SUN RGB-D and ARKitScenes. To compare with the baseline, we also present the OVM3D-Det results trained using ground-truth annotations for base classes and pseudo labels for novel classes, denoted by *.

🔼 This table compares the performance of the proposed OVM3D-Det model against several existing point cloud-based open-vocabulary 3D object detection methods on the SUN RGB-D dataset. The comparison focuses on the average precision (AP) metric, highlighting the significant improvement achieved by OVM3D-Det, which leverages only RGB images for training.
read the caption
Table 3: Comparison with point cloud-based open-vocabulary 3D object detection methods on SUN RGB-D.
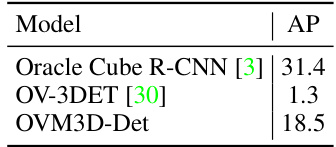
🔼 This table compares the performance of the proposed OVM3D-Det model against existing point cloud-based open-vocabulary 3D object detection methods on the KITTI dataset. It highlights the significant improvement achieved by OVM3D-Det in terms of average precision (AP), demonstrating its superiority in open-vocabulary 3D object detection without relying on LiDAR point cloud data.
read the caption
Table 4: Comparison with point cloud-based open-vocabulary 3D object detection methods on KITTI.
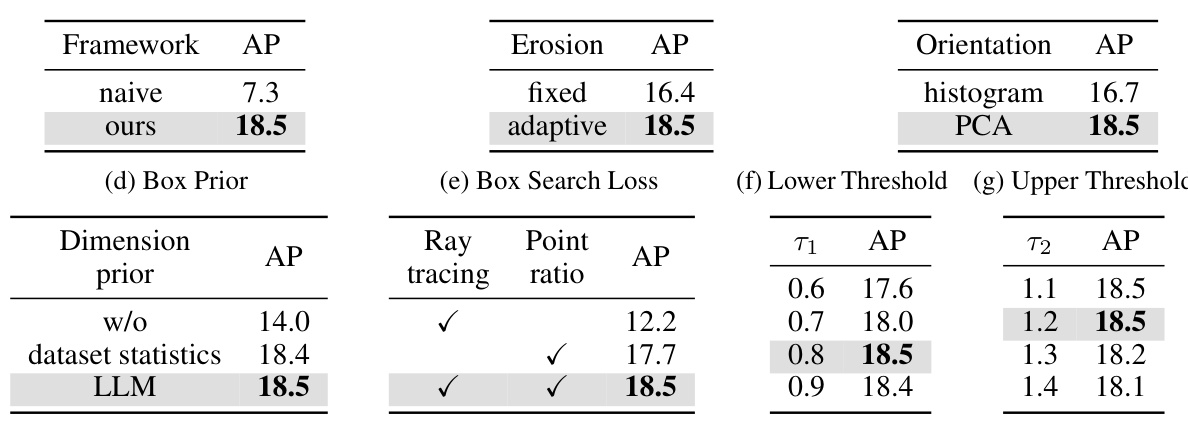
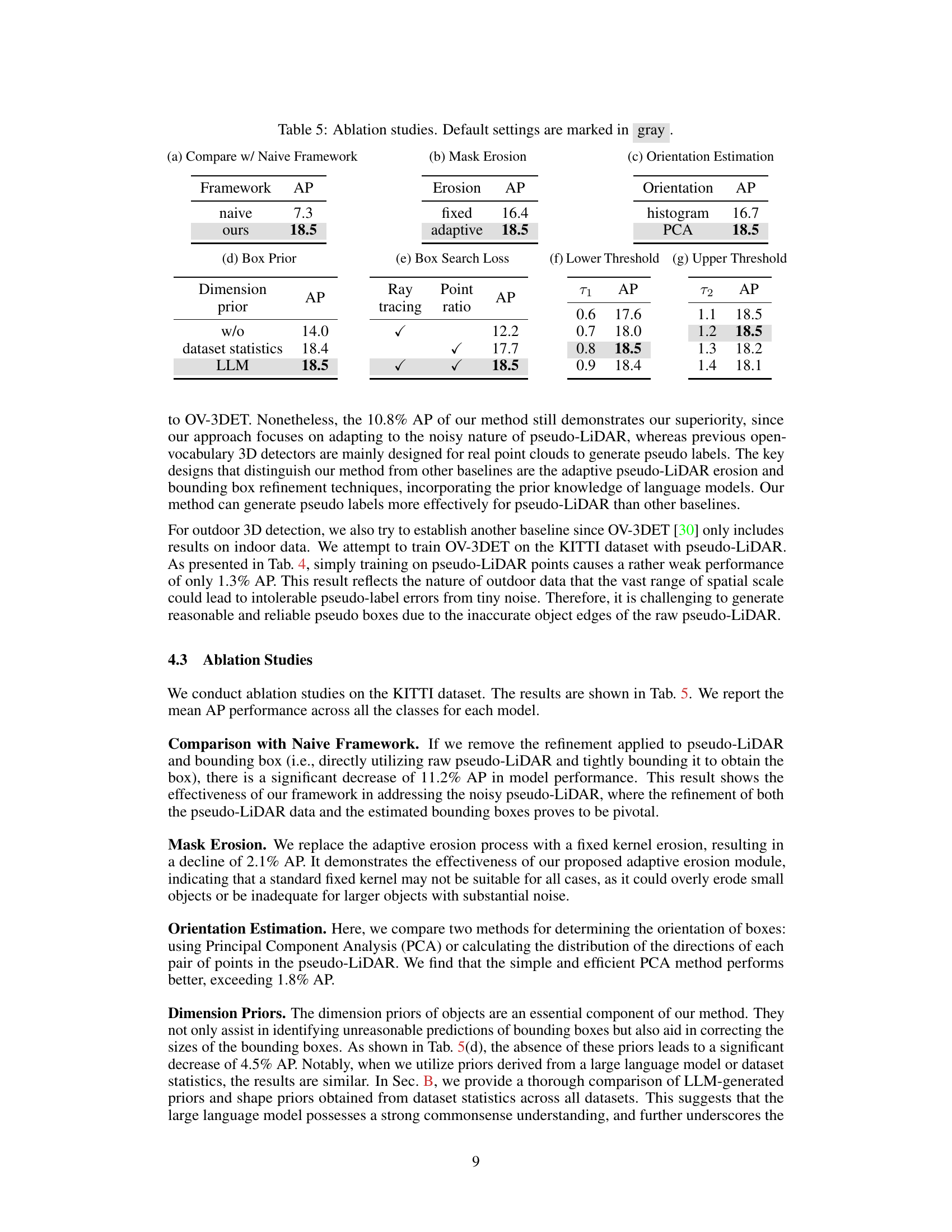
🔼 This table presents the results of ablation studies conducted on the KITTI dataset to analyze the impact of different components of the OVM3D-Det framework. It shows how the performance (measured by Average Precision, AP) changes when specific components are removed or modified. The components examined include the core framework, the adaptive pseudo-LiDAR erosion, orientation estimation method, dimension priors, box search loss function, and the thresholds used for the box search. The results highlight the importance of each component and the overall effectiveness of the proposed adaptive methods.
read the caption
Table 5: Ablation studies. Default settings are marked in gray

🔼 This table shows the improvement of the model’s performance after applying self-training. Self-training is a technique that uses the model’s previous predictions as pseudo-labels to further train the model. The table shows that after self-training, the model’s overall performance (AP) improves, and the performance on objects at various distances (AP-Near, AP-Middle, AP-Far) also improves.
read the caption
Table 6: Self-training can further improve the quality of the initially generated pseudo boxes.

🔼 This table shows how the datasets used in the paper (KITTI, nuScenes, SUN RGB-D, and ARKitScenes) are divided into base classes and novel classes. The base classes are those present in the training data, while the novel classes are those not seen during training and used to test the model’s ability to generalize to unseen objects.
read the caption
Table 7: Category splits for open-vocabulary 3D detection.

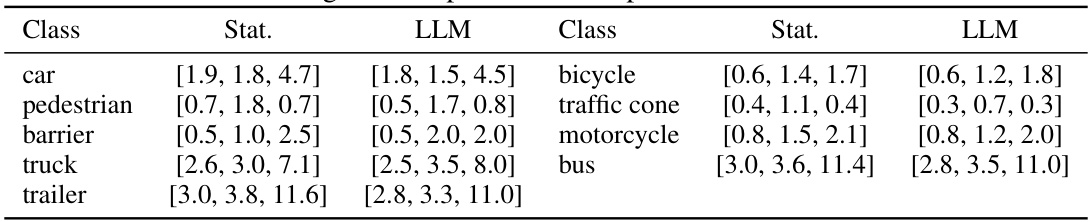
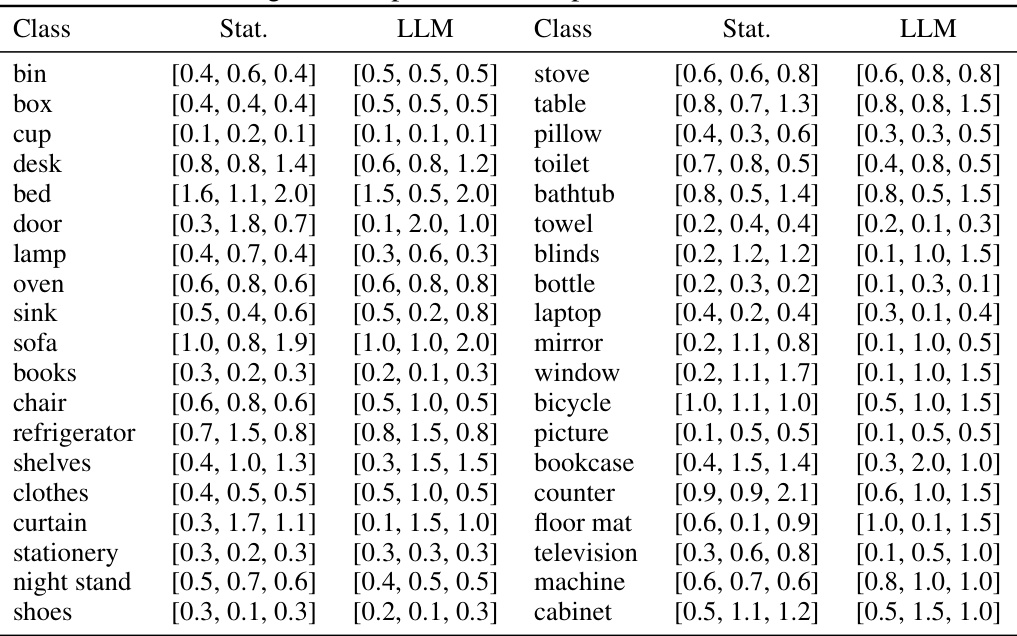
🔼 This table compares the typical dimensions (length, width, height) of objects in the KITTI dataset as predicted by a large language model (LLM) and as calculated from the actual data statistics. This comparison helps demonstrate the effectiveness of the LLM in providing reasonable estimations of object dimensions, which are used to evaluate the plausibility of automatically generated 3D bounding boxes.
read the caption
Table 8: LLM-generated priors and real priors of KITTI dataset.
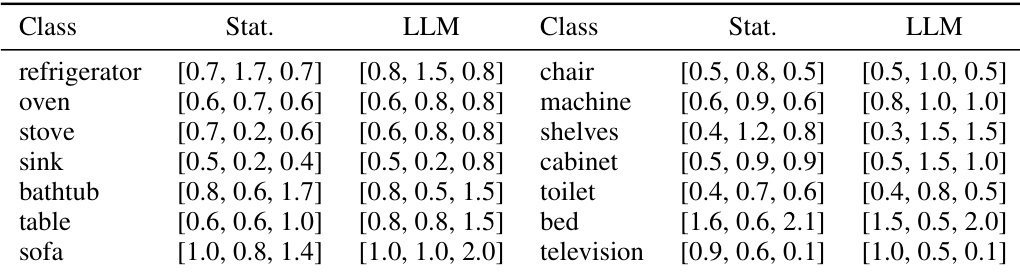
🔼 This table compares the typical dimensions (length, width, height) of various object categories in the nuScenes dataset, as predicted by a large language model (LLM) and as derived from the dataset’s statistical distribution. The comparison helps assess the accuracy and reliability of using LLM-generated priors as a reasonable estimate for object dimensions in the absence of ground truth data. The slight discrepancies may arise from inherent ambiguities in natural language descriptions and variations in object sizes.
read the caption
Table 9: LLM-generated priors and real priors of nuScenes dataset.
🔼 This table presents a comparison of open-vocabulary monocular 3D object detection results on the KITTI and nuScenes datasets. It compares the performance of the proposed OVM3D-Det model against several baselines. The results are broken down into average precision (AP) for both base classes and novel classes. A variant of the OVM3D-Det model is included (*), which uses ground truth labels for base classes and pseudo labels for novel classes, demonstrating the effectiveness of the method’s pseudo-labeling technique.
read the caption
Table 1: Open-vocabulary monocular 3D object detection results on KITTI and nuScenes. To compare with the baseline, we also present the OVM3D-Det results trained using ground-truth annotations for base classes and pseudo labels for novel classes, denoted by *.
🔼 This table presents the results of open-vocabulary monocular 3D object detection experiments performed on the KITTI and nuScenes datasets. The results are compared against several baselines, including an oracle model trained with ground truth labels, a model using Grounding DINO for novel class labeling and the proposed OVM3D-Det method. A variant of OVM3D-Det (*) is included which uses ground truth for base classes and pseudo labels for novel classes to help understand the effectiveness of the pseudo-labeling approach.
read the caption
Table 1: Open-vocabulary monocular 3D object detection results on KITTI and nuScenes. To compare with the baseline, we also present the OVM3D-Det results trained using ground-truth annotations for base classes and pseudo labels for novel classes, denoted by *.

🔼 This table shows the comparison result of depth estimation and 3D detection performance on KITTI dataset using two different depth estimation models: Metric3D and Unidepth. It demonstrates the correlation between depth estimation accuracy and the performance of the 3D object detection model. A more accurate depth estimation model leads to better 3D detection performance.
read the caption
Table 12: Depth Estimation and 3D Detection Performance on KITTI dataset.
🔼 This table lists the assets used in the paper and specifies their respective licenses. The assets include various models for 3D object detection and depth estimation, as well as several publicly available datasets. Knowing the licenses is important for understanding the usage rights and restrictions for each asset.
read the caption
Table 13: Licenses of assets used.
Full paper#