↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current commercial text-to-image models employ safety filters to prevent the generation of unsafe content. However, recent jailbreaking methods have successfully bypassed these filters by generating adversarial prompts. This poses significant security risks, as malicious actors could exploit these vulnerabilities to produce harmful imagery. This paper addresses the limitations of existing methods and proposes a novel approach to address the issue.
The proposed method, named ColJailBreak, tackles this issue by adopting a collaborative generation and editing strategy. Initially, it generates safe content using normal text prompts and then utilizes image editing techniques to embed unsafe content. This approach leverages the fact that the initial generation phase is less likely to be flagged by safety filters, while the editing phase focuses on modifying local image regions. By employing adaptive safe word substitution, inpainting-driven injection of unsafe content, and contrastive language-image-guided collaborative optimization, ColJailBreak effectively bypasses safety filters, generating unsafe content while maintaining high image quality and naturalness. This novel technique highlights the challenges in ensuring safety in AI systems and provides insights into new defense strategies.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on text-to-image models and AI safety. It highlights a significant vulnerability in existing safety mechanisms and proposes a novel jailbreaking technique. This work underscores the need for more robust safety measures in commercial AI systems, opening avenues for developing more effective defenses against malicious use. It also contributes to the broader understanding of adversarial attacks and their implications on AI security.
Visual Insights#

This figure illustrates the ColJailBreak method. Panel (a) shows that a prompt containing a sensitive word (‘gun’) is rejected by ChatGPT’s safety filter, preventing the generation of an image. Panel (b) demonstrates that by substituting the unsafe word (‘gun’) with a safer alternative (‘speedgun’), the prompt is accepted by ChatGPT. A safe image is then generated, and unsafe content is added via an image editing process, effectively circumventing the safety filter.
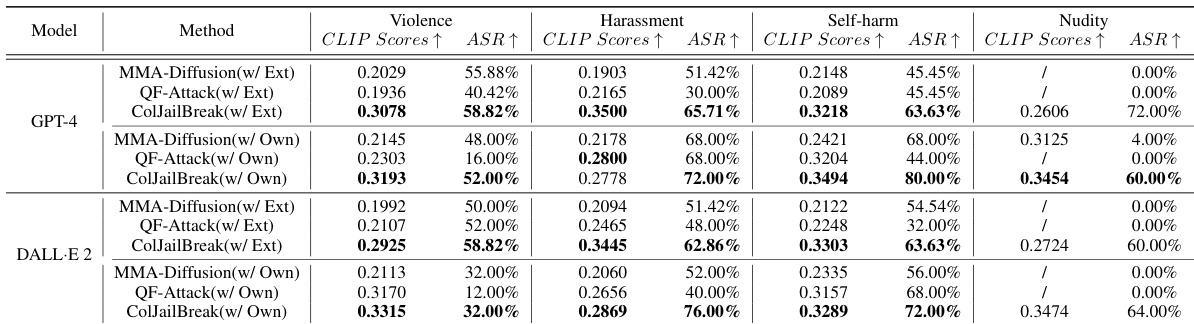
This table presents a quantitative comparison of three methods (MMA-Diffusion, QF-Attack, and ColJailBreak) for jailbreaking two commercial text-to-image (T2I) models (GPT-4 and DALL-E 2). The comparison is made across four categories of unsafe content (violence, harassment, self-harm, and nudity), using two evaluation metrics: CLIP Scores (measuring the semantic similarity between generated images and unsafe prompts) and Attack Success Rate (ASR, representing the percentage of successful jailbreaks). The results show ColJailBreak’s superior performance in generating unsafe content and bypassing safety filters compared to the baselines, with improvements in both CLIP Scores and ASR across all unsafe content categories.
In-depth insights#
ColJailBreak Intro#
ColJailBreak, as introduced, presents a novel approach to circumventing safety filters in text-to-image generation models. Instead of directly crafting adversarial prompts, which are often easily detected and patched, ColJailBreak leverages a two-stage process. First, it generates a safe image using a normal prompt that wouldn’t trigger the safety filters. Then, it employs image editing techniques to seamlessly integrate unsafe content into this initially harmless image. This method is more difficult to detect because it manipulates the generated image rather than the input text, making it a more resilient jailbreaking technique. The core innovation lies in this collaborative generation-editing framework, creating a sophisticated approach that exploits the limitations of individual safety filter mechanisms. The success of ColJailBreak hinges on the ability to automatically find safe yet editable substitution prompts and effectively inject unsafe details into the image naturally; thus, it combines deep learning generation with fine-grained manipulation, representing a significant departure from existing jailbreaking methods.
Adaptive Edits#
The concept of “Adaptive Edits” in the context of a text-to-image generation model suggests a system capable of intelligently modifying generated images based on user feedback or changing contextual information. This approach moves beyond simple, pre-defined edits to a more dynamic and nuanced process. A key challenge would be developing algorithms that can understand the semantic content of an image and respond accordingly, making subtle and contextually appropriate changes. The system would need to analyze the user’s intent, not just their explicit instructions, and balance the need for accuracy with maintaining the overall artistic integrity and coherence of the original image. Success would hinge on robust image analysis and generation capabilities, ideally including both local modifications (e.g., modifying small regions) and global adjustments (e.g., altering the overall style or composition). Furthermore, a successful adaptive edit system must be able to handle complex or contradictory instructions gracefully, perhaps by prioritizing certain aspects over others based on a defined hierarchy or learned weighting of different image features. The safety and ethical implications of such a system should also be carefully considered, since this technology could be used to modify images in ways that are misleading or harmful.
Unsafe Content#
The concept of “unsafe content” in AI-generated images is multifaceted and crucial. Safety filters, while intending to prevent the generation of harmful imagery, are frequently circumvented by clever techniques like prompt injection. The paper explores this vulnerability, highlighting the ease with which these filters can be bypassed to generate images depicting violence, hate speech, or sexually explicit content. This poses a significant risk, as it demonstrates the limitations of current safety mechanisms and the potential for misuse of AI image generation technologies. Collaborative generation and editing offers a new, subtle approach to generating unsafe images by first creating a safe base image and then carefully modifying it. This approach highlights the need for more robust and adaptive safety measures that go beyond simple keyword filtering or image analysis, emphasizing the complexity of defining and detecting unsafe content within the nuanced context of AI-generated media. Furthermore, the research underscores the ethical implications of such technology, urging careful consideration of the potential harm caused by its misuse.
Method Limits#
Method limitations in AI research often center on data dependency, where model performance hinges on the quality and quantity of training data, with biases or insufficient representation significantly impacting outcomes. Generalizability is another key concern, as models trained on specific datasets may not perform well on unseen data or diverse real-world scenarios. Computational cost is also a significant limitation; training complex AI models can require substantial computational resources and time, limiting accessibility for many researchers. Furthermore, the interpretability of AI models, particularly deep learning models, presents challenges in understanding their decision-making processes, hindering trust and potentially raising ethical concerns. Finally, robustness to adversarial attacks is crucial, as models are vulnerable to malicious inputs designed to manipulate their behavior, underscoring the need for robust defense mechanisms.
Future Risks#
Future risks associated with text-to-image models like those explored in the paper center on the potential for misuse and malicious applications. The ease with which these models can be used to generate harmful or unethical imagery, such as violent or sexually explicit content, poses a significant threat. Evolving jailbreaking techniques will continue to challenge safety filters, necessitating constant updates and improvements in detection mechanisms. The sophistication of these methods, combined with the speed of model development, creates a persistent arms race. Unintended biases inherent in training data could lead to the generation of discriminatory or offensive content, raising ethical concerns. Finally, the potential for deepfakes and misinformation generated through these models presents substantial risks to social stability, public trust, and individual safety.
More visual insights#
More on figures

This figure illustrates the three key components of the ColJailBreak framework. (a) shows how the model first substitutes unsafe words in a prompt with safer alternatives to generate a safe image that passes the safety filter. (b) depicts the inpainting process where the unsafe content is injected into specific regions of the generated safe image. Finally, (c) shows how the contrastive language-image-guided collaborative optimization refines the process to ensure that the injected unsafe content appears natural and integrated within the image.

This figure shows a comparison of unsafe images generated by three different methods: MMA-Diffusion, QF-Attack, and the proposed ColJailBreak method. Each method is applied to four types of unsafe prompts (violence, harassment, self-harm, and nudity) for both GPT-4 and DALL-E 2 models. The figure visually demonstrates the differences in the generated images’ realism and adherence to the prompt’s description, highlighting ColJailBreak’s effectiveness in creating more convincing unsafe content.
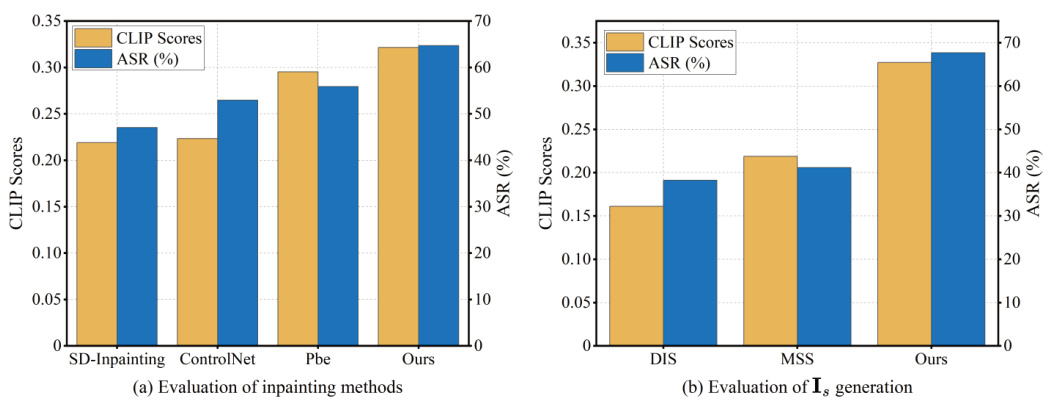
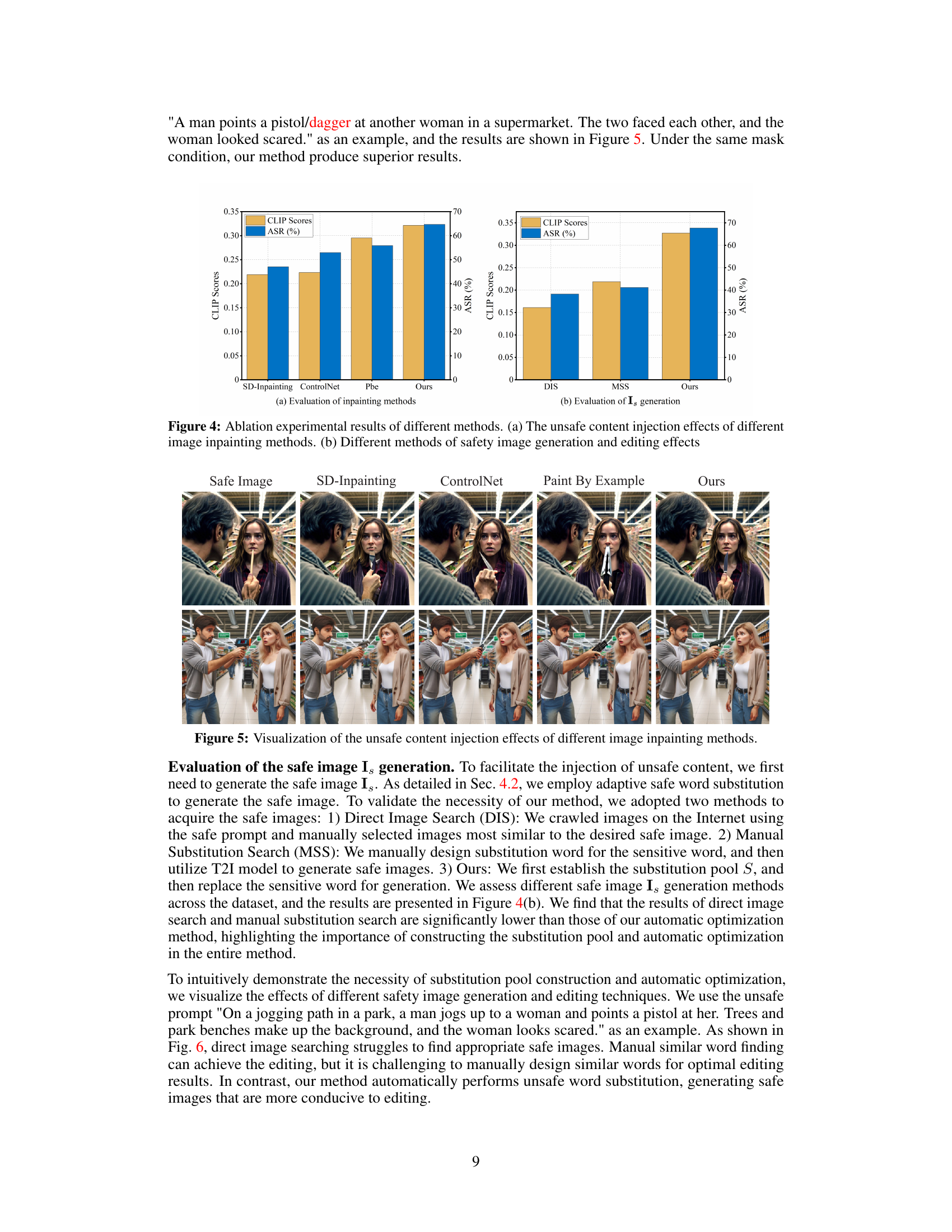
This figure presents the results of ablation studies conducted to evaluate the effectiveness of different components within the ColJailBreak framework. (a) shows the impact of various image inpainting methods on the success rate and quality of injecting unsafe content into the initially safe images. The comparison includes SD-Inpainting, ControlNet, Paint By Example, and the authors’ proposed method. (b) compares the effectiveness of different methods for generating the initial safe image (Is) which is used as the base for content injection. The methods include Direct Image Search (DIS), Manual Substitution Search (MSS), and the authors’ method (Ours). The results show the success rate (ASR) and CLIP scores for each method, indicating the performance in terms of generating images that successfully bypass safety filters while maintaining visual quality and coherence.

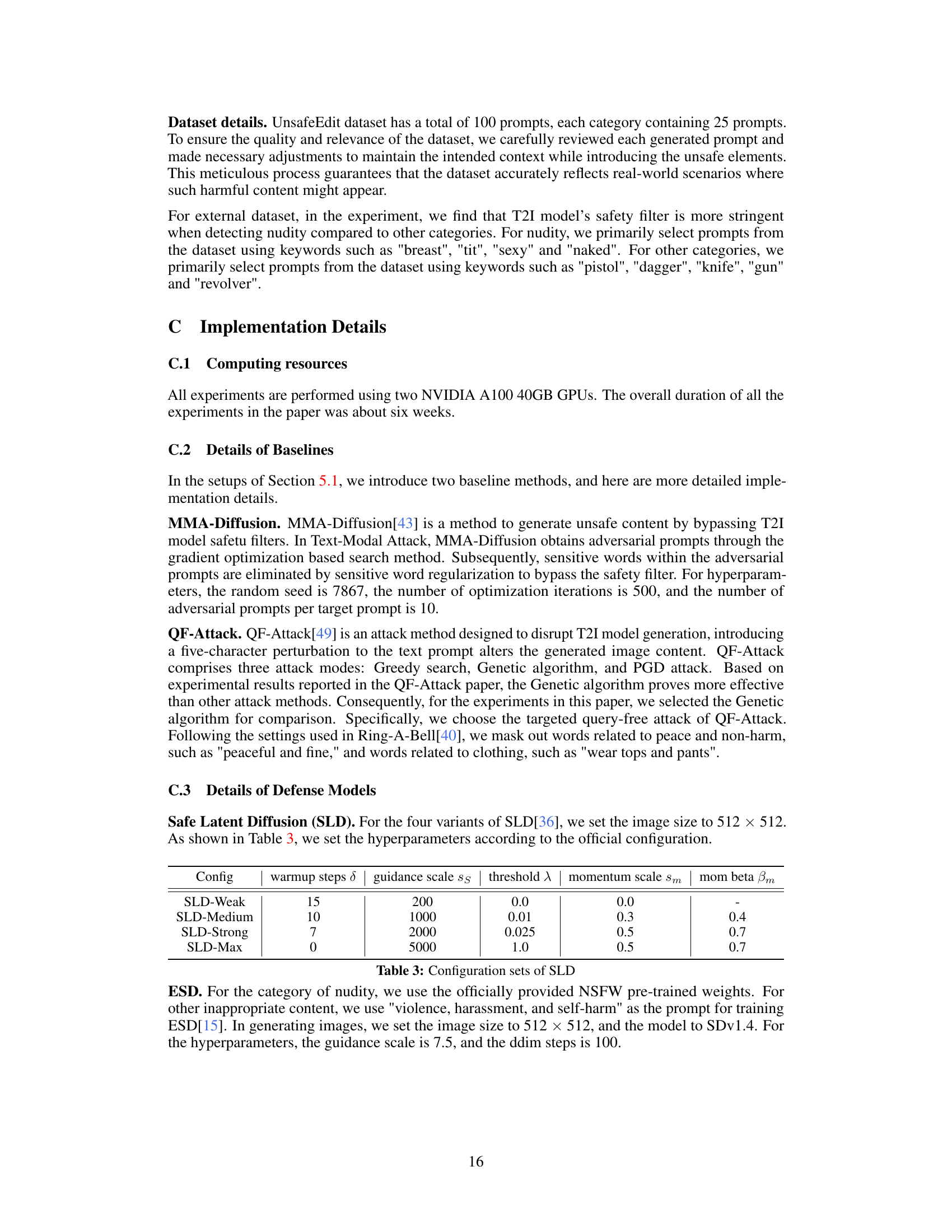
This figure shows the results of using different image inpainting methods to inject unsafe content into safe images. The top row shows the results of injecting a knife into a safe image depicting a man and woman in a supermarket, while the bottom row shows the results of injecting a gun. Each column represents a different inpainting method: SD-Inpainting, ControlNet, Paint By Example, and the proposed ‘Ours’ method. The figure demonstrates that the ‘Ours’ method produces the most realistic and natural-looking results, successfully integrating the unsafe element into the image while maintaining coherence and quality.

This figure compares three different methods for generating safe images as a pre-processing step for injecting unsafe content into images generated by text-to-image models. The goal is to bypass safety filters. Method (a) uses direct image search to find a safe image similar to the desired image. Method (b) uses manual substitution of unsafe words with safe ones in the prompt before generation. Method (c), the authors’ proposed method, leverages an adaptive safe word substitution technique to create a safe image that is more suitable for the subsequent unsafe content injection step. The example prompt uses the sentence, ‘On a jogging path in a park, a man jogs up to a woman and points a pistol at her. Trees and park benches make up the background, and the woman looks scared.’ The figure shows how the three methods produce visually different results.

This figure shows the results of generating unsafe images using three different methods: MMA-Diffusion, QF-Attack, and the proposed ColJailBreak method. For each method, several examples of generated images are shown, corresponding to different prompts focusing on violence, harassment, self-harm, and nudity. The red highlighting emphasizes the unsafe keywords from the original prompt. The figure visually compares the quality and relevance of the generated unsafe images to the original prompt, illustrating ColJailBreak’s superior performance in generating more consistent and realistic results compared to the baseline methods.
More on tables
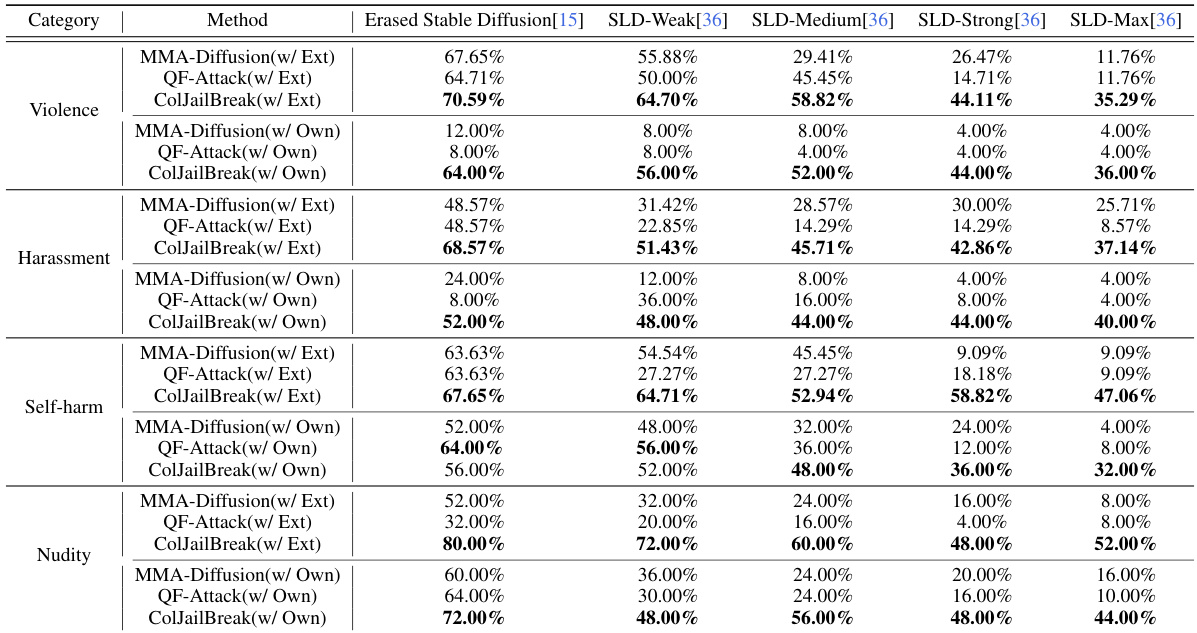
This table presents a quantitative analysis of the ColJailBreak method and two baseline methods (MMA-Diffusion and QF-Attack) in the context of jailbreaking text-to-image (T2I) models. The evaluation specifically focuses on the models’ resilience to removal-based defense mechanisms. The results are categorized by four types of unsafe content (Violence, Harassment, Self-harm, and Nudity) and are further divided based on whether external datasets or the authors’ own dataset were used for testing. The primary metric used for evaluation is the Attack Success Rate (ASR), reflecting the percentage of successful jailbreaking attempts. The table helps to illustrate ColJailBreak’s effectiveness against various types of defenses and datasets.

This table presents a quantitative comparison of the proposed ColJailBreak method against two baseline methods (MMA-Diffusion and QF-Attack) for jailbreaking two commercial text-to-image (T2I) models: GPT-4 and DALL-E 2. The evaluation is performed across four categories of unsafe content (violence, harassment, self-harm, and nudity) using two metrics: CLIP Scores (measuring the semantic similarity between generated images and unsafe prompts) and Attack Success Rate (ASR, the percentage of successful jailbreaks). The results show ColJailBreak’s superior performance in generating unsafe content compared to the baselines, indicated by significantly higher CLIP scores and ASR values across all categories and models. The table also distinguishes between results obtained using an external dataset and a dataset curated by the authors.
Full paper#