↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Processing large-scale 3D point cloud data remains computationally expensive, hindering applications in areas like autonomous driving and robotics. Existing point-based methods often struggle with scalability due to complex neighborhood search algorithms. Voxel-based methods, while efficient, lose geometric detail through quantization.
LinNet tackles these issues by introducing a novel disassembled set abstraction (DSA) module and a linear-time point search strategy. DSA efficiently leverages spatial and channel anisotropy for feature aggregation. The linear search uses space-filling curves to map 3D points onto 1D space, enabling parallelization on GPUs. This results in significant speed improvements, outperforming existing methods in accuracy and efficiency across multiple benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it presents LinNet, a novel approach to point cloud representation learning that significantly improves both efficiency and scalability. It addresses the challenge of processing large-scale 3D point cloud data, a crucial limitation in many applications. LinNet’s linear time complexity for point searching and novel DSA module make it particularly valuable for researchers working with large datasets, opening new avenues for efficient 3D scene understanding.
Visual Insights#
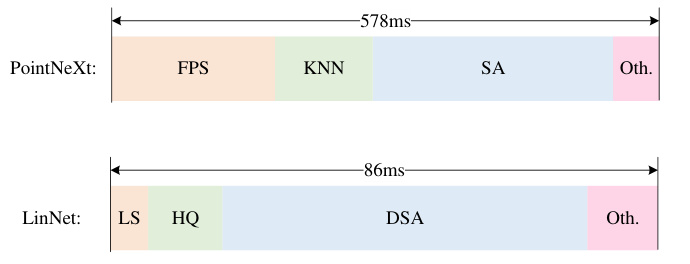
This figure compares the latency of LinNet with other point-based methods (PointNext, Point Transformer V2, PointVector, Stratified Transformer) for point cloud semantic segmentation on S3DIS Area5. It shows a breakdown of the inference time for each method, highlighting the components contributing to latency (Set Abstraction (SA), KNN search, etc). It demonstrates LinNet’s significantly improved speed while achieving higher mIoU (mean Intersection over Union).
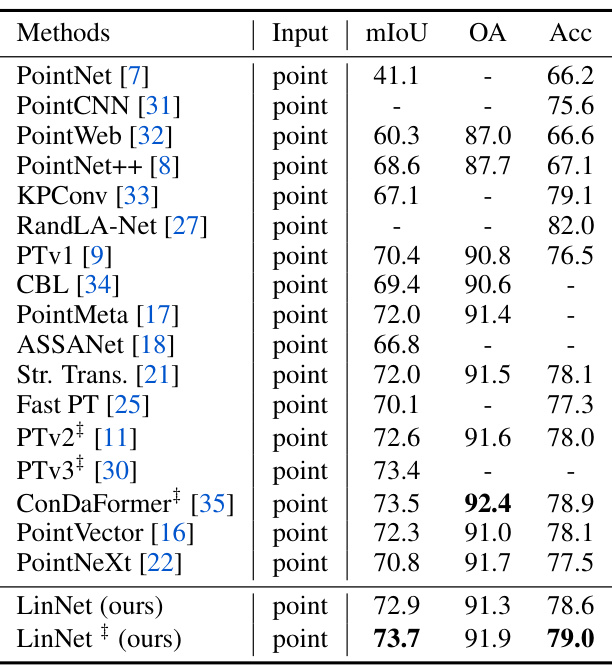
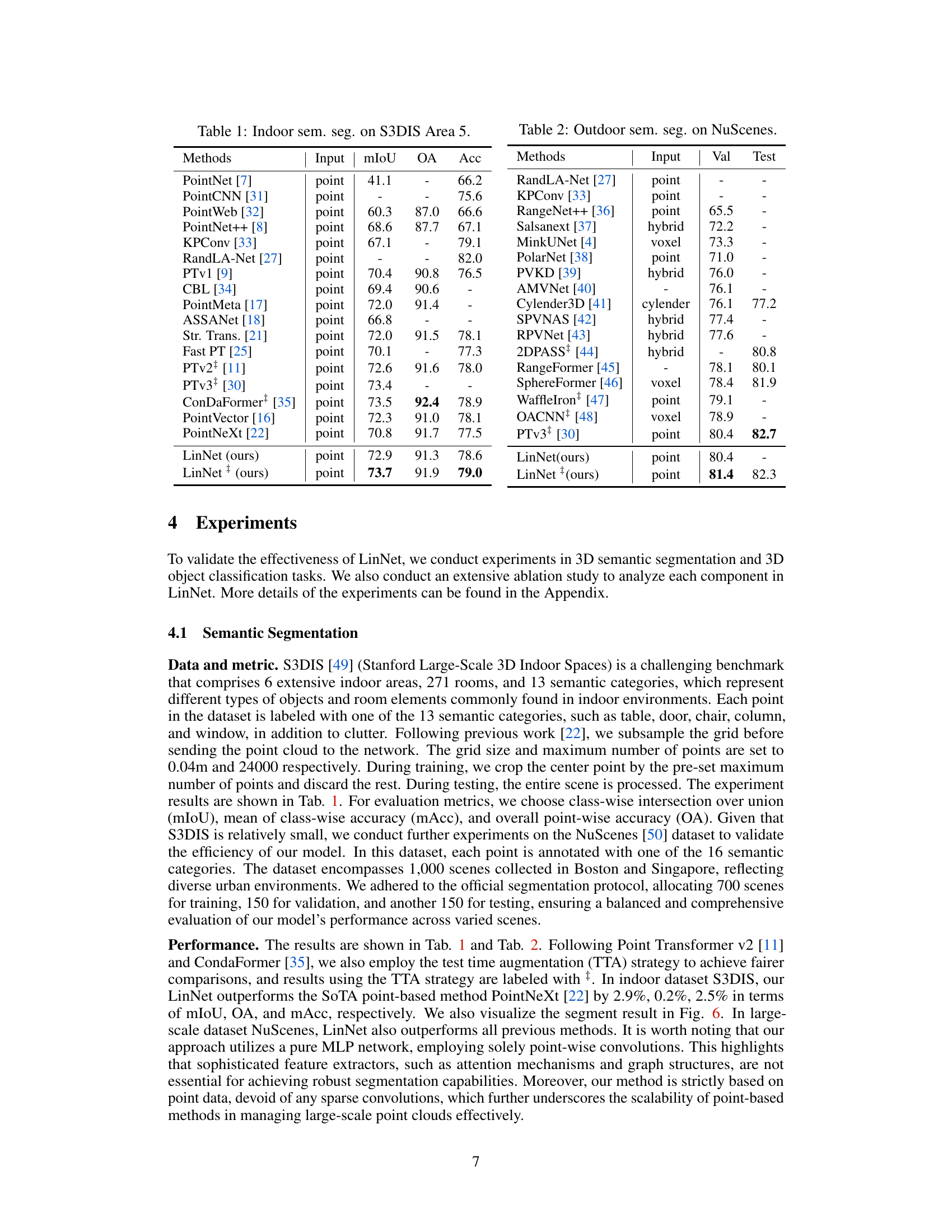
This table presents the results of indoor semantic segmentation on the S3DIS Area 5 dataset. It compares the performance of various methods (PointNet, PointCNN, PointWeb, PointNet++, KPConv, RandLA-Net, PTv1, CBL, PointMeta, ASSANet, Str. Trans., Fast PT, PTv2+, PTv3+, ConDaFormer, PointVector, PointNeXt, and LinNet) in terms of mIoU (mean Intersection over Union), OA (Overall Accuracy), and Acc (Accuracy). The ‘Input’ column specifies the type of input used by each method (point cloud). LinNet and LinNet+ (with test time augmentation) achieve the best results.
In-depth insights#
LinNet Architecture#
LinNet’s architecture is thoughtfully designed for efficiency in processing large-scale point clouds. A key innovation is the DSA (Disassembled Set Abstraction) module, replacing the traditional SA module with two independent MLPs for spatial and channel anisotropy, improving feature aggregation efficiency. The use of space-filling curves and hash queries maps 3D point cloud data into 1D space, enabling parallelization on GPUs for faster neighborhood queries and sampling. Linearization sampling further enhances efficiency. This linear complexity approach contrasts sharply with the quadratic complexity of traditional methods. The network utilizes a series of DSA blocks, progressively downsampling point clouds through multiple stages. The overall structure is a hierarchical design, mimicking a typical encoder-decoder structure common in point cloud segmentation. Simplicity is another notable characteristic; LinNet avoids the computationally expensive sparse convolutions found in other methods, relying instead on a basic MLP, achieving efficiency gains while maintaining competitive accuracy.
DSA Module Analysis#
A Disassembled Set Abstraction (DSA) module likely aims to improve the efficiency and effectiveness of point cloud feature aggregation. Standard set abstraction methods often involve high computational costs due to dense feature interactions. DSA likely decouples spatial and channel-wise feature processing, potentially using separate Multi-Layer Perceptrons (MLPs) to handle these independently. This approach could significantly reduce the computational burden by lowering the number of operations, especially in high-dimensional feature spaces. By carefully designing this separation, the DSA module might also achieve better feature representation learning, leading to improved performance in tasks such as point cloud classification and segmentation. The efficacy of DSA would likely be validated through experiments comparing its performance against conventional set abstraction methods in various scenarios such as different point cloud densities, data sizes, and task complexities. The results would highlight the trade-off between computational efficiency and performance gains offered by this novel design. Ablation studies focusing on the separate spatial and channel MLPs would be essential to demonstrate the contribution of each component to the overall performance.
Efficient Search#
Efficient search strategies are crucial for processing large-scale point cloud data. The challenge lies in balancing speed and accuracy when finding nearest neighbors, a fundamental operation in many point cloud algorithms. This often involves exploring spatial data structures or approximate nearest neighbor (ANN) techniques. Hashing methods offer a promising avenue for rapid neighbor retrieval by mapping points to a hash table based on their spatial location. However, challenges such as hash collision and the need for efficient hash function design must be addressed to ensure both speed and accuracy. Space-filling curves offer another approach by mapping 3D points onto a 1D space, enabling efficient range queries and parallel processing. This approach trades off some precision for a significant gain in speed. Ultimately, the optimal strategy often depends on the specific application and dataset characteristics, with a careful consideration of factors like point distribution and the desired precision level.
Scalability & Speed#
This research paper emphasizes efficiency and scalability in processing large-scale 3D point cloud data. A critical challenge addressed is the computational cost associated with neighborhood search operations, commonly bottlenecks in point cloud processing. The proposed method, LinNet, tackles this by introducing a linear-time complexity search strategy, mapping the 3D space onto a 1D space-filling curve, enabling parallelization and dramatically reducing query times. LinNet also employs a novel disassembled set abstraction (DSA) module that significantly improves local feature aggregation efficiency compared to existing methods, further contributing to overall speed. Benchmark results demonstrate near 10x speedup over state-of-the-art approaches while maintaining competitive accuracy, highlighting the effectiveness of LinNet’s design in achieving both scalability and speed in processing massive point cloud datasets.
Future Enhancements#
Future enhancements for this research could involve exploring advanced architectures such as transformers or graph neural networks to potentially capture more complex spatial relationships within point clouds. Investigating novel loss functions designed to address class imbalance issues in semantic segmentation tasks is also warranted. The current methodology relies on space-filling curves, but exploring alternative data structures or techniques for efficient point cloud processing could lead to significant improvements in scalability. Improving the handling of noise and outliers in point clouds is essential for real-world application robustness. Finally, adapting the model to handle dynamic or streaming point cloud data would enhance its applicability in autonomous driving and robotic perception scenarios, where real-time processing is critical. These directions would advance the model’s accuracy and efficiency, broadening its utility for diverse applications.
More visual insights#
More on figures

This figure demonstrates the efficiency of LinNet. Subfigure (a) breaks down the inference time of LinNet and other methods into components such as set abstraction (SA), the novel disassembled set abstraction (DSA), linearization sampling (LS), hash query (HQ), and other operations. Subfigure (b) shows a comparison of LinNet’s performance against other point-based methods in terms of accuracy (mIoU) and speed (latency). LinNet achieves the highest accuracy with significantly lower latency.
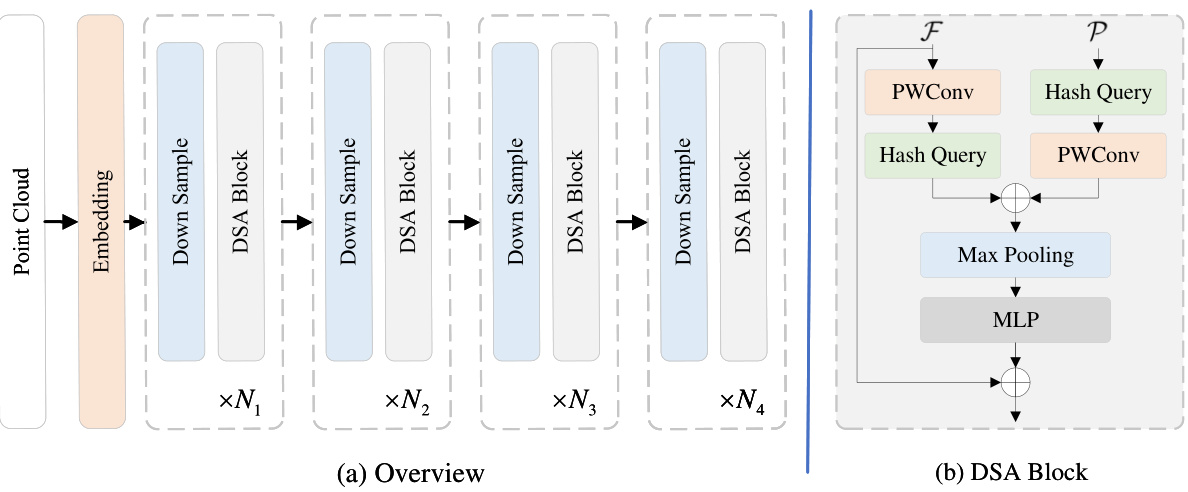
This figure illustrates the overall architecture of LinNet, a linear network for efficient point cloud representation learning. (a) shows a high-level overview of the network’s structure, highlighting the embedding layer, four stages of downsampling and DSA (disassembled set abstraction) blocks, and the sequential nature of the processing. Each stage involves downsampling the point cloud to reduce computational load and increase efficiency. (b) provides a detailed view of a single DSA block, outlining its internal components: a DSA module and multiple MLPs (multilayer perceptrons). The DSA module is a key innovation in LinNet, improving local feature aggregation efficiency.

This figure shows the training loss curves for three different set abstraction modules: SA (standard set abstraction), DSSA (depth-wise separate set abstraction), and DSA (disassembled set abstraction). The x-axis represents the training epochs, and the y-axis represents the training loss. The plot shows that DSA achieves a lower training loss compared to SA and DSSA. A zoomed-in section of the plot highlights the early training stages, further emphasizing the faster convergence of DSA.
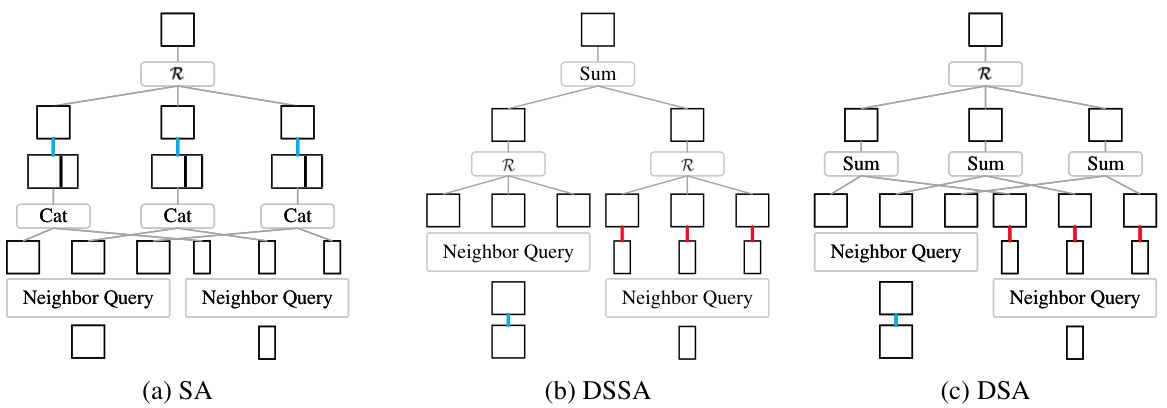
This figure compares three different local aggregation methods: SA (standard set abstraction), DSSA (depth-wise separated set abstraction), and DSA (disassembled set abstraction). It illustrates how each method processes semantic features and relative coordinates of neighboring points to aggregate local features. The number of neighbors considered is 3 in all cases. Blue lines represent high-dimensional mappings (more computation), and red lines represent low-dimensional mappings (less computation). DSA is shown to be more efficient with fewer high-dimensional mappings than the other two methods.
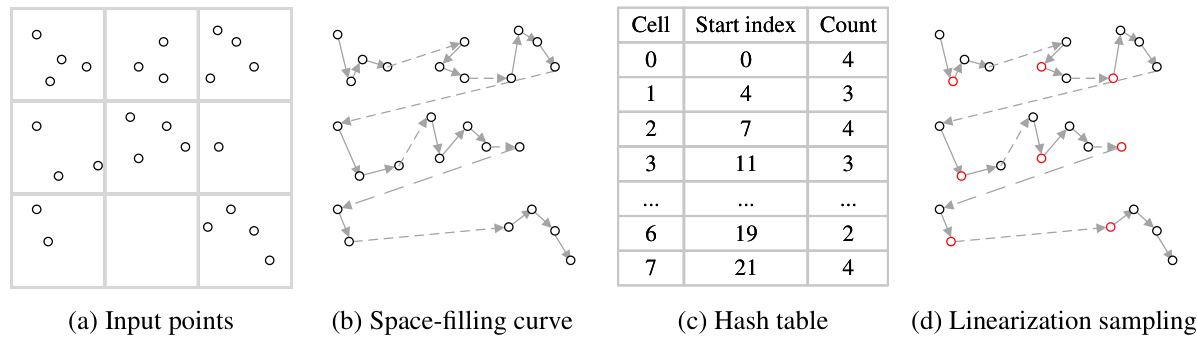
This figure illustrates the process of efficient point cloud searching and sampling using space-filling curves and a hash table. (a) shows the input point cloud. (b) shows how the points are linearized using a space-filling curve, grouping points in the same grid with solid arrows and points in neighboring grids with dashed lines. (c) shows the hash table created by storing each segment of the curve as a bucket, enabling efficient neighborhood queries. (d) shows the linearization sampling strategy, where the point closest to the center of each grid is selected as a new sampling point, ensuring uniform sampling and reducing computation.
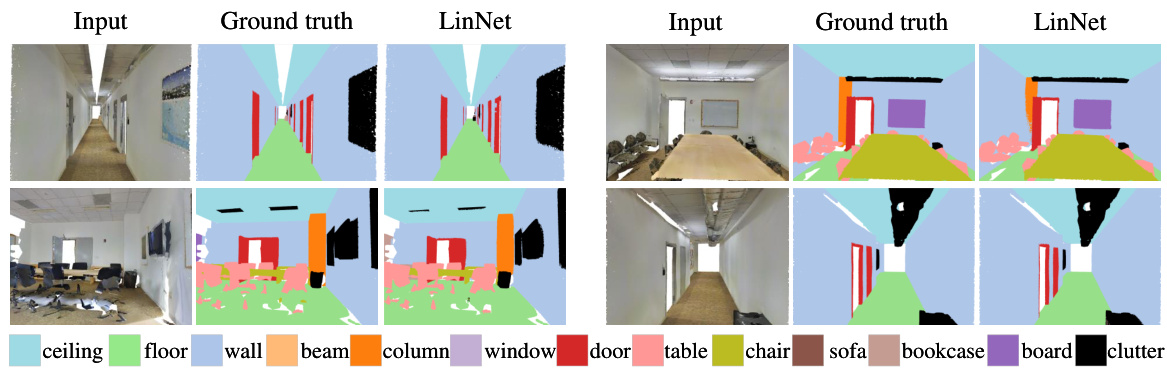
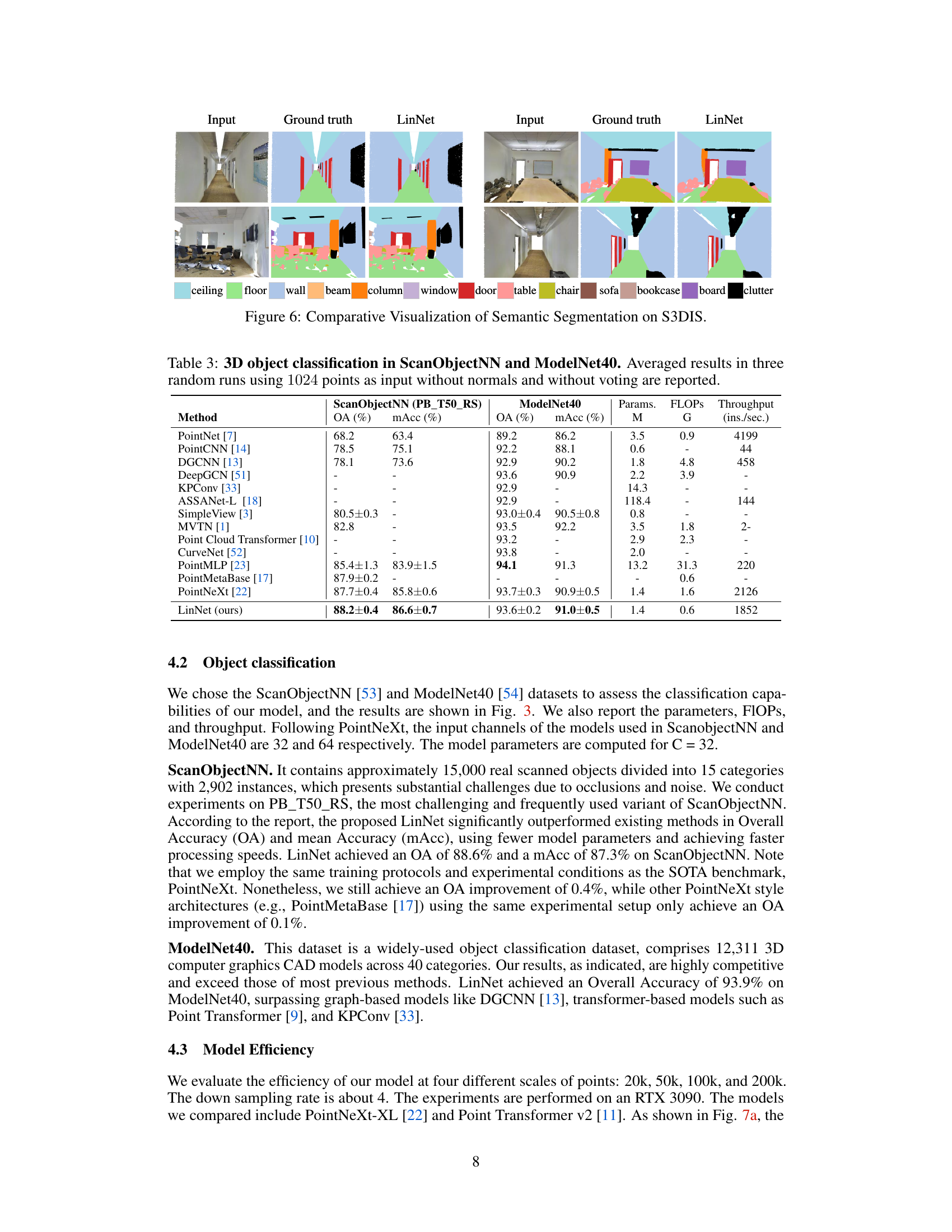
This figure shows a qualitative comparison of semantic segmentation results on the S3DIS dataset. For several example scenes, the input point cloud, ground truth segmentation, and the segmentation generated by LinNet are shown side-by-side. This allows for a visual comparison of the accuracy of LinNet’s predictions against the ground truth labels for various indoor scene types, illustrating the model’s performance on different types of objects and scene layouts.
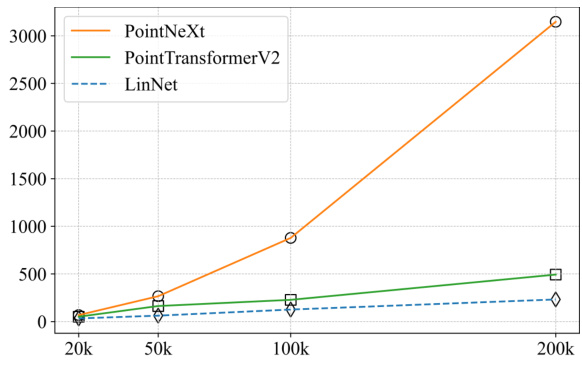
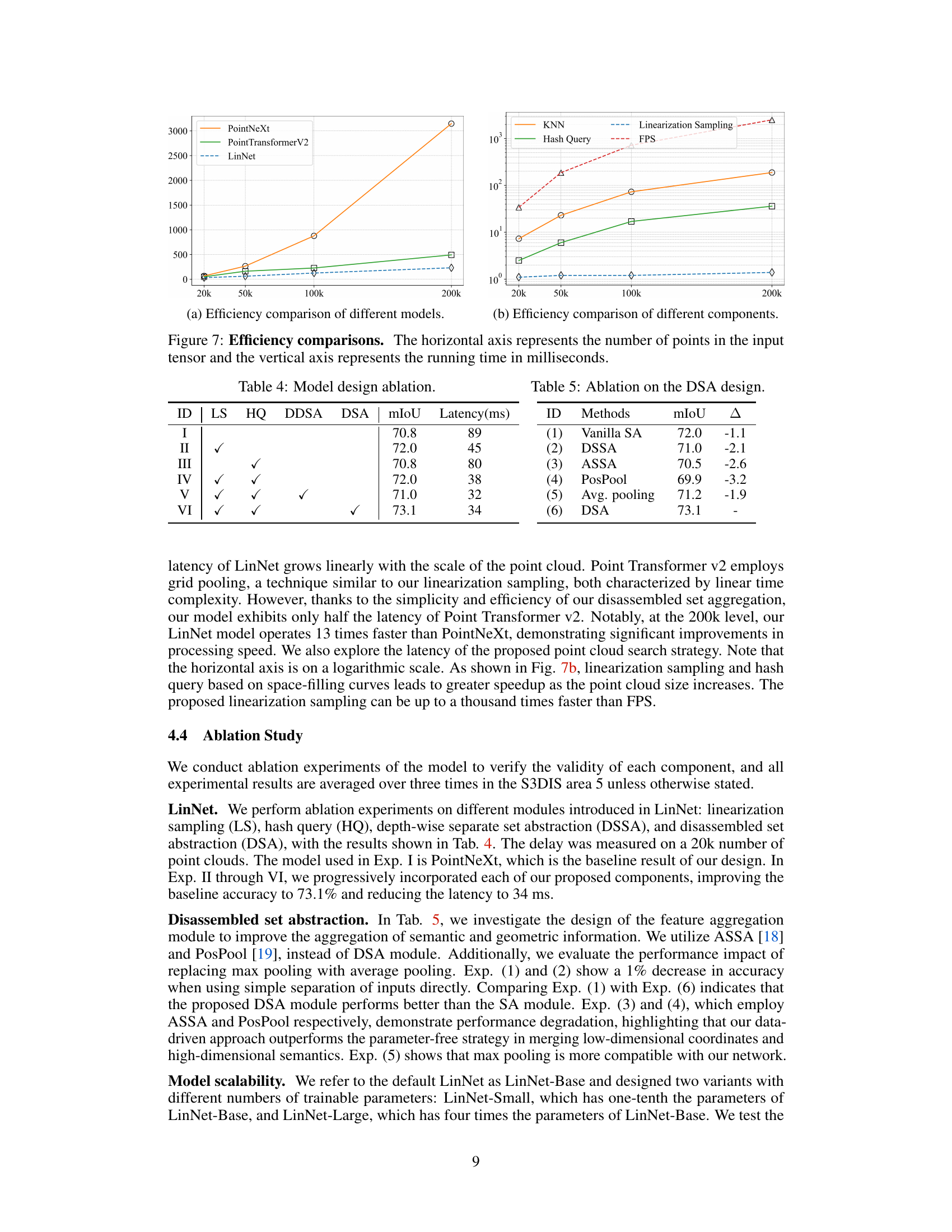
This figure compares the efficiency of LinNet with PointNeXt and Point Transformer V2. The x-axis shows the number of points in the input point cloud (20k, 50k, 100k, 200k), and the y-axis represents the inference time in milliseconds. It demonstrates that LinNet’s inference time scales linearly with the number of input points, significantly outperforming the other two methods, especially as the point cloud size increases. This highlights LinNet’s efficiency and scalability in handling large-scale point clouds.

This figure compares the efficiency of different point cloud search strategies: KNN, Hash Query, Linearization Sampling, and FPS. The x-axis shows the number of points in the input point cloud, ranging from 20k to 200k. The y-axis represents the time taken in milliseconds for each method to complete its search. The graph clearly demonstrates the superior efficiency of Linearization Sampling, showing significantly lower processing times compared to the other methods, particularly as the number of points increases. This highlights the advantage of the Linearization Sampling method proposed by the authors in enhancing the scalability and speed of their LinNet model.
More on tables
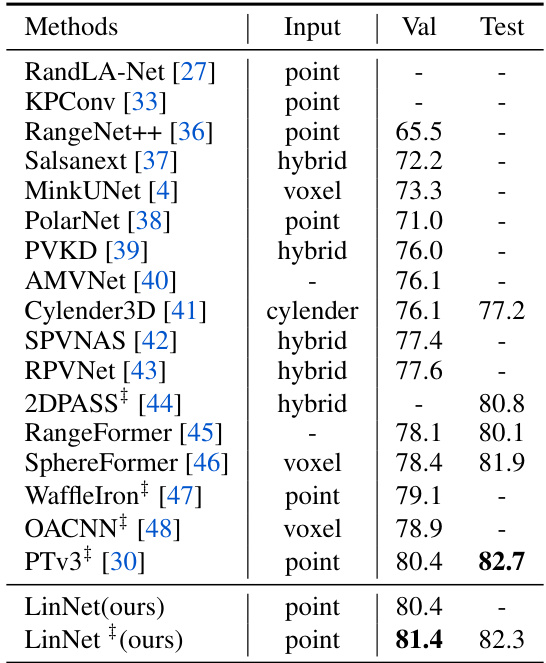
This table presents the performance comparison of different semantic segmentation methods on the NuScenes dataset. The table shows the input type (point cloud, voxel, or hybrid), validation mIoU, and test mIoU for each method. The methods are a mix of point-based, voxel-based, and hybrid approaches. LinNet is compared to state-of-the-art methods, showing competitive or superior performance.

This table presents a comparison of different 3D object classification methods on two benchmark datasets: ScanObjectNN and ModelNet40. The results, averaged over three runs, show the overall accuracy (OA) and mean accuracy (mAcc) for each method. The table also includes model parameters (in millions), FLOPs (in billions), and throughput (in instances per second). The absence of normals and voting in the experiments is noted.

This table presents the ablation study on the Disassembled Set Abstraction (DSA) module. It compares the performance (mIoU) and latency of different variations of the DSA module against a vanilla set abstraction (SA) baseline. The variations include depthwise separable set abstraction (DSSA), anisotropic separable set abstraction (ASSA), positional pooling (PosPool), average pooling, and the final DSA module. The results show the impact of each component on both accuracy and efficiency.

This table shows the impact of model size on the performance of LinNet. Three different model sizes (Small, Base, Large) are evaluated, each with varying numbers of channels and depths. The table presents the model parameters (Param(M)), floating-point operations (FLOPs (G)), inference latency (Latency (ms)), and mean Intersection over Union (mIoU(%)) achieved on a 24k point dataset. It demonstrates the scalability of LinNet in terms of both efficiency and accuracy.

This table presents a comparison of the memory usage (both training and inference) for different models on the NuScenes dataset. It shows that PointNeXt runs out of memory, while LinNet and LinNet-Small have considerably lower memory footprints, highlighting the efficiency of the proposed method. MinkUNet is included as a baseline for comparison.
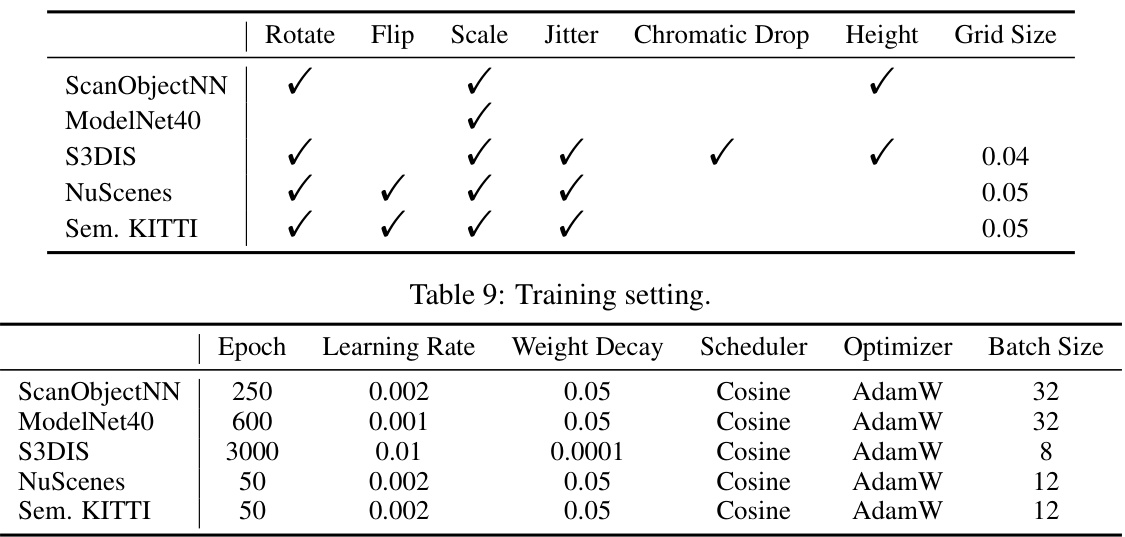
This table details the hyperparameters used during the training phase for different datasets. It includes the number of epochs, learning rate, weight decay, scheduler type (Cosine Annealing), optimizer (AdamW), and batch size used for each dataset (ScanObjectNN, ModelNet40, S3DIS, NuScenes, and SemanticKITTI).

This table presents the results of outdoor semantic segmentation on the NuScenes dataset. It compares various methods (listed in the first column) based on their input data type (point cloud, voxel, or hybrid), validation mIoU, and test mIoU. The results demonstrate the performance of LinNet in comparison to other state-of-the-art approaches for this task.
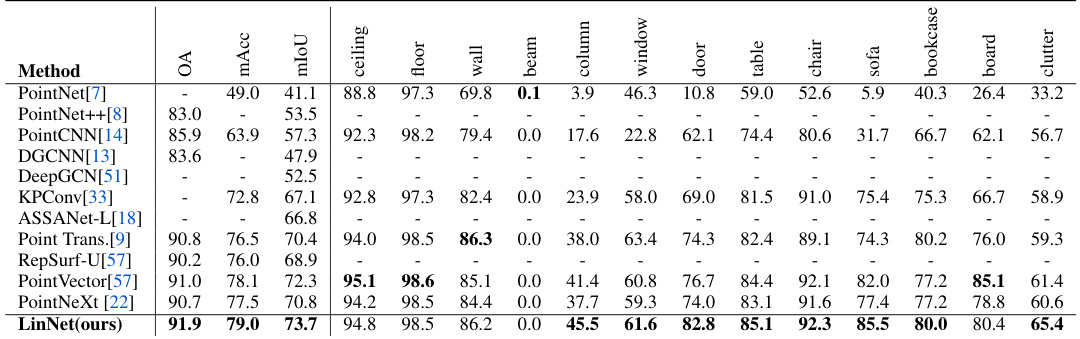
This table presents the results of indoor semantic segmentation on the S3DIS Area 5 dataset. It compares various methods (PointNet, PointCNN, PointNet++, etc.) in terms of their performance metrics: mIoU (mean Intersection over Union), OA (Overall Accuracy), and Acc (Accuracy). The ‘Input’ column indicates whether the method uses point clouds or other representations. The table highlights the performance of LinNet compared to state-of-the-art methods.
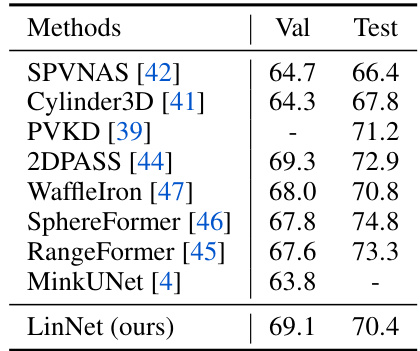
This table shows the performance of different semantic segmentation methods on the SemanticKITTI dataset. The table presents the validation and test mIoU scores for each method. The SemanticKITTI dataset is a challenging benchmark for evaluating the performance of 3D semantic segmentation models, particularly in outdoor environments.

This table presents the ablation study result on the normalization layer used in LinNet. Three different types of normalization layers were tested, including None (no normalization), Batch Normalization (BN), and Layer Normalization (LN). The results are presented in terms of mIoU (mean Intersection over Union), mAcc (mean Accuracy), and OA (Overall Accuracy). The table shows that BN achieves slightly better performance than both LN and no normalization.
Full paper#