↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Machine learning models often rely on spurious correlations, leading to poor performance on minority groups. This paper investigates the effects of finetuning and class balancing on worst-group accuracy (WGA), a key metric for assessing fairness. Existing class-balancing techniques like mini-batch upsampling and loss upweighting are shown to sometimes harm WGA, unexpectedly.
The researchers propose a novel mixture balancing method that combines the benefits of subsetting and upsampling to mitigate the shortcomings of existing methods. They also discover a previously unknown spectral imbalance in finetuning features, which contributes to group disparities. This comprehensive study highlights the nuanced interaction between model finetuning, class balancing, and group robustness, providing valuable insights for improving fairness in machine learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges common assumptions about model scaling and class balancing in finetuning, offering valuable insights into improving group robustness. It opens avenues for further research into spectral imbalance and its impact on fairness, and its findings will directly influence how researchers approach these techniques in various applications.
Visual Insights#
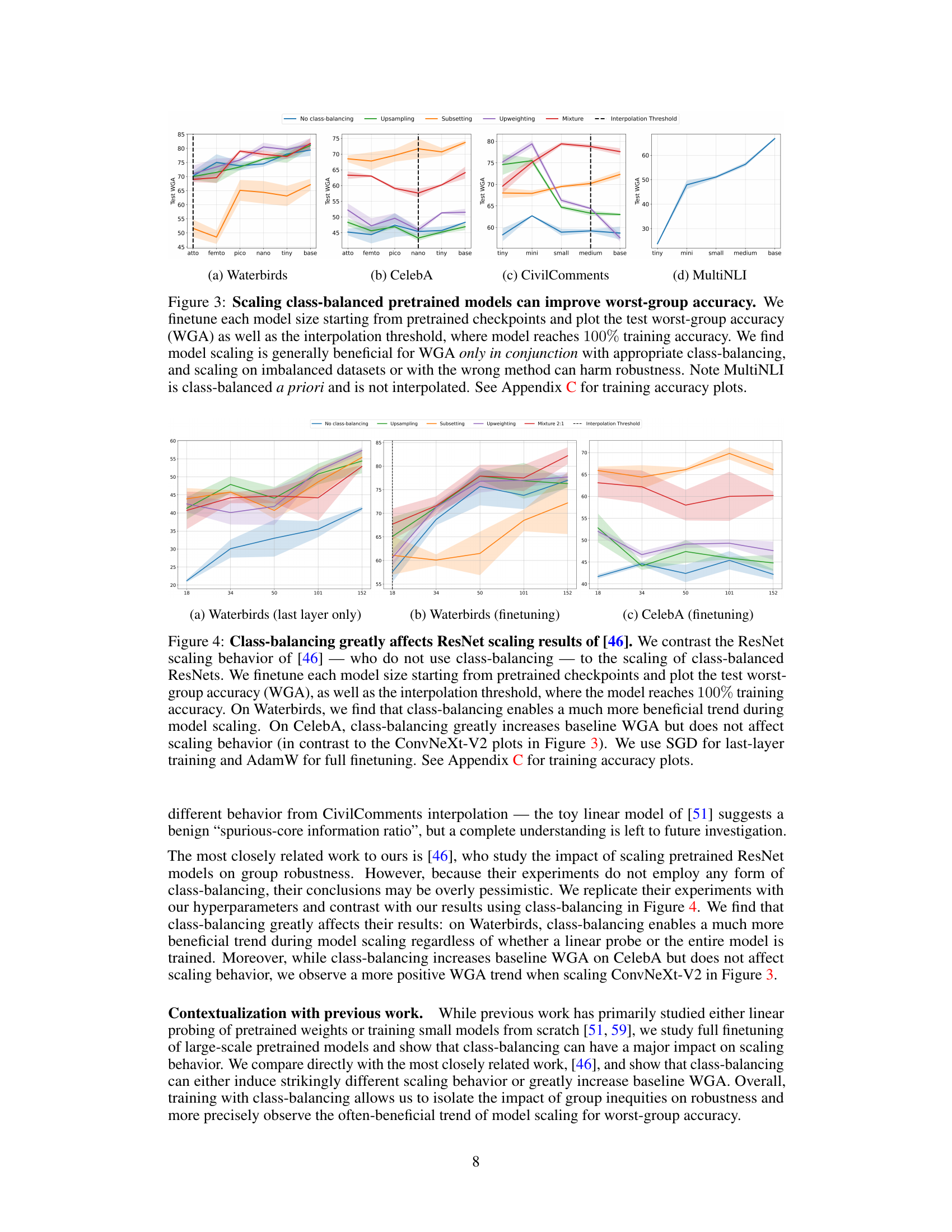
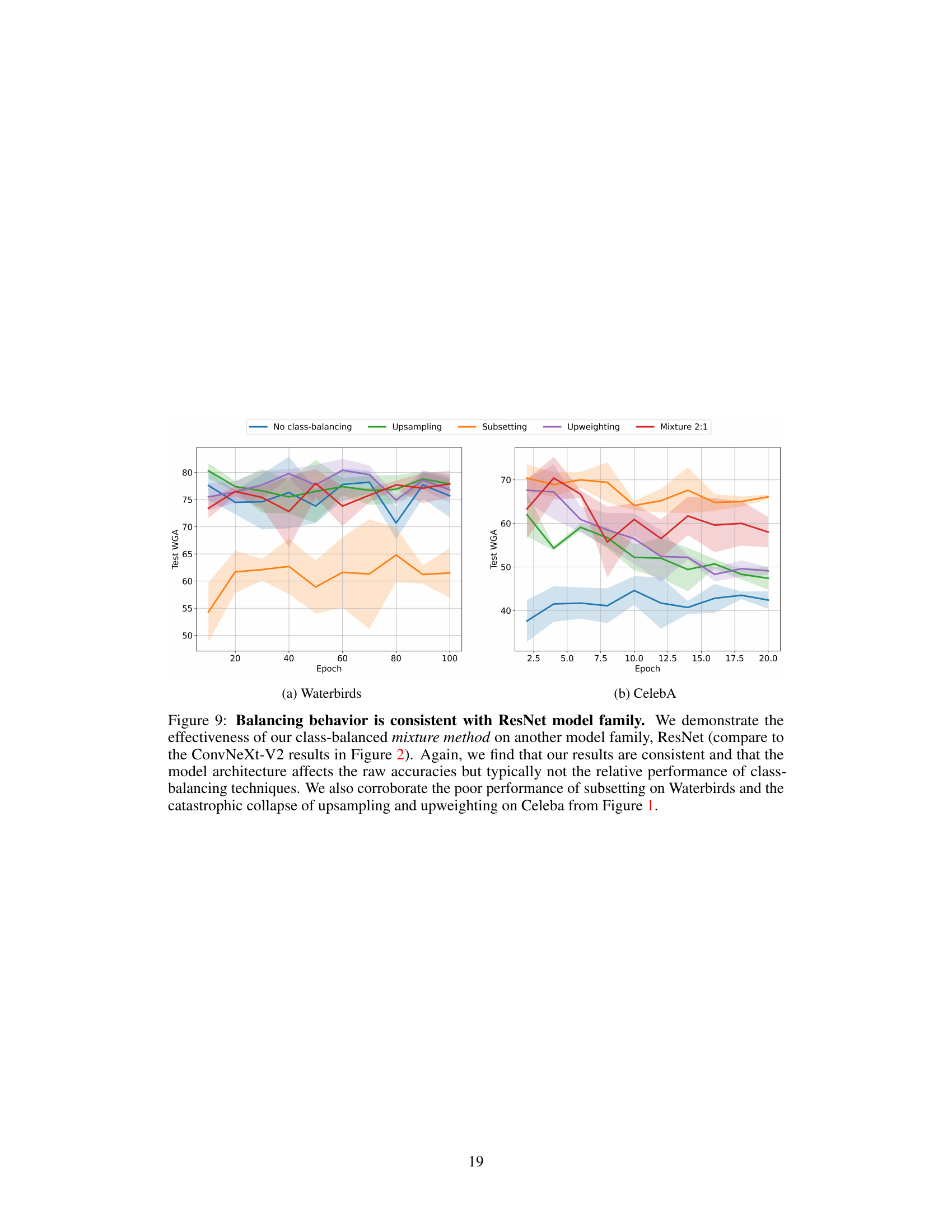
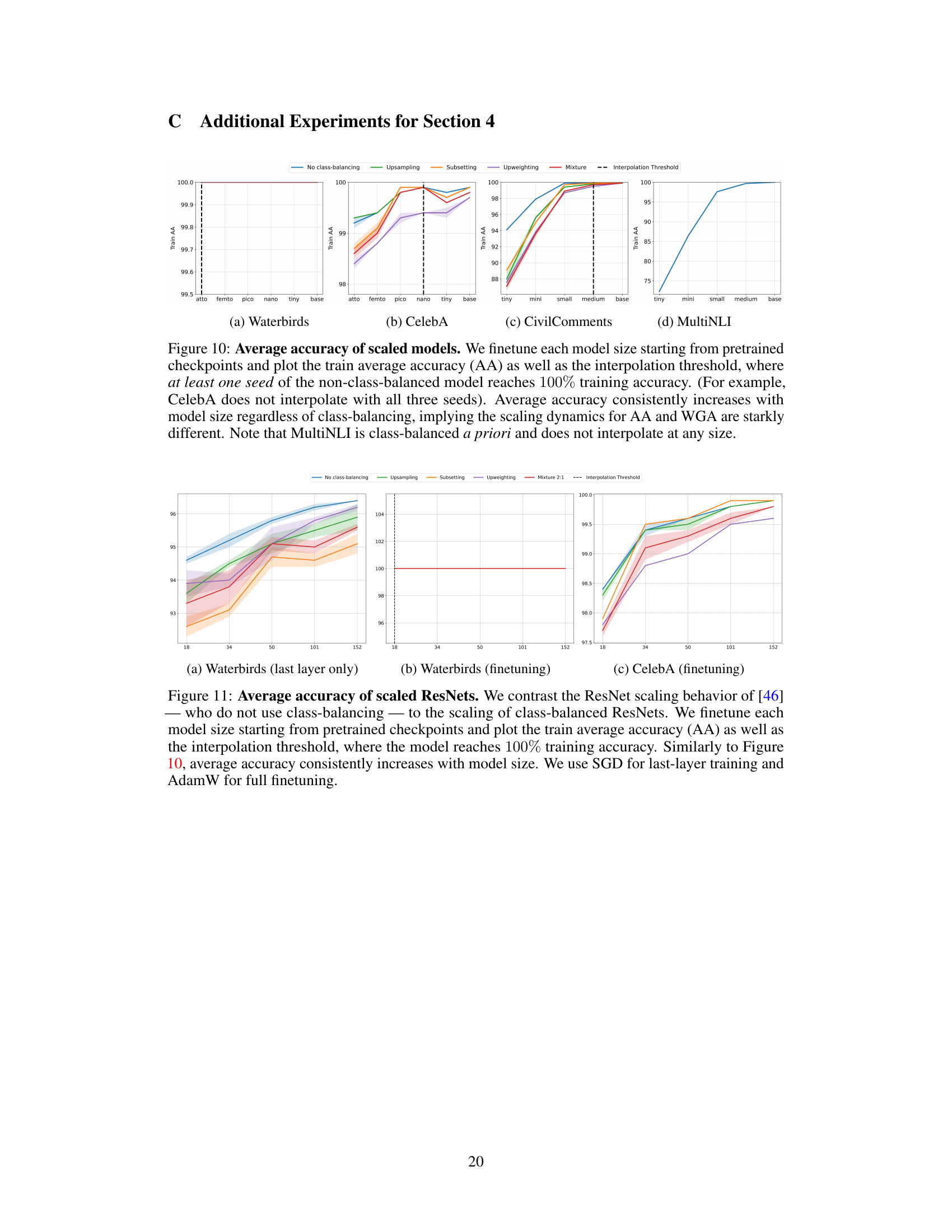
This figure compares three class-balancing techniques (subsetting, upsampling, and upweighting) against a no-class-balancing baseline across three datasets (Waterbirds, CelebA, and CivilComments). It shows that upsampling and upweighting lead to a catastrophic collapse in worst-group accuracy (WGA) over training epochs, especially on the more imbalanced datasets (CelebA and CivilComments). In contrast, subsetting reduces WGA on Waterbirds due to its removal of data from a small minority group, while MultiNLI, already class-balanced, shows no change.

This table compares the performance of different class balancing methods (upsampling, subsetting, mixture balancing) for model selection in the absence of group annotations. Three different metrics are used for model selection: bias-unsupervised score, worst-class accuracy, and worst-group accuracy. The table shows the best performing method according to each metric and its average worst-group accuracy across three independent seeds for Waterbirds, CelebA, and CivilComments datasets.
In-depth insights#
Spurious Correlation#
Spurious correlations, relationships that appear statistically significant but lack true causal connections, pose a significant challenge to machine learning models. These misleading correlations can lead models to over-rely on non-robust features for prediction, impacting performance, particularly on underrepresented groups. The paper explores the nuanced impact of spurious correlations on model finetuning, revealing surprising behaviors. Common class-balancing techniques like upsampling, while aiming to improve minority group performance, can paradoxically worsen it by causing overfitting. Model scaling also shows complex interaction with class-balancing, with the latter often being crucial for positive effects of scaling on worst-group accuracy. The detection and mitigation of spurious correlations are highlighted as crucial steps towards building truly robust and fair machine learning models. Identifying the spectral imbalance in group covariance matrices is proposed as a promising direction to diagnose and potentially address these issues.
Finetuning Dynamics#
The paper’s analysis of finetuning dynamics reveals crucial insights into how model scaling and class balancing interact to affect group robustness. Class-balancing techniques, while seemingly beneficial, can catastrophically harm worst-group accuracy (WGA) if not carefully implemented. The study highlights the surprising ineffectiveness of commonly used methods like mini-batch upsampling and loss upweighting, demonstrating a nuanced behavior. Overparameterization, contrary to some beliefs, does not automatically improve WGA, but rather interacts with class balancing in complex ways. The authors discover a spectral imbalance in finetuned features, where minority group covariance matrices exhibit larger spectral norms. This finding suggests that minority groups are disproportionately affected by the model’s reliance on spurious correlations, even with class balancing. A proposed mixture method combines subsetting and upsampling, mitigating the shortcomings of individual techniques and improving WGA.
Class Balancing woes#
The concept of ‘Class Balancing woes’ in machine learning highlights the challenges and unexpected outcomes associated with common class balancing techniques. Mini-batch upsampling and loss upweighting, often used to address class imbalance, can paradoxically reduce worst-group accuracy (WGA). This counterintuitive result stems from the methods’ potential to overfit to minority classes within already underrepresented groups. Data removal techniques, while effective in certain scenarios, are shown to negatively impact WGA if the data removed disproportionately affects minority groups within larger classes. The research emphasizes the importance of considering group structure and employing more sophisticated mixture methods, combining subsetting and upsampling, to mitigate these issues and achieve improved robustness and fairness.
Model Scaling Effects#
The paper investigates the effects of model scaling on worst-group accuracy (WGA) in the context of finetuned models. It challenges the common assumptions around overparameterization, demonstrating that scaling can improve WGA, but crucially, only when combined with proper class balancing. The findings reveal nuanced interactions between model size and group robustness, highlighting that simply increasing model capacity does not guarantee improved fairness. Instead, the study underscores the importance of considering the interplay between overparameterization and class balancing techniques to effectively mitigate the impact of spurious correlations on minority groups. The authors find that model scaling with appropriate class balancing methods is generally beneficial for WGA, even after the interpolation threshold. However, scaling without class balancing, or with the wrong balancing approach, can negatively impact WGA, emphasizing the need for a careful and holistic approach. This research contributes significant insights into optimizing for group robustness in the context of modern deep learning practices.
Spectral Imbalance#
The concept of spectral imbalance, explored in the context of group robustness, suggests that disparities in the eigenspectra of group covariance matrices might contribute to performance discrepancies across groups, even when class balance is achieved. The analysis reveals that minority groups often exhibit covariance matrices with larger spectral norms compared to majority groups within the same class. This finding underscores a more nuanced understanding of group fairness than previously assumed, suggesting that simply balancing class distributions may be insufficient to address underlying group disparities. Spectral imbalance highlights the importance of considering not only the distribution of data but also the structure of the feature space when aiming for robust and equitable model performance across all groups. Further investigation into the root causes and mitigation strategies of spectral imbalance is essential for improving fairness in machine learning models.
More visual insights#
More on figures

The figure displays the worst-group accuracy (WGA) over training epochs for three class-balancing techniques (subsetting, upsampling, upweighting) and a no-class-balancing baseline on three datasets (Waterbirds, CelebA, CivilComments). Upsampling and upweighting show a catastrophic collapse in WGA, especially on the more imbalanced datasets. Subsetting improves WGA on Waterbirds but not CelebA or CivilComments.
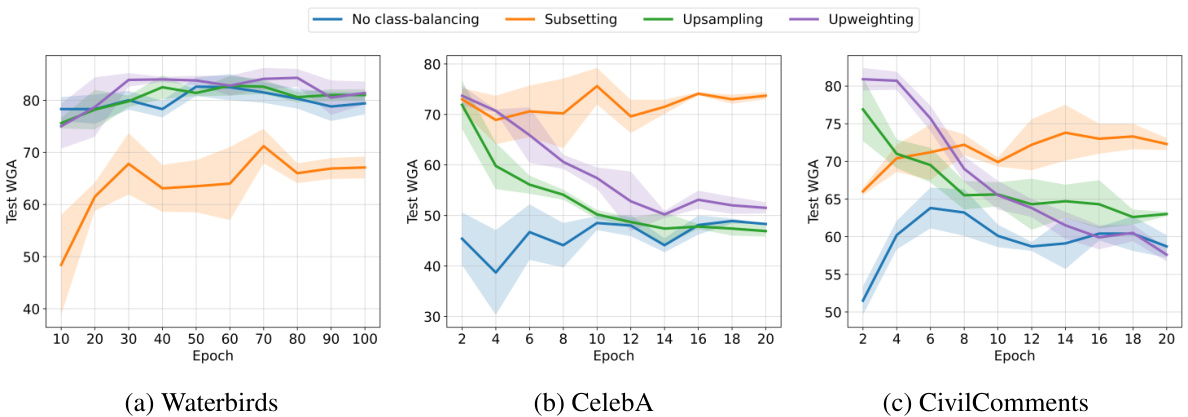
This figure shows the impact of model scaling on the worst-group accuracy (WGA) when finetuning pretrained models with different class-balancing techniques. It demonstrates that scaling improves WGA with appropriate class balancing but can be harmful with inappropriate techniques or imbalanced data. The results are shown for four different datasets.

This figure shows the impact of model scaling on worst-group accuracy (WGA) when finetuning pretrained models with different class-balancing techniques. Across four datasets, it demonstrates that scaling improves WGA only when combined with the appropriate class-balancing method. Scaling without proper balancing, or on imbalanced datasets, can negatively affect WGA. The MultiNLI dataset, being pre-balanced, shows a different trend.

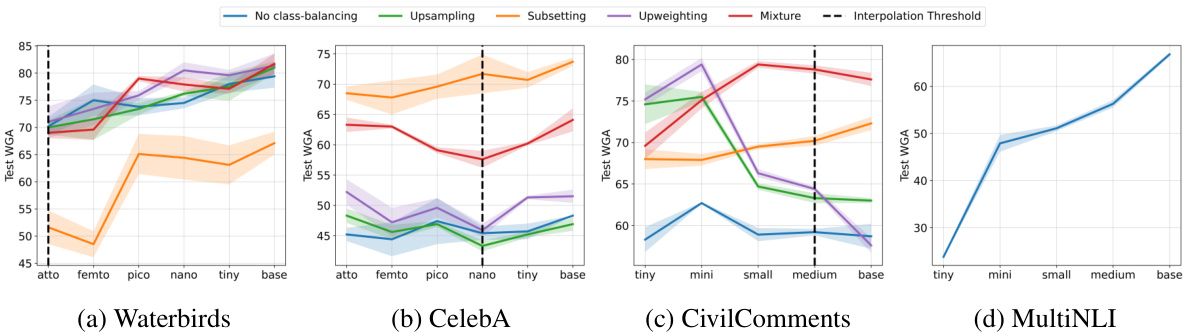
This figure visualizes the top 10 eigenvalues of group covariance matrices for four datasets (Waterbirds, CelebA, CivilComments, MultiNLI) after finetuning with the best class balancing method. It highlights that the largest eigenvalue for each dataset belongs to a minority group, and that minority groups generally have larger eigenvalues than majority groups within the same class. This suggests a spectral imbalance that may contribute to group disparities in model performance.
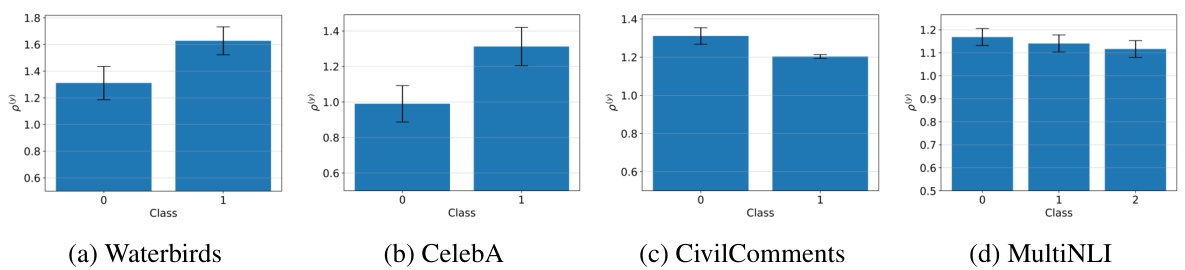
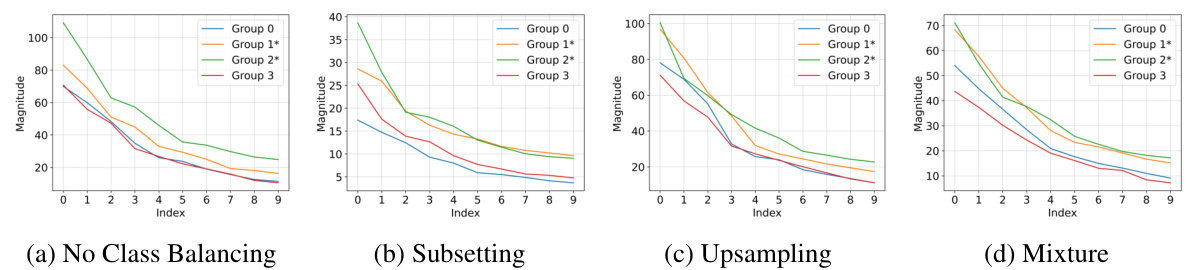
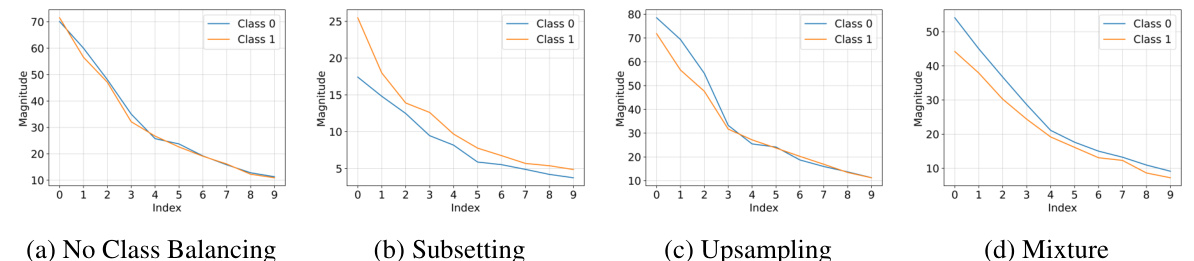
This figure shows that even when classes are balanced, there is still a spectral imbalance between minority and majority groups within each class. The intra-class spectral norm ratio (p(y)) is calculated as the ratio of the top eigenvalue of the minority group’s covariance matrix to that of the majority group’s covariance matrix, within each class. The results show that p(y) is greater than or equal to 1 for almost all classes across all datasets, indicating that minority groups tend to have larger spectral norms than majority groups within the same class.

This figure shows ablation studies on the mixture balancing method. The first study varies the class-imbalance ratio, showing the impact of using a balanced subset (subsetting) vs. not using a subset (upsampling). The second study compares the full mixture balancing method to a version without the initial subsetting step. The results demonstrate that the mixture method outperforms other techniques, particularly on class-imbalanced datasets.

The figure shows the test worst-group accuracy (WGA) over training epochs for three different class-balancing techniques: subsetting, upsampling, and upweighting, compared to the no class-balancing baseline. The results are shown for three datasets: Waterbirds, CelebA, and CivilComments. Upsampling and upweighting show a catastrophic collapse in WGA on CelebA and CivilComments, while subsetting reduces WGA on Waterbirds due to the dataset’s specific group structure. MultiNLI, being already class-balanced, is not included.
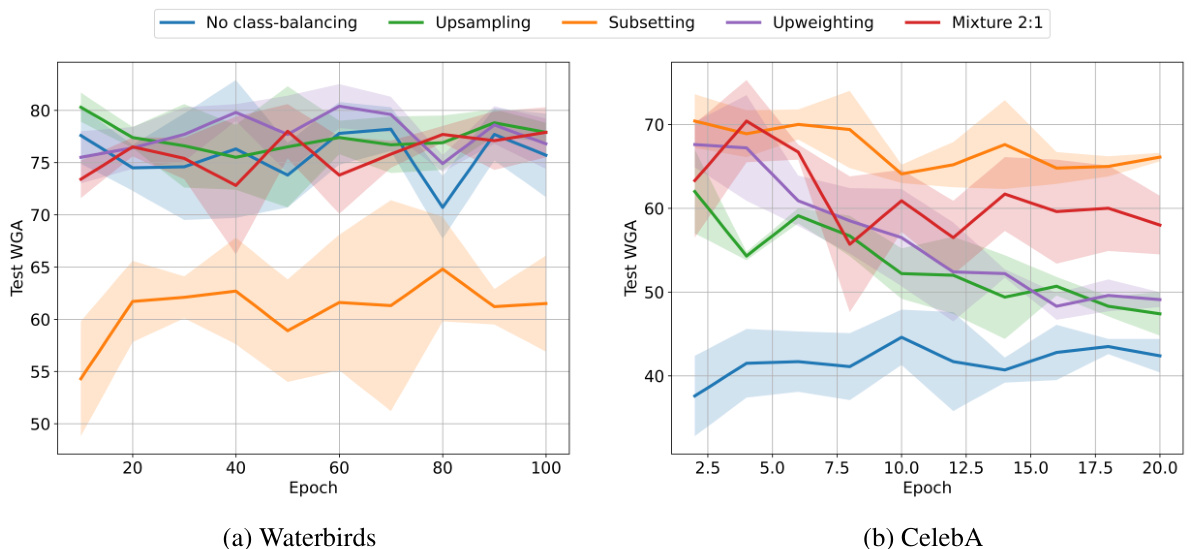
The figure shows the test worst-group accuracy (WGA) over training epochs for three different class-balancing techniques: subsetting, upsampling, and upweighting, compared to the baseline without class balancing. The results are shown for three datasets: Waterbirds, CelebA, and CivilComments. The figure demonstrates that upsampling and upweighting can lead to a significant decrease in WGA as training progresses, a phenomenon called ‘catastrophic collapse’. Subsetting has varied effects depending on the dataset’s group structure. MultiNLI is excluded because it’s already class-balanced.

This figure shows the effect of model scaling on worst-group accuracy (WGA) for four datasets (Waterbirds, CelebA, CivilComments, MultiNLI) using different class-balancing techniques. It demonstrates that scaling pretrained models improves WGA but only when combined with appropriate class balancing. Scaling without proper class balancing or on already imbalanced datasets can negatively impact WGA. The interpolation threshold is also shown, indicating when models reach 100% training accuracy.

This figure shows the impact of model scaling on worst-group accuracy (WGA) for four different datasets (Waterbirds, CelebA, CivilComments, and MultiNLI) with different class-balancing techniques. It demonstrates that scaling pretrained models improves WGA but only when combined with appropriate class balancing. Scaling with inappropriate techniques or imbalanced data can harm robustness. MultiNLI is unique because it’s already class-balanced.

This figure displays the results of an experiment on the impact of model scaling on worst-group accuracy (WGA) when finetuning pretrained models. The experiments were performed on four datasets with varying class-balancing techniques. The results show that model scaling improves WGA only when used with appropriate class balancing, and that scaling on imbalanced datasets can even be harmful to WGA.

The figure visualizes the top 10 eigenvalues of group covariance matrices for four datasets (Waterbirds, CelebA, CivilComments, MultiNLI) after finetuning with the best class-balancing method. It highlights that the largest eigenvalue often belongs to a minority group, and minority groups generally have larger eigenvalues than majority groups within the same class, suggesting a spectral imbalance that might contribute to group disparities.

This figure visualizes the top 10 eigenvalues of group covariance matrices for four datasets (Waterbirds, CelebA, CivilComments, MultiNLI) after fine-tuning with the best class balancing methods. It highlights that minority groups tend to have larger eigenvalues than majority groups within the same class, suggesting a spectral imbalance that could contribute to group disparities. Note that the largest eigenvalue isn’t always from the worst-performing group.
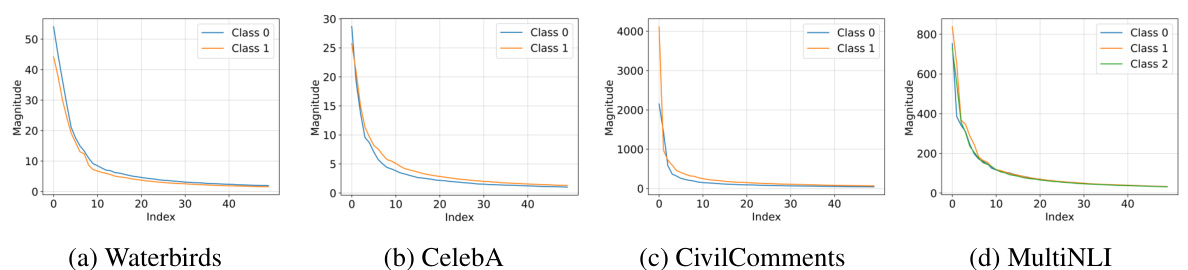
This figure visualizes the top 10 eigenvalues of group covariance matrices for four datasets (Waterbirds, CelebA, CivilComments, MultiNLI) after finetuning with the best class-balancing method. It shows that minority groups tend to have larger top eigenvalues than majority groups within the same class, indicating a potential spectral imbalance that might contribute to group disparities in model performance.
This figure visualizes the top 10 eigenvalues of group covariance matrices for four datasets (Waterbirds, CelebA, CivilComments, MultiNLI) after finetuning with different class-balancing methods. It shows that minority groups tend to have larger top eigenvalues compared to majority groups within the same class, even after class balancing, suggesting a potential source of group disparities.
The figure displays the test worst-group accuracy (WGA) over training epochs for three class-balancing techniques (subsetting, upsampling, upweighting) and a no class-balancing baseline on three datasets (Waterbirds, CelebA, CivilComments). Upsampling and upweighting show a catastrophic collapse in WGA on CelebA and CivilComments, whereas subsetting reduces WGA on Waterbirds due to its removal of data from a minority group in the majority class. MultiNLI is excluded as it’s already class balanced.

This figure shows the intra-class spectral norm ratio (p(y)) for each class in four different datasets. The p(y) metric is the ratio of the largest eigenvalue of the minority group’s covariance matrix to that of the majority group’s covariance matrix, within each class. The results demonstrate that, even when classes are balanced, a spectral imbalance exists, where minority groups consistently exhibit larger spectral norms than majority groups within the same class. This suggests a potential link between spectral imbalance and group disparities.
More on tables

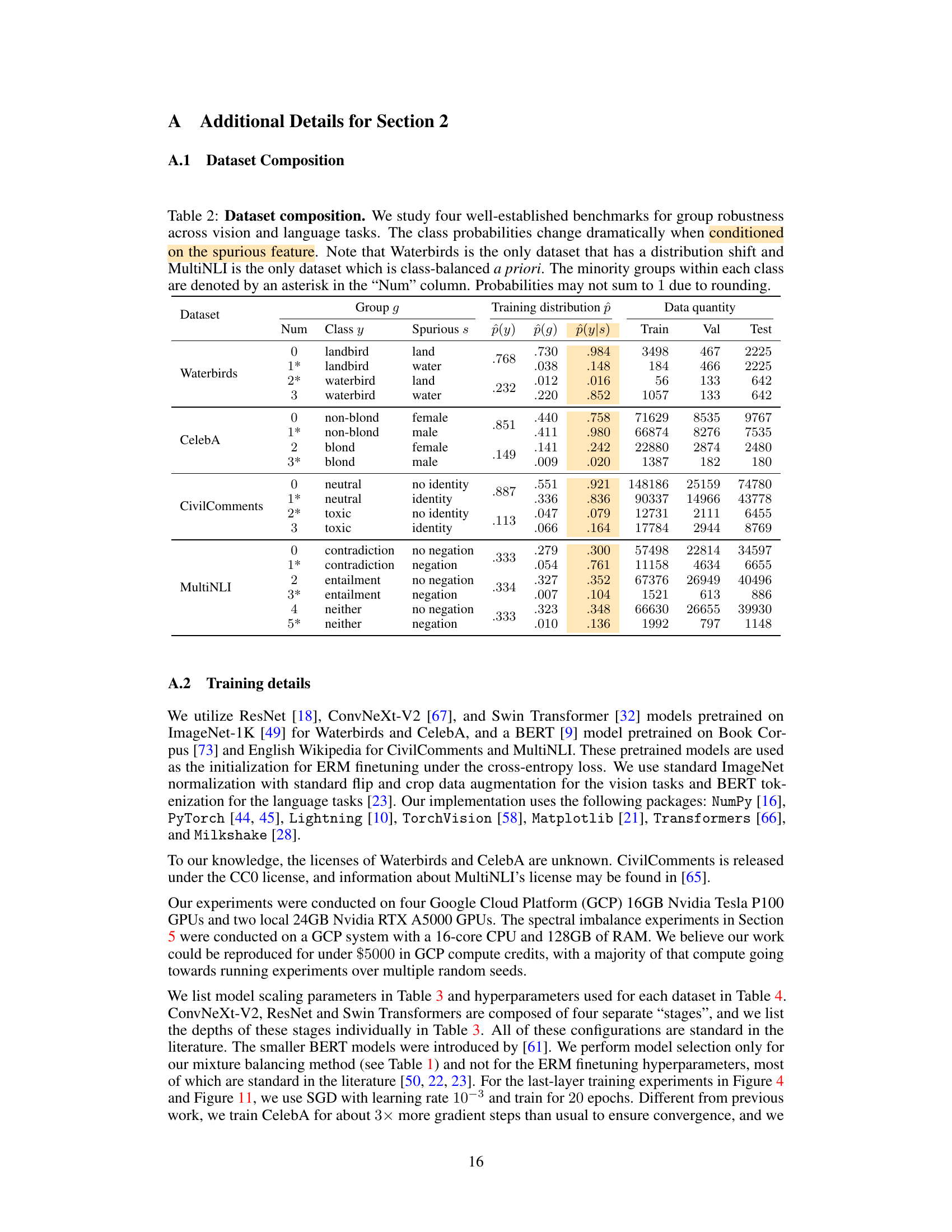
This table presents the details of four datasets used in the paper to evaluate group robustness in machine learning models. For each dataset, it lists the class labels, spurious features, and the proportions of each group in the training, validation, and test sets. The table also indicates which groups are considered minority groups within each class. This information is crucial for understanding the experimental setup and the challenges involved in evaluating group robustness.
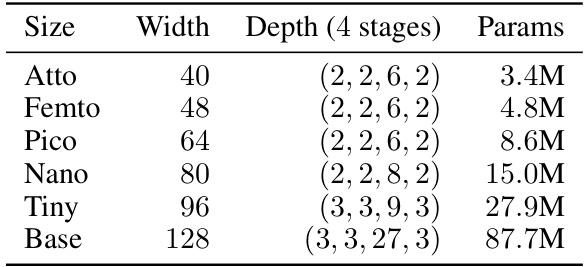
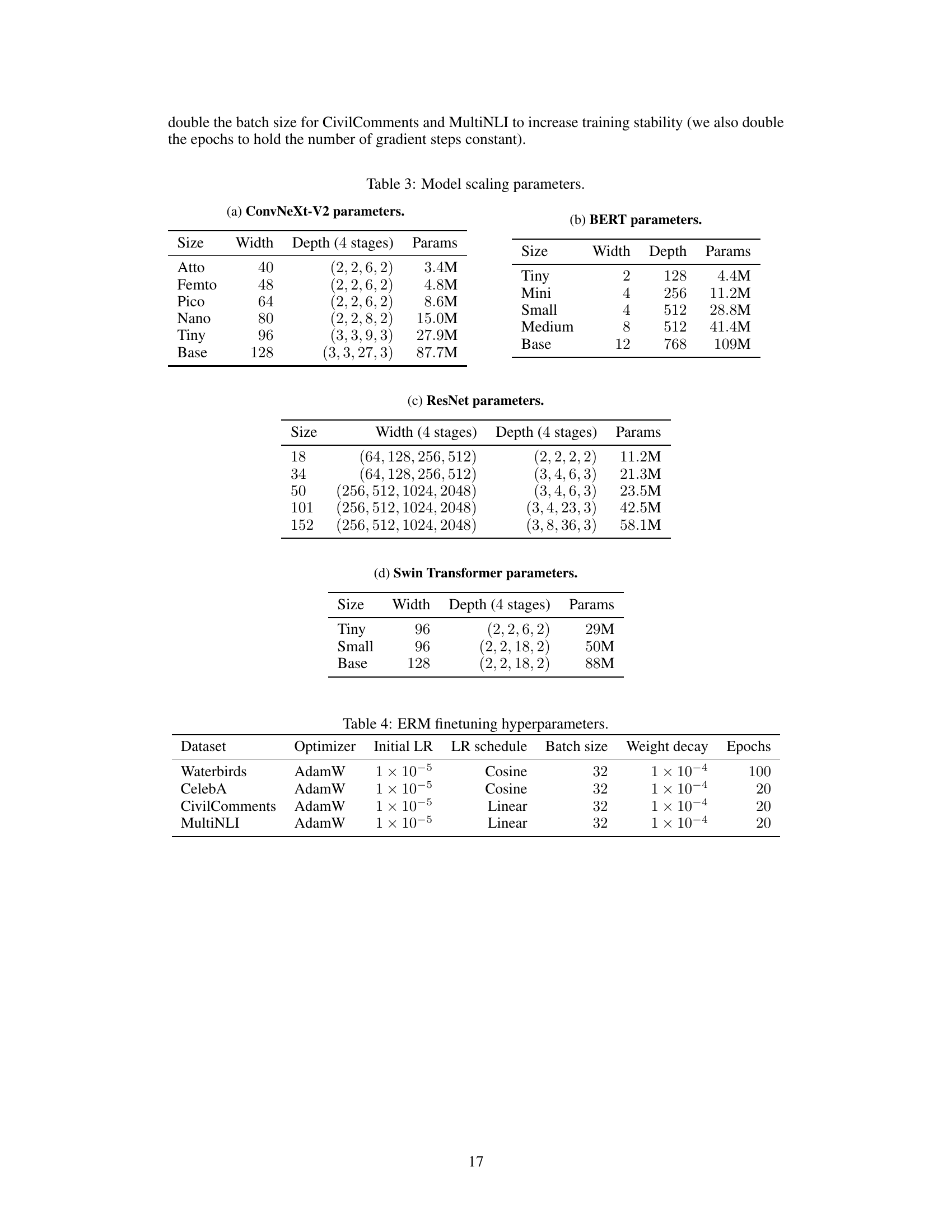
This table presents the details of four datasets used in the paper to evaluate the group robustness of machine learning models. Each dataset is described by its name, the number of groups, the class and spurious features used to define those groups, the size of the training, validation, and test sets, and the proportion of each group in the training set. The table helps to understand the characteristics of each dataset, particularly the class and group imbalances which present challenges for finetuning models.
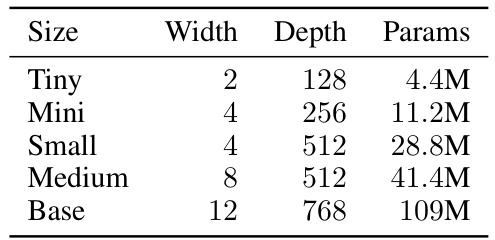
This table details the composition of the four datasets used in the paper’s experiments. For each dataset, it provides information on the number of training, validation, and testing samples, as well as the class and spurious feature distributions within those samples. This information is crucial for understanding the experimental setup and the challenges faced in addressing group robustness.
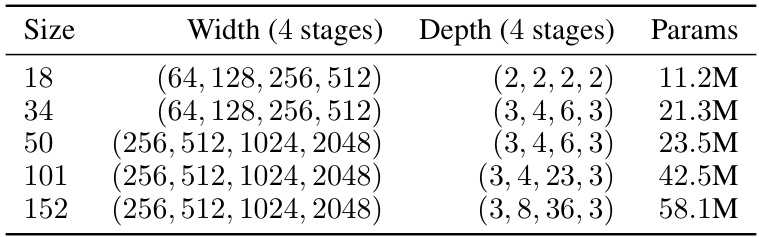
This table details the four datasets used in the paper’s experiments: Waterbirds, CelebA, CivilComments, and MultiNLI. For each dataset, it lists the number of classes, the spurious features, and the number of training, validation, and test examples for each class and spurious feature combination. It also provides the proportion of each group within the training data. Note that the Waterbirds dataset has a distribution shift between the training and test sets, and the MultiNLI dataset is class-balanced.

This table details the composition of the four datasets used in the paper’s experiments. It shows the number of training, validation, and test examples for each group within each dataset. Groups are defined by the combination of class and spurious feature. The table also highlights which datasets are class-imbalanced and which dataset has a distribution shift (Waterbirds). Minority groups within each class are marked with an asterisk.

This table presents the details of the four datasets used in the paper’s experiments. For each dataset, it shows the class labels, spurious features, group IDs, and the number of training, validation, and test samples in each group. It also indicates the class-imbalance ratio and highlights the minority groups within each class. The table clarifies the composition and characteristics of the datasets, which are crucial for understanding the experimental results.

This table shows the correspondence between the intra-class spectral norm ratio (p(y)) and the difference in intra-class group accuracy for each seed across four datasets. The intra-class spectral norm ratio is a metric showing spectral imbalance, while the accuracy difference reflects the group disparity. The correspondence between these two metrics suggests that spectral imbalance may be a factor contributing to group disparities in accuracy.
Full paper#