TL;DR#
Current transformer models heavily rely on pairwise dot-product self-attention, which uses Euclidean distance to compute attention weights. This approach suffers from representation collapse, where the model focuses on a limited subset of informative features, and vulnerability to noisy data. The Euclidean distance is also not optimal because it lacks direction awareness for coordinate significance.
To address these issues, the paper proposes Elliptical Attention, a novel self-attention mechanism that employs a Mahalanobis distance metric. This allows for more contextually relevant attention by stretching the underlying feature space in directions of high contextual relevance, effectively creating hyper-ellipsoidal neighborhoods around queries. The authors demonstrate the advantages of their approach through empirical evaluation on various practical tasks, including object classification, image segmentation, and language modeling.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on attention mechanisms and transformers because it introduces a novel approach to improve their robustness and mitigate representation collapse. Elliptical Attention offers a theoretical framework and empirical validation, paving the way for more reliable and efficient transformer models. It directly addresses limitations of existing self-attention methods, impacting various applications across diverse data modalities. The provided code also facilitates broader adoption and further research.
Visual Insights#

🔼 The figure shows a comparison of attention heatmaps for DeiT and DeiT-Elliptical models on two example images. DeiT focuses its attention on a small subset of features, while DeiT-Elliptical distributes attention more broadly across contextually relevant features. The color intensity represents the attention weight, with brighter colors indicating higher weights. This visual comparison illustrates the key advantage of Elliptical Attention: improved robustness and accuracy by considering a wider context.
read the caption
Figure 1: Comparison of Attention Heatmaps. Elliptical pays attention to more relevant information. DeiT focuses on just a subset of informative features while Elliptical considers a wider set of contextually relevant information, helping to produce more accurate and robust predictions. Attention scores are min-max scaled for visualization purposes.

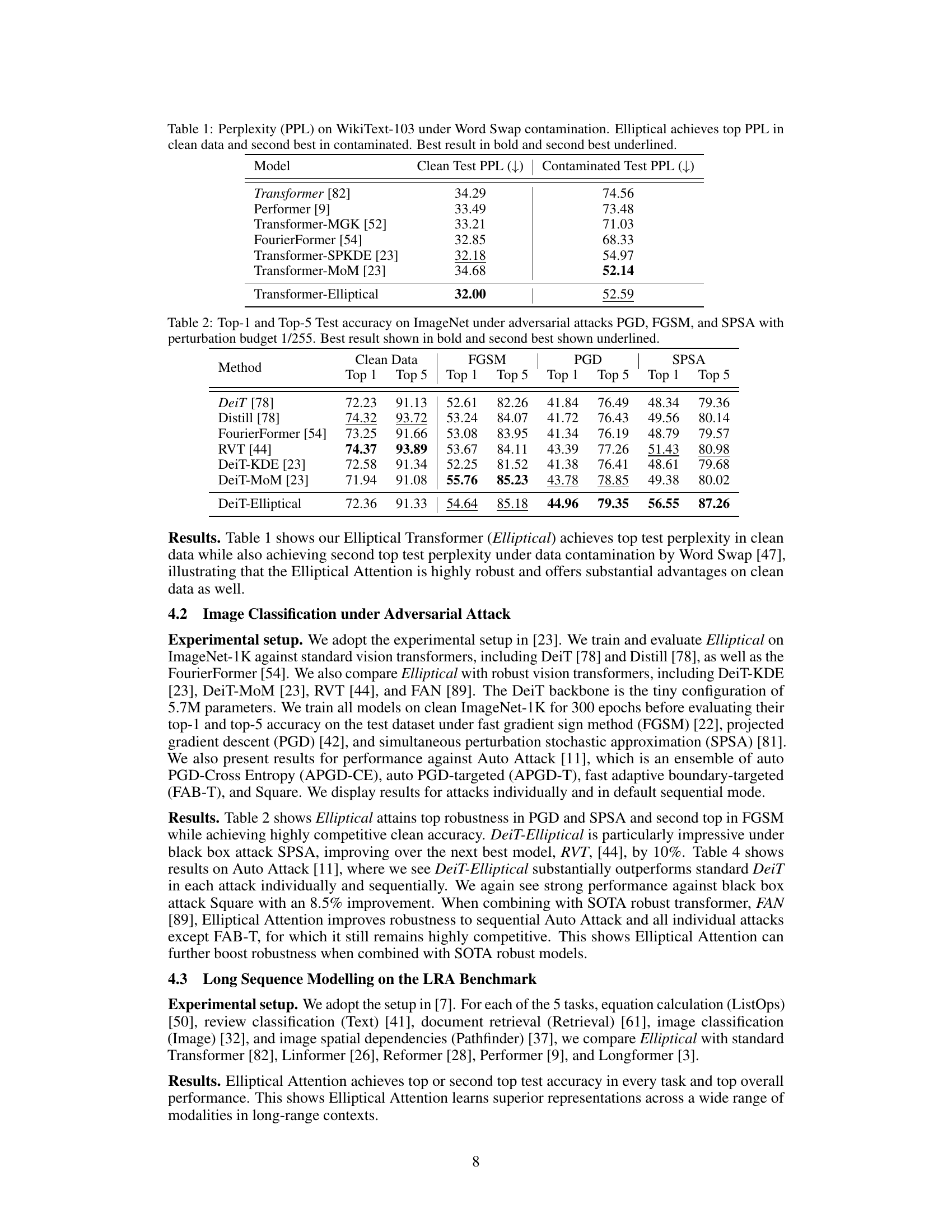
🔼 This table presents the results of the WikiText-103 language modeling experiment under word swap attack. It compares the perplexity (PPL) scores of different transformer models, including the proposed Elliptical Attention model, on both clean and contaminated test sets. Lower perplexity indicates better performance.
read the caption
Table 1: Perplexity (PPL) on WikiText-103 under Word Swap contamination. Elliptical achieves top PPL in clean data and second best in contaminated. Best result in bold and second best underlined.
In-depth insights#
Elliptical Attention#
The proposed “Elliptical Attention” mechanism offers a novel approach to self-attention by employing a Mahalanobis distance metric instead of the standard Euclidean distance. This modification allows the model to focus on contextually relevant information by stretching the feature space in directions of high importance, effectively creating hyper-ellipsoidal neighborhoods around query tokens. This addresses the limitations of Euclidean distance-based attention, which is prone to representation collapse and vulnerability to noisy data. By weighting tokens based on their Mahalanobis distance from the query, Elliptical Attention enhances robustness and reduces sensitivity to outliers. Empirical evaluations across diverse tasks including object classification, image segmentation, and language modeling demonstrate its effectiveness, showing improvements over both standard self-attention and other state-of-the-art attention mechanisms. The theoretical analysis further supports these findings, linking hyper-ellipsoidal neighborhoods to reduced estimator variance and enhanced robustness in non-parametric regression models. Overall, Elliptical Attention presents a promising alternative, offering improved performance and robustness with minimal computational overhead.
Hyper-Ellipsoidal NW#
The concept of “Hyper-Ellipsoidal NW” likely refers to an extension of the Nadaraya-Watson (NW) kernel regression method, a non-parametric technique used in various fields including machine learning. Standard NW uses spherical kernels, assigning weights based on Euclidean distance. Hyper-ellipsoidal NW modifies this by employing ellipsoidal kernels, stretching the feature space along directions of higher contextual relevance, thereby weighting keys based on Mahalanobis distance rather than Euclidean distance. This change addresses the limitations of the standard NW approach, specifically its vulnerability to representation collapse and contaminated samples. By focusing attention on contextually relevant information, hyper-ellipsoidal NW enhances the model’s robustness and prevents an over-reliance on a small subset of informative features. The effectiveness of this approach likely rests on the ability to effectively learn the orientation and shape of the hyper-ellipsoid, a crucial aspect for optimal performance.
Robustness & Collapse#
The concepts of robustness and collapse are central to evaluating the performance and reliability of machine learning models, especially deep learning models. Robustness refers to a model’s ability to maintain accuracy and generalization capabilities even when exposed to noisy, incomplete, or adversarial data. A robust model is resilient to perturbations and unexpected inputs, performing consistently across various conditions. In contrast, collapse signifies a failure of the model’s representational capacity. This often occurs when the model fails to learn diverse and meaningful features, resulting in oversimplified representations that are overly sensitive to small changes in input data, thus lacking generalizability and potentially leading to unpredictable behavior. The tension between these two concepts is critical: a highly robust model might still exhibit some level of collapse, and conversely, a model designed to avoid collapse might not exhibit sufficient robustness in real-world applications. Therefore, analyzing and mitigating representation collapse are crucial steps to enhance model robustness and reliability.
Efficient Estimator#
The paper introduces an efficient estimator for coordinate-wise variability, a crucial component in their novel Elliptical Attention mechanism. This estimator is parameter-free, meaning it doesn’t require training or learning, significantly improving computational efficiency. Its design cleverly leverages the L1 norm of differences between neighboring layer feature vectors to approximate the variability, offering a computationally inexpensive yet effective solution. The authors provide theoretical justification for the estimator’s accuracy, showing that under certain conditions, the estimator reliably captures the relative coordinate-wise variability. This efficiency is particularly important in the context of large-scale transformer models, where the computational cost of attention mechanisms can be significant. The simplicity and theoretical grounding of this estimator make it a practical and valuable contribution, highlighting the paper’s focus on both theoretical rigor and efficient practical implementation.
Future Work#
The paper’s “Future Work” section presents exciting avenues for enhancing Elliptical Attention. Improving the coordinate-wise variability estimator is crucial, as the current method relies on noisy layer-wise estimations. Exploring theoretically grounded, more precise estimators with provable convergence guarantees, while maintaining efficiency, is key. This would solidify the theoretical foundation and likely boost performance further. Investigating the impact of hyper-ellipsoid geometry on different data modalities and task types offers opportunities to generalize the approach. Combining Elliptical Attention with other robust transformer techniques should also yield substantial improvements in robustness. Finally, extending the framework to other attention mechanisms beyond pairwise dot-product self-attention would broaden its applicability and demonstrate its underlying principles more broadly.
More visual insights#
More on figures

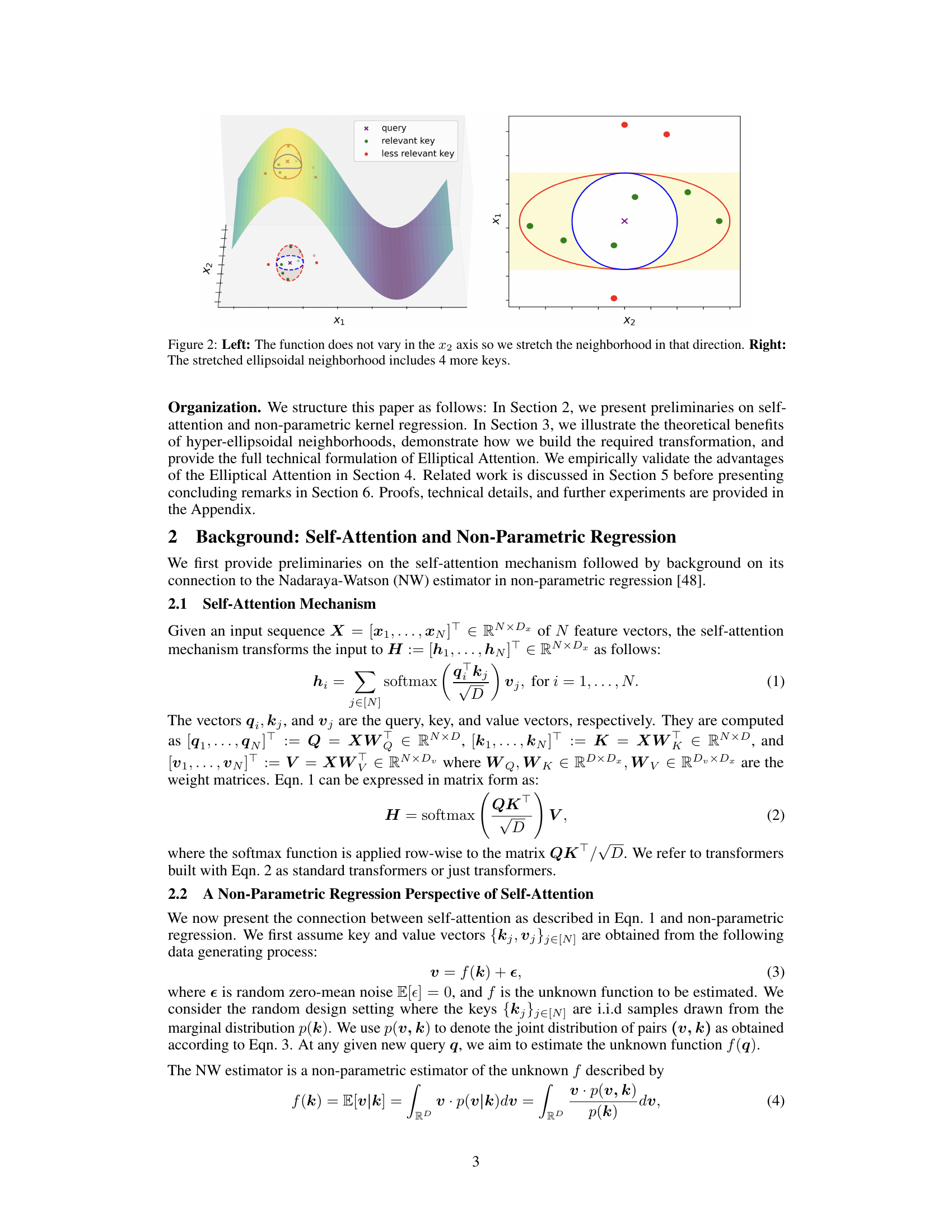
🔼 This figure illustrates the concept of hyper-ellipsoidal neighborhoods in the context of non-parametric regression, a perspective used to explain the self-attention mechanism. The left panel shows a 2D function that doesn’t vary along the x2-axis. A circular neighborhood (representing standard self-attention) around a query point only includes keys close in Euclidean distance, regardless of direction, missing potentially relevant keys. The right panel demonstrates that stretching the neighborhood into an ellipse along the x2-axis (the direction of low variability) incorporates additional relevant keys into the neighborhood, improving the accuracy of the regression estimate.
read the caption
Figure 2: Left: The function does not vary in the x2 axis so we stretch the neighborhood in that direction. Right: The stretched ellipsoidal neighborhood includes 4 more keys.
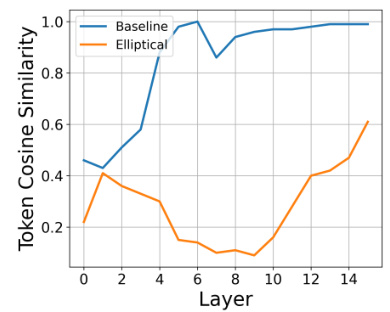
🔼 This figure shows a comparison of token cosine similarity over layers for baseline and elliptical attention on the WikiText-103 dataset. The baseline shows increasing similarity, indicating representation collapse, while elliptical attention maintains more diverse representations across layers.
read the caption
Figure 3: Representation Collapse on WikiText-103. Elliptical Attention learns more diverse representations.
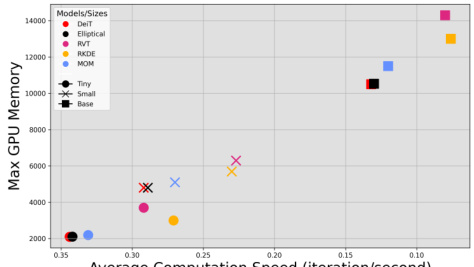
🔼 This figure compares the efficiency of different models (DeiT, Elliptical, RVT, RKDE, MoM) across various sizes (Tiny, Small, Base) in terms of average computation speed and maximum GPU memory usage. It demonstrates that Elliptical Attention achieves high robustness while being the most efficient model among those compared.
read the caption
Figure 4: ImageNet Efficiency: Comparison of throughput and max memory allocated for DeiT, Elliptical, RVT, RKDE, MoM on Tiny, Small, and Base sizes. Elliptical is the most efficient robust model.
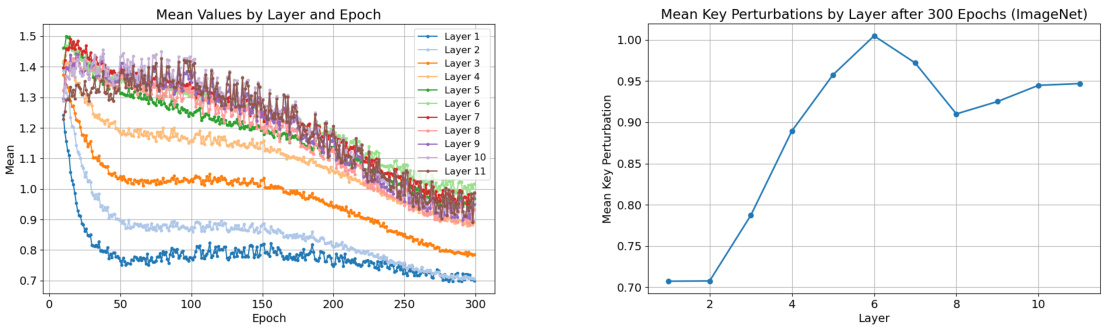
🔼 The left plot shows the evolution of mean values of key perturbations over successive layers during the training process on ImageNet dataset. The right plot shows the mean key perturbation at different layers after 300 training epochs. Both plots show that as the number of layers increases, the mean key perturbation values stabilize around a constant value, indicating the model’s robustness.
read the caption
Figure 5: Left: Evolution of mean values of key perturbations over successive layers. Right: Mean key perturbations at different layers after 300 epochs. The figures show that as the number of layers increases, mean key perturbations over layers stabilize around a constant value.

🔼 This figure compares the token cosine similarity over layers for both the baseline transformer and the proposed Elliptical Attention model across three different tasks: ADE20K image segmentation, WikiText-103 language modeling, and ImageNet image recognition. It visually demonstrates that Elliptical Attention effectively reduces representation collapse by decreasing the similarity of token representations as the number of layers increases, thereby enhancing the model’s ability to learn diverse and informative features across various data modalities. Lower cosine similarity indicates more diverse feature representations.
read the caption
Figure 6: Additional Representation Collapse Results on ADE20K, WikiText-103 and ImageNet. Elliptical reduces token similarity over layers across a range of modalities

🔼 The figure compares the attention heatmaps of two models, DeiT and DeiT-Elliptical, on an image classification task. DeiT, a standard transformer-based model, focuses its attention on a small subset of features. DeiT-Elliptical, employing the proposed Elliptical Attention, distributes its attention more broadly across contextually relevant features. This broader attention results in more accurate and robust predictions by the DeiT-Elliptical model.
read the caption
Figure 1: Comparison of Attention Heatmaps. Elliptical pays attention to more relevant information. DeiT focuses on just a subset of informative features while Elliptical considers a wider set of contextually relevant information, helping to produce more accurate and robust predictions. Attention scores are min-max scaled for visualization purposes.
More on tables
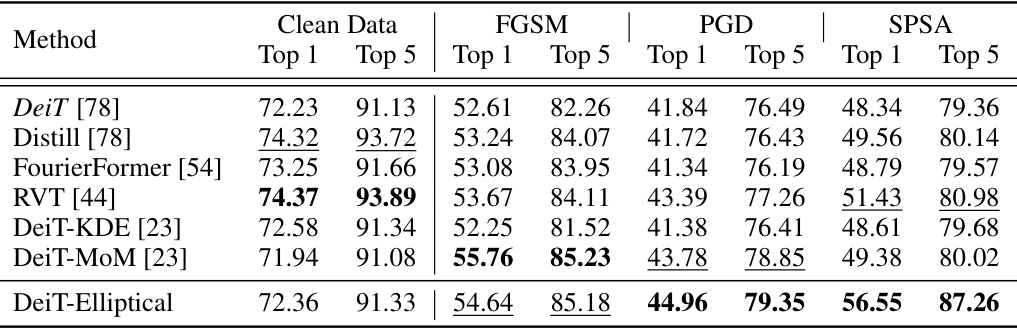
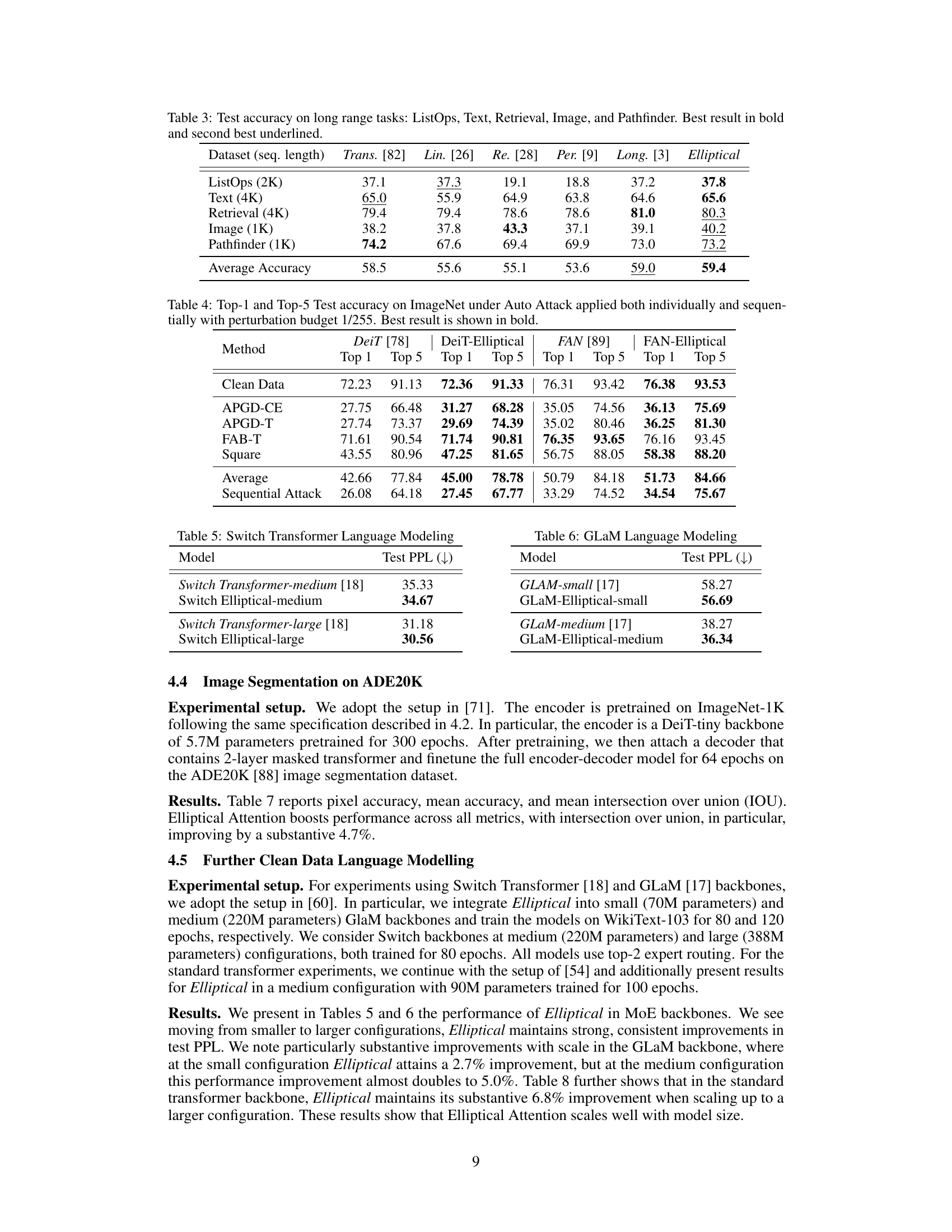
🔼 This table presents the top-1 and top-5 test accuracy results on the ImageNet dataset under three different adversarial attacks (PGD, FGSM, and SPSA) with a perturbation budget of 1/255. It compares the performance of the Elliptical Attention method against several other state-of-the-art methods (DeiT, Distill, FourierFormer, RVT, DeiT-KDE, DeiT-MoM). The best accuracy for each attack and metric is highlighted in bold, and the second-best is underlined. The results demonstrate the robustness of the Elliptical Attention method in handling adversarial attacks.
read the caption
Table 2: Top-1 and Top-5 Test accuracy on ImageNet under adversarial attacks PGD, FGSM, and SPSA with perturbation budget 1/255. Best result shown in bold and second best shown underlined.

🔼 This table presents the test accuracy results of different transformer models on five long-range tasks: ListOps, Text, Retrieval, Image, and Pathfinder. The sequence lengths for these tasks vary. The models compared are the standard Transformer, Linformer, Reformer, Performer, Longformer, and the proposed Elliptical Attention model. The best and second-best performing models for each task are highlighted in bold and underlined, respectively. The final row shows the average accuracy across all five tasks. This provides a comparison of the model’s performance on a variety of long-range sequence tasks, showcasing Elliptical Attention’s competitive performance in terms of accuracy.
read the caption
Table 3: Test accuracy on long range tasks: ListOps, Text, Retrieval, Image, and Pathfinder. Best result in bold and second best underlined.
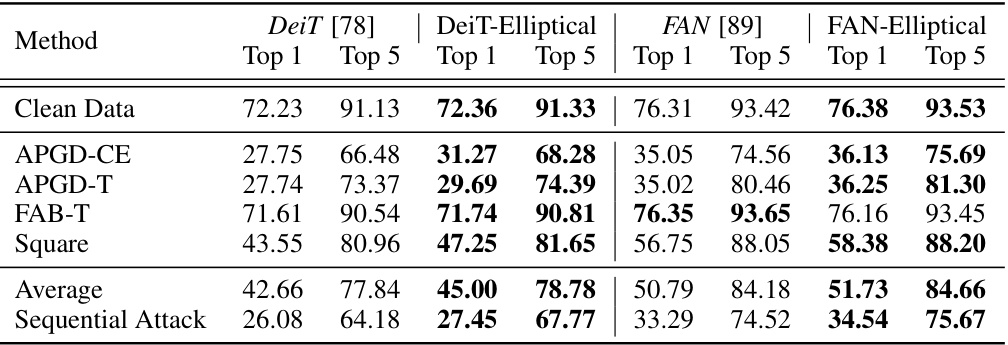
🔼 This table presents the results of an ImageNet classification experiment under various adversarial attacks (PGD, FGSM, and SPSA). It compares the top-1 and top-5 accuracies of different models, including the proposed Elliptical Attention model, against standard DeiT and robust vision transformer models. The best and second-best accuracies are highlighted.
read the caption
Table 4: Top-1 and Top-5 Test accuracy on ImageNet under adversarial attacks PGD, FGSM, and SPSA with perturbation budget 1/255. Best result shown in bold and second best shown underlined.

🔼 This table shows the results of the WikiText-103 language modeling experiment under Word Swap attack. The performance is measured by perplexity (PPL), a lower score indicating better performance. The table compares the performance of the proposed Elliptical Attention method against several baseline transformer models, both in a clean setting and under the Word Swap data contamination. Elliptical achieves the best perplexity on clean data and is second best on contaminated data, indicating robustness.
read the caption
Table 1: Perplexity (PPL) on WikiText-103 under Word Swap contamination. Elliptical achieves top PPL in clean data and second best in contaminated. Best result in bold and second best underlined.

🔼 This table presents the test perplexity results for the GLaM language model with and without the proposed Elliptical Attention mechanism. Two different sizes of the GLaM model are evaluated: small and medium. Lower perplexity indicates better performance.
read the caption
Table 15: Test Perplexity of Elliptical GLaM on WikiText-103 Modeling
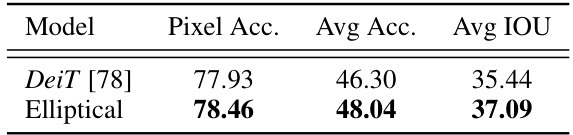
🔼 This table presents the results of image segmentation on the ADE20K dataset. It compares the performance of the DeiT model and the Elliptical Attention model, reporting Pixel Accuracy, Average Accuracy, and Average Intersection over Union (IoU). The Elliptical model shows improvements across all three metrics, demonstrating enhanced performance in image segmentation tasks.
read the caption
Table 7: Image Segmentation Results

🔼 This table compares the perplexity (PPL) scores achieved by different language models on the WikiText-103 benchmark under both clean and Word Swap contaminated conditions. The results show that the Elliptical model achieves the lowest PPL score in the clean setting and the second lowest score under contamination.
read the caption
Table 1: Perplexity (PPL) on WikiText-103 under Word Swap contamination. Elliptical achieves top PPL in clean data and second best in contaminated. Best result in bold and second best underlined.

🔼 This table compares the performance of DeiT and DeiT-Elliptical on ImageNet robustness benchmarks (ImageNet-R, ImageNet-A, ImageNet-C, and ImageNet-C (Extra)). It shows top-1 accuracy for ImageNet-R and ImageNet-A, and mean corruption error (mCE) for ImageNet-C and ImageNet-C (Extra). The results indicate how well each model performs under different types of image corruption and adversarial attacks. The mCE values show lower is better.
read the caption
Table 9: Evaluation of the performance of our model and DeiT across multiple robustness benchmarks, using appropriate evaluation metrics for each.

🔼 This table shows the impact of increasing the number of attention heads while keeping the total number of parameters constant in the DeiT and Elliptical models. It demonstrates that Elliptical Attention consistently achieves higher top-1 and top-5 accuracy compared to the baseline DeiT model across different head configurations.
read the caption
Table 10: Additional Results on Imagenet Increasing Heads But Maintaining Overall Embedding Dimension

🔼 This table compares the computation speed, maximum memory usage, FLOPs per sample, and number of parameters for DeiT and DeiT-Elliptical models at three different scales: Tiny, Small, and Base. It shows the percentage change in each metric between the two models at each scale. The results indicate that Elliptical Attention offers efficiency improvements with only a slight increase in memory usage.
read the caption
Table 11: Side-by-side Efficiency comparison of DeiT and DeiT-Elliptical
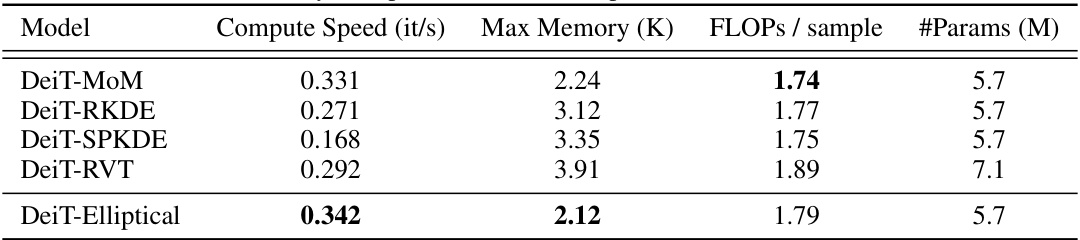
🔼 This table compares the computational efficiency (compute speed in iterations per second), memory usage (max memory in kilobytes), floating point operations per sample, and the number of parameters (in millions) for different models. The models compared include DeiT-MoM, DeiT-RKDE, DeiT-SPKDE, DeiT-RVT, and DeiT-Elliptical (the proposed model). It highlights that DeiT-Elliptical achieves good performance with reasonable efficiency and memory usage.
read the caption
Table 12: Efficiency Comparison between Elliptical and baseline robust models

🔼 This table compares the performance of standard Switch Transformers and Switch Transformers with Elliptical Attention on two different sizes of models (medium and large) after pretraining on WikiText-103 and fine-tuning on Stanford Sentiment Treebank 2 (SST-2). It shows the test perplexity (PPL) and finetune test accuracy. Elliptical Attention consistently improves both metrics over the baseline Switch Transformers for both model sizes.
read the caption
Table 13: Elliptical Switch Transformers Pretrained on WikiText-103 and Finetuned on Stanford Sentiment Treebank 2 (SST-2)

🔼 This table presents the results of experiments using Switch Transformers, comparing the standard Switch Transformer with the proposed Elliptical Switch Transformer. The models were pretrained on the EnWik8 dataset and then finetuned on the Stanford Sentiment Treebank 2 (SST-2) dataset. The table shows the test bits-per-character (BPC) and the finetune test accuracy for both models. The results demonstrate the improved performance of the Elliptical Switch Transformer compared to the standard Switch Transformer after finetuning.
read the caption
Table 14: Elliptical Switch Transformers Pretrained on EnWik8 and Finetuned on Stanford Sentiment Treebank 2 (SST-2)

🔼 This table presents the results of the WikiText-103 language modeling experiments using the GLAM (Generalist Language Model) architecture. It compares the performance of the standard GLAM model with the Elliptical Attention-enhanced GLAM model (GLAM-Elliptical) across two different sizes: small and medium. The results are expressed in terms of Test Perplexity (PPL), a lower score indicating better performance. The table shows the improvements achieved by incorporating Elliptical Attention into the GLAM model for both sizes.
read the caption
Table 15: Test Perplexity of Elliptical GLaM on WikiText-103 Modeling

🔼 This table shows the top-1 and top-5 accuracy of DeiT and DeiT with Elliptical Attention on ImageNet under three different adversarial attacks (PGD, FGSM, and SPSA) with a perturbation budget of 1/255. The results are presented for both clean data and data subjected to adversarial attacks. The best and second-best results in each attack category are highlighted in bold and underlined, respectively, to demonstrate the performance improvement achieved by incorporating Elliptical Attention.
read the caption
Table 2: Top-1 and Top-5 Test accuracy on ImageNet under adversarial attacks PGD, FGSM, and SPSA with perturbation budget 1/255. Best result shown in bold and second best shown underlined.

🔼 This table presents the top-1 and top-5 test accuracy results on the ImageNet dataset under three different adversarial attacks (PGD, FGSM, and SPSA) with a perturbation budget of 1/255. The results are compared across several different models. The best performance for each metric is highlighted in bold, and the second-best is underlined. This demonstrates the models’ robustness to adversarial attacks.
read the caption
Table 2: Top-1 and Top-5 Test accuracy on ImageNet under adversarial attacks PGD, FGSM, and SPSA with perturbation budget 1/255. Best result shown in bold and second best shown underlined.

🔼 This table presents the results of measuring head redundancy for both the baseline transformer and the Elliptical Attention model on two large-scale tasks: WikiText-103 language modeling and ImageNet-1K object classification. For each task and model, the table shows the number of attention heads, the dimension of each head, and the mean L2 distance between the vectorized attention heads (averaged across layers and batches). The L2 distance is a measure of head redundancy; higher values indicate greater redundancy.
read the caption
Table 18: Head Redundancy Results
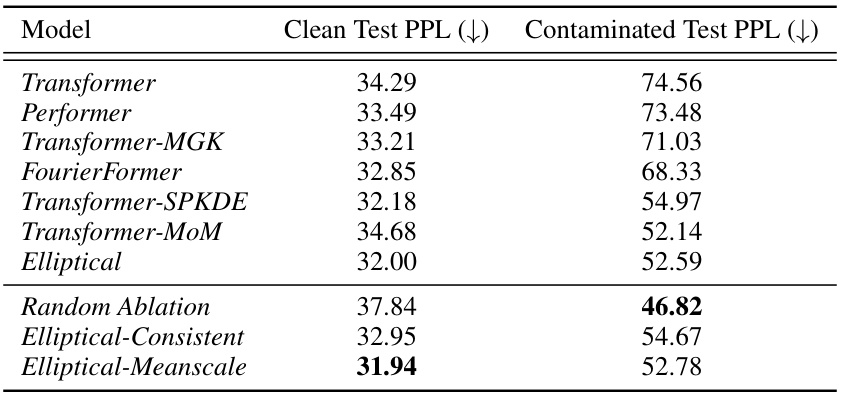
🔼 The table compares the performance of various language models, including the proposed Elliptical Attention model, on the WikiText-103 benchmark under clean and Word Swap contamination conditions. The perplexity (PPL) score, a measure of how well a model predicts a sequence of words, is shown for each model under both clean and contaminated scenarios. Elliptical achieves the best PPL on clean data and is second-best on contaminated data, demonstrating its robustness.
read the caption
Table 1: Perplexity (PPL) on WikiText-103 under Word Swap contamination. Elliptical achieves top PPL in clean data and second best in contaminated. Best result in bold and second best underlined.

🔼 This table presents a comparison of the performance of the proposed Elliptical Attention model and the DeiT model across various ImageNet robustness benchmarks. It shows the Top-1 accuracy for ImageNet-R (real-world adversarial examples) and ImageNet-A (artistic renditions), and the mean Corruption Error (mCE) for ImageNet-C (algorithmically generated corruptions) and ImageNet-C (Extra). The results highlight the relative performance of each model under different types of image perturbations.
read the caption
Table 9: Evaluation of the performance of our model and DeiT across multiple robustness benchmarks, using appropriate evaluation metrics for each.

🔼 This table presents the results of the ImageNet classification experiment under three different adversarial attacks: PGD, FGSM, and SPSA. The performance of DeiT and DeiT-Elliptical is compared with other baseline models. The ‘Top 1’ and ‘Top 5’ columns represent the top-1 and top-5 accuracy, respectively. A perturbation budget of 1/255 was used for all attacks. The best results are bolded, and the second best are underlined. The table demonstrates the robustness of DeiT-Elliptical against adversarial attacks.
read the caption
Table 2: Top-1 and Top-5 Test accuracy on ImageNet under adversarial attacks PGD, FGSM, and SPSA with perturbation budget 1/255. Best result shown in bold and second best shown underlined.
Full paper#