TL;DR#
Traditional 3D reconstruction struggles in challenging conditions like fast motion and low light. Neural Radiance Fields (NeRF) methods, while offering photorealistic results, are computationally expensive and lack scene-editing flexibility. This research tackles these issues.
The proposed Event-3DGS framework utilizes 3D Gaussian splatting (3DGS) for event-based 3D reconstruction. It directly processes event data, optimizing scene and sensor parameters simultaneously. A key innovation is a high-pass filter to reduce noise in event data, improving robustness. The method demonstrates superior performance and robustness in various challenging scenarios compared to existing techniques.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Event-3DGS, the first event-based 3D reconstruction framework using 3D Gaussian splatting. This offers a significant advancement over existing methods, which are often time-consuming, limited in scene editing capabilities, and struggle with real-world conditions. Event-3DGS shows superior performance and robustness in real-world scenarios with extreme noise, fast motion, and low light, opening avenues for high-quality, efficient, and robust 3D reconstruction in various applications.
Visual Insights#
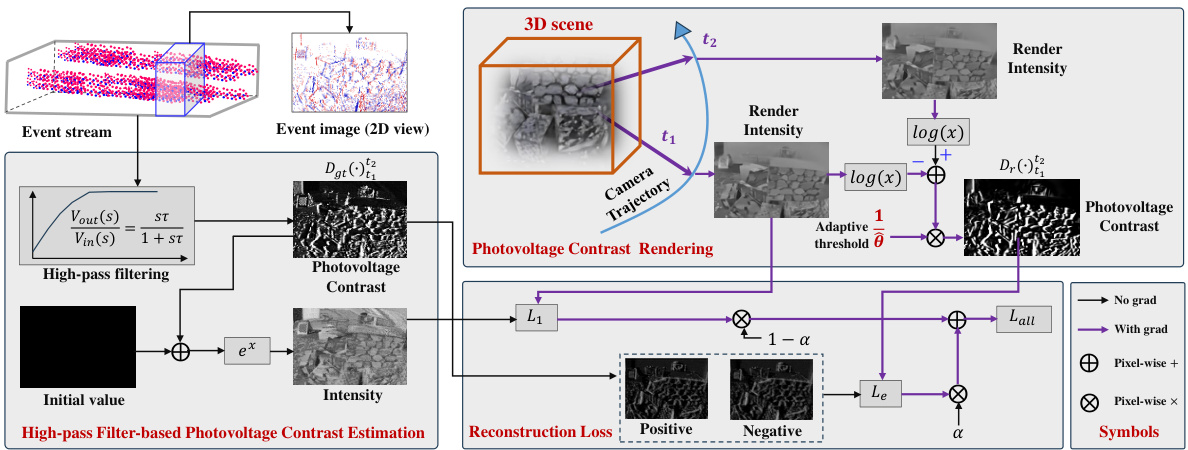
🔼 This figure illustrates the overall framework of Event-3DGS. It consists of three main modules: 1) High-pass filter-based photovoltage contrast estimation, which preprocesses event data to reduce noise. 2) Photovoltage contrast rendering, which uses 3D Gaussian splatting to render the photovoltage contrast images from the 3D scene representation. 3) Event-based 3D reconstruction loss, which compares the rendered photovoltage contrast with the ground truth obtained from the event data to optimize the model parameters for better reconstruction quality. The framework directly processes event data and reconstructs 3D scenes by simultaneously optimizing both scene and sensor parameters.
read the caption
Figure 1: The pipeline of Event-based 3D Reconstruction using 3D Gaussian Splatting (Event-3DGS). The proposed event-based 3DGS framework enables direct processing of event data and reconstructs 3D scenes while simultaneously optimizing scenario and sensor parameters. A high-pass filter-based photovoltage contrast estimation module is presented to reduce noise in event data, enhancing the robustness of our method in real-world scenes. An event-based 3D reconstruction loss is designed to optimize the parameters of our method for better reconstruction quality.
🔼 This table compares the performance of Event-3DGS against two state-of-the-art methods (E2VID [34]+3DGS [15] and PI-3DGS) on the DeepVoxels synthetic dataset. The comparison is done using three metrics: SSIM, PSNR, and LPIPS, across seven different sequences. The results demonstrate that Event-3DGS achieves superior performance compared to the other methods, particularly in terms of PSNR and SSIM, highlighting its effectiveness in 3D reconstruction.
read the caption
Table 1: Performance comparison on the DeepVoxels synthetic dataset [38]. our Event-3DGS outperforms two state-of-the-art methods and our baseline using pure integration without filtering.
In-depth insights#
Event-Based 3DGS#
Event-Based 3DGS represents a novel approach to 3D reconstruction, leveraging the high temporal resolution and dynamic range of event cameras. Unlike traditional methods or those based on Neural Radiance Fields (NeRFs), which often struggle with time-consuming processing, Event-3DGS utilizes 3D Gaussian Splatting (3DGS) for efficient and robust scene representation. This combination addresses the limitations of NeRF-based methods, such as slow training and limited scene editing. The framework directly processes event data, simultaneously optimizing scene and sensor parameters, resulting in improved reconstruction quality even in challenging conditions like low light or fast motion. The incorporation of a high-pass filter-based photovoltage estimation module further enhances robustness, reducing noise inherent in event data. A custom event-based reconstruction loss function ensures accurate model optimization. In essence, Event-3DGS offers a faster, more efficient, and robust alternative to existing event-based 3D reconstruction techniques, paving the way for real-time applications.
3DGS Reconstruction#
3D Gaussian Splatting (3DGS) offers a compelling alternative to traditional NeRF-based methods for 3D reconstruction. 3DGS excels in speed and accuracy, rapidly converting input images into detailed 3D point clouds. Its explicit representation, unlike NeRF’s implicit approach, facilitates efficient scene editing and rendering. However, the existing literature primarily focuses on image and video data, leaving the application of 3DGS to event streams largely unexplored. Event-based 3D reconstruction using 3DGS presents unique challenges related to the asynchronous and sparse nature of event data. Adapting 3DGS to directly handle event data requires innovative solutions for noise reduction, photovoltage estimation, and loss function design to optimize reconstruction quality in challenging real-world conditions. The potential of combining the strengths of event cameras and 3DGS is significant, opening new avenues for high-quality, efficient, and robust 3D scene capture in dynamic and low-light scenarios.
High-Pass Filtering#
High-pass filtering, in the context of event-based vision, is a crucial preprocessing step for enhancing the robustness of 3D reconstruction. It directly addresses the inherent noisiness of event streams, which originate from asynchronous measurements of light intensity changes. By selectively preserving high-frequency components (rapid changes in light), high-pass filtering effectively attenuates low-frequency noise such as thermal noise and sensor drift. This leads to a cleaner, more reliable signal suitable for subsequent processing stages, such as photovoltage contrast estimation. The specific implementation of high-pass filtering, whether it involves a simple temporal filter or a more sophisticated spatiotemporal approach, significantly impacts the accuracy and efficiency of the subsequent 3D reconstruction. Careful selection of filter parameters is paramount for balancing noise reduction with the preservation of crucial event information. The choice between methods also hinges on computational cost and the specific characteristics of the sensor being used. Optimal filter design is critical for achieving high-quality and robust 3D reconstruction from event camera data.
Real-world Robustness#
Real-world robustness is a crucial aspect for evaluating the practical applicability of any 3D reconstruction method. A system demonstrating strong performance on simulated datasets may fail spectacularly when confronted with the complexities of real-world environments. Factors such as unpredictable lighting conditions, fast motion, and sensor noise significantly impact the quality of reconstruction. A truly robust system must account for these variations, ideally exhibiting graceful degradation rather than complete failure. Methods incorporating noise reduction techniques, sophisticated motion estimation, and adaptive parameter tuning are more likely to achieve high real-world robustness. Furthermore, comprehensive testing on diverse real-world datasets, spanning various scenes and conditions, is necessary for validation. Qualitative and quantitative metrics should be used to evaluate the performance across different challenges, showcasing the resilience and generalizability of the approach. The ultimate goal is to develop algorithms capable of producing accurate and reliable 3D models even under challenging circumstances, bridging the gap between theoretical potential and real-world deployment.
Future Directions#
Future research directions stemming from this event-based 3D reconstruction work could involve improving robustness in challenging conditions. While the paper demonstrates progress, further enhancing performance in extreme noise, low light, or rapid motion remains crucial. Another key area is exploring different event camera models beyond the DVS, investigating how Event-3DGS adapts to varying sensor characteristics and data formats. Extending 3DGS capabilities to handle dynamic scenes is important, perhaps by incorporating temporal context more effectively. Finally, integration with other modalities (e.g., RGB cameras, IMUs) to create hybrid 3D reconstruction systems capable of achieving high-fidelity, real-time reconstruction in complex environments would greatly enhance practical applications.
More visual insights#
More on figures

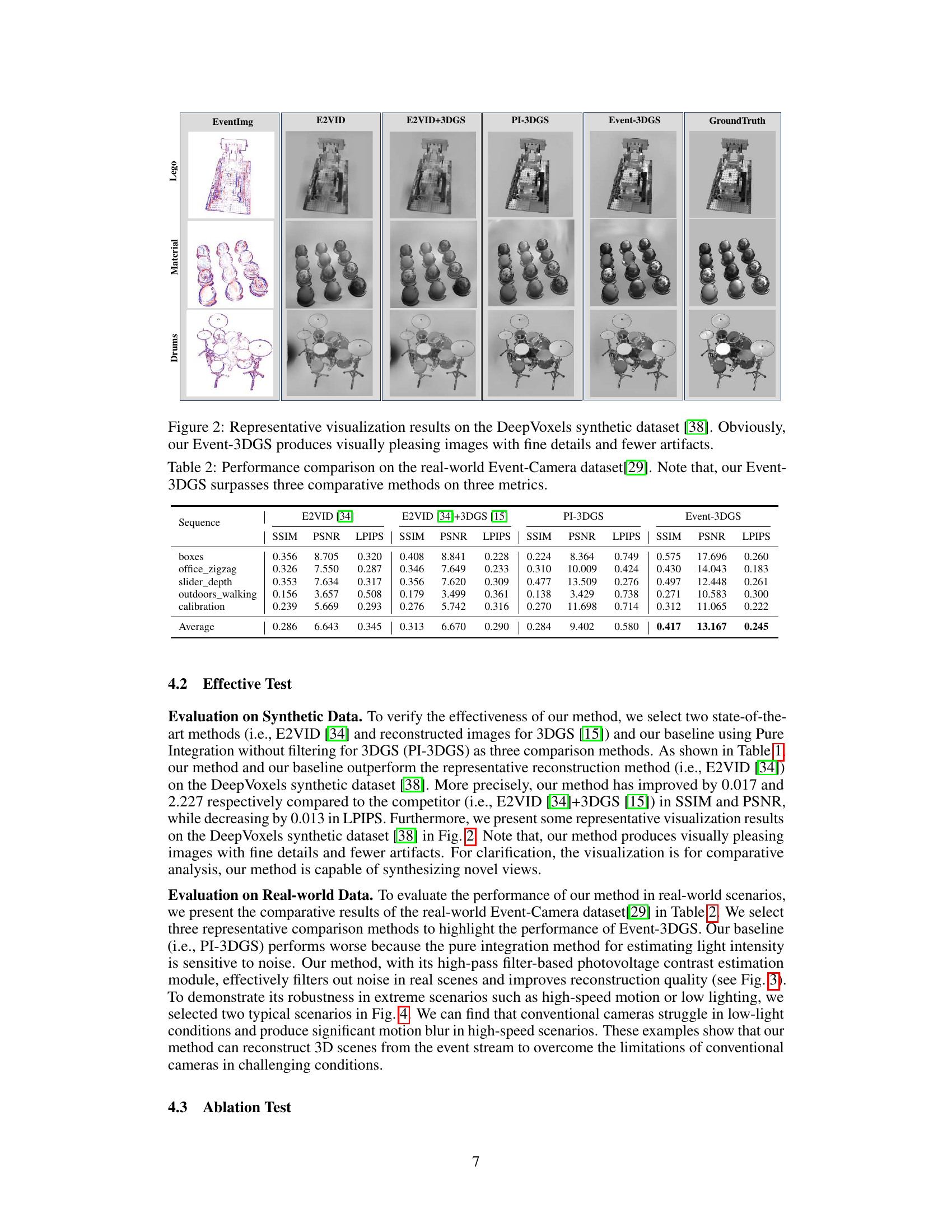
🔼 This figure compares the 3D reconstruction results of different methods on the DeepVoxels dataset. The first column shows the original event image data. The second column displays the results from E2VID, a state-of-the-art method. The third column showcases the results of combining E2VID with 3D Gaussian Splatting (3DGS). The fourth column presents the results using pure integration with 3DGS (PI-3DGS). The fifth column shows the results of the proposed Event-3DGS method. The final column shows the ground truth images. The comparison highlights that Event-3DGS produces higher-quality 3D reconstructions with finer details and fewer artifacts than the other methods.
read the caption
Figure 2: Representative visualization results on the DeepVoxels synthetic dataset [38]. Obviously, our Event-3DGS produces visually pleasing images with fine details and fewer artifacts.

🔼 This figure compares the visual results of different 3D reconstruction methods on real-world scenes from the Event-Camera dataset. It shows the original event data, results from E2VID, E2VID+3DGS, PI-3DGS, and finally the results from the proposed Event-3DGS method. The frame camera images are also provided for comparison. The figure demonstrates that Event-3DGS produces clearer, more detailed 3D reconstructions compared to other methods, especially handling noisy or low-light conditions better.
read the caption
Figure 7: Representative visualization results series the real-world Event-Camera dataset[29]. Our Event-3DGS method produces clearer results compared to other methods.

🔼 This figure shows the results of 3D reconstruction using Event-3DGS in challenging scenarios with low light and high speed motion. The top row shows the results under low light condition, where a conventional RGB camera struggles to capture clear images. The bottom row shows the results under high speed motion condition, where motion blur is prominent in the conventional RGB image. In contrast, Event-3DGS produces more visually pleasing results even under these challenging conditions.
read the caption
Figure 4: Representative visualization examples on low-light and high-speed motion blur scenarios.

🔼 This figure showcases the motion deblurring capabilities of the proposed Event-3DGS method. It compares results from different methods on a sequence of images containing motion blur. The first column displays the original RGB image; the second column presents the corresponding event data; subsequent columns illustrate the reconstructed images using E2VID, E2VID+3DGS, Event-3DGS, and E-Deblur-3DGS, respectively. The figure highlights how Event-3DGS and its deblurring extension effectively mitigate motion blur, yielding sharper and more detailed reconstructions compared to other methods.
read the caption
Figure 6: Representative visualization examples of motion deblurring. Note that, our Event-3DGS can be extended for high-quality hybrid reconstruction using events and frames with motion blur.

🔼 This figure showcases the results of colorful 3D reconstruction using the proposed Event-3DGS method. It compares the reconstruction quality of the proposed method (C-Event3DGS) with two other methods (Event and E2VID+3DGS) on a real-world dataset. The results demonstrate that C-Event3DGS produces visually pleasing images with fine details and fewer artifacts compared to other methods.
read the caption
Figure 5: Representative examples of colorful event-based 3D reconstruction.

🔼 This figure compares the 3D reconstruction results of five different methods using real-world event camera data. The methods compared are: raw event data, E2VID, E2VID+3DGS, PI-3DGS, Event-3DGS, and a frame camera. The figure shows that the Event-3DGS method significantly improves the quality and clarity of the reconstruction, producing clearer results than all the other methods. Each row presents the same viewpoint from slightly different angles.
read the caption
Figure 7: Representative visualization results series the real-world Event-Camera dataset[29]. Our Event-3DGS method produces clearer results compared to other methods.
More on tables
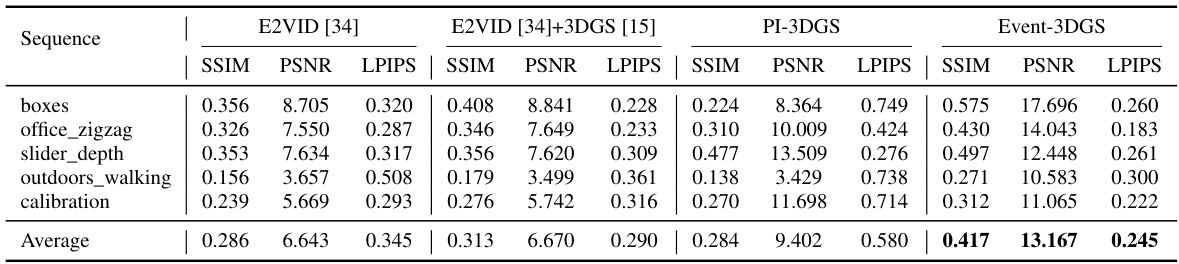
🔼 This table compares the performance of four different methods for 3D reconstruction using event cameras on a real-world dataset. The methods compared are E2VID [34], E2VID [34]+3DGS [15], PI-3DGS, and Event-3DGS. The performance is measured using three metrics: SSIM, PSNR, and LPIPS. The results show that Event-3DGS outperforms the other three methods across all three metrics.
read the caption
Table 2: Performance comparison on the real-world Event-Camera dataset[29]. Note that, our Event-3DGS surpasses three comparative methods on three metrics.
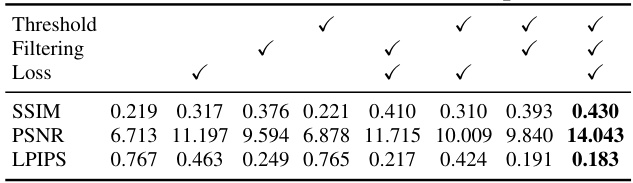
🔼 This table presents the ablation study results, showing the impact of each component (Threshold, Filtering, and Loss) on the performance of the Event-3DGS model. The performance is evaluated using SSIM, PSNR, and LPIPS metrics. The table demonstrates that incorporating all three components yields the best performance.
read the caption
Table 3: The contribution of each component.
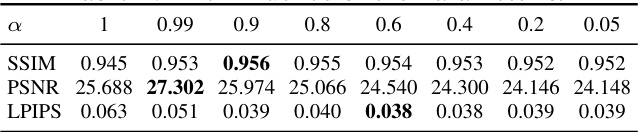
🔼 This table presents the results of an ablation study on the influence of the hyperparameter α in the proposed Event-3DGS model. The hyperparameter α controls the weight of the intensity loss in the overall loss function. The table shows the SSIM, PSNR, and LPIPS metrics for different values of α, ranging from 0.05 to 1. The best performance (highest SSIM and PSNR and lowest LPIPS) is observed at α = 0.9. This suggests that balancing the importance of intensity and photovoltage contrast in the loss function is crucial for optimal performance.
read the caption
Table 4: The influence of the Parameter α
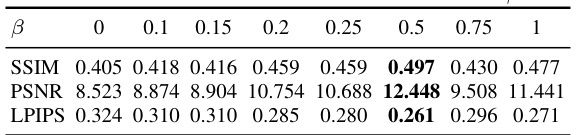
🔼 This table presents the results of an ablation study, varying the parameter β in the loss function of the Event-3DGS model. The parameter β controls the tolerance in the estimated photovoltage contrast. The table shows the impact of different β values on the SSIM, PSNR, and LPIPS metrics across several sequences. The best performance (highest SSIM and PSNR, lowest LPIPS) is achieved with β=0.5, highlighting its importance for balancing reconstruction quality and robustness.
read the caption
Table 5: The influence of the Parameter β.
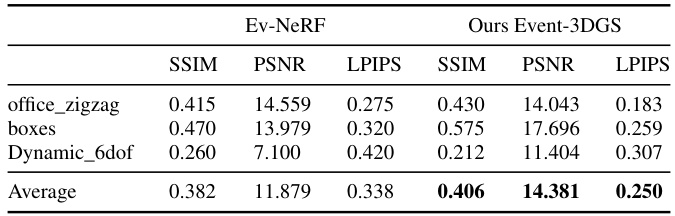
🔼 This table presents a comparison of the performance of the proposed Event-3DGS method against the Ev-NeRF method on a real-world dataset. The comparison uses three metrics: SSIM, PSNR, and LPIPS. The results show that Event-3DGS outperforms Ev-NeRF across all three metrics in three different real-world scenarios.
read the caption
Table 6: Experiment results on real dataset between Ev-NeRF and our Event-3DGS. Our Event-3DGS outperforms Ev-NeRF in all metrics.

🔼 This table presents the performance and time metrics of Event-3DGS using synthetic data at different training iterations. The initial stage represents when the parameter α is set to zero. Subsequently, α is set to 0.99, and the training is continued until 7999 iterations. The table shows that Event-3DGS achieves high-quality reconstruction in approximately five minutes, demonstrating its potential for real-time applications.
read the caption
Table 7: Experiment results on performance and time of different training iterations
Full paper#