↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Pixel-level long-tail semantic segmentation struggles with class imbalance, where models overemphasize major classes and underperform on minor classes. Existing solutions often neglect the theoretical impact of loss functions, or ignore the high computational demands of pixel-level AUC optimization. This paper directly addresses these issues.
The proposed AUCSeg framework tackles this problem using a novel AUC-oriented loss function, theoretically analyzed for generalization. To address memory limitations, AUCSeg incorporates a Tail-Classes Memory Bank, storing information from less frequent classes. Experimental results on multiple benchmark datasets demonstrate AUCSeg’s effectiveness, particularly in improving performance on minority classes, significantly outperforming previous approaches.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between AUC optimization and pixel-level long-tail semantic segmentation, a significant challenge in computer vision. It offers a novel theoretical framework and practical solutions, paving the way for improved model performance and generalization on complex, real-world scenarios. The proposed method, AUCSeg, and its memory-efficient design make a significant contribution to the field. The findings could accelerate research into handling class imbalance in other pixel-level tasks and potentially improve various applications in computer vision and image processing.
Visual Insights#
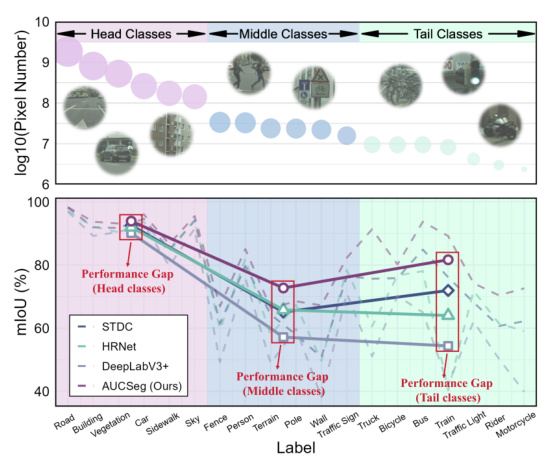
This figure shows the pixel number distribution for each class in the Cityscapes dataset, categorized into head, middle, and tail classes based on the number of pixels. It also compares the performance (mIoU) of existing semantic segmentation methods (DeepLabV3+, HRNet, and STDC) with the proposed AUCSeg method. The graph visually demonstrates the long-tail distribution problem where head classes have significantly more pixels than tail classes. AUCSeg aims to improve overall performance, especially addressing the performance gap for tail classes.
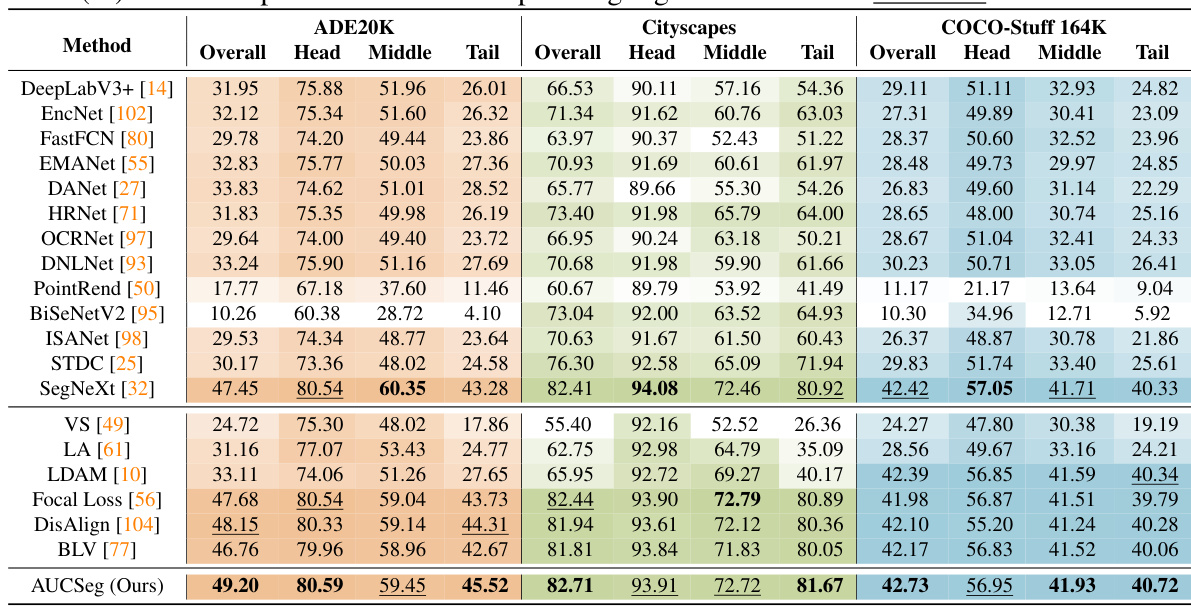
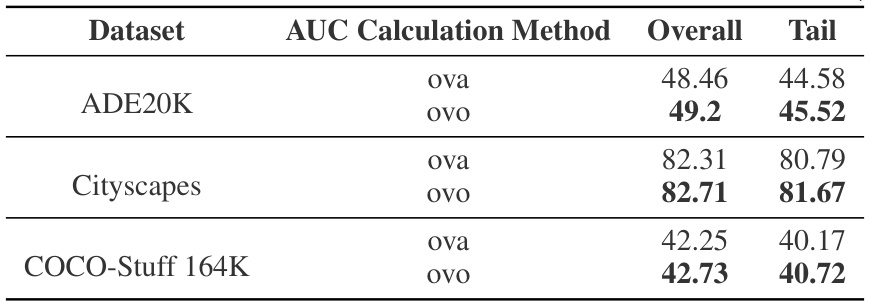
This table presents a comparison of the performance of different semantic segmentation methods on three benchmark datasets (Cityscapes, ADE20K, and COCO-Stuff 164K). The results are presented in terms of mean Intersection over Union (mIoU), broken down by overall performance, and performance on head, middle, and tail classes. The best-performing method for each metric is highlighted in bold, and the second-best is underlined. This allows for a direct comparison of the effectiveness of various methods in handling long-tailed distributions in semantic segmentation.
In-depth insights#
AUC-Seg Overview#
AUCSeg, short for AUC-oriented Pixel-level Long-tail Semantic Segmentation, is a novel framework designed to address the challenges of long-tail semantic segmentation. Its core innovation is the use of Area Under the ROC Curve (AUC) as the primary optimization metric, shifting away from traditional cross-entropy loss which often struggles with class imbalance. The pixel-level application of AUC presents significant challenges. AUCSeg tackles the computational complexity associated with pixel-level AUC optimization through a Tail-Classes Memory Bank, which efficiently manages the memory demands by cleverly supplementing missing tail classes within each mini-batch. This memory bank, paired with a theoretical analysis of the dependency graph, allows AUCSeg to achieve strong generalization performance, especially for under-represented classes. The framework’s flexibility allows it to seamlessly integrate with various state-of-the-art backbones, demonstrating its adaptability and effectiveness across different semantic segmentation tasks and datasets.
Pixel-level AUC Loss#
Pixel-level AUC loss presents a novel approach to address class imbalance in semantic segmentation. Unlike traditional methods that focus on individual pixels, this loss function considers the ranking of pixel scores across all classes within an image, making it less sensitive to the number of samples per class. This is achieved through a pairwise comparison of pixels and calculating the area under the ROC curve for each class pair. This approach can be computationally intensive; hence, the authors of the research paper explore various optimization techniques to handle the increased computational complexity, such as Tail-Classes Memory Bank. The pixel-level AUC loss function, coupled with these optimizations, offers a promising approach to improving the performance of semantic segmentation models on long-tail datasets, as it implicitly addresses the class imbalance problem without requiring complex data augmentation or re-weighting schemes.
T-Memory Bank#
The T-Memory Bank addresses the challenge of insufficient tail class samples during mini-batch generation for AUC-based pixel-level long-tail semantic segmentation. Standard AUC optimization techniques require at least one sample from each class per mini-batch, which is difficult to achieve with the dense pixel labels of semantic segmentation. The T-Memory Bank cleverly mitigates this by storing historical tail class pixel information. When a mini-batch lacks certain tail classes, the bank supplements these missing classes by retrieving similar pixel data. This approach enables efficient AUC optimization with significantly reduced memory demand, thus improving the scalability of the overall model. The bank’s effectiveness relies on balancing the need for diverse tail class samples with the risk of overfitting. It offers a practical solution to a memory-intensive problem inherent in pixel-level long-tail learning, thereby enhancing the performance of the AUCSeg method.
Generalization Bounds#
The Generalization Bounds section of a research paper is crucial for establishing the reliability and applicability of a model. It mathematically quantifies the difference between a model’s performance on training data and its expected performance on unseen data. This is vital because a model that performs well only on its training data is likely overfit and will generalize poorly to new, real-world scenarios. A strong generalization bound, often expressed as a function of dataset size and model complexity, provides confidence that the model’s learned patterns are not merely artifacts of the training set but reflect underlying structure. The derivation of such bounds often involves sophisticated mathematical tools, such as Rademacher complexity or covering numbers, to analyze the model’s capacity to fit random noise. Tight bounds are highly desirable; loose bounds offer less reassurance about the model’s ability to generalize. The choice of technique (Rademacher complexity, VC dimension, etc.) is also important, and the discussion should clearly explain why the specific technique is suitable for the problem and model type. Finally, the practical implications of the bounds should be thoughtfully discussed, acknowledging any limitations and potential caveats.
Future Work#
Future research directions stemming from this paper could explore several promising avenues. Extending the AUCSeg framework to 3D semantic segmentation would be a significant advance, tackling the challenges of increased computational cost and data complexity inherent in volumetric data. Another important direction is investigating more sophisticated memory management techniques to further reduce the memory footprint and enable processing of even larger images and datasets. The theoretical analysis presented could also be expanded upon, potentially developing tighter generalization bounds and exploring the impact of different architectural choices and data distributions on the model’s performance. Finally, comprehensive evaluations on diverse long-tail datasets beyond the benchmark datasets used in this study would strengthen the generalizability and robustness claims of the proposed AUCSeg method.
More visual insights#
More on figures

This figure provides a visual overview of the AUCSeg framework. It shows the different components of the system, including the T-Memory Bank, the AUC optimization process, and the theoretical result. The T-Memory Bank is used to address the problem of missing tail classes in each mini-batch. The AUC optimization process aims to maximize the AUC score. The theoretical result shows that the AUCSeg method is guaranteed to generalize well to unseen data.

This figure illustrates the difference in sampling strategies between instance-level classification and pixel-level semantic segmentation tasks, particularly highlighting the challenges posed by long-tailed distributions in the pixel-level scenario. (a) shows instance-level sampling where stratified sampling ensures representation from all classes. (b) demonstrates the difficulty of stratified sampling in pixel-level tasks due to the indivisible nature of pixels and the resulting missing tail-class pixels in mini-batches. (c) introduces the Tail-class Memory Bank proposed by the authors as a solution to address the missing tail-class pixels problem by augmenting the mini-batches with historical class information.

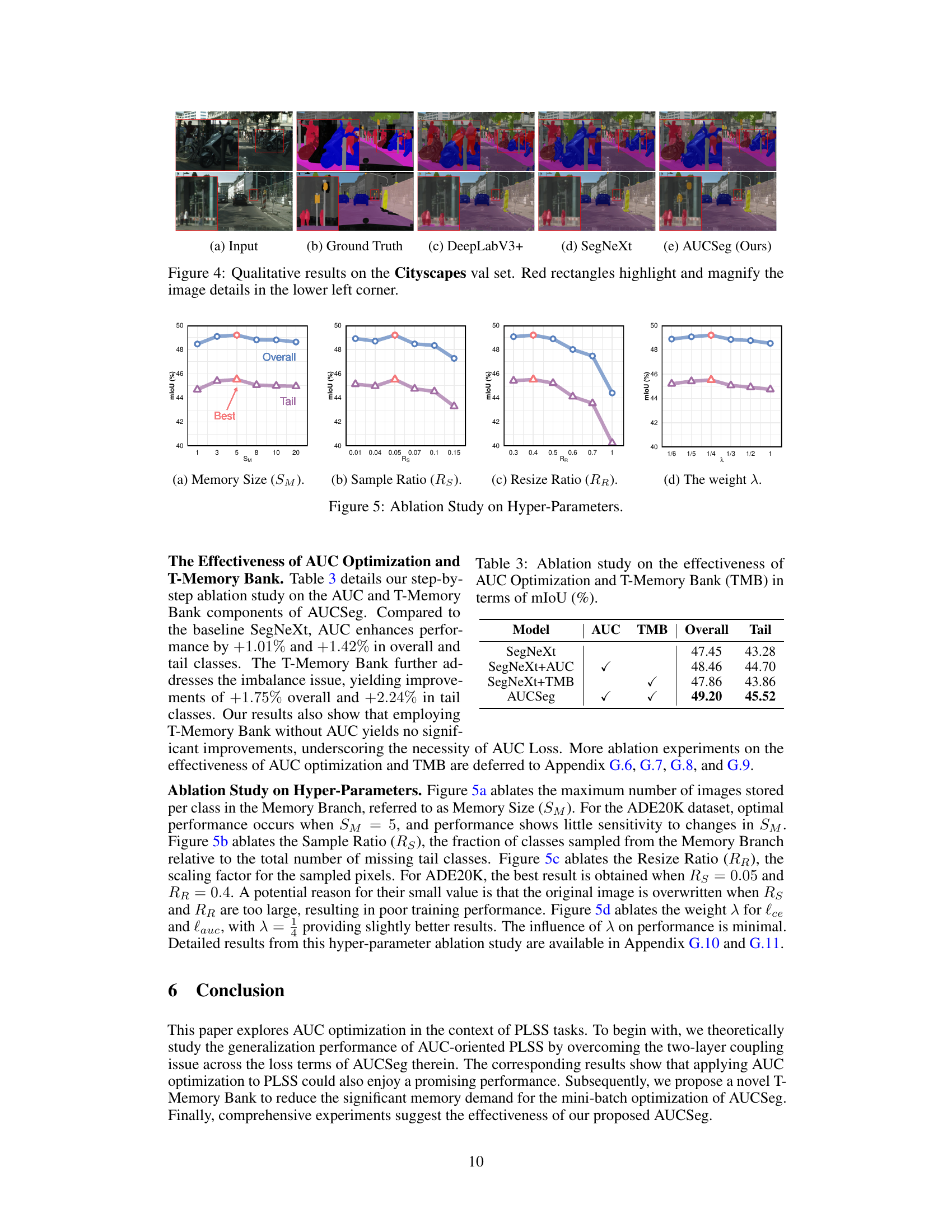
This figure showcases qualitative results of the proposed AUCSeg model on the Cityscapes validation set. It compares the input images with their ground truth segmentations and the results obtained from three different methods: DeepLabV3+, SegNeXt, and AUCSeg (the authors’ method). Red boxes highlight specific areas of interest, focusing on detailed segmentation of objects, particularly in complex scenes or instances where the model may struggle, to emphasize the improved performance of AUCSeg in areas that are challenging for other methods. This visual comparison aims to demonstrate the effectiveness of AUCSeg in producing more accurate and detailed semantic segmentation results, especially for smaller or less frequent object classes.
This figure shows a schematic overview of the proposed AUCSeg framework. It illustrates the main components of the model, including the encoder, decoder, T-Memory Bank, and the AUC optimization process. The figure also highlights the theoretical results of the generalization bound for AUCSeg, emphasizing the key contributions and working mechanism of the model.

This figure presents a schematic overview of the proposed AUCSeg framework. It illustrates the main components of the model, including the encoder, decoder, T-Memory Bank, and the AUC optimization process. The input image undergoes encoding and decoding to generate pixel-level predictions, which are then used in conjunction with the ground truth to optimize the AUC loss function. The T-Memory Bank plays a crucial role in addressing the issues related to the memory demands of AUC optimization. It stores and retrieves historical class information to ensure efficient optimization and manages the significant memory demand.
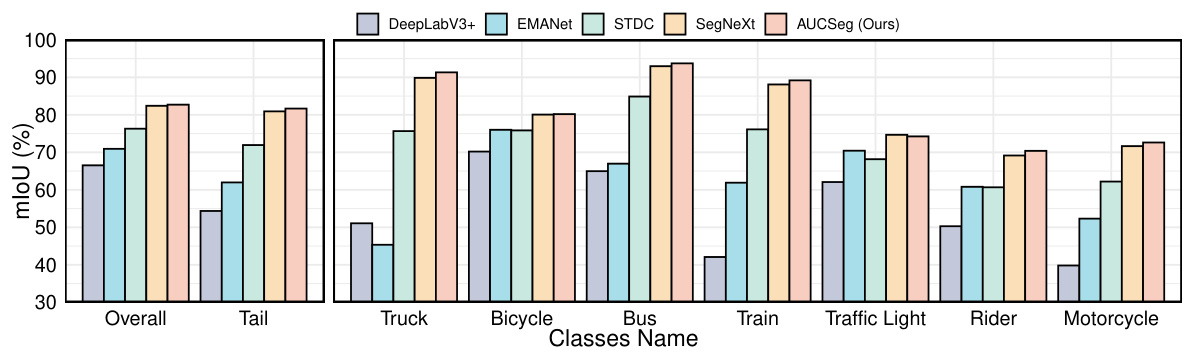
This figure shows the performance of different semantic segmentation models on the Cityscapes validation set, broken down by individual tail classes. The tail classes are ordered from left to right based on the number of training samples available for each, with ‘motorcycles’ having the fewest samples. The graph compares the overall and per-tail-class mIoU (mean Intersection over Union) scores for several models including DeepLabV3+, EMANet, STDC, SegNeXt, and the proposed AUCSeg model. It visually demonstrates the effectiveness of AUCSeg in improving the performance of semantic segmentation on tail classes, which tend to be underrepresented in datasets.

This figure shows qualitative results of semantic segmentation on the Cityscapes validation set. It compares the segmentation results of DeepLabV3+, SegNeXt, and the proposed AUCSeg method. Red boxes highlight areas where the differences between the methods are most apparent, allowing for detailed visual comparison of their performances on various image regions.
More on tables
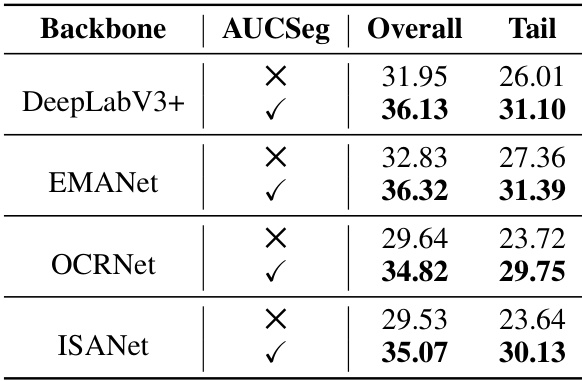
This table presents the performance comparison of AUCSeg using four different backbones (DeepLabV3+, EMANet, OCRNet, and ISANet) on the semantic segmentation task. For each backbone, the table shows the overall mean Intersection over Union (mIoU) and the mIoU specifically for the tail classes. The ‘X’ indicates that the backbone was used without AUCSeg, while the ‘✓’ indicates that AUCSeg was applied. This highlights the improvement achieved by integrating AUCSeg with various state-of-the-art backbones.

This table presents the results of an ablation study to evaluate the individual and combined effects of AUC optimization and the T-Memory Bank on the performance of the AUCSeg model. The mIoU (mean Intersection over Union) metric is used to assess the overall and tail class performance. The table shows that both AUC optimization and the T-Memory Bank contribute to improved performance, especially in the tail classes.

This table presents the quantitative performance comparison of AUCSeg against 13 state-of-the-art semantic segmentation methods and 6 long-tail approaches on three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The evaluation metric used is mean Intersection over Union (mIoU). The results are broken down by overall performance, as well as performance on head, middle, and tail classes. The best-performing method and the second-best method for each category are highlighted.

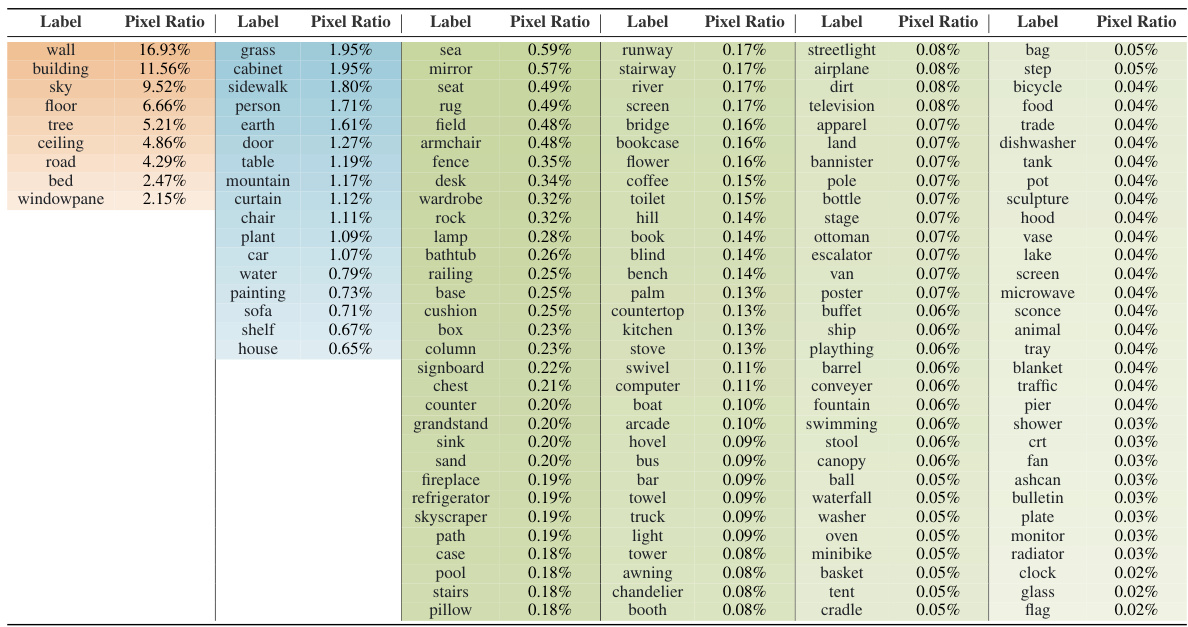
This table shows the number of images in the Cityscapes dataset that contain at least one pixel belonging to each of the 19 classes. It provides a visual representation of class imbalance, showing how many images have pixels from each class. Classes with lower numbers indicate a higher frequency of occurrence in the dataset, while those with higher numbers are less frequent.
This table presents a comparison of the performance of different semantic segmentation methods on three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The metrics used is mean Intersection over Union (mIoU), which is broken down into overall performance, and performance on head, middle and tail classes. The best and second-best performing methods are highlighted for each dataset and class.
This table presents the quantitative results of the proposed AUCSeg model and other state-of-the-art models on three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The evaluation metric is mean Intersection over Union (mIoU), calculated for overall performance and broken down into head, middle, and tail classes. The best and second-best performing models are highlighted.

This table presents the quantitative results of the proposed AUCSeg method and other state-of-the-art semantic segmentation methods on three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The evaluation metric used is the mean Intersection over Union (mIoU). The results are broken down by overall performance, as well as performance on head, middle, and tail classes. The best-performing method for each metric is highlighted in bold, with the second-best method underlined.
This table presents the quantitative results of the proposed AUCSeg method and other state-of-the-art semantic segmentation methods on three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The results are shown in terms of mean Intersection over Union (mIoU), a common metric for evaluating semantic segmentation performance. The table breaks down the mIoU scores into overall performance, and performance on head, middle, and tail classes to highlight the impact of long-tailed distribution. The best-performing method for each metric is highlighted in bold, and the second-best is underlined.

This table presents a comparison of the mean Intersection over Union (mIoU) scores achieved by various semantic segmentation methods on three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The results are broken down by overall performance, as well as performance on head, middle, and tail classes. The best-performing method and the second-best method in each category are highlighted.

This table compares the imbalance ratio (rm) across three datasets (ADE20K, Cityscapes, and COCO-Stuff 164K) and shows the performance improvement of AUCSeg on tail classes compared to the second-best performing method. The imbalance ratio (rm) is calculated using a formula shown in the paper and represents the degree of class imbalance. The table demonstrates a correlation between the imbalance ratio and the improvement achieved by AUCSeg, suggesting better performance gains on more imbalanced datasets.

This table presents the results of the AUCSeg model using different sizes (Tiny, Small, Base, Large) of the SegNeXt backbone. It shows the overall and tail class mIoU for each backbone size with and without AUCSeg, demonstrating the performance improvement of AUCSeg across all sizes.

This table shows the experimental results of AUCSeg on three benchmark datasets (ECSSD, HKU-IS, and PASCAL-S) for salient object detection. The baseline method used is SI-SOD-EDN. The metrics used for evaluation are MAE (Mean Absolute Error), Fm (F-measure), and Em (E-measure). Lower MAE indicates better performance. Higher Fm and Em values indicate better performance. The table demonstrates the improvement achieved by AUCSeg over the baseline SI-SOD-EDN on each dataset for each metric.
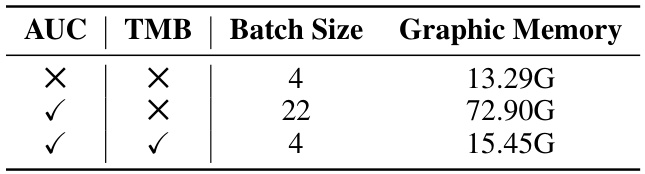
This table shows the GPU memory usage during training with different configurations. The first row shows the baseline without AUC and TMB, which requires 13.29G of memory. The second row demonstrates that using AUC alone drastically increases memory usage to 72.90G, due to the larger batch size required for convergence. Finally, the third row illustrates that by using both AUC and TMB, the memory consumption is reduced back down to 15.45G, showcasing the memory efficiency of the T-Memory Bank.

This table presents a quantitative comparison of the proposed AUCSeg method against 13 state-of-the-art semantic segmentation methods and 6 long-tail approaches across three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The evaluation metric is mean Intersection over Union (mIoU). The results are broken down into overall performance, as well as performance on head, middle, and tail classes. The best and second-best performing methods are highlighted.
This table presents a comparison of the performance of the proposed AUCSeg method against other state-of-the-art semantic segmentation methods on three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The evaluation metric used is mean Intersection over Union (mIoU). The table shows the overall mIoU, as well as the mIoU for head, middle, and tail classes. The best-performing method for each metric is highlighted in bold, and the second-best is underlined. This allows for a direct comparison of the effectiveness of different methods in handling long-tailed distributions in pixel-level semantic segmentation.

This table presents a quantitative comparison of the average number of pixels belonging to head and tail classes per image across three different datasets: ADE20K, Cityscapes, and COCO-Stuff 164K. The data highlights the class imbalance present in these datasets, showcasing a significantly larger number of head class pixels compared to tail class pixels.

This table compares the performance of the proposed Tail-class Memory Bank (TMB) against a Pixel-level Memory Bank (PMB) in terms of mean Intersection over Union (mIoU) across three benchmark datasets (ADE20K, Cityscapes, and COCO-Stuff 164K). The PMB stores all pixel classes, while the TMB focuses on storing only tail class pixels. The results demonstrate the effectiveness of TMB compared to PMB, highlighting its efficiency in terms of memory usage without significant performance loss.

This table presents the ablation study on different memory bank update strategies. The strategies compared are random sampling, FIFO, LIFO, and PU. The results are evaluated in terms of mIoU across overall, head, middle, and tail classes on the ADE20K dataset. The random update strategy shows the best results overall but is surpassed by the FIFO strategy on tail classes.

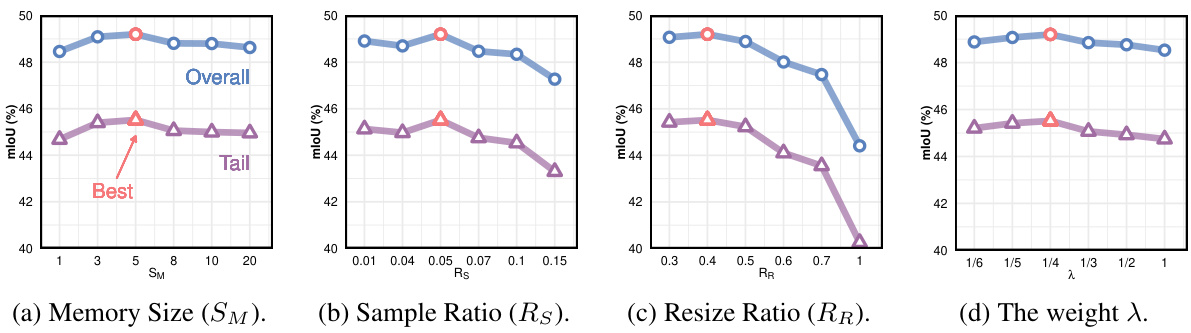
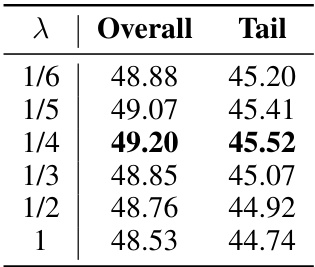
This table presents the ablation study on the impact of the sample ratio (Rs) on the performance of the proposed AUCSeg method. The sample ratio is a hyperparameter that controls the number of tail classes selected from the T-Memory bank for augmentation. The table shows the overall and tail mIoU achieved for different Rs values on the ADE20K dataset. The best performance is observed at Rs=0.05.

This table presents the ablation study results on the impact of the memory size (SM) on the performance of the proposed AUCSeg model. The mIoU (mean Intersection over Union) metric is used to evaluate the overall and tail class segmentation performance. The results are presented for different values of SM (1, 3, 5, 8, 10, and 20), showing how the memory size affects the model’s ability to learn and generalize, especially for tail classes.

This table presents the results of the AUCSeg method using different model sizes (tiny, small, base, and large) of the SegNeXt backbone network. The mIoU (mean Intersection over Union) metric is used to evaluate the performance on overall semantic segmentation and specifically on tail classes. It demonstrates the effectiveness of AUCSeg across various model sizes.
This table presents a comparison of the performance of different semantic segmentation methods on three benchmark datasets: Cityscapes, ADE20K, and COCO-Stuff 164K. The results are measured using mean Intersection over Union (mIoU) and are broken down into overall performance, as well as performance on head, middle, and tail classes. The best and second-best performing methods are highlighted for each category.

This table presents a comparison of the model’s performance (measured by mean Intersection over Union or mIoU) on three benchmark datasets (Cityscapes, ADE20K, and COCO-Stuff 164K) across different categories (Overall, Head, Middle, and Tail). The results show the mIoU for various semantic segmentation methods, highlighting the best-performing (champion) and second-best-performing (runner-up) models for each dataset and category.
Full paper#