TL;DR#
Current unsupervised semantic segmentation methods often struggle with the inherent ambiguity of variable granularity in natural scene groupings. They frequently rely on dataset-specific priors, limiting their generalizability. This introduces biases and hinders accurate, unbiased parsing of image structures.
This research tackles this challenge head-on. It proposes a new algebraic method using self-supervised models’ latent representations to identify semantic regions recursively, dynamically estimating components and ensuring smoothness. This innovative approach yields a hierarchy-agnostic semantic regions tree, capturing fine and coarse details for nuanced segmentation. The method is validated through new metrics, demonstrating improved accuracy and unbiasedness compared to existing techniques.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in unsupervised image segmentation and self-supervised learning. It offers a novel algebraic methodology that surpasses existing methods by addressing the ambiguity of granularity levels in semantic segmentation. The robust framework, validated across diverse datasets, opens new avenues for unbiased and detailed scene parsing, impacting applications like autonomous driving and image analysis.
Visual Insights#
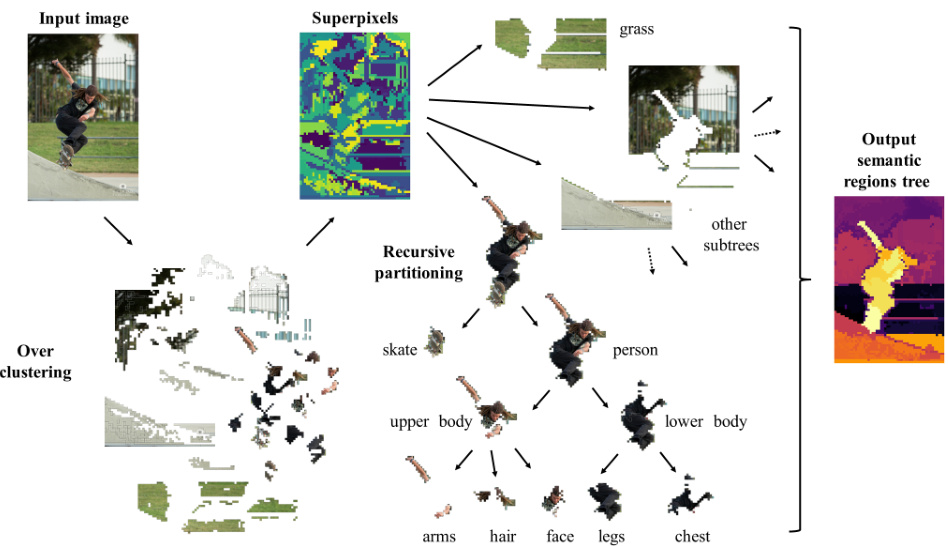
🔼 This figure illustrates the process of unsupervised hierarchy-agnostic image segmentation. It starts with an input image that is first processed into superpixels. These superpixels are then over-clustered, resulting in finer image parts. The algorithm then recursively partitions these parts into coarser regions at multiple granularity levels, forming a hierarchical tree structure. The tree represents the semantic segmentation of the image, with nodes representing semantic regions, and the arrangement of nodes reflecting their semantic distance. A color-coded heatmap visually represents this distance.
read the caption
Figure 1: Unsupervised hierarchy-agnostic segmentation. Finer image parts are generated via over-clustering, each region colour-coded randomly. Our algorithm recursively partitions these parts, grouping them into coarser regions across multiple levels of granularity. The resulting tree represents an unsupervised hierarchical semantic segmentation. The arrangement of regions in the tree reflects their semantic distance, which is colour-coded in the heat map shown on the right.
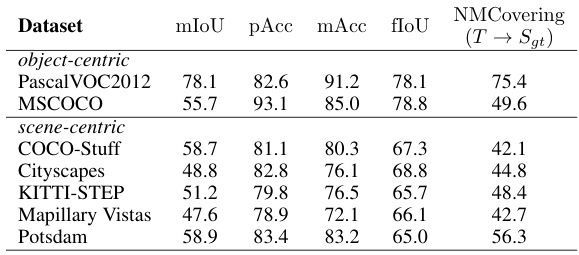
🔼 This table presents the results of the proposed granularity-agnostic unsupervised semantic segmentation algorithm. It evaluates performance across seven major datasets, each characterized by different object and scene types and granularities. The results, displayed as mIoU (mean Intersection over Union), pAcc (pixel accuracy), mAcc (mean accuracy), and fIoU (frequency weighted IoU), alongside the NMCovering metric (which evaluates overall segmentation quality without considering a specific granularity level), demonstrate the algorithm’s effectiveness in diverse scenarios.
read the caption
Table 1: Granularity-agnostic. Evaluation of our algorithm on different datasets using a maximum overlap heuristic for category matching.
In-depth insights#
Unsupervised Parsing#
Unsupervised parsing tackles the challenge of extracting meaningful information from data without relying on labeled examples. This is particularly relevant in image analysis where generating labeled datasets can be costly and time-consuming. The core idea revolves around leveraging self-supervised models, which learn rich representations of image data without human intervention. These representations capture inherent structural and semantic relationships present in the images. An unsupervised parsing algorithm would then use these learned representations to segment images into meaningful parts, discovering underlying structure and potentially hierarchical relationships between these parts. Unlike supervised methods, this approach is agnostic to pre-defined labels or hierarchies, making it adaptable to different datasets and image types. Key challenges include handling the inherent ambiguity of image segmentation, defining robust metrics to evaluate the quality of the generated parse tree, and ensuring scalability to large datasets. A successful unsupervised parsing method could have significant implications for various image analysis applications, particularly in scenarios where labeled data is scarce or impossible to obtain.
Recursive Partitioning#
Recursive partitioning, in the context of unsupervised semantic segmentation, is a powerful technique for parsing hierarchical image structures. It leverages the inherent nested nature of scenes, iteratively refining a segmentation by recursively dividing regions into increasingly smaller, more homogenous parts. This approach elegantly handles the ambiguity of variable granularity in natural object groupings, unlike methods relying on dataset-specific priors. The process continues until a stopping criterion is met, such as reaching a minimum region size or encountering significant instability in partition quality due to perturbation. A key strength of this approach is its ability to uncover semantic relationships between scene elements without prior knowledge, instead relying on latent representations from self-supervised models to guide the partitioning process. The resulting hierarchical structure, typically visualized as a tree, facilitates a nuanced and unbiased segmentation. Recursive partitioning is computationally intensive, but effective algorithms can leverage spectral clustering techniques and graph partitioning to manage complexity, ensuring that the methodology remains scalable. The recursive nature also provides a means to capture both fine and coarse-grained semantic details within an image, resulting in a superior level of representation compared to flat segmentation methods.
Granularity Metrics#
Evaluating image segmentation models requires robust metrics capable of assessing performance across varying levels of detail. Granularity metrics are crucial for evaluating the ability of a model to accurately identify objects and their parts at different scales. A good granularity metric should capture both fine-grained details (individual parts) and coarse-grained structures (objects and scenes), providing a nuanced evaluation of the segmentation’s completeness and accuracy. Ideally, such metrics should be hierarchy-agnostic, meaning they work regardless of the specific arrangement of parts and objects in the image, rather than relying on predefined hierarchies. Challenges in developing these metrics include handling various image datasets with different object complexities, dealing with image noise and ambiguity, and ensuring computational feasibility. A good granularity metric needs to be unbiased, avoiding inherent biases in dataset annotations or model assumptions. Furthermore, the metric should be easily interpretable and provide a clear indication of the model’s ability to capture meaningful semantic information in the image.
Algorithm Stability#
Algorithm stability is paramount for reliable and reproducible results in any machine learning application. In the context of unsupervised semantic image segmentation, stability refers to the algorithm’s robustness against variations in input data, model parameters, or even the underlying self-supervised model’s representations. A stable algorithm would consistently identify similar semantic regions across various images of the same scene, regardless of minor differences in viewpoint or lighting conditions. This characteristic is crucial for ensuring the generalizability of the segmentation results to unseen data. Factors influencing stability could include the choice of self-supervised backbone model, spectral clustering methodology, recursive partitioning strategy, and the use of post-processing techniques like Conditional Random Fields (CRFs). A thorough analysis of algorithm stability should involve quantitative metrics like NMCovering or NHCovering, and qualitative assessments of segmentation results. Rigorous testing across various datasets with different characteristics is necessary to evaluate the algorithm’s resilience against diverse visual conditions. The selection and tuning of hyperparameters also play a critical role. In essence, establishing algorithm stability involves demonstrating the robustness and consistency of the semantic segmentation results under a variety of conditions and variations, ultimately leading to greater confidence in its application.
Future Directions#
Future research could explore enhancing the model’s scalability by investigating more efficient graph partitioning techniques and exploring alternative graph representations beyond the current weighted adjacency matrix. Improving the model’s ability to handle diverse visual conditions, such as varying lighting, occlusion, and viewpoint changes, is crucial. Addressing the limitations of relying solely on self-supervised features and potentially integrating other modalities, such as depth or motion information, could enhance the model’s accuracy and robustness. Further research into the theoretical foundations and perturbation stability aspects of the algebraic methodology is warranted. Development of more sophisticated evaluation metrics that go beyond simple overlap measures to capture the nuances of hierarchical semantic segmentation is a key area for future improvement. Exploring the model’s applicability to various downstream tasks, such as object recognition, scene understanding, and video analysis, would demonstrate its broader impact and potential.
More visual insights#
More on figures

🔼 This figure shows qualitative results of the proposed unsupervised hierarchy-agnostic segmentation algorithm applied to three different datasets: PascalVOC2012, COCO-Stuff, and Cityscapes. For each dataset, the figure presents example images with their corresponding segmentation results. The results are displayed in two columns: one showing the hierarchical semantic segmentation (Hierarchy) where pixels with similar semantic meaning are assigned the same color, and another showing a flat category-based segmentation (Category) with random color assignments. This visualization helps to highlight the algorithm’s ability to capture the semantic relationships between different parts of an image across multiple levels of granularity. The hierarchical segmentation reveals a nuanced understanding of the image structure.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.
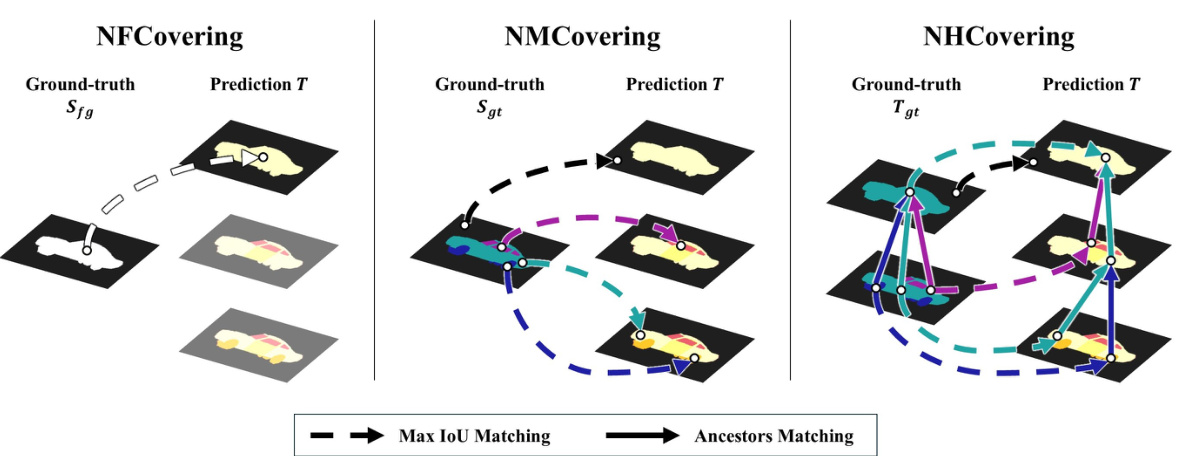
🔼 This figure compares three different metrics used to evaluate the quality of semantic segmentation in the paper. NFCovering measures the overlap between the predicted segmentation and the ground truth at a single granularity level, focusing only on the foreground. NMCovering extends this by considering multiple granularity levels and including both foreground and background. Finally, NHCovering incorporates hierarchical consistency, evaluating not only the overlap but also the accuracy of the hierarchical relationships between regions. The colored arrows in the diagram highlight category-specific matches.
read the caption
Figure 3: Comparison of segmentation metrics. NFCovering evaluates single-level foreground overlap, NMCovering extends across multiple granular levels for all categories, and NHCovering integrates hierarchical consistency. Coloured arrows indicate category-specific matches.

🔼 This figure shows qualitative results of the proposed unsupervised hierarchy-agnostic segmentation algorithm on three different datasets: Pascal VOC2012, COCO-Stuff, and Cityscapes. Each dataset is represented in a row. The figure consists of three columns for each dataset. The first column shows the input image. The second column displays the hierarchical semantic segmentation results, where each color represents a different level of the hierarchy, allowing for visualization of the hierarchical relationships between different semantic parts. The third column shows a simpler segmentation, randomly assigning colors to each region, without considering the hierarchical structure. This comparison helps to visually highlight the effectiveness of the proposed method in producing a nuanced and hierarchical segmentation compared to a simpler, flat segmentation.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.
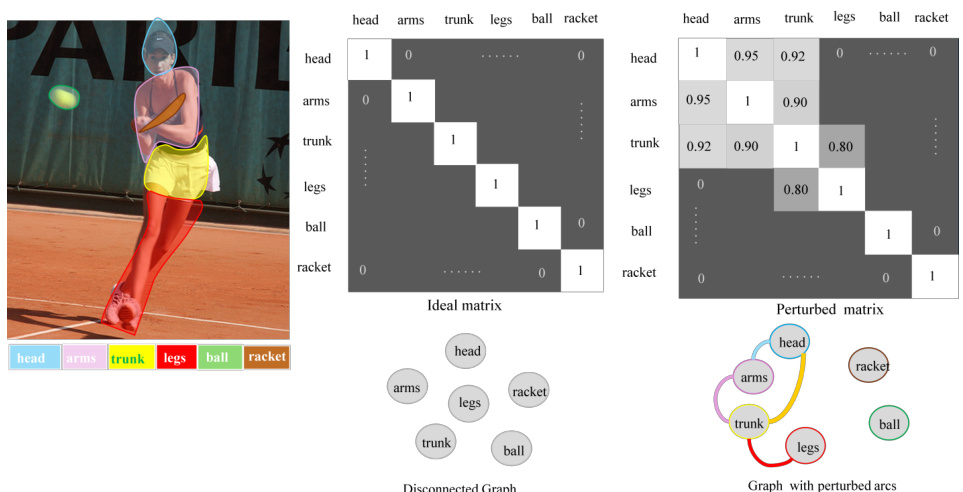
🔼 This figure illustrates the concept of ideal versus perturbed adjacency matrices in the context of graph-based image segmentation. The ideal matrix represents a perfectly segmented image where parts are completely independent; the perturbed matrix shows the reality of images where some level of similarity and connection exists between parts, introducing noise into the segmentation process.
read the caption
Figure 5: An example of ideal and perturbed adjacency matrices. The left shows an input image with highlighted parts and a colour legend. The central matrix represents the ideal adjacency matrix W', corresponding to the Laplacian L', with non-zero diagonal blocks for k' disconnected components at a specific semantic granularity. Below, a disconnected graph illustrates these isolated parts. On the right, the perturbed adjacency matrix W introduces off-diagonal entries due to pixel similarity across regions, resulting in the perturbed Laplacian L. Below, a graph with added connections shows these perturbations, with colours matching the highlighted parts in the input image.

🔼 This figure shows example results of the proposed algorithm. The left column shows the input images. The middle column shows the results of the first step, which involves a coarse semantic parts extraction using quantization. The right column shows the results of the second step which is a fine semantic hierarchy extraction using recursive grouping. The colormap shows the distances between tree leaves.
read the caption
Figure 6: The algorithm's two steps outputs. First, we quantize the graph to create an initial over-clustering of semantic parts. Next, we recursively group these parts, forming multi-level semantic clusters from coarse to fine granularity. The heatmap colour-codes the distance between tree leaves.
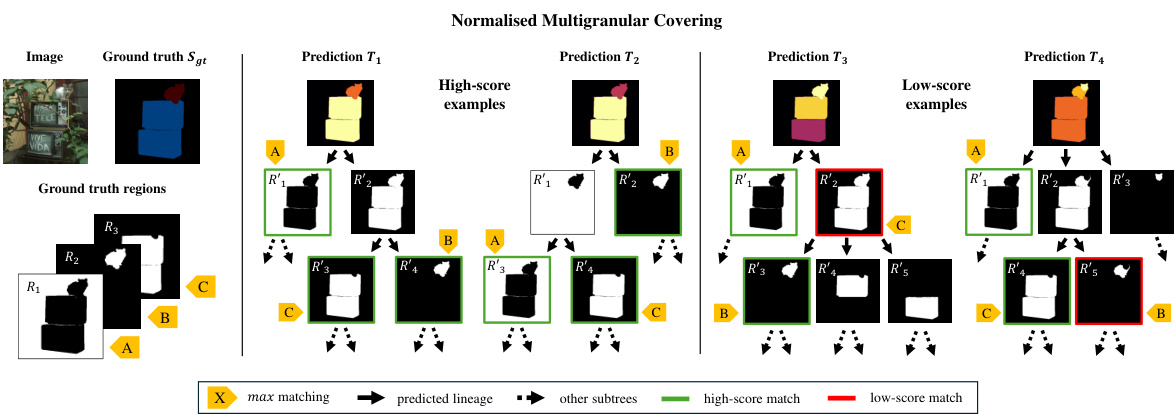
🔼 This figure illustrates the NMCovering metric, which evaluates the quality of semantic segmentation by comparing predicted regions (from the generated semantic region tree) with ground truth regions. It shows examples of high-scoring and low-scoring predictions, highlighting the impact of correctly identifying semantic regions across multiple levels of granularity.
read the caption
Figure 7: Normalised Multigranular Covering (NMCovering) examples. For each available ground truth categorical region R in the semantic map Sgt (left), we evaluate the overlap with the unrolled segments R' in the predicted region tree, e.g. T₁. The yellow labels indicate the maximum IoU matching correspondence between the ground truth and the prediction. Green line borders indicate high-score matching and red line borders indicate low-score matching. We propose two high-scoring predictions (centre) and two low-scoring (right). The total NMCovering is the average sum of the matching scores, as defined in Equation (3). The NMCovering metric evaluates the granularity-independent performance of the semantic segmentation model. The absence of correct semantic regions in T3 and T4 yields low score matches; see plate C in T3 and plate B in T4.
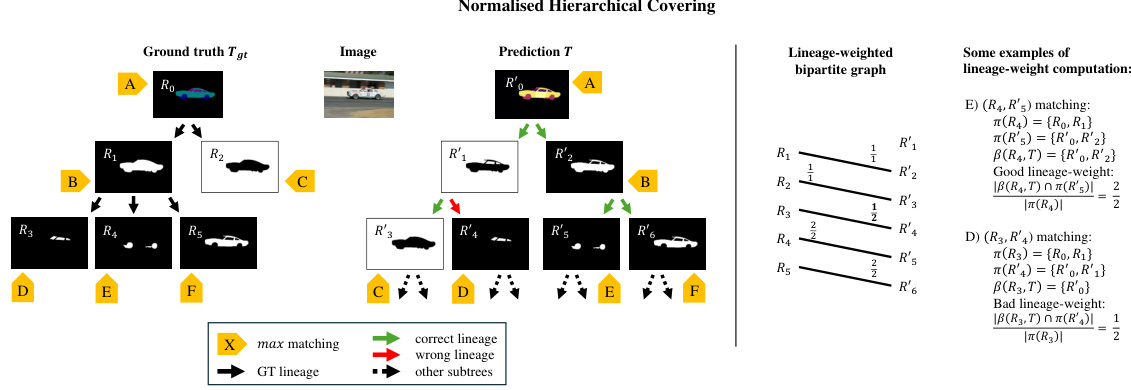
🔼 This figure illustrates the calculation of the Normalized Hierarchical Covering (NHCovering) metric. It shows how the algorithm compares the predicted semantic hierarchy (tree T) with the ground truth hierarchy (tree Tgt). The metric considers not only the overlap of regions at each level but also the correctness of the hierarchical relationships between those regions. Green arrows indicate correctly predicted hierarchical relationships, while red arrows show incorrect ones. The example demonstrates how the lineage-weight calculation favors matches with accurate ancestor relationships.
read the caption
Figure 8: Normalised Hierarchical Covering (NHCovering) computation example. Given the semantic tree Tgt (left), for each available ground truth categorical region R, we evaluate the overlap with the unrolled segments R' in the predicted region tree T. We consider one low-score lineage prediction edge (R1, R₁) and one high-score (R2, R5). The yellow labels indicate the maximum IoU matching correspondence between the ground truth and the predicted regions. Green and red arrows indicate correct and wrong lineage prediction, respectively. The total NHCovering is the sum of the matching scores weighted by the ratio of correct lineages, as reported in Equation (4). The NHCovering metric assesses the granularity and hierarchy-independent performance of the semantic segmentation model. Examples of lineage-weight computation are reported for the E and D matching, on the right, using the operators π(·) and ẞ(,) defined in Section 4.1.

🔼 This figure displays qualitative results of the proposed unsupervised hierarchy-agnostic image segmentation algorithm on three major datasets: Pascal VOC2012, COCO-Stuff, and Cityscapes. Each image shows three columns: input image, pixel semantic hierarchy (color-coded), and random color-coded categories. The color-coding in the ‘Hierarchy’ column helps visualize the hierarchical relationships between pixels, making it easy to see how the algorithm groups semantically similar pixels together at multiple levels of granularity. This visual representation demonstrates the algorithm’s ability to capture both fine and coarse semantic details, producing a nuanced and unbiased segmentation.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.

🔼 This figure compares three different metrics used to evaluate the quality of semantic segmentation: Normalized Foreground Covering (NFCovering), Normalized Multigranular Covering (NMCovering), and Normalized Hierarchical Covering (NHCovering). NFCovering only considers single-level foreground overlap, while NMCovering accounts for multiple granularity levels and all categories. NHCovering further incorporates hierarchical consistency. The colored arrows in the figure highlight the matches between predicted and ground-truth segmentations at different granularity levels.
read the caption
Figure 3: Comparison of segmentation metrics. NFCovering evaluates single-level foreground overlap, NMCovering extends across multiple granular levels for all categories, and NHCovering integrates hierarchical consistency. Coloured arrows indicate category-specific matches.

🔼 This figure displays qualitative results of the proposed unsupervised hierarchy-agnostic segmentation algorithm applied to three major datasets: PascalVOC2012, COCO-Stuff, and Cityscapes. Each image is shown with two representations: a ‘Hierarchy’ visualization that color-codes pixels according to their position within the resulting semantic hierarchy and a ‘Category’ visualization where regions are randomly colored. The goal is to visually demonstrate the algorithm’s ability to segment images at multiple granularity levels and to show how it captures the hierarchical relationships between parts and objects in a scene.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.

🔼 This figure shows the qualitative results of the proposed unsupervised hierarchy-agnostic segmentation algorithm on three popular image segmentation datasets: PascalVOC2012, COCO-Stuff, and Cityscapes. Each dataset presents unique segmentation challenges regarding object and scene complexity. The figure displays sample images from each dataset, organized into columns representing input images, resulting semantic hierarchy (color-coded to represent semantic relationships), and resulting category labels (randomly colored for visual distinction). The visualization demonstrates the algorithm’s ability to produce a detailed and nuanced segmentation across varying levels of granularity, revealing the hierarchical relationships between image components.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.

🔼 This figure shows the qualitative results of the proposed unsupervised hierarchy-agnostic segmentation algorithm on three different datasets: PascalVOC2012, COCO-Stuff, and Cityscapes. For each dataset, it displays input images alongside their corresponding semantic segmentations. The ‘Hierarchy’ columns use a color-coding scheme to visualize the hierarchical relationships between semantic regions, allowing for easy visual identification of pixels belonging to similar semantic categories. In contrast, the ‘Category’ columns use random colors for each category, providing a clearer visual distinction between different semantic groups. The figure effectively demonstrates the algorithm’s ability to capture both fine-grained details and coarse semantic structures within images.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.

🔼 This figure shows qualitative results of the proposed unsupervised hierarchy-agnostic image segmentation algorithm on three major datasets: Pascal VOC2012, COCO-Stuff, and Cityscapes. Each image is displayed with two representations: a hierarchical representation, where colors represent the semantic hierarchy of the pixels, allowing for visualization of the hierarchical relationships between image components; and a categorical representation, where colors are randomly assigned to categories, enabling a clear visual distinction between different semantic regions in the image. These visualizations illustrate the algorithm’s ability to parse semantic image structures at multiple granularity levels. The consistent results across different datasets highlight the generalizability and robustness of the method.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.

🔼 This figure shows qualitative results of the proposed unsupervised hierarchy-agnostic segmentation algorithm on three major datasets: Pascal VOC2012, COCO-Stuff, and Cityscapes. Each dataset presents unique challenges in terms of object categories, scene complexity, and annotation granularity. The figure demonstrates the algorithm’s ability to segment images into semantic regions across multiple levels of detail. The ‘Hierarchy’ columns use color-coding to represent the semantic hierarchy discovered by the algorithm, enabling a visual comparison of pixels with similar semantic relationships. The ‘Category’ columns utilize random color-coding, facilitating easier discrimination between semantically close pixels, even if those pixels are visually similar. The results showcase the algorithm’s robustness and applicability in parsing semantic image structure across diverse datasets.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.

🔼 This figure displays qualitative results from the proposed unsupervised hierarchy-agnostic segmentation algorithm. It showcases the algorithm’s performance on three different datasets: PascalVOC2012, COCO-Stuff, and Cityscapes. Each image is divided into three columns. The first shows the input image. The second displays the hierarchical semantic segmentation, with each pixel color-coded based on its position in the semantic hierarchy. The third column shows a random color-coding of semantic categories. The color-coding in the second column helps to visualize the hierarchical relationships between different image parts. By comparing the hierarchy-based color-coding with the random category color-coding, one can appreciate the algorithm’s ability to discover meaningful semantic relationships in images.
read the caption
Figure 2: Qualitative results of our algorithm on PascalVOC2012, COCO-Stuff and Cityscapes datasets. The Hierarchy columns colour-code the pixel semantic hierarchy, and the Category columns are random colour-coded, helping visually discriminate hierarchically close pixels.

🔼 This figure shows qualitative results of the proposed unsupervised semantic segmentation method on the Cityscapes dataset. It presents a random selection of images where the algorithm achieved an NMCovering score above 40%. The results have been post-processed using Conditional Random Fields (CRF) to sharpen boundaries. Each image displays the original image alongside a color-coded segmentation map. The color coding represents the semantic labels assigned by the algorithm to different image parts. A legend in the bottom explains the correspondence between colors and semantic labels.
read the caption
Figure 14: Qualitative results on Cityscapes. Random sampling from a subset of our results, refined with CRF, with NMCovering greater than 40%. We assign unsupervised masks to the best overlapping classes.
More on tables
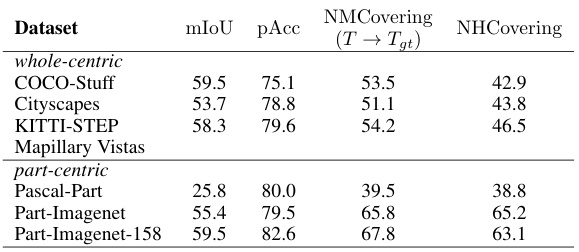
🔼 This table presents the results of the proposed hierarchy-agnostic semantic segmentation algorithm on various datasets. It specifically evaluates the performance using the NHCovering and NMCovering metrics, which assess the quality of the segmentation and its adherence to the semantic hierarchy present in the ground truth data. The datasets are categorized into whole-centric (where the focus is on entire scenes) and part-centric (where the focus is on individual object parts) for clearer comparison of the algorithm’s performance in different contexts. mIoU and pAcc are also included as traditional evaluation metrics.
read the caption
Table 2: Hierarchy-agnostic. Evaluation of our algorithm on different datasets using a maximum overlap heuristic for category matching.
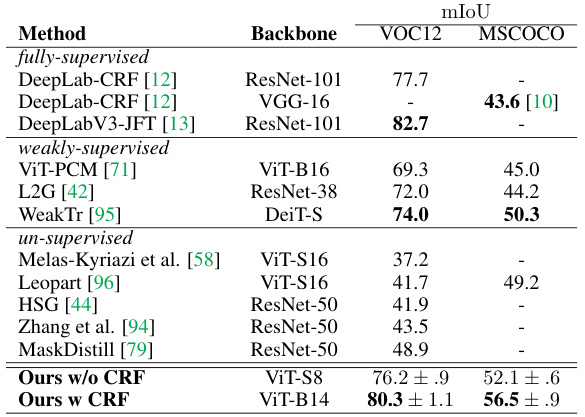
🔼 This table presents a comparison of semantic segmentation performance on the PascalVOC2012 validation set. It compares the performance of the proposed unsupervised method (both with and without CRF post-processing) against several other fully-supervised and weakly-supervised methods. The results are presented in terms of mIoU (mean Intersection over Union), indicating the overall accuracy of the segmentation. The table highlights the competitive performance of the proposed method, particularly when CRF post-processing is included, demonstrating its ability to achieve results comparable or superior to other state-of-the-art approaches.
read the caption
Table 3: Semantic segmentation. Comparison on PascalVOC2012 val. Ours match unsupervised masks to best overlapping classes.

🔼 This table compares the performance of different boundary potential methods for unsupervised semantic segmentation on the PascalVOC2012 dataset. The methods compared include SE-OWT-UCM, PMI-OWT-UCM, and the proposed method (Ours) with and without CRF. The evaluation metric used is mIoU, pAcc (the pixel accuracy that assigns the unsupervised masks to the best overlapping classes), and NHCovering (a new metric introduced in the paper to evaluate the hierarchical consistency of the segmentation). The results show that the proposed method outperforms the other methods in terms of both mIoU and NHCovering, demonstrating its effectiveness in capturing hierarchical relationships between scene elements.
read the caption
Table 4: Boundary potential methods. All methods match unsupervised tree segments to best overlapping classes.

🔼 This table compares the performance of the proposed unsupervised semantic segmentation method against several other methods on the PascalVOC2012 validation set. It shows the mIoU (mean Intersection over Union), pAcc (pixel accuracy), mAcc (mean accuracy), fIoU (frequency weighted IoU), and NMCovering (Normalized Multigranular Covering) scores for various methods, including fully supervised, weakly supervised, and unsupervised approaches. The table highlights the competitive performance of the proposed method compared to existing techniques.
read the caption
Table 3: Semantic segmentation. Comparison on PascalVOC2012 val. Ours match unsupervised masks to best overlapping classes.
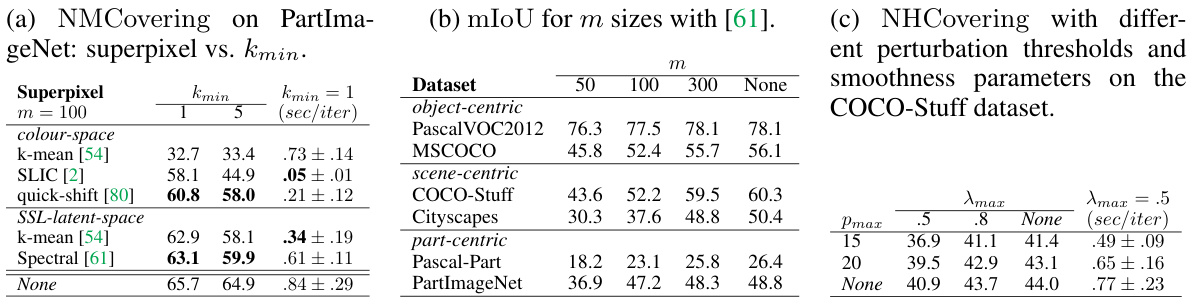
🔼 This table presents ablation studies evaluating the impact of different superpixel methods, the number of superpixels (m), and the parameters kmin, Pmax, and λmax on the performance of the proposed algorithm. Specifically, (a) shows the effect of various superpixel methods on NMCovering for PartImageNet, (b) shows how the number of superpixels impacts mIoU across several datasets, and (c) demonstrates the relationship between perturbation thresholds (Pmax), smoothness parameters (λmax), and NHCovering on COCO-Stuff.
read the caption
Table 6: Superpixel and parameters ablation experiments. (a) NMCovering on PartImageNet: superpixel vs. kmin. (b) mIoU for m sizes with [61]. (c) NHCovering with different perturbation thresholds and smoothness parameters on the COCO-Stuff dataset.

🔼 This table presents the results of hierarchical semantic segmentation on the Potsdam and Vaihingen datasets using the proposed algorithm. The DINO-ViT-B8 model and Amax parameter value 0.9 were used. The results are evaluated using the NMCovering metric with exclusive matching against ground truth masks. The table shows the performance (in terms of NMCovering, mIoU, pAcc, mAcc, and fIoU) for each of the six categories in each dataset.
read the caption
Table 8: Hierarchical semantic segmentation on Potsdam and Vaihingen train sets. We use DINO-ViT-B8 [11] features and Amax = 0.9. The two datasets have six categories. Segmentation performances are computed using NMCovering for ground truth masks exclusive matching.

🔼 This table compares the performance of different hierarchical clustering algorithms on the PascalVOC2012 dataset using the NMCovering metric. It specifically contrasts methods based on boundary potentials (SE-OWT-UCM, PMI-OWT-UCM) with methods using semantic smoothness (Ours). The results highlight the superior performance of the semantic smoothness approach, demonstrating its effectiveness in capturing hierarchical relationships within image data for semantic segmentation.
read the caption
Table 7: Boundary potential vs. semantic smoothness. Comparison among hierarchical clustering algorithms in terms of NMCovering on PascalVOC2012 val set for Amax = 0.6.
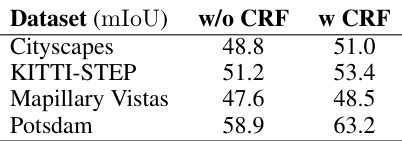
🔼 This table presents the ablation study of the Conditional Random Field (CRF) post-processing step on the performance of the proposed unsupervised semantic segmentation algorithm. It compares the mean Intersection over Union (mIoU) scores achieved on four different datasets (Cityscapes, KITTI-STEP, Mapillary Vistas, and Potsdam) with and without the CRF post-processing step. The results demonstrate that the CRF step improves the segmentation accuracy on all the four datasets.
read the caption
Table 11: CRF ablation. We use maximum overlap for ground-truth category matching.

🔼 This table compares the performance of different hierarchical clustering algorithms on the PascalVOC2012 validation set, specifically focusing on the NMCovering metric. The comparison highlights the relative effectiveness of methods that leverage boundary potentials versus those employing semantic smoothness for multi-granular segmentation. The Amax parameter is fixed at 0.6. The table shows the NMCovering scores across various object categories for each method.
read the caption
Table 7: Boundary potential vs. semantic smoothness. Comparison among hierarchical clustering algorithms in terms of NMCovering on PascalVOC2012 val set for Amax = 0.6.
Full paper#



















