↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for 3D model generation from images often struggle with low resolution and inefficient use of dense view information. They neglect the inherent sparsity of 3D structures and fail to fully utilize geometric relationships between 3D points and 2D images. This results in limitations on resolution and quality. This paper tackles these issues by introducing a new approach.
The proposed GeoLRM model uses a two-stage pipeline that addresses the limitations of prior methods. The first stage uses a lightweight proposal network to generate sparse 3D points. The second stage leverages a specialized reconstruction transformer incorporating a novel 3D-aware structure and deformable cross-attention mechanisms to efficiently integrate image features and refine the geometry, thereby achieving high-quality 3D Gaussian generation. Experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs.
Key Takeaways#
Why does it matter?#
This paper is important because it presents GeoLRM, a novel approach to high-quality 3D Gaussian generation that significantly outperforms existing methods, especially with dense view inputs. It introduces a novel 3D-aware transformer structure and addresses limitations in previous works by incorporating geometric principles. This opens new avenues for research in 3D modeling, virtual reality, and robotics applications that demand high-quality, efficient 3D asset creation.
Visual Insights#
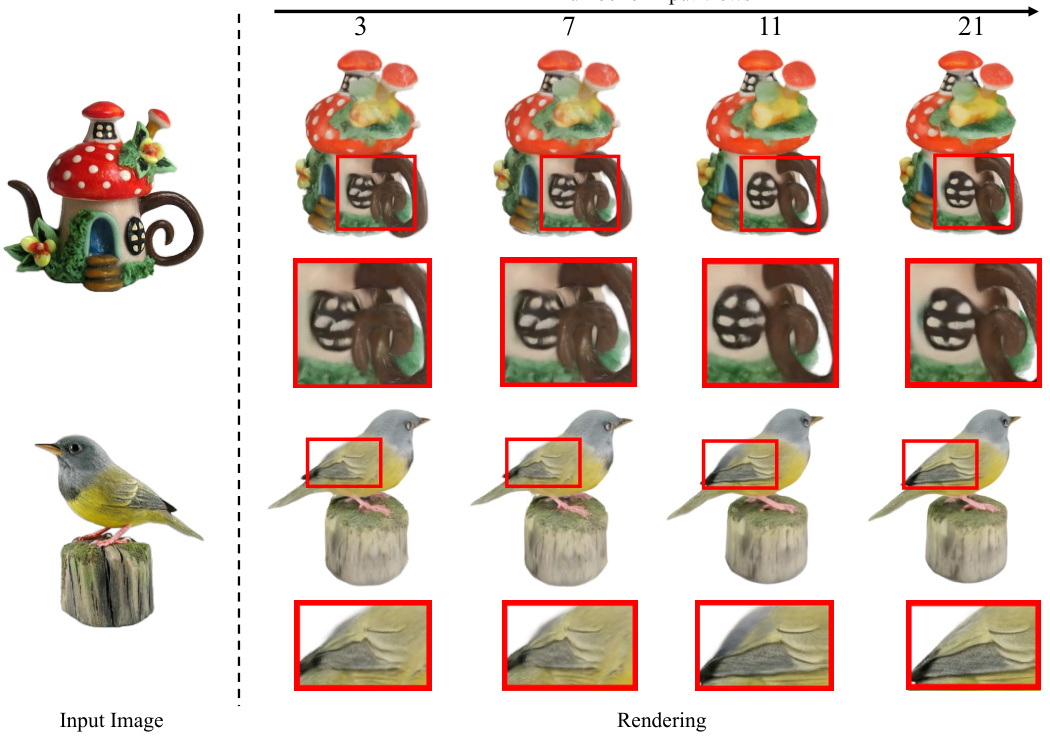
This figure shows the results of converting a single input image into a 3D model using GeoLRM. The process begins with a 3D-aware diffusion model (SV3D) generating multiple views from the input image. GeoLRM then processes these views to create a high-quality 3D asset. The figure demonstrates how the quality of the 3D model improves with an increasing number of input views, highlighting GeoLRM’s advantage over other similar methods.

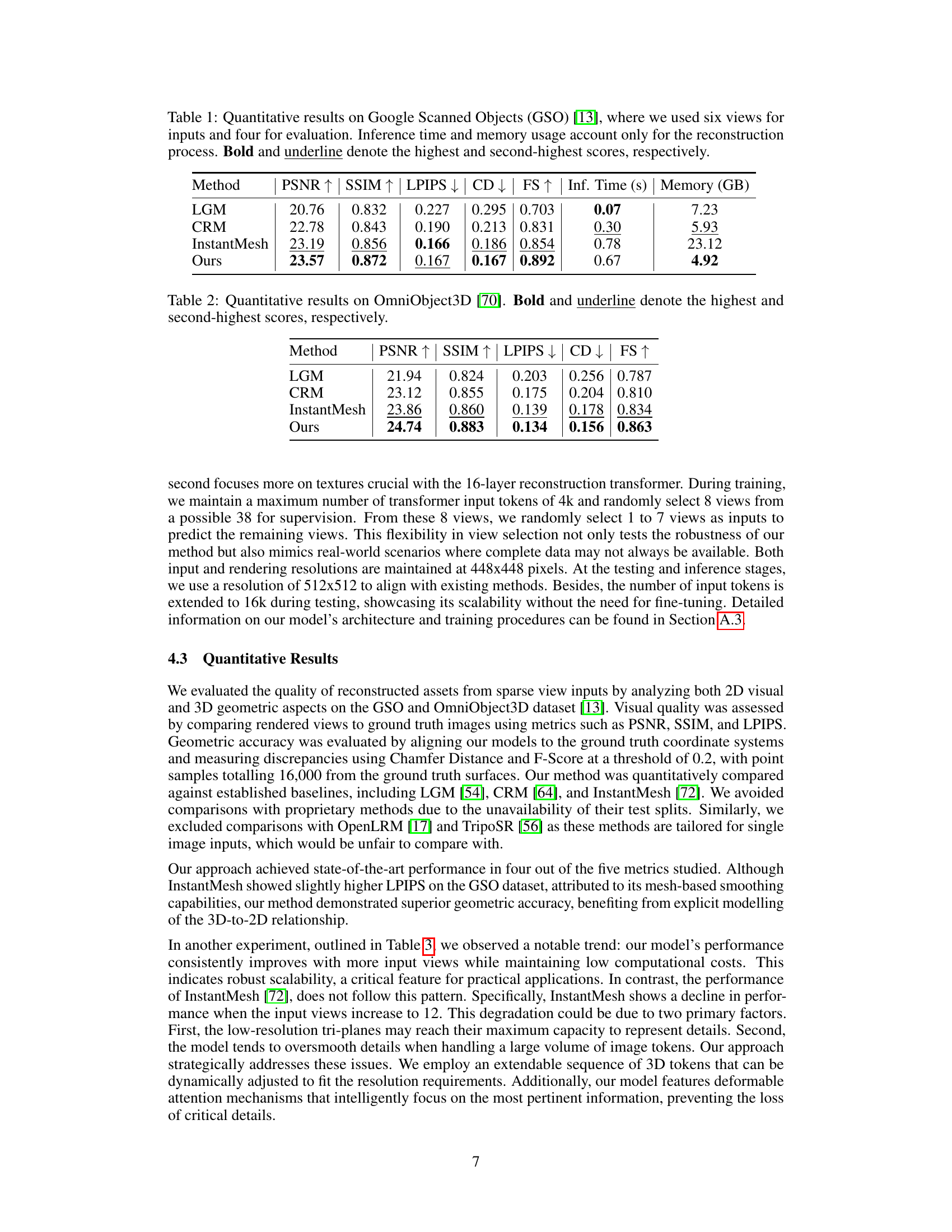
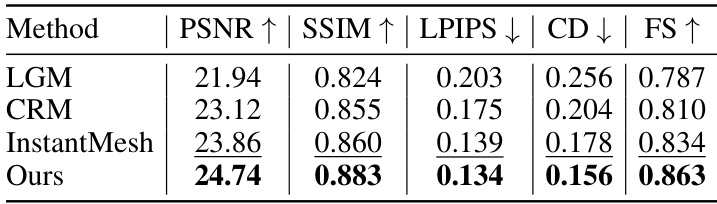
This table presents a quantitative comparison of the proposed GeoLRM model against existing state-of-the-art methods (LGM, CRM, InstantMesh) on the Google Scanned Objects dataset. The metrics used for comparison include PSNR, SSIM, LPIPS (lower is better), Chamfer Distance (CD), and F-score (FS). Inference time and memory usage are also reported, demonstrating the efficiency of GeoLRM. The bold and underlined values highlight the best and second-best performance for each metric.
In-depth insights#
3D Gaussian Gen#
Generating high-quality 3D models using Gaussian functions presents a powerful approach in the field of 3D graphics and computer vision. This technique, often referred to as “3D Gaussian Generation,” leverages the inherent properties of Gaussian distributions to represent 3D shapes effectively. Gaussians offer a smooth, continuous representation, making them particularly well-suited for capturing complex surfaces and fine details. The approach often involves predicting the parameters of these Gaussian components (position, scale, orientation, and intensity) which then collectively define the final 3D model. Several advantages stem from using Gaussian-based methods. Efficiency in rendering is one key advantage, as the smooth nature of the Gaussians can lead to fewer computations. Furthermore, the parameterization of 3D shapes using Gaussians allows for compact storage and easier manipulation and editing. However, challenges remain: effectively predicting the parameters of numerous Gaussians to accurately reconstruct complex shapes requires powerful models and significant computational resources. Robust handling of occlusion and noise in input data during the training phase is also critical. This is an active research area with potential for further improvements in terms of computational efficiency and the expressiveness of the models.
GeoLRM Model#
The GeoLRM model represents a novel approach to high-quality 3D Gaussian generation from multiple images. Its core innovation lies in a geometry-aware transformer architecture that directly processes 3D points, unlike previous methods that rely on less efficient representations. This allows GeoLRM to effectively integrate image features and explicitly leverage geometric relationships between 2D and 3D spaces. A two-stage pipeline, starting with a lightweight proposal network to generate sparse 3D anchor points, followed by a refinement stage using deformable cross-attention, enhances efficiency and accuracy. GeoLRM excels with dense view inputs, significantly outperforming existing methods in both quantitative and qualitative evaluations, demonstrating its suitability for applications demanding high-fidelity 3D assets. The model’s scalability and ability to handle a large number of input views are particularly notable strengths.
Sparse View Inputs#
The concept of ‘Sparse View Inputs’ in 3D reconstruction is crucial because it directly addresses the challenge of limited data availability. Traditional methods often require numerous images from various viewpoints to accurately reconstruct a 3D model. Sparse view input techniques aim to achieve comparable results using significantly fewer images, thus reducing the cost and effort associated with data acquisition. This is particularly beneficial in scenarios with limited accessibility or high costs related to capturing comprehensive visual data. The challenge lies in developing robust algorithms that can effectively infer the missing information from the limited available views, relying on learned representations and geometric priors to recover the complete 3D structure. Successful methods utilize sophisticated deep learning architectures, often incorporating attention mechanisms to selectively focus on relevant image features, and leverage geometric constraints to improve reconstruction accuracy. Strategies include employing 3D-aware transformers to handle sparse point clouds and incorporating geometric cues to guide the reconstruction process. Research in this area is essential for enabling efficient and cost-effective 3D modeling in real-world applications.
Ablation Study#
An ablation study systematically removes components of a model to determine their individual contributions. In this context, it would involve selectively disabling or removing parts of the GeoLRM, such as the Plücker ray embeddings, high-level or low-level image features, or the 3D RoPE positional encoding. By observing the impact of each removal on performance metrics (e.g., PSNR, SSIM, LPIPS), the ablation study reveals the importance of each element in the overall model architecture. This analysis is crucial for understanding the model’s design choices and their effectiveness, highlighting the critical role of geometry-aware components and positional encoding in achieving high-quality 3D reconstruction. Furthermore, the ablation study on the number of input views and sampling points in the deformable attention mechanism would provide valuable insights into the model’s scalability and robustness to noise and varying data conditions. The results should clearly indicate whether the model’s performance degrades significantly with the removal of crucial parts and how the chosen hyperparameters optimize the balance between performance and computational cost.
Future Work#
Future work for this research could explore several promising avenues. Extending GeoLRM to handle dynamic scenes and video inputs would significantly increase the model’s real-world applicability. This necessitates developing more robust temporal consistency mechanisms and addressing the increased computational demands of processing spatiotemporal data. Another important area involves improving the model’s ability to handle noisy or incomplete inputs, which is crucial for real-world scenarios where perfect data is rare. This could involve incorporating uncertainty estimation into the model or using data augmentation techniques to improve robustness. Furthermore, investigating the use of different 3D representations beyond Gaussians, such as point clouds or meshes, could lead to improved efficiency and fidelity. Finally, a thorough investigation of the model’s limitations, especially regarding the scalability with extremely large datasets and the potential for biased outputs, is necessary before broader deployment. Addressing ethical considerations around generating realistic 3D content, such as the potential for misuse in generating deepfakes, is also vital.
More visual insights#
More on figures

This figure illustrates the pipeline of the GeoLRM model, showing how it efficiently converts images into 3D Gaussians. It uses a two-stage process: a proposal transformer creates a sparse occupancy grid from input images, and a reconstruction transformer refines this geometry and extracts texture details using deformable cross-attention. The final output is a set of 3D Gaussians suitable for real-time rendering.
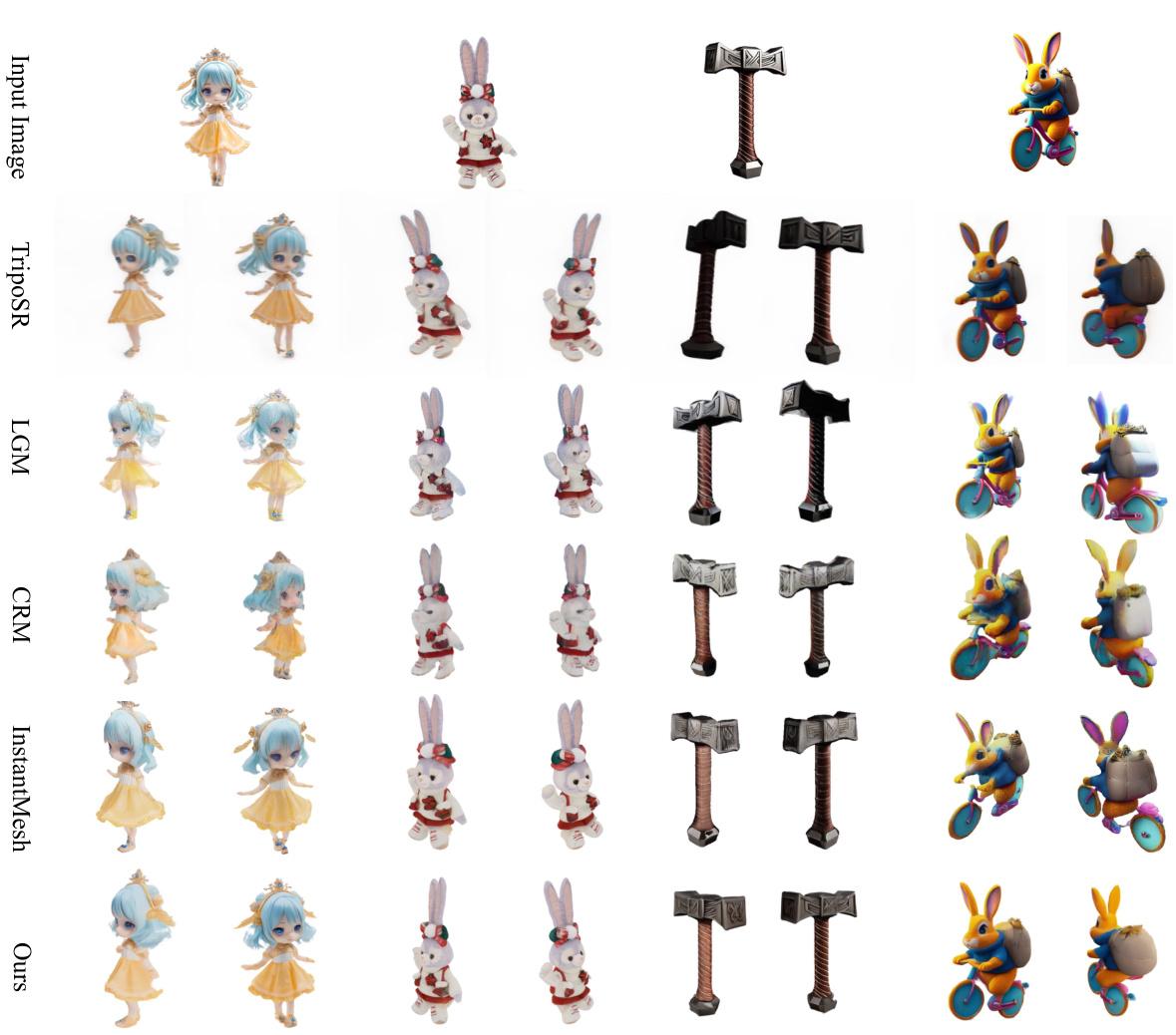
This figure presents a qualitative comparison of several image-to-3D reconstruction methods. Four different objects (a girl, a rabbit, a hammer, and a rabbit on a bicycle) are shown, each rendered using different methods including TripoSR, LGM, CRM, InstantMesh and the proposed GeoLRM. The results demonstrate the relative visual quality and level of detail achievable by each method. The figure highlights the superior rendering quality of the GeoLRM, particularly noticeable upon zooming in.
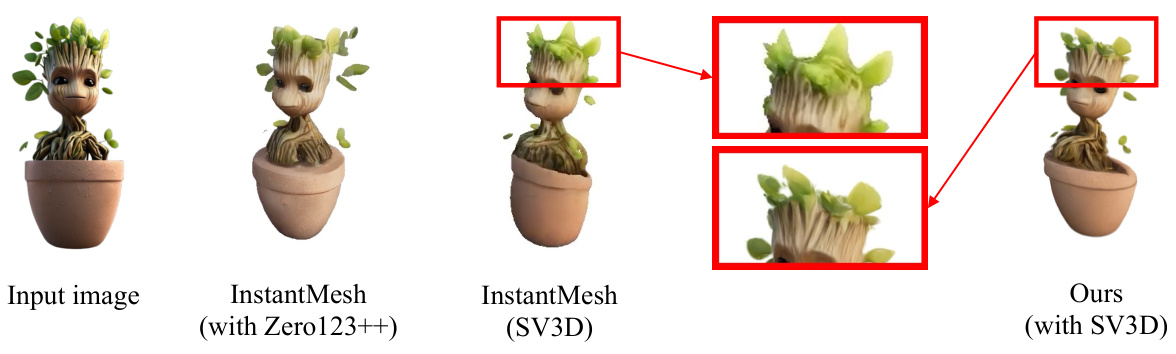
This figure compares the 3D reconstruction results of different methods using varying numbers of input views. The input image shows a small potted plant. InstantMesh (using Zero123++) produces a blurry and incomplete model. InstantMesh (using SV3D) provides a slightly better reconstruction, but still suffers from artifacts and a lack of detail. In contrast, the ‘Ours (with SV3D)’ reconstruction is significantly more detailed and accurate, demonstrating improved scalability and performance with increased input views.

This ablation study in the paper demonstrates the importance of using both high-level (semantic information like object identity and arrangement) and low-level (texture details such as surface patterns and colors) image features for accurate 3D reconstruction. Excluding high-level features results in model instability, while omitting low-level features leads to a loss of textural detail. The figure shows a qualitative comparison of the model’s reconstruction with both features included, and with each feature type removed individually.

This figure showcases the results of image-to-3D generation using mesh extraction. It presents four different objects (a mushroom cluster, a phoenix, a robot, and a Na’vi-like character). For each object, the figure displays the original input image, four rendered views from different angles, and the final extracted mesh. The rendered views demonstrate the quality of the 3D model generated from the input image, highlighting its visual realism and detail. The mesh representation provides a geometric understanding of the 3D structure and serves as the foundation for creating various visual representations of the object.
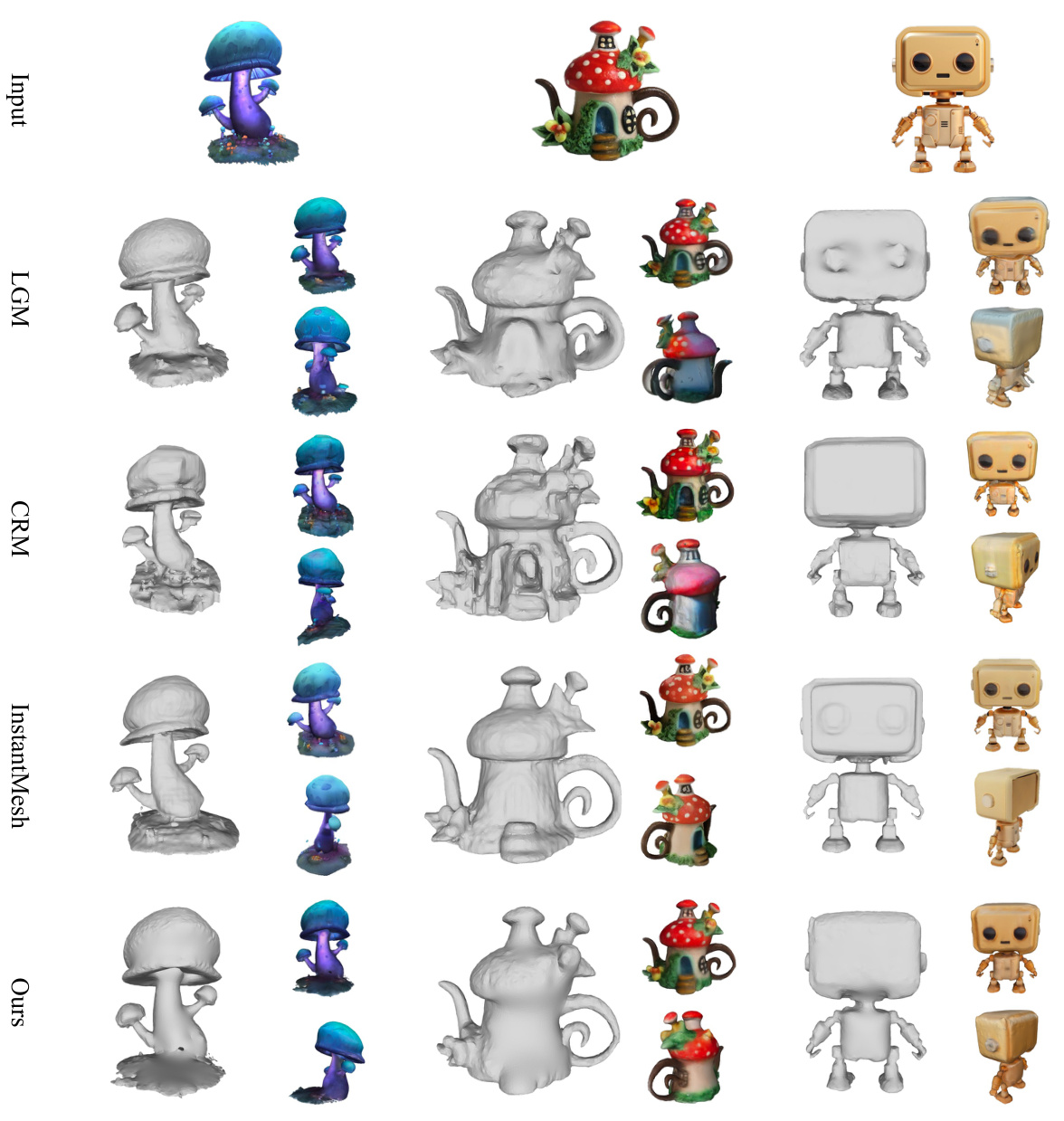
This figure shows a comparison of 3D mesh reconstruction results from different methods (LGM, CRM, InstantMesh, and Ours) on three example objects: mushrooms, teapots, and robots. Each row represents a different method, showing the generated meshes from multiple viewpoints. The figure aims to visually demonstrate the relative quality and detail of the meshes generated by each method.
More on tables
This table presents a quantitative comparison of the proposed GeoLRM model against other state-of-the-art methods on the OmniObject3D dataset. The metrics used for comparison include PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), CD (Chamfer Distance), and FS (F-Score). Higher PSNR and SSIM values, and lower LPIPS and CD values indicate better performance. The highest and second-highest scores for each metric are highlighted.
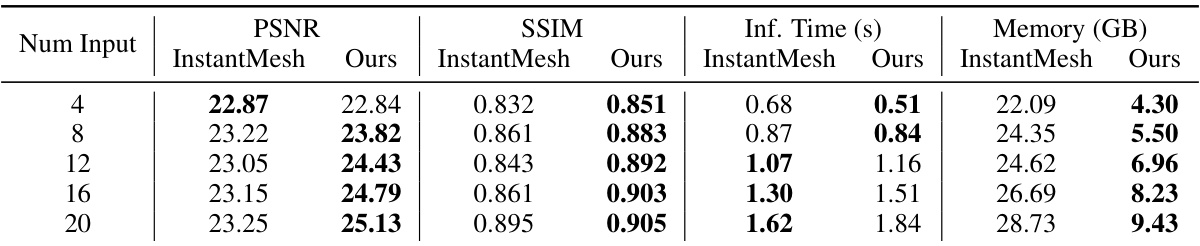
This table presents a quantitative comparison of the model’s performance using different numbers of input views. The model’s performance is evaluated using four metrics: PSNR, SSIM, inference time, and memory usage. The results show how the model’s performance improves as the number of input views increases, indicating that the model benefits from denser input data. The table shows that while the performance of InstantMesh plateaus and then declines as the input views increase, our method continues to improve.
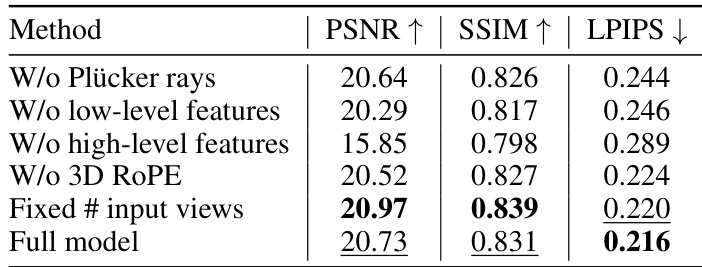
This table presents the ablation study results on the Google Scanned Objects (GSO) dataset. It shows the impact of removing different components of the GeoLRM model on its performance. The upper part of the table shows the comparison of the full model with models missing Plücker rays, low-level features, high-level features, and 3D RoPE, using 6 input views and 4 testing views. The lower part shows the influence of varying the number of input views on model performance for the full model and a model with a fixed number of input views.
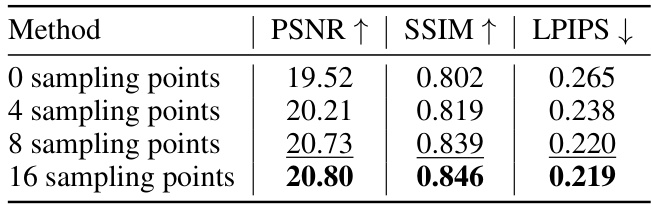
This table presents the results of an ablation study on the deformable attention mechanism. It shows the effect of using different numbers of sampling points (0, 4, 8, and 16) on the model’s performance, measured by PSNR, SSIM, and LPIPS. The results demonstrate that increasing the number of sampling points generally improves performance, suggesting that the deformable attention mechanism effectively leverages multi-view features to improve the quality of 3D reconstruction. However, there are diminishing returns with more than 8 sampling points, striking a balance between performance and computational cost.
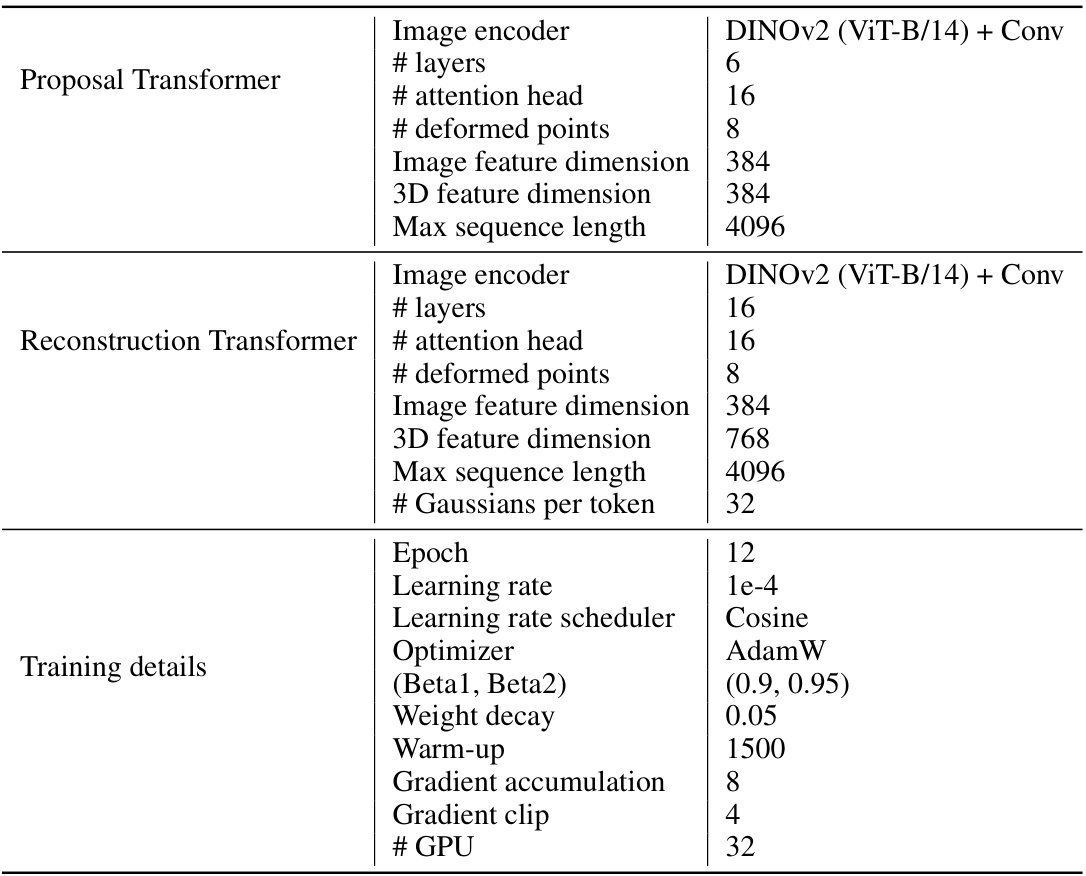
This table presents a quantitative comparison of the proposed GeoLRM model against several state-of-the-art methods on the Google Scanned Objects dataset. The comparison uses six input views and four evaluation views. Metrics include PSNR, SSIM, LPIPS, CD, and FS, along with inference time and memory usage. The best and second-best results for each metric are highlighted.
Full paper#