TL;DR#
Current object synthesis methods often struggle to create new objects that effectively combine textual descriptions with existing images; they tend to favor either the text or image. This leads to imbalanced results, where the generated objects are primarily reflections of one input, neglecting the other.
This research proposes a new method, Adaptive Text-Image Harmony (ATIH), which addresses this issue. ATIH introduces a scale factor and injection step to balance text and image features during cross-attention, thus improving both the editability and fidelity of the generated images. A balanced loss function and a similarity score function are also designed to harmonize the generated object with both the input image and text. Experimental results demonstrate that ATIH excels in creating novel and harmonious object fusions.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to object synthesis that addresses the limitations of existing methods. By introducing the Adaptive Text-Image Harmony (ATIH) method, the paper achieves a better balance between text and image features in generating novel object combinations. This work opens up new avenues for research in the field of generative models and creative image synthesis.
Visual Insights#

🔼 This figure shows example results of the proposed method for novel object synthesis. The method takes as input an image and a text description of an object and generates a new image that combines features from both. The left panel shows a glass jar combined with a porcupine, resulting in a glass jar with porcupine-like textures. The right panel shows a horse combined with a bald eagle, resulting in a horse with eagle-like features. The figure demonstrates the ability of the method to generate creative and surprising combinations of objects.
read the caption
Figure 1: We propose a straightforward yet powerful approach to generate combinational objects from a given object text-image pair for novel object synthesis. Our algorithm produces these combined object images using the central image and its surrounding text inputs, such as glass jar (image) and porcupine (text) in the left picture, and horse (image) and bald eagle (text) in the right picture.

🔼 This table presents a quantitative comparison of the proposed ATIH model with several other image editing and mixing models on a custom object text-image fusion (OTIF) dataset. The comparison uses five metrics: DINO-I (image similarity), CLIP-T (text-image similarity), AES (aesthetic score), HPS (human preference score), Fscore (a novel similarity score combining text and image similarities), and Bsim (balance similarity). Higher scores are better for all metrics except Bsim, where a lower score indicates better balance between text and image features in the generated images. The results show that ATIH achieves the best performance in AES, HPS, Fscore and Bsim metrics, suggesting superior visual appeal, human preference, and harmonious integration of text and image features compared to other models.
read the caption
Table 1: Quantitative comparisons on our TIF dataset.
In-depth insights#
Adaptive Harmony#
The concept of “Adaptive Harmony” in the context of a research paper likely refers to a system or algorithm that dynamically balances conflicting or competing elements to achieve an optimal outcome. This could manifest in several ways, such as adaptively weighting different input signals (e.g., text and image features) or adjusting internal parameters based on the current state. The “adaptive” aspect suggests a learning or feedback mechanism, possibly involving machine learning techniques, to optimize the balance over time. Achieving “harmony” implies a goal of smooth integration or seamless blending of the disparate elements, avoiding conflicts or dominance by any single component. This might be measured via metrics like visual fidelity, semantic consistency, or user preference scores. The success of such a system hinges on the ability to effectively learn and adjust the balance parameters, thereby resulting in a cohesive and pleasing output that satisfies the defined criteria for harmony.
Diffusion Model Fusion#
Diffusion model fusion presents a powerful paradigm for generating novel objects by harmoniously integrating information from diverse sources. The core idea revolves around combining the strengths of different diffusion models, potentially including those specializing in image generation from text, image editing, or style transfer. Effective fusion strategies are crucial; they might involve carefully weighting the outputs of different models, concatenating their latent representations, or using a more sophisticated approach such as attention mechanisms to selectively combine relevant features. A key challenge lies in managing the potential for conflicting or inconsistent information between models. Successful fusion necessitates careful consideration of how to resolve these conflicts, potentially through the use of a learned loss function, an arbitration mechanism, or by employing a hierarchical approach to fusion. Beyond technical aspects, algorithmic efficiency and the interpretability of the fusion process are critical. A well-designed fusion approach should be computationally feasible for real-world applications while offering insights into how the combined models work together.
Balanced Loss Function#
A balanced loss function in the context of image synthesis, particularly using diffusion models, aims to harmoniously balance the competing objectives of image fidelity and editability. The challenge arises because increasing editability (the ability to modify the image) often comes at the cost of reduced fidelity (how well the generated image matches the original). A balanced loss function might incorporate multiple loss terms, such as a reconstruction loss (measuring the difference between the generated and original images), and a regularization term (e.g., promoting Gaussian noise characteristics), each weighted to optimize the overall balance. The weights assigned to these terms are crucial and often require careful tuning. The optimal balance would yield high-fidelity outputs that are also readily editable, allowing for creative control without excessive image degradation. This approach is especially important when merging disparate image and text data because the tension between these two inputs is likely to be strong.
Object Synthesis Results#
An in-depth analysis of object synthesis results would involve a multifaceted approach. First, it’s crucial to quantitatively assess the generated images using metrics like FID (Fréchet Inception Distance) or IS (Inception Score) to evaluate image quality and diversity. Secondly, a qualitative evaluation is necessary. This would involve visual inspection of the synthesized images to determine their realism, coherence, and adherence to the input text and image. Specifically, assessing whether novel objects successfully integrate attributes from both sources while avoiding artifacts or distortions is crucial. It’s vital to note the methodology employed for comparison against baseline models. Did the study use existing metrics or did they introduce novel ones? The dataset’s composition is also relevant; does it consist of diverse and challenging object pairs? Finally, and critically, the analysis should highlight the limitations of the approach; does it struggle with specific object types or text descriptions? The findings must be thoroughly presented and interpreted in context to fully understand the success and potential failures of the presented object synthesis technique.
Future Work#
The authors outline several promising avenues for future research. Improving the handling of semantic mismatches between text and image is crucial; the current method struggles when the textual description and visual content are semantically distant. Investigating alternative similarity metrics or embedding techniques could enhance the model’s ability to bridge this gap. Exploring more advanced techniques for harmonizing the contribution of text and image features within the diffusion model architecture would also be beneficial. This might involve refining the attention mechanisms or introducing novel loss functions specifically designed to balance both modalities. Addressing potential biases in the model’s outputs, particularly toward favoring either the textual or visual input, requires further investigation. Investigating the effect of different training data distributions and exploring techniques to mitigate bias would be crucial. Finally, extending the model to handle more complex object manipulations, such as changing object attributes, poses, or relationships, could lead to more versatile applications. These extensions would involve significant architectural changes and may necessitate the development of more sophisticated training strategies.
More visual insights#
More on figures

🔼 This figure compares the results of two different diffusion models, SDXL-Turbo and PnPInv, when tasked with combining an object image and an object text to create a new object image. The top row shows that SDXL-Turbo often favors either the text or the image, ignoring the other input; while PnPInv shows a similar imbalance. The bottom row shows the results obtained using the proposed method, ATIH, which demonstrates a better balance between text and image in the generated images.
read the caption
Figure 2: Imbalances between text and image in diffusion models. Using SDXL-Turbo [56] (left) and PnPinv [27] (right), the top pictures show a tendency for generated objects to align with textual content (green circles), while the bottom pictures tend to align with visual aspects (orange circles). In contrast, our approach achieves a more harmonious integration of both object text and image.
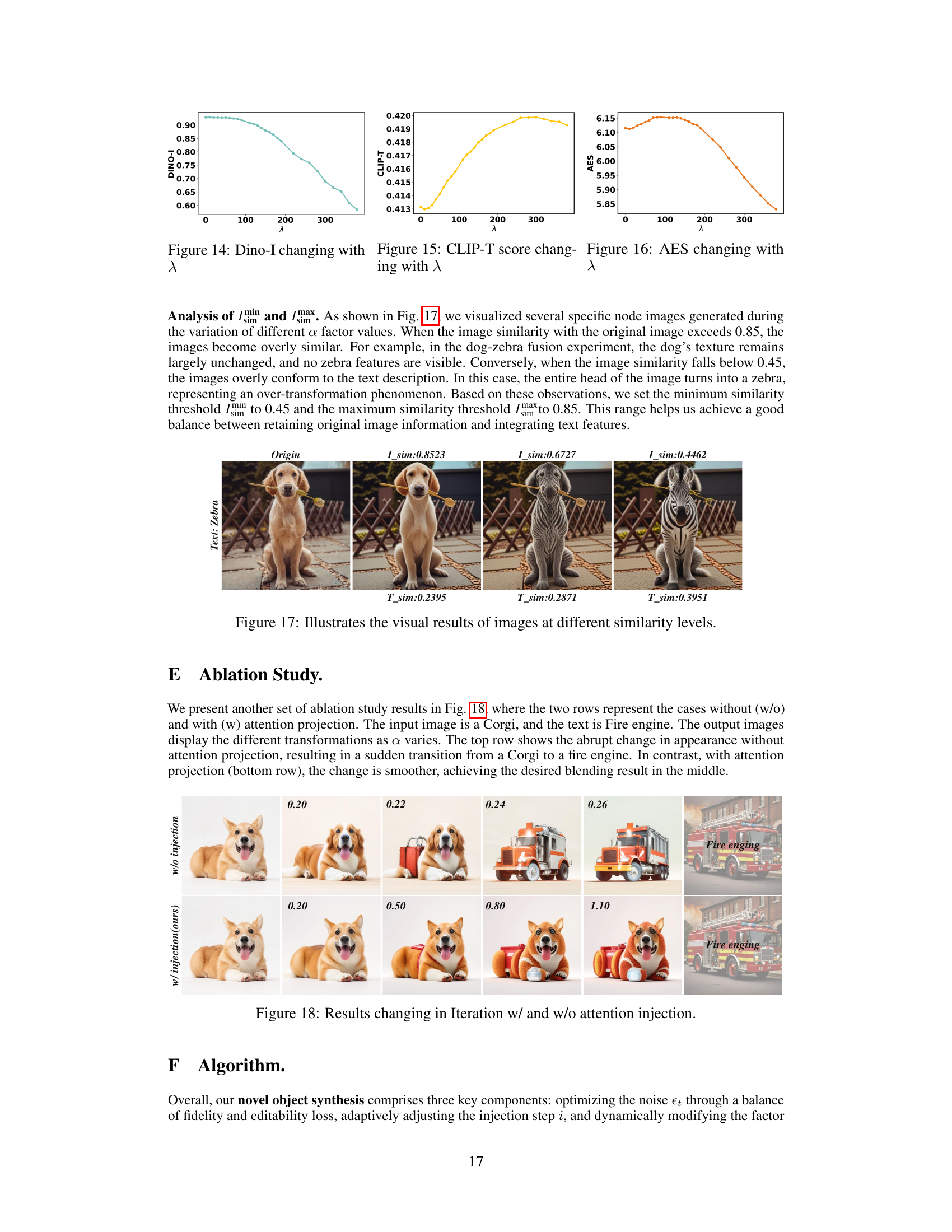
🔼 This figure illustrates the framework of the proposed object synthesis method, Adaptive Text-Image Harmony (ATIH). It shows how a scale factor (α) and an injection step (i) are used to balance text and image features in the diffusion process. A balanced loss function optimizes noise (εt) to balance object editability and fidelity. The adaptive harmony mechanism dynamically adjusts α and i based on the similarity between the generated object and the input text and image.
read the caption
Figure 3: Framework of our object synthesis incorporating a scale factor α, an injection step i and noise εt in the diffusion process. We design a balance loss for optimizing the noise εt to balance object editability and fidelity. Using the optimal noise εt, we introduce an adaptive harmony mechanism to adjust α and i, balancing text (Peacock) and image (Rabbit) similarities.
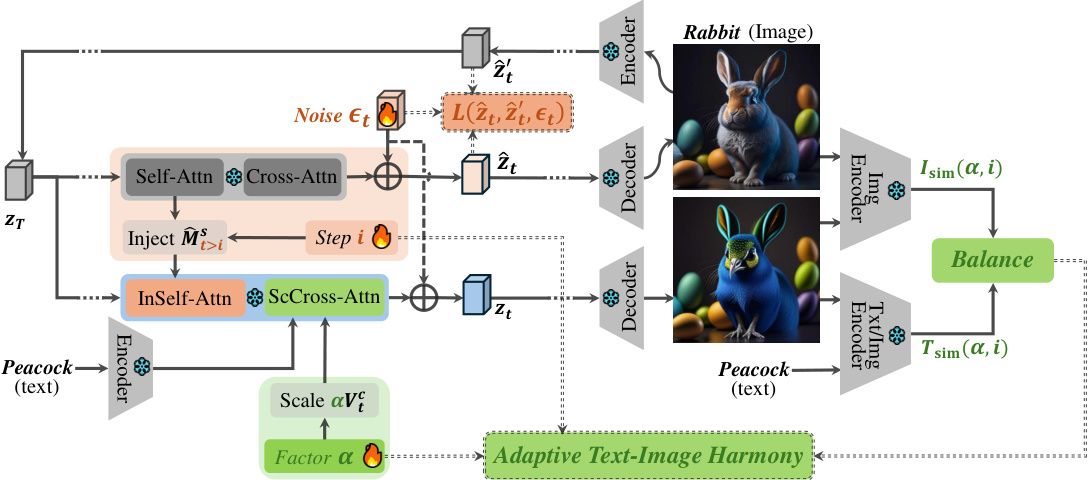
🔼 This figure shows the relationship between the image similarity (Isim) and text similarity (Tsim) scores with the scaling factor α. The x-axis represents the scaling factor α, while the y-axis represents the similarity scores. Both Isim(α) and Tsim(α) curves are plotted. The green shaded area shows the range where the balance between Isim(α) and Tsim(α) is optimized according to the criteria kmax ≥ k ≥ kmin, where kmax = Iα1/Tα1 and kmin = Iα2/Tα2, for a better integration of text and image. The images shown on the figure illustrate the differences in generated images for different values of α, showing how α impacts the balance between text and image information.
read the caption
Figure 4: Isim and Tsim with a ∈ [0, 1.4].

🔼 This figure illustrates the adaptive process of the proposed Adaptive Text-Image Harmony (ATIH) method. It shows how the injection step (i) and scale factor (a) are adjusted iteratively to balance the similarities between the generated image and the input text and image. The process starts with three initial points, and the optimal values of i and a are found by maximizing a similarity score function that considers both the image and text similarities while balancing them.
read the caption
Figure 5: The adjusted process of our ATIH with three initial points and ε = Isim(a) + k*Tsim(a) - F(a).

🔼 This figure compares the results of the proposed ATIH method with three other image editing methods (InfEdit, MasaCtrl, and InstructPix2Pix) on six different text-image pairs. Each pair combines an image of an animal or object with a text description of a different object. The goal is to generate a new image that harmoniously combines elements from both the original image and the text description. The figure demonstrates that ATIH achieves more successful and creative object synthesis than the other methods, often producing more natural and coherent combinations.
read the caption
Figure 6: Comparisons with different image editing methods. We observe that InfEdit [69], MasaCtrl [5], and InstructPix2Pix [4] struggle to fuse object images and texts, while our method successfully implements new object synthesis, such as bowling ball-fawn in the second row.

🔼 This figure shows the framework of the proposed object synthesis method. It highlights the key components, including a scale factor (α) to balance text and image features, an injection step (i) to preserve image information, and a noise parameter (εt) to balance object editability and fidelity. The adaptive harmony mechanism dynamically adjusts α and i to achieve an optimal balance between text and image similarities, leading to a more harmonious integration of both object text and image.
read the caption
Figure 3: Framework of our object synthesis incorporating a scale factor α, an injection step i and noise εt in the diffusion process. We design a balance loss for optimizing the noise εt to balance object editability and fidelity. Using the optimal noise εt, we introduce an adaptive harmony mechanism to adjust α and i, balancing text (Peacock) and image (Rabbit) similarities.

🔼 This figure compares the results of the proposed ATIH method with two other creative mixing methods: MagicMix and ConceptLab. It shows that ATIH produces more harmonious and successful combinations of object text and image than the other methods. The ConceptLab method is noted as having a different approach to creative generation, making a direct comparison difficult. The figure showcases several examples of object combinations generated by each method.
read the caption
Figure 8: Comparisons with different creative mixing methods. We observe that our results surpass those of MagicMix [34]. For ConceptLab [50], we exclusively examine its fusion results without making good or bad comparisons, as it is a distinct approach to creative generation.

🔼 This figure compares the results of the proposed ATIH method with those obtained using ControlNet for image editing tasks. The input is an image and text prompt describing the fusion of these two elements. ControlNet uses depth and edge maps for control. The results show that ATIH achieves better harmonization between the image and the text compared to ControlNet.
read the caption
Figure 9: Comparisons with ControlNet-depth and ControlNet-edge [72] using a description that “A photo of an {object image} creatively fused with an object text }”.

🔼 This figure illustrates the framework of the proposed object synthesis method, called Adaptive Text-Image Harmony (ATIH). It highlights the key components involved in the process, such as the scale factor (α) to balance text and image features in cross-attention, an injection step (i) to maintain image information during self-attention, and a balanced loss function to optimize noise (εt) for better object editability and fidelity. The adaptive harmony mechanism adjusts α and i to balance the similarities between the generated object and the input text and image.
read the caption
Figure 3: Framework of our object synthesis incorporating a scale factor α, an injection step i and noise εt in the diffusion process. We design a balance loss for optimizing the noise εt to balance object editability and fidelity. Using the optimal noise εt, we introduce an adaptive harmony mechanism to adjust α and i, balancing text (Peacock) and image (Rabbit) similarities.

🔼 This figure shows two examples of the proposed method for novel object synthesis. The method combines an object image with a textual description to generate a new, combined image. The left example shows a glass jar combined with the text ‘porcupine’, resulting in an image that looks like a glass jar with porcupine-like features. The right example shows a horse combined with the text ‘bald eagle’, resulting in a horse with features resembling a bald eagle.
read the caption
Figure 1: We propose a straightforward yet powerful approach to generate combinational objects from a given object text-image pair for novel object synthesis. Our algorithm produces these combined object images using the central image and its surrounding text inputs, such as glass jar (image) and porcupine (text) in the left picture, and horse (image) and bald eagle (text) in the right picture.

🔼 This figure shows the 30 images used in the dataset for the object synthesis task. The images are diverse and depict a variety of animals and objects, including mammals, birds, reptiles, plants, fruits, and other objects, to ensure a wide range of visual features for the model to learn from.
read the caption
Figure 12: Original Object Image Set.
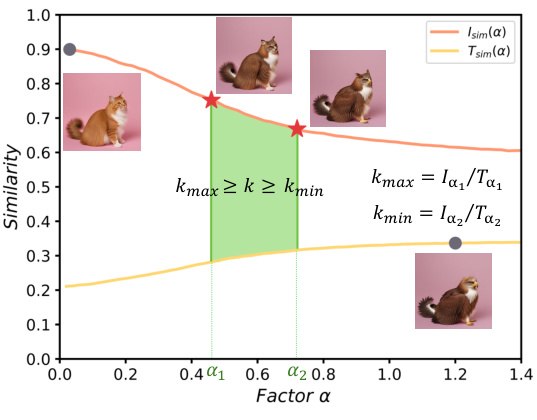
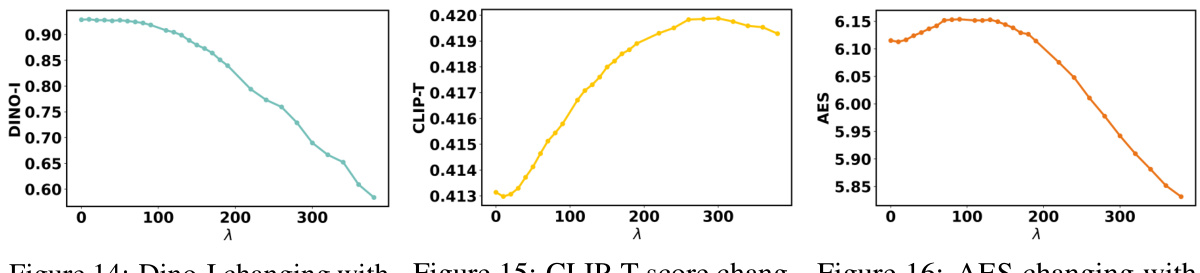
🔼 This figure shows how different values of the lambda (λ) parameter affect the balance between image fidelity and editability in the object synthesis process. The top row displays the original reconstructed images. The two bottom rows show results from editing the reconstructed image with different textual prompts, demonstrating the extremes of editability (left), balanced results (center), and constructability (right). The red box highlights the balanced results for each example.
read the caption
Figure 13: Image variations under different λ values. The first row displays the reconstructed images. The middle and bottom rows show the results of editing with different prompts, demonstrating variations in maximum editability, a balanced approach, and maximum constructability.
🔼 This figure shows the framework of the proposed Adaptive Text-Image Harmony (ATIH) method for novel object synthesis. It highlights three key components: a scale factor (α) to balance text and image features in cross-attention; an injection step (i) to preserve image information in self-attention; and a noise parameter (εt) optimized by a balanced loss function to ensure both optimal editability and fidelity of the generated object image. The ATIH method adaptively adjusts α and i to create a harmonious balance between text and image similarities, enabling the synthesis of novel and surprising objects.
read the caption
Figure 3: Framework of our object synthesis incorporating a scale factor α, an injection step i and noise εt in the diffusion process. We design a balance loss for optimizing the noise εt to balance object editability and fidelity. Using the optimal noise εt, we introduce an adaptive harmony mechanism to adjust α and i, balancing text (Peacock) and image (Rabbit) similarities.

🔼 This figure shows example results of the proposed method, ATIH (Adaptive Text-Image Harmony), for novel object synthesis. The method takes an image and text as input and generates a new image that combines features of both. The two examples in the figure illustrate the combination of a glass jar image with ‘porcupine’ text, and a horse image with ‘bald eagle’ text, resulting in novel object images.
read the caption
Figure 1: We propose a straightforward yet powerful approach to generate combinational objects from a given object text-image pair for novel object synthesis. Our algorithm produces these combined object images using the central image and its surrounding text inputs, such as glass jar (image) and porcupine (text) in the left picture, and horse (image) and bald eagle (text) in the right picture.

🔼 This ablation study shows the results of changing the attention injection parameter (α) with and without attention injection in the model. The input image is a Corgi, and the target text is ‘Fire Engine’. The figure displays how the model transforms the image into a fire engine with different α values. Without attention injection, the transformation is abrupt; while with injection, the transformation is smoother and more harmonious, resulting in a better integration of the original image and target concept.
read the caption
Figure 18: Results changing in Iteration w/ and w/o attention injection.

🔼 This figure shows two examples of novel object synthesis. The left image shows a glass jar combined with the text ‘porcupine’, resulting in a porcupine-like creature in a glass jar. The right image combines a horse with the text ‘bald eagle’, resulting in a horse-like creature with eagle-like features. This demonstrates the capability of the proposed method to generate combinational objects by combining an object image and its surrounding text descriptions.
read the caption
Figure 1: We propose a straightforward yet powerful approach to generate combinational objects from a given object text-image pair for novel object synthesis. Our algorithm produces these combined object images using the central image and its surrounding text inputs, such as glass jar (image) and porcupine (text) in the left picture, and horse (image) and bald eagle (text) in the right picture.

🔼 This figure shows example results of the proposed method for novel object synthesis. The method takes an image and a text description as input and generates a new image that combines elements of both. The examples shown include a glass jar combined with a porcupine and a horse combined with a bald eagle. The results demonstrate the ability of the model to create novel and visually appealing combinations of objects.
read the caption
Figure 1: We propose a straightforward yet powerful approach to generate combinational objects from a given object text-image pair for novel object synthesis. Our algorithm produces these combined object images using the central image and its surrounding text inputs, such as glass jar (image) and porcupine (text) in the left picture, and horse (image) and bald eagle (text) in the right picture.

🔼 This figure shows two examples of novel object synthesis using the proposed method. The method combines an input image with a textual description to generate a new, composite image. The left example combines a glass jar image with the text ‘porcupine’, resulting in a porcupine-like object formed from a glass jar. The right example combines a horse image with the text ‘bald eagle’, resulting in an eagle-like object formed from a horse.
read the caption
Figure 1: We propose a straightforward yet powerful approach to generate combinational objects from a given object text-image pair for novel object synthesis. Our algorithm produces these combined object images using the central image and its surrounding text inputs, such as glass jar (image) and porcupine (text) in the left picture, and horse (image) and bald eagle (text) in the right picture.

🔼 This figure shows two examples of the novel object synthesis approach proposed in the paper. The approach combines an object image with a textual description to generate a new, combined object image. The left image shows a glass jar combined with the text ‘porcupine’, resulting in a glass jar with a porcupine-like texture and features. The right image shows a horse combined with the text ‘bald eagle’, resulting in a horse with bald eagle-like features.
read the caption
Figure 1: We propose a straightforward yet powerful approach to generate combinational objects from a given object text-image pair for novel object synthesis. Our algorithm produces these combined object images using the central image and its surrounding text inputs, such as glass jar (image) and porcupine (text) in the left picture, and horse (image) and bald eagle (text) in the right picture.

🔼 This figure shows two examples of novel object synthesis using the proposed method. The left image combines a glass jar (image) with a porcupine (text), resulting in a glass jar with porcupine-like features. The right image combines a horse (image) with a bald eagle (text), resulting in a horse with bald eagle-like features.
read the caption
Figure 1: We propose a straightforward yet powerful approach to generate combinational objects from a given object text-image pair for novel object synthesis. Our algorithm produces these combined object images using the central image and its surrounding text inputs, such as glass jar (image) and porcupine (text) in the left picture, and horse (image) and bald eagle (text) in the right picture.

🔼 This figure demonstrates the limitations of existing diffusion models in harmoniously combining text and image information for object synthesis. The top row shows examples where the generated object strongly favors either the textual description (left) or the visual input image (right), indicating an imbalance in how the model processes the combined input. In contrast, the bottom row illustrates the results from the proposed ATIH model, which better integrates text and image features to create harmoniously combined objects.
read the caption
Figure 2: Imbalances between text and image in diffusion models. Using SDXL-Turbo [56] (left) and PnPinv [27] (right), the top pictures show a tendency for generated objects to align with textual content (green circles), while the bottom pictures tend to align with visual aspects (orange circles). In contrast, our approach achieves a more harmonious integration of both object text and image.

🔼 This figure compares the results of the proposed method (ATIH) against three other image editing methods (InfEdit, MasaCtrl, and InstructPix2Pix) on the task of object synthesis by fusing object images and texts. The results show that ATIH produces more harmonious and successful fusions, creating novel objects that effectively combine features from both the image and text, unlike the other methods which struggle to balance the two inputs.
read the caption
Figure 6: Comparisons with different image editing methods. We observe that InfEdit [69], MasaCtrl [5], and InstructPix2Pix [4] struggle to fuse object images and texts, while our method successfully implements new object synthesis, such as bowling ball-fawn in the second row.

🔼 This figure compares the results of the proposed ATIH model with the Kosmos-G model on two examples of object synthesis. The top row shows the results of applying ‘Strawberry’ text to an original image of an owl. The ATIH model produces a harmoniously fused image of an owl with pink strawberry-like coloration, while the Kosmos-G model results in an owl with strawberry-like spots on its feathers. The bottom row shows the results of applying ‘Badger’ text to an original image of a squirrel. The ATIH model generates an image of a squirrel with badger-like fur and coloration, while Kosmos-G model results in a badger image with a stylized appearance.
read the caption
Figure 27: Comparisons with Subject-driven method.
More on tables

🔼 This table presents a quantitative comparison of the proposed ATIH model against four other image editing models (MagicMix, InfEdit, MasaCtrl, InstructPix2Pix) across five metrics: DINO-I (image similarity), CLIP-T (text-image similarity), AES (aesthetic score), HPS (human preference score), F-score (a combined score reflecting both text and image similarities), and Bsim (a measure of the balance between text and image similarities). Higher scores generally indicate better performance. The p-values in parentheses indicate the statistical significance of the differences between ATIH and the other methods.
read the caption
Table 1: Quantitative comparisons on our TIF dataset.

🔼 This table lists the 60 text items used in the paper’s experiments, categorized into seven object categories: Mammals, Birds, Reptiles and Amphibians, Fish and Marine Life, Plants, Fruits, and Objects. Each category contains a variety of descriptive text terms that represent different animals, plants, and objects used for the novel object synthesis task. This categorization enables a comprehensive evaluation of the model’s ability to generate and combine various concepts.
read the caption
Table 5: List of Text Items by Object Category.
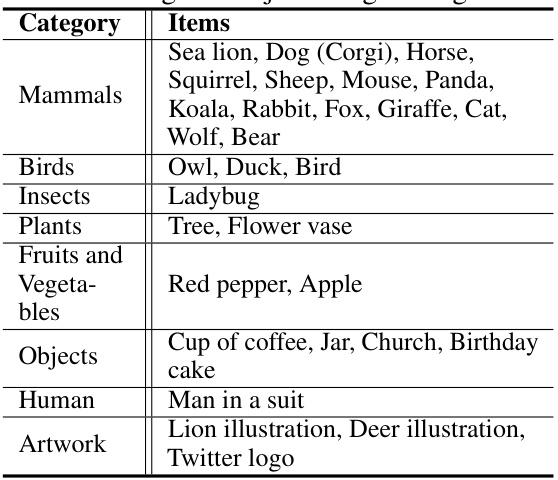
🔼 This table lists the categories of the 30 original object images used in the paper’s experiments, including mammals, birds, insects, plants, fruits and vegetables, objects, humans, and artwork. Each category contains a list of example images used in the dataset.
read the caption
Table 6: Original Object Image Categories.

🔼 This table presents a quantitative comparison of the proposed ATIH model against several other image editing and mixing methods across various metrics. The metrics used include aesthetic score (AES), CLIP text-image similarity (CLIP-T), Dinov2 image similarity (Dino-I), and human preference score (HPS). Additionally, the table includes the F-score and balance similarities (Bsim), which are used to assess the effectiveness of text-image fusion. The results show that the ATIH model significantly outperforms other methods across most metrics.
read the caption
Table 1: Quantitative comparisons on our TIF dataset.
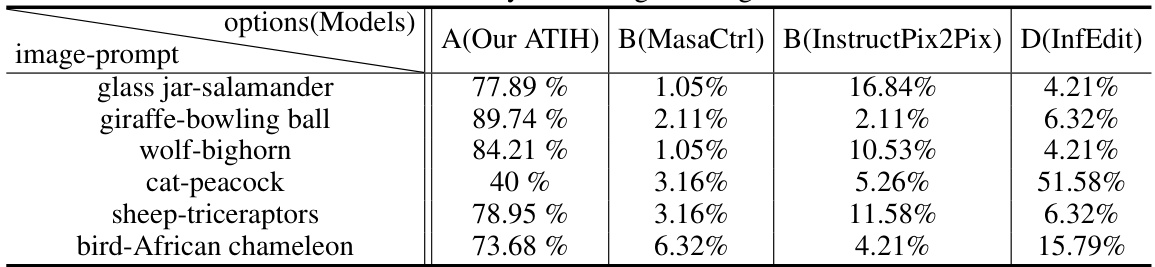
🔼 This table presents the results of a user study comparing the performance of different image editing methods. The study asked participants to rate the results based on novelty, harmony, and artistic value. The table shows the percentage of votes each method received for each image-prompt pair. The results suggest that the proposed ATIH method outperforms the other methods in terms of generating novel and harmonious images.
read the caption
Table 8: User study with image editing methods.
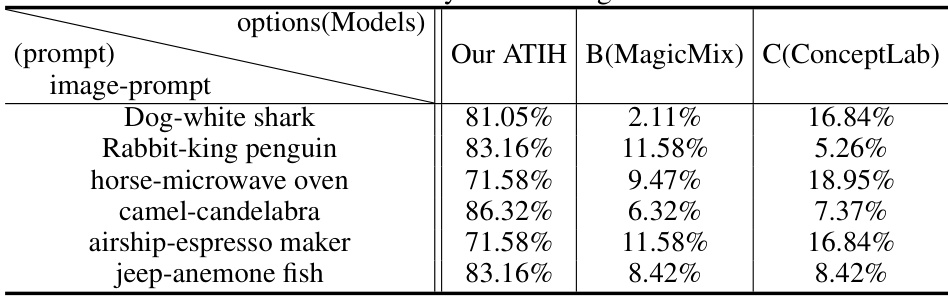
🔼 This table presents the results of a user study comparing different object synthesis methods. The study asked participants to rate the generated images based on the novelty, harmony, and artistic value of the fusion. The table shows the percentage of votes each method received for different image-text pairs. This provides a qualitative assessment of the performance of the proposed ATIH method against other competitive methods.
read the caption
Table 9: User study with mixing methods.
Full paper#