↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Standard large language models struggle with long conversations due to computational limitations and memory constraints. The quadratic growth in computational complexity with longer contexts makes supporting prolonged dialogues challenging. Current methods like local attention or attention sinks, while improving efficiency, often suffer from significant information loss, negatively impacting the quality and coherence of the conversation.
StreamingDialogue tackles this problem by introducing a novel method that compresses lengthy dialogue histories into ‘conversational attention sinks’ (end-of-utterance tokens). This approach cleverly utilizes the inherent structure of dialogues, reducing complexity quadratically with the number of utterances. To minimize information loss, the research introduces two effective learning strategies: short-memory reconstruction (SMR) and long-memory reactivation (LMR). Evaluations demonstrate that StreamingDialogue significantly outperforms existing methods in various dialogue tasks, achieving substantial speedups and significant reductions in memory usage.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on dialogue systems and large language models as it directly addresses the limitations of existing models in handling long conversations. By proposing a novel method for compressing dialogue history and effectively recalling information, the research unlocks possibilities for creating more engaging and coherent conversational AI agents. This offers significant improvements in efficiency and memory usage, making it highly relevant to the field’s current focus on resource-efficient AI.
Visual Insights#

This figure visualizes the attention maps of different LLMs. (a) shows the attention patterns of Llama-2-7B and Llama-2-7B-Chat models, highlighting how the end-of-utterance tokens ( and \n) aggregate attention. (b) compares the attention mechanisms of StreamingLLM and the proposed StreamingDialogue, demonstrating that StreamingDialogue focuses attention more effectively on the end-of-utterance tokens, which are crucial for aggregating utterance information. This difference in attention distribution is key to StreamingDialogue’s ability to handle longer contexts.

This table presents the main experimental results on the PersonaChat and Multi-Session Chat (MSC) datasets. It compares the performance of StreamingDialogue against several baseline methods across various metrics including Perplexity (PPL), BLEU, ROUGE, Distinct, USL-H, and Dial-M. Lower PPL is better, while higher scores for the other metrics indicate better performance. The best result for each metric is highlighted in bold, and statistically significant differences (p<0.05) are marked with an asterisk.
In-depth insights#
Conv-Attn Sinks#
The concept of “Conv-Attn Sinks” in the context of dialogue processing is a novel approach to handling long conversations. It leverages the observation that end-of-utterance (EoU) tokens, such as “” or “\n”, tend to act as significant points of attention aggregation in transformer models. By identifying these EoU tokens as “Conv-Attn Sinks”, the method proposes a way to compress long dialogue histories into these key points. This compression leads to a quadratic reduction in computational complexity, making processing of prolonged conversations significantly more efficient. This approach contrasts with methods that either rely on truncating the conversation history, thus losing crucial information, or that use computationally expensive methods to handle long contexts. The efficiency gains are particularly relevant for applications such as chatbots and virtual assistants where managing long conversational histories is critical.
SMR & LMR#
The paper introduces two novel learning strategies, Short-Memory Reconstruction (SMR) and Long-Memory Reactivation (LMR), to improve the model’s ability to handle prolonged dialogues. SMR focuses on reconstructing utterances based solely on their corresponding end-of-utterance (EoU) tokens, forcing the model to efficiently encapsulate utterance information within these ‘conversational attention sinks’. This approach is crucial for maintaining short-term memory and ensuring coherence within individual turns of conversation. In contrast, LMR aims to retrieve information from the long dialogue history, leveraging only the EoU tokens to reactivate relevant context. This long-term memory component is essential for maintaining dialogue consistency across extended conversations, enabling the model to retain and effectively use information from previous turns. By jointly optimizing SMR and LMR, the model learns to effectively utilize these attention sinks for both short and long-term memory, resulting in significant performance improvements in prolonged dialogue settings. The combination of these two techniques addresses the critical challenge of maintaining both coherence within individual turns and consistency across extended dialogue history.
Efficiency Gains#
The efficiency gains reported in this hypothetical research paper likely stem from the core innovation of compressing long dialogue contexts into ‘conversational attention sinks’ (EoUs). This method drastically reduces the computational complexity of attention mechanisms, scaling quadratically rather than linearly with the number of utterances. This quadratic reduction is a major efficiency improvement, especially beneficial for prolonged dialogues. The paper likely details how this compression is achieved with minimal information loss, possibly through novel learning strategies that aid in reconstructing the compressed context efficiently. Further efficiency gains could result from strategies like caching only essential information during inference (such as the EoUs and recent utterances) instead of the entire dialogue history. Reduced memory usage is another likely efficiency gain, stemming directly from only needing to cache a fraction of the dialogue history. The overall effect is a potentially significant speedup in dialogue generation, making prolonged conversations computationally feasible and practically efficient.
Long Dialogue#
The concept of “Long Dialogue” in research papers centers on the challenges and opportunities presented by extending conversational AI beyond short exchanges. Contextual understanding is key; maintaining coherence and consistency across numerous turns requires sophisticated memory mechanisms. Existing models struggle with the computational cost of long-range dependencies. This limitation is particularly acute in attention-based models. Addressing this, researchers explore various approaches including sparse attention, memory networks, and compression techniques. Efficient memory management becomes crucial, prompting innovations in how past dialogue is represented and accessed. The goal is to create systems capable of sustaining engaging and meaningful conversations over extended periods, mirroring human conversational capabilities. This involves not only technical advancements but also consideration of the user experience and the ethical implications of maintaining and accessing long conversational histories.
Future Works#
Future work could explore several promising directions. Extending StreamingDialogue to lifelong learning contexts would be valuable, allowing the model to continuously adapt and improve its conversation abilities over time. This necessitates mechanisms for efficiently incorporating new information and discarding outdated knowledge. Investigating the impact of different EoU token choices and strategies on performance is crucial. While the paper focuses on ‘’ and ‘\n’, exploring alternative separators, or even dynamic selection of EoUs based on conversation context, could yield improvements. A deeper analysis of the attention mechanisms used within the model is warranted. Understanding how exactly conv-attn sinks aggregate and retain information, as well as the interplay between short-term and long-term memory, could inspire new architectural designs. Finally, thorough experimentation on a broader range of conversational datasets and tasks is needed to validate the model’s generality. Evaluating performance on more diverse dialogue styles and topics, while exploring multi-lingual capabilities, would enhance the model’s practical applicability.
More visual insights#
More on figures

This figure illustrates the StreamingDialogue framework, highlighting the two main learning strategies: short-memory reconstruction (SMR) and long-memory reactivation (LMR). It shows how these strategies work together to co-train the model by adjusting attention mechanisms. The figure also depicts the supervised learning phase and the inference phase, where specific tokens (EoU tokens and recent tokens) are cached to maintain efficiency. The bold italics in the inference section emphasize how the critical historical information is maintained for coherent responses.

The figure visualizes attention maps from different LLMs. Panel (a) shows attention maps from Llama-2-7B and Llama-2-7B-Chat models, highlighting how end-of-utterance tokens (EoU) aggregate attention. Panel (b) compares the attention patterns of StreamingLLM and the proposed StreamingDialogue approach on Llama-2-7B, demonstrating how StreamingDialogue focuses attention on conversational attention sinks (EoUs) for efficient long-context processing.

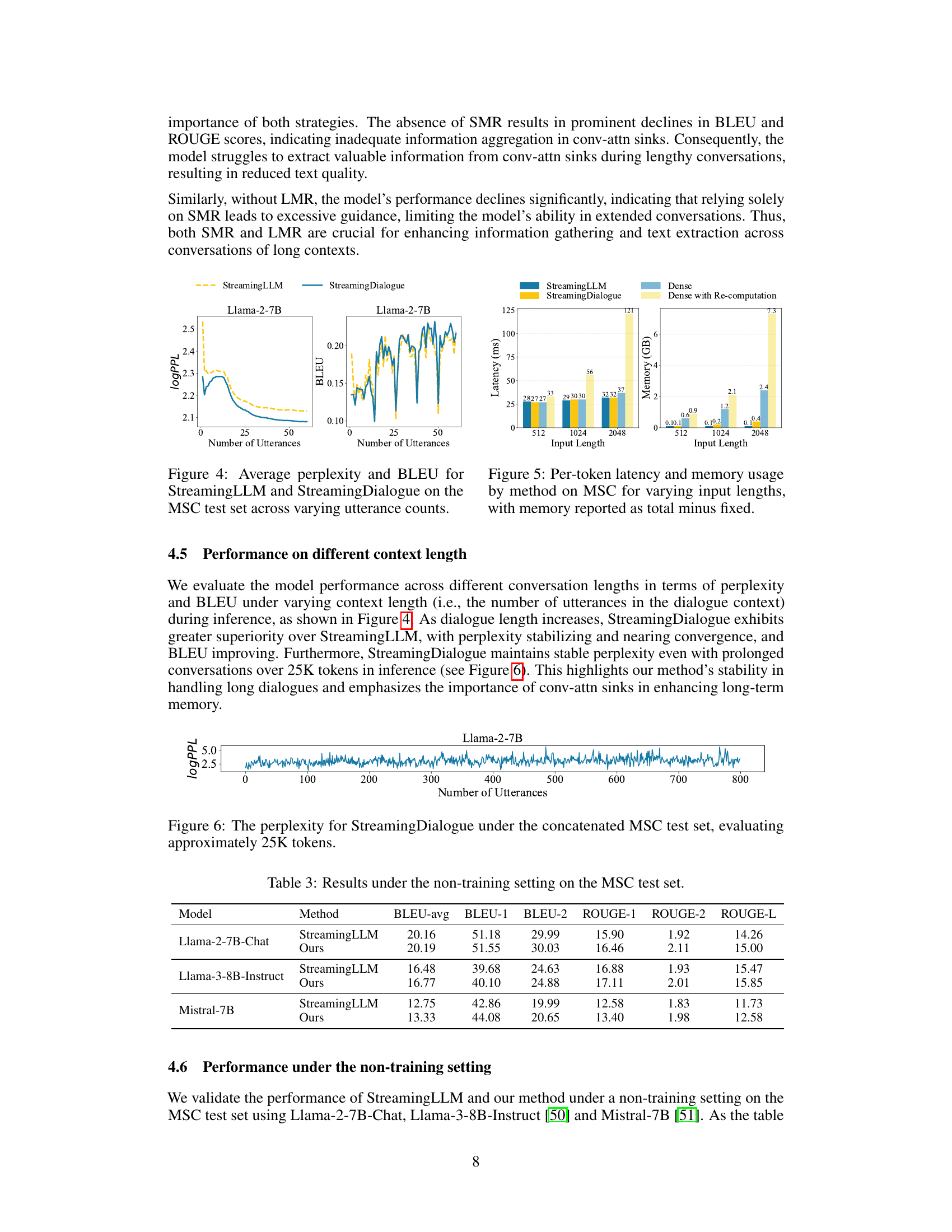
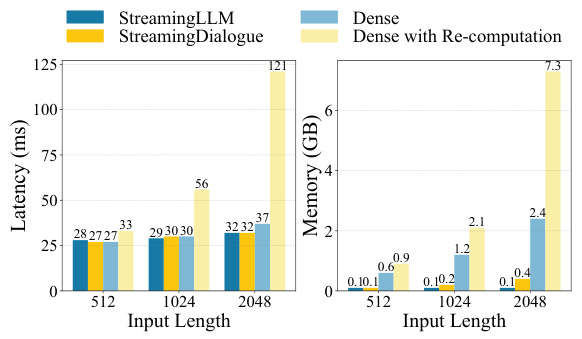
This figure compares the performance of StreamingLLM and StreamingDialogue on the Multi-Session Chat (MSC) test dataset across different lengths of conversation (measured by the number of utterances). Specifically, it shows how average perplexity (a measure of how well the model predicts the next token) and BLEU score (a measure of the similarity between generated text and reference text) change as the number of utterances in the conversation increases. The goal is to illustrate how well each method handles increasing context length in dialogue generation.
This figure compares the memory usage of different attention mechanisms (dense, local, Big Bird, StreamingLLM) with the proposed StreamingDialogue approach. It visually represents how many tokens each method needs to cache in memory during dialogue processing. Dense attention has the highest memory requirement, scaling quadratically with the number of tokens (TL). Methods like local and Big Bird aim to reduce this by using windows, but still have significant memory demands. StreamingLLM uses attention sinks, caching a limited window plus the sinks. StreamingDialogue optimizes this further by only caching the first token, the attention sinks (representing utterances), and the last two utterances, resulting in the lowest memory footprint (1+T+2L).

This figure shows the perplexity (a measure of how well the model predicts the next token) for the StreamingDialogue model when tested on the concatenated MSC test set (a collection of multiple dialogues). The x-axis represents the number of utterances processed. The y-axis represents the perplexity. The graph demonstrates the stability of StreamingDialogue’s perplexity even with a very long dialogue context (25,000 tokens), highlighting its ability to handle prolonged conversations.

This figure compares attention maps of the base Llama-2-7B model and the model after training with short-memory reconstruction (SMR) and long-memory reactivation (LMR). The visualization shows that after SMR & LMR training, the model’s attention focuses more sharply on the end-of-utterance tokens, demonstrating the effectiveness of the proposed learning strategies in enhancing information aggregation.

This figure visualizes the attention mechanisms used in various methods for handling long dialogues. It compares dense attention, local attention, Big Bird, StreamingLLM, and StreamingDialogue (the proposed method). It shows how many tokens each method needs to cache to maintain context during dialogue generation. Dense attention caches the largest number, while StreamingDialogue efficiently caches a significantly smaller number, demonstrating its memory efficiency advantage.

This figure shows the impact of hyperparameters s (number of utterances in SMR samples) and l (number of query-response pairs in LMR samples) on the model’s performance. The x-axis represents the values of s and l, ranging from 8 to 32. The y-axis shows the normalized scores for perplexity (PPL), BLEU (B-avg), ROUGE-L (R-L), and Distinct-3 (D-3). The results indicate that higher values of both s and l generally lead to better performance, with optimal values around s = 28 and l = 24.

This figure compares the memory usage of different attention mechanisms for handling long dialogues. Dense attention has quadratic complexity, needing to cache all token pairs. Local attention and Big Bird are more efficient but still require a linearly increasing amount of memory with dialogue length. StreamingLLM introduces attention sinks to reduce memory, but StreamingDialogue further improves upon this by identifying ‘conversational attention sinks’ (EoUs) – tokens such as end-of-utterance markers – that effectively summarize utterances, allowing for quadratic memory savings.
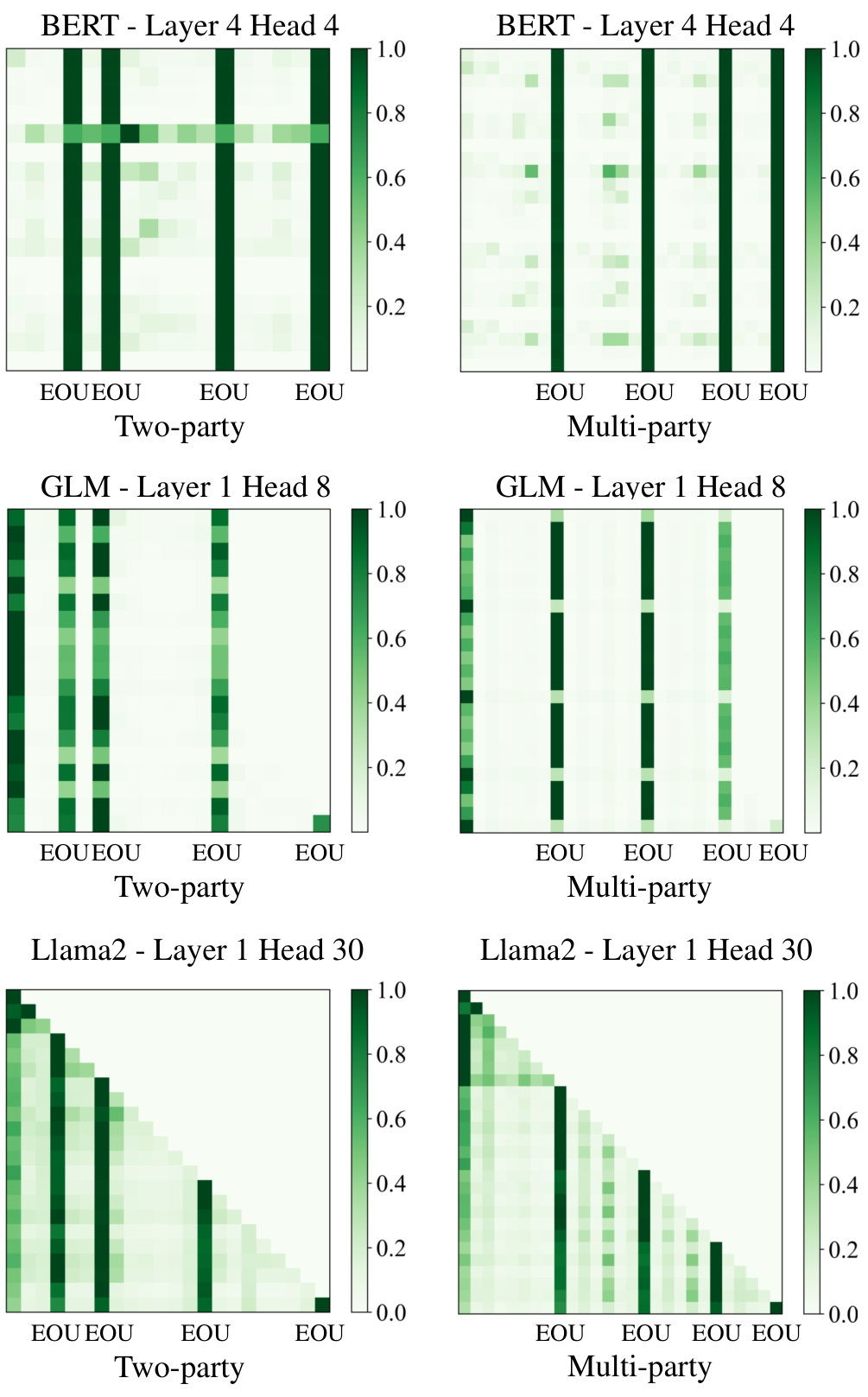
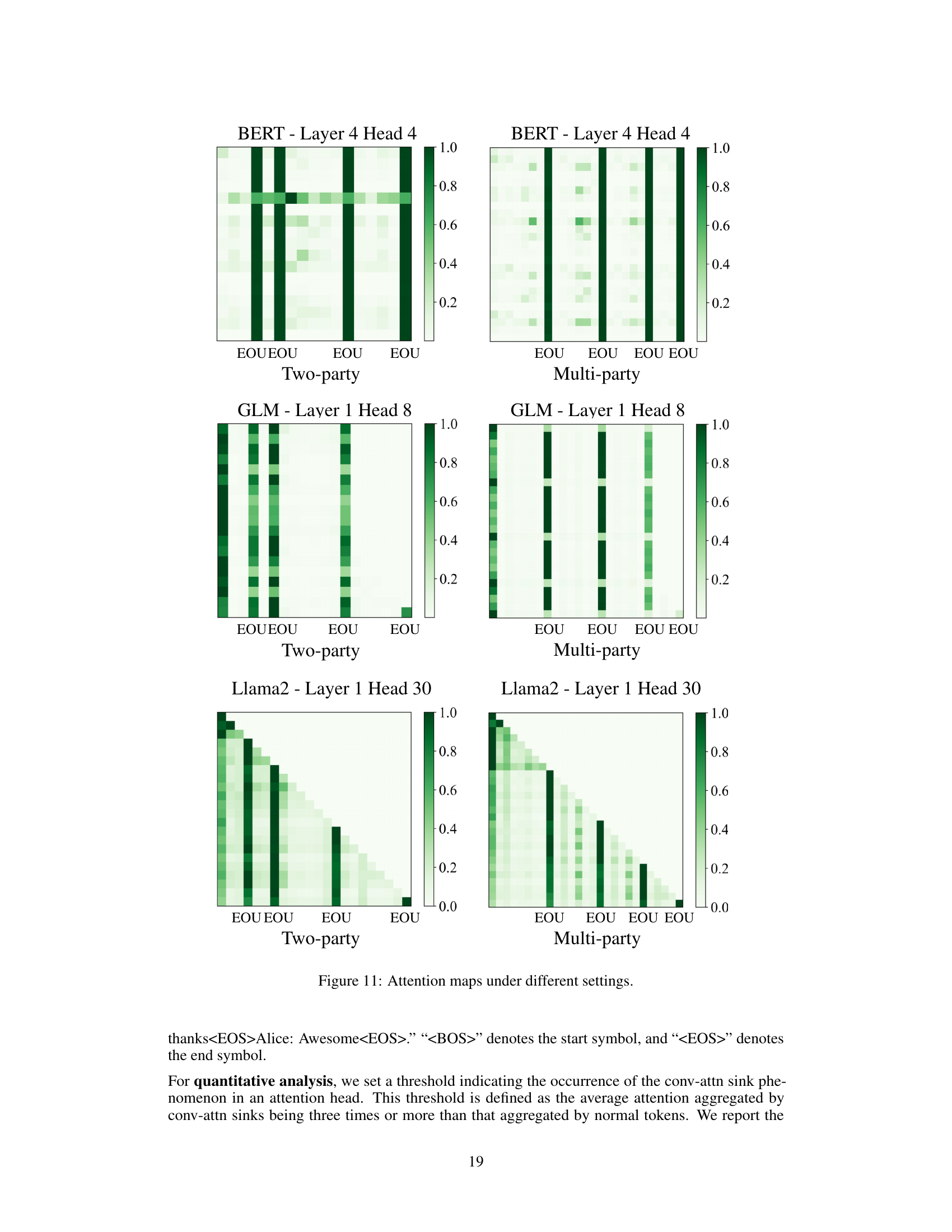
This figure compares attention maps from different models (BERT, GLM, Llama2) under different settings (two-party and multi-party dialogues). It visually demonstrates that regardless of the model or dialogue structure, End-of-Utterance (EoU) tokens consistently attract significantly more attention than other tokens. This visual evidence supports the paper’s core argument that EoU tokens act as ‘conversational attention sinks’, effectively aggregating information within the dialogue context.
More on tables
This table presents the main results of the proposed StreamingDialogue model and compares its performance against several baseline methods on two dialogue datasets: PersonaChat and Multi-Session Chat (MSC). It shows the performance across various metrics, including Perplexity (PPL), BLEU, ROUGE, Distinct, USL-H, and Dial-M. The best-performing method for each metric is highlighted in bold, and the second-best is underlined. Statistical significance (p < 0.05) compared to other methods is indicated by an asterisk (*). Abbreviations are provided for clarity.

This table presents the main experimental results comparing StreamingDialogue against several baseline methods on the PersonaChat and Multi-Session Chat (MSC) datasets. It shows the performance of each method across various metrics including perplexity (PPL), BLEU score, ROUGE score, Distinct score, USL-H score and Dial-M score. Lower PPL is better, while higher scores for the other metrics generally indicate better performance. The best result for each metric is highlighted in bold, and the statistically significant improvements (p<0.05) compared to other methods are marked with an asterisk (*).

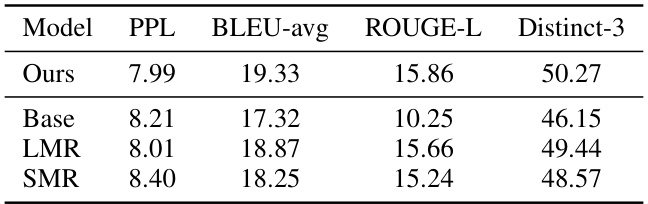
This table presents the results of reconstructing dialogues using only the conversational attention sinks (EoUs). The model, trained solely on the short-memory reconstruction task (SMR), attempts to regenerate the original utterance from its corresponding EoU. The metrics used are BLEU (B-avg, B-1, B-2) and ROUGE (R-1, R-L), which assess the quality of the reconstructed dialogues by comparing them to the originals. The higher the score, the better the reconstruction performance.

This table presents the main experimental results of the proposed StreamingDialogue model and compares its performance with several baselines on two dialogue datasets: PersonaChat and Multi-Session Chat (MSC). It shows the results for various metrics, including perplexity (PPL), BLEU score, ROUGE score, Distinct score, USL-H score, and Dial-M score. Lower PPL values indicate better performance. For the other metrics, higher values generally indicate better performance. The table highlights the best-performing method for each metric in bold and the second-best method in underlined font. Significance levels (p < 0.05) obtained through pairwise t-tests are marked with asterisks.

This table presents the main experimental results comparing the proposed StreamingDialogue method against several baselines (dense attention, local attention, Big Bird, StreamingLLM, and MemBART) on two dialogue datasets: PersonaChat and Multi-Session Chat (MSC). For each dataset, it shows the performance on various metrics, including perplexity (PPL), BLEU, ROUGE, Distinct, USL-H, and Dial-M. The best performing model for each metric is shown in bold, while the second best is underlined. Statistical significance (p<0.05) is indicated using asterisks. The table helps demonstrate the superiority of the proposed StreamingDialogue method by comparing various performance metrics of multiple baseline methods on two well-known dialogue datasets.

This table presents the main experimental results of the proposed StreamingDialogue method compared to several baseline methods on two dialogue datasets: PersonaChat and Multi-Session Chat (MSC). It shows the performance of different methods across various metrics for evaluating dialogue generation quality, including Perplexity (PPL), BLEU, ROUGE, Distinct, USL-H, and Dial-M. The best performing method for each metric is highlighted in bold, and statistically significant improvements over other methods (p<0.05) are marked with an asterisk. The table provides a concise summary of the quantitative evaluation, enabling a comparison of the proposed method’s performance against existing techniques.
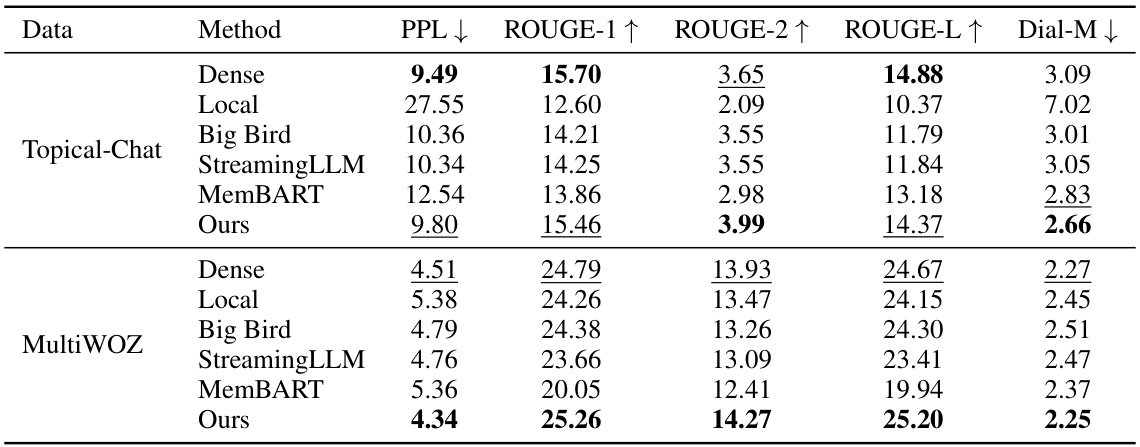
This table presents the main experimental results comparing the proposed StreamingDialogue method with several baseline methods on two dialogue datasets: PersonaChat and Multi-Session Chat (MSC). It shows the performance of each method across various metrics, including Perplexity (PPL), BLEU, ROUGE, Distinct, USL-H, and Dial-M. Lower PPL is better, while higher scores for other metrics indicate better performance. Statistical significance (p<0.05) is indicated with an asterisk (*). The best and second-best results for each metric are highlighted in bold and underlined, respectively. Abbreviations are provided for clarity (PC = PersonaChat, StrLLM = StreamingLLM).

This table presents the main experimental results on the PersonaChat and Multi-Session Chat (MSC) datasets. It compares the performance of StreamingDialogue against several baseline methods across various metrics such as Perplexity (PPL), BLEU, ROUGE, Distinct, USL-H, and Dial-M. Lower values are better for PPL and Dial-M, while higher values are better for the rest. The best results for each metric are highlighted in bold, the second best in underlined. Statistical significance is indicated by asterisks.

This table presents the main experimental results comparing StreamingDialogue against several baselines on two dialogue datasets: PersonaChat and Multi-Session Chat (MSC). For each dataset, the table shows the performance of each method on several key metrics including Perplexity (PPL), BLEU score (a measure of translation accuracy), ROUGE score (another measure of translation accuracy), Distinct score (a measure of diversity in generated text), USL-H score (a measure of dialogue coherence), and Dial-M score (a measure of dialogue quality). Lower values are preferred for PPL and Dial-M, while higher values are preferred for all other metrics. The best result for each metric is shown in bold, while the second best result is underlined. Statistically significant improvements (p<0.05) are marked with an asterisk.

This table presents the main experimental results comparing StreamingDialogue against several baseline methods on two dialogue datasets: PersonaChat and Multi-Session Chat (MSC). It shows the performance of each method across multiple metrics, including Perplexity (PPL), BLEU, ROUGE, Distinct, USL-H, and Dial-M. Lower PPL values are preferred, while higher scores are better for all other metrics. Statistical significance (p<0.05) is indicated using asterisks. The best and second-best results for each metric are highlighted in bold and underlined, respectively.
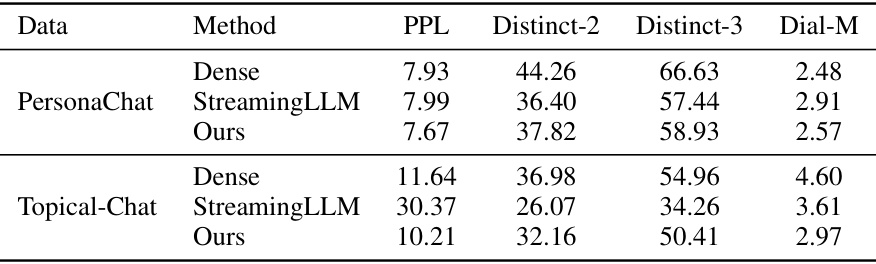
This table presents the main results of the proposed StreamingDialogue method and compares it against several baselines on two dialogue datasets: PersonaChat and Multi-Session Chat (MSC). For each dataset, the table shows the performance of different methods across multiple evaluation metrics. Lower values are preferred for perplexity (PPL) and Dial-M, while higher values are preferred for BLEU, ROUGE, Distinct, and USL-H. The best performance for each metric is highlighted in bold, with the second-best underlined. Statistical significance (p<0.05) compared to other methods is indicated with an asterisk (*).
Full paper#