↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional Temporal Sentence Grounding (TSG) in videos unrealistically assumes relevant segments always exist. This paper introduces Temporal Sentence Grounding with Relevance Feedback (TSG-RF), addressing this limitation by incorporating relevance feedback. TSG-RF localizes segments when relevant content is present and provides feedback on the content’s absence otherwise.
The proposed Relation-aware Temporal Sentence Grounding (RaTSG) network tackles TSG-RF as a foreground-background detection problem. It uses a multi-granularity relevance discriminator to assess video-query relevance at both frame and video levels, and a relation-aware segment grounding module dynamically adapts to the presence or absence of query-related segments. Experimental results on reconstructed TSG datasets show RaTSG’s effectiveness.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in existing Temporal Sentence Grounding (TSG) methods by introducing a new task, TSG-RF, which considers the uncertainty of relevant segments’ existence in videos. This is highly relevant to the current research trend of building more robust and realistic multi-modal models. The proposed RaTSG network offers a novel solution to a challenging problem, paving the way for further research on improving TSG methods’ accuracy and applicability to real-world scenarios.
Visual Insights#

This figure shows the difference between the traditional Temporal Sentence Grounding (TSG) task and the proposed Temporal Sentence Grounding with Relevance Feedback (TSG-RF) task. In TSG, the model always predicts a video segment even if the query is not present in the video. In TSG-RF, the model provides relevance feedback (indicating whether the query is relevant to the video), and only predicts a segment if the query is present. This demonstrates the key improvement of TSG-RF in handling real-world scenarios where relevant content may be missing from the input video.

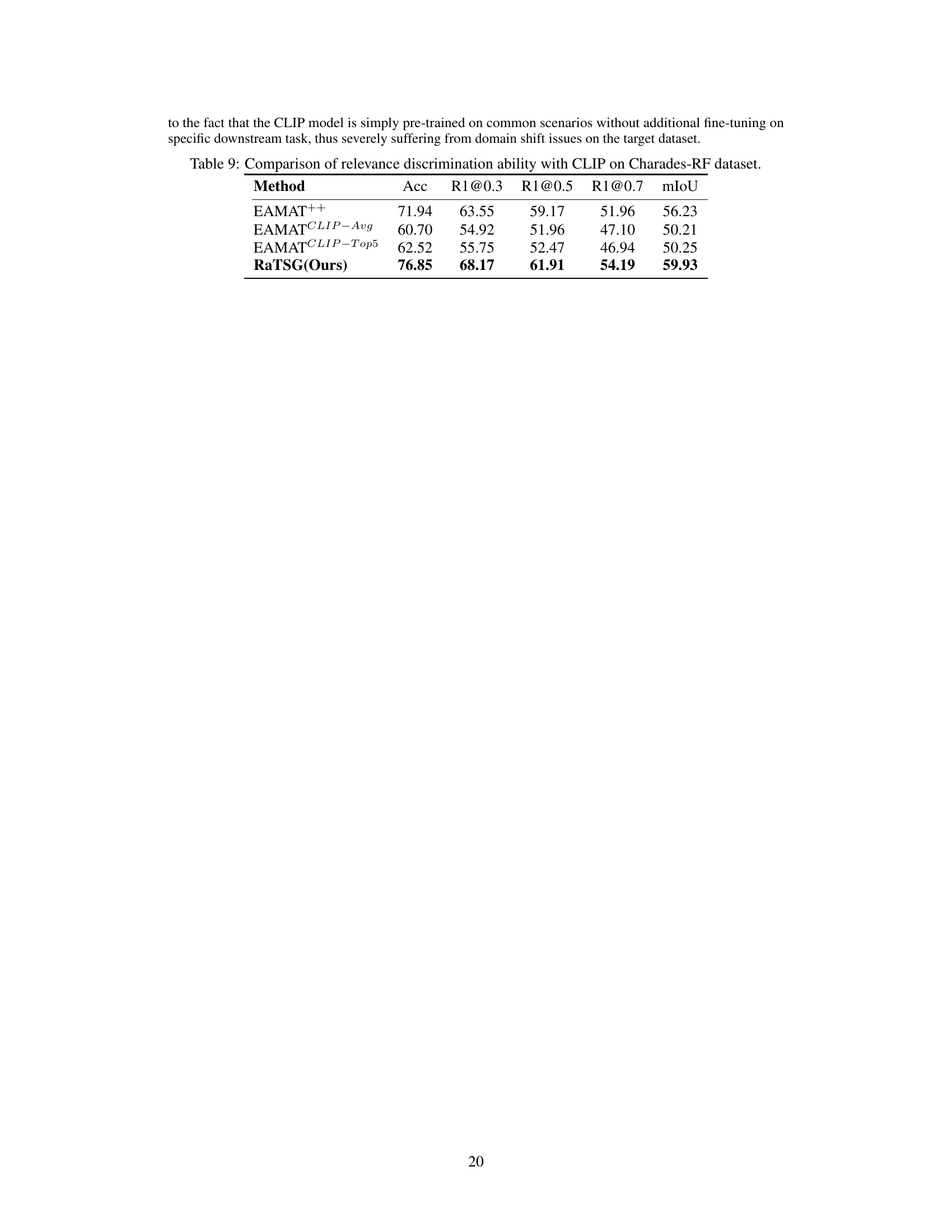
This table presents a quantitative comparison of the proposed RaTSG model against several baseline models for the Temporal Sentence Grounding with Relevance Feedback (TSG-RF) task. It shows the performance on two datasets: Charades-RF and ActivityNet-RF. The metrics used include accuracy (Acc), recall at different IoU thresholds (R1@0.3, R1@0.5, R1@0.7), and mean IoU (mIoU). The table also compares the performance of enhanced baseline models (Model++) that include an additional relevance discriminator and the proposed RaTSG model, highlighting the latter’s superior performance and efficiency.
In-depth insights#
Relevance Feedback TSG#
Relevance Feedback Temporal Sentence Grounding (TSG) represents a significant advancement in video understanding. Traditional TSG methods assume the existence of a relevant video segment for every given query, which is unrealistic. Relevance Feedback TSG addresses this limitation by incorporating a feedback mechanism that explicitly acknowledges the possibility of a query’s irrelevance to the video. This is a crucial improvement, enhancing the robustness and practicality of TSG in real-world applications where query-relevant segments may be absent. The feedback mechanism allows for more accurate and nuanced results, differentiating between scenarios where a relevant segment is successfully identified and those where the query is deemed irrelevant. This refined approach moves beyond simplistic yes/no answers towards a more sophisticated understanding of video-text alignment, leading to more reliable and informative systems.
RaTSG Network#
The RaTSG (Relation-aware Temporal Sentence Grounding) network is a novel architecture designed for the challenging task of Temporal Sentence Grounding with Relevance Feedback (TSG-RF). Its key innovation lies in addressing the uncertainty of relevant segment existence within videos. Unlike traditional TSG methods, RaTSG doesn’t assume relevance; it predicts relevance first, using a multi-granularity discriminator operating at both frame and video levels. This allows for precise feedback on whether a query is relevant to a given video, moving beyond the limitations of previous TSG models. This relevance score then dynamically gates a relation-aware grounding module, selectively activating the grounding process only when relevance is detected. This adaptive approach is crucial for handling real-world scenarios where query-related content might be absent, significantly improving efficiency and accuracy. The framework’s multi-task learning nature fosters mutual enhancement between relevance discrimination and segment grounding, resulting in a unified and effective architecture. The use of multi-granularity analysis (frame and video levels) is a strength, enhancing robustness and accuracy in discerning relevance. The entire approach is rigorously benchmarked using reconstructed datasets, addressing the scarcity of existing suitable TSG-RF datasets. In essence, RaTSG represents a significant advancement in the TSG field, offering a more practical and adaptable solution to a pervasive real-world problem.
Multi-Granularity Relevance#
The concept of “Multi-Granularity Relevance” in the context of Temporal Sentence Grounding with Relevance Feedback (TSG-RF) is a crucial advancement. It cleverly addresses the challenge of determining relevance between a video and a query by examining this relationship at both fine-grained (frame-level) and coarse-grained (video-level) levels. This dual approach is insightful because it acknowledges that the semantic connection might not be uniform across the entire video. Frame-level analysis allows for identifying precisely which frames contain query-related information, crucial when only parts of the video are relevant. Video-level analysis, on the other hand, accounts for the holistic context, capturing the overall semantic relevance even if it’s spread sparsely across frames. The integration of both levels provides robustness, leading to a more reliable relevance score. This strategy is particularly valuable in scenarios where the query-related content’s presence is uncertain. By combining these levels, the model avoids the pitfalls of relying solely on one level’s perspective, which could lead to inaccuracies or missed connections. This multi-granularity approach represents a more nuanced and robust way to tackle the relevance assessment problem, pushing the TSG-RF task towards a more realistic and effective solution.
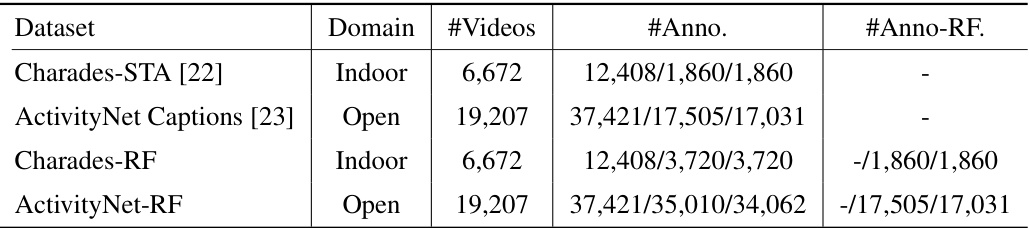
TSG-RF Datasets#
Creating effective datasets for Temporal Sentence Grounding with Relevance Feedback (TSG-RF) presents unique challenges. Existing TSG datasets assume relevance always exists, which is unrealistic. TSG-RF requires datasets reflecting scenarios where relevant segments may be absent, necessitating careful design. Reconstruction of existing datasets, like Charades-STA and ActivityNet Captions, by adding samples without relevant segments, is a crucial step. However, ensuring a balanced representation of positive and negative examples is vital for model training, avoiding bias towards one class. The process of identifying and curating ‘irrelevant’ samples requires careful consideration. Automated methods, possibly leveraging large language models, could improve efficiency and consistency in data creation. A well-defined methodology for dataset construction, including the criteria for determining relevance, is essential for transparency and reproducibility, ultimately benefiting the advancement and validation of TSG-RF research.
Future of TSG#
The future of Temporal Sentence Grounding (TSG) rests on addressing its current limitations and expanding its capabilities. Improving robustness to noisy or incomplete data is crucial, as real-world videos often contain irrelevant information or ambiguities. This could involve incorporating advanced techniques like multi-modal fusion that effectively combines audio, visual, and textual cues to improve grounding accuracy. Addressing the challenges posed by long videos and complex scenes requires scaling current methods and exploring more efficient architectures. Furthermore, developing more comprehensive evaluation metrics that assess not only grounding accuracy but also the semantic relevance and temporal coherence of the grounded segments is needed. Finally, extending TSG to handle diverse video types (e.g., live streams, 360° videos) and tasks (e.g., video summarization, question answering) will enhance its practical applications and broaden its impact.
More visual insights#
More on figures

This figure illustrates the architecture of the Relation-aware Temporal Sentence Grounding (RaTSG) network, which is proposed to address the Temporal Sentence Grounding with Relevance Feedback (TSG-RF) task. The network consists of two main components: a multi-granularity relevance discriminator and a relation-aware segment grounding module. The relevance discriminator determines whether query-related segments are present in the video. The grounding module localizes the segments if they exist. The multi-granularity relevance discriminator works at the frame and video levels to capture the relevance between text and video at different granularities. The relation-aware segment grounding module selectively performs grounding based on the relevance feedback.
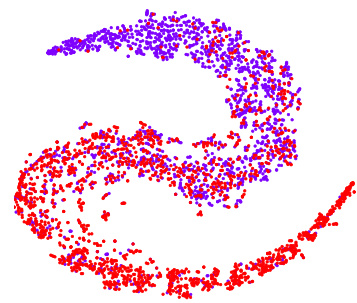
This figure visualizes the relation signal vectors obtained from the multi-granularity relevance discriminator using t-SNE (t-distributed Stochastic Neighbor Embedding). The t-SNE algorithm reduces the dimensionality of the high-dimensional relation signal vectors, allowing for visualization in a 2D space. Each point represents a sample from the Charades-RF test set, colored red if it is a relevant sample (i.e., query-video pair where the query text is semantically relevant to the video content) and blue if it is irrelevant. The visualization helps to understand how effectively the model distinguishes between relevant and irrelevant samples based on their relation signal vectors. The clustering of points suggests that the model effectively captures semantic relationships between the query text and video segments.
This figure highlights the key difference between the traditional Temporal Sentence Grounding (TSG) task and the proposed Temporal Sentence Grounding with Relevance Feedback (TSG-RF) task. TSG always outputs temporal boundaries for a query, even if the query is not present in the video. In contrast, TSG-RF first determines whether the query is relevant to the video and then selectively grounds the segment only if relevant. This makes TSG-RF more realistic for real-world applications.
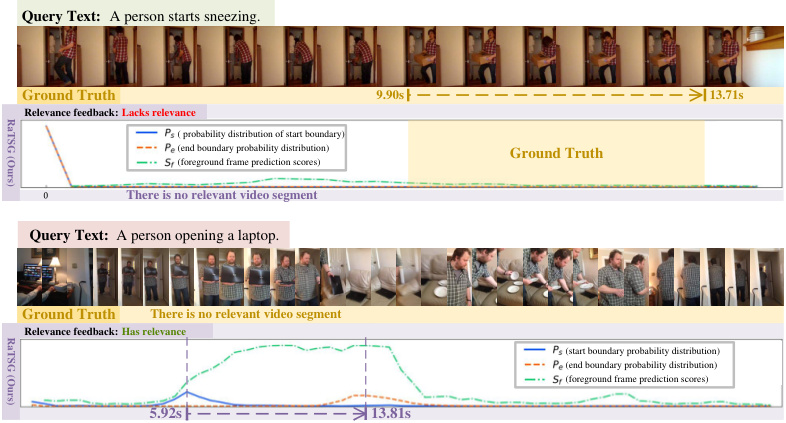
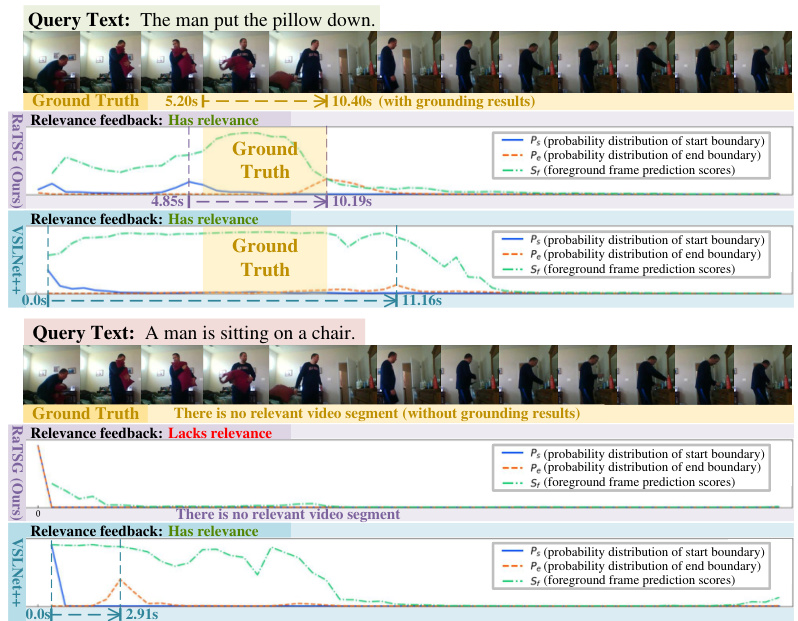
This figure shows two examples where the proposed RaTSG model makes mistakes. In the first example, the model incorrectly judges the relevance feedback due to a lack of audio cues (which are important for identifying the action of sneezing). In the second example, the model misinterprets the temporal sequence of actions (mistaking a closing action for an opening action). These examples demonstrate that the model struggles with audio-related actions and temporally sensitive content. The figure also includes visualizations of the model’s output probabilities for start and end boundaries, as well as foreground frame prediction scores.

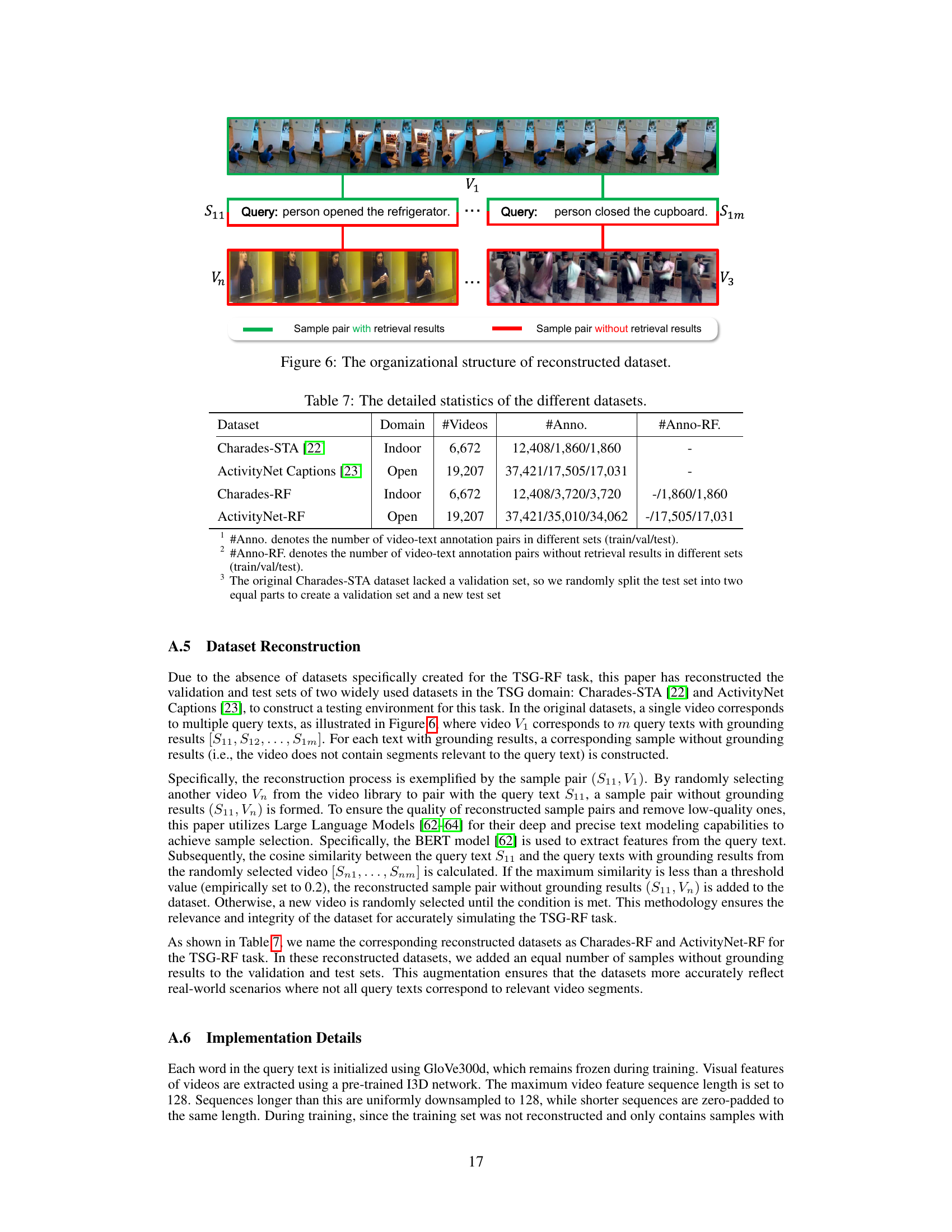
The figure illustrates how the datasets were reconstructed for the Temporal Sentence Grounding with Relevance Feedback (TSG-RF) task. Each video (V1) in the original datasets had multiple associated query sentences (S11, S12… S1m) with grounding results. To create the TSG-RF datasets, for each of these (query, video) pairs, another video (Vn) was randomly selected, and a new (query, video) pair was formed. This new pair is considered a sample without grounding results because the video (Vn) might not have any segment related to the query sentence. The figure visually represents this process, clearly differentiating samples with and without grounding results. This new dataset design allows the model to learn relevance feedback.
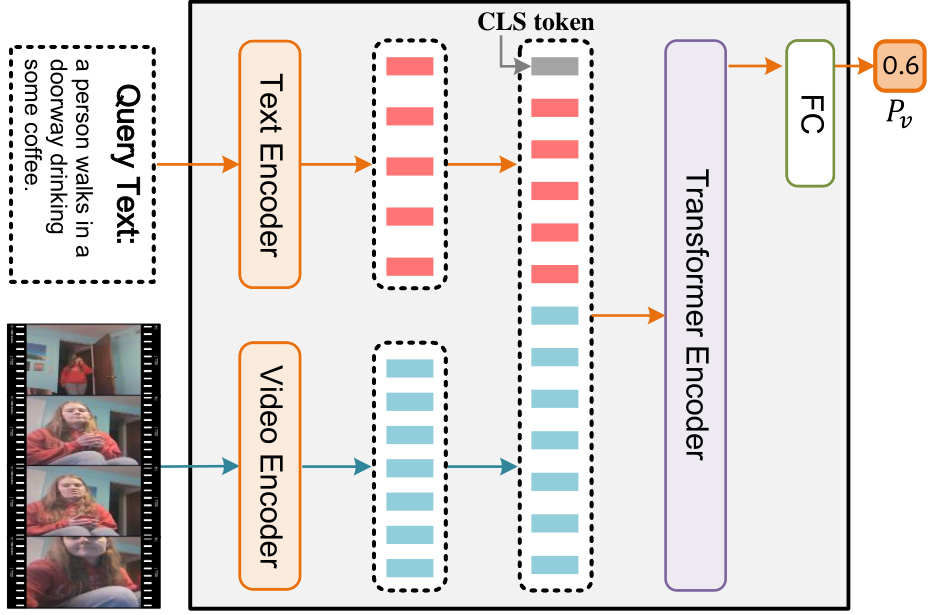
This figure shows the architecture of the Relation-aware Temporal Sentence Grounding (RaTSG) network. The network consists of two main modules: a multi-granularity relevance discriminator and a relation-aware segment grounding module. The relevance discriminator determines if a query is relevant to a video by assessing relevance at both the frame and video levels. If the query is relevant, the segment grounding module then identifies the precise temporal segment in the video that matches the query. If the query is not relevant, the grounding module does not produce any results.

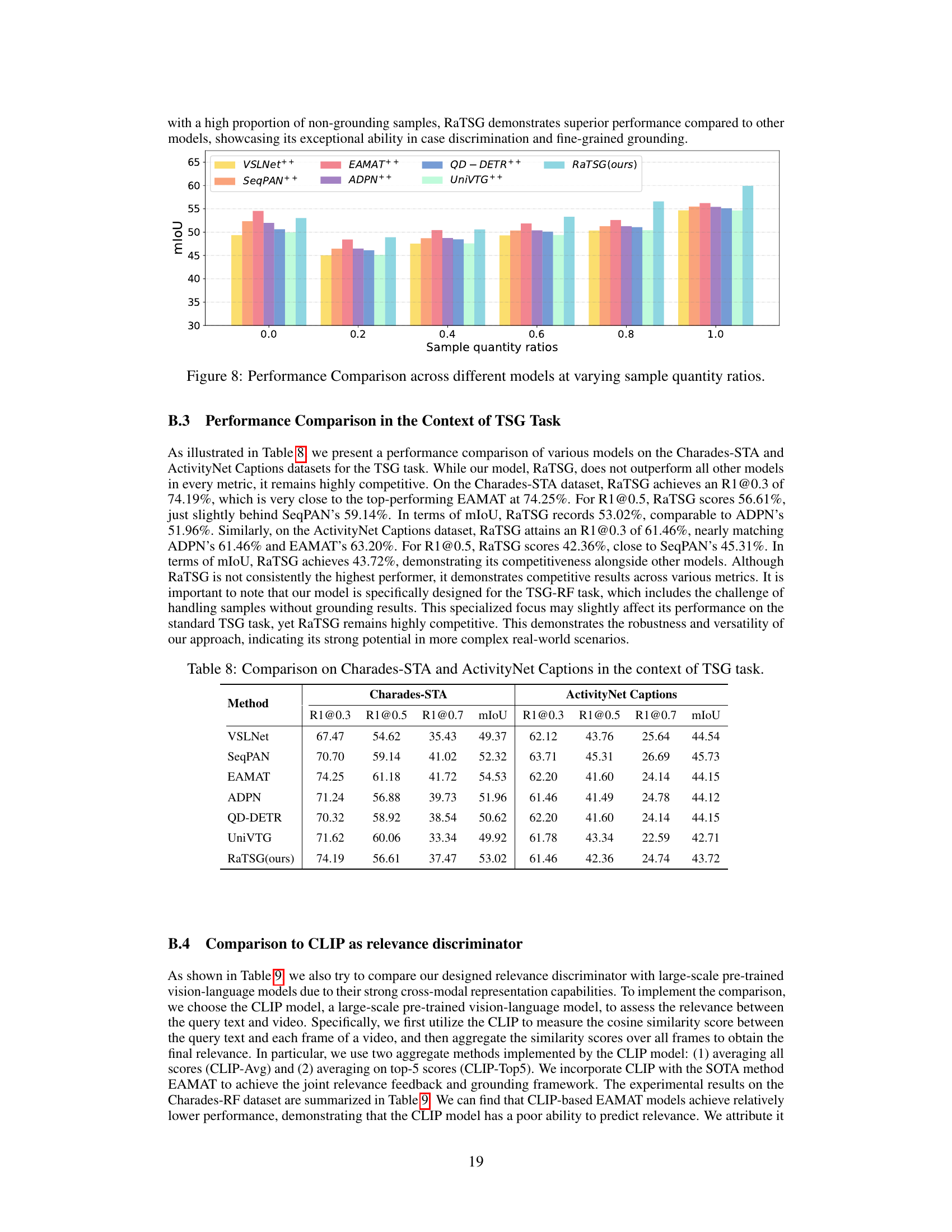
This figure presents a performance comparison of several models on the task of temporal sentence grounding with relevance feedback (TSG-RF). The x-axis represents the ratio of samples without grounding results to samples with grounding results in the test set. The y-axis shows the mean Intersection over Union (mIoU), a metric evaluating the accuracy of segment localization. The results demonstrate that as the proportion of samples without grounding results increases, the performance of all models improves, but RaTSG (the proposed model) shows the most significant improvement. This highlights RaTSG’s ability to effectively handle the TSG-RF task, especially in situations where a significant portion of the data lacks relevant segments.
More on tables
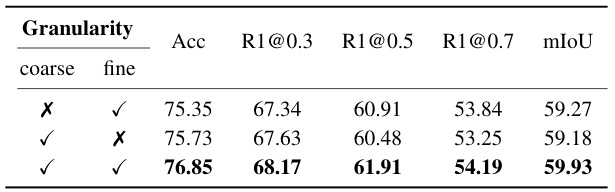
This table presents the ablation study results on the Charades-RF dataset to evaluate the effectiveness of the multi-granularity relevance discriminator. It compares the performance of the model using only coarse-grained relevance, only fine-grained relevance, and both coarse-grained and fine-grained relevance. The results demonstrate that using both granularities leads to the best performance, highlighting the importance of incorporating both frame-level and video-level relevance information.

This table presents the ablation study results on the effectiveness of the relation-aware segment grounding module in the proposed RaTSG model. It compares the performance of the model with and without the relation-aware segment grounding module on the Charades-RF dataset. The results demonstrate the positive impact of the relation-aware module on various metrics, including accuracy (Acc), recall at different IoU thresholds (R1@0.3, R1@0.5, R1@0.7), and mean IoU (mIoU).
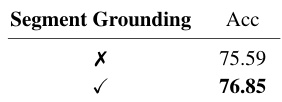
This table presents the ablation study results on the Charades-RF dataset, comparing the performance of relevance discrimination with and without the segment grounding module. It shows that including the segment grounding module improves the accuracy of relevance discrimination, highlighting the mutual enhancement between these two components of the RaTSG network.

This table presents a comparison of the performance of segment grounding on the Charades-STA dataset with and without a relevance discriminator. It shows that including the relevance discriminator improves the performance across all metrics (Acc, R1@0.3, R1@0.5, R1@0.7, mIoU). This highlights the importance of the relevance discriminator in improving the accuracy of segment localization.

This table compares the performance of the EAMAT model, its enhanced version with an added relevance discriminator (EAMAT++), and the EAMAT model enhanced with the proposed multi-granularity relevance discriminator and relation-aware segment grounding modules (EAMAT+Ours). The results demonstrate that integrating the proposed modules improves the performance of a traditional TSG model when adapted for the TSG-RF task.
This table presents a comparison of the proposed RaTSG model’s performance against several baseline models on two datasets (Charades-RF and ActivityNet-RF). The baseline models were adapted to handle the TSG-RF task by adding a separate relevance discriminator. The table shows that RaTSG, a unified model, outperforms the adapted baseline models across various metrics (Accuracy, Recall@0.3, Recall@0.5, Recall@0.7, and mean IoU) while maintaining a smaller model size, highlighting its efficiency and effectiveness.

This table presents a quantitative comparison of the proposed RaTSG model against several baseline models on two datasets: Charades-RF and ActivityNet-RF. The baseline models are adapted to handle the TSG-RF task by adding a separate relevance discriminator. The table shows the accuracy of relevance feedback, recall at various IoU thresholds (R1@0.3, R1@0.5, R1@0.7), and mean IoU (mIoU). RaTSG consistently outperforms the other methods, demonstrating the effectiveness of its unified approach.

This table compares the performance of several models on two datasets (Charades-RF and ActivityNet-RF) for the task of Temporal Sentence Grounding with Relevance Feedback (TSG-RF). It shows the accuracy (Acc), recall at different IoU thresholds (R1@0.3, R1@0.5, R1@0.7), and mean IoU (mIoU) for each model. The models include several baseline TSG models adapted to handle the TSG-RF task (by adding a relevance discriminator), and the proposed RaTSG model, which is a unified approach combining relevance discrimination and segment grounding. The results demonstrate that RaTSG achieves the best performance with a simpler architecture than the adapted baseline models.
Full paper#