↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Unsupervised skill discovery aims to train AI agents to learn reusable skills solely through interaction with their environment. However, current methods frequently generate entangled skills, where a single skill affects multiple environmental aspects, impeding efficient skill chaining. This significantly hinders the effective application of skills to solve complex downstream tasks.
The proposed method, Disentangled Unsupervised Skill Discovery (DUSDi), directly tackles this challenge. DUSDi decomposes skills into independent components and uses a novel mutual information-based reward to optimize for disentanglement. By using value factorization, DUSDi efficiently learns these disentangled skills, outperforming prior methods in solving complex tasks. The results demonstrate the significance of disentanglement in unsupervised skill learning and hierarchical reinforcement learning, opening new avenues for training more versatile and efficient AI agents.
Key Takeaways#
Why does it matter?#
This paper is highly relevant to researchers working on hierarchical reinforcement learning and unsupervised skill discovery. It offers a novel solution to the problem of entangled skills, which significantly improves the efficiency of downstream task learning. The proposed method, DUSDI, is both innovative and practical, paving the way for more efficient and versatile AI agents. The results have the potential to impact various applications, ranging from robotics and autonomous systems to multi-agent systems, making this paper crucial reading for researchers in these areas.
Visual Insights#
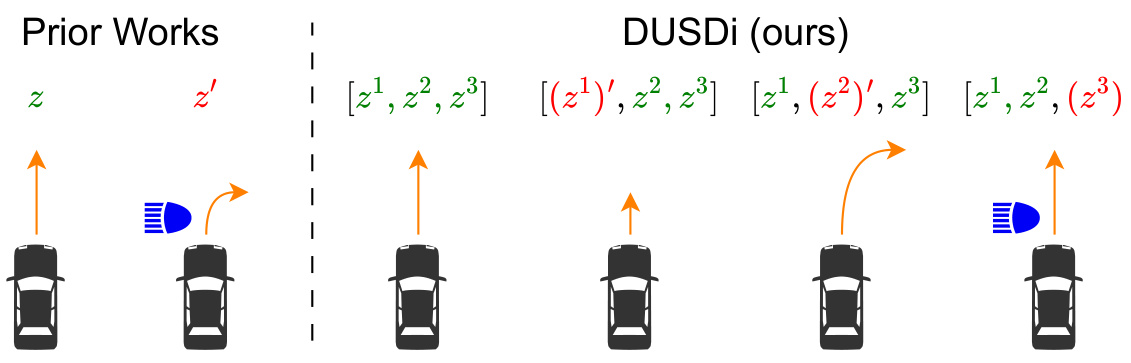
This figure illustrates the difference between entangled and disentangled skills in unsupervised reinforcement learning. The left side shows prior methods learning entangled skills, where a single skill variable affects multiple aspects of the environment (speed, steering, headlights). The right side depicts DUSDi, which learns disentangled skills. Each skill component independently controls a single aspect of the environment, enabling more efficient downstream task solving with hierarchical reinforcement learning.

This table presents the results of evaluating skill disentanglement using the Disentanglement, Completeness, and Informativeness (DCI) metric. The DCI metric assesses how well-separated (disentangled) the learned skills are, whether they cover a comprehensive range of states, and how informative they are in predicting states. The table shows the mean and standard deviation of DCI scores across three different training runs for four different methods, specifically, the proposed method DUSDi and three baselines. Three different environments are used: 2D Gunner, Multi-Particle, and iGibson, reflecting the diversity of environments used for training and evaluation.
In-depth insights#
Unsupervised Skill#
Unsupervised skill discovery in reinforcement learning aims to enable agents to learn reusable skills without explicit reward signals. This is a significant challenge because it requires the agent to intrinsically motivate itself to explore and discover useful behaviors. Effective unsupervised skill discovery methods must address the problem of skill entanglement, where a single skill variable influences multiple aspects of the environment simultaneously, hindering the efficient reuse of skills for downstream tasks. Disentangled skill discovery methods strive to overcome this limitation, learning skill components that independently affect specific factors of the environment’s state space, leading to improved flexibility and compositionality. A key aspect involves defining appropriate intrinsic reward functions to encourage disentanglement, often based on mutual information measures between skills and state factors. The evaluation of unsupervised skill discovery often focuses on the downstream performance, comparing the efficiency and success rate of solving new tasks when using the learned skills versus learning from scratch. Successful methods demonstrate a considerable improvement in sample efficiency and the ability to handle complex tasks. Further research focuses on improving the scalability, robustness, and generalizability of these techniques across diverse environments.
Disentangled Learning#
Disentangled learning aims to decompose complex data into independent, meaningful factors. Unlike traditional machine learning models that often learn entangled representations where features are intertwined and difficult to interpret, disentangled learning seeks to uncover latent variables that cleanly separate these factors. This allows for better understanding of the underlying data structure, improved generalizability to unseen data, and enhanced control over the model’s output. In the context of reinforcement learning, disentangled representations are especially beneficial because they enable agents to acquire a set of reusable skills that can be efficiently combined to perform complex tasks in novel situations. A key challenge in disentangled learning is defining and enforcing appropriate disentanglement criteria, as there is often no single, universally optimal way to separate latent factors. Different methods have been proposed, with each approach having its own strengths and weaknesses. Mutual information and variational autoencoders are commonly used techniques, but newer methods utilize generative models and other more sophisticated tools to further improve disentanglement. Despite ongoing research, creating truly disentangled representations remains an active area of research.
Q-function Decomp#
The proposed Q-function decomposition method is a crucial innovation for handling high-dimensional state spaces in reinforcement learning. By decomposing the Q-function into N disentangled Q-functions, one for each disentangled skill component, the method addresses the challenges posed by high-variance rewards when using standard RL algorithms with many state factors. This decomposition not only reduces reward variance but also facilitates efficient credit assignment by decoupling reward terms for each component, enabling faster and more stable learning. This approach is particularly beneficial in complex environments where learning a single Q-function for all state factors simultaneously is difficult and leads to suboptimal results. The efficacy of this method is evident in its improved convergence and superior performance compared to standard techniques when dealing with multiple entangled state factors. It significantly improves downstream task learning by facilitating the efficient reuse of the learned disentangled skills in hierarchical RL settings. The efficient and reliable training of the disentangled skill components is a vital step toward more efficient and scalable reinforcement learning, particularly in complex multi-agent and robotics systems.
HRL Efficiency#
Hierarchical Reinforcement Learning (HRL) efficiency is a crucial aspect of the research paper. The core argument centers on how disentangled skills, learned through the proposed Disentangled Unsupervised Skill Discovery (DUSDi) method, significantly boost HRL efficiency compared to using entangled skills. The paper posits that disentangled skills enable easier recombination and concurrent execution, which is crucial for complex downstream tasks. This is because each skill component in DUSDi affects only one factor of the environment’s state space, leading to improved modularity and simpler skill chaining in HRL. The improved efficiency manifests in faster learning and higher overall performance in downstream tasks. The use of Q-function decomposition further enhances the method’s efficiency by reducing reward variance and enhancing the stability of the learning process. Overall, the paper demonstrates that DUSDi’s approach to learning disentangled skills is key to unlocking significant improvements in HRL’s effectiveness, particularly in scenarios involving complex state spaces and the need for concurrent skill execution.
Future Directions#
Future research could explore extending DUSDi’s capabilities to handle continuous skill spaces and richer, non-discrete state representations, potentially through advancements in representation learning. Investigating the effects of different mutual information estimations and alternative reward formulations would also be valuable. Furthermore, developing methods for automatically inferring the state factorization from raw sensory data would greatly expand DUSDi’s applicability to real-world robotics. Comparative analysis against additional unsupervised skill discovery techniques, including those that don’t explicitly leverage mutual information, would strengthen the evaluation and highlight DUSDi’s unique strengths. Finally, exploring advanced methods to integrate domain knowledge into the learning process and scaling DUSDi to handle a significantly larger number of state factors and skill components represent exciting avenues for future work.
More visual insights#
More on figures
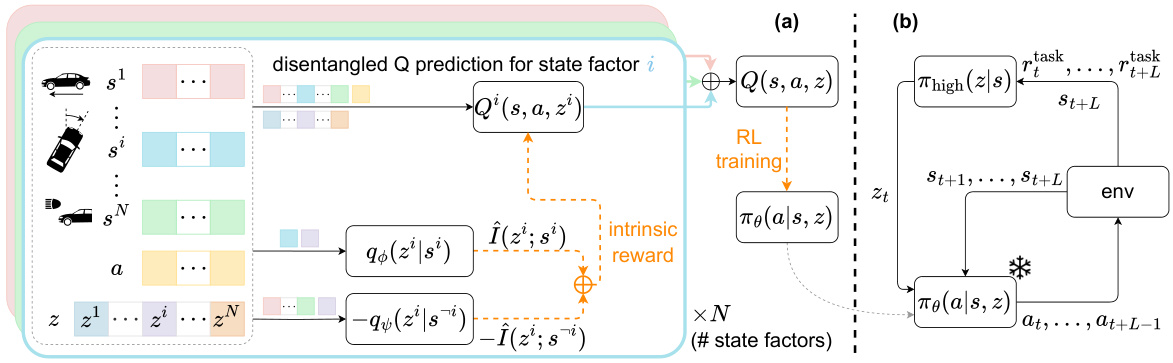
This figure illustrates the two-stage learning process in DUSDi. The first stage (a) focuses on learning disentangled skills where each skill component affects only one state factor. A novel mutual-information-based intrinsic reward and Q-value decomposition are used to achieve efficient learning. The second stage (b) uses these learned skills within a hierarchical RL framework to solve downstream tasks by training a high-level policy to select appropriate low-level skills.
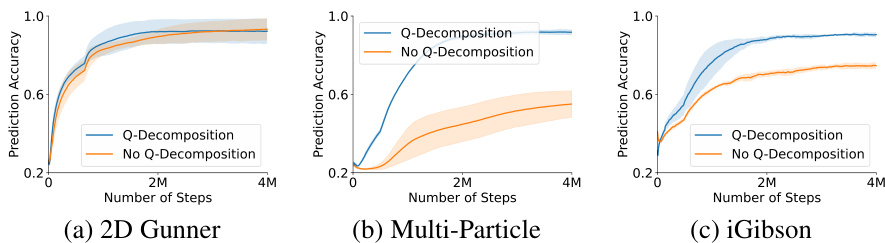
This figure shows the impact of using Q-decomposition in the skill learning phase of DUSDi. Three subplots present the prediction accuracy for skill components (z²) based on state factors (s²) across three different environments: 2D Gunner, Multi-Particle, and iGibson. Higher accuracy signifies that the learned skills successfully control more state factors independently, improving downstream task learning efficiency. The error bars represent the standard deviation across three training runs.
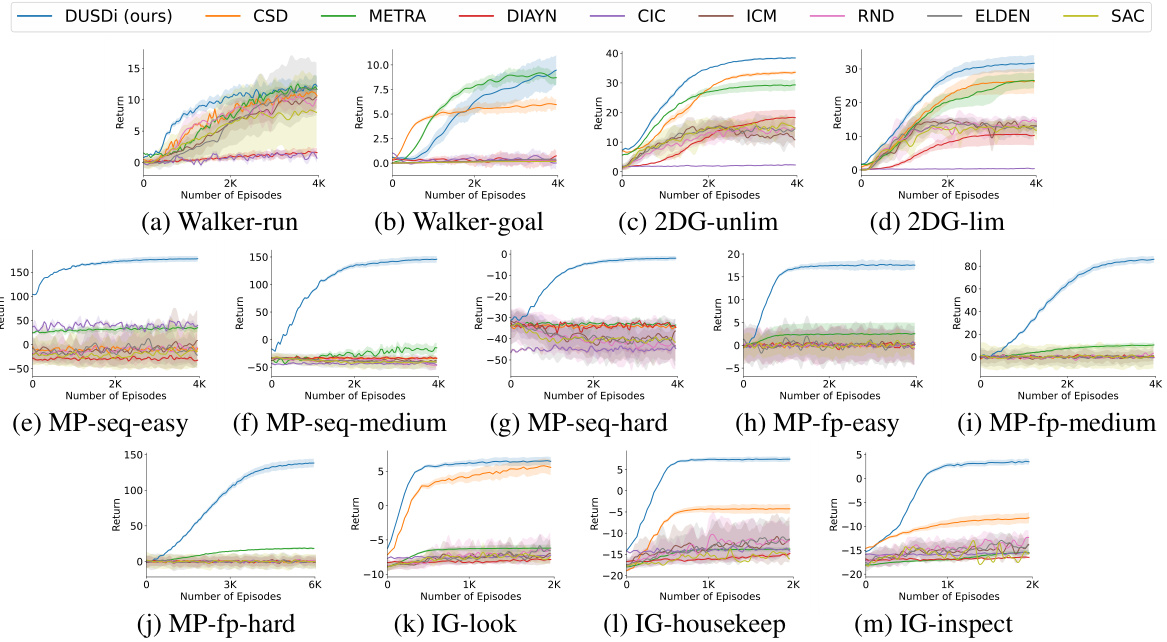
This figure displays the performance comparison of DUSDi against several baseline methods across various downstream tasks. Each subplot represents a different task, and the y-axis shows the average return achieved by each algorithm. The x-axis indicates the number of training episodes. The shaded area around each line represents the standard deviation over three independent trials. The figure highlights DUSDi’s superior performance and faster convergence in most tasks compared to other unsupervised reinforcement learning methods. This emphasizes the effectiveness of DUSDi’s disentangled skill learning in handling complex downstream tasks.
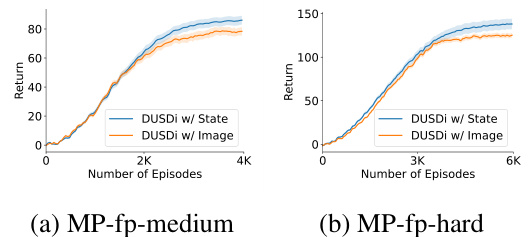
This figure shows the performance comparison between DUSDI using state observations and DUSDI using image observations on two downstream tasks in the Multi-Particle environment. The results demonstrate that DUSDI can effectively learn skills from image observations and achieve similar performance to when using state observations, while baseline methods fail to learn these tasks even with state observations. This highlights the effectiveness of DUSDI’s disentangled representation learning in handling complex observation spaces.

This figure shows the performance comparison of DUSDi with and without Causal Policy Gradient (CPG) on two downstream tasks in the Multi-particle environment. The results demonstrate that using DUSDi’s disentangled skills allows for leveraging structure in the downstream task, leading to a significant improvement in sample efficiency. Specifically, the plots show the learning curves for the two methods across multiple training runs, indicating faster convergence and higher overall returns when using CPG in conjunction with DUSDi.
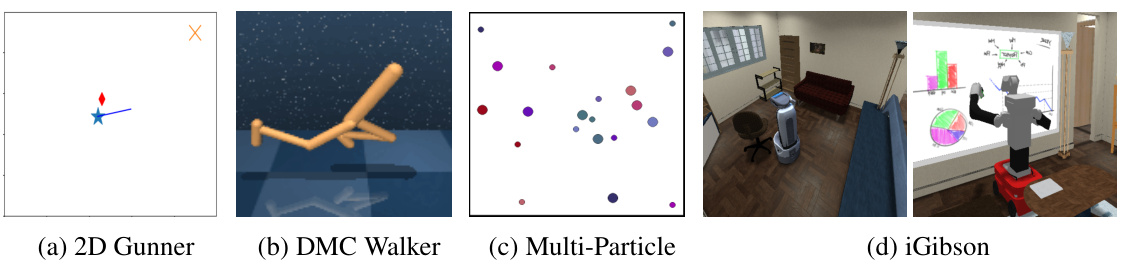
This figure shows four different environments used in the paper’s experiments: 2D Gunner, DMC Walker, Multi-Particle, and iGibson. Each environment is a simulation used to evaluate the effectiveness of the proposed Disentangled Unsupervised Skill Discovery (DUSDi) method. The visualizations provide a visual representation of the state space of each environment, illustrating the diversity of task settings used in the experiments and the complexity of the challenges addressed by the method.
More on tables
This table presents the results of evaluating skill disentanglement using the DCI (Disentanglement, Completeness, Informativeness) metric. The mean and standard deviation of the DCI scores are shown for DUSDI and a baseline method (DIAYN-MC) across three different environments (2D Gunner, Multi-Particle, iGibson). Each environment has its own row in the table, and each method has its own set of columns for Disentanglement, Completeness, and Informativeness. Higher scores indicate better disentanglement, completeness, and informativeness, which are aspects of how well the learned skills separate different aspects of the environment’s state.
This table lists the hyperparameters used for downstream learning (the second phase of the DUSDi process) using Proximal Policy Optimization (PPO). These hyperparameters are consistent across all skill discovery methods and downstream tasks within the paper’s experiments. The hyperparameters cover optimization settings (optimizer, activation function, learning rate, batch size), policy update parameters (clip ratio, MLP size, GAE lambda, target steps, n steps), and environmental parameters (number of environments and low-level steps).
Full paper#



















