↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual learning (CL) aims to enable AI models to learn new tasks without forgetting previously learned ones. Existing prompt-based CL methods, while effective, lack theoretical explanations for their success. Catastrophic forgetting is a major challenge in CL; it is the phenomenon where a model struggles to remember previous tasks when it learns new ones. Existing solutions often lack theoretical justifications or are not parameter efficient.
This paper provides a novel theoretical analysis demonstrating that the attention mechanism in pre-trained models inherently encodes a Mixture-of-Experts (MoE) architecture. The authors show that prefix tuning introduces new task-specific experts to this architecture. Based on this finding, they introduce a novel gating mechanism called Non-linear Residual Gates (NoRGa) to enhance performance. NoRGa integrates non-linear activation and residual connections for improved sample efficiency. Extensive experiments show NoRGa achieves state-of-the-art results across multiple benchmarks, showcasing its practical value and theoretical soundness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in continual learning, offering a novel theoretical understanding of prompt-based methods and a new, efficient gating mechanism. It bridges the gap between prompt engineering and mixture-of-experts models, opening avenues for more effective and efficient continual learning approaches. The theoretical justification adds rigor, while the empirical results demonstrate state-of-the-art performance, making this a significant contribution to the field.
Visual Insights#
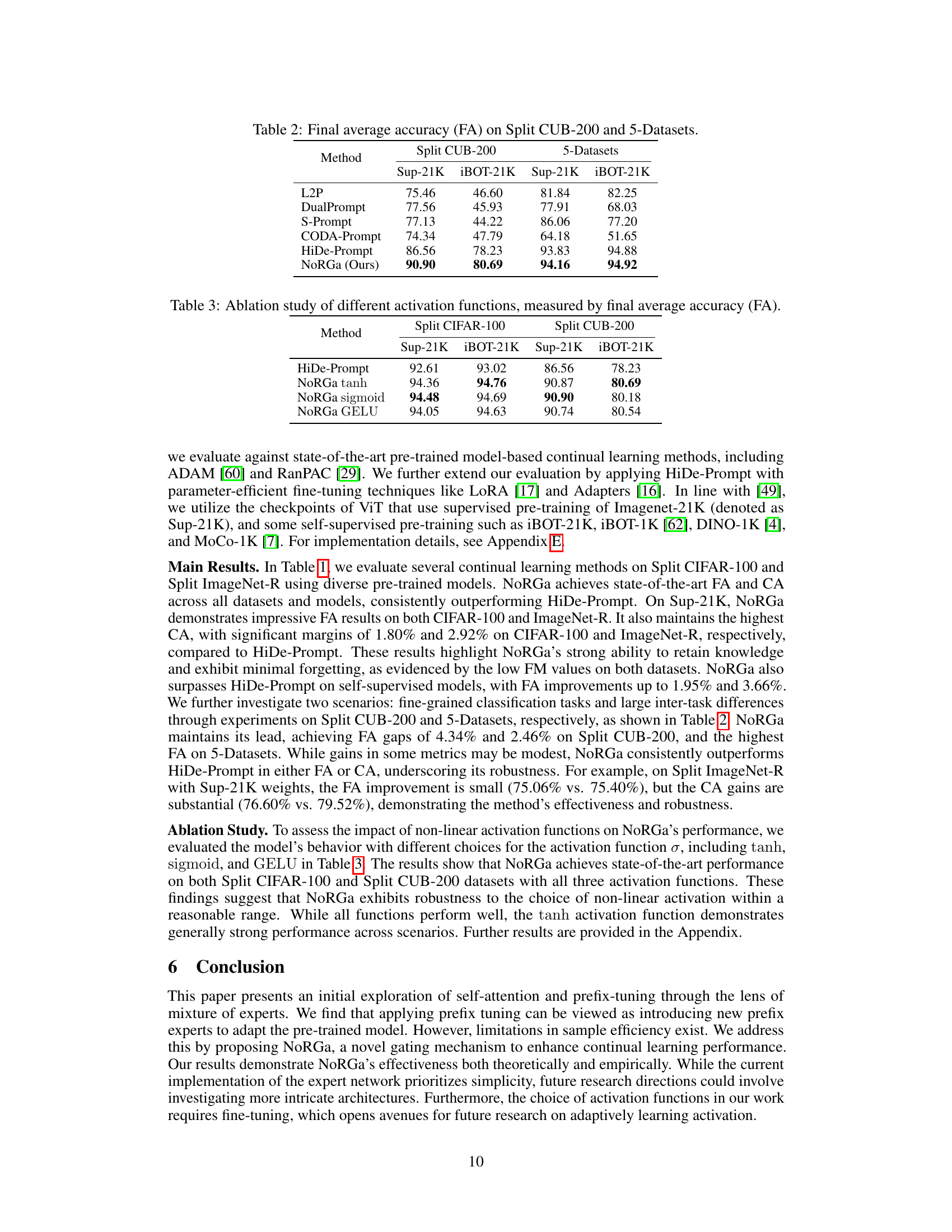
This figure illustrates the connection between the self-attention mechanism in Vision Transformers and the Mixture of Experts (MoE) model. It shows how each output vector from a self-attention head can be interpreted as the output of an MoE model. The experts in this MoE are represented by the rows of the value matrix in the self-attention, and each element of the attention matrix represents a score function used for gating in the MoE. This visual representation helps to understand how the self-attention block implicitly incorporates an MoE architecture.

This table compares the performance of different continual learning methods (L2P, DualPrompt, S-Prompt, CODA-Prompt, HiDe-Prompt, and NoRGa) on two benchmark datasets (Split CIFAR-100 and Split ImageNet-R). The comparison is done using various pre-trained models (Sup-21K, iBOT-21K, iBOT-1K, DINO-1K, and MoCo-1K). The table shows the final average accuracy (FA), cumulative average accuracy (CA), and average forgetting measure (FM) for each method and pre-trained model combination. The results highlight the effectiveness of the proposed NoRGa method in achieving state-of-the-art performance on both datasets.
In-depth insights#
Prompt-MoE Link#
The heading ‘Prompt-MoE Link’ suggests a crucial connection between prompt-based learning and Mixture of Experts (MoE) models. The core idea likely revolves around interpreting prompt tuning, a popular technique in continual learning, as a mechanism for dynamically adding or modulating experts within a pre-trained MoE architecture. Prompt engineering becomes expert management, where different prompts activate or weight specific expert networks to handle new tasks or data distributions. This reframing offers a powerful theoretical lens, potentially leading to more efficient and robust continual learning. The effectiveness of this ‘Prompt-MoE Link’ would hinge on demonstrating how the attention mechanisms in transformers, often implicitly encoding an MoE structure, can be leveraged and controlled through prompt design. Successfully establishing this link would be a significant contribution, bridging the gap between empirical success of prompt methods and a deeper theoretical understanding. Parameter-efficient continual learning becomes the practical outcome, offering a path towards models that retain knowledge over time while still being computationally feasible.
NoRGa Gating#
The proposed NoRGa (Non-linear Residual Gates) gating mechanism offers a novel approach to enhance prompt-based continual learning. NoRGa directly addresses the suboptimal sample efficiency of existing prefix tuning methods by incorporating non-linear activation functions and residual connections into the gating score functions. This modification not only improves the within-task prediction accuracy but also provides theoretical justification for accelerated parameter estimation rates. The integration of non-linearity introduces a beneficial complexity, enabling the model to learn more nuanced relationships between tasks and prevent catastrophic forgetting more effectively. The residual connection safeguards against vanishing gradients, ensuring stable training and robustness. By reframing prefix tuning as the addition of new task-specific experts within a mixture-of-experts architecture, NoRGa leverages the strengths of both approaches to achieve superior performance. Empirically, NoRGa demonstrates state-of-the-art results across diverse benchmarks and pre-training paradigms, highlighting its practical significance and broad applicability.
CIL Experiments#
In a hypothetical research paper section on “CIL Experiments,” a thorough analysis would delve into the methodologies used to evaluate Class Incremental Learning (CIL) performance. This would involve a detailed description of the datasets employed, likely including standard benchmarks like CIFAR-100 and ImageNet-R, and potentially others suited to assess fine-grained classification. The experimental setup should be meticulously documented, specifying data splits, evaluation metrics (e.g., accuracy, forgetting rate), and the specific CIL algorithms being compared. Crucially, the analysis should highlight the baseline methods used for comparison, ensuring a robust evaluation. Furthermore, a discussion of the results is imperative, focusing not only on the overall performance achieved but also on identifying trends, such as performance degradation over time or the effectiveness of particular techniques in mitigating catastrophic forgetting. Statistical significance testing would be critical, as would an analysis of the computational cost and memory requirements of different approaches. A complete and transparent presentation of experimental details is vital for reproducibility and allows for a fair assessment of the presented results.
Statistical Analysis#
A thorough statistical analysis within a research paper is crucial for validating the claims and conclusions. It involves meticulous planning and execution, encompassing the selection of appropriate statistical methods, consideration of sample size and power, and the proper handling of missing data. The choice of statistical tests must align with the data type and research question, while ensuring that assumptions underlying the tests are met or addressed. Reporting of results should be clear and comprehensive, including effect sizes, confidence intervals, p-values, and measures of variability. Visualizations, like graphs and charts, can effectively complement numerical results. Furthermore, interpreting results requires careful consideration of the limitations of the statistical methods used, and potential confounding factors. Finally, the discussion section should clearly articulate the implications of the findings, acknowledging any limitations and suggesting directions for future research. A robust statistical analysis strengthens the credibility and impact of a research paper significantly.
Future Works#
Future research could explore more complex expert architectures within the Mixture of Experts framework to potentially boost performance. Investigating alternative non-linear activation functions beyond those tested (tanh, sigmoid, GELU) might reveal further improvements in sample efficiency. A deeper exploration of the interplay between the choice of activation functions and algebraic independence is needed for optimal performance and theoretical understanding. Adaptively learning activation functions during training, instead of using fixed ones, is a promising avenue for enhanced performance. Exploring different prompt designs and their impact on the MoE structure could lead to even more efficient continual learning solutions. Finally, extending these findings to other continual learning scenarios beyond the class-incremental setting would strengthen the generality of the proposed methods and their potential applicability across a wider range of tasks and problems.
More visual insights#
More on figures
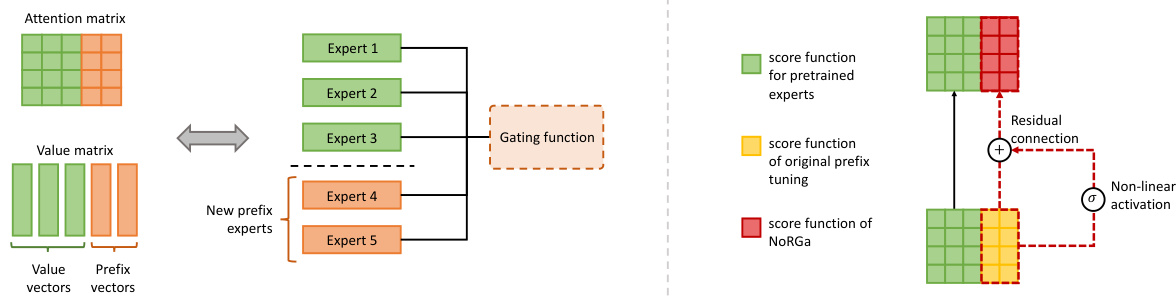
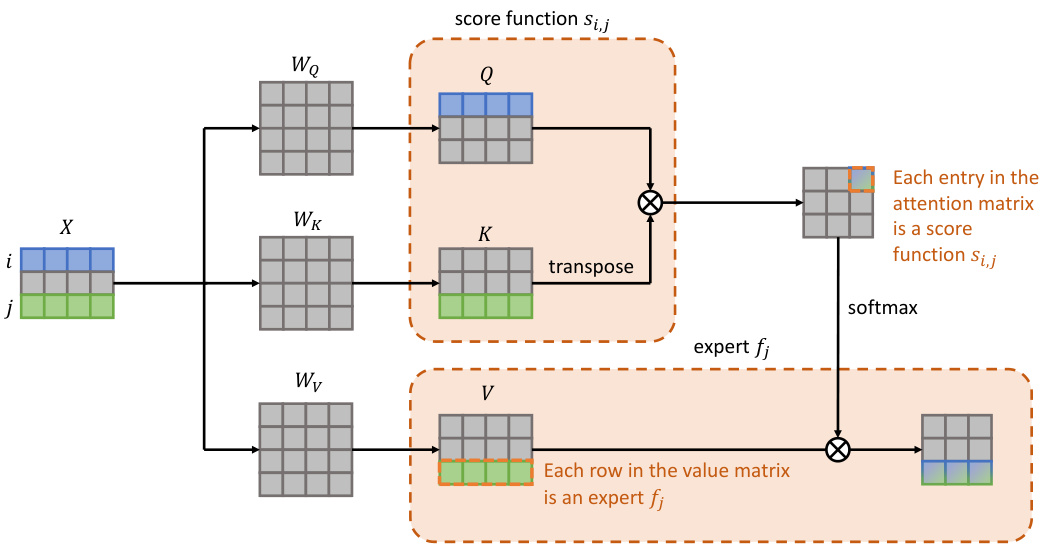
The figure illustrates the concept of prefix tuning as introducing new experts to a pre-trained Mixture of Experts (MoE) model. The left side shows how prefix tuning adds new experts (represented in the value matrix) to the existing experts of the pre-trained model, while the right side details the proposed NoRGa mechanism, highlighting how it enhances the gating function of prefix tuning through non-linear activation and residual connections. NoRGa improves the model’s ability to adapt to new tasks and enhance the efficiency of parameter estimations.
The figure shows two illustrations. The left one illustrates prefix tuning as introducing new experts to pre-trained Mixture of Experts (MoE) models. The right one visualizes the implementation of Non-linear Residual Gates (NoRGa), which integrates non-linear activation and residual connections into the prefix tuning attention matrix. NoRGa is proposed to address the suboptimal sample efficiency of the original prefix tuning by incorporating non-linearity and residual connection.
More on tables
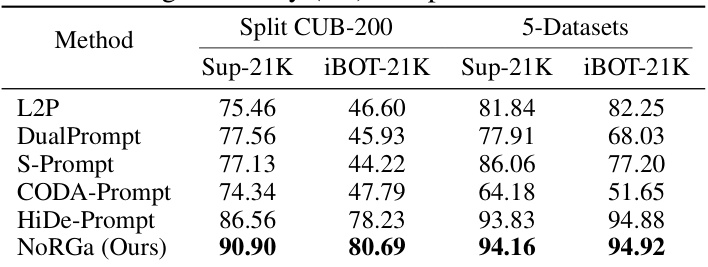
This table presents the final average accuracy (FA) achieved by different continual learning methods on two benchmark datasets: Split CUB-200 (a fine-grained image classification dataset) and 5-Datasets (a dataset combining five different datasets with varying characteristics). The results are broken down by the pre-trained model used (Sup-21K and iBOT-21K), showing the performance of each method across different data scenarios and pre-training techniques. This helps in understanding the generalization capabilities of each method across diverse datasets.
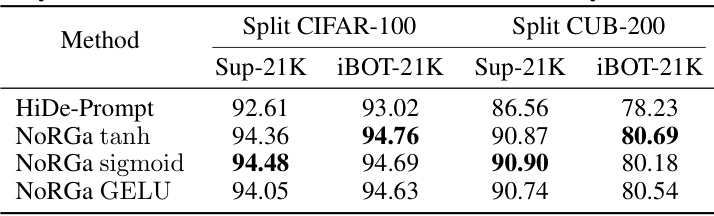
This table presents the ablation study results of using different activation functions (tanh, sigmoid, and GELU) within the NoRGa method. The final average accuracy (FA) metric is used to evaluate the performance on Split CIFAR-100 and Split CUB-200 datasets with both Sup-21k and iBOT-21k pre-trained models. The results show the impact of the activation function on the model’s performance in a continual learning setting.

This table presents the final average accuracy (FA) achieved by different methods in a task-incremental learning setting. Task-incremental learning differs from class-incremental learning in that the model knows the task identity at test time. The table compares the performance of HiDe-Prompt and NoRGa (with different activation functions) on two datasets (Split CIFAR-100 and Split CUB-200), using two different pre-trained models (Sup-21K and iBOT-21K). The results show that NoRGa generally outperforms HiDe-Prompt, achieving higher accuracy across the different datasets and pre-trained models.

This table shows the final average accuracy (FA) achieved by different continual learning methods on two benchmark datasets: Split CUB-200 (a fine-grained image classification dataset) and 5-Datasets (a dataset designed to test continual learning performance with large inter-task differences). The results are broken down by the pre-trained model used (Sup-21K and iBOT-21K). The table helps demonstrate the effectiveness of the NoRGa method compared to other state-of-the-art continual learning approaches, showing that NoRGa maintains higher accuracy and exhibits less catastrophic forgetting across a range of tasks and pre-trained models.

This table compares the final average accuracy (FA) of several pre-trained model-based continual learning methods on the Split CIFAR-100 and Split CUB-200 datasets. The methods compared include ADAM with various parameter-efficient fine-tuning techniques (VPT-D, SSF, Adapter) and RanPAC, a recent state-of-the-art method. The results show that the proposed NoRGa method significantly outperforms all other methods.

This ablation study analyzes the impact of different activation functions (tanh, sigmoid, GELU) on the NoRGa model’s final average accuracy (FA). The experiment measures the performance on the Split CIFAR-100 and Split CUB-200 datasets using Sup-21K and iBOT-21K pre-trained models to determine the optimal activation function for the NoRGa model.

This table compares the performance of different continual learning methods (L2P, DualPrompt, S-Prompt, CODA-Prompt, HiDe-Prompt, and NoRGa) on two benchmark datasets (Split CIFAR-100 and Split ImageNet-R). It shows the final average accuracy (FA), cumulative average accuracy (CA), and average forgetting measure (FM) for each method, using various pre-trained models (Sup-21K, iBOT-21K, iBOT-1K, DINO-1K, and MoCo-1K). The results demonstrate the relative effectiveness of each method in preventing catastrophic forgetting and maintaining high accuracy across multiple tasks.
Full paper#