↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional self-supervised learning (SSL) methods for image representation often enforce strong inductive biases by hardcoding invariances or equivariances to specific augmentations. This can make the learned representations brittle and not adaptable to downstream tasks with different symmetry requirements. This is because the augmentations used during pretraining do not universally apply across all tasks.
The paper introduces CONTEXTSSL, a contrastive learning framework that learns a general representation by paying attention to context, which represents a task. Unlike previous methods, CONTEXTSSL adapts to task-specific symmetries without parameter updates. This adaptive approach makes it a general-purpose SSL framework that achieves state-of-the-art performance on various benchmark datasets and exhibits significant improvements over existing methods. The results indicate that CONTEXTSSL is effective in addressing the issue of brittleness in existing SSL models and in learning a general representation adaptable to different task-specific symmetries.
Key Takeaways#
Why does it matter?#
This paper is highly relevant to researchers working on self-supervised learning, world models, and equivariance. It offers a novel approach that addresses the limitations of existing methods and opens up new avenues for research in these areas. The proposed method, CONTEXTSSL, is adaptable, general-purpose, and shows significant performance improvements in several benchmark datasets, making it a valuable contribution to the field.
Visual Insights#
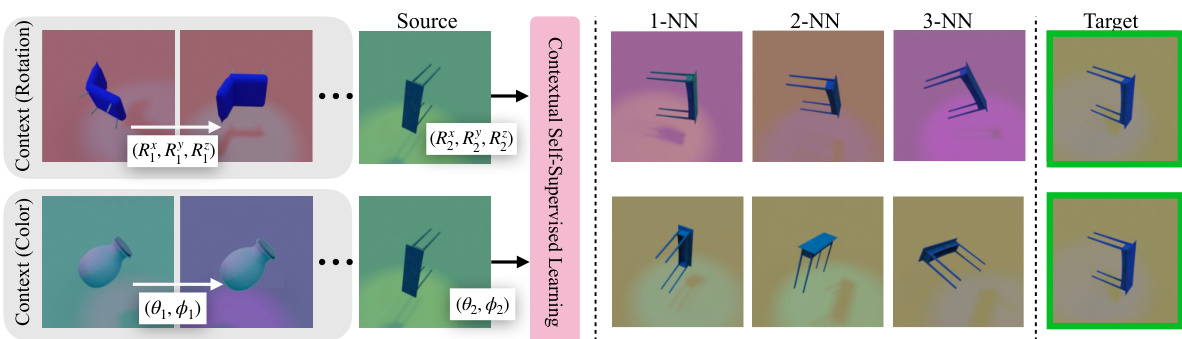
This figure demonstrates the adaptive nature of CONTEXTSSL in learning task-specific symmetries. It shows how the model’s response to transformations (rotation and color changes) depends on the provided context. When the context includes rotation examples, CONTEXTSSL becomes equivariant to rotation and invariant to color (top). Conversely, when the context contains color examples, CONTEXTSSL learns the opposite, showing equivariance to color and invariance to rotation (bottom). This highlights the model’s ability to adapt its symmetry behavior based on the context provided, showcasing its flexibility and generalizability.
This table presents the quantitative results of CONTEXTSSL on MIMIC-III dataset. It compares the performance of CONTEXTSSL with different context lengths (0 and 126) on two tasks: invariant LOS prediction and equivariant treatment prediction. The results show the accuracy (Acc) for gender prediction, LOS prediction, and treatment prediction, along with fairness metrics for LOS prediction (equalized odds and equality of opportunity). This demonstrates CONTEXTSSL’s ability to adapt to task-specific symmetries, showing improved performance on equivariant tasks with longer context lengths while maintaining or improving fairness on invariant tasks.
In-depth insights#
Contextual SSL#
Contextual Self-Supervised Learning (SSL) offers a novel approach to learning representations by adapting to task-specific symmetries. Unlike traditional SSL methods that enforce fixed invariances or equivariances, Contextual SSL dynamically adjusts its symmetry based on contextual cues. This adaptation is achieved through a memory module that tracks task-specific states, actions, and future states, effectively using context to guide the learning process. The action is defined as the transformation applied, while current and future states represent input before and after the transformation. The use of attention mechanisms further enhances the model’s adaptability. By leveraging context, Contextual SSL can eliminate augmentation-based inductive priors, enabling flexible adaptation to various downstream tasks without the need for extensive retraining. This approach holds significant promise for building more robust and generalizable visual representations that are not limited by pre-defined symmetries.
World Models#
The concept of ‘World Models’ in the context of this research paper appears to be a crucial innovation, bridging the gap between traditional self-supervised learning (SSL) and more adaptive, context-aware representations. Instead of imposing fixed inductive biases through data augmentations, the paper leverages the power of world models to learn representations that are dynamically invariant or equivariant to different transformations, adapting on a per-task basis. This adaptive nature of the model is key, as it addresses a fundamental limitation of many SSL methods that fail to generalize effectively across various downstream applications due to their hardcoded assumptions about task-relevant symmetries. By incorporating a context module, the ‘World Model’ framework learns which specific features to focus on (or ignore) for a given task, effectively eliminating the need for retraining when dealing with different data transformations. This approach allows for more robust and generalizable representations that dynamically adapt to the needs of various tasks, mirroring human perceptual abilities.
Adaptive Symmetry#
The concept of “Adaptive Symmetry” in the context of self-supervised learning is a powerful idea that addresses the limitations of traditional methods that enforce fixed invariances or equivariances. Instead of predefining symmetries, adaptive symmetry allows the model to dynamically adjust its sensitivity to different transformations based on the task or context at hand. This adaptability is crucial because different downstream tasks may require different invariances or equivariances, and a fixed set of symmetries can lead to brittle representations. A key aspect of adaptive symmetry is the incorporation of contextual information—perhaps a memory module that tracks task-specific states, actions, and future states, or learned feature representations—which allows the model to learn the relevant symmetries. This approach enables the model to learn general representations that are adaptable to various downstream tasks, eliminating the need for task-specific retraining. The successful implementation of adaptive symmetry would represent a significant advancement in self-supervised learning, potentially paving the way for more robust, general-purpose vision models capable of performing well across a wider range of tasks.
Empirical Gains#
An ‘Empirical Gains’ section in a research paper would detail the quantifiable improvements achieved by the proposed method. It would likely present benchmark results showing performance surpassing existing state-of-the-art techniques on relevant tasks. The gains would be demonstrated through metrics such as accuracy, precision, recall, F1-score, or others specific to the problem domain. Statistical significance testing would be crucial to ensure that the observed improvements are not due to random chance. A thorough analysis would consider various factors, like dataset size and model parameters, explaining any potential impact on the observed gains. The section might also feature qualitative evaluations to provide a more holistic understanding of the performance differences, supplementing the quantitative data with visualizations or case studies. Detailed ablation studies could further demonstrate the contribution of specific components of the proposed method. Overall, a robust ‘Empirical Gains’ section would offer compelling evidence for the practical value of the new approach.
Future Work#
The paper’s core contribution is CONTEXTSSL, a self-supervised learning method adapting to task-specific symmetries via context. Future work could explore several promising directions. Firstly, scaling CONTEXTSSL to larger datasets and more complex tasks is crucial. Secondly, investigating the theoretical properties of CONTEXTSSL, proving its convergence and analyzing its generalization capabilities would be valuable. Thirdly, the approach currently uses a fixed-size context. Dynamic context length or methods for context selection could improve efficiency and robustness. Finally, exploring applications beyond image data, such as video or 3D point clouds, would demonstrate the wider applicability of the contextual world model. Combining CONTEXTSSL with other SSL techniques could lead to further improvements and new research avenues.
More visual insights#
More on figures

This figure illustrates three different families of self-supervised learning approaches. (a) shows the Joint Embedding methods that align representations of augmented views of the same image to learn invariances to transformations. (b) depicts the Image World Models that train a world model in the latent space to encode equivariance to transformations by considering data transformations as actions and the input and its transformed counterpart as world states. (c) presents the Contextual World Models, which selectively enforces equivariance or invariance to transformations based on a context, which is an abstract representation of a task.
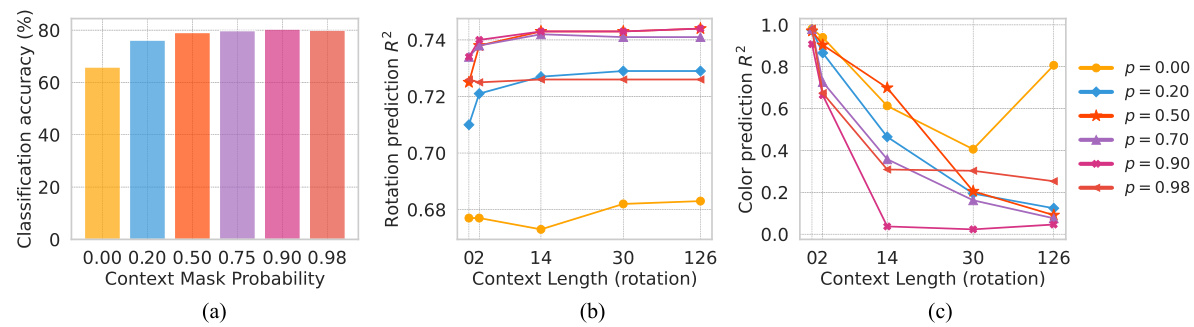
This figure shows the ablation study on the effect of context masking probability on the performance of CONTEXTSSL. The left panel shows classification accuracy, while the middle and right panels depict rotation and color prediction R-squared values, respectively, for different context lengths. The results suggest that a masking probability of around 90% yields optimal performance, preventing the model from exploiting shortcuts and improving generalization.

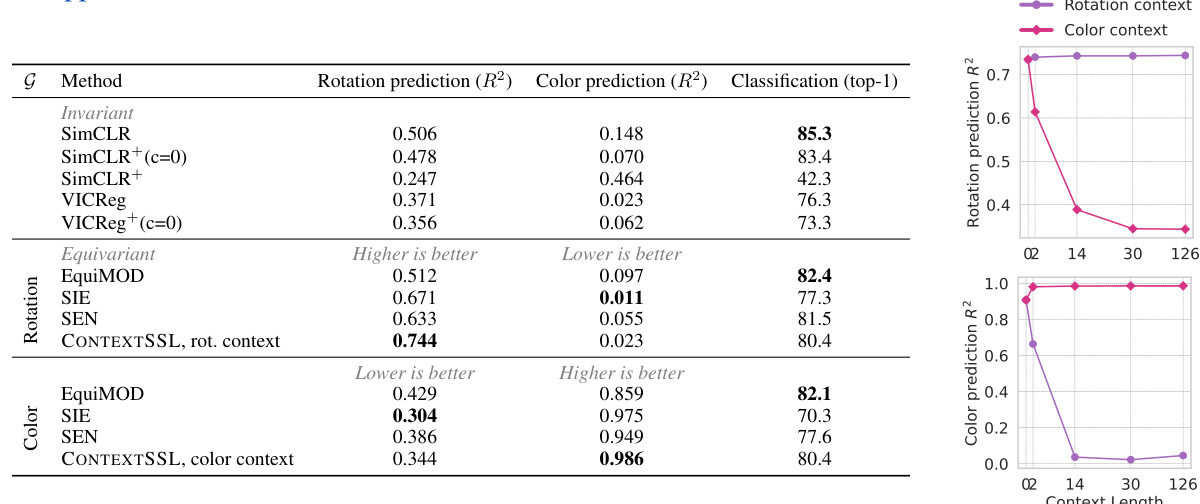
The left panel shows a quantitative comparison of invariant and equivariant methods on classification and prediction tasks (rotation and color). CONTEXTSSL outperforms other methods, particularly in terms of equivariance. The right panel shows how CONTEXTSSL’s performance changes with varying context lengths, demonstrating an adaptive behavior. For example, when the context contains rotation information, CONTEXTSSL becomes increasingly equivariant to rotations and more invariant to colors, demonstrating successful task-specific symmetry learning.
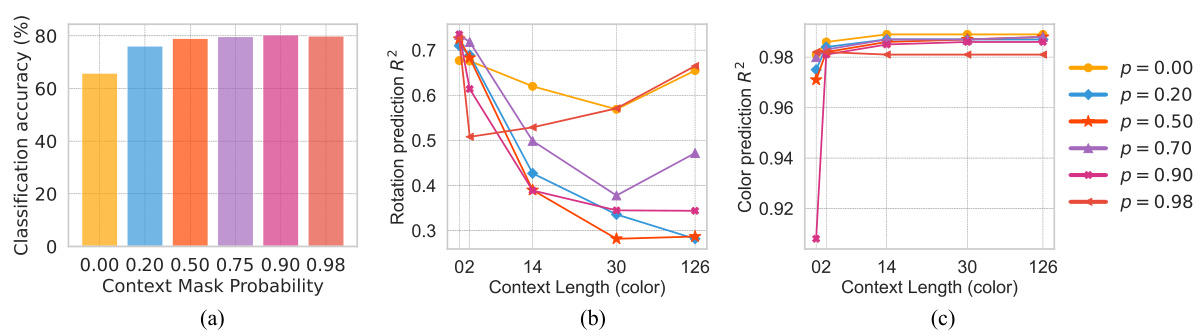
This figure shows the ablation study with varying masking probabilities on the CONTEXTSSL model. The leftmost panel shows the effect of the context mask probability on classification accuracy, rotation prediction R^2, and color prediction R^2. The middle and rightmost panels show the effect of the context length on rotation prediction R^2 and color prediction R^2 for different masking probabilities. It demonstrates how the masking probability affects the ability of CONTEXTSSL to avoid context-based shortcuts. Optimal performance is achieved at around 90% masking probability, balancing the need for contextual information and preventing trivial solutions based on the context.

This figure compares the nearest neighbors retrieved by different self-supervised learning methods (SimCLR, VICReg, SEN, SIE, EquiMOD, and CONTEXTSSL) when given a source image and a rotation angle as input. The goal is to see how well each method learns to represent the rotational aspect of an image. The figure shows that CONTEXTSSL, the proposed method, is best at aligning the retrieved nearest neighbors with the target image’s actual rotation, demonstrating its superior ability to learn and utilize rotational information.

This figure shows the results of applying Contextual Self-Supervised Learning (CONTEXTSSL) to learn equivariance and invariance to different transformations. The top row shows the results for rotation transformations, where CONTEXTSSL learns to be equivariant to rotation (the angle of the nearest neighbor matches the target) and invariant to color (the color does not match the target). The bottom row shows the results for color transformations, where CONTEXTSSL learns to be equivariant to color and invariant to rotation. This demonstrates that CONTEXTSSL can adapt to different transformation based on the provided context.

This figure demonstrates the adaptive nature of CONTEXTSSL in learning task-specific symmetries. It shows how the model responds to different transformations (rotation and color change) applied to source images, depending on the provided context. The top row shows the model learning equivariance to rotation while remaining invariant to color changes. The bottom row illustrates the model adapting to the color context and thus showing the reverse behavior—equivariance to color and invariance to rotation. This illustrates how CONTEXTSSL dynamically adapts its symmetry behavior based on context, unlike traditional methods which enforce fixed invariances or equivariances.

This figure demonstrates the adaptive nature of CONTEXTSSL in learning task-specific symmetries. The top row shows that with a rotation context, the model learns to be equivariant to rotations (nearest neighbor matches the angle of the target) but invariant to color (nearest neighbor has a different color). The bottom row, however, shows that when provided with a color context, the model instead becomes equivariant to color and invariant to rotation. This showcases the model’s ability to adapt its symmetries based on the provided context.
More on tables

This table presents a quantitative evaluation of the learned representations using three different metrics: classification accuracy for invariant tasks, and R-squared values for rotation and color prediction in equivariant tasks. It compares the performance of CONTEXTSSL against other baselines (SimCLR, VICReg, EquiMOD, SIE, SEN) under different context lengths (0, 2, 14, 30, 126) and corresponding context types (rotation or color). The results demonstrate CONTEXTSSL’s ability to adapt to specific symmetries by showing significant performance gains over existing methods on both invariant and equivariant tasks. For instance, as the context length increases, CONTEXTSSL demonstrates higher equivariance for the specified transformation while maintaining more invariance to the other.

This table presents a quantitative evaluation of CONTEXTSSL’s performance on CIFAR-10, comparing its results against SimCLR and its variations. The results are categorized into invariant (classification accuracy) and equivariant (crop and blur prediction R-squared values) tasks. The experiment is conducted under two scenarios: one where CONTEXTSSL adapts to symmetries specific to crop transformations, and another where it adapts to those specific to blur transformations. This table demonstrates CONTEXTSSL’s ability to learn context-specific symmetries and achieve competitive results across both invariant and equivariant tasks.

This table presents the performance of the CONTEXTSSL model on MIMIC-III dataset for Length of Stay (LOS) prediction (invariant task) and treatment prediction (equivariant task), considering the context length of 0 and 126, and whether the model is trained to be equivariant or invariant to gender. The metrics used are Gender prediction accuracy, LOS prediction accuracy, Equalized odds, Equality of opportunity, and Treatment prediction accuracy. The results show how CONTEXTSSL adapts its performance based on the context and the desired task symmetry (invariance or equivariance to gender).
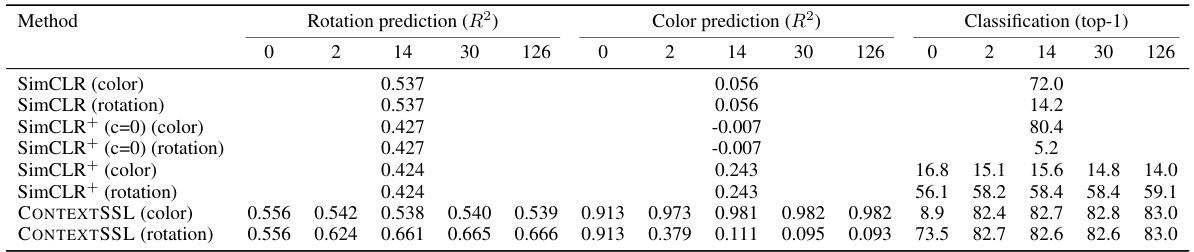
This table presents the quantitative results of CONTEXTSSL and several baseline methods on 3DIEBench dataset when the labels are context-dependent, meaning the labels are influenced by the context (i.e., rotation or color transformations). The table shows the performance (R^2) of rotation and color prediction tasks and the top-1 classification accuracy for different context lengths (0, 2, 14, 30, 126). The results demonstrate CONTEXTSSL’s ability to adapt its symmetry (equivariance or invariance) to the specific context, showcasing superior performance over baseline methods.
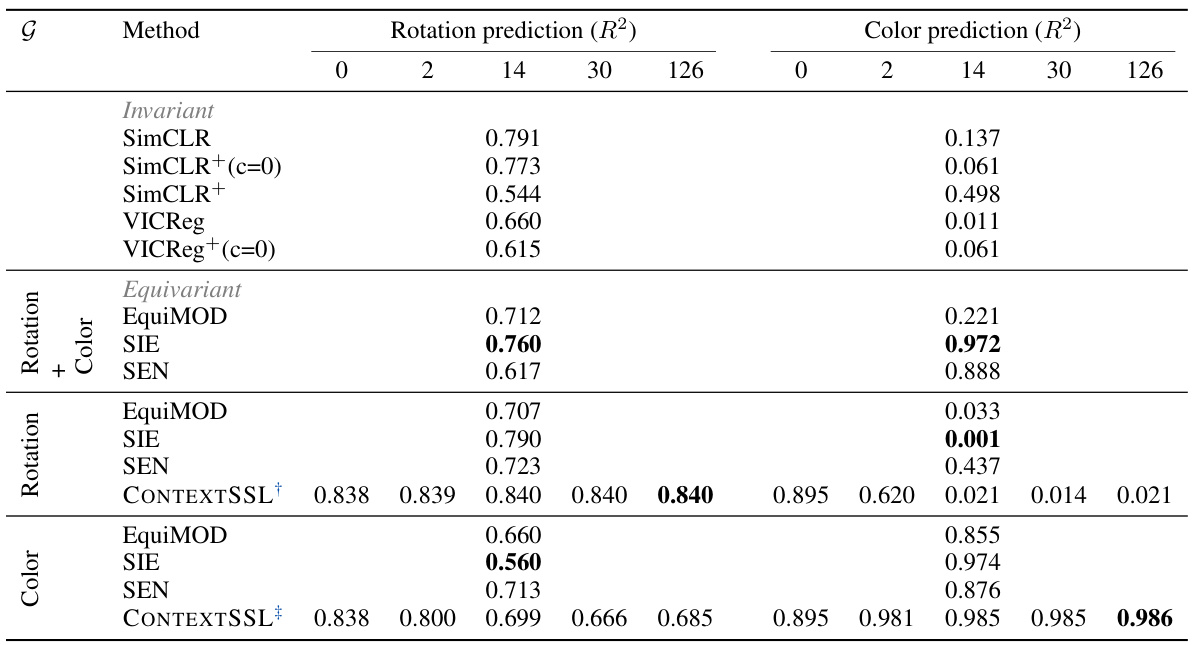
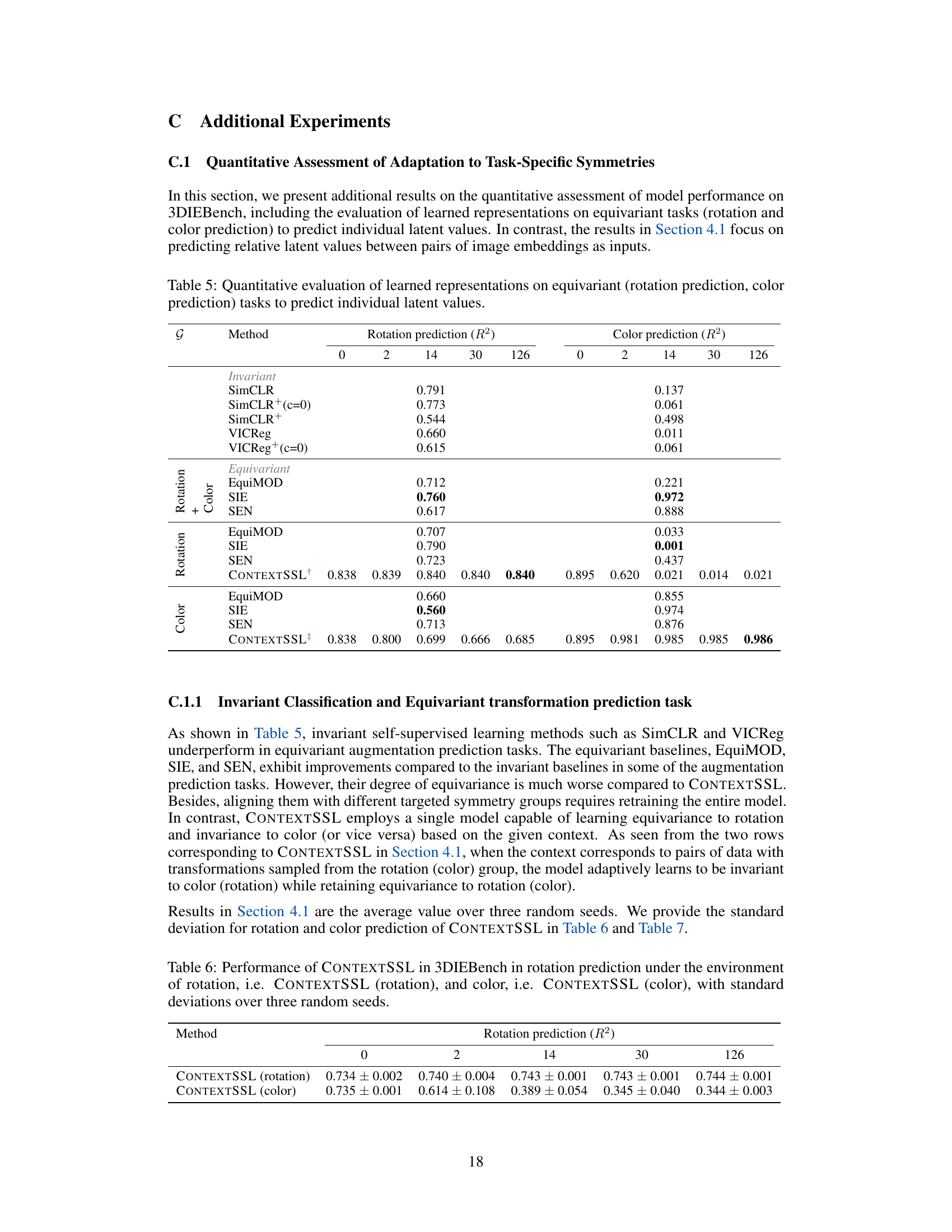
This table presents a quantitative evaluation of learned representations on equivariant tasks (rotation and color prediction). Unlike Table 3 and Table 4 which predict relative latent values between pairs of image embeddings, this table focuses on predicting individual latent values for more precise analysis of the model’s performance in rotation and color prediction tasks. It compares several methods, including invariant and equivariant approaches, across different context lengths, showing how the performance changes with varying context.

This table shows the performance of CONTEXTSSL on rotation prediction in the 3DIEBench benchmark. The model is evaluated under two different conditions: when the context is focused on rotation, and when the context is focused on color. The results are given for different context lengths (0, 2, 14, 30, 126). Standard deviations are included to show variability across three random seed runs.

This table presents the results of color prediction (R^2) using CONTEXTSSL under two different conditions: one where the model is trained to be equivariant to rotation and another where it’s trained to be equivariant to color. The results are shown for different context lengths (0, 2, 14, 30, and 126). Standard deviations are included to represent the variability across three independent runs. It shows the model’s ability to adapt its equivariance/invariance properties to color or rotation depending on the context.

This table presents a quantitative evaluation of the learned representations by comparing CONTEXTSSL with other invariant and equivariant self-supervised learning approaches. The evaluation is performed on both invariant (classification) and equivariant (rotation and color prediction) tasks. The results show CONTEXTSSL’s ability to adapt to task-specific symmetries by paying attention to context, achieving significant performance gains over existing methods. The table also includes results showing the effect of varying context lengths on CONTEXTSSL’s performance.
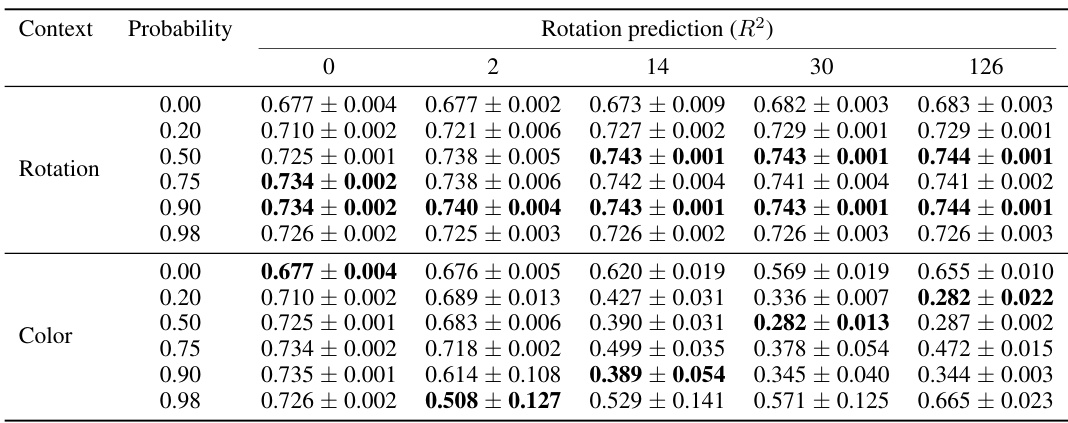
This table presents a quantitative evaluation of the CONTEXTSSL model’s performance on rotation prediction tasks within the 3DIEBench benchmark. It shows how the model’s performance (R²) varies with different context lengths (0, 2, 14, 30, 126) under various random masking probabilities (0.00, 0.20, 0.50, 0.75, 0.90, 0.98). The results are averaged over three random seeds, and standard deviations are included to show the variability of the results. The table is separated into two sections: ‘Rotation’ context and ‘Color’ context, indicating the type of context used during the experiment.

This table presents the results of rotation prediction tasks using the CONTEXTSSL model on the 3DIEBench dataset. The experiments were conducted under various random masking probabilities (0.00, 0.20, 0.50, 0.75, 0.90, 0.98). The table shows the performance (R²) of the model for different context lengths (0, 2, 14, 30, 126) for both rotation and color contexts. Standard deviations across three random seeds are included to show variability in the results.

This table presents a quantitative evaluation of learned representations focusing on equivariant tasks (rotation and color prediction). Unlike Table 3, which predicts relative latent values between image pairs, this table assesses the performance on predicting individual latent values. It compares several methods (SimCLR, VICReg, EquiMOD, SIE, SEN, and CONTEXTSSL) across different context lengths (0, 2, 14, 30, 126) for both rotation and color prediction tasks. The R² metric is used to evaluate the performance of each method in predicting the latent values for rotation and color, highlighting the impact of the context length on the model’s ability to learn equivariant representations.

This table presents the quantitative results of CONTEXTSSL and several baselines on CIFAR-10 dataset, where color and blur are used as transformations. It compares the performance on invariant classification and equivariant color/blur prediction tasks under two different contexts: one where the model is trained to be equivariant to color and invariant to blur, and another where it is trained to be equivariant to blur and invariant to color. The performance metrics include R-squared (R2) for equivariant tasks and top-1 classification accuracy for the invariant task. The results show how CONTEXTSSL adaptively learns to be equivariant/invariant to specific transformations based on context.

This table presents a quantitative evaluation of the CONTEXTSSL model’s performance on CIFAR-10 dataset. It compares CONTEXTSSL’s performance to SimCLR, a baseline invariant self-supervised learning method. The evaluation focuses on classification accuracy and the equivariance of the model’s representations regarding two augmentations: cropping and blurring. The table shows how the model’s performance changes based on the context provided (crop or blur) and context length. The results highlight CONTEXTSSL’s ability to adapt its symmetry (invariance or equivariance) based on the contextual information provided.

This table shows the performance of the CONTEXTSSL model and several baseline models on CIFAR-10 image classification and equivariant prediction tasks (crop and blur). The results are broken down by whether the model is trained with a context focused on crop or blur, demonstrating the model’s ability to adapt to different task-specific symmetries.

This table presents quantitative results evaluating the performance of CONTEXTSSL and baseline methods on CIFAR-10 dataset for color and blur prediction tasks. The results are broken down by the context length used during training, showing how performance changes as the model receives more contextual information. It specifically focuses on evaluating the model’s ability to learn equivariance or invariance to color or blur transformations, depending on which transformation is emphasized in the training context.

This table presents the performance of the CONTEXTSSL model and several baselines on CIFAR-10 data, focusing on equivariant tasks (crop and color prediction). It shows the R-squared values for crop and color prediction at different context lengths (0, 2, 14, 30, 126), comparing the performance of CONTEXTSSL when the context is specifically geared towards either crop or color transformations. The results illustrate CONTEXTSSL’s adaptability to different contexts in learning both invariance and equivariance.

This table presents the results of CONTEXTSSL on MIMIC-III dataset, evaluating both invariant (LOS prediction) and equivariant (treatment prediction) tasks. It demonstrates the performance of CONTEXTSSL under different context lengths (0 and 126), comparing equivariant and invariant settings. The metrics used include prediction accuracy for LOS and treatment, along with equalized odds and equality of opportunity to assess fairness.

This table presents a quantitative comparison of different self-supervised learning methods on their ability to predict individual latent values for rotation and color transformations. It compares the performance of invariant methods (SimCLR and VICReg) and equivariant methods (EquiMOD, SIE, SEN) with CONTEXTSSL. The results are broken down by context length (0, 2, 14, 30, 126), showing how the performance of each model changes as more contextual information becomes available.
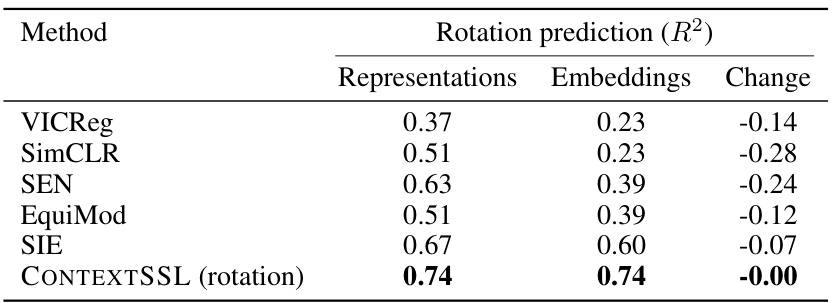
This table compares the performance of several self-supervised learning methods on a rotation prediction task, using either the learned representations directly or the embeddings from a projection head or predictor. The key finding is that CONTEXTSSL shows consistent performance regardless of whether representations or embeddings are used, unlike other methods which show significant performance drops when using embeddings.
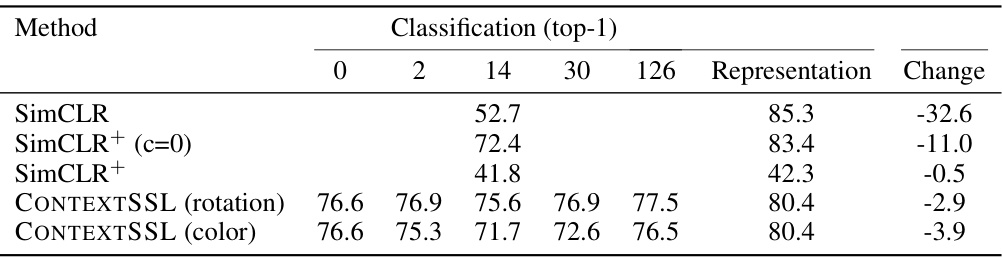
This table shows the performance of the CONTEXTSSL model and several baseline models on CIFAR-10 image data. The experiment uses crop and blur as transformations. The table presents results for three different tasks: classification accuracy (invariant), crop prediction accuracy (equivariant), and blur prediction accuracy (equivariant). Results are shown for CONTEXTSSL under two conditions: when the context focuses on crop transformations and when it focuses on blur transformations. This allows us to examine the model’s ability to adapt its symmetries (invariance/equivariance) based on contextual information. Baseline models are also included for comparison.
This table presents a quantitative evaluation of learned representations using different methods on invariant and equivariant tasks. It compares the performance of CONTEXTSSL against several baselines (SimCLR, VICReg, EquiMOD, SIE, SEN) across varying context lengths (0, 2, 14, 30, and 126). The results show how CONTEXTSSL dynamically adapts to either enforce invariance or equivariance to specific transformations based on the provided context. Invariant tasks refer to image classification, while equivariant tasks measure the model’s ability to predict rotations or color transformations.
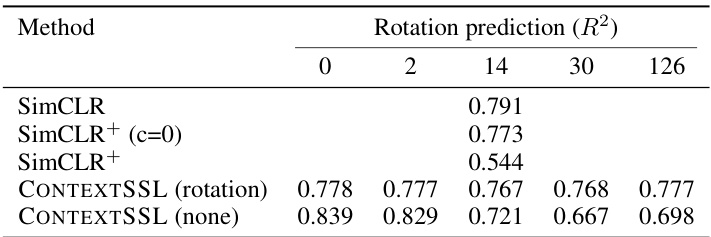
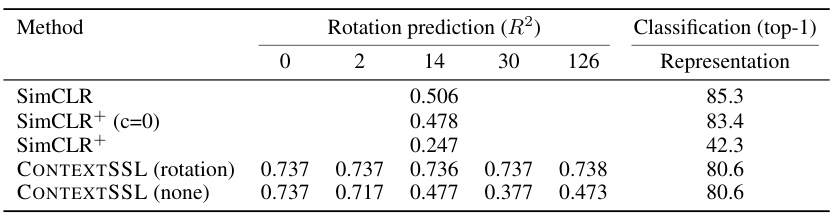
This table presents the results of CONTEXTSSL and baseline methods on the 3DIEBench dataset. It shows the performance on rotation prediction (R^2) and classification (top-1 accuracy) in two scenarios: 1. Equivariant environment: CONTEXTSSL is trained to learn equivariance to rotation transformations. 2. Invariant environment: CONTEXTSSL is trained to learn invariance to rotation transformations. The results are shown for different context lengths (0, 2, 14, 30, and 126), demonstrating how the model’s performance changes based on the level of context provided.
Full paper#