↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large vision-language models (LVLMs) evaluation is currently hindered by two major problems: many samples don’t require visual understanding, and unintentional data leakage occurs during training. This leads to misjudgments about actual multi-modal improvements and misguides research.
To address this, the authors introduce MMStar, a new benchmark with 1500 carefully selected samples. These samples are designed to be purely vision-dependent, minimize data leakage, and challenge the advanced multi-modal capabilities of LVLMs. Furthermore, they propose two new metrics: multi-modal gain and multi-modal leakage, to provide more accurate measurements of LVLMs’ true performance and data leakage during training.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large vision-language models (LVLMs). It addresses critical issues in current evaluation methods, proposing new metrics and a benchmark to ensure fair and accurate assessment of model performance. This will significantly impact future research in this rapidly advancing field, as well as improve the reliability of model development and comparison.
Visual Insights#
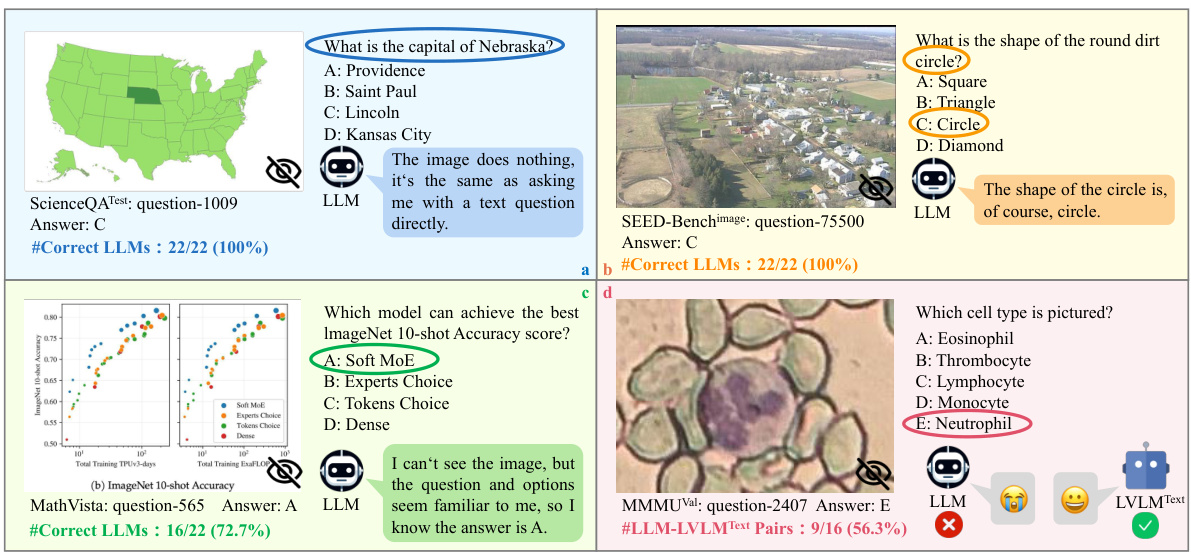
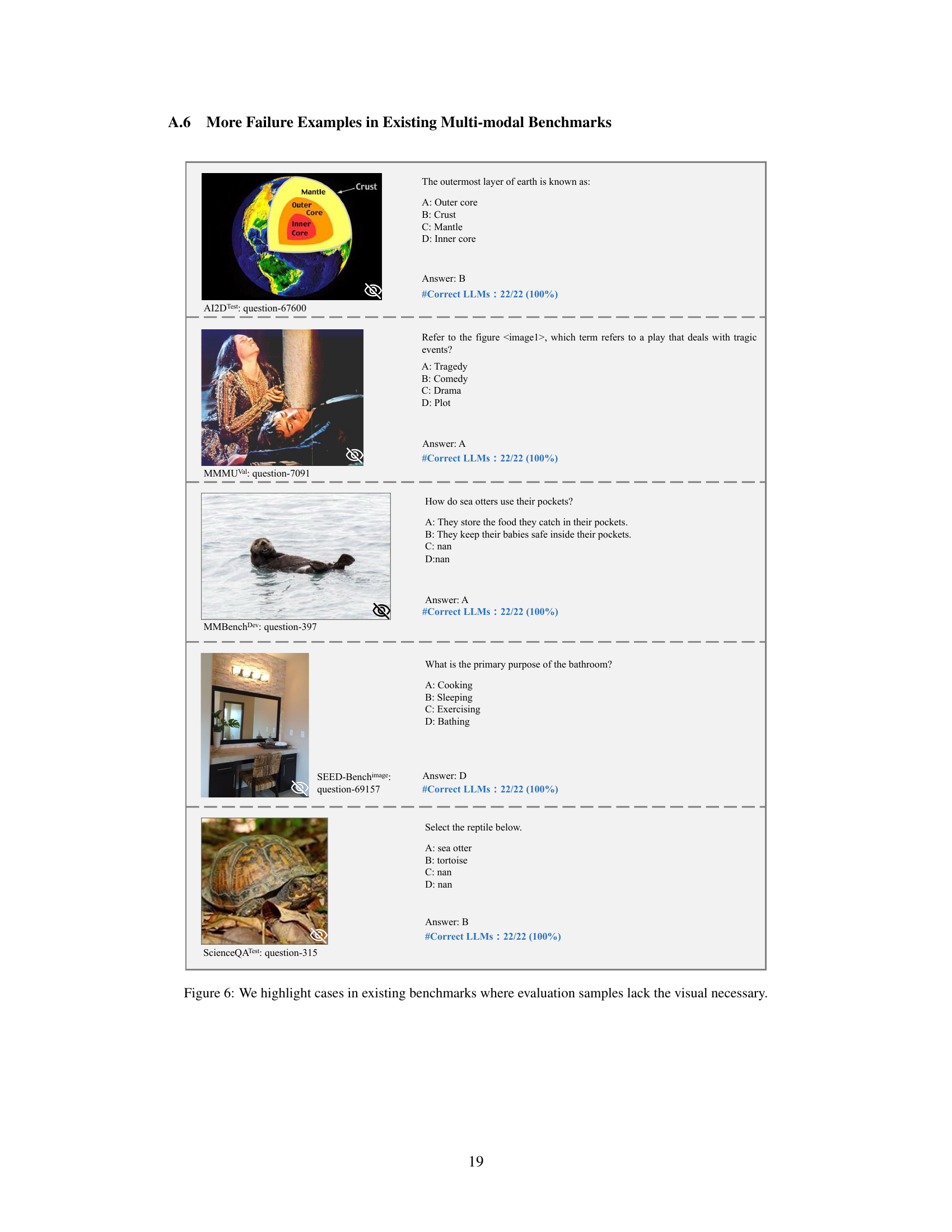
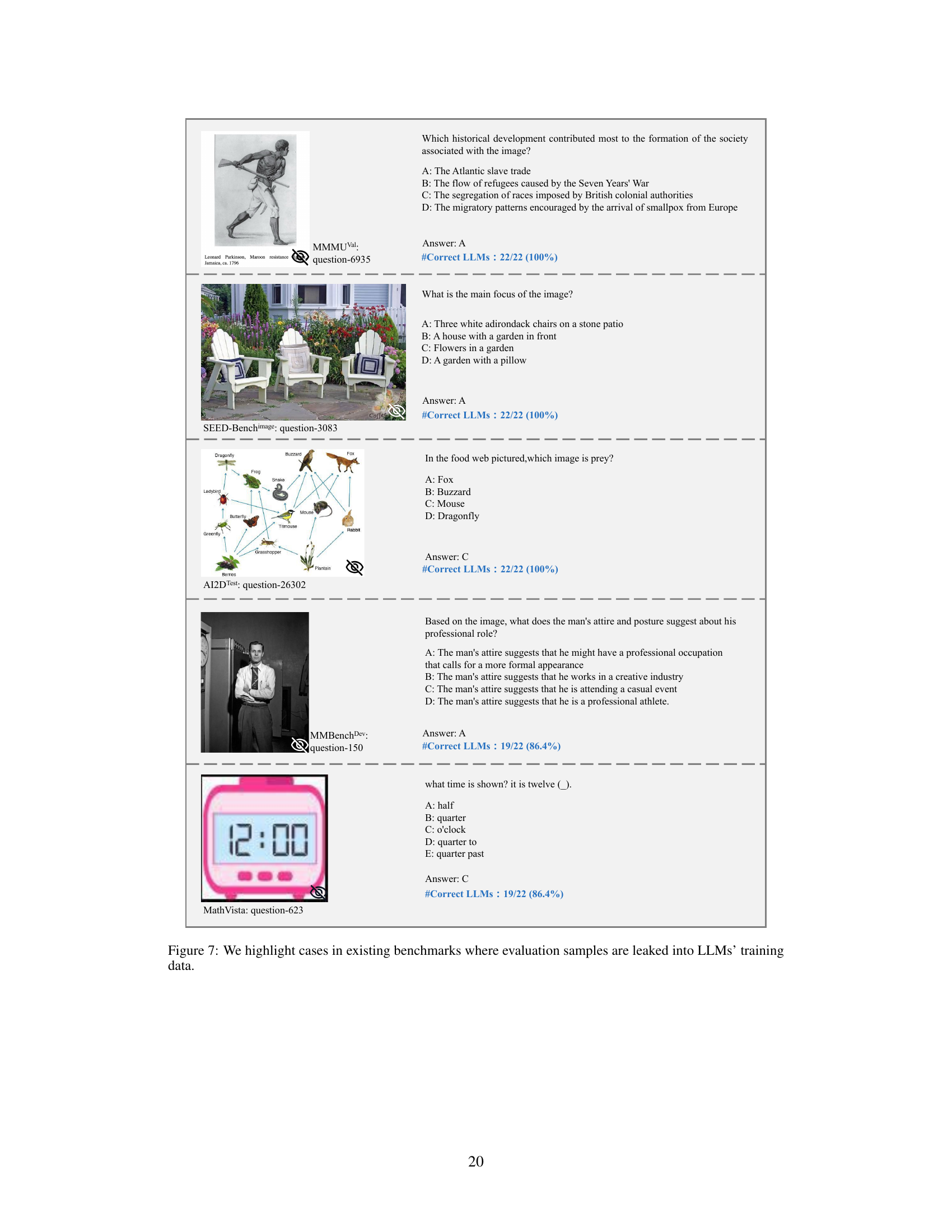
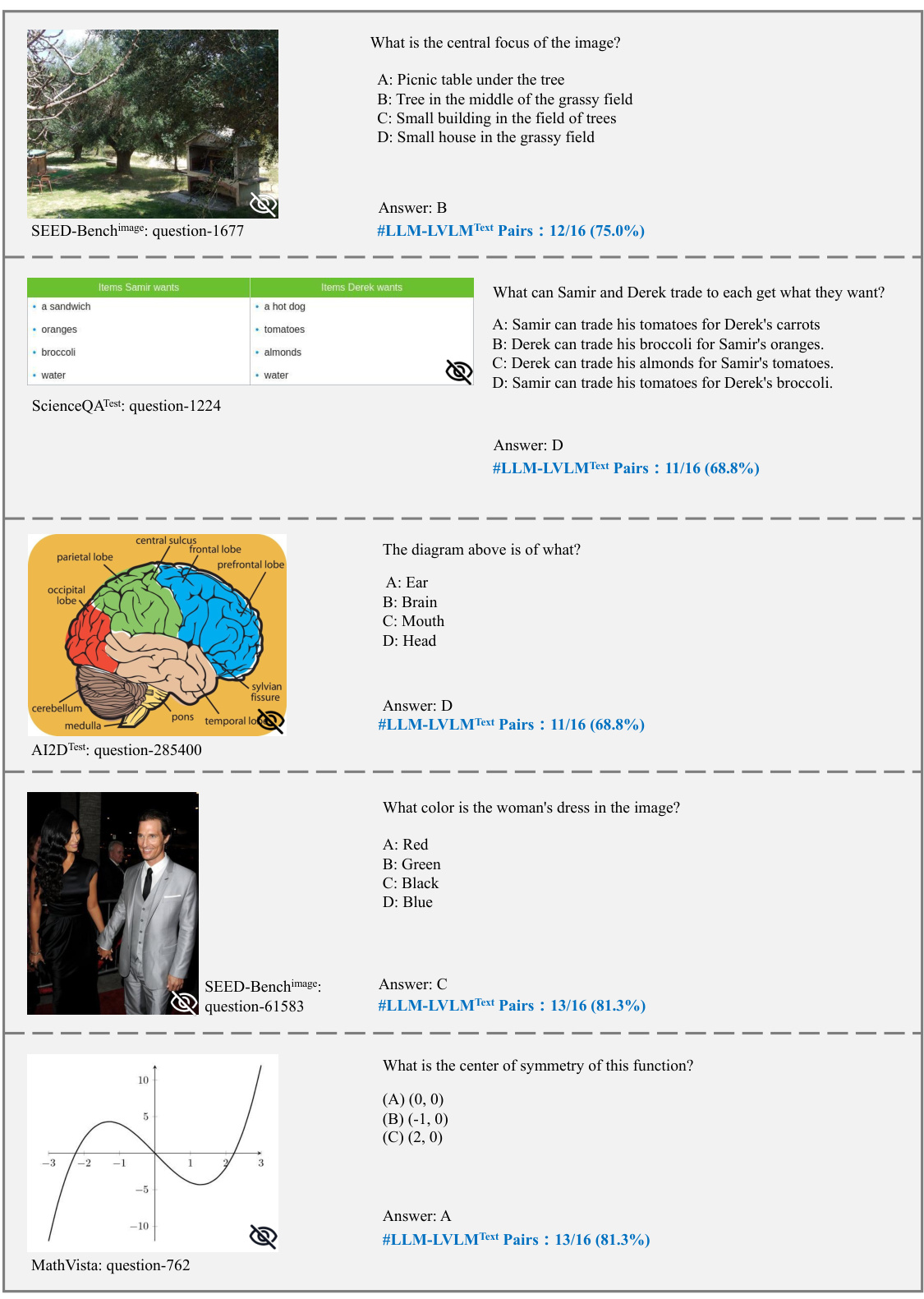
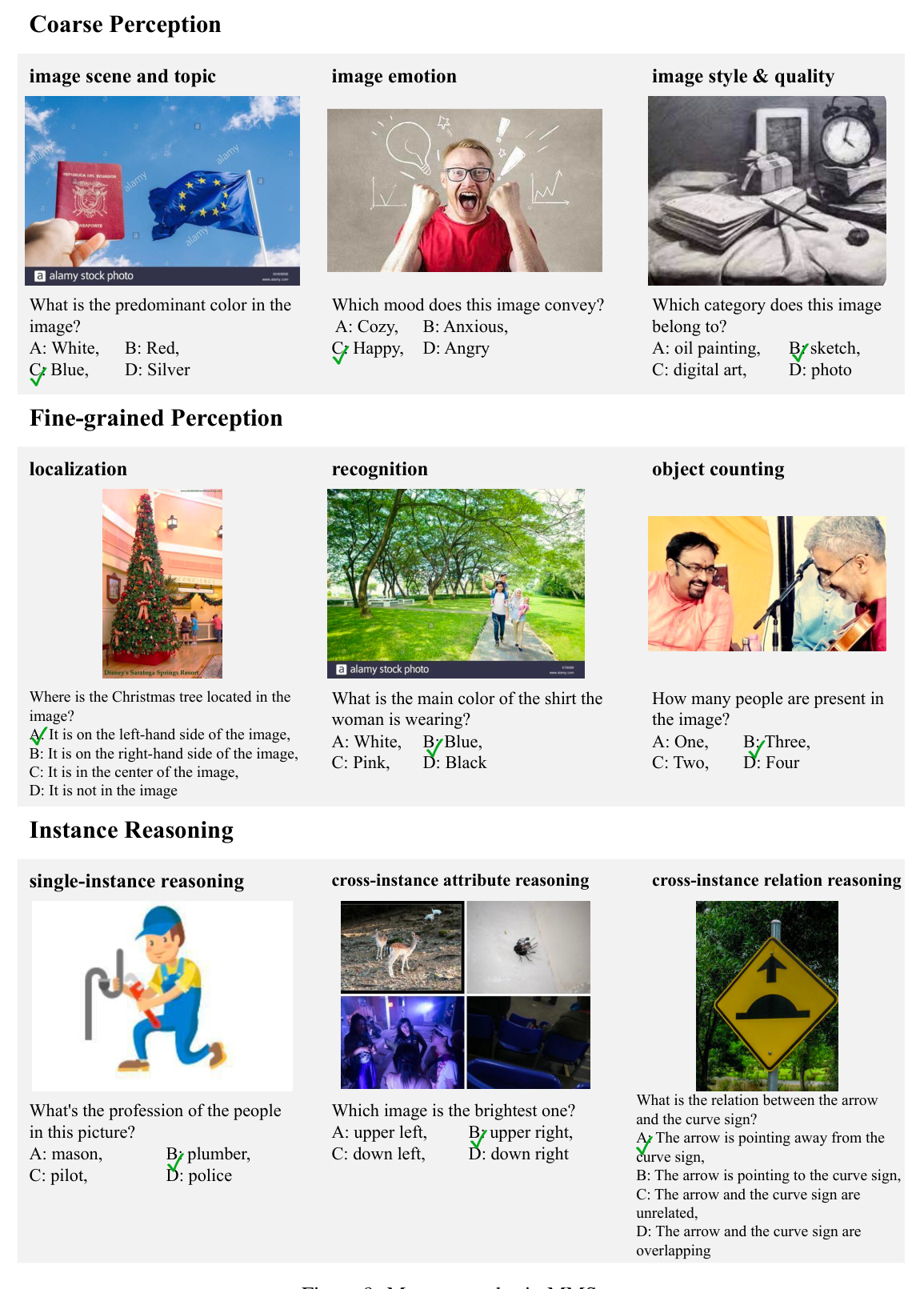
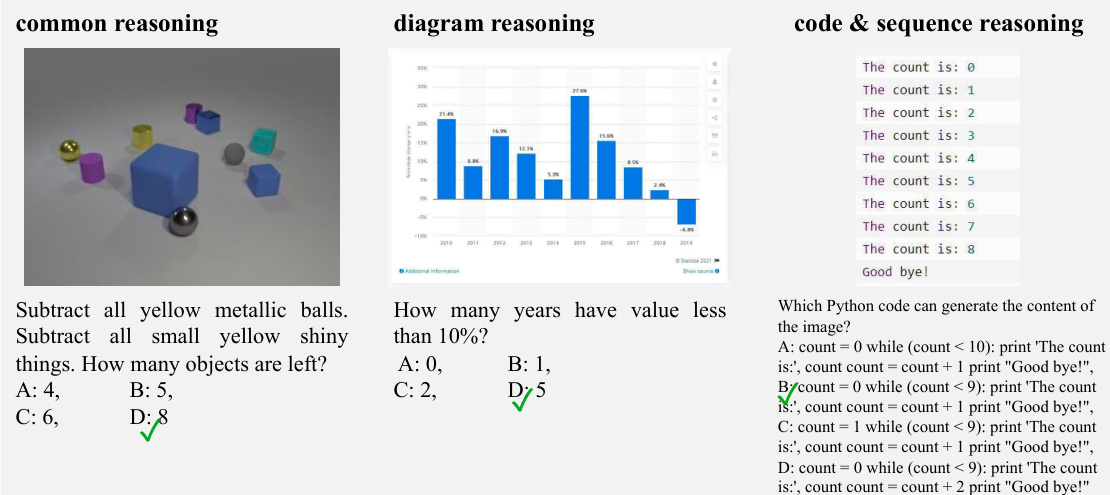
This figure shows four examples highlighting issues in existing multi-modal benchmark datasets. Panel (a) demonstrates cases where LLMs can answer questions using only their existing knowledge without any need for visual input. Panel (b) shows examples where the question itself contains the answer, rendering the image irrelevant. Panel (c) illustrates unintentional data leakage in LLM training datasets. Panel (d) shows how LVLMs can answer questions without visual input, suggesting data leakage in their training.
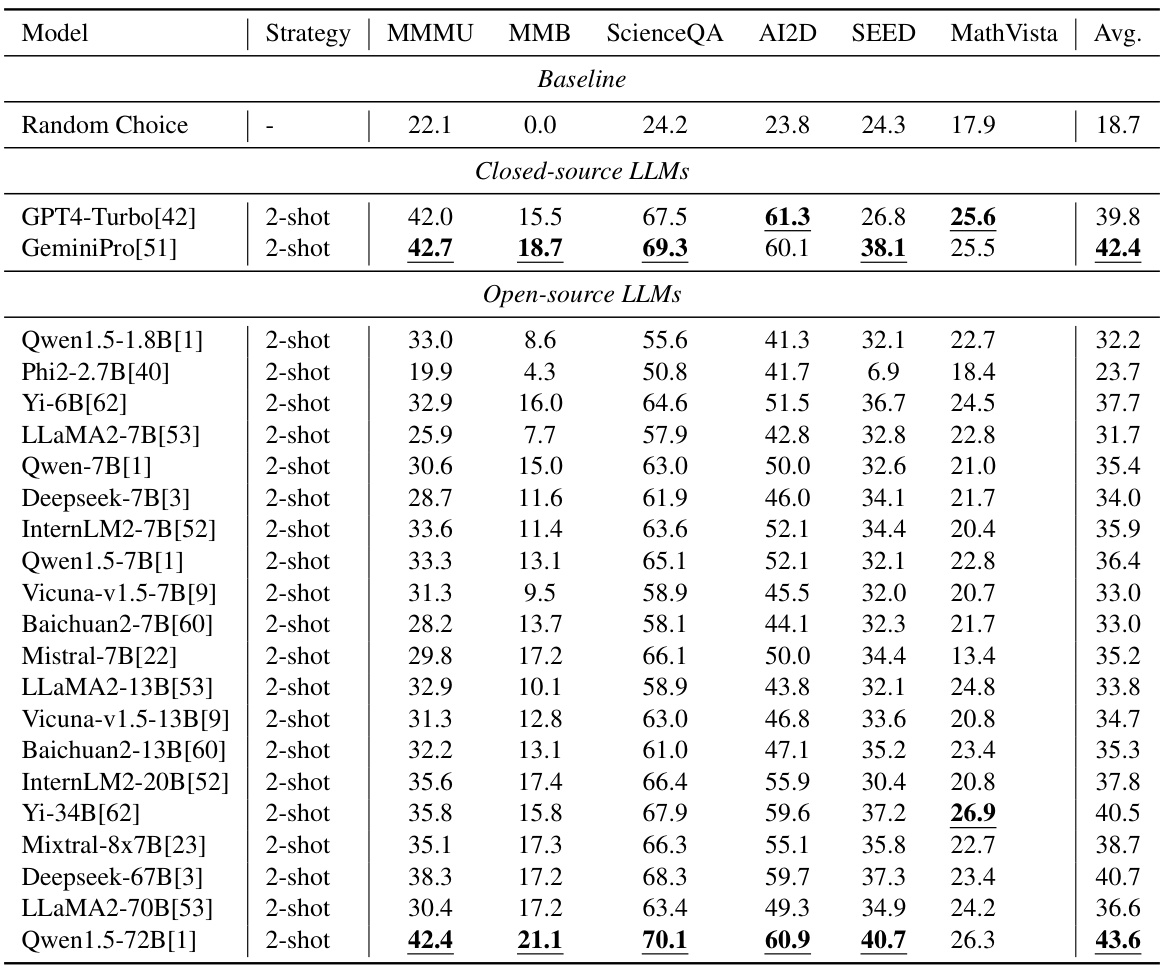
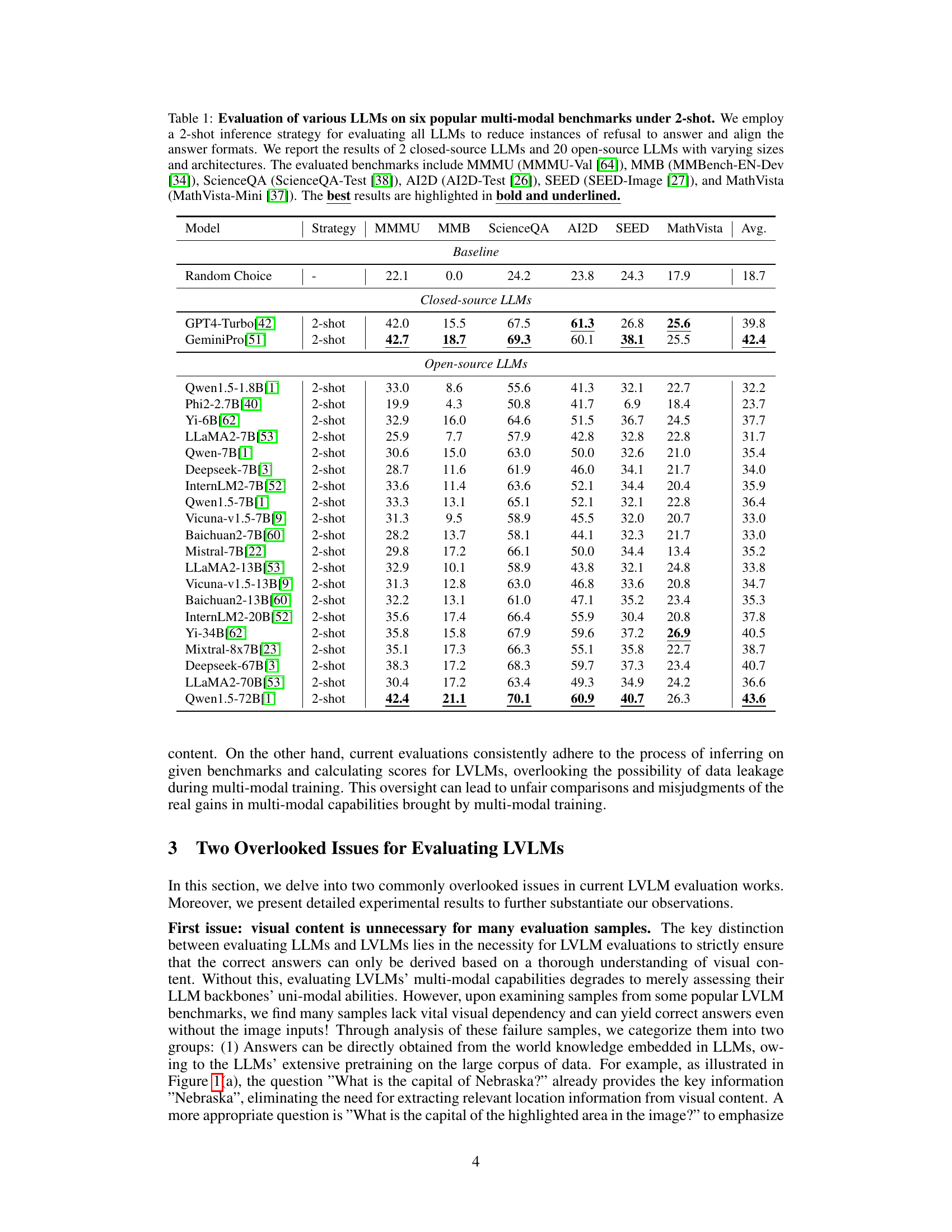
This table presents the performance of 22 large language models (LLMs) on six popular multi-modal benchmarks using a 2-shot inference strategy. It compares the performance of both closed-source and open-source LLMs across different benchmarks, highlighting the best results for each benchmark. The table aims to illustrate the varying capabilities of different LLMs in answering questions that may or may not require visual input, setting the stage for the subsequent analysis of multi-modal models.
In-depth insights#
LVLM Evaluation Issues#
Current Large Vision-Language Model (LVLM) evaluation methods suffer from two key issues. First, many benchmark datasets include questions whose answers do not require visual input, relying instead on general world knowledge readily available to strong Language Models (LMs). This inflates reported LVLM performance and obscures the true contribution of the visual modality. Second, there’s significant evidence of unintentional data leakage in both LM and LVLM training datasets, leading to LMs and LVLMs successfully answering visually-dependent questions without access to the image. This data leakage misrepresents true multi-modal capabilities and undermines the reliability of the benchmarks. Addressing these issues demands the creation of new benchmarks with meticulously curated samples, carefully designed to be truly vision-dependent and free from leakage, along with more sophisticated evaluation metrics that account for these problems. Only then can researchers fairly assess the progress and potential of LVLM research.
MMStar Benchmark#
The MMStar benchmark is presented as a solution to address the shortcomings of existing vision-language model (VLM) evaluation methods. Current benchmarks suffer from two key issues: reliance on samples where visual content is unnecessary for accurate response, and unintentional data leakage during LLM and VLM training. MMStar is meticulously constructed to mitigate these problems. It features 1500 human-selected samples, ensuring each requires genuine multi-modal understanding. The benchmark’s structure, emphasizing 6 core capabilities and 18 detailed axes, provides a more comprehensive and nuanced assessment of VLM capabilities. Two novel metrics, multi-modal gain and multi-modal leakage, are also introduced to measure actual performance improvements and data contamination, offering a more robust and informative evaluation framework. The rigorous curation process and focus on vision-critical samples differentiates MMStar, potentially establishing a new standard for VLM evaluation.
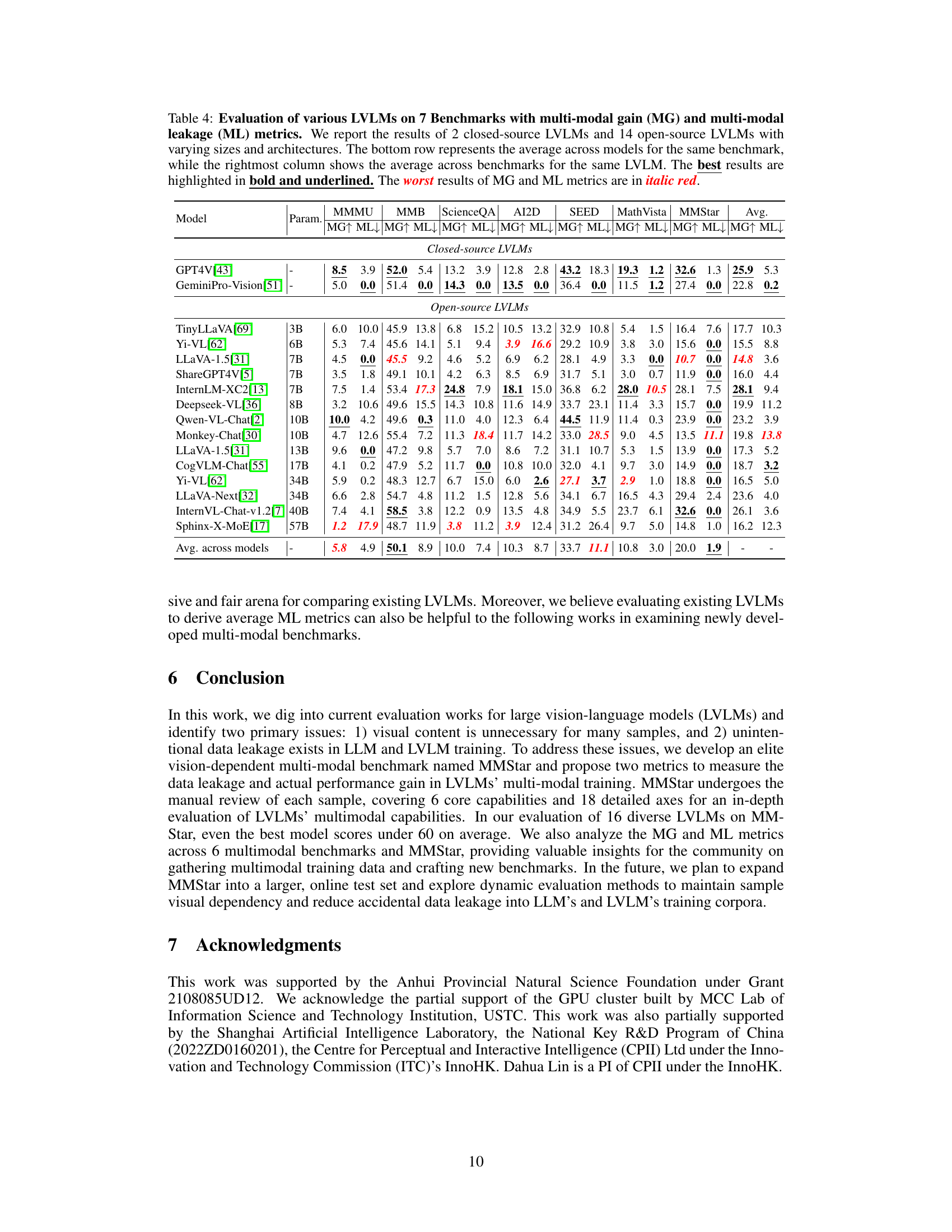
Multimodal Gain/Leakage#
The concept of “Multimodal Gain/Leakage” in evaluating large vision-language models (LVLMs) is crucial. Multimodal gain quantifies the genuine performance improvement achieved by integrating visual information into the model. This is distinct from the performance of the language model alone. Multimodal leakage, on the other hand, highlights the issue of unintended data memorization during training. This leakage manifests when models answer questions correctly even without visual input, indicating they’ve memorized answers from their training data. Accurate evaluation necessitates careful consideration of both aspects. A benchmark that successfully isolates genuinely multimodal capabilities from the effects of data leakage provides more robust and reliable evaluations, preventing misleading conclusions regarding the actual benefits of multimodal training. Therefore, measuring both multimodal gain and leakage is essential for a fair assessment of LVLMs.
MMStar Analysis#
MMStar analysis in this research paper would deeply investigate the performance of various Large Vision-Language Models (LVLMs) on a newly developed benchmark dataset. A key aspect would be assessing the models’ ability to correctly answer questions that require genuine visual understanding, as opposed to relying on textual information or memorized data. The analysis would likely involve comparing the performance of different LVLMs across various dimensions of multi-modal capabilities, potentially revealing strengths and weaknesses of individual models. Crucially, the analysis would incorporate novel metrics designed to measure data leakage and actual multi-modal gain, providing a more accurate evaluation that accounts for unintentional memorization of training data. The results could highlight the state-of-the-art in LVLM performance, identify areas for improvement in model design, and inform the development of better benchmark datasets. Ultimately, this section would serve as a central element to assess the true capacity and reliability of the current generation of LVLMs.
Future Work#
Future research directions stemming from this work could involve expanding the MMStar benchmark to include a broader range of visual tasks and complexities, addressing the limitations highlighted in the current study. Further investigation into mitigating data leakage during the training of LLMs and LVLMs is crucial. This might involve exploring novel training techniques or developing more robust evaluation methodologies. A key area for future exploration would be developing more sophisticated evaluation metrics capable of not only assessing accuracy but also quantifying the nuances of multi-modal understanding such as reasoning and knowledge integration. Finally, it will be valuable to delve into the broader societal implications of increasingly powerful LVLMs, with a focus on mitigating potential biases, ensuring fairness, and addressing ethical concerns.
More visual insights#
More on figures
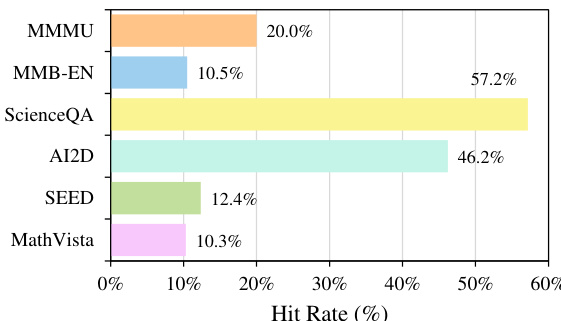
The figure shows the percentage of questions in several popular multi-modal benchmarks that could be answered correctly by most LLMs without using any visual input. It illustrates the prevalence of samples where visual content is unnecessary, highlighting a shortcoming in the design of these benchmarks. The high hit rates (ScienceQA at 57.2%, AI2D at 46.2%) indicate that a significant portion of these benchmarks primarily assess LLMs’ textual capabilities rather than true multi-modal reasoning.
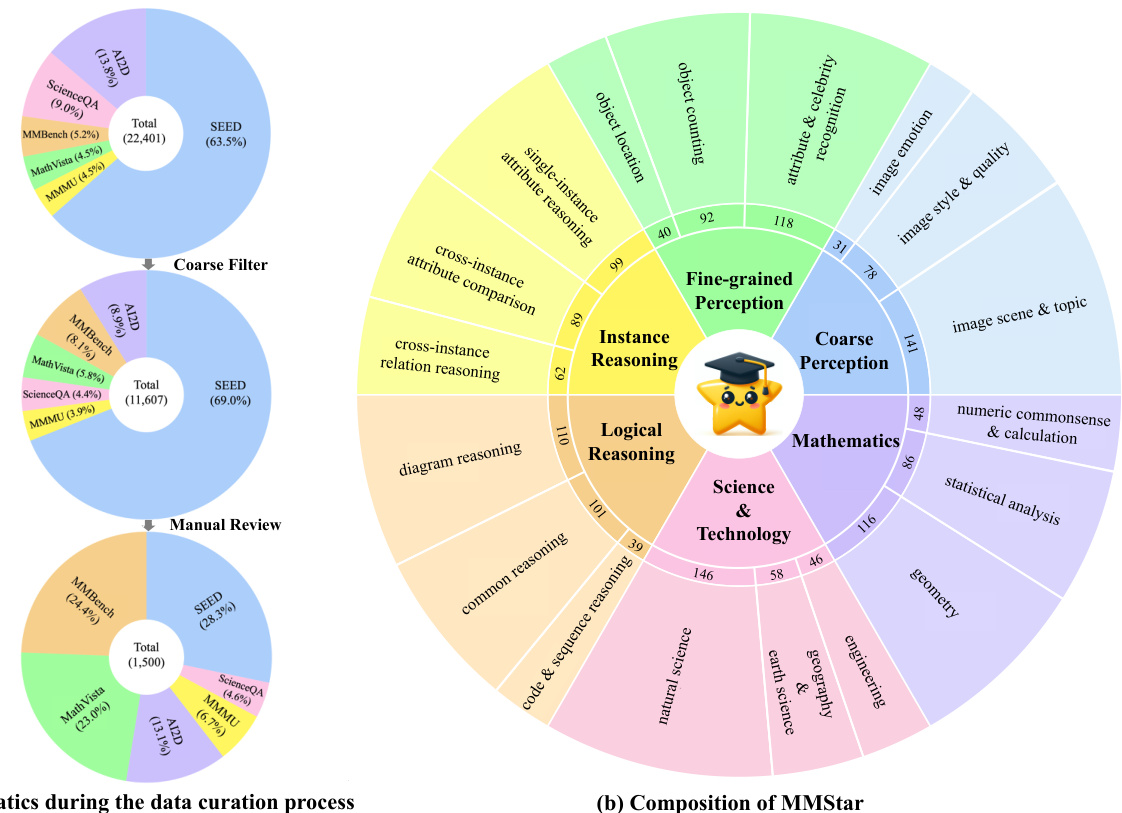
This figure shows the process of curating the MMStar benchmark dataset. The left panel (a) illustrates the data reduction steps from 22,401 initial samples to the final 1,500 samples through a coarse filter and manual review process. The right panel (b) displays the composition of MMStar, showing its six core capabilities (inner ring), eighteen detailed axes (outer ring), and the number of samples per axis (middle ring).
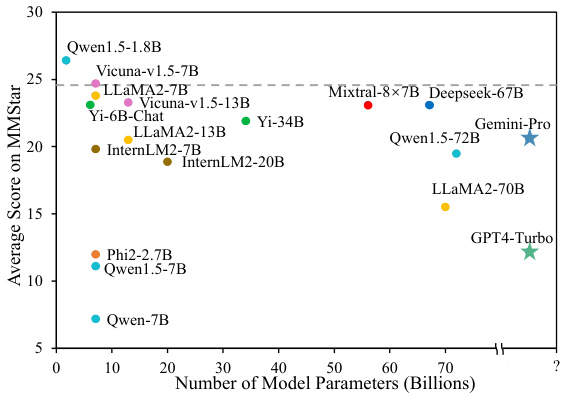
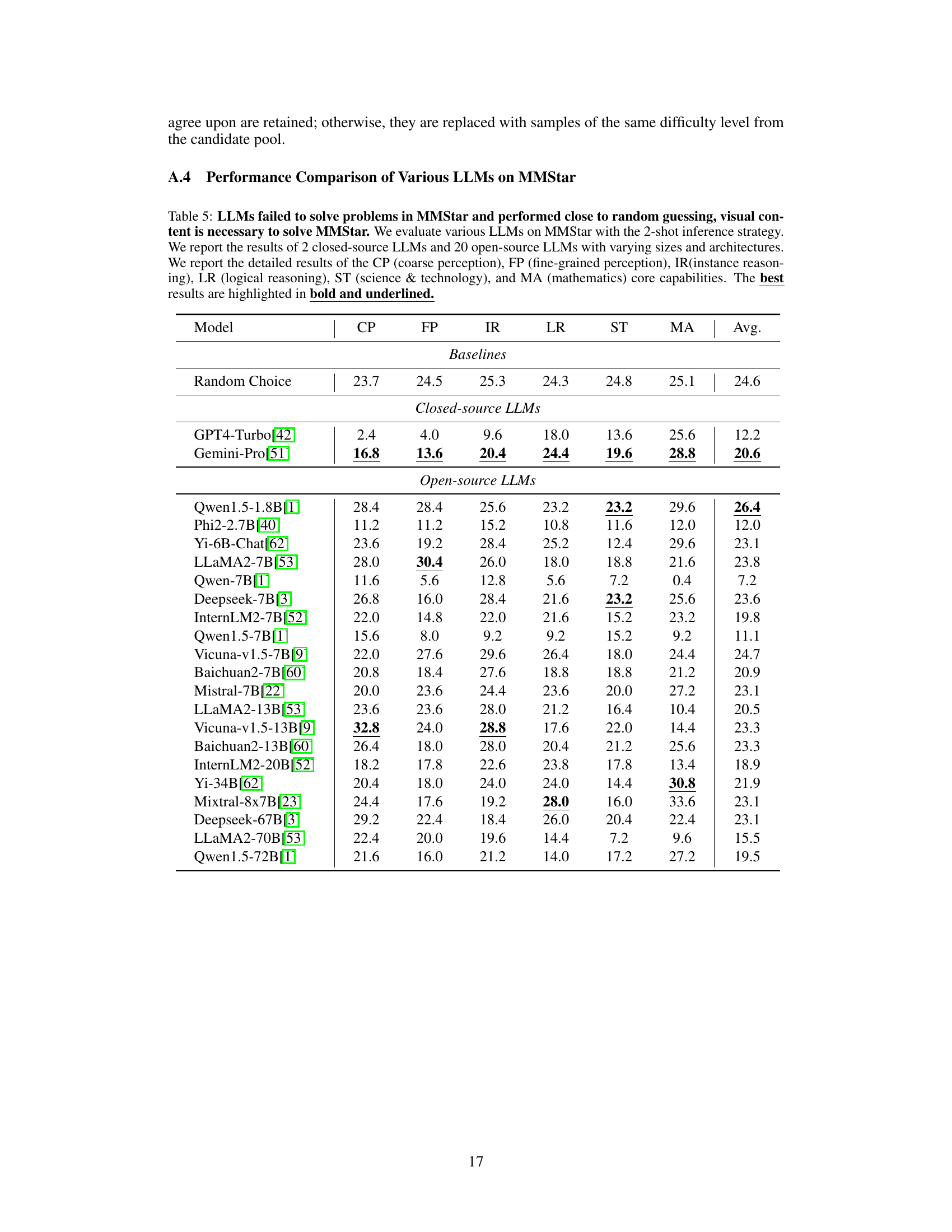
The figure is a scatter plot showing the average performance of various LLMs on the MMStar benchmark against the number of parameters in each model. The plot demonstrates that, despite differences in model size and architecture, most LLMs achieve performance very close to that of a random baseline (indicated by the dashed horizontal line). This suggests that visual content is crucial for solving the MMStar benchmark, as the LLMs are unable to leverage their language understanding capabilities alone to provide accurate answers. The best-performing LLM, Qwen1.5-1.8B, still only achieves a score only slightly above the random baseline.

This figure shows four examples highlighting issues with existing multi-modal benchmarks. Panel (a) demonstrates samples answerable by LLMs using only text. Panel (b) shows cases where the question implies the answer, making the image irrelevant. Panel (c) illustrates samples unintentionally present in LLM training data, allowing LLMs to answer without visual input. Panel (d) shows samples that LVLMs can solve without images, suggesting leakage into LVLM training data.

This figure shows four examples of problems found in existing multi-modal benchmark datasets. The problems highlighted are: 1. Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. 2. Unintentional data leakage exists in LLM and LVLM training. LLMs and LVLMs could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data.

This figure shows four examples from existing multi-modal benchmarks to illustrate the issues of visual content not being necessary and unintentional data leakage in LLM and LVLM training. Each subfigure demonstrates one aspect of these problems. Specifically, it illustrates instances where: (a) LLMs can answer questions using only world knowledge. (b) The question already contains the answer; images are irrelevant. (c) LLMs can answer questions because the questions and answers were in the LLMs’ training data. (d) LVLMs solve questions without visual input, suggesting data leakage in the LVLM training data.
This figure demonstrates cases where LLMs fail to answer correctly, but LVLMs (even without visual input) succeed. This highlights unintentional data leakage from LLMs and LVLMs during training, where models memorize samples from training data instead of using multi-modal reasoning. The central chart shows the percentage of samples in various benchmarks that were correctly answered by more than half of the LLMs tested, illustrating the prevalence of data leakage.
This figure shows examples where LLMs fail to answer questions correctly, but LVLMs (without visual input) succeed. This highlights the problem of data leakage in LVLMs’ training data. The chart summarizes the number of samples across benchmarks where more than half of the tested LLMs and LVLMs could answer correctly without visual input, thus demonstrating how widespread data leakage is within existing multimodal benchmarks.
This figure shows four examples of issues found in existing multi-modal benchmarks. These issues include questions that can be answered without visual information, questions where the answers are already present in the question, and unintended data leakage in LLM and LVLM training data. These issues lead to inaccurate evaluation results and potentially misleading research directions.
This figure shows four examples of issues with current multi-modal benchmarks. The first two examples show questions that LLMs can answer without visual input, because the answers are found in the question or can be derived from world knowledge. The second two examples show questions that LVLMs can answer even without visual input, because these questions were present in the training data for the LLMs and LVLMs. These issues highlight the necessity of improved benchmarks that are free of data leakage and truly require multi-modal reasoning to be answered.
This figure demonstrates unintentional data leakage in existing multi-modal benchmarks by showing examples where LLMs fail to answer questions correctly, but LVLMs (without visual input) succeed, indicating that these samples were memorized during training. The central chart further quantifies this issue by showing the percentage of samples in various benchmarks that LLMs could answer without visual input.
The figure showcases four examples illustrating the two main issues the paper identifies with existing multi-modal benchmark datasets. These problems are: (a) Visual content is unnecessary for many samples (the answer can be inferred from text alone). (b) The question itself contains the answer making visual input redundant. (c) Unintentional data leakage in LLM/LVLM training - LLMs/LVLMs can answer visual-necessary questions without image content, indicating memorization of training data. (d) Data leakage in LVLM training - LVLMs can answer questions that LLMs cannot, suggesting memorization of multi-modal training data.
This figure shows examples of data leakage in existing multi-modal benchmarks. It illustrates how LLMs without visual input are able to answer questions that require visual understanding, demonstrating that some benchmark questions unintentionally appeared in the training data of LLMs and LVLMs. The chart summarizes this phenomenon by showing the percentage of samples correctly answered by more than half of the evaluated LLMs.

This figure shows four examples illustrating issues in existing multimodal benchmarks. (a) shows examples where LLMs can answer questions using only world knowledge, (b) shows examples where questions themselves contain the answers, making the images unnecessary. (c) shows examples of unintentional data leakage in LLM training data, where LLMs can ‘recall’ answers without visual input, and (d) demonstrates data leakage in LVLM training, where LVLMs can answer questions without visual input that LLMs cannot answer.
More on tables
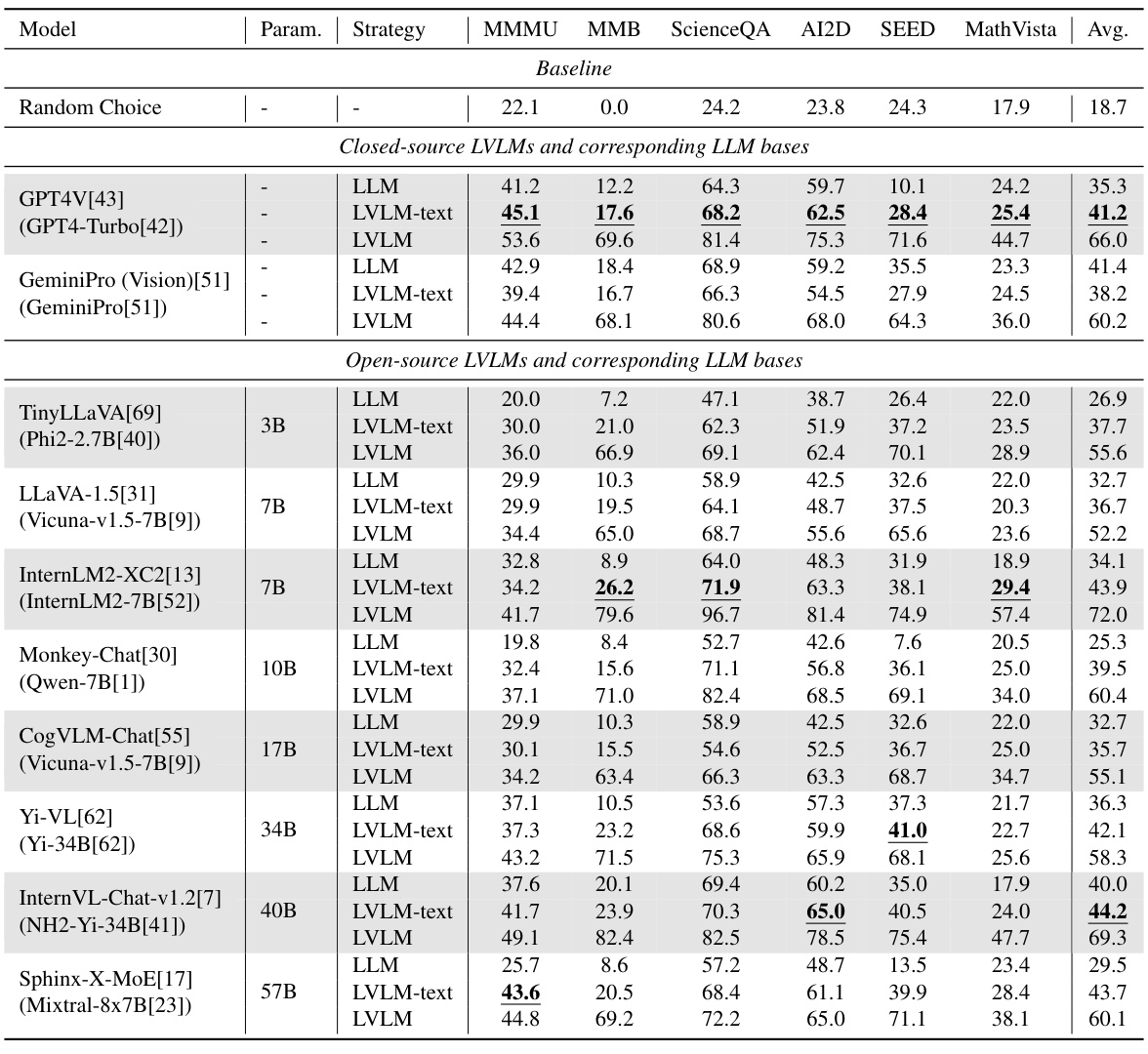
This table presents a comparison of the performance of several Large Vision-Language Models (LVLMs) and their corresponding Large Language Models (LLMs) across six popular multi-modal benchmarks. The ‘strategy’ column indicates whether the model used only text (‘LLM’) or both text and images (‘LVLM’) during the evaluation. Results are shown for multiple metrics across different models to evaluate multi-modal capabilities and data leakage during training. Due to space limitations, only a subset of models are presented in the table.
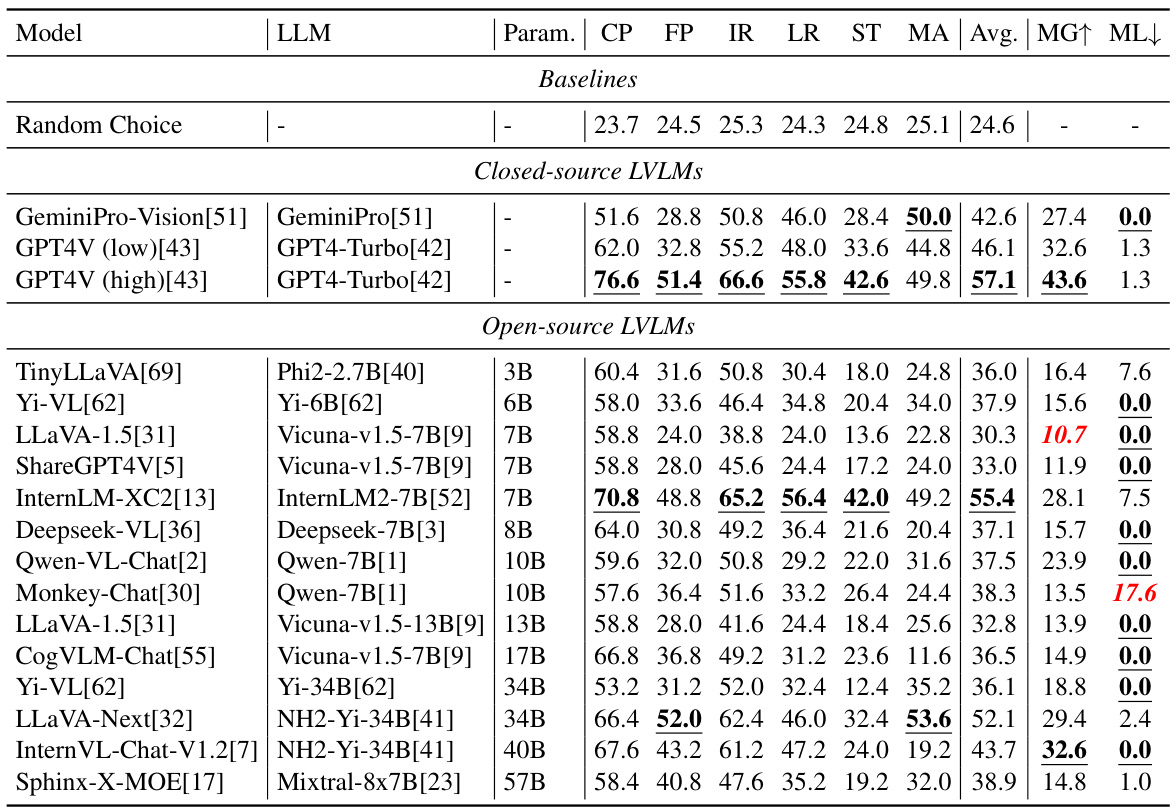
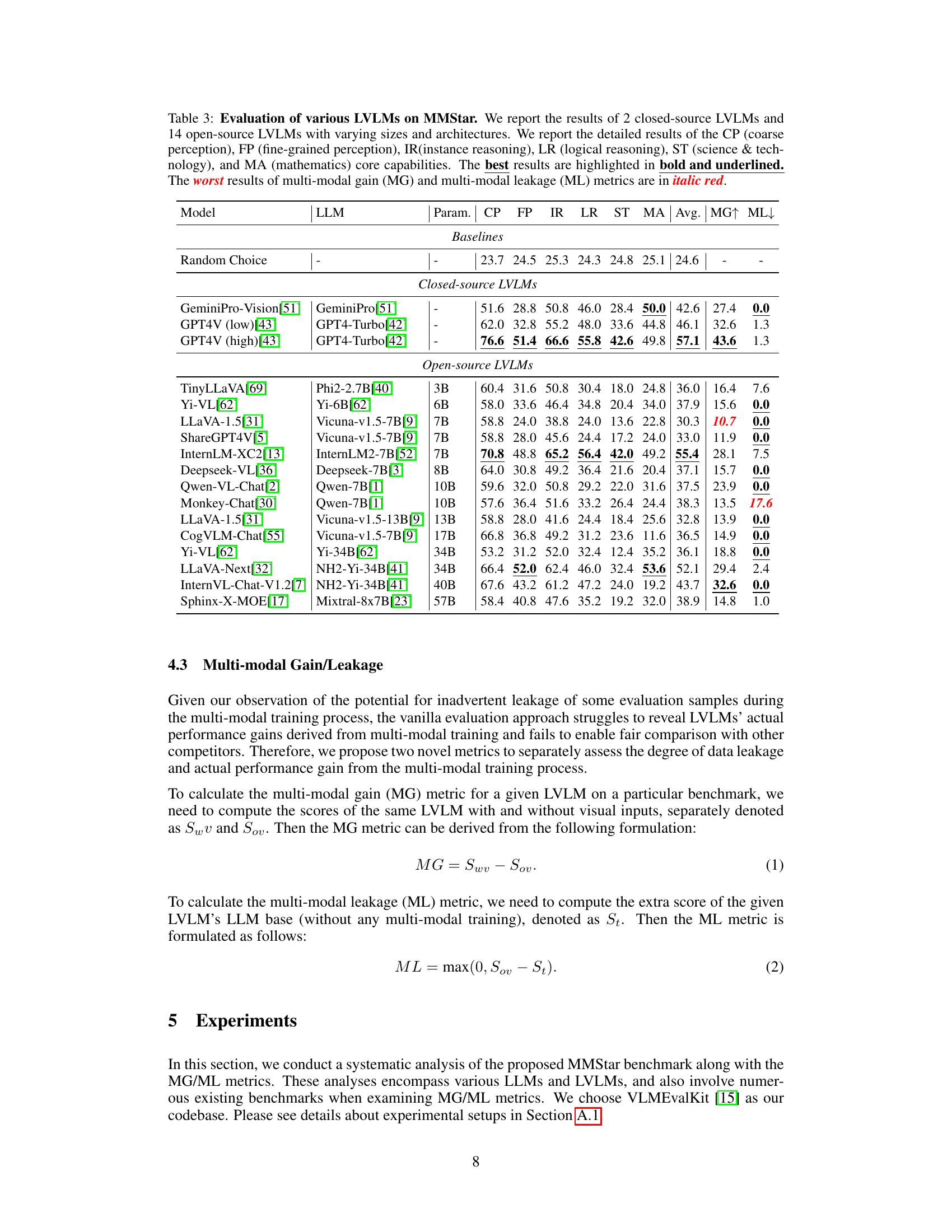
This table presents the performance of 16 Large Vision-Language Models (LVLMs) on the MMStar benchmark. It breaks down the results by six core multimodal capabilities (coarse perception, fine-grained perception, instance reasoning, logical reasoning, science & technology, and mathematics), showing the average score for each and the multi-modal gain (MG) and multi-modal leakage (ML). The best performing models for each capability are highlighted.

This table presents the performance comparison of various Large Vision-Language Models (LVLMs) and their corresponding Large Language Models (LLMs) across six popular multi-modal benchmarks. The results are shown for two evaluation strategies: using the full LVLM with visual input and using only the LLM text component (without visual input). The table highlights the best performance in the ‘LVLM-text’ setting (using only the text part of the model, without images) to illustrate data leakage issues. It helps in understanding the actual multimodal capabilities of LVLMs beyond the LLM backbone and reveals unintentional data leakage.
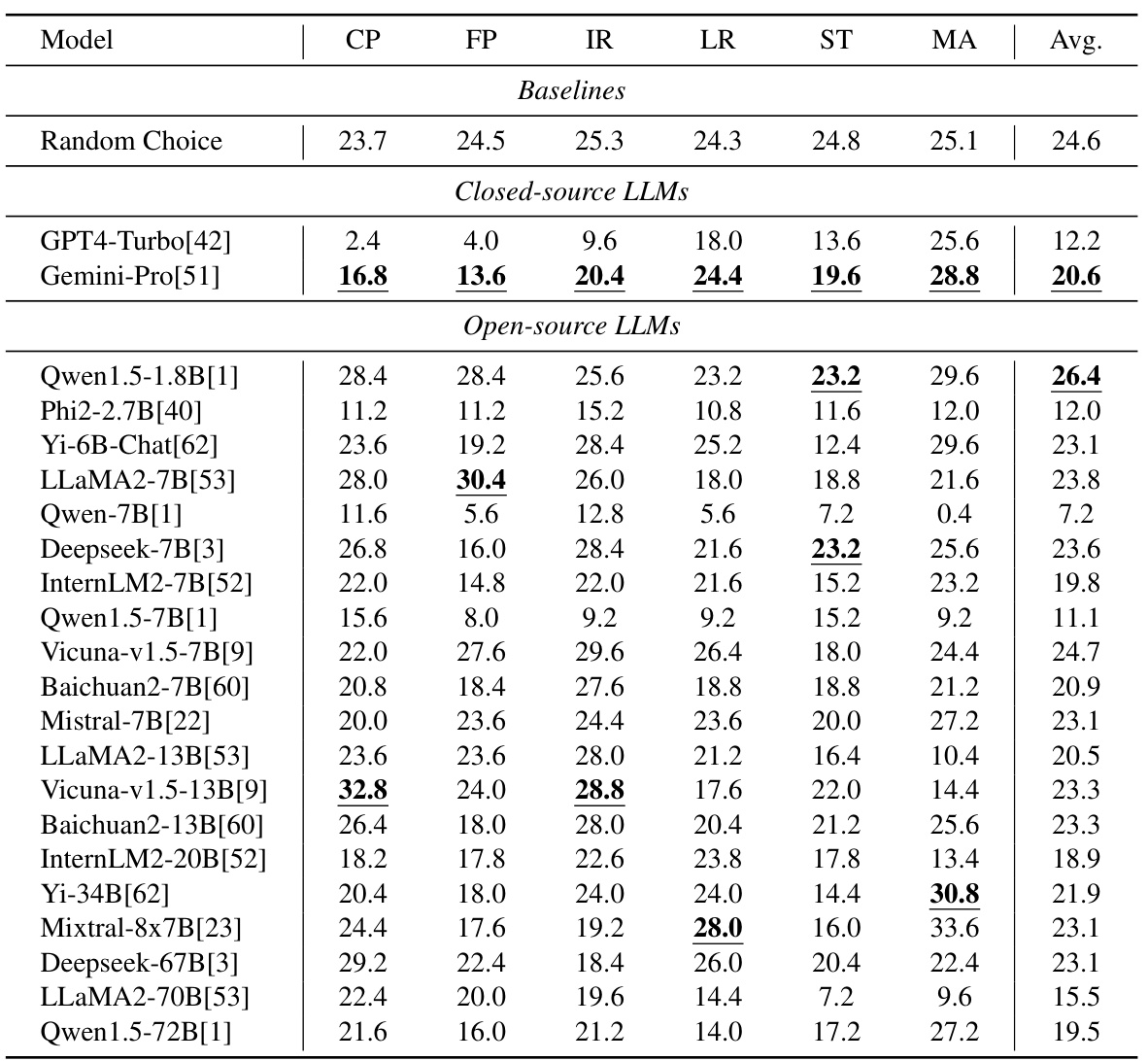
This table presents the performance of 22 LLMs (2 closed-source and 20 open-source) on six popular multi-modal benchmarks using a 2-shot inference strategy. The benchmarks assess different aspects of multimodal understanding. The table highlights the best-performing LLMs for each benchmark and provides an average performance score across all benchmarks. It demonstrates that even powerful LLMs can solve many questions without needing the visual information, highlighting a potential problem in existing multi-modal benchmark design.
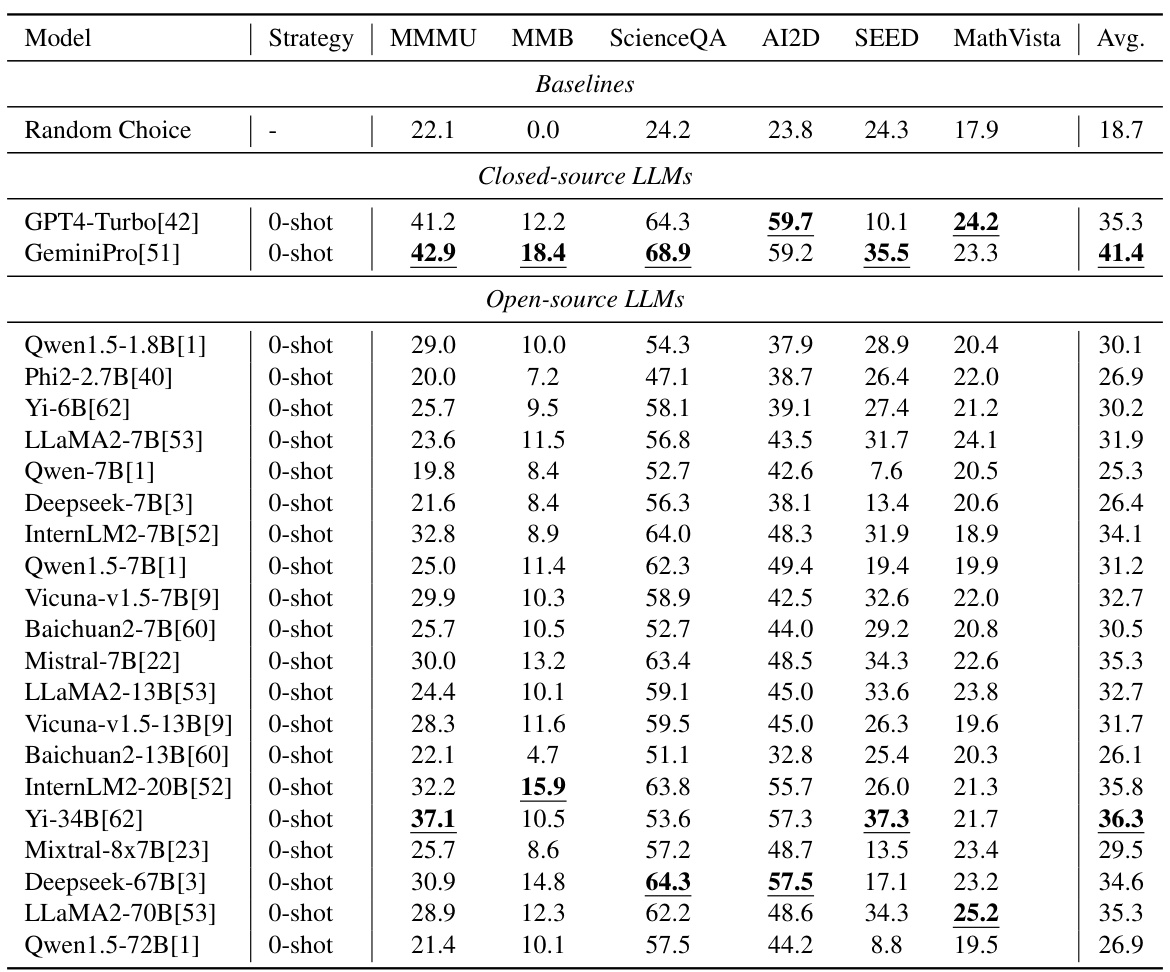
This table presents the performance of 22 large language models (LLMs) on six popular multi-modal benchmarks using a 2-shot inference strategy. It compares the performance of 2 closed-source LLMs and 20 open-source LLMs with different model sizes and architectures, highlighting the best-performing model for each benchmark. The table showcases the limitations of existing benchmarks, as LLMs can achieve high scores without needing visual input.
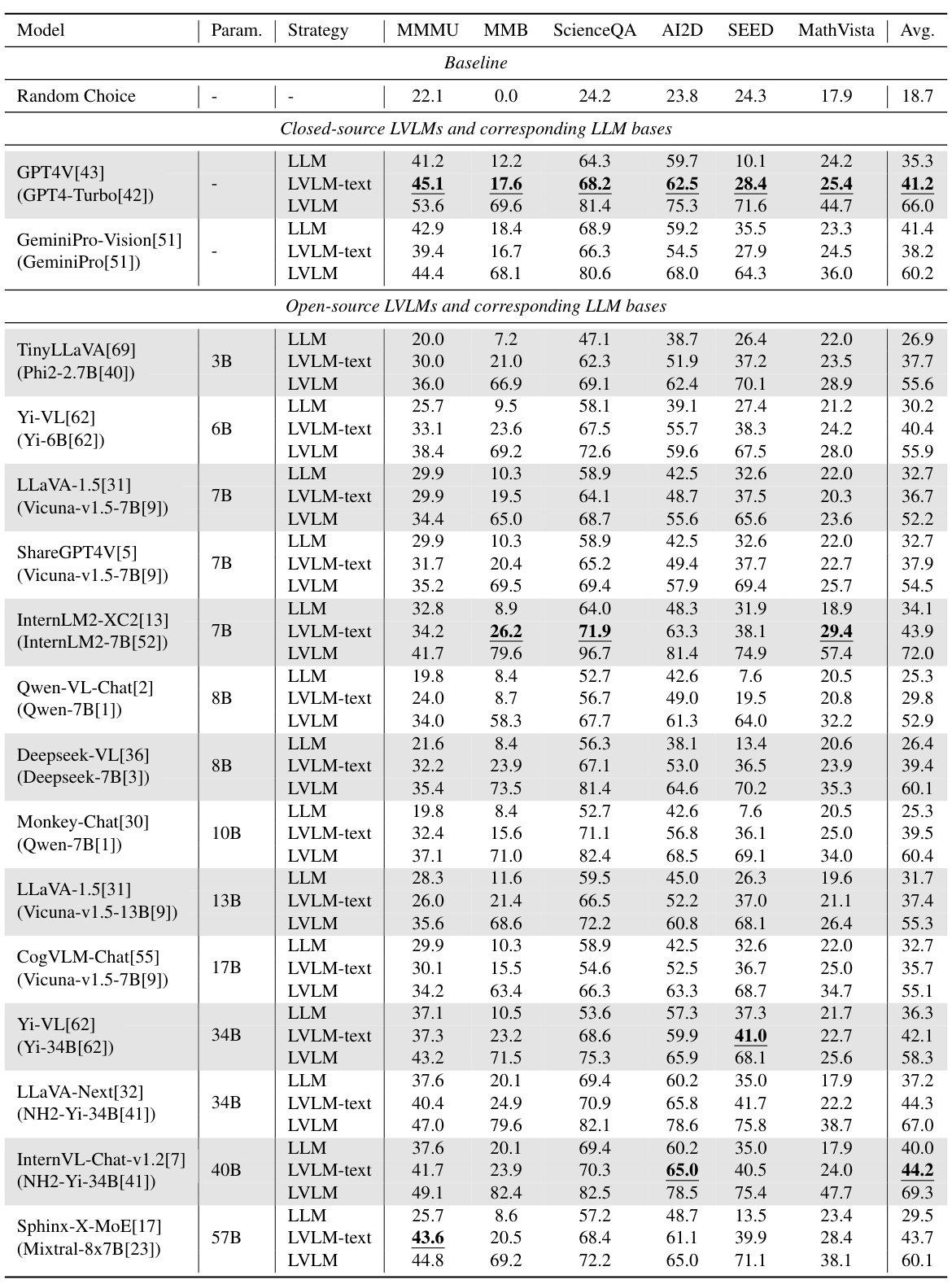
This table presents the performance of various Large Vision-Language Models (LVLMs) on six popular multi-modal benchmarks. It compares the performance of each LVLM using both its full capabilities (‘LVLM’) and only its underlying Large Language Model (‘LLM’) to assess the impact of visual information. The table highlights the best ‘LVLM-text’ (no visual input) scores for each benchmark.
Full paper#