TL;DR#
Federated learning (FL), while offering privacy benefits, is vulnerable to poisoning attacks (malicious data compromising model accuracy) and privacy breaches (inference attacks revealing private training data). Existing solutions often address these issues separately, leading to inefficiencies. Secure aggregation methods, while protecting data privacy, can inadvertently facilitate poisoning attacks because anomaly detection often requires access to the unencrypted local model updates. Additionally, existing dual defense approaches are often hampered by impractical assumptions and scalability issues.
DDFed introduces a novel dual-defense framework that simultaneously strengthens privacy and mitigates poisoning attacks. It leverages fully homomorphic encryption (FHE) for secure aggregation, providing strong privacy protection without relying on impractical multi-server setups. Furthermore, a two-phase anomaly detection method, encompassing secure similarity computation and feedback-driven collaborative selection, effectively identifies and filters out malicious updates, even in the presence of Byzantine clients. The use of FHE and a well-designed detection mechanism enhances the robustness and overall effectiveness of the DDFed approach. Experimental results confirm its superior performance in defending against various poisoning attacks across diverse scenarios, demonstrating the feasibility and efficacy of this innovative dual-defense strategy.
Key Takeaways#
Why does it matter?#
This paper is crucial because it directly addresses the critical challenge of enhancing privacy and mitigating poisoning attacks in federated learning, a rapidly growing field with significant security and privacy concerns. The proposed Dual Defense Federated learning (DDFed) framework offers a novel, practical solution by combining cutting-edge cryptography with a unique anomaly detection mechanism. This work opens avenues for further research into secure aggregation, anomaly detection techniques, and privacy-preserving machine learning.
Visual Insights#

🔼 This figure illustrates the Dual Defense Federated learning (DDFed) framework. It shows the interactions between multiple clients (C1…Cn) and a single aggregation server (A). Each client trains a local model, encrypts it using Fully Homomorphic Encryption (FHE), and sends it to the server. The server performs a two-phase anomaly detection: secure similarity computation and feedback-driven collaborative selection, to identify and filter out malicious models. Finally, the server securely aggregates the remaining models using FHE and sends the updated global model back to the clients. The figure visually demonstrates the key steps involved in a single round of DDFed training.
read the caption
Figure 1: Overview of DDFed framework and illustration of a single round DDFed training.
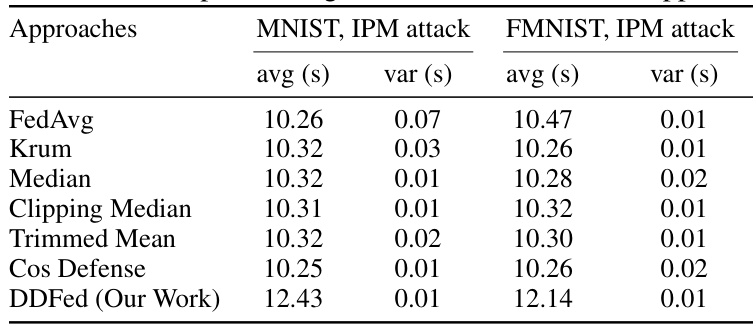
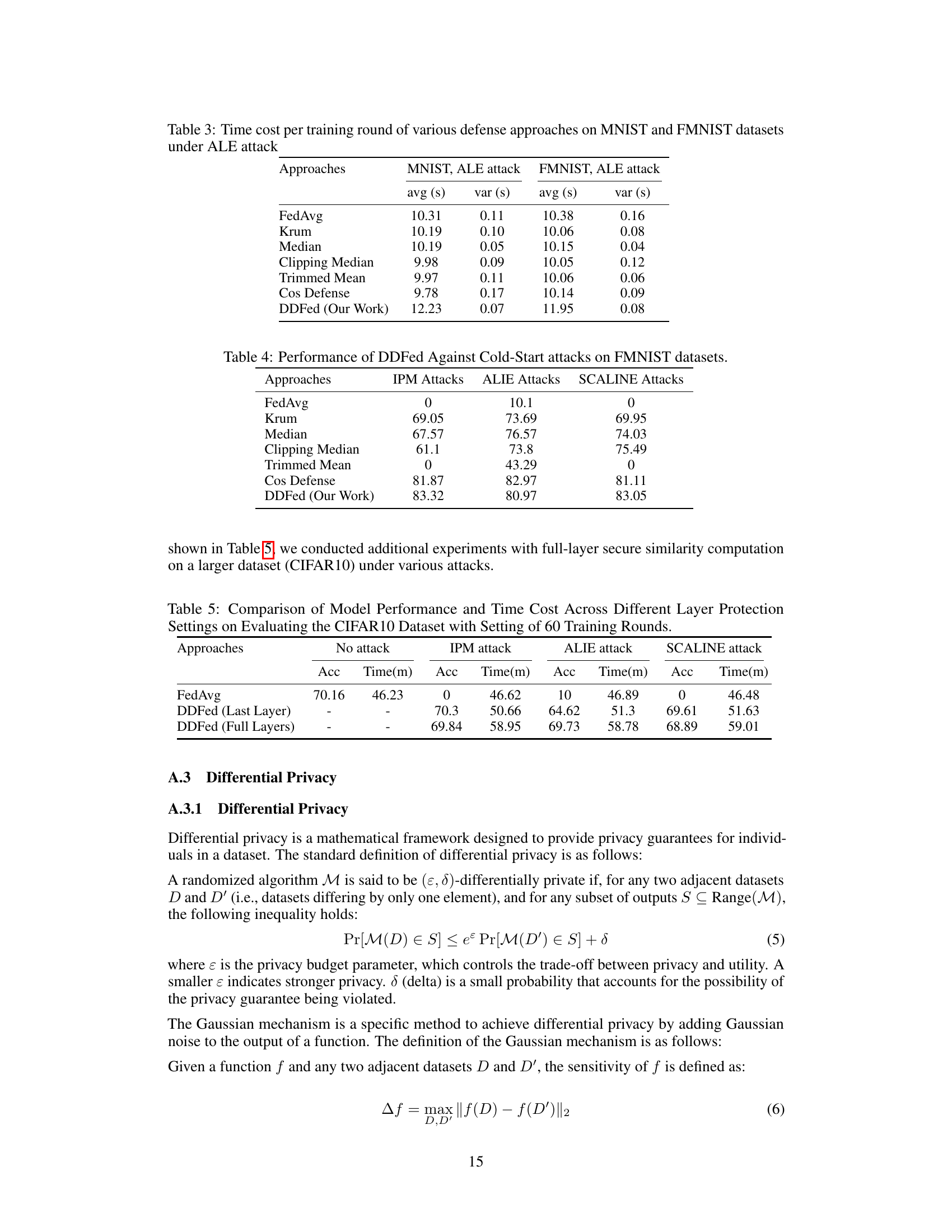
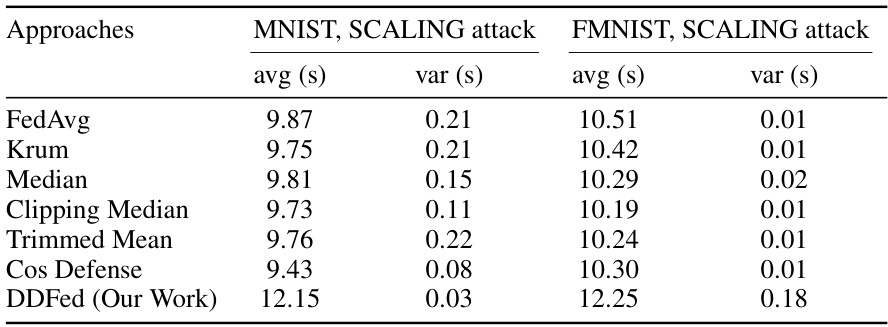
🔼 This table shows the average and variance of the time (in seconds) taken for one training round using different defense approaches. The experiments were conducted using MNIST and FMNIST datasets under an IPM attack. The results demonstrate the additional computational overhead introduced by the DDFed approach compared to other methods, due to its use of fully homomorphic encryption (FHE) and other privacy-enhancing techniques.
read the caption
Table 1: Time cost per training round of various defense approaches.
In-depth insights#
Dual Defense in FL#
The concept of “Dual Defense in FL” suggests a layered security approach to address the inherent vulnerabilities of Federated Learning (FL). Privacy and robustness against poisoning attacks are two critical challenges in FL. A dual defense strategy tackles both simultaneously. The first layer focuses on strong privacy-preserving mechanisms, perhaps leveraging fully homomorphic encryption (FHE) to secure model aggregation. This prevents unauthorized access to sensitive training data during the process. The second layer implements robust aggregation techniques to filter out malicious or anomalous model updates from compromised clients. This could involve secure similarity computations or Byzantine-resilient aggregation methods. The core innovation likely lies in the seamless integration of these two layers, addressing the trade-off between privacy and robustness. While secure aggregation can hinder traditional anomaly detection, a dual defense approach cleverly manages this by enabling robust methods that operate effectively even on encrypted data. The strength of this approach is its holistic nature, offering strong guarantees for both privacy and security against poisoning attacks within the constraints of FL’s distributed architecture.
FHE Secure Aggregation#
Fully Homomorphic Encryption (FHE)-based secure aggregation is a crucial technique for privacy-preserving machine learning, especially in federated learning settings. It allows for the aggregation of sensitive data (like model updates from various clients) without revealing individual contributions to a central server. The core idea is to encrypt the data before aggregation, perform the computation on the encrypted data, and decrypt the result only at the end. This ensures that the central server only gets the aggregated result and cannot access any individual client’s data, thus strengthening data privacy. However, FHE’s computational overhead can be significant, impacting the performance and efficiency of the entire system. Optimization techniques are essential to mitigate this. While FHE offers strong security properties, it’s also important to consider potential vulnerabilities. For instance, the security of the system might be compromised if the encryption scheme is flawed or if the server is compromised. Hence, robust protocols and careful implementation are key to the success of FHE-based secure aggregation. Moreover, the choice of the specific FHE scheme needs careful consideration, balancing security needs with computational efficiency and practical constraints.
Two-Phase Anomaly Detection#
The proposed two-phase anomaly detection method is a key contribution, addressing the challenge of identifying malicious model updates within the encrypted environment of federated learning. The first phase cleverly leverages secure similarity computation using fully homomorphic encryption (FHE), enabling the comparison of encrypted model updates against a global model without revealing sensitive information. This secure computation forms the basis for detecting anomalies. The second phase introduces a feedback-driven collaborative selection mechanism. This innovative approach uses the similarity scores to identify potentially malicious clients, allowing the system to collaboratively filter out compromised model updates, thus enhancing the robustness of the overall system. The two-phase approach not only ensures strong privacy protection by operating primarily on encrypted data but also demonstrates effectiveness in mitigating model poisoning attacks, highlighting a significant advance in securing federated learning.
Privacy-Preserving Mechanisms#
Privacy-preserving mechanisms in federated learning aim to address the inherent conflict between collaborative model training and individual data privacy. Secure aggregation techniques, such as homomorphic encryption and secure multi-party computation, are crucial for protecting sensitive training data during model updates. These methods allow for computations on encrypted data, preventing the aggregation server from accessing sensitive information directly. However, the computational overhead of these techniques can be substantial and may limit scalability. Differential privacy, another popular approach, injects carefully calibrated noise into the model updates to mask individual data contributions. While it provides strong privacy guarantees, it can impact the accuracy of the model. The choice of a specific mechanism depends heavily on the application’s specific privacy and accuracy requirements, considering the trade-off between security and performance. Ongoing research focuses on developing more efficient and robust privacy-preserving techniques, including exploring novel cryptographic methods and optimizing existing ones for efficiency and scalability. The design of optimal mechanisms must also account for the threat model, considering potential adversarial attacks that attempt to compromise privacy or infer sensitive information.
Future Research Directions#
Future research could explore relaxing the constraint that less than 50% of clients are malicious, investigating methods to maintain effective dual defense even with a higher proportion of compromised nodes. Adapting DDFed to more complex FL settings, such as those with dynamic participant groups or employing dropout techniques, would enhance its practical applicability. A thorough investigation into the interplay between different hyperparameter settings in DDFed and their impact on both privacy and robustness is warranted. Finally, exploring the integration of DDFed with other advanced privacy-enhancing techniques beyond FHE, and evaluating its performance on diverse real-world datasets, will solidify its potential as a truly robust and practical defense mechanism for federated learning.
More visual insights#
More on figures

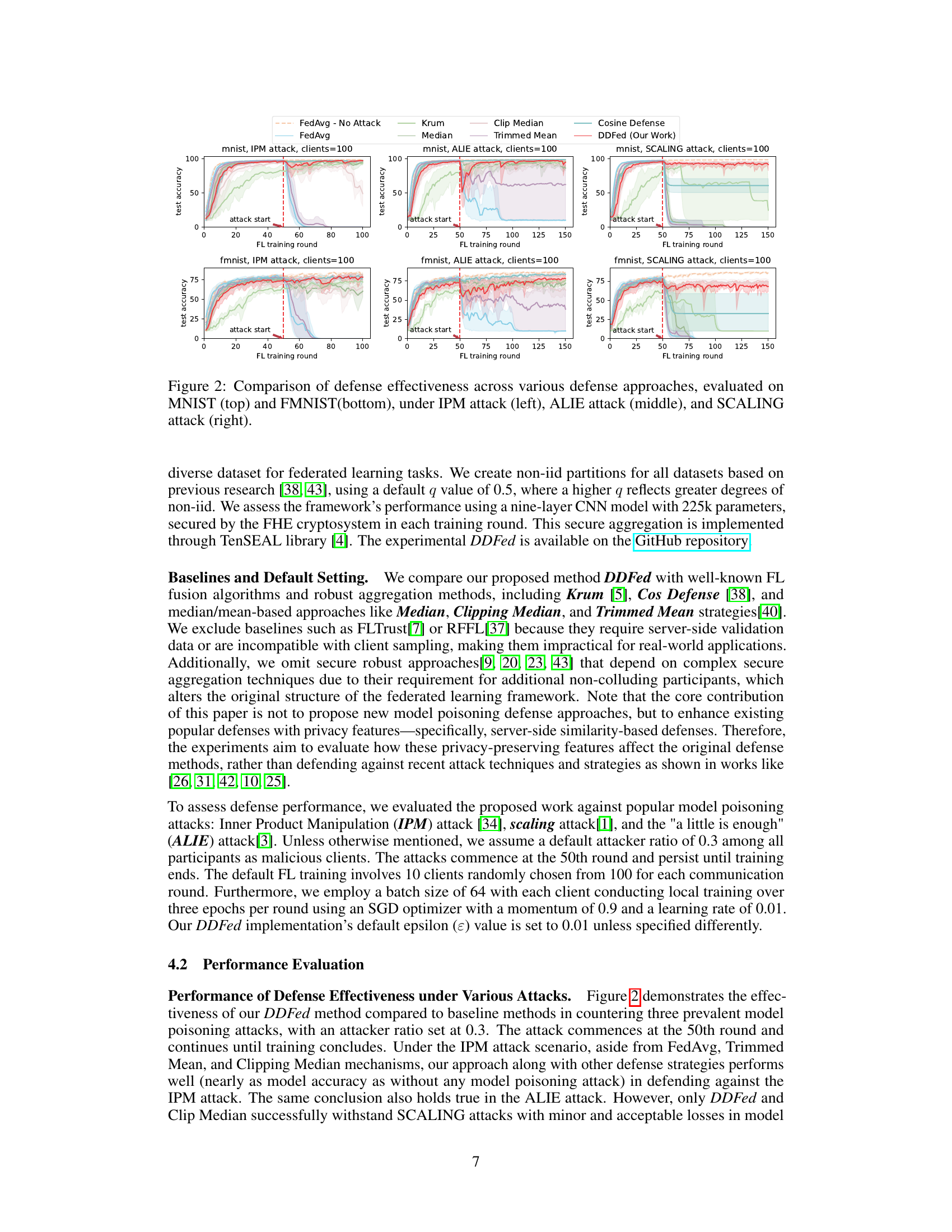
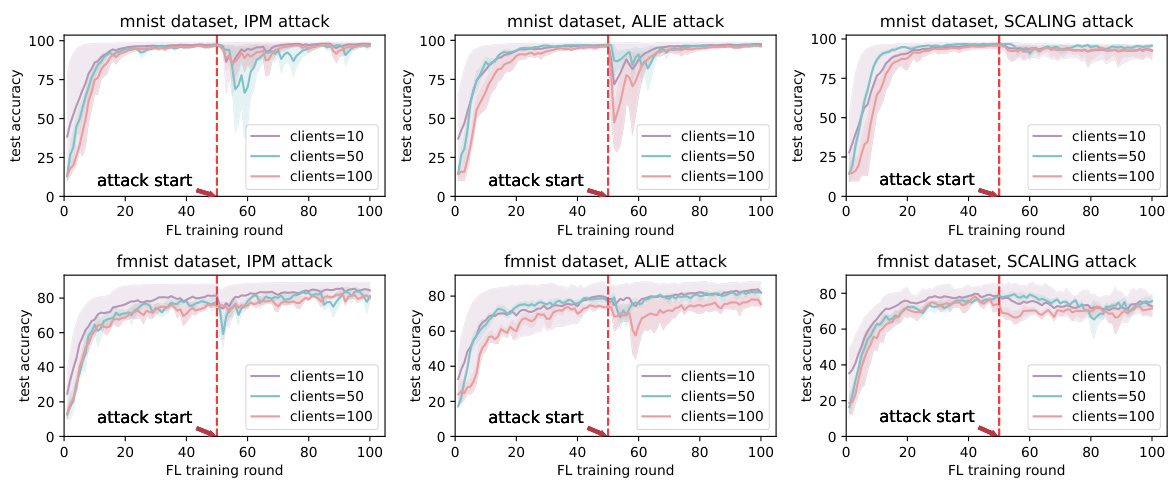
🔼 This figure compares the performance of different defense mechanisms against three common model poisoning attacks: IPM, ALIE, and SCALING. The top row shows results using the MNIST dataset, while the bottom row uses the Fashion-MNIST (FMNIST) dataset. Each column represents a different attack type. The plot shows test accuracy over federated learning training rounds. The vertical dashed line indicates when the attack begins. The comparison includes FedAvg (without attack), FedAvg (with attack), Krum, Median, Clipped Median, Trimmed Mean, Cosine Defense, and the proposed DDFed method. The shaded areas around the lines represent confidence intervals.
read the caption
Figure 2: Comparison of defense effectiveness across various defense approaches, evaluated on MNIST (top) and FMNIST(bottom), under IPM attack (left), ALIE attack (middle), and SCALING attack (right).

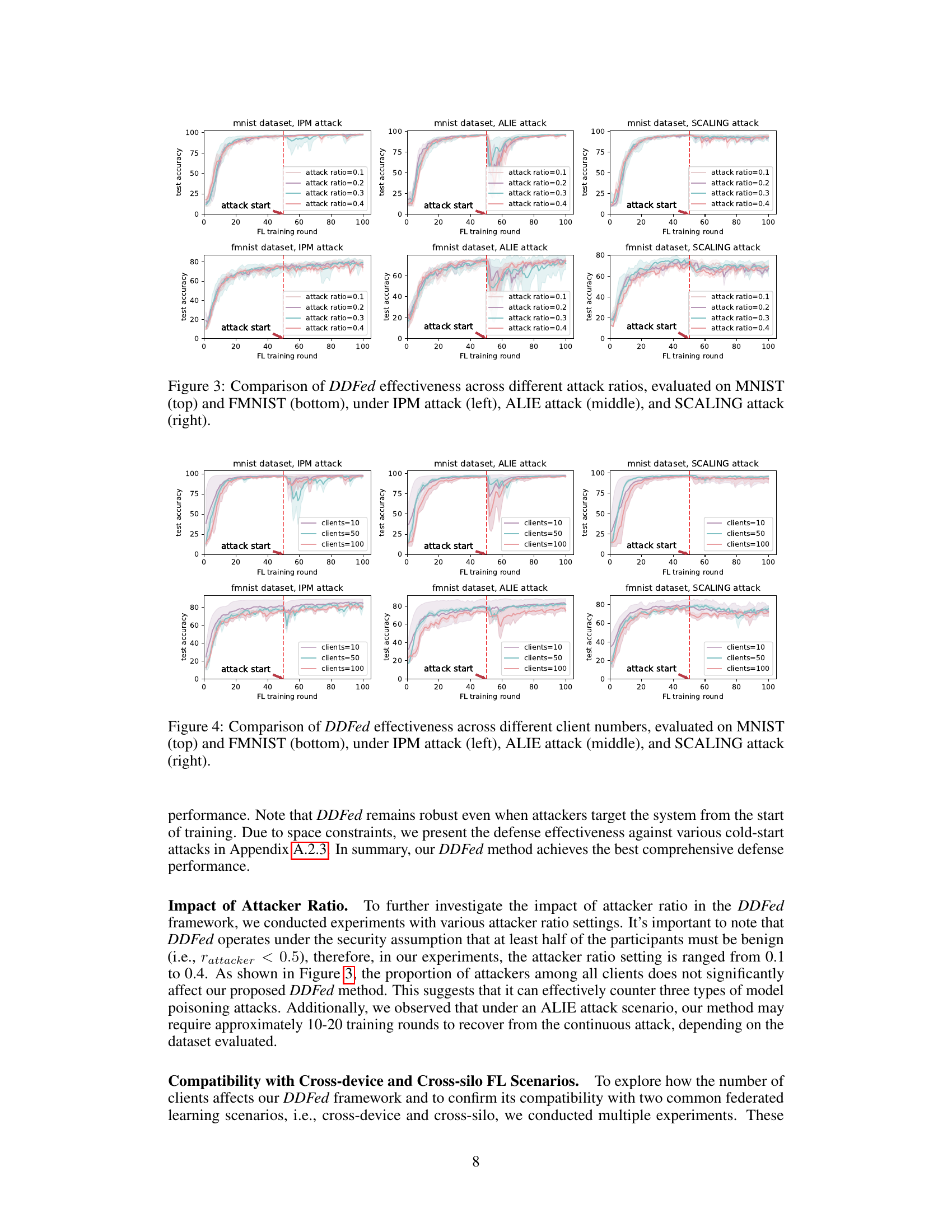
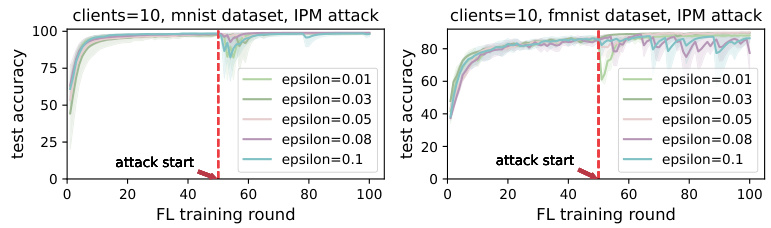
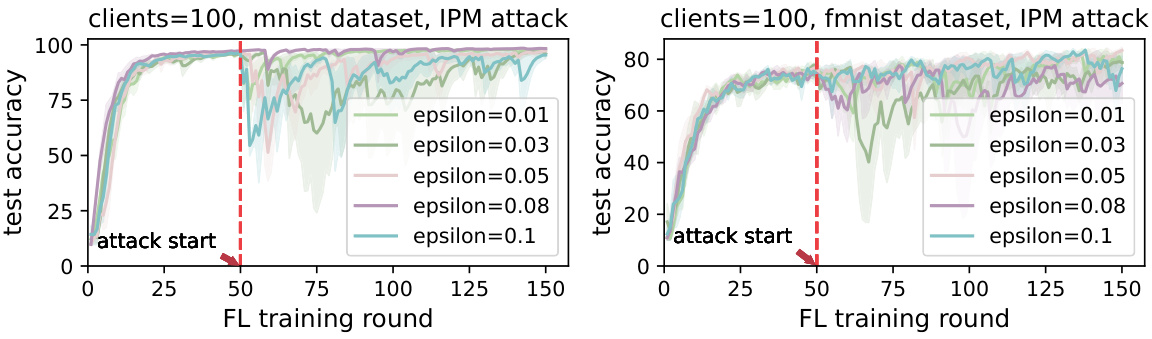
🔼 This figure displays the results of experiments evaluating the effectiveness of the Dual Defense Federated learning (DDFed) framework against three different model poisoning attacks (IPM, ALIE, and SCALING) at varying attack ratios (0.1 to 0.4). The top row shows results for the MNIST dataset, while the bottom row shows results for the FMNIST dataset. Each subfigure shows the test accuracy over training rounds, with different colored lines representing different attack ratios. The vertical dashed line indicates the start of the attack. This figure demonstrates the robustness of DDFed against these attacks even at higher attack ratios. The relatively steady performance, even with attacks starting from the beginning, is highlighted.
read the caption
Figure 3: Comparison of DDFed effectiveness across different attack ratios, evaluated on MNIST (top) and FMNIST (bottom), under IPM attack (left), ALIE attack (middle), and SCALING attack (right).
🔼 This figure compares the performance of different defense mechanisms against three common model poisoning attacks (IPM, ALIE, SCALING) on two datasets (MNIST and FMNIST). The x-axis represents the federated learning training round, and the y-axis shows the test accuracy. Each subplot shows the test accuracy for different defenses (FedAvg, Krum, Median, Clipping Median, Trimmed Mean, Cosine Defense, and DDFed). The red vertical dashed line indicates when the attacks begin. The figure visually demonstrates DDFed’s superior robustness compared to other defenses across various attacks and datasets.
read the caption
Figure 2: Comparison of defense effectiveness across various defense approaches, evaluated on MNIST (top) and FMNIST(bottom), under IPM attack (left), ALIE attack (middle), and SCALING attack (right).
🔼 This figure compares the performance of the Dual Defense Federated Learning (DDFed) framework against three different model poisoning attacks (IPM, ALIE, and SCALING) at various attack ratios. The top row shows results using the MNIST dataset, while the bottom row uses the Fashion-MNIST (FMNIST) dataset. Each column represents a different attack, and each line within a column represents a different attack ratio (proportion of malicious clients). The red dashed line indicates when the attacks begin. The graphs show that DDFed maintains relatively high accuracy even with a significant proportion of malicious clients, demonstrating its robustness to model poisoning attacks.
read the caption
Figure 3: Comparison of DDFed effectiveness across different attack ratios, evaluated on MNIST (top) and FMNIST (bottom), under IPM attack (left), ALIE attack (middle), and SCALING attack (right).

🔼 This figure provides a visual representation of the Dual Defense Federated Learning (DDFed) framework. It shows the interactions between multiple clients (C1…Cn), each possessing their own dataset and local model, and a single aggregation server (A). The figure details the steps involved in a single training round, highlighting the use of Fully Homomorphic Encryption (FHE) for secure aggregation and a two-phase anomaly detection mechanism that involves secure similarity computation and feedback-driven collaborative selection. The process demonstrates how local model updates are securely aggregated while simultaneously mitigating potential poisoning attacks by identifying and filtering out malicious updates.
read the caption
Figure 1: Overview of DDFed framework and illustration of a single round DDFed training.
🔼 This figure compares the performance of the Dual Defense Federated Learning (DDFed) framework against three different model poisoning attacks (IPM, ALIE, and SCALING) at various attack ratios. The results are shown for both MNIST and Fashion-MNIST datasets. The x-axis represents the federated learning training round, and the y-axis represents the test accuracy. Each line represents a different attack ratio. The dashed vertical line indicates the point where the attack starts. The figure demonstrates the robustness of DDFed across varying attack intensities.
read the caption
Figure 3: Comparison of DDFed effectiveness across different attack ratios, evaluated on MNIST (top) and FMNIST (bottom), under IPM attack (left), ALIE attack (middle), and SCALING attack (right).
More on tables
🔼 This table presents the average and variance of the time cost (in seconds) per training round for different defense approaches on the MNIST and FMNIST datasets under a SCALING attack. The approaches compared include FedAvg, Krum, Median, Clipping Median, Trimmed Mean, Cosine Defense, and the proposed DDFed. The table shows the time overhead introduced by the DDFed approach compared to other methods.
read the caption
Table 2: Time cost per training round of various defense approaches on MNIST and FMNIST datasets under SCALING attack
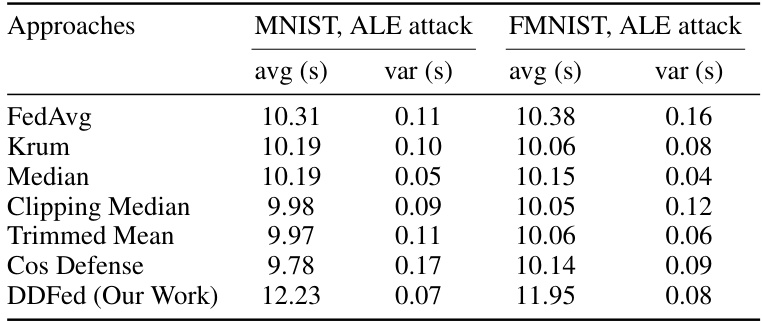
🔼 This table compares the average and variance of the time cost per training round for different defense methods (FedAvg, Krum, Median, Clipping Median, Trimmed Mean, Cosine Defense, and DDFed) on the MNIST and FMNIST datasets when under the ALIE attack. It shows the computational overhead introduced by each method.
read the caption
Table 3: Time cost per training round of various defense approaches on MNIST and FMNIST datasets under ALE attack

🔼 This table presents the performance comparison of different defense methods against three types of model poisoning attacks (IPM, ALIE, and SCALINE) on the FMNIST dataset. The attacks start from the beginning of the training process (cold-start attacks), unlike the primary experiments in the paper that started the attacks at training round 50. The table shows the test accuracy achieved by different methods under these attacks. DDFed (Our Work) shows relatively high accuracy compared to other methods.
read the caption
Table 4: Performance of DDFed Against Cold-Start attacks on FMNIST datasets.

🔼 This table compares the model performance (accuracy) and time cost of three different approaches: FedAvg, DDFed (using only the last layer for similarity computation), and DDFed (using all layers for similarity computation). The comparison is made under four different attack scenarios: no attack, IPM attack, ALIE attack, and SCALINE attack. It demonstrates the effectiveness of DDFed, especially when using all layers, in maintaining model accuracy while adding minimal computational overhead compared to FedAvg, even under various model poisoning attacks.
read the caption
Table 5: Comparison of Model Performance and Time Cost Across Different Layer Protection Settings on Evaluating the CIFAR10 Dataset with Setting of 60 Training Rounds.

🔼 This table compares the model performance of DDFed with and without the addition of differential privacy (DP) noise to the encrypted similarity computation. The simulated DDFed uses DP noise added to non-encrypted parameters, and the actual DDFed integrates DP into the encrypted computations. The accuracy results (in percentage) for IPM, ALIE, and SCALINE attacks are presented for both versions. The results show that adding DP noise to the encrypted similarity does not significantly impact the model performance.
read the caption
Table 6: Impact of DP on FHE-based Similarity Detection in DDFed on evaluating CIFAR10 datasets.
Full paper#