↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Vision transformers (ViTs) use attention modules that are computationally expensive. State space models (SSMs) offer an efficient alternative with linear computational complexity, but their efficiency can be further enhanced. Existing token pruning techniques for ViTs fail to deliver good performance when directly applied to SSMs, motivating the search for SSM-specific pruning methods. This disruption of the token order causes performance degradation.
This paper addresses this issue by introducing a novel token pruning method specifically designed for SSMs. The key innovation is a pruning-aware hidden state alignment that stabilizes the neighborhood of remaining tokens, thereby mitigating the accuracy drop from naive application. The authors also propose a new token importance evaluation method tailored to SSMs to effectively guide token selection and pruning. Their method demonstrates significant computational speedups and minimal impact on performance across different benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with vision state space models (SSM). It offers a novel token pruning method, enhancing SSM efficiency and addressing existing limitations of direct ViT token pruning methods. It opens avenues for improving SSM efficiency and understanding their unique computational patterns. The findings are broadly applicable and relevant for researchers working on accelerating vision models and improving their interpretability.
Visual Insights#

This figure illustrates the difference between standard ViT token pruning and its application to ViM (Vision-based State Space Models). The left side shows ViT token pruning where patches are simply removed. The middle shows the ViM scan process, illustrating how tokens are processed sequentially across various directions. The right displays the result of applying ViT-style token pruning to ViM. The condensed token matrix and the actual ViM scan after pruning show how the naive application of ViT pruning disrupts the sequential pattern of the ViM scan, leading to performance degradation. This disruption is a key point the paper makes about why existing ViT pruning techniques fail when applied directly to ViMs.
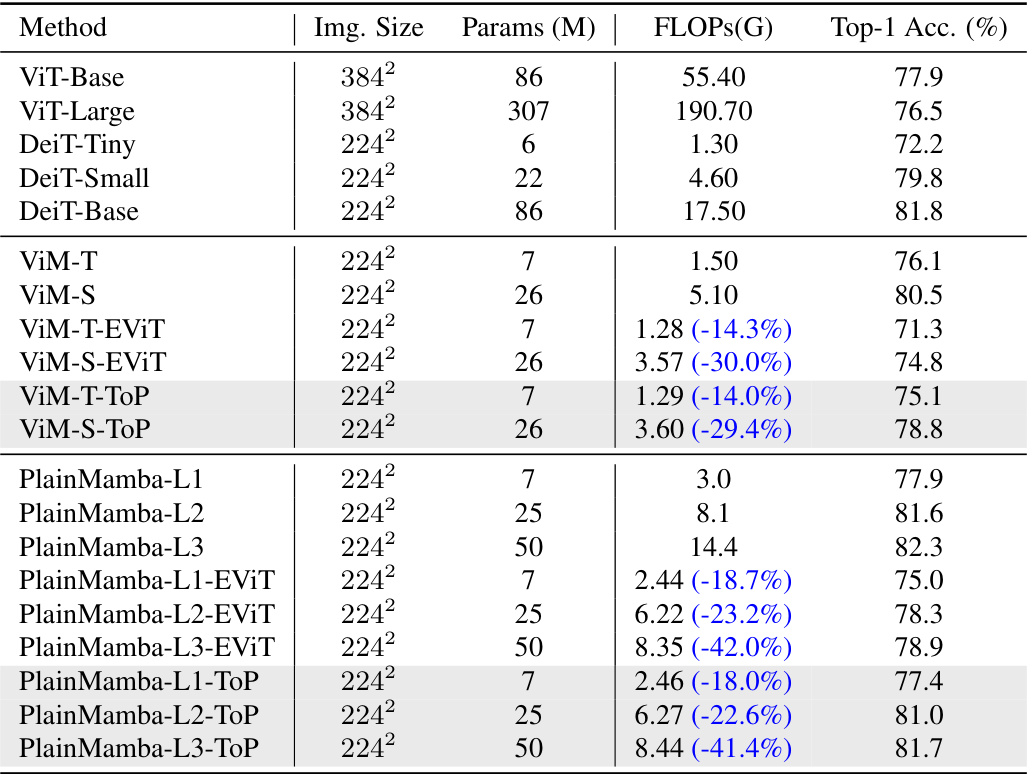
This table presents the results of image classification experiments conducted on the ImageNet-1K dataset. It compares various vision transformer models (ViT, DeiT, ViM, PlainMamba) and their performance after applying different token pruning methods (EViT and the proposed TOP method). The table shows the model size (image size, parameters, and FLOPs), along with the top-1 accuracy achieved. This allows for a direct comparison of the efficiency gains (FLOP reduction) obtained by each pruning method, while maintaining classification accuracy.
In-depth insights#
SSM Token Pruning#
State Space Models (SSMs) offer a computationally efficient alternative to transformers for vision tasks. SSM token pruning aims to further enhance efficiency by selectively removing less informative tokens, similar to techniques used in Vision Transformers (ViTs). However, directly applying ViT pruning methods to SSMs proves ineffective, significantly degrading accuracy. This is because naive pruning disrupts the crucial sequential order of tokens within SSMs, affecting the model’s inherent scan mechanism. Therefore, a novel pruning-aware hidden state alignment method is proposed to maintain the integrity of the remaining tokens during the scan. This method, coupled with a specialized token importance evaluation metric, yields a significant computational reduction with minimal performance impact. The approach is general and applicable across various SSM-based vision models, achieving substantial gains in both accuracy and speed. Efficient implementation strategies further accelerate performance, demonstrating the viability of token pruning as a powerful optimization technique for SSMs.
Hidden State Align#
The concept of ‘Hidden State Alignment’ in the context of token pruning for state space models (SSMs) is crucial for maintaining model accuracy. Naive token pruning disrupts the sequential relationships between tokens, harming performance. Hidden state alignment aims to mitigate this by strategically modifying the hidden states of both retained and pruned tokens. This ensures that the computational flow within the SSM remains consistent despite the removal of certain tokens. The method likely involves careful manipulation of the transition matrices and hidden state vectors, preserving the original sequential context as much as possible. A successful alignment technique should retain the spatial and temporal relationships that define the SSM’s scan mechanism. This approach focuses on solving the fundamental issue of maintaining the context and integrity of SSMs even when processing a reduced set of tokens, thus improving both model efficiency and accuracy.
Importance Eval#
The ‘Importance Eval’ section, crucial for efficient token pruning, focuses on discerning the significance of each token within the SSM. A key insight is the leveraging of the SSM’s inherent structure to guide the importance assessment. Unlike attention-based methods, SSMs lack explicit attention weights. Therefore, a novel approach is needed, likely involving analysis of hidden state transformations or output values to derive a token importance score. This score might reflect the token’s contribution to the overall model output or its impact on subsequent processing stages. The choice of the importance metric is likely to be experimentally determined, with various metrics (e.g., L1/L2 norms, max pooling across channels) being compared to determine which yields the best pruning results while minimizing performance degradation. The effectiveness of the chosen metric ultimately depends on the balance between computational savings and accuracy preservation. The details will explain precisely how token importance is calculated and used to rank tokens for subsequent pruning.
ViT Pruning Fail#
The section ‘ViT Pruning Fail’ would analyze why directly applying token pruning methods developed for Vision Transformers (ViTs) to Vision State Space Models (ViMs) proves ineffective. It would highlight that naive application disrupts the inherent sequential nature of token processing in ViMs, unlike the independent patch processing in ViTs. This disruption significantly harms accuracy, even with extensive fine-tuning. The analysis would likely delve into the computational differences between ViTs (quadratic complexity of attention) and ViMs (linear complexity using state space), explaining how token pruning, effective in ViTs, negatively impacts the sequential dependencies crucial to ViM performance. The failure underscores the need for specialized token pruning tailored to the unique architectural characteristics of ViMs, motivating the development of a new pruning method specifically designed for these models, emphasizing the preservation of sequential information during the pruning process.
Future Research#
Future research directions stemming from this paper could explore several key areas. Extending the token pruning methodology to other SSM-based architectures beyond those tested is crucial for broader applicability. Investigating the impact of different token importance metrics and developing more robust and accurate methods would improve pruning efficiency and accuracy. A particularly promising avenue would involve developing more sophisticated hidden state alignment techniques to further mitigate the disruption caused by token removal, potentially leveraging advanced optimization algorithms or exploring alternative alignment strategies. Finally, a deeper theoretical understanding of how token pruning affects the learning dynamics and generalization capabilities of SSMs is needed, possibly through developing novel theoretical frameworks to analyze the interplay between token sparsity and model performance. This research would solidify the foundations and enhance the effectiveness of token pruning methods in vision state space models.
More visual insights#
More on figures

This figure shows the cross-scan mechanism in Vision State Space Models (ViMs) before and after applying token pruning. The left side illustrates a standard ViM-S model, showing the input tokens arranged in a grid, processed in the pattern of a ‘ViM scan’. The middle panel shows the result of applying a naive token pruning strategy (as is commonly used in Vision Transformers), randomly removing tokens from the input. The right side shows how the ViM scan is disrupted after naive token pruning, resulting in an uneven distribution of remaining tokens. This disruption of the sequential order is a key reason why traditional token pruning methods designed for ViTs are ineffective on ViMs.

This figure visualizes the attention maps of the ViM-S model on ImageNet-1K. It compares the attention maps of the original model, a model with token pruning without the proposed hidden state alignment, and a model with token pruning using the proposed alignment. Each row represents a different example image, showing how the attention is distributed across different parts of the image. The results demonstrate the effect of the proposed alignment in maintaining similar attention patterns to the original model despite token pruning, unlike the model without alignment.

This figure illustrates the concept of cross-scan in Vision State Space Models (ViMs) and how it is affected by token pruning. The top row shows the original ViM scan process, where image patches are processed sequentially along traversal paths. The bottom row shows the effect of token pruning. Some tokens (patches) are removed, resulting in a ‘condensed token matrix’. The key point is that the naive application of token pruning disrupts the original sequential pattern of the scan, which is a crucial difference from the independent patch processing in Vision Transformers (ViTs).
More on tables
This table presents the comparison of top-1 accuracy and GFLOPs for various models on the ImageNet-1K dataset. It compares different Vision Transformers (ViTs) and State Space Models (SSMs), both with and without the proposed token pruning method (ToP) and a baseline ViT token pruning method (EViT). The table shows the impact of different pruning strategies on model performance and computational efficiency.

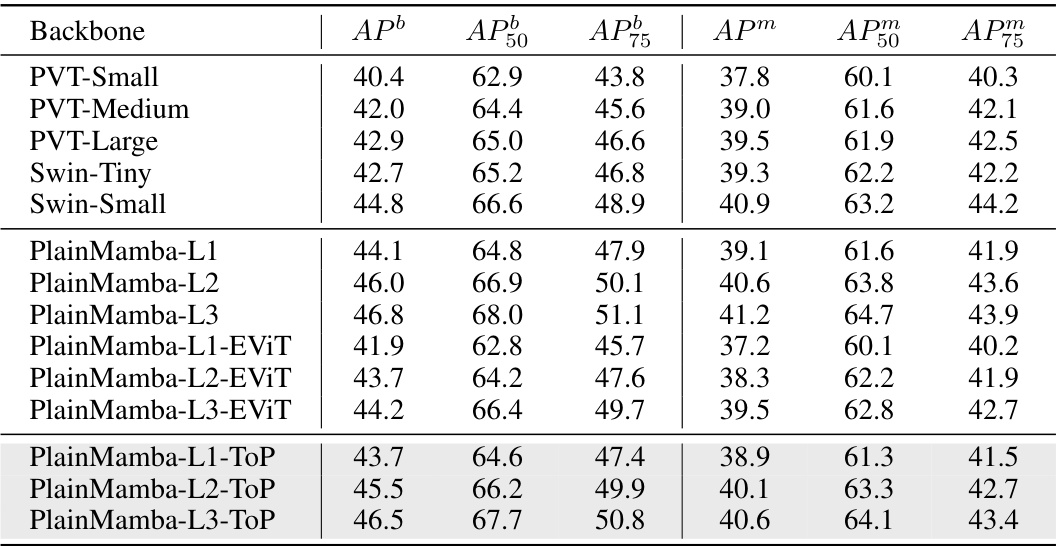
This table presents the results of semantic segmentation on the ADE20K dataset. It compares the mean Intersection over Union (mIoU) achieved by several different models, including various sizes of ViM and PlainMamba, and their corresponding versions with token pruning using the EViT method and the proposed ToP method. The purpose is to show the effectiveness of the proposed token pruning method for achieving comparable performance with significantly reduced computational cost.
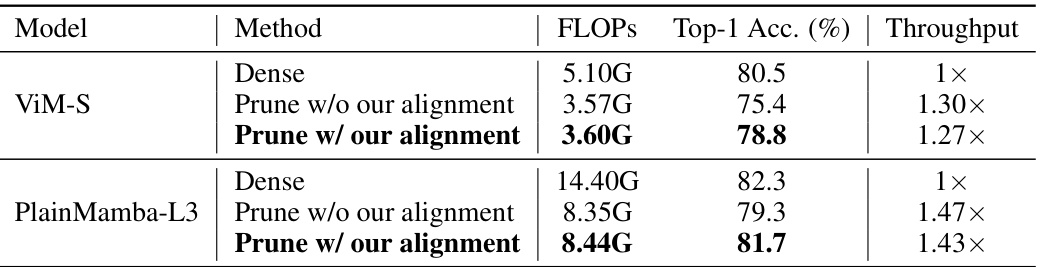
This table presents a quantitative comparison of the proposed token pruning method with and without the pruning-aware hidden state alignment. It shows the FLOPs, Top-1 accuracy, and throughput for two models, ViM-S and PlainMamba-L3, under different conditions: dense (no pruning), pruning without alignment, and pruning with alignment. The results highlight the effectiveness of the proposed alignment technique in maintaining accuracy while reducing FLOPs and improving throughput.

This table presents the ablation study of different token importance metrics used in the proposed token pruning method. It compares the performance of using l1-norm, l2-norm, unclipped values (w/o Clip), and the proposed clipping method (Clip) for two different models, ViM-S and L3. The results show that the proposed clipping method consistently achieves higher accuracy than the other methods, suggesting its effectiveness in mitigating the adverse effects of extreme token importance values.
Full paper#



















