TL;DR#
Current multimodal large language models (MLLMs) struggle to fully capture the appearance and geometry of objects from images or 3D data. Neural Radiance Fields (NeRFs) offer an alternative by encoding this information in the weights of a simple neural network, but integrating NeRFs with LLMs remains challenging. There’s a need for methods that directly process NeRFs for enhanced understanding and efficient task completion.
This research introduces LLaNA, the first general-purpose NeRF-language assistant. LLaNA directly processes the weights of a NeRF’s MLP using a meta-network encoder, enabling it to perform tasks such as NeRF captioning and Q&A without needing to render images or create 3D data structures. This novel approach significantly improves efficiency and effectiveness. The researchers also create a benchmark and dataset for evaluating NeRF understanding and demonstrate that LLaNA surpasses other methods that rely on 2D or 3D representations from NeRFs.
Key Takeaways#
Why does it matter?#
This paper is highly relevant to researchers working on multimodal learning, large language models, and neural radiance fields. It bridges the gap between LLMs and NeRFs, opening new avenues for research in 3D scene understanding and generation. The proposed benchmark and dataset are valuable resources for the community, facilitating future research and development in this rapidly evolving area. By directly processing NeRF weights, it offers a new paradigm for efficient and effective NeRF understanding.
Visual Insights#

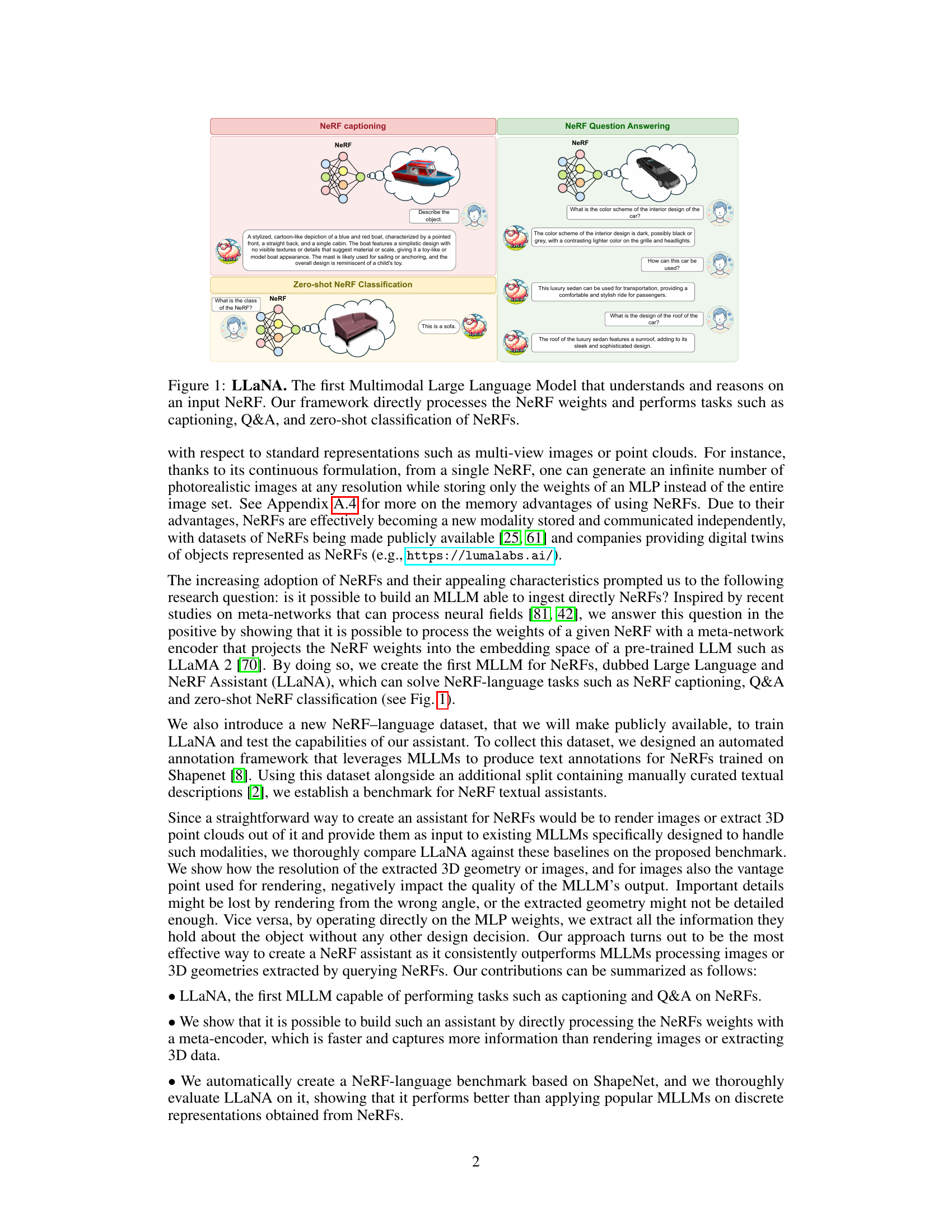
🔼 LLaNA is a multimodal large language model designed to directly process the weights of Neural Radiance Fields (NeRFs). Unlike methods that rely on rendering images or extracting 3D point clouds from NeRFs, LLaNA operates on the NeRF’s MLP weights to extract information about the objects. The figure visually depicts LLaNA performing three tasks: NeRF captioning (generating textual descriptions of NeRF-represented objects), NeRF question answering (answering questions about NeRF-represented objects), and zero-shot NeRF classification (classifying objects represented in NeRFs without prior training).
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.

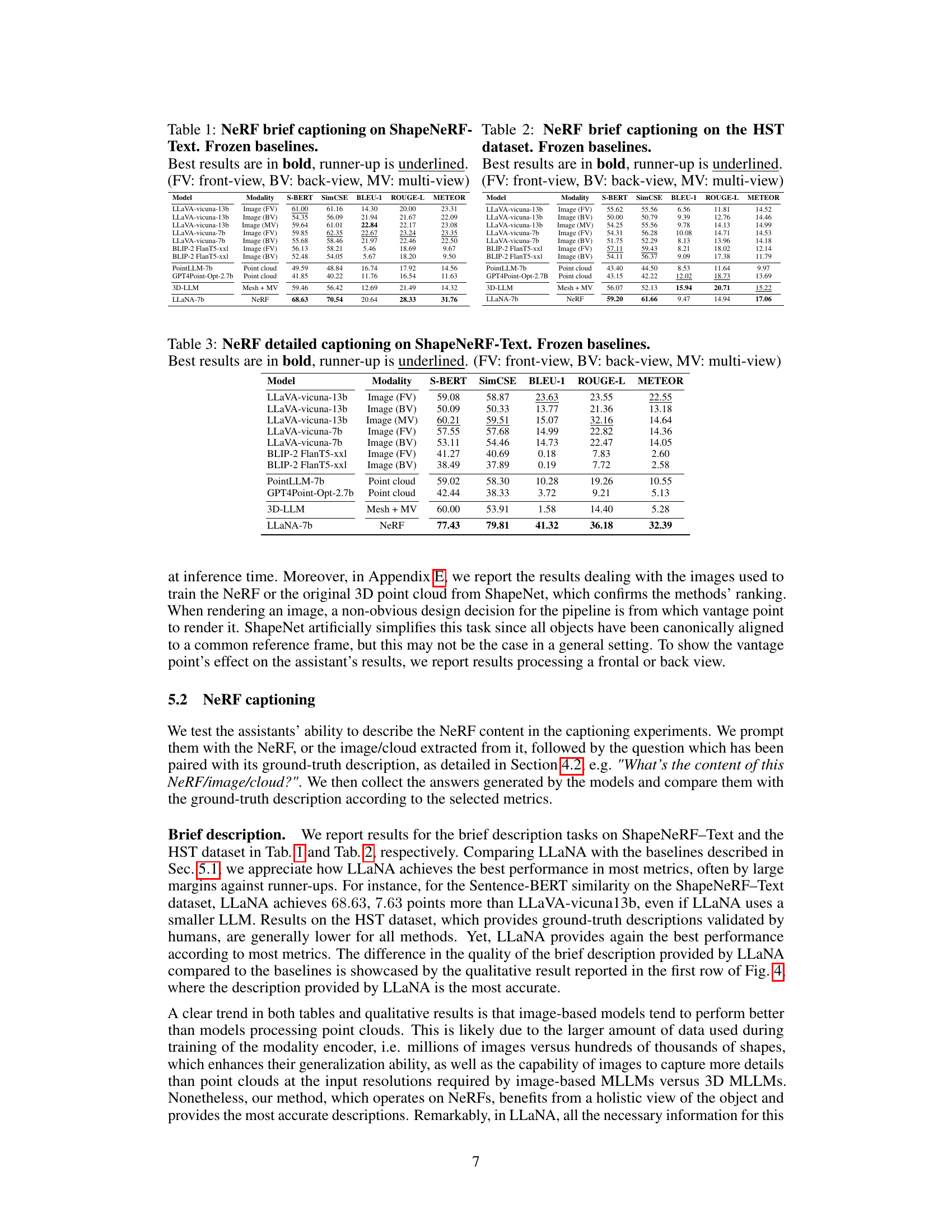
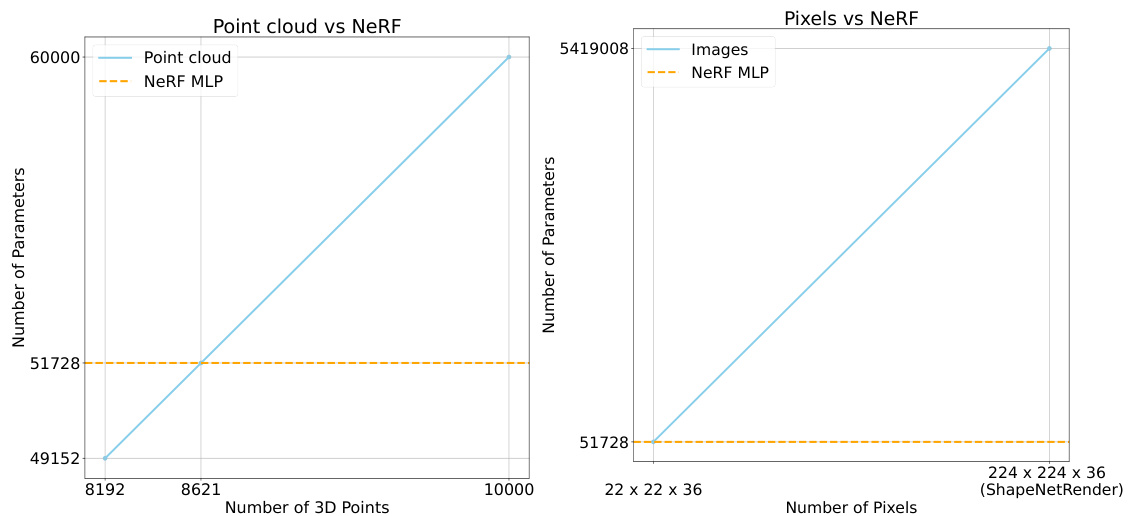
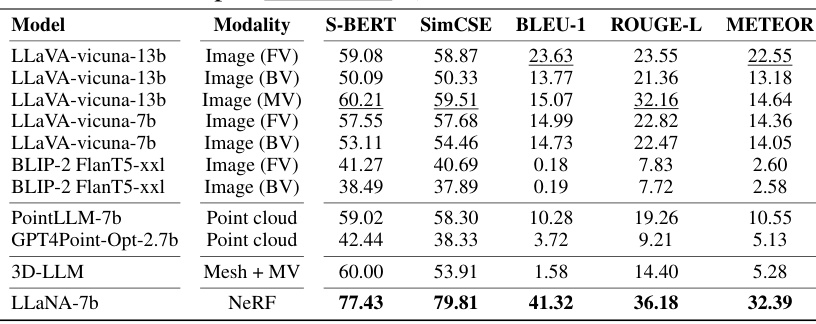
🔼 This table presents the results of the NeRF brief captioning task using several frozen baselines on the ShapeNeRF-Text dataset. The baselines used various modalities, including front-view images, back-view images, multi-view images, point clouds, and meshes. The table shows the performance of each model using S-BERT, SimCSE, BLEU-1, ROUGE-L, and METEOR metrics. The best result for each metric is highlighted in bold, and the second-best is underlined.
read the caption
Table 1: NeRF brief captioning on ShapeNeRF-Text. Frozen baselines. Best results are in bold, runner-up is underlined. (FV: front-view, BV: back-view, MV: multi-view)
In-depth insights#
NeRF-LLM Fusion#
NeRF-LLM fusion represents a significant advancement in multimodal AI, aiming to synergize the strengths of Neural Radiance Fields (NeRFs) for 3D scene representation and Large Language Models (LLMs) for natural language processing. This fusion allows LLMs to understand and reason about 3D scenes directly from their NeRF encodings, bypassing the need for intermediate 2D or 3D data representations. The key advantage lies in the direct processing of the NeRF’s MLP weights, enabling the extraction of rich, holistic information about the scene’s geometry and appearance, without information loss associated with rendering or 3D reconstruction. This innovative approach unlocks new possibilities, including tasks such as NeRF captioning, question-answering (Q&A), and zero-shot classification. However, challenges include the development of suitable datasets with comprehensive text annotations and the evaluation of model performance across various tasks. Further research is needed to explore the potential of this fusion in diverse applications and to address challenges related to the generalizability of NeRF-LLM models to real-world scenarios. The success of this fusion hinges on effective meta-encoders capable of bridging the semantic gap between NeRF weight representations and LLM embeddings, and the development of robust benchmarks to fully assess the capabilities of these novel systems.
NeRF Weight Encoder#
A NeRF Weight Encoder is a crucial component for processing Neural Radiance Fields (NeRFs) directly, bypassing the need for intermediate 2D or 3D representations. Instead of rendering images or extracting point clouds, this encoder processes the NeRF’s MLP weights, which implicitly encode the scene’s geometry and appearance. This approach is computationally efficient and avoids information loss associated with image rendering or downsampling inherent in 3D data extraction. The encoder’s output is a compact embedding which can then be effectively integrated with a multimodal large language model (MLLM), enabling new capabilities like NeRF captioning and Q&A. This direct processing of NeRF weights is a significant advance as it leverages the complete, continuous information encoded within the NeRF, resulting in improved performance and robustness compared to methods relying on discretized representations. The key innovation is the ability to map the high-dimensional weight space into a lower-dimensional embedding suitable for language tasks. Future work should explore improved encoder architectures to further enhance efficiency and scalability, as well as adapting this approach to more complex and advanced NeRF models.
ShapeNeRF-Text Dataset#
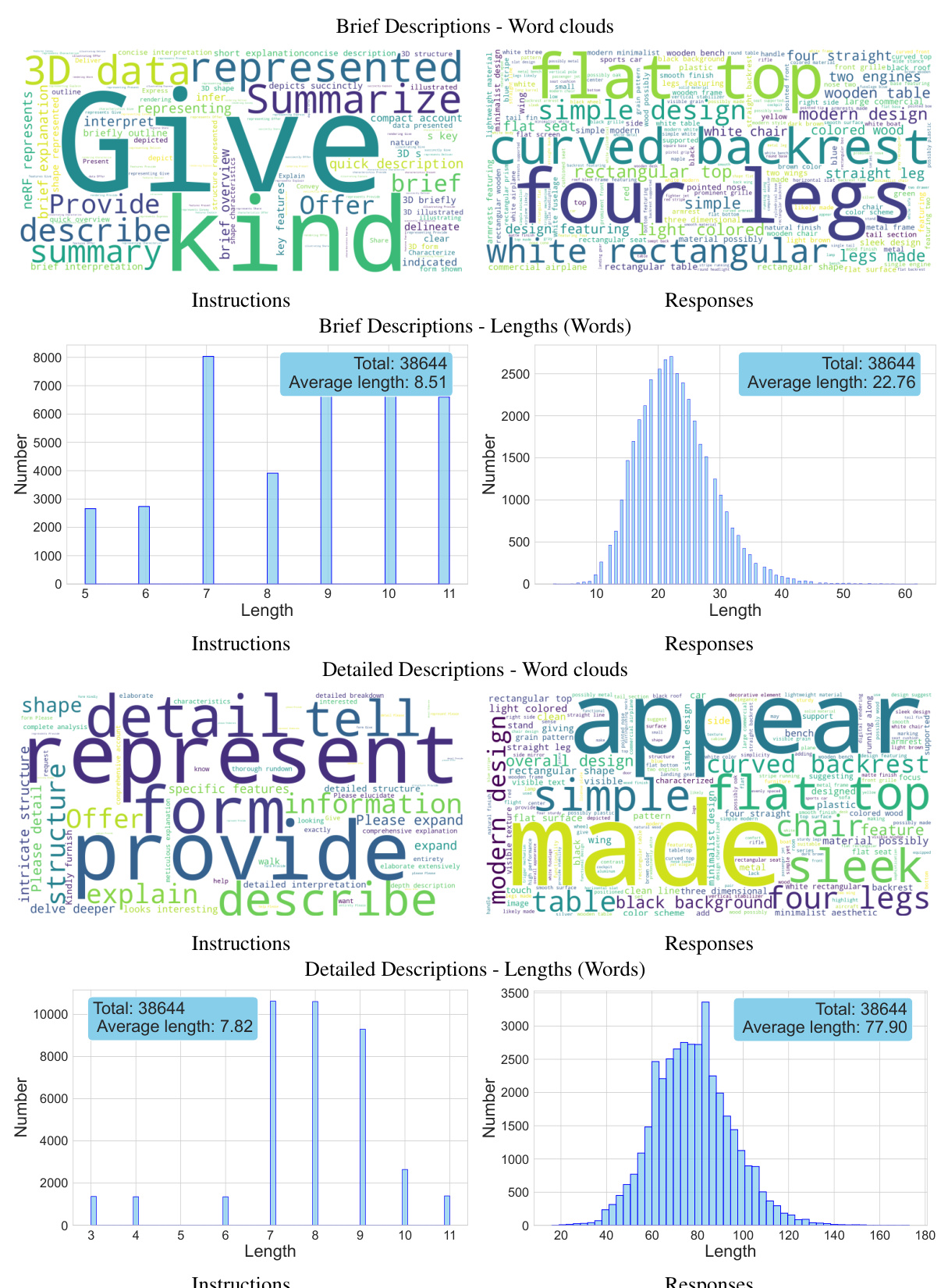
The creation of a robust and comprehensive dataset is crucial for evaluating the performance of AI models that process and understand 3D objects described using natural language. The proposed ShapeNeRF-Text dataset addresses this by pairing 40,000 NeRFs (Neural Radiance Fields) with text annotations obtained from ShapeNet, a collection of 3D models. This approach offers several key advantages. First, NeRFs provide a holistic and continuous representation of 3D objects, unlike discrete representations such as point clouds or images. Second, the dataset’s structure is well-defined, including brief and detailed descriptions, single and multi-round question-answering (Q&A) conversations, which allows for a multifaceted evaluation of different aspects of NeRF understanding. Third, the automated annotation process is described using Large Language Models (LLMs), providing a reproducible and scalable approach to data generation. However, future improvements could focus on expanding beyond ShapeNet’s objects to incorporate more diverse and realistic scenarios. Furthermore, carefully analyzing the limitations of the automated annotation process is necessary to ensure the dataset’s reliability and quality. Ultimately, ShapeNeRF-Text offers a significant step towards rigorous testing and development of advanced multimodal AI models capable of dealing with complex visual and textual information in 3D space.
LLaNA Limitations#
LLaNA, while innovative, faces several limitations. The reliance on the nf2vec meta-encoder, pre-trained solely on synthetic ShapeNet data, restricts its generalizability to real-world scenarios. Real-world NeRFs exhibit greater variability in object complexity and data quality, impacting LLaNA’s performance. The current architecture’s restriction to MLP-only NeRFs limits its applicability to advanced NeRF structures like InstantNGP. Furthermore, the evaluation is predominantly focused on object-centric NeRFs; scaling to scene-level NeRFs would require significant architectural adaptations and additional data. The automatic annotation framework, while efficient, may introduce biases in the generated text annotations, affecting the model’s learning and downstream performance. Finally, the study lacks detailed quantitative analysis of the model’s limitations under various data conditions or noise levels. Addressing these challenges would enhance LLaNA’s robustness and potential as a versatile NeRF assistant.
Future of NeRF-LLMs#
The fusion of Neural Radiance Fields (NeRFs) and Large Language Models (LLMs) is a nascent yet promising field. The future of NeRF-LLMs hinges on several key advancements. Firstly, improving NeRF representation efficiency is crucial; current NeRFs can be computationally expensive, limiting their scalability for real-world applications. Secondly, enhancing the robustness and generalizability of NeRFs is vital; current methods often struggle with complex scenes or unseen objects. A focus on developing techniques that enable NeRFs to handle diverse lighting conditions, occlusions and dynamic scenes would greatly expand their utility. Thirdly, the integration with LLMs needs to be further refined; current approaches largely rely on intermediate 2D/3D representations, potentially losing information. Direct integration of NeRFs within the LLM architecture promises more efficient and nuanced multimodal understanding. Finally, creating larger, higher-quality datasets of NeRFs annotated with rich textual descriptions will be instrumental in training more powerful and versatile NeRF-LLMs. These datasets should ideally capture diverse object classes, viewpoints, and lighting scenarios. The future likely involves more sophisticated architectures that elegantly combine the strengths of both NeRFs and LLMs, enabling applications in areas such as photorealistic scene generation, 3D modeling from text descriptions, and virtual and augmented reality experiences.
More visual insights#
More on figures

🔼 This figure illustrates the functionality of LLaNA, a novel multimodal large language model (MLLM) capable of directly processing Neural Radiance Field (NeRF) weights. It showcases how LLaNA performs three tasks: NeRF captioning (generating text descriptions of the objects represented in NeRFs), NeRF question answering (answering questions about the NeRFs), and zero-shot NeRF classification (classifying the object represented in a NeRF without prior training on that specific object). The image visually depicts the NeRF input, the processing steps within LLaNA, and the corresponding outputs for each task.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
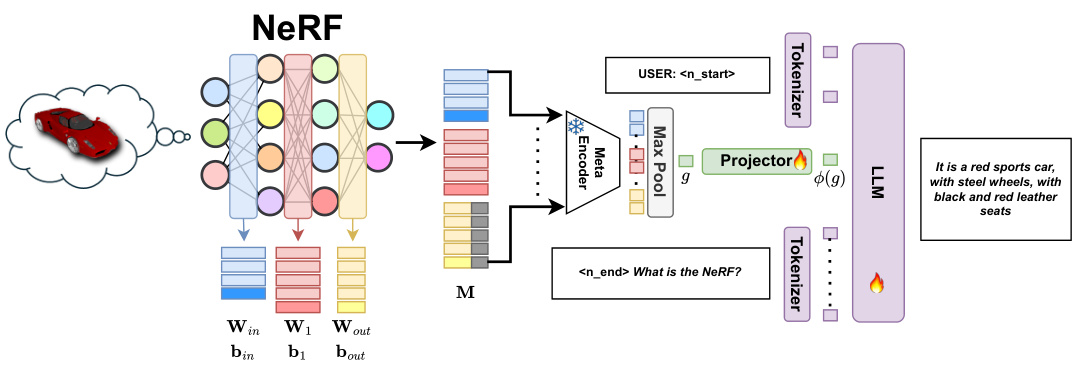
🔼 The figure illustrates the architecture of LLaNA, a multimodal large language model designed to process Neural Radiance Fields (NeRFs) directly. Instead of relying on intermediate representations like images or point clouds, LLaNA processes the NeRF’s MLP weights to extract information about the object. The model then uses this information to perform various tasks, including NeRF captioning (describing the object depicted in the NeRF), question answering (answering questions about the object), and zero-shot NeRF classification (classifying the object without prior training). The diagram shows the flow of information from the NeRF weights, through a meta-encoder and projector, to a large language model (LLM) that produces the final output.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.

🔼 The figure illustrates the LLaNA framework, which directly processes NeRF weights to perform various tasks. It shows how NeRF inputs are processed, and the various outputs generated including NeRF captions, answers to questions, and zero-shot classifications. This direct processing of NeRF weights is a key innovation of the LLaNA model, differentiating it from approaches that rely on intermediate image or point cloud representations.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
🔼 LLaNA is presented as the first multimodal large language model capable of understanding and processing neural radiance fields (NeRFs) directly from their weight representations. Instead of relying on intermediate 2D or 3D representations (like images or point clouds), LLaNA directly processes the NeRF’s MLP weights. This allows it to perform tasks such as NeRF captioning, question answering (Q&A), and zero-shot classification, all without the need for rendering images or creating 3D data structures. The figure visually depicts this process, showing how the NeRF weights are fed into LLaNA, which then produces outputs related to the caption, answer, and classification tasks.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
🔼 This figure shows a schematic of the LLaNA model, highlighting its ability to process NeRF weights directly and perform various tasks, including captioning, question answering, and zero-shot classification, without the need to render images or extract 3D point clouds. It showcases the novel approach of the research, processing the NeRF’s MLP weights rather than relying on traditional image or point cloud representations.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
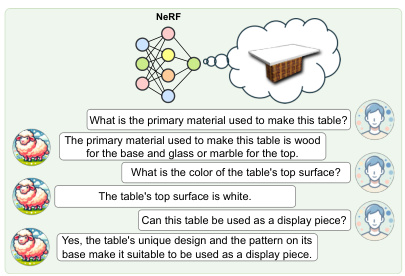
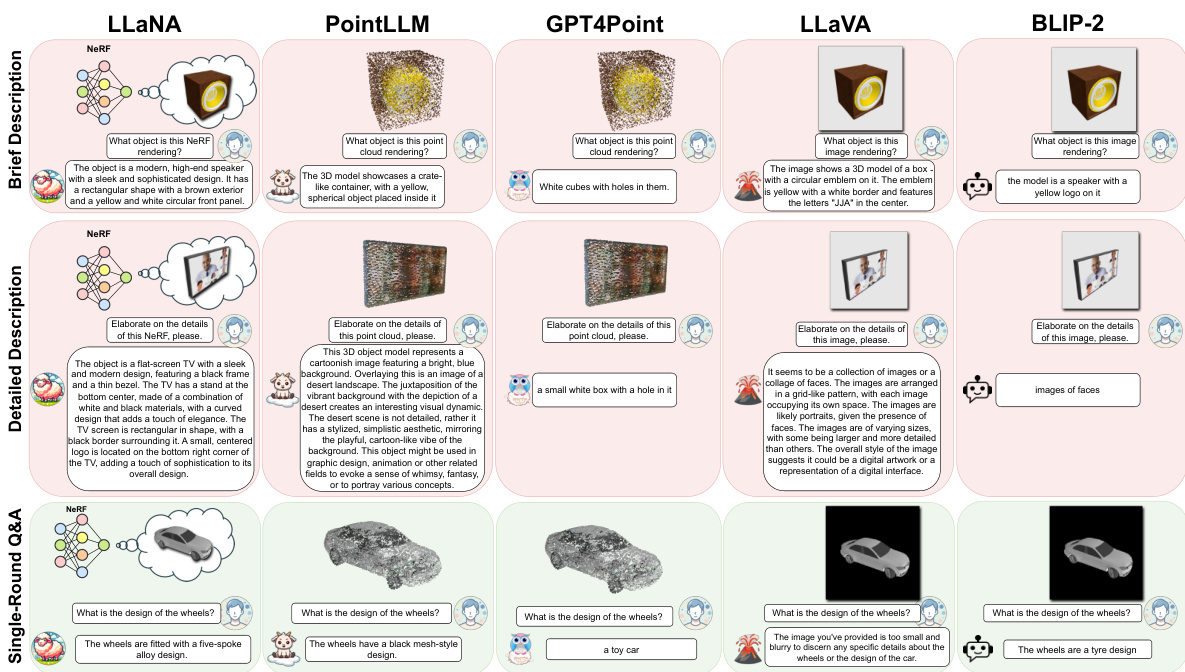
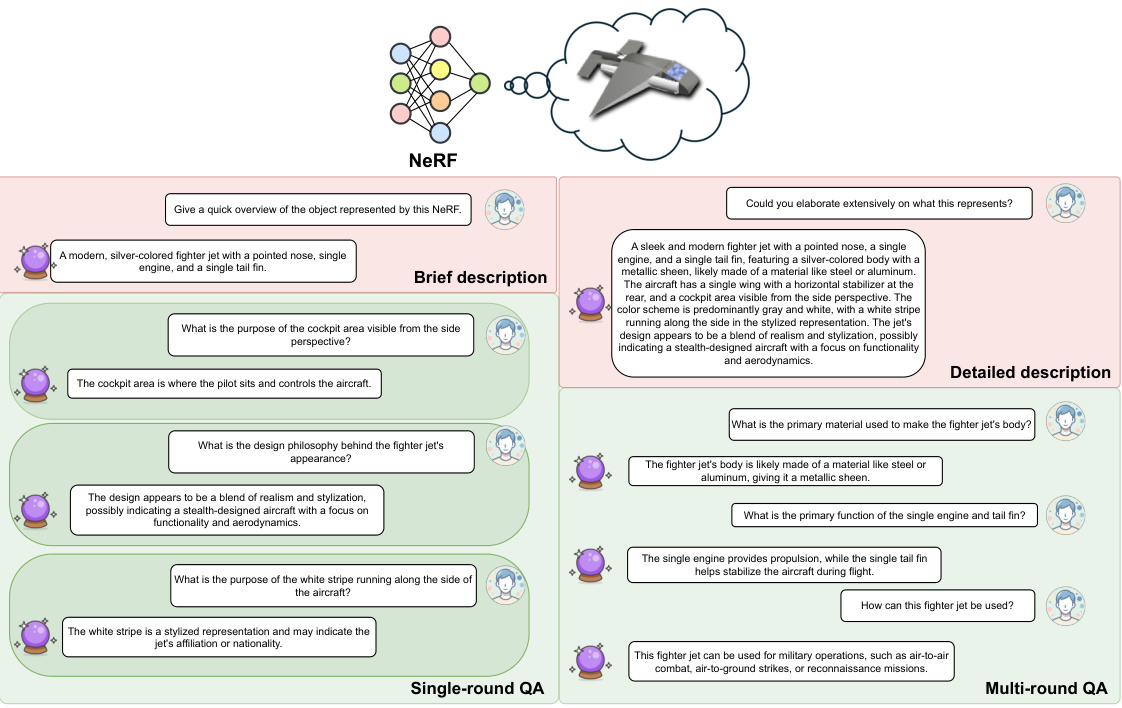
🔼 This figure shows an example of a multi-round question answering task using LLaNA. The input is a NeRF (Neural Radiance Field) representing a table. The user asks a series of questions about the table’s material, color, and suitability as a display piece. LLaNA successfully answers all questions, demonstrating its ability to process NeRFs and provide detailed, relevant responses.
read the caption
Figure 5: NeRF multi-round Q&A example.

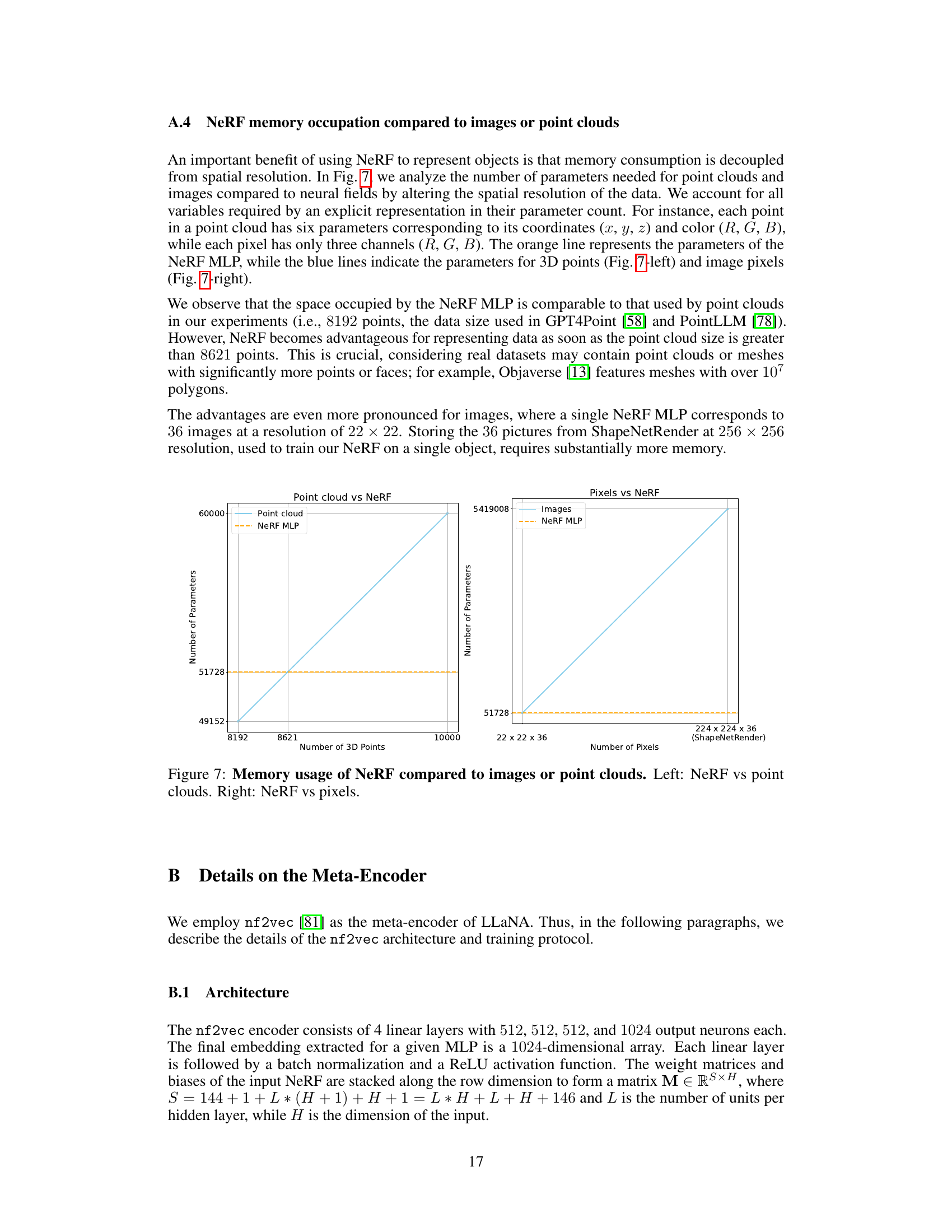
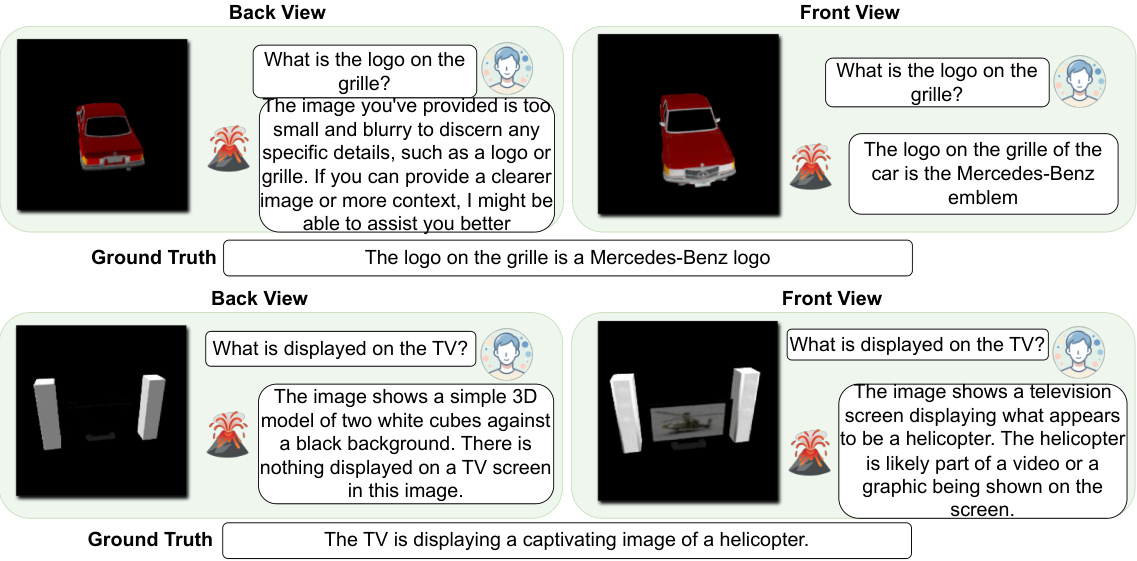
🔼 This figure shows a comparison of ground truth data and data extracted from a Neural Radiance Field (NeRF). The left side shows the ground truth front and back views of a 3D object (a yellow box with holes and speakers). The center displays the rendered front and back views of the object produced by the NeRF. The right displays the ground truth point cloud and a point cloud generated from the NeRF. The point cloud extraction process uses a marching cubes algorithm applied to the volumetric density field to create a mesh and then samples the RGB values from the NeRF for each point to get the color information.
read the caption
Figure 6: Example of data extracted from NeRF. From left to right: GT front view, rendered front view, GT back view, rendered back view, GT point cloud, extracted point cloud.
🔼 LLaNA is a multimodal large language model capable of understanding and processing Neural Radiance Fields (NeRFs). Unlike previous methods that extract 2D or 3D representations from NeRFs, LLaNA directly processes the NeRF weights to extract information about the objects without rendering images or creating 3D data structures. It performs tasks such as NeRF captioning, question answering, and zero-shot classification, demonstrating superior performance compared to methods relying on intermediate representations.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
🔼 This figure illustrates the LLaNA framework, highlighting its ability to directly process NeRF weights to perform various tasks like captioning, question answering (Q&A), and zero-shot classification of NeRFs. It showcases the novel approach of directly working with the NeRF’s MLP weights, eliminating the need to generate intermediate 2D or 3D representations.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
🔼 This figure shows a schematic of the LLaNA model, highlighting its ability to directly process NeRF weights to perform various tasks such as captioning, question answering, and zero-shot classification. It emphasizes that LLaNA doesn’t rely on intermediate representations like images or point clouds, making it more efficient and potentially more accurate. The diagram illustrates the flow of information: NeRF weights are processed directly, which are then combined with textual inputs within the LLM, resulting in outputs relevant to the specific task.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.

🔼 The figure illustrates the LLaNA framework, a multimodal large language model that directly processes the weights of a Neural Radiance Field (NeRF) to perform various tasks. Instead of relying on rendered images or 3D point clouds, LLaNA directly uses NeRF weights, making it more efficient and capable of performing new tasks like NeRF captioning, question answering (Q&A), and zero-shot classification. The diagram shows the input NeRF, the processing steps within the LLaNA framework, and the various output tasks it can perform.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
🔼 The figure illustrates the LLaNA framework, which directly processes the weights of a Neural Radiance Field (NeRF) to perform various tasks, including NeRF captioning, question answering, and zero-shot classification. This is in contrast to traditional methods that rely on rendering images or extracting 3D representations from the NeRF.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
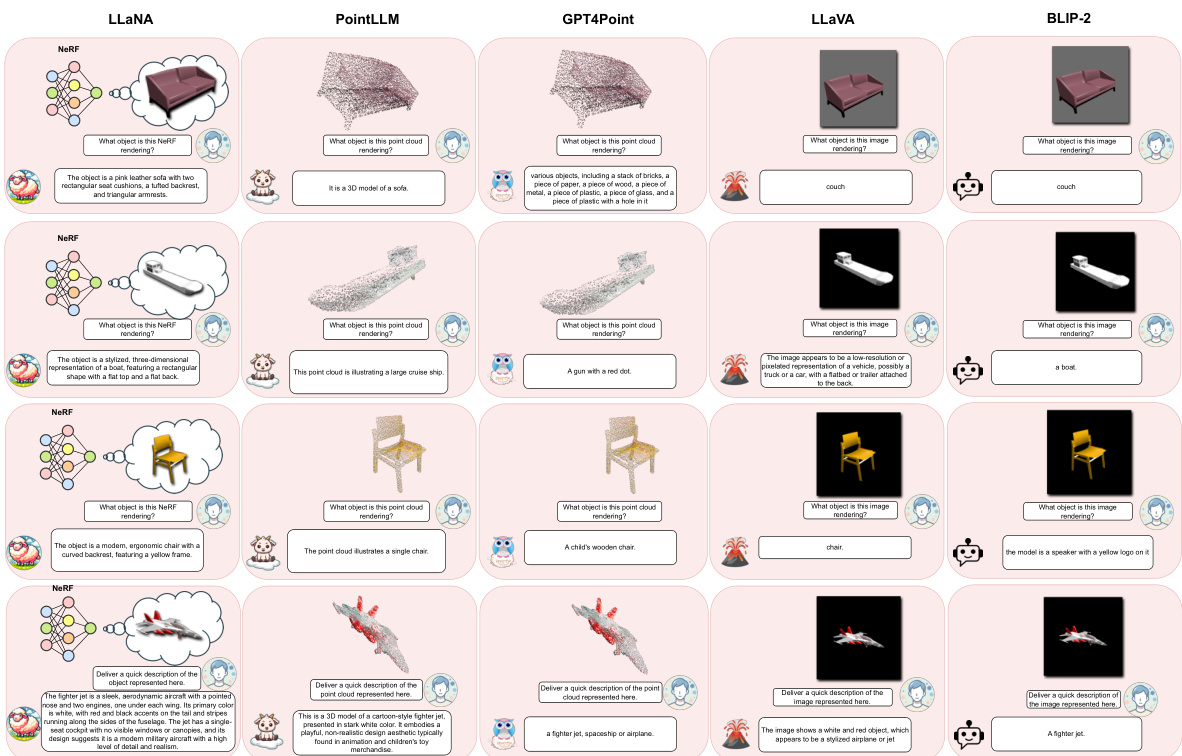
🔼 LLaNA is a multimodal large language model that directly processes the weights of a Neural Radiance Field (NeRF) to perform tasks such as NeRF captioning, question answering, and zero-shot classification. It bypasses the need to render images or create 3D point clouds, offering efficiency and detailed understanding of the NeRF’s content. The figure visually represents LLaNA’s process, showing the input NeRF, its processing by the model, and the output of different tasks.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.

🔼 LLaNA is a multimodal large language model (MLLM) that directly processes the weights of a Neural Radiance Field (NeRF) to perform various tasks like captioning the object represented by the NeRF, answering questions about it, and classifying the NeRF into categories without rendering images or creating 3D structures. This is a novel approach that leverages the inherent information within the NeRF’s MLP weights rather than relying on intermediate representations.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
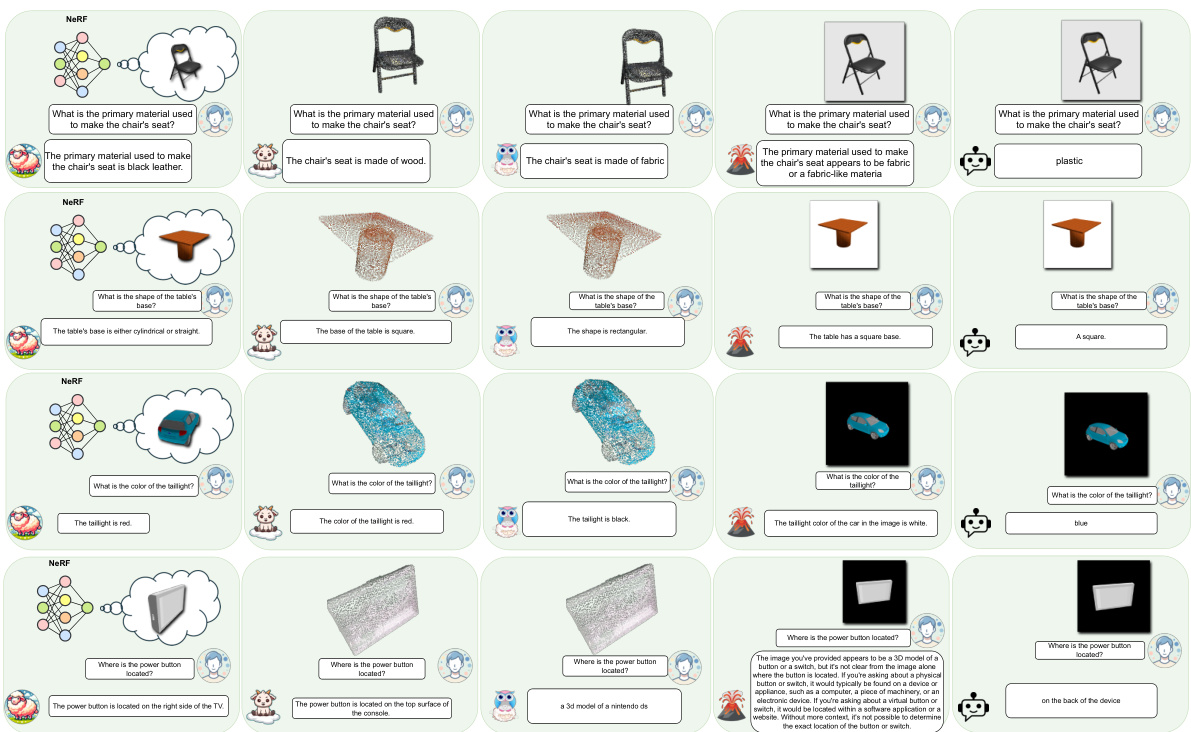
🔼 The figure shows a schematic of the LLaNA model, illustrating its ability to process NeRF weights directly to perform various tasks such as captioning, question answering, and zero-shot classification. It highlights the unique aspect of LLaNA in directly processing NeRF weights rather than relying on intermediate image or 3D representations.
read the caption
Figure 1: LLaNA. The first Multimodal Large Language Model that understands and reasons on an input NeRF. Our framework directly processes the NeRF weights and performs tasks such as captioning, Q&A, and zero-shot classification of NeRFs.
More on tables
🔼 This table presents the results of a detailed captioning task on the ShapeNeRF-Text dataset using various frozen baselines. It compares different modalities (front-view images, back-view images, multi-view images, point clouds, and NeRFs) for their ability to generate detailed captions of the objects represented in the NeRFs. The performance is evaluated using four metrics: Sentence-BERT similarity, SimCSE similarity, BLEU-1, ROUGE-L, and METEOR. The best performing model for each metric is highlighted in bold, and the second-best performing model is underlined. The table shows that processing the NeRF weights directly (LLaNA) significantly outperforms other methods.
read the caption
Table 3: NeRF detailed captioning on ShapeNeRF-Text. Frozen baselines. Best results are in bold, runner-up is underlined. (FV: front-view, BV: back-view, MV: multi-view)
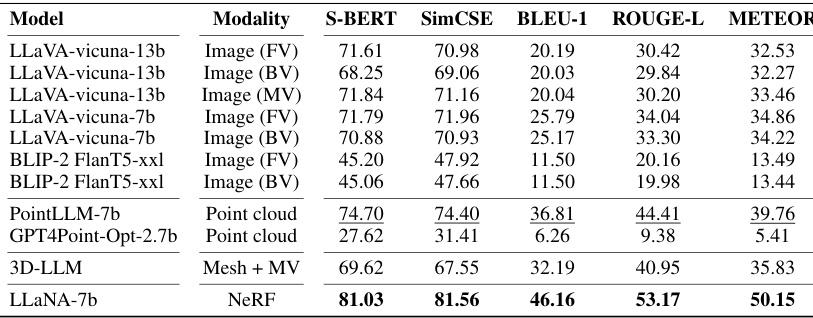
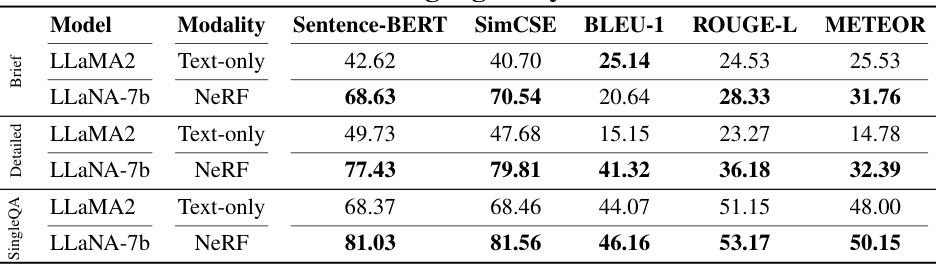
🔼 This table presents the results of single-round question answering task on the ShapeNeRF-Text dataset using various baselines with their modalities, including front-view, back-view, and multi-view images and point clouds. The performance is evaluated using S-BERT, SimCSE, BLEU-1, ROUGE-L, and METEOR metrics. LLaNA-7b using NeRF significantly outperforms other baselines across all metrics.
read the caption
Table 4: NeRF single-round Q&A on ShapeNeRF-Text. Frozen baselines. Best results are in bold, runner-up is underlined. (FV: front-view, BV: back-view, MV: multi-view)
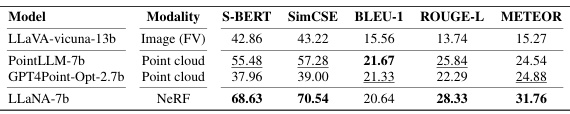
🔼 This table presents the performance of various models on the brief captioning task using the ShapeNeRF-Text dataset. The models have been fine-tuned on this dataset. The table shows the results achieved by different models using various modalities such as images, point clouds and directly processing NeRFs (LLaNA). The metrics used to evaluate the performance are S-BERT, SimCSE, BLEU-1, ROUGE-L, and METEOR. The best performance for each metric is highlighted in bold, and the second-best performance is underlined. The results are separated by modality (front-view images) to illustrate how the performance varies depending on the input representation used.
read the caption
Table 6: NeRF brief captioning on ShapeNeRF-Text. Trained baselines. Best results are in bold, runner-up is underlined. (FV: front-view)

🔼 This table presents the results of the NeRF brief captioning task on the HST dataset using several frozen baselines. The table compares different models and modalities (front-view images, back-view images, multi-view images, point clouds, and NeRFs) based on several metrics. The best results for each metric are highlighted in bold, while runner-up results are underlined.
read the caption
Table 2: NeRF brief captioning on the HST dataset. Frozen baselines. Best results are in bold, runner-up is underlined. (FV: front-view, BV: back-view, MV: multi-view)

🔼 This table presents the results of the detailed captioning task on the ShapeNeRF-Text dataset using trained baselines. The best performing model in terms of each metric (S-BERT, SimCSE, BLEU-1, ROUGE-L, METEOR) is shown in bold, and the second-best is underlined. The results are broken down by model and modality, with a focus on front-view (FV) images. This allows for comparison of different approaches to language modeling on NeRF data, particularly assessing the improvements gained through training on the specific dataset.
read the caption
Table 8: NeRF detailed captioning on ShapeNeRF-Text. Trained baselines. Best results are in bold, runner-up is underlined. (FV: front-view)

🔼 This table presents the results of single-round question answering tasks on the ShapeNeRF-Text dataset using trained baseline models. The models’ performance is evaluated using various metrics, including S-BERT, SimCSE, BLEU-1, ROUGE-L, and METEOR. The best performing model for each metric is shown in bold, and the second-best is underlined. The results are broken down by modality (image (front view), point cloud, and NeRF).
read the caption
Table 9: NeRF single-round Q&A on ShapeNeRF-Text. Trained baselines. Best results are in bold, runner-up is underlined. (FV: front-view)
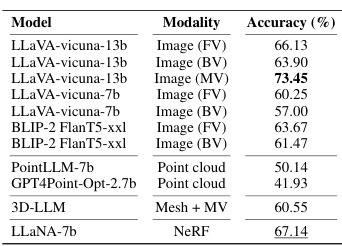
🔼 This table presents the results of a single-round question answering task on the ShapeNeRF-Text dataset, comparing the performance of various models (LLaVA, BLIP-2, PointLLM, GPT4Point, and LLaNA) using different input modalities (front-view images, back-view images, multi-view images, point clouds, and NeRFs). The metrics used are Sentence-BERT, SimCSE, BLEU-1, ROUGE-L, and METEOR. The best performing model for each metric is highlighted in bold, indicating LLaNA’s superior performance in NeRF understanding.
read the caption
Table 4: NeRF single-round Q&A on ShapeNeRF-Text. Frozen baselines. Best results are in bold, runner-up is underlined. (FV: front-view, BV: back-view, MV: multi-view)
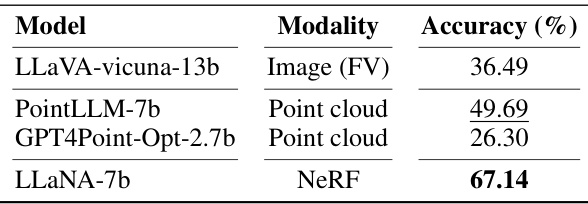
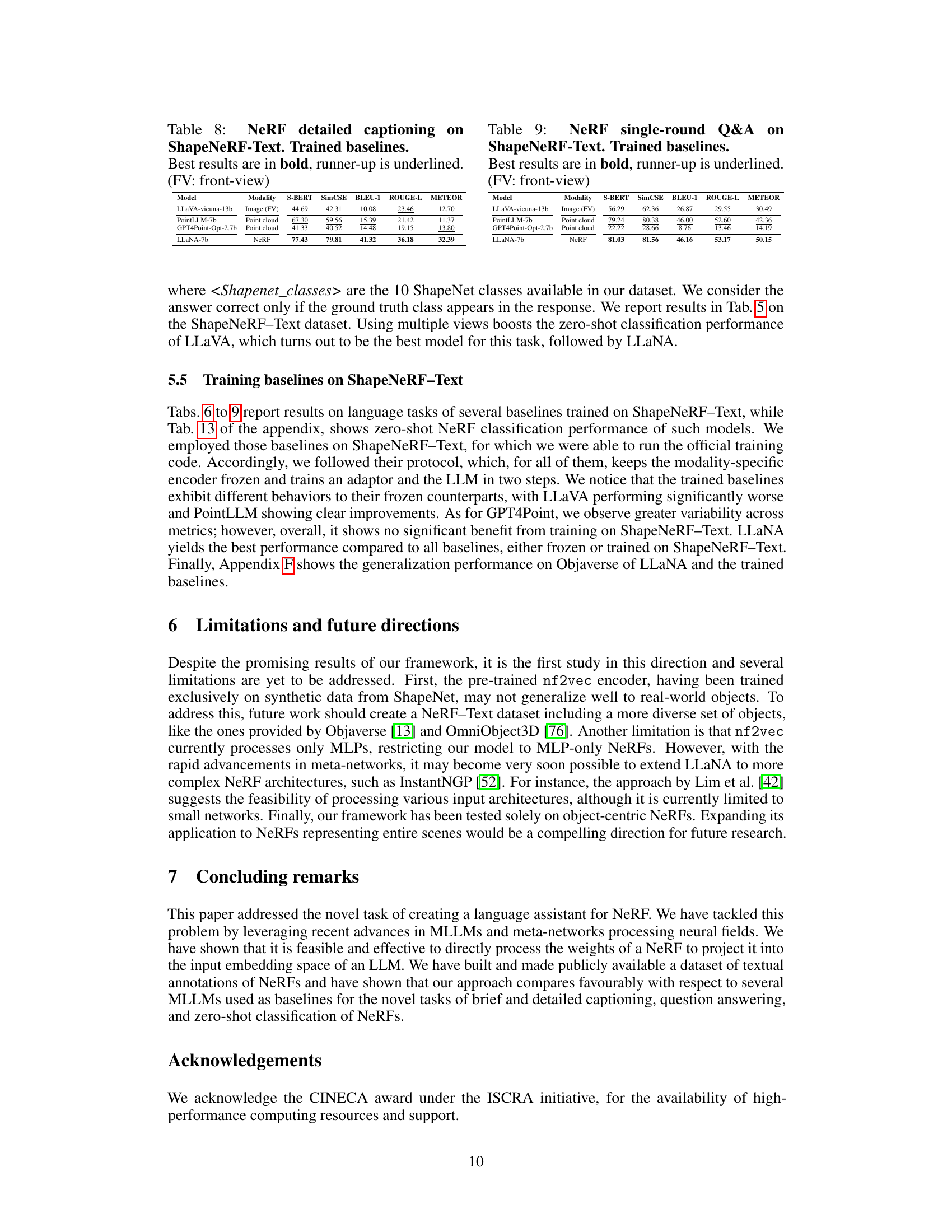
🔼 This table presents the results of a zero-shot NeRF classification task performed by several baselines which were trained on ShapeNeRF-Text dataset. The models were tested using the same evaluation protocol described in the paper, except that they were trained on ShapeNeRF-Text dataset instead of only being tested.
read the caption
Table 13: Zero-shot NeRF classification on ShapeNeRF-Text. Trained baselines. Best results are in bold, runner-up is underlined. (FV: front-view)

🔼 This table presents the results of the NeRF brief captioning task using different frozen baselines. It compares the performance of various models, including those using images (front, back, and multi-view) and point clouds, against the proposed LLaNA model which operates directly on the NeRF. The metrics used for evaluation are S-BERT similarity, SimCSE, BLEU-1, ROUGE-L, and METEOR.
read the caption
Table 14: NeRF brief captioning on ShapeNeRF-Text. Frozen baselines. Best results are in bold, runner-up is underlined. (FV: front-view, BV: back-view, MV: multi-view)

🔼 This table presents the results of different baselines for the NeRF brief captioning task on the ShapeNeRF-Text dataset. The baselines are compared using various metrics including Sentence-BERT, SimCSE, BLEU-1, ROUGE-L, and METEOR. The results are categorized by the modality used (front-view image, back-view image, multi-view image, point cloud, and NeRF) and the model used. LLaNA-7b shows superior performance using NeRF modality compared to image-based and point cloud-based baselines.
read the caption
Table 1: NeRF brief captioning on ShapeNeRF-Text. Frozen baselines. Best results are in bold, runner-up is underlined. (FV: front-view, BV: back-view, MV: multi-view)

🔼 This table presents the results of single-round question answering tasks using different input modalities on the ShapeNeRF-Text dataset. It compares the performance of various models (LLaVA-vicuna-13b, LLaVA-vicuna-7b, BLIP-2 FlanT5-xxl, PointLLM-7b, GPT4Point-Opt-2.7b, 3D-LLM, and LLaNA-7b) using different input types (front-view images, back-view images, multi-view images, point clouds, and NeRFs). The evaluation metrics used are Sentence-BERT similarity, SimCSE similarity, BLEU-1, ROUGE-L, and METEOR. The table showcases LLaNA’s superior performance across all metrics when compared to baselines which use images, point clouds, or meshes derived from the NeRF. It highlights the advantage of processing NeRF weights directly instead of relying on intermediate 2D or 3D representations.
read the caption
Table 4: NeRF single-round Q&A on ShapeNeRF-Text. Frozen baselines. Best results are in bold, runner-up is underlined. (FV: front-view, BV: back-view, MV: multi-view)
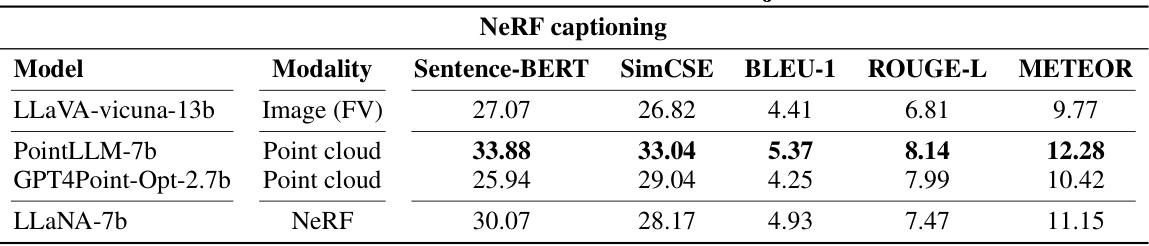
🔼 This table presents the results of an experiment conducted to evaluate the generalization capabilities of the proposed model, LLaNA, and several baseline models. The models were tested on the Objaverse dataset, which contains objects not seen during the training phase. The table shows the performance of each model in terms of various metrics: Sentence-BERT, SimCSE, BLEU-1, ROUGE-L, and METEOR. These metrics are used to assess the quality of captions generated by the models. The modalities used by the models are also indicated: Image (front view), Point cloud, and NeRF. This experiment assesses how well the models trained on one dataset can generalize to a new and different dataset.
read the caption
Table 17: Generalization results on Objaverse. NeRF captioning
Full paper#