TL;DR#
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with multi-channel imaging (MCI) data. It introduces DiChaViT, a novel approach that significantly improves the accuracy and robustness of vision transformer models in MCI. This advancement is especially important in diverse applications like satellite imagery and cell microscopy where channel configurations vary greatly. The proposed techniques can inspire new architectural designs for more adaptive and effective MCI models, opening exciting avenues for future research.
Visual Insights#

🔼 This figure compares ChannelViT and DiChaViT’s performance on the Human Protein Atlas (HPA) dataset within the CHAMMI benchmark. The left sub-figure (a) shows mutual information between channel tokens, indicating redundancy in ChannelViT and diversity in DiChaViT. The right sub-figure (b) displays aggregated attention scores, demonstrating that ChannelViT focuses on specific channels, while DiChaViT distributes attention more evenly.
read the caption
Figure 1: Comparison of the redundant information learned by different models on the HPA dataset in CHAMMI [14]. (a) Measures the mutual information between the channel tokens, which captured the configuration of channels in an image. Note we gray out the diagonal for better visualization. We find ChannelViT tokens have high mutual information, which suggests significant redundancy exists across channels [34, 35]. In contrast, DiChaViT has little mutual information as each channel is encouraged to learn different features. (b) We compute attention scores of the [CLS] token to the patch tokens in the penultimate layers and aggregate them by channel. ChannelViT (top) relies on certain channels (e.g., microtubules and nucleus) to make predictions and less on other channels (e.g., protein and er). In contrast, DiChaViT demonstrates more evenly distributed attention scores across channels, suggesting that each channel contributes more to the model's predictions.

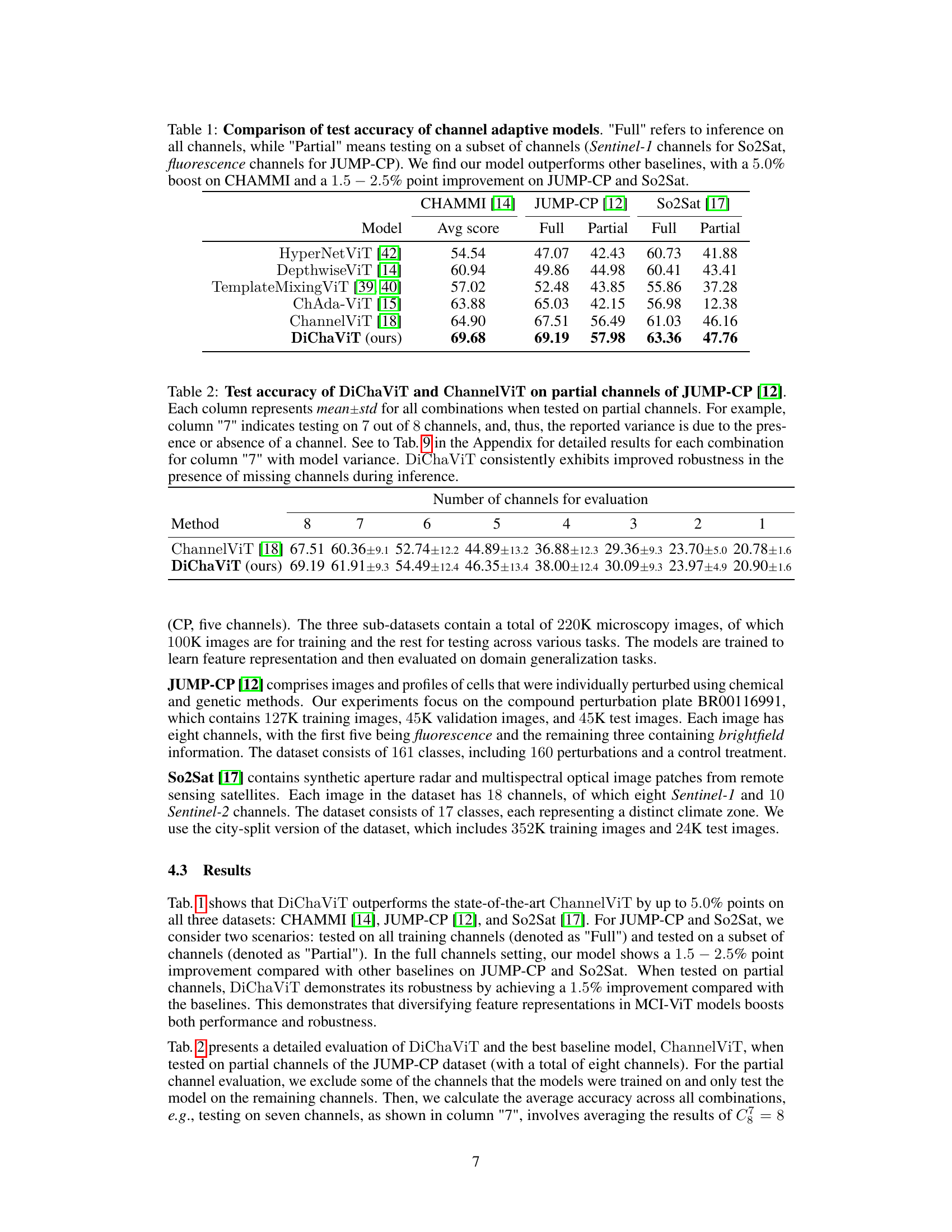
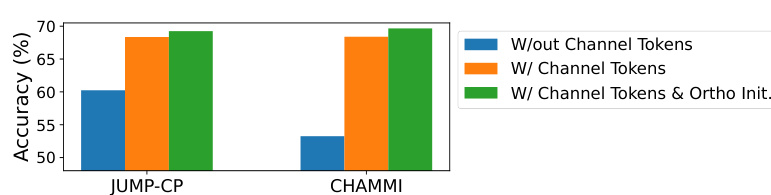
🔼 This table compares the testing accuracy of various channel adaptive models, including the proposed DiChaViT model and several baselines. The accuracy is measured under two conditions: using all available channels (‘Full’) and a subset of channels (‘Partial’). The ‘Partial’ results simulate real-world scenarios where some channels may be missing or unavailable. DiChaViT demonstrates superior performance across all datasets, especially showing a significant 5.0% improvement on the CHAMMI dataset. On the JUMP-CP and So2Sat datasets, DiChaViT achieves a 1.5% to 2.5% improvement in accuracy.
read the caption
Table 1: Comparison of test accuracy of channel adaptive models. 'Full' refers to inference on all channels, while 'Partial' means testing on a subset of channels (Sentinel-1 channels for So2Sat, fluorescence channels for JUMP-CP). We find our model outperforms other baselines, with a 5.0% boost on CHAMMI and a 1.5–2.5% point improvement on JUMP-CP and So2Sat.
In-depth insights#
MCI-ViT Challenges#
Multi-Channel Imaging (MCI) presents significant challenges for Vision Transformers (ViTs). A core issue is the variability in channel configurations across different MCI datasets. Traditional ViTs assume a fixed input channel structure (e.g., RGB), making them ill-suited for MCI’s heterogeneous nature where the number and types of channels vary. This necessitates models capable of handling diverse channel combinations at test time, requiring robust generalization beyond the training data’s specific channel sets. Another challenge lies in effectively encoding the unique properties of each channel type. Simply concatenating channel information can lead to redundant feature learning and inefficient representation. Effective MCI-ViTs must learn distinct features from each channel, avoiding unnecessary feature repetition and maximizing information extraction. Furthermore, designing robust training strategies is crucial, considering the potential for missing or noisy channels, which requires mechanisms to prevent overfitting while maintaining adequate model performance. Addressing these challenges is key to developing truly effective MCI-ViT architectures.
DiChaViT Approach#
The DiChaViT approach tackles the challenge of handling multi-channel imaging (MCI) data in vision transformers by focusing on feature diversity. Unlike methods that treat all channels equally, DiChaViT introduces three key components: Diverse Channel Sampling (DCS), which selects dissimilar channels for training, promoting more unique feature learning; Channel Diversification Loss (CDL), a regularization technique that encourages channel tokens to be distinct; and Token Diversification Loss (TDL), which promotes the learning of diverse features within each image patch. This multifaceted approach combats redundancy inherent in traditional MCI methods, leading to improved performance and robustness across different channel configurations. The effectiveness of DiChaViT’s design is demonstrated through experiments on diverse MCI datasets, showing significant performance gains over state-of-the-art models, particularly in scenarios with missing channels. This method shows promise in robustly handling the variability in channel configurations found in real-world MCI applications.
Diverse Sampling#
Diverse sampling, in the context of multi-channel imaging (MCI) and vision transformers, is a crucial technique for enhancing model robustness and feature diversity. The core idea is to move beyond uniform random sampling of channels during training, which can lead to redundancy and hinder the learning of unique information from each channel type. Instead, diverse sampling strategies aim to select channel combinations that are more distinct, thus encouraging the model to learn a wider range of features. This is especially beneficial for MCI, where the number and types of channels can vary substantially across datasets, and robustness to changes in channel configuration is paramount. Effective diverse sampling methods often incorporate measures of channel similarity or dissimilarity (e.g., using mutual information or other distance metrics between channel feature representations). The selection of channels may be deterministic or probabilistic, with the best choice likely depending on the dataset characteristics and model architecture. Successfully implementing diverse sampling often requires balancing exploration (seeking novel channel combinations) and exploitation (focusing on previously successful combinations) for optimal performance. Furthermore, the integration of other techniques, such as regularization, may further improve the effectiveness of diverse sampling.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, removing components like the Channel Diversification Loss (CDL), Token Diversification Loss (TDL), or Diverse Channel Sampling (DCS) allows researchers to understand how each element affects the model’s overall performance. The results of ablation studies are crucial for demonstrating the effectiveness of each component and validating the design choices of the model. Removing any single component significantly reduced performance, especially in scenarios with missing channels, proving their necessity. This highlights the synergy between these components; they work together to improve feature diversity, robustness, and accuracy. The study’s findings are valuable because they go beyond simply reporting overall performance; they provide detailed insights into the mechanisms underlying the model’s success, strengthening the paper’s claims and overall contribution.
Future Works#
The paper’s core contribution is DiChaViT, a novel approach to enhance feature diversity and robustness in multi-channel vision transformers (ViTs). Future work could naturally extend DiChaViT’s capabilities to handle unseen channels during inference. This is a significant challenge as it requires establishing meaningful connections between existing and new channels, which is particularly difficult in the presence of domain shifts. Another important direction is to investigate more sophisticated channel sampling strategies than the Diverse Channel Sampling (DCS) currently employed. While DCS is effective, exploring alternative methods to select diverse channel sets could lead to improved performance. A third area ripe for exploration is extending DiChaViT to other vision architectures, going beyond the ViT backbone to evaluate its adaptability and potential benefits in various model settings. Finally, a deeper investigation into the interplay between the different loss functions (CDL and TDL) would help optimize DiChaViT’s performance and provide a better understanding of the individual contributions of each component. These future directions together would strengthen and broaden DiChaViT’s impact on the field.
More visual insights#
More on figures

🔼 This figure compares the information learned by ChannelViT and DiChaViT models. (a) shows that ChannelViT learns redundant information across channels while DiChaViT learns more diverse features. (b) illustrates that ChannelViT focuses attention on specific channels for prediction whereas DiChaViT distributes attention evenly across channels.
read the caption
Figure 1: Comparison of the redundant information learned by different models on the HPA dataset in CHAMMI [14]). (a) Measures the mutual information between the channel tokens, which captured the configuration of channels in an image. Note we gray out the diagonal for better visualization. We find ChannelViT tokens have high mutual information, which suggests significant redundancy exists across channels [34, 35]. In contrast, DiChaViT has little mutual information as each channel is encouraged to learn different features. (b) We compute attention scores of the [CLS] token to the patch tokens in the penultimate layers and aggregate them by channel. ChannelViT (top) relies on certain channels (e.g., microtubules and nucleus) to make predictions and less on other channels (e.g., protein and er). In contrast, DiChaViT demonstrates more evenly distributed attention scores across channels, suggesting that each channel contributes more to the model's predictions.
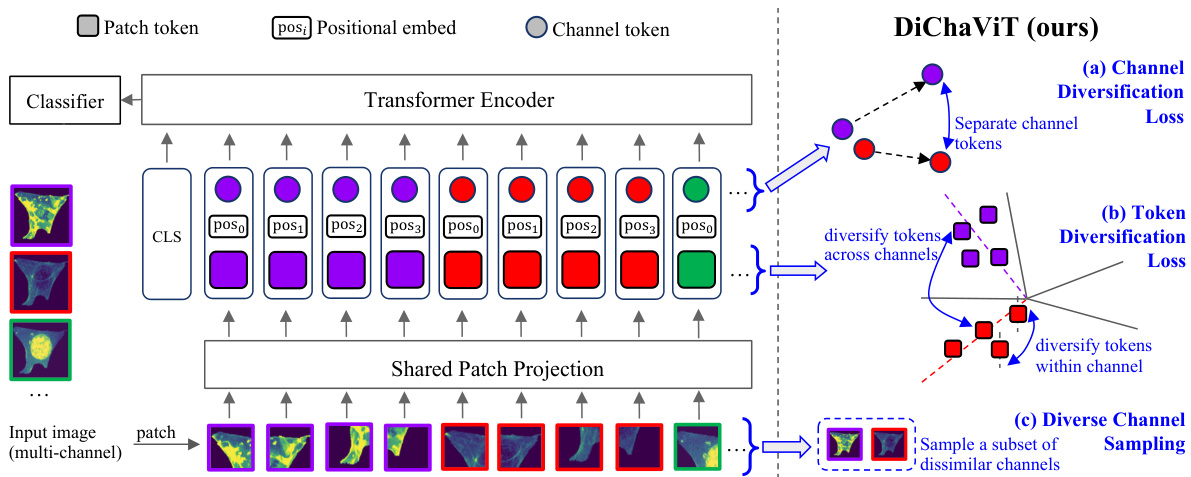
🔼 This figure illustrates the architecture of DiChaViT, a vision transformer designed for multi-channel imaging. It shows three main components: (a) Channel Diversification Loss (CDL) to diversify channel tokens, (b) Token Diversification Loss (TDL) to diversify patch tokens within each channel, and (c) Diverse Channel Sampling (DCS) to select a subset of dissimilar channels during training. The figure highlights how these components work together to improve feature diversity and robustness in multi-channel vision transformers.
read the caption
Figure 2: An overview of DiChaViT. We introduce two regularization methods on the features and a channel sampling strategy to promote diversity in feature representations. We apply (a) Channel Diversification Loss (CDL) (Sec. 3.1) for channel tokens (), and (b) Token Diversification Loss (TDL) (Sec. 3.2) on the patch tokens (). Additionally, we (c) sample a subset of dissimilar channels using Diverse Channel Sampling (DCS) (Sec. 3.3).
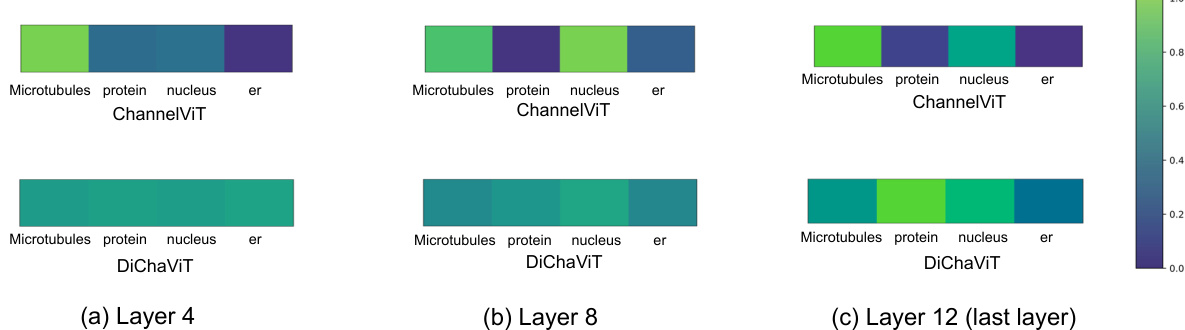
🔼 This figure compares the redundant information learned by ChannelViT and DiChaViT models on the Human Protein Atlas (HPA) dataset. Part (a) shows the mutual information between channel tokens, revealing high redundancy in ChannelViT and low redundancy in DiChaViT, indicating that DiChaViT encourages each channel to learn distinct features. Part (b) visualizes aggregated patch token attention scores by channel, demonstrating that ChannelViT focuses on specific channels for predictions while DiChaViT distributes attention more evenly across channels.
read the caption
Figure 1: Comparison of the redundant information learned by different models on the HPA dataset in CHAMMI [14]. (a) Measures the mutual information between the channel tokens, which captured the configuration of channels in an image. Note we gray out the diagonal for better visualization. We find ChannelViT tokens have high mutual information, which suggests significant redundancy exists across channels [34, 35]. In contrast, DiChaViT has little mutual information as each channel is encouraged to learn different features. (b) We compute attention scores of the [CLS] token to the patch tokens in the penultimate layers and aggregate them by channel. ChannelViT (top) relies on certain channels (e.g., microtubules and nucleus) to make predictions and less on other channels (e.g., protein and er). In contrast, DiChaViT demonstrates more evenly distributed attention scores across channels, suggesting that each channel contributes more to the model's predictions.

🔼 This figure compares ChannelViT and DiChaViT’s performance on the Human Protein Atlas (HPA) dataset from CHAMMI. Panel (a) shows mutual information between channel tokens, revealing redundancy in ChannelViT but diversity in DiChaViT. Panel (b) illustrates attention scores, demonstrating that DiChaViT distributes attention more evenly across channels than ChannelViT.
read the caption
Figure 1: Comparison of the redundant information learned by different models on the HPA dataset in CHAMMI [14]. (a) Measures the mutual information between the channel tokens, which captured the configuration of channels in an image. Note we gray out the diagonal for better visualization. We find ChannelViT tokens have high mutual information, which suggests significant redundancy exists across channels [34, 35]. In contrast, DiChaViT has little mutual information as each channel is encouraged to learn different features. (b) We compute attention scores of the [CLS] token to the patch tokens in the penultimate layers and aggregate them by channel. ChannelViT (top) relies on certain channels (e.g., microtubules and nucleus) to make predictions and less on other channels (e.g., protein and er). In contrast, DiChaViT demonstrates more evenly distributed attention scores across channels, suggesting that each channel contributes more to the model's predictions.

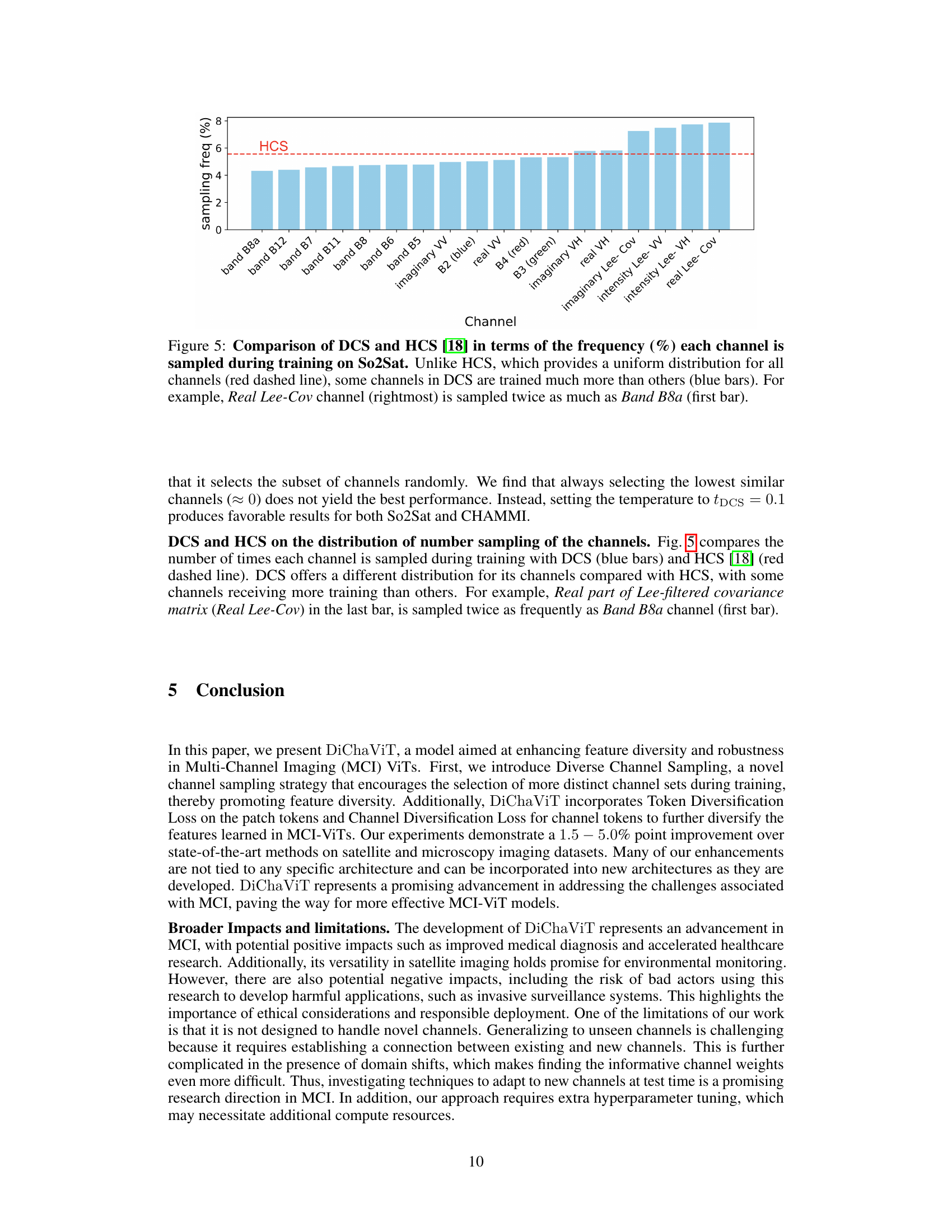
🔼 This figure compares the channel sampling frequencies of Diverse Channel Sampling (DCS) and Hierarchical Channel Sampling (HCS) on the So2Sat dataset. DCS, unlike HCS which samples channels uniformly, shows a non-uniform distribution, with some channels being sampled significantly more often than others. This highlights the inherent difference in the training strategies employed by the two methods.
read the caption
Figure 5: Comparison of DCS and HCS [18] in terms of the frequency (%) each channel is sampled during training on So2Sat. Unlike HCS, which provides a uniform distribution for all channels (red dashed line), some channels in DCS are trained much more than others (blue bars). For example, Real Lee-Cov channel (rightmost) is sampled twice as much as Band B8a (first bar).

🔼 This figure compares the performance of ChannelViT and DiChaViT on the Human Protein Atlas (HPA) dataset from the CHAMMI benchmark. Panel (a) shows the mutual information between channel tokens, revealing high redundancy in ChannelViT and low redundancy in DiChaViT, indicating DiChaViT learns more distinct features per channel. Panel (b) visualizes aggregated attention scores from the [CLS] token to patch tokens, demonstrating that ChannelViT relies heavily on specific channels while DiChaViT distributes attention more evenly across channels. This highlights DiChaViT’s ability to leverage diverse information from all channels.
read the caption
Figure 1: Comparison of the redundant information learned by different models on the HPA dataset in CHAMMI [14]. (a) Measures the mutual information between the channel tokens, which captured the configuration of channels in an image. Note we gray out the diagonal for better visualization. We find ChannelViT tokens have high mutual information, which suggests significant redundancy exists across channels [34, 35]. In contrast, DiChaViT has little mutual information as each channel is encouraged to learn different features. (b) We compute attention scores of the [CLS] token to the patch tokens in the penultimate layers and aggregate them by channel. ChannelViT (top) relies on certain channels (e.g., microtubules and nucleus) to make predictions and less on other channels (e.g., protein and er). In contrast, DiChaViT demonstrates more evenly distributed attention scores across channels, suggesting that each channel contributes more to the model's predictions.
🔼 This figure compares the redundant information learned by ChannelViT and DiChaViT models on the Human Protein Atlas (HPA) dataset. Panel (a) shows the mutual information between channel tokens, revealing high redundancy in ChannelViT but low redundancy in DiChaViT, indicating that DiChaViT effectively learns diverse features from each channel. Panel (b) displays the aggregated patch token attention scores by channel, demonstrating that ChannelViT focuses on specific channels while DiChaViT distributes attention more evenly, suggesting improved feature utilization.
read the caption
Figure 1: Comparison of the redundant information learned by different models on the HPA dataset in CHAMMI [14]). (a) Measures the mutual information between the channel tokens, which captured the configuration of channels in an image. Note we gray out the diagonal for better visualization. We find ChannelViT tokens have high mutual information, which suggests significant redundancy exists across channels [34, 35]. In contrast, DiChaViT has little mutual information as each channel is encouraged to learn different features. (b) We compute attention scores of the [CLS] token to the patch tokens in the penultimate layers and aggregate them by channel. ChannelViT (top) relies on certain channels (e.g., microtubules and nucleus) to make predictions and less on other channels (e.g., protein and er). In contrast, DiChaViT demonstrates more evenly distributed attention scores across channels, suggesting that each channel contributes more to the model's predictions.
More on tables

🔼 This table compares the performance of different channel-adaptive vision transformer models on three multi-channel image datasets: CHAMMI, JUMP-CP, and So2Sat. The models are tested under two conditions: using all available channels (‘Full’) and a subset of channels (‘Partial’). The results show that the proposed DiChaViT model outperforms the state-of-the-art, achieving significant gains in accuracy, particularly when only a subset of channels are used.
read the caption
Table 1: Comparison of test accuracy of channel adaptive models. 'Full' refers to inference on all channels, while 'Partial' means testing on a subset of channels (Sentinel-1 channels for So2Sat, fluorescence channels for JUMP-CP). We find our model outperforms other baselines, with a 5.0% boost on CHAMMI and a 1.5–2.5% point improvement on JUMP-CP and So2Sat.

🔼 This table compares the performance of DiChaViT and ChannelViT when tested on a subset of channels from the JUMP-CP dataset. It shows the mean and standard deviation of accuracy for various combinations of channels and highlights DiChaViT’s improved robustness to missing channels.
read the caption
Table 2: Test accuracy of DiChaViT and ChannelViT on partial channels of JUMP-CP [12]. Each column represents mean±std for all combinations when tested on partial channels. For example, column '7' indicates testing on 7 out of 8 channels, and, thus, the reported variance is due to the presence or absence of a channel. See to Tab. 9 in the Appendix for detailed results for each combination for column '7' with model variance. DiChaViT consistently exhibits improved robustness in the presence of missing channels during inference.
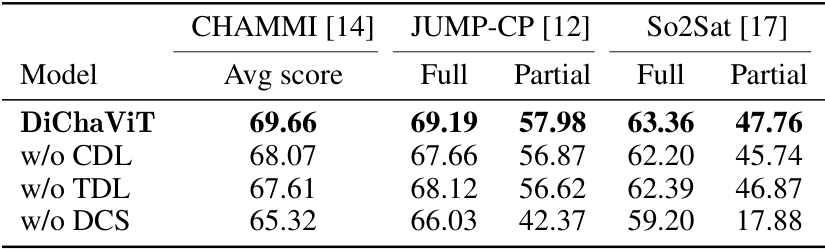
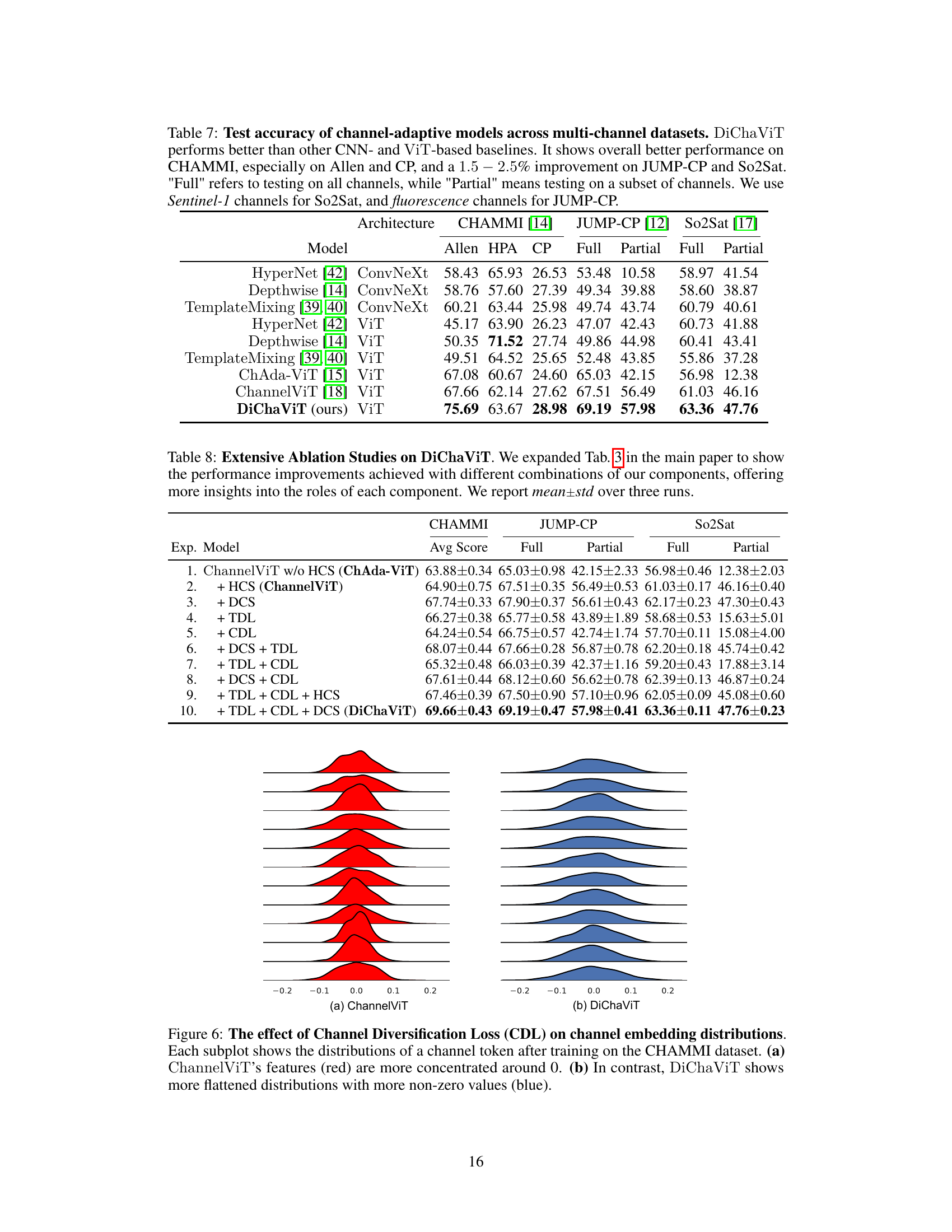
🔼 This table presents ablation study results for the DiChaViT model. It shows the impact of removing each component (CDL, TDL, DCS) on the model’s performance across three datasets (CHAMMI, JUMP-CP, So2Sat) under both full and partial channel settings. The results demonstrate the importance of each component for achieving optimal performance, particularly the DCS component for robustness.
read the caption
Table 3: Model ablations of DiChaViT. Removing any component in DiChaViT has a negative impact on overall performance, with significant decreases observed on the Partial setting when DCS is removed. Including all components improves performance across all three datasets.
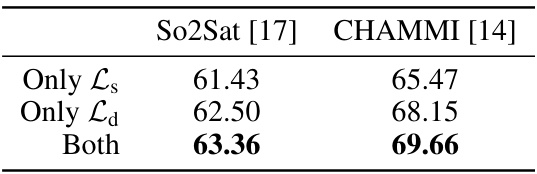
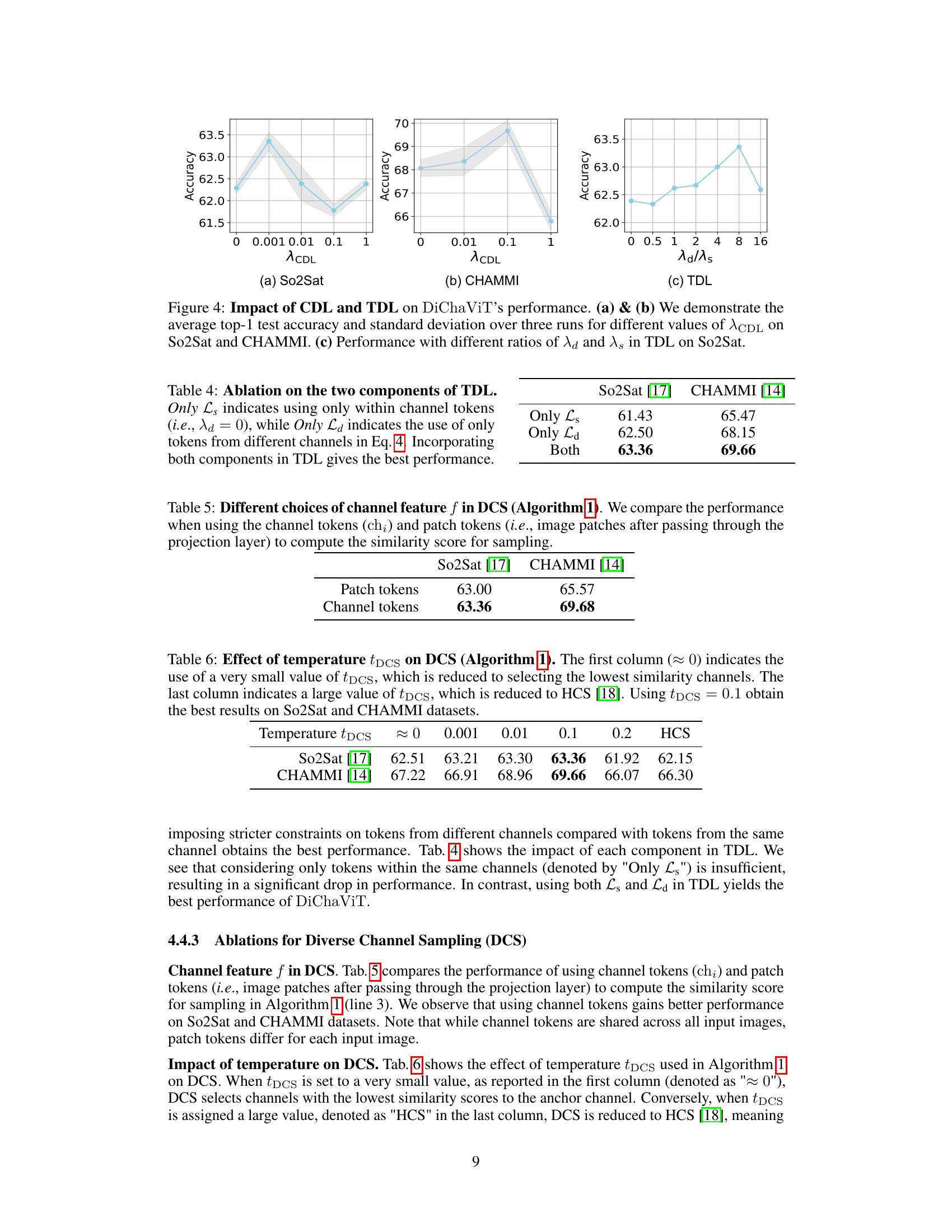
🔼 This table shows the ablation study of the Token Diversification Loss (TDL) by removing one of its components. The TDL encourages patch tokens to learn distinct features. It has two parts: Ls (same channel tokens) and Ld (different channel tokens). The table compares the performance when only Ls is used, only Ld is used, and when both are used. The results show that using both components of TDL leads to the best performance on both So2Sat and CHAMMI datasets.
read the caption
Table 4: Ablation on the two components of TDL. Only Ls indicates using only within channel tokens (i.e., λd = 0), while Only Ld indicates the use of only tokens from different channels in Eq. 4. Incorporating both components in TDL gives the best performance.
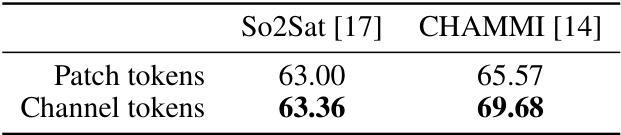
🔼 This table compares the performance of using channel tokens and patch tokens to compute the similarity score in Diverse Channel Sampling (DCS). Channel tokens represent the channel feature, while patch tokens are the image patches after a shared projection layer. The results show the performance on So2Sat and CHAMMI datasets, indicating whether using channel or patch tokens is better for channel selection in DCS.
read the caption
Table 5: Different choices of channel feature f in DCS (Algorithm 1). We compare the performance when using the channel tokens (chᵢ) and patch tokens (i.e., image patches after passing through the projection layer) to compute the similarity score for sampling.

🔼 This table shows the impact of the temperature parameter (tDCS) in the Diverse Channel Sampling (DCS) algorithm on the model’s performance. It shows that using a temperature of 0.1 yields the best results for both So2Sat and CHAMMI datasets. A very small tDCS value (approximately 0) is similar to selecting channels with the lowest similarity, while a very large tDCS value is similar to using Hierarchical Channel Sampling (HCS).
read the caption
Table 6: Effect of temperature tDCS on DCS (Algorithm 1). The first column (≈ 0) indicates the use of a very small value of tDCS, which is reduced to selecting the lowest similarity channels. The last column indicates a large value of tDCS, which is reduced to HCS [18]. Using tDCS = 0.1 obtain the best results on So2Sat and CHAMMI datasets.

🔼 This table compares the performance of DiChaViT against several baseline models on three different multi-channel image datasets: CHAMMI, JUMP-CP, and So2Sat. The performance is evaluated under two conditions: using all available channels (‘Full’) and a subset of channels (‘Partial’). DiChaViT demonstrates a significant improvement in accuracy over the baselines, particularly on CHAMMI.
read the caption
Table 1: Comparison of test accuracy of channel adaptive models. 'Full' refers to inference on all channels, while 'Partial' means testing on a subset of channels (Sentinel-1 channels for So2Sat, fluorescence channels for JUMP-CP). We find our model outperforms other baselines, with a 5.0% boost on CHAMMI and a 1.5–2.5% point improvement on JUMP-CP and So2Sat.

🔼 This table compares the performance of different channel adaptive models, including the proposed DiChaViT model, on three datasets: CHAMMI, JUMP-CP, and So2Sat. The ‘Full’ column represents the accuracy when all channels are used during testing, while the ‘Partial’ column shows the accuracy when only a subset of channels are used. The results demonstrate that DiChaViT outperforms other baseline models in both full and partial channel settings, achieving a significant improvement on CHAMMI and moderate improvements on JUMP-CP and So2Sat.
read the caption
Table 1: Comparison of test accuracy of channel adaptive models. 'Full' refers to inference on all channels, while 'Partial' means testing on a subset of channels (Sentinel-1 channels for So2Sat, fluorescence channels for JUMP-CP). We find our model outperforms other baselines, with a 5.0% boost on CHAMMI and a 1.5–2.5% point improvement on JUMP-CP and So2Sat.

🔼 This table presents a detailed comparison of ChannelViT and DiChaViT’s performance on the JUMP-CP dataset when one channel is left out during testing. It expands on the results shown in Table 2 of the main paper, providing the accuracy (with standard deviation) for each combination of 7 out of the 8 available channels. The results show that DiChaViT consistently outperforms ChannelViT across all channel combinations, demonstrating improved robustness to missing channels.
read the caption
Table 9: Detailed performances of ChannelViT and DiChaViT on JUMP-CP in the leave-one-channel-out at test time setting. We present the details of column '7' in Tab. 2 of the main paper. DiChaViT achieves 1–2% better performance on each combination compared with ChannelViT.
Full paper#