↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world machine learning models suffer performance degradation due to unpredictable data shifts. Current adaptation strategies often react without understanding the root cause, leading to inefficient or even harmful corrections. This paper introduces a novel approach called self-healing machine learning (SHML) which equips ML models with the ability to autonomously diagnose the reason for performance issues and select appropriate corrective actions. This addresses limitations of existing reason-agnostic approaches.
The core of SHML involves four stages: monitoring performance, diagnosing the cause of degradation, selecting an appropriate adaptation action based on the diagnosis, and testing the effectiveness of the action. The paper introduces H-LLM, a novel self-healing algorithm that employs large language models to perform self-diagnosis and adaptation. Through extensive experiments, the authors demonstrate that H-LLM effectively improves model performance under various conditions compared to traditional methods. This establishes SHML’s effectiveness and suggests exciting future research avenues.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on robust and reliable machine learning systems in dynamic environments. It introduces a novel paradigm of self-healing machine learning, addressing the limitations of existing methods. The proposed framework opens new avenues for research in autonomous model adaptation, particularly in high-stakes applications requiring continuous performance. The empirical evaluations further establish the practicality and effectiveness of self-healing, making this a significant contribution to the field.
Visual Insights#

This figure shows a time series plot of model accuracy over time. Initially, the model shows relatively stable performance. At time t, an environment change causes a sudden drop in accuracy. Following the change, four different adaptation strategies (a1, a2, a3, a4) are applied. Each strategy leads to a different pattern of model recovery. Some strategies result in quick and sustained improvement, while others lead to more gradual or less effective recovery. The figure illustrates the concept that the choice of adaptation strategy significantly impacts model performance after an environmental shift.

This table summarizes the four components of self-healing machine learning: Monitoring, Diagnosis, Adaptation, and Testing. For each component, it provides the equation number (if applicable), the methodological and experimental contributions, the main practical implications, and links to relevant sections of the paper. It serves as a quick reference guide to navigate the paper’s content.
In-depth insights#
Self-Healing ML#
Self-healing machine learning (SHML) presents a novel paradigm for enhancing the robustness of machine learning models in dynamic, real-world environments. Unlike traditional methods that react to performance degradation in a reason-agnostic manner, SHML incorporates a diagnostic component that autonomously identifies the root cause of model decline. This diagnosis is then used to inform the selection of targeted corrective actions, minimizing the expected risk under the shifted data-generating process. The framework is composed of four stages: monitoring, diagnosis, adaptation, and testing, with each stage playing a crucial role in the self-healing process. The proposed H-LLM system leverages large language models to effectively diagnose and adapt, demonstrating strong empirical performance and robustness across various datasets and model types. A key advantage of SHML lies in its ability to move beyond pre-defined adaptation strategies, allowing for more informed and effective responses to real-world challenges. However, challenges remain in accurately diagnosing complex causes and evaluating actions effectively. The theoretical underpinnings provided in the paper establish the foundation for future research in this field and the development of more sophisticated self-healing algorithms.
H-LLM: Design#
The design of H-LLM, a self-healing machine learning system, centers on addressing the limitations of reason-agnostic methods. Four core components are integrated: monitoring, diagnosis, adaptation, and testing. Monitoring detects performance degradation; diagnosis, powered by large language models (LLMs), identifies the root causes; adaptation, guided by the diagnosis, proposes corrective actions (retraining, data cleaning, etc.); and testing evaluates the efficacy of these actions. LLMs are crucial because of their ability to generate hypotheses, understand context, and act as agents within the system. The design cleverly leverages LLMs’ strengths to overcome the challenges of diagnosing complex real-world issues and selecting from a potentially vast space of adaptation actions. Empirically evaluating actions is vital, hence the inclusion of a testing component. H-LLM’s architecture thus integrates theoretical principles of self-healing with the practical capabilities of LLMs, offering a novel approach to robust and autonomous model adaptation.
Diagnosis Analysis#
Diagnosis analysis in a self-healing machine learning (SHML) system is crucial for effective adaptation. It involves identifying the root cause of model performance degradation, going beyond simple drift detection. The quality of diagnosis is paramount; high-quality diagnoses should be informative, sensitive to subtle changes, and maximize uncertainty when lacking knowledge. This is formalized through concepts like optimal diagnosis, minimizing expected risk, and measuring diagnostic certainty using entropy. The use of large language models (LLMs) emerges as a powerful tool, leveraging their ability to generate and evaluate hypotheses, enabling autonomous diagnosis and informing the selection of appropriate corrective actions. However, challenges remain, such as the complexity of the space of possible reasons and the need for well-calibrated probability assignment to these reasons, requiring further methodological advances to ensure robust and reliable self-healing in real-world applications. Ultimately, the success of SHML depends heavily on the accuracy and effectiveness of the diagnosis phase.
Viability Studies#
The viability studies section of a research paper is crucial for demonstrating the practical applicability and effectiveness of the proposed method. It involves designing and conducting experiments to test the various aspects of the method under different conditions and comparing its performance against existing benchmarks. A robust viability study will employ a well-defined experimental setup, ensuring proper controls and rigorous statistical analysis to validate the claims made. A well-designed study will analyze the impact of various parameters and explore edge cases, testing the limits of the methodology’s performance. The results should be presented clearly, employing appropriate visualizations and statistical measures. Moreover, a detailed discussion section is essential, interpreting the results and explaining any unexpected findings or limitations, providing insights into the method’s strengths, weaknesses, and practical implications. Overall, a comprehensive viability study is vital for demonstrating the reliability and potential of the research’s findings.
Future of SHML#
The future of Self-Healing Machine Learning (SHML) is bright, promising more robust and reliable AI systems. Improved diagnostic capabilities are crucial; advancements in explainable AI and causal inference could significantly enhance SHML’s ability to pinpoint root causes of model degradation. More sophisticated adaptation strategies will emerge, moving beyond simple retraining to encompass dynamic model architecture adjustments, transfer learning, and even the ability to synthesize new data to address data scarcity. The integration of SHML with other advanced AI paradigms like reinforcement learning and federated learning will create self-managing, decentralized AI systems capable of adapting to highly dynamic real-world scenarios. Addressing ethical considerations will also be paramount, ensuring fairness, transparency, and accountability as SHML becomes more prevalent. Finally, research into the theoretical underpinnings of SHML and development of standardized evaluation metrics is needed to advance the field. Practical applications will expand to high-stakes domains (healthcare, finance) and require ongoing development of robust and safe methods.
More visual insights#
More on figures

This figure illustrates the architecture of a self-healing machine learning system. The system consists of a deployed machine learning model (f) and a healing mechanism (H) that interacts with it. The healing mechanism has four main components: 1. Monitoring: Checks if the model’s performance has decreased. 2. Diagnosis: Identifies the reasons for the performance decrease. 3. Adaptation: Proposes and implements corrective actions to improve the model’s performance. 4. Testing: Evaluates the effectiveness of the implemented actions. The ultimate goal is to find the optimal adaptation strategy to maximize the predictive performance of the model.

This figure illustrates the four stages of the self-healing machine learning (SHML) framework. The deployed model, f, interacts with the healing mechanism, H, which consists of four components: monitoring (HM), diagnosis (HD), adaptation, and testing (HT). The monitoring component detects performance degradation. If degradation is detected, the diagnosis component identifies the cause. Based on the diagnosis, the adaptation component selects an action (a) from a set of possible actions (A) according to an adaptation policy (π). Finally, the testing component evaluates the action’s effect on the model’s performance. The chosen action is then applied to the model (f) at the next time step. The entire process repeats continuously, allowing for autonomous adaptation to changes in the environment.

This figure shows the relationship between the drift detection threshold and the average recovery time and post-intervention accuracy of the Self-Healing Machine Learning (SHML) system. The average recovery time shows an exponential relationship with the drift detection threshold, increasing significantly as the threshold increases. The post-intervention accuracy decreases linearly as the drift detection threshold increases. This indicates that lower thresholds lead to faster recovery and higher accuracy, but with greater risks of false positives and unnecessary interventions. Conversely, higher thresholds increase recovery time but reduce the likelihood of false positives and unnecessary actions.

This figure shows the relationship between the drift detection threshold and both the average recovery time and the post-intervention accuracy of the self-healing machine learning model, H-LLM. Lower thresholds (meaning higher sensitivity to detecting shifts) lead to faster recovery times, but also an increase in false positives that can impact accuracy. However, the self-healing model is quite robust to these false positives; there is still a marked improvement in post-intervention accuracy even with a low threshold compared to traditional systems.

This figure shows the results of the fifth viability study (Sec. 6.5) in the paper, which analyzes the sensitivity of the SHML adaptation actions. The left panel shows how the accuracy of each action varies with the range of values corrupted, demonstrating that as more values are corrupted, the actions become more concentrated and less effective. The right panel shows how the accuracy varies with the size of the backtesting dataset, suggesting that with a larger dataset, the actions are more spread out. Overall, this highlights the importance of high-quality data and a large backtesting window for reliable adaptation action selection in SHML.

This figure shows the impact of including a testing phase (using a backtesting window) in the self-healing machine learning process. The x-axis represents the accuracy achieved by the adaptation policies, and the y-axis shows the percentage of corrupted data. The blue circles represent the performance when there is no backtesting window, while the black circles show the performance when the backtesting window is used to evaluate proposed actions. The figure demonstrates that including the testing phase significantly improves the accuracy of the selected actions. The improvement is most substantial at lower levels of data corruption.
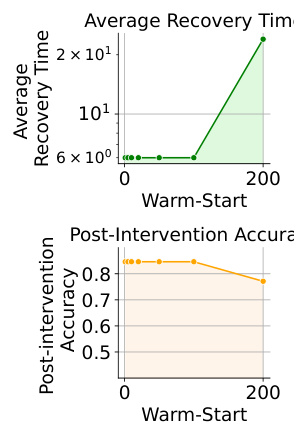
This figure shows the relationship between the warm-start parameter (x-axis) and two metrics: average recovery time and post-intervention accuracy. The average recovery time shows a significant increase when the warm-start parameter is set high, indicating a delay in triggering the self-healing system due to false positive drift detection. Conversely, the post-intervention accuracy is higher with smaller thresholds. This suggests that SHML is robust to false positives from drift detection algorithms, making it more effective when the threshold for detecting drift is lower (higher sensitivity).

This figure displays the quality of diagnosis made by the model as the number of corrupted columns increases. The y-axis represents the KL-divergence between the true and predicted probabilities of corrupted columns. Lower KL-divergence indicates a better quality of diagnosis (closer to the truth). As more columns are corrupted, the uncertainty increases, leading to a more uniform diagnosis (higher KL-divergence). This indicates that when many columns are impacted, pinpointing the exact source of the problem becomes more challenging.

This figure shows the potential impact of different adaptation strategies on model performance when facing environmental changes. Four different strategies (a1-a4) are represented, and their effect on model accuracy over time is illustrated. The graph demonstrates that different strategies have varying degrees of success in maintaining performance after an environmental change, highlighting the importance of selecting an appropriate strategy.
More on tables

This table compares the theoretical components of the Self-Healing Machine Learning (SHML) framework with their implementations in the H-LLM algorithm. It shows how each theoretical component (Monitoring, Diagnosis, Adaptation, and Testing) is approximated in practice using specific techniques. The table highlights the use of drift detection algorithms, Large Language Models (LLMs) for diagnosis and adaptation via Monte Carlo sampling, and empirical datasets for testing.

This table presents the accuracy of a deployed model (f) after an intervention that changes the data generating process (DGP) and corrupts a certain percentage (τ) of columns (k). The results compare the performance of several methods: no retraining, partially updating, new model training, ensemble method, and H-LLM. The table helps showcase that H-LLM, the proposed self-healing approach, significantly outperforms the other methods, particularly when the corruption level is high.

This table presents the accuracy of different methods (no retraining, partially updating, new model training, ensemble method, and H-LLM) across five datasets (airlines, poker, weather, electricity, and covtype) under two conditions: (1) corrupting 5 columns (k=5) and (2) corrupting 5% of the values (τ=5). It demonstrates H-LLM’s robustness and ability to handle data corruption, consistently outperforming other methods.

This table summarizes the four stages of self-healing machine learning: Monitoring, Diagnosis, Adaptation, and Testing. For each stage, it provides the equation number (if applicable), the methodological and experimental contributions, and the main practical implications, along with links to relevant sections of the paper, serving as a guide for the reader.

This table summarizes the four key components of self-healing machine learning (SHML): Monitoring, Diagnosis, Adaptation, and Testing. For each component, it provides the equation number from the paper where the component is defined, the methodological and experimental contributions related to that component, the main practical implications of that component, and links to relevant sections within the paper. It acts as a guide for navigating through the various sections of the paper that deal with each component.

This table compares the theoretical components of the Self-healing Machine Learning (SHML) framework with their practical implementations in the H-LLM algorithm. It shows how each component (monitoring, diagnosis, adaptation, testing) is conceptually defined and then approximated in the H-LLM system using large language models (LLMs). The table highlights the trade-offs and approximations made in translating the theoretical framework into a practical algorithm.

This table presents the accuracy of a deployed model (f) after an intervention that changes the data generating process (DGP) and introduces corruption in a percentage (τ) of k columns. The results compare the performance of H-LLM against four other methods (No retraining, Partially Updating, New model training, Ensemble Method) across different levels of corruption (both the number of corrupted columns and the percentage of corrupted values within those columns). Higher accuracy is indicated by the upward-pointing arrow (↑). The table demonstrates H-LLM’s superior performance in handling model degradation caused by DGP changes and data corruption.

This table presents the accuracy results of different model adaptation methods under varying levels of data corruption. The methods compared include: No retraining, Partially Updating, New model training, Ensemble Method and the proposed H-LLM. The accuracy is measured under different numbers of corrupted columns (k) and different corruption percentages (τ). Higher accuracy is better, indicating superior model adaptation in the face of corruption and distribution shifts. The results demonstrate H-LLM’s superior performance compared to existing methods across various levels of data corruption.

This table compares the accuracies achieved by different model adaptation methods on the diabetes prediction task. It includes standard adaptation techniques like no retraining, partial updating, new model training, and ensemble methods, along with streaming-specific algorithms (ADWIN Bagging, Hoeffding Tree, Adaptive Voting), and the authors’ proposed Self-Healing ML approach. The results show that while specialized streaming algorithms outperform basic adaptations, they still underperform the Self-Healing ML approach.

This table summarizes the four components of self-healing machine learning: monitoring, diagnosis, adaptation, and testing. For each component, it provides a brief definition, links to the relevant sections of the paper where the component is discussed in detail, and notes on the methodological and experimental contributions associated with that component. It is designed as a navigation guide for readers to locate specific information within the paper.

This table compares the performance of different model adaptation methods across various machine learning models on a weather dataset. The features were corrupted during the test phase to simulate real-world scenarios. The table shows that the self-healing machine learning (SHML) approach consistently outperforms other methods, demonstrating its robustness and adaptability across different models and corruption levels.
Full paper#



















