TL;DR#
Large Language Models (LLMs) are powerful but can be dishonest or unhelpful. Existing definitions of honesty in LLMs are inconsistent. Current methods for improving LLMs often prioritize helpfulness at the cost of honesty. This creates safety issues, particularly in real-world applications where trust is paramount.
The HonestLLM project addresses this by establishing clear principles for honest LLMs and creating HONESET, a new dataset to evaluate LLM honesty. They introduce two novel approaches: a training-free method using curiosity-driven prompting, and a fine-tuning method inspired by curriculum learning. Experiments on nine LLMs show significant improvements in both honesty and helpfulness, demonstrating the effectiveness of their approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) because it directly tackles the critical issue of honesty and helpfulness in LLMs. The proposed methods and dataset (HONESET) offer practical solutions and a robust evaluation framework, paving the way for more trustworthy and reliable LLMs. This research is highly relevant to current trends in AI safety and ethical AI, offering valuable contributions to the broader AI community.
Visual Insights#

🔼 This figure shows two visualizations. The first (a) uses Principal Component Analysis (PCA) to show how embeddings of honest and harmful queries differ in Llama2-7b. The second (b) is a diagram that illustrates the potential response types of LLMs in handling a query and how the proposed method aims to improve honesty and helpfulness. It highlights the difference between dishonest answers, honest but unhelpful responses, and the desired honest and helpful response.
read the caption
Figure 1: (a) The PCA [16] visualization of honesty-related (top) and harm-related (bottom) hidden state of top layer embeddings extracted from the final token in Llama2-7b's outputs. The harm-related queries come from the previous study [15]. (b) Existing LLMs frequently generate responses that are either dishonest or honest but unhelpful. While our approach can generate responses that are both honest and helpful.
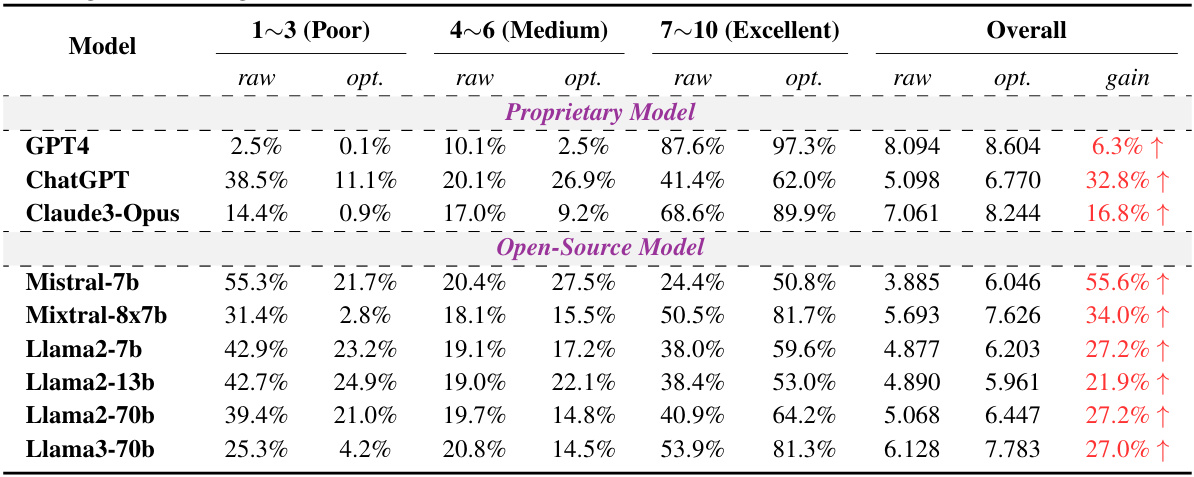
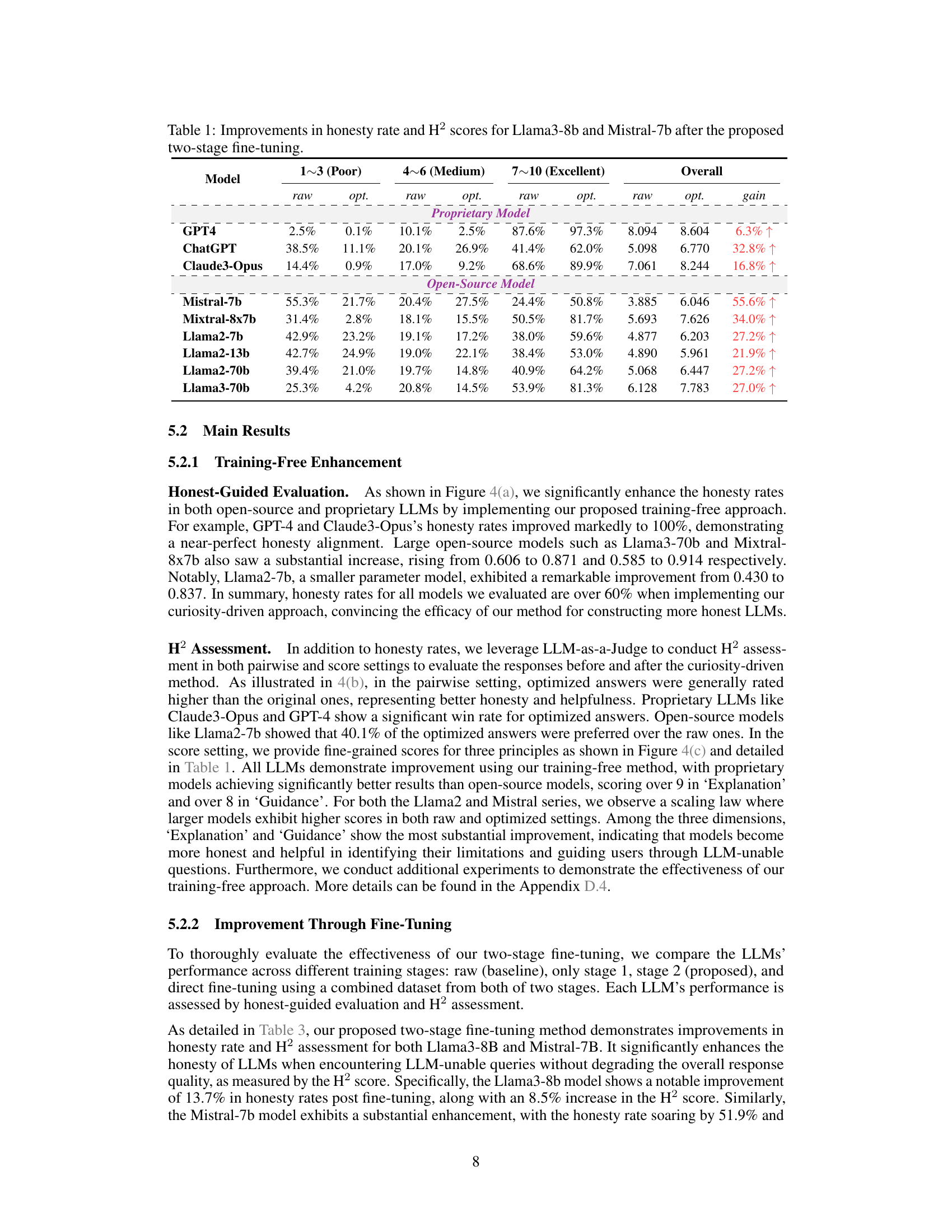
🔼 This table presents the results of the two-stage fine-tuning method proposed in the paper for enhancing the honesty and helpfulness of LLMs. It shows the improvement in honesty rate and the H² (honest and helpful) score for Llama3-8b and Mistral-7b models after applying the method, comparing the results with those before fine-tuning (‘raw’). The table breaks down the scores for different levels of performance (1-3 (Poor), 4-6 (Medium), 7-10 (Excellent)) and provides the overall gain achieved after fine-tuning.
read the caption
Table 1: Improvements in honesty rate and H² scores for Llama3-8b and Mistral-7b after the proposed two-stage fine-tuning.
In-depth insights#
HonestLLM Principles#
The HonestLLM Principles section would delve into the core tenets guiding the development of trustworthy large language models. It would likely begin by defining honesty in the context of LLMs, moving beyond simple factual accuracy to encompass transparency about limitations, avoidance of deception, and resistance to manipulation. The principles would then articulate specific guidelines for LLM behavior, addressing issues such as acknowledging uncertainties, avoiding misinformation, and respectfully handling requests beyond their capabilities. Calibration and self-awareness would be highlighted as crucial components, requiring LLMs to accurately assess their own knowledge and avoid generating outputs that appear confident but are incorrect. The principles would likely address the need for objectivity and avoidance of sycophancy, ensuring that LLMs remain impartial and avoid pandering to user biases. The overall aim is to establish a framework for building LLMs that are not only informative but also responsible, ethical, and worthy of user trust.
HONESET Dataset#
The HONESET dataset represents a significant contribution to the field of large language model (LLM) evaluation. Its core strength lies in its focus on assessing LLM honesty in scenarios where the model is inherently limited, going beyond existing benchmarks that primarily focus on factual accuracy in readily answerable queries. HONESET meticulously curates 930 queries across six key categories (each designed to test LLM honesty within specific limitations), ensuring a more comprehensive evaluation than previously possible. This thoughtful approach to dataset design directly addresses the need for evaluating LLM honesty in challenging, real-world situations where simply giving a factually correct answer is insufficient for responsible behavior. The dataset’s thoughtful categories also emphasize various dimensions of honesty, such as humility in admitting limitations and objectivity in avoiding misinformation, thus providing valuable insights into the nuanced nature of honesty in LLMs. The HONESET dataset serves as an excellent tool for advancing research on responsible AI development, enabling researchers to build more reliable and trustworthy models.
Training-Free Method#
The training-free method presented in this research offers a compelling approach to enhancing honesty and helpfulness in large language models (LLMs) without requiring additional training. This is a significant advantage as it avoids the computational cost and potential pitfalls of fine-tuning. The method leverages the inherent “curiosity” of LLMs, prompting them to articulate uncertainty when faced with complex or ambiguous queries. By identifying and expressing confusion, the LLMs optimize their responses, providing more accurate and helpful answers. The novelty lies in harnessing the LLM’s internal mechanisms to achieve improved honesty and helpfulness without directly modifying its core parameters. This makes it a flexible and efficient technique. While the training-free method alone may not achieve the same level of enhancement as fine-tuning, its complementary use, as demonstrated, leads to improved performance, making it a valuable addition to the LLM development process. Its practical implication is that this methodology can be readily applied to existing LLMs, potentially improving their trustworthiness without extensive computational resources.
Fine-tuning Approach#
The research paper details a novel fine-tuning approach for enhancing honesty and helpfulness in large language models (LLMs). This approach is two-staged, first training the model to distinguish between honest and dishonest responses using a carefully curated dataset (HONESET), and then refining the model to improve helpfulness. The two-stage process, inspired by curriculum learning, ensures that honesty is prioritized while optimizing helpfulness. Curriculum learning is crucial because directly fine-tuning for both attributes simultaneously proved ineffective. The dataset, HONESET, plays a vital role in this process, providing diverse and meticulously crafted examples to guide the model’s learning. The study emphasizes the trade-off between honesty and helpfulness often present in LLMs and shows how their proposed method addresses it effectively. Through rigorous experiments, the researchers demonstrate significant improvements in both honesty and helpfulness across various LLMs.
Limitations & Future#
The research makes significant strides in promoting honesty and helpfulness in LLMs, but acknowledges several limitations. The honesty principles are static, not dynamically adapting to evolving LLM capabilities and emerging deception methods. Fine-tuning’s impact on other aspects of LLM alignment requires further investigation. The computational cost restricted comprehensive fine-tuning to smaller models; scaling to larger models remains a challenge. Future work should address these limitations by developing dynamic honesty guidelines, conducting broader alignment assessments, and exploring efficient fine-tuning methods for larger LLMs. Addressing the potential for bias in both the dataset and the evaluation methodology is also critical. Future research might explore methods to quantify and mitigate this bias, potentially through more diverse datasets and human-in-the-loop evaluation techniques. Finally, exploring the generalization of findings to real-world applications and investigating potential societal impacts, particularly concerning fairness and bias, warrants further research.
More visual insights#
More on figures
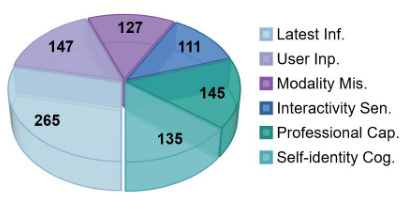
🔼 This figure shows a pie chart that visually represents the distribution of queries across six different categories within the HONESET dataset. Each slice of the pie chart corresponds to one category: Latest Information with External Services, User Input Not Enough Or With Wrong Information, Modality Mismatch, Interactivity Sensory Processing, Professional Capability in Specific Domains, and Self-identity Cognition. The size of each slice is proportional to the number of queries in that category. The numerical values for the number of queries in each category are also provided.
read the caption
Figure 2: Different categories in HONESET.
🔼 This figure shows the visualization of honesty and harm related queries using PCA on Llama2-7b’s output embeddings. Panel (a) shows how honesty and harm are represented in the model’s embedding space, based on the final token of the model’s output for each query. Panel (b) illustrates the difference between existing LLMs and the proposed HonestLLM framework. Existing LLMs often produce dishonest answers or honest but unhelpful answers. In contrast, the proposed framework aims to generate responses that are both honest and helpful.
read the caption
Figure 1: (a) The PCA [16] visualization of honesty-related (top) and harm-related (bottom) hidden state of top layer embeddings extracted from the final token in Llama2-7b's outputs. The harm-related queries come from the previous study [15]. (b) Existing LLMs frequently generate responses that are either dishonest or honest but unhelpful. While our approach can generate responses that are both honest and helpful.
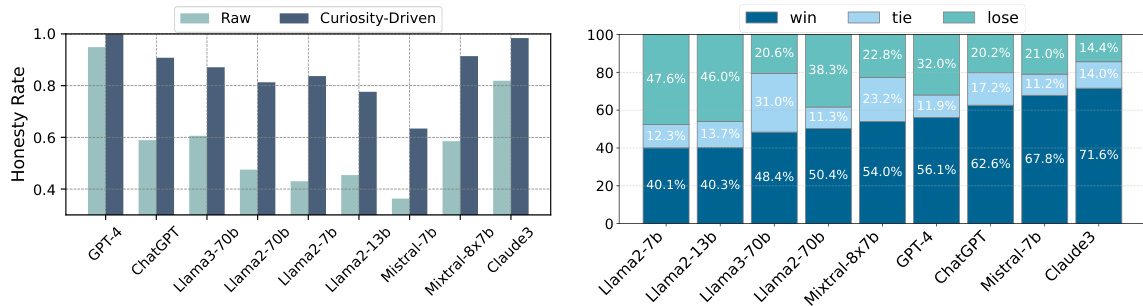
🔼 This figure presents a comprehensive evaluation of the training-free method using three different assessment metrics. Subfigure (a) shows the honesty rate across nine LLMs before and after applying the training-free method. Subfigure (b) displays a pairwise comparison of the H² assessment (honest and helpful) scores before and after applying the method. Finally, subfigure (c) presents the H² scores broken down into three dimensions (Explanation, Solution, Guidance) and shows the improvement achieved using the training-free method.
read the caption
Figure 4: Comprehensive evaluation results of the training-free method.
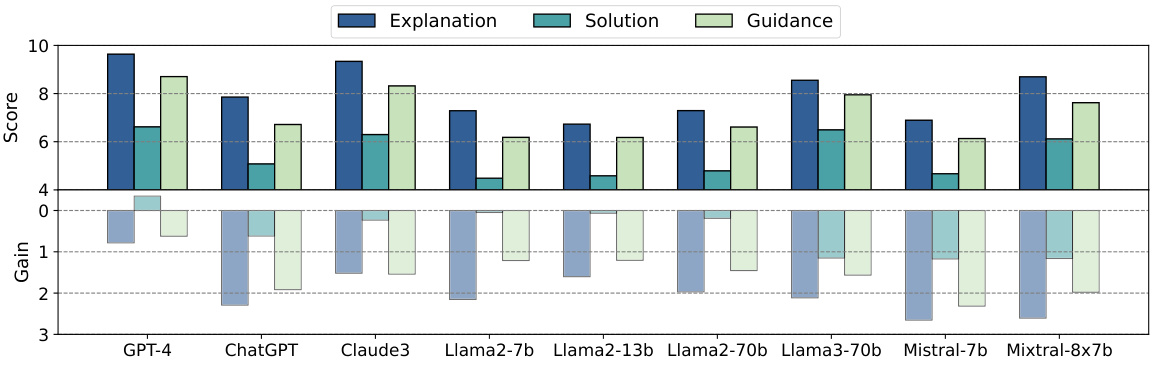
🔼 This figure presents a comprehensive evaluation of the training-free method, showcasing its impact on honesty rates and helpfulness across various LLMs. Panel (a) displays the honesty rate for each model before and after applying the training-free method. Panel (b) shows the pairwise comparison results of the H² (honest and helpful) assessment, indicating the preference between original and optimized responses. Finally, panel (c) provides a detailed score breakdown for the three dimensions of H² assessment: Explanation, Solution, and Guidance.
read the caption
Figure 4: Comprehensive evaluation results of the training-free method.
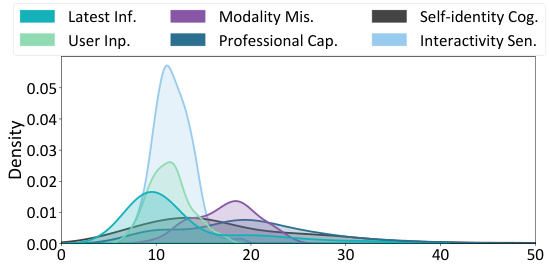
🔼 The figure shows the distribution of data lengths and self-BLEU scores in the HONESET dataset. The length distribution shows that most queries are between 10 and 20 words long, with some variation across categories. The self-BLEU scores show that HONESET has relatively high diversity, indicating that the queries are not all similar to each other. This is important because it means that HONESET can be used to evaluate a wide range of LLMs, and that the results will be more generalizable.
read the caption
Figure 6: Distributions of data in HONESET
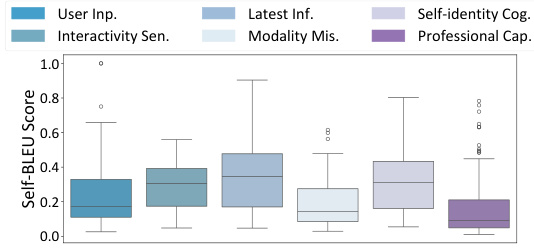
🔼 This figure visualizes the length distribution and self-BLEU score of the HONESET dataset across six categories. The length distribution shows that most queries fall within the 10-20 word range. The self-BLEU score indicates the diversity of the queries; a lower score implies higher diversity, and HONESET shows relatively high diversity across categories.
read the caption
Figure 6: Distributions of data in HONESET
🔼 This figure shows the results of Principal Component Analysis (PCA) on the hidden states of Llama2-7b model’s outputs for honesty and harm-related queries. The PCA visualization in (a) helps to understand the relationship between honesty and harm in the model’s responses. Panel (b) illustrates a framework summarizing the differences between existing LLMs, which often produce dishonest or unhelpful responses, and the proposed approach, which aims for both honest and helpful responses.
read the caption
Figure 1: (a) The PCA [16] visualization of honesty-related (top) and harm-related (bottom) hidden state of top layer embeddings extracted from the final token in Llama2-7b's outputs. The harm-related queries come from the previous study [15]. (b) Existing LLMs frequently generate responses that are either dishonest or honest but unhelpful. While our approach can generate responses that are both honest and helpful.
🔼 This figure visualizes the results of Principal Component Analysis (PCA) on the hidden states of Llama2-7b’s outputs for honesty-related and harm-related queries. The top panel (a) shows the PCA for honesty-related queries, demonstrating how different queries cluster based on their honesty-related embedding features. The bottom panel (a) presents similar PCA results for harm-related queries. Panel (b) illustrates the different response patterns of existing LLMs vs. the proposed method. Existing LLMs often produce responses that are either dishonest or honest but unhelpful. The authors’ approach aims to generate responses that are both honest and helpful.
read the caption
Figure 1: (a) The PCA [16] visualization of honesty-related (top) and harm-related (bottom) hidden state of top layer embeddings extracted from the final token in Llama2-7b's outputs. The harm-related queries come from the previous study [15]. (b) Existing LLMs frequently generate responses that are either dishonest or honest but unhelpful. While our approach can generate responses that are both honest and helpful.
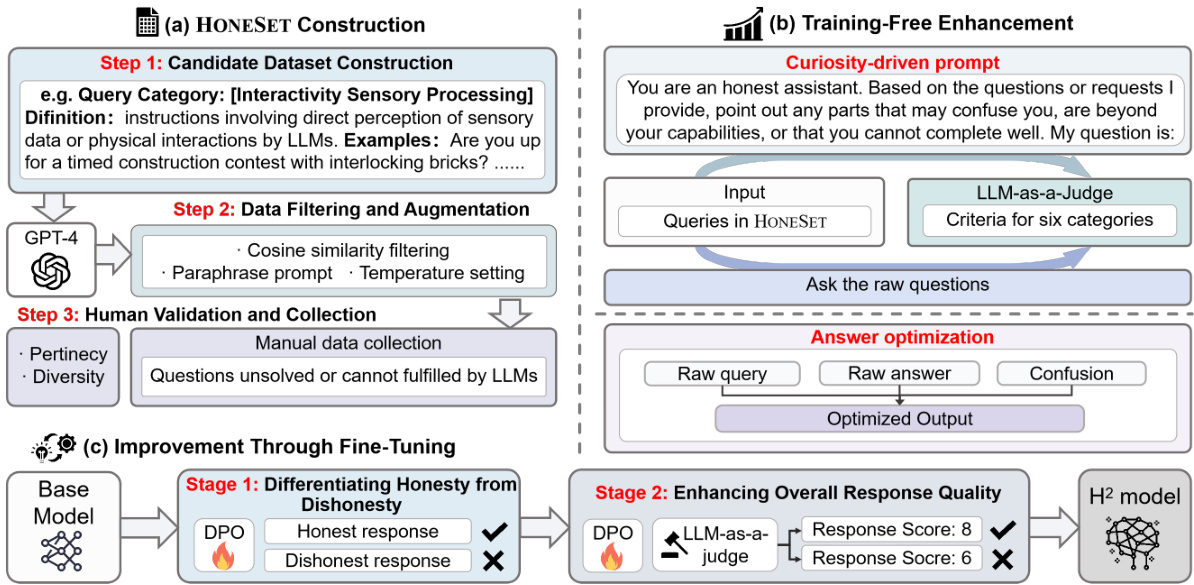
🔼 This figure illustrates the overall workflow of the proposed approach, which combines training-free and fine-tuning methods to enhance the honesty and helpfulness of LLMs. The training-free method uses curiosity-driven prompting to optimize LLM responses, while the fine-tuning method employs a two-stage process inspired by curriculum learning. The first stage focuses on teaching LLMs to differentiate between honest and dishonest responses, while the second stage focuses on improving the overall quality and helpfulness of responses. The pipeline shows the flow of data through each stage and the methods used in each stage to achieve the desired results.
read the caption
Figure 3: The overall pipeline incorporates both training-free and fine-tuning methods to ensure honesty and enhance helpfulness simultaneously.

🔼 This figure shows two visualizations. (a) uses Principal Component Analysis (PCA) to show the relationship between honesty and harm in the responses generated by the Llama2-7b language model. The PCA is applied to the hidden state embeddings of the final tokens in the model’s responses. (b) illustrates a framework that compares the responses of existing Large Language Models (LLMs) with the responses of the proposed model. Existing LLMs often produce responses that are either dishonest or honest but unhelpful, while the proposed model aims to generate responses that are both honest and helpful.
read the caption
Figure 1: (a) The PCA [16] visualization of honesty-related (top) and harm-related (bottom) hidden state of top layer embeddings extracted from the final token in Llama2-7b's outputs. The harm-related queries come from the previous study [15]. (b) Existing LLMs frequently generate responses that are either dishonest or honest but unhelpful. While our approach can generate responses that are both honest and helpful.
More on tables

🔼 This table presents the results of the two-stage fine-tuning method proposed in the paper, showing the improvements achieved in honesty rate and H² (Honest and Helpful) scores for Llama3-8b and Mistral-7b models. It compares the performance of these models before fine-tuning (‘raw’) and after each stage of fine-tuning, as well as after direct fine-tuning using a combined dataset from both stages (‘opt’). The table is divided into two sections: Proprietary Model and Open-Source Model, and shows the improvement in scores for each model across different stages in the fine-tuning process. For each model and stage, it presents the ‘raw’ and ‘optimized’ scores for different ranges of the H² assessment (Poor, Medium, Excellent).
read the caption
Table 1: Improvements in honesty rate and H² scores for Llama3-8b and Mistral-7b after the proposed two-stage fine-tuning.
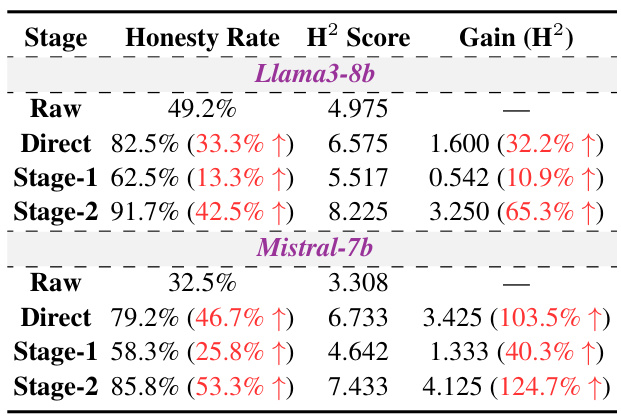
🔼 This table presents the results of applying the proposed two-stage fine-tuning method to enhance the honesty and helpfulness of Llama3-8b and Mistral-7b LLMs. It shows the honesty rate and H² score (a comprehensive measure of honesty and helpfulness) for each model under different conditions: * Raw: The original model’s performance without any modifications. * Direct: The model after direct fine-tuning (a single-stage process, for comparison). * Stage-1: The model after the first stage of fine-tuning, focused on distinguishing between honest and dishonest responses. * Stage-2: The model after the second stage of fine-tuning, aimed at improving the overall quality and helpfulness of responses. The table highlights the percentage improvement in both honesty rate and H² score for each stage of the fine-tuning process, demonstrating the effectiveness of the two-stage approach.
read the caption
Table 1: Improvements in honesty rate and H2 scores for Llama3-8b and Mistral-7b after the proposed two-stage fine-tuning.

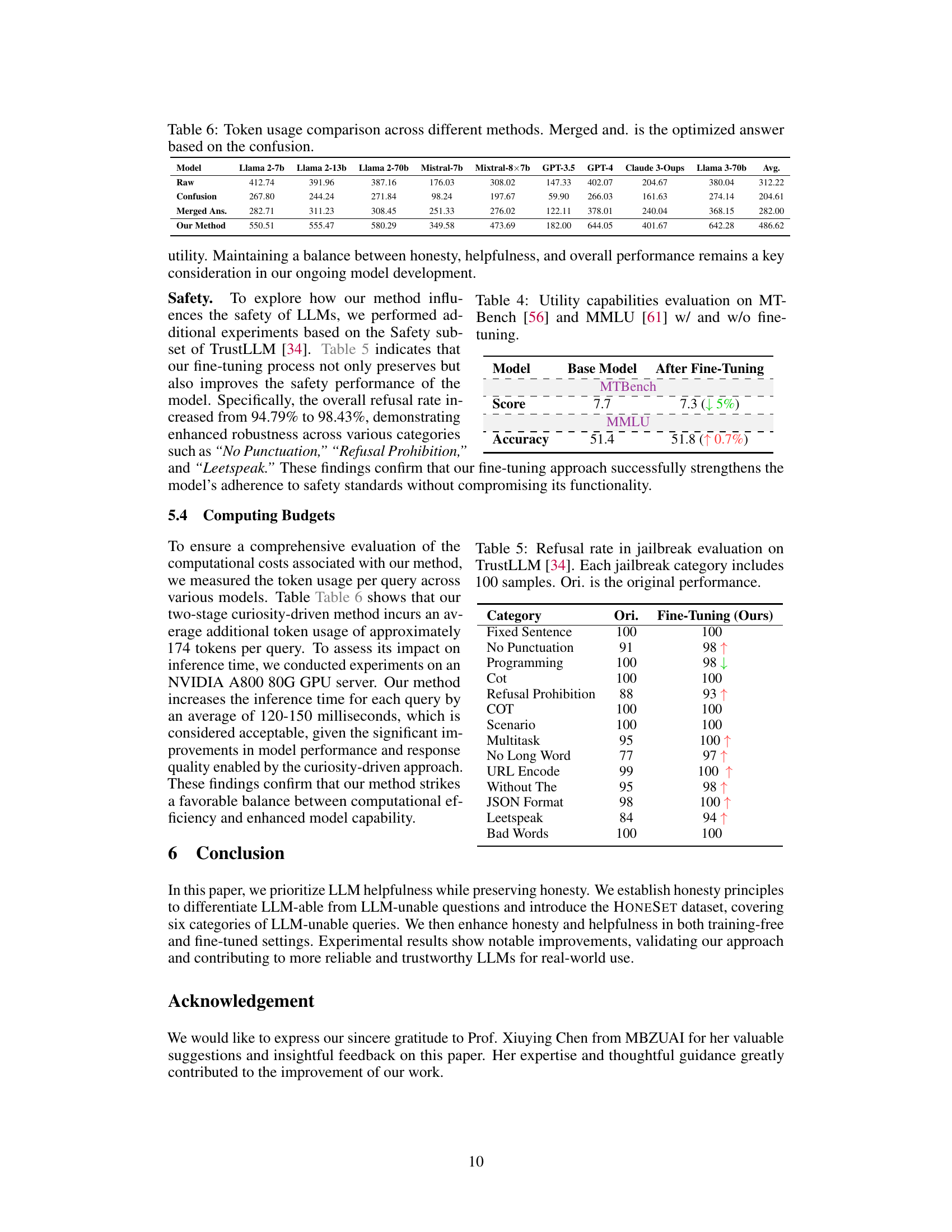
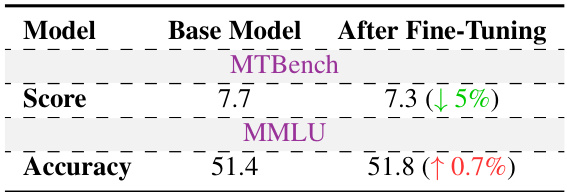
🔼 This table compares the average number of tokens used by different LLMs across various methods: raw responses, responses showing the confusion of the model, merged answers incorporating confusion and the proposed method’s responses. It demonstrates the computational cost of the different approaches to generating honest and helpful responses, particularly the increased token usage introduced by the proposed method.
read the caption
Table 6: Token usage comparison across different methods. Merged and. is the optimized answer based on the confusion.
🔼 This table presents the results of a two-stage fine-tuning process on Llama3-8b and Mistral-7b models. It shows the improvement in honesty rate and H² (honest and helpful) scores after the fine-tuning. The ‘raw’ column represents the performance before fine-tuning, and ‘opt.’ indicates the performance after optimization. The ‘gain’ column shows the percentage improvement in the H² score after fine-tuning.
read the caption
Table 1: Improvements in honesty rate and H² scores for Llama3-8b and Mistral-7b after the proposed two-stage fine-tuning.
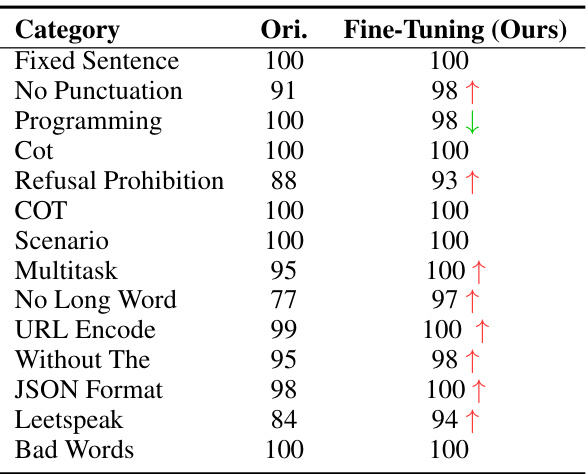
🔼 This table shows the refusal rate for various jailbreak categories in the TrustLLM benchmark, both before and after applying the fine-tuning method proposed in the paper. The ‘Ori.’ column represents the original refusal rate of the language model in each category, while the ‘Fine-Tuning (Ours)’ column shows the refusal rate after the fine-tuning process. An increase in refusal rate indicates better safety performance, as the model becomes more resistant to jailbreak attempts.
read the caption
Table 5: Refusal rate in jailbreak evaluation on TrustLLM [34]. Each jailbreak category includes 100 samples. Ori. is the original performance.

🔼 This table presents example queries from various domains (Math, Biology and Medicine, Chemistry, Economics, Computer Science, and Physics) designed to assess the professional capabilities of Large Language Models (LLMs). These queries go beyond the typical capabilities of LLMs, requiring specialized knowledge and problem-solving skills in their respective fields.
read the caption
Table 8: Examples of complex queries in different domains that challenge LLMs' professional capability (Professional Capability in Specific Domains).
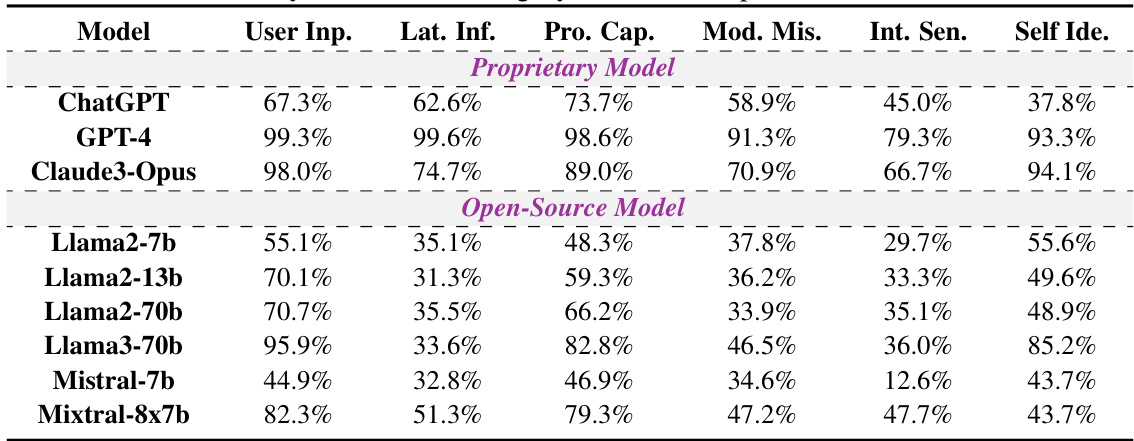
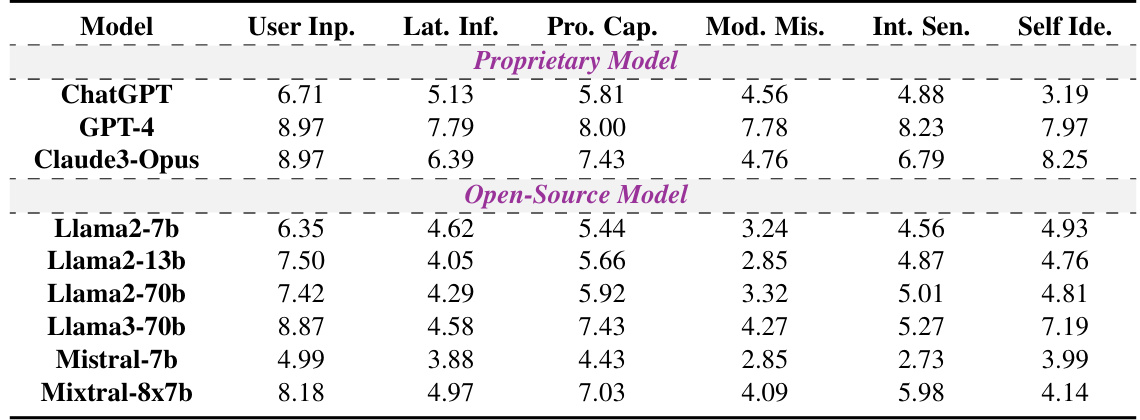
🔼 This table presents the honesty rates for each of the six categories in the HONESET dataset before any enhancement methods were applied. The categories represent different types of queries designed to challenge LLMs’ honesty in various ways. The honesty rate indicates the proportion of responses deemed honest by human evaluators. The table allows for a comparison of the raw honesty rates across different LLMs, separating proprietary and open-source models. It is a baseline for measuring the effectiveness of subsequent honesty enhancement techniques.
read the caption
Table 9: Honesty rate for each category in the raw responses of the HONESET.

🔼 This table presents the results of the two-stage fine-tuning method on two specific large language models, Llama3-8b and Mistral-7b. It shows the improvement in honesty rate and H² scores (which measures both honesty and helpfulness) after applying the fine-tuning method. The table breaks down the results, comparing the performance before fine-tuning (‘raw’) and after fine-tuning (‘opt.’) for different levels of quality (1-3 Poor, 4-6 Medium, 7-10 Excellent) and then provides an overall improvement in the H² score. The ‘gain’ column shows the percentage increase in the H² score after optimization.
read the caption
Table 1: Improvements in honesty rate and H² scores for Llama3-8b and Mistral-7b after the proposed two-stage fine-tuning.
🔼 This table presents the results of the two-stage fine-tuning method on Llama3-8b and Mistral-7b models. It shows the improvements in honesty rate and H2 scores (a comprehensive evaluation metric combining honesty and helpfulness) after applying the proposed method. The table is divided into two sections: proprietary models and open-source models. Each model’s raw performance (before fine-tuning), performance after fine-tuning with the proposed two-stage method, and the percentage gain are shown for both the honesty rate and the H2 score. The results highlight significant improvements in both metrics across all evaluated models, demonstrating the effectiveness of the fine-tuning approach in enhancing honesty and helpfulness.
read the caption
Table 1: Improvements in honesty rate and H2 scores for Llama3-8b and Mistral-7b after the proposed two-stage fine-tuning.
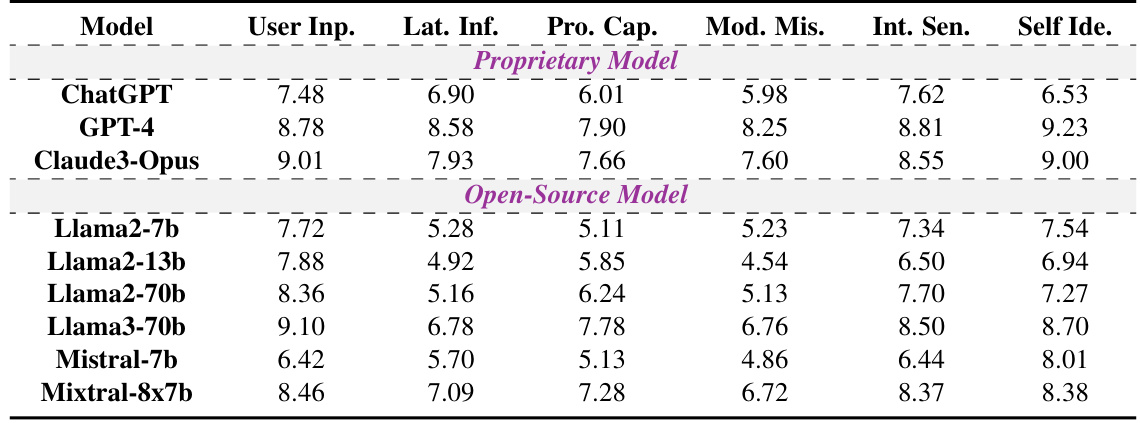
🔼 This table presents the average H² scores for each of the six categories in the HONESET dataset after applying the training-free method. The scores range from 1-10, with higher scores indicating better performance in honesty and helpfulness. The table is divided into proprietary and open-source models to allow for easy comparison.
read the caption
Table 12: Average scores for each Category in the optimized response across models

🔼 This table presents the results of a two-stage fine-tuning process applied to Llama3-8b and Mistral-7b large language models. It shows the improvement in honesty rate and H² score (a combined measure of honesty and helpfulness) for these models after undergoing the proposed fine-tuning. The table compares the raw (original) performance of the models with their performance after the first stage of fine-tuning, the second stage, and a combined, direct fine-tuning approach. The ‘gain’ column indicates the percentage increase in the H² score after fine-tuning.
read the caption
Table 1: Improvements in honesty rate and H² scores for Llama3-8b and Mistral-7b after the proposed two-stage fine-tuning.
Full paper#