↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current state-of-the-art dense object detection methods often struggle with a large number of false positive detections, particularly in complex scenes. This is because these models prioritize high recall, leading to many inaccurate bounding boxes. This problem significantly impacts applications relying on high precision, such as autonomous driving or medical image analysis.
To tackle this challenge, the researchers propose AIRS, a novel framework guided by Evidential Q-learning and a uniquely designed reward function. AIRS uses a top-down, hierarchical search to focus on the most promising image regions likely containing objects of interest. The evidential Q-learning mechanism encodes uncertainty to encourage the exploration of less-known areas, balancing exploration and exploitation for optimal accuracy. Experiments demonstrate that AIRS outperforms current state-of-the-art methods across various datasets, showcasing a significant improvement in detection accuracy and a reduction in false positives.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical issue in object detection: the high number of false positives. By introducing a novel framework that combines adaptive region selection with reinforcement learning, it offers a significant improvement in accuracy. This approach also has potential applications beyond object detection, opening new avenues in computer vision research. The theoretical analysis of convergence further strengthens its contribution to the field, providing a rigorous foundation for future work.
Visual Insights#

The figure compares the bounding boxes generated by GFocal, GFocal-V2, and AIRS. GFocal and GFocal-V2 produce many false positive bounding boxes (unnecessary boxes), whereas AIRS more accurately identifies and outlines the objects of interest.
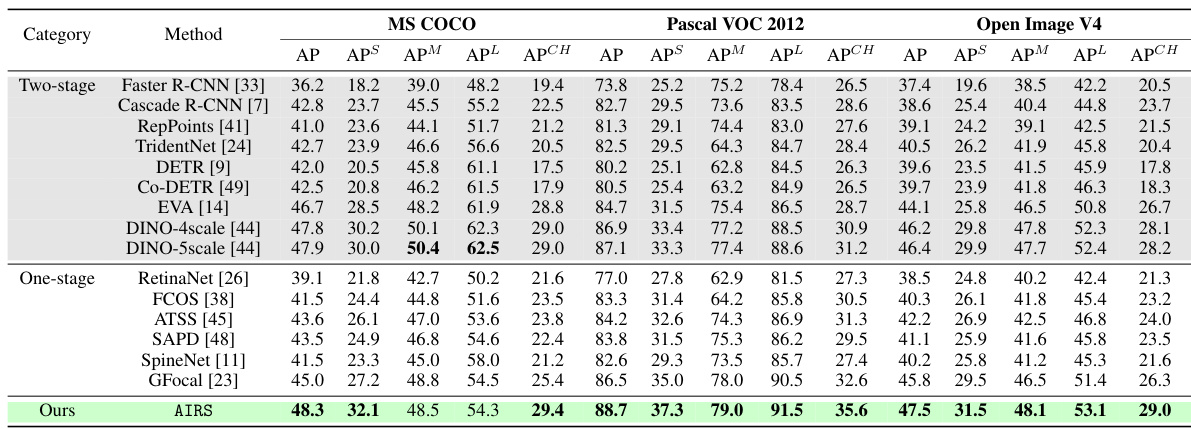
This table presents a quantitative comparison of the proposed AIRS model against several state-of-the-art (SOTA) object detection models on three benchmark datasets: MS COCO, Pascal VOC 2012, and Google Open Images V4. For each dataset, results are shown for the standard evaluation split, as well as a specifically created ‘challenging subset’ designed to evaluate performance on more difficult images with complex scenes and numerous small objects. The metrics used for comparison include Average Precision (AP), as well as AP for small, medium, and large objects (APS, APM, APL, respectively), and AP on the challenging subset (APCH).
In-depth insights#
AIRS Framework#
The AIRS (Adaptive Important Region Selection) framework is a novel approach to dense object detection that leverages reinforcement learning and a hierarchical search strategy. Its core innovation lies in guiding the search process using evidential Q-learning, which effectively balances exploration and exploitation of potentially valuable image regions. Starting with a coarse-grained search at higher levels of a feature pyramid, AIRS progressively refines its focus by selecting informative patches and discarding less promising ones. The use of epistemic uncertainty in the evidential Q-value encourages exploration of unknown regions, particularly in the early stages of training, enhancing the model’s ability to identify objects in complex or challenging scenes. This hierarchical and uncertainty-driven approach contrasts with traditional methods, which often produce a high number of false positives by prioritizing recall. By dynamically balancing exploration and exploitation, AIRS demonstrates superior performance and reduced false positives. The framework is theoretically well-founded, with provided convergence guarantees for its evidential Q-learning algorithm. Overall, AIRS offers a significant advancement in dense object detection.
Evidential Q-learning#
The proposed evidential Q-learning is a novel approach that addresses the limitations of traditional Q-learning in exploration-exploitation balance, particularly in the early stages of training. By incorporating epistemic uncertainty into the Q-value estimation, it encourages exploration of uncertain patches, especially during the initial phases of learning. This systematic exploration ensures adequate coverage of the search space, improving the identification of both valuable and informative patches in the hierarchical object detection framework. The use of evidential Q-networks allows for the encoding of uncertainty, leading to a more robust and reliable learning process. Further, the proposed method dynamically balances exploration and exploitation, which helps in avoiding the selection of low-quality patches and improving overall detection accuracy.
Hierarchical Search#
The concept of “Hierarchical Search” in object detection involves a multi-level, top-down approach to locate objects. Instead of processing the entire image at once, the model starts at a coarse level (low resolution), identifying potential regions of interest. This reduces computational cost and improves efficiency by focusing resources on promising areas. The model then progressively refines its search, moving to higher resolutions (finer granularity) within these selected regions for more accurate localization. This hierarchical strategy mimics human visual attention, where we initially focus on salient features and subsequently zoom in for detailed analysis. The inherent structure helps balance exploration and exploitation, systematically exploring uncertain areas while prioritizing high-value regions. By integrating reinforcement learning, the model learns which areas to focus on and adapt to image complexities dynamically. This method is especially advantageous in dealing with cluttered scenes or images with multiple, densely packed objects, ultimately improving both detection accuracy and efficiency.
Ablation Studies#
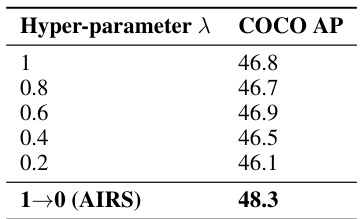
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper on object detection, this might involve removing specific modules (e.g., the reinforcement learning agent, the evidential Q-learning mechanism, or different components of the reward function). By observing the impact on performance metrics (e.g., precision, recall, mAP) after each ablation, researchers gain insights into the importance and effectiveness of each component. This process is critical for understanding the inner workings of the proposed model, verifying the contributions of novel components, and providing a basis for future model improvements. A well-designed ablation study should isolate the effects of specific components, avoiding confounding factors that could obscure the results. For instance, removing the RL agent while keeping other components intact helps to isolate the specific contribution of RL to the overall performance. The results should then be thoroughly analyzed and discussed to provide insights into design choices and potential areas for further improvement. Finally, ablation studies are crucial for demonstrating the novelty and effectiveness of a proposed model, compared to the baseline models, especially by providing evidence for the role of specific components in achieving improved performance in challenging scenarios.
Future Works#
Future research directions stemming from this adaptive important region selection (AIRS) framework for dense object detection could explore several promising avenues. Extending AIRS to video data presents a significant challenge and opportunity, requiring adaptation of the RL agent to handle temporal dependencies and motion cues effectively. The current reliance on ResNet-50 as the backbone could be expanded by investigating the integration of more powerful backbones, such as Swin Transformers or Vision Transformers, which have shown superior performance in other object detection tasks. Improving the robustness of AIRS to diverse lighting conditions, occlusions, and unusual object poses is crucial for real-world deployment, potentially requiring augmentation of the training data or more sophisticated uncertainty modeling techniques. A deeper theoretical analysis, potentially focusing on the convergence rates and sample complexity of the evidential Q-learning algorithm, would enhance the framework’s foundation. Finally, exploring the applicability of AIRS to other computer vision tasks beyond object detection, such as semantic segmentation or instance segmentation, warrants further research. These avenues hold potential for significant advancements in the field.
More visual insights#
More on figures
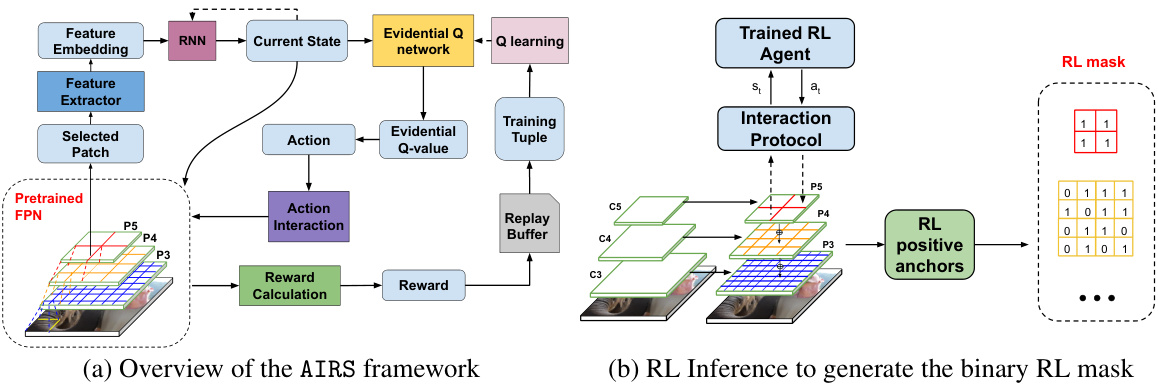
This figure illustrates the training and testing pipelines of the Adaptive Important Region Selection (AIRS) framework. The training pipeline (a) shows how the RL agent interacts with the FPN (Feature Pyramid Network) to select patches and generate training tuples. The testing pipeline (b) shows how the trained RL agent generates a binary mask that filters out unnecessary bounding boxes. The figure also visually explains the hierarchical search process used by AIRS.

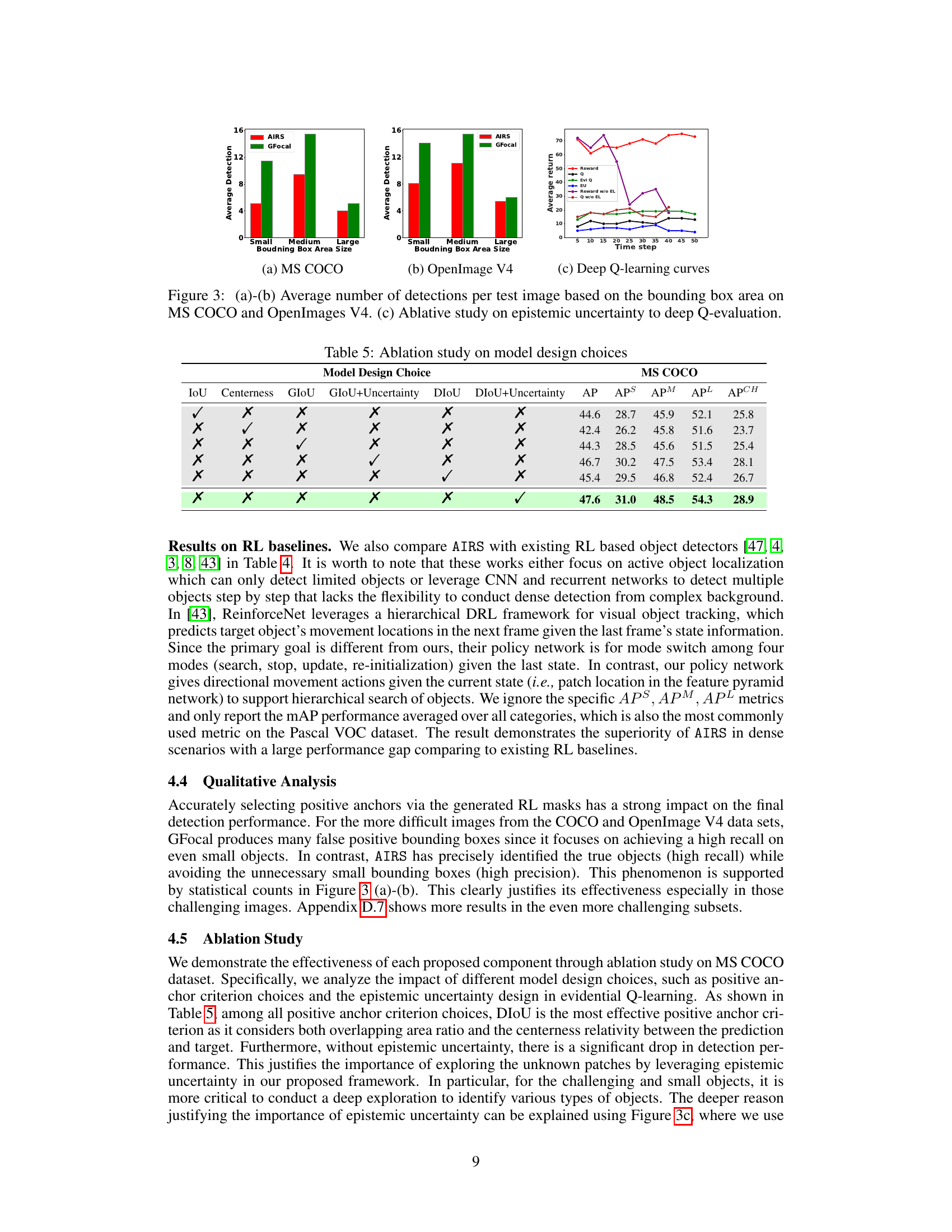
This figure presents a comparison of the average number of detections per image based on bounding box area size for the MS COCO and OpenImages V4 datasets, comparing the proposed AIRS model with GFocal. It also includes an ablative study showing the impact of epistemic uncertainty on deep Q-evaluation, demonstrating the effectiveness of incorporating uncertainty to guide exploration during the learning process. The graphs illustrate how AIRS improves detection performance for small and medium-sized objects, particularly in the OpenImages V4 dataset, by dynamically balancing exploration and exploitation and reducing false positives.
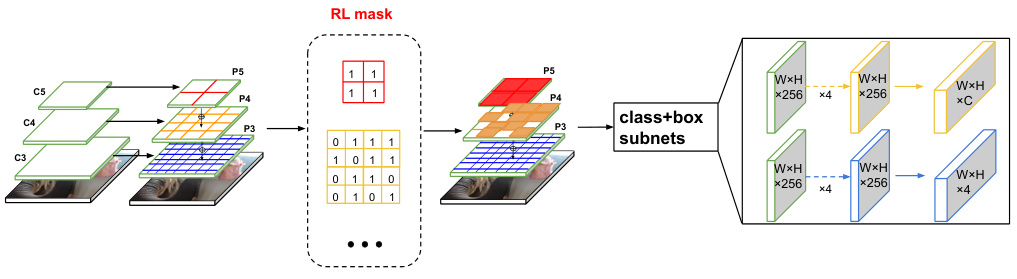
This figure illustrates the process of RL-augmented object detection. The input image is passed through a Feature Pyramid Network (FPN), generating multi-scale feature maps. An RL agent interacts with the FPN, selecting patches (regions) to analyze hierarchically, starting from coarser levels. The agent’s decisions are guided by an evidential Q-learning process, which incorporates uncertainty to balance exploration and exploitation. The result is a binary RL mask that filters out less informative patches, improving the accuracy of object detection in the subsequent ‘class+box’ subnets.

This figure illustrates the detailed workflow of the Adaptive Important Region Selection (AIRS) framework. It starts with a selected patch from the Feature Pyramid Network (FPN) which passes through a feature extractor and RNN to generate a state representation. The state is input to an evidential Q-network, which outputs evidential Q-values and uncertainty estimates for each action. The action interaction and reward calculation modules translate the action into the location of the next patch, balancing exploration and exploitation. The resulting training tuple is added to a replay buffer for Q-learning updates.

This figure shows a detailed workflow of the Adaptive Important Region Selection (AIRS) framework. It illustrates how the RL agent interacts with the feature pyramid network (FPN), generating state representations, obtaining evidential Q-values, selecting actions (downward or upward movements), and receiving rewards. The process involves generating state representations using an RNN, calculating evidential Q-values with epistemic uncertainty, selecting actions based on masked evidential Q-values, and updating the network parameters via Q-learning. The figure also shows the interaction protocol with the FPN and the calculation of reward values.
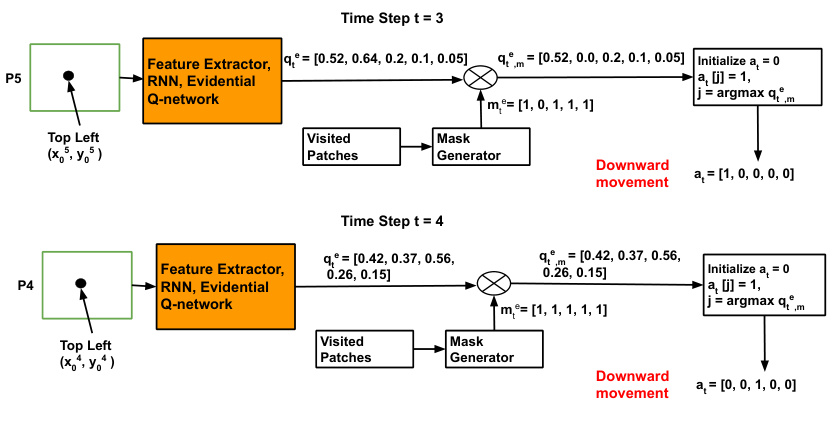
This figure illustrates the detailed workflow of the Adaptive Important Region Selection (AIRS) framework. It shows how the RL agent interacts with the environment (FPN), generates states, selects actions, receives rewards, and updates its policy through evidential Q-learning. The process involves generating feature embeddings, calculating evidential Q-values, applying masks to filter out invalid actions, and updating the agent’s policy based on rewards. The process continues until termination or reaching a maximum time step.

This figure compares the object detection results of GFocal and AIRS on an aerial dataset and a challenging subset of MS COCO. The images show that AIRS, guided by its reinforcement learning (RL) agent, effectively suppresses false positive bounding boxes (grey) that often result from detecting irrelevant background or partially covered objects. AIRS accurately identifies and keeps the true positive bounding boxes (red).

This figure presents the results of experiments comparing the average number of detections per image from the proposed AIRS model and a baseline model (GFocal) across three datasets (MS COCO, OpenImages V4, and Pascal VOC 2012). The graphs in (a) and (b) show a breakdown of the number of detections by bounding box size (small, medium, large), revealing how AIRS effectively reduces false positives, especially for smaller objects. Graph (c) depicts the Q-learning curves, showcasing the effect of incorporating epistemic uncertainty (EU) into the AIRS model. The comparison demonstrates that the inclusion of EU significantly improves the model’s ability to explore under-represented regions of the feature space, leading to better overall performance.

This figure shows a qualitative comparison of object detection results between GFocal and AIRS on three different datasets (COCO, PASCAL VOC 2012, and OpenImages V4). For each dataset, two images are displayed, one showing the GFocal results and the other showing the AIRS results. Red boxes are used to represent the bounding boxes predicted by the models. The figure aims to illustrate AIRS’ ability to reduce false positive detections while maintaining high recall compared to GFocal, especially in complex scenarios with many small or partially occluded objects.
More on tables
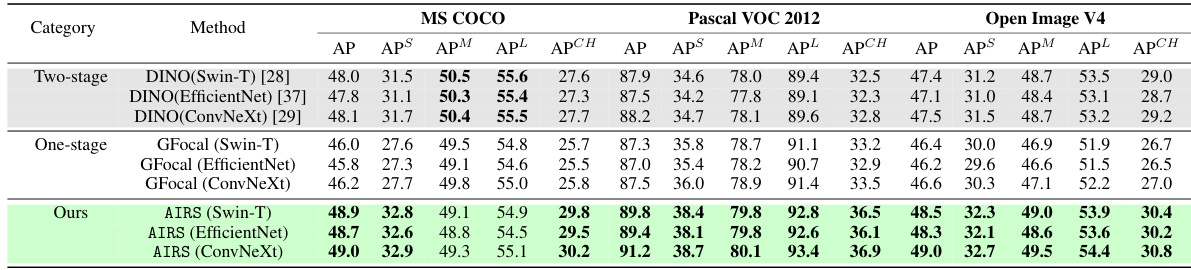
This table presents a quantitative comparison of the proposed AIRS model against various state-of-the-art (SOTA) object detection models on three benchmark datasets: MS COCO, Pascal VOC 2012, and Google Open Images V4. For each dataset, the performance is evaluated using Average Precision (AP), broken down by object size (APS for small objects, APM for medium, APL for large) and also on a challenging subset of images (APCH) designed to evaluate performance in complex scenes. The table allows for a direct comparison of the proposed method against both one-stage and two-stage detectors, highlighting its strengths and potential weaknesses across different scenarios.
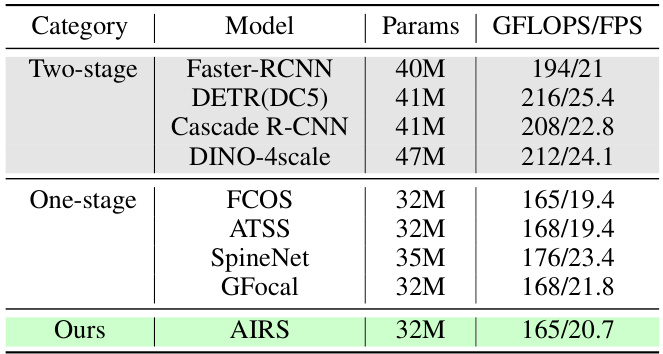
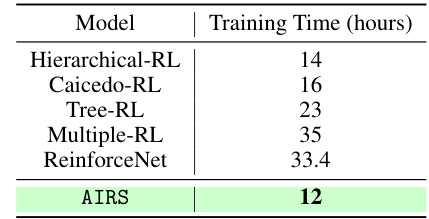
This table compares the inference speed and the number of parameters of different models. It shows that AIRS, despite being a novel object detection method using reinforcement learning, achieves comparable inference speed to other state-of-the-art (SOTA) one-stage and two-stage object detectors.

This table compares the performance of the proposed AIRS model against other existing RL-based object detection methods. The mAP (mean Average Precision) metric is used to evaluate the performance of each model. AIRS significantly outperforms the other methods.

This ablation study analyzes the impact of different model design choices, including positive anchor criterion choices and the epistemic uncertainty design in evidential Q-learning, on the object detection performance. The results show that DIoU is the most effective positive anchor criterion and that the epistemic uncertainty significantly improves detection performance.

This table presents a comparison of the proposed AIRS model’s object detection performance against various state-of-the-art (SOTA) methods across three benchmark datasets: MS COCO, Pascal VOC 2012, and Open Images V4. For each dataset, the performance is evaluated using Average Precision (AP), and further broken down into AP for small, medium, and large objects (APS, APM, APL). Additionally, a challenging subset (‘CH’) of images from each dataset is used for evaluation to highlight the model’s robustness in handling complex scenes. The results demonstrate AIRS’s superior performance, particularly in detecting small objects and in challenging scenarios.
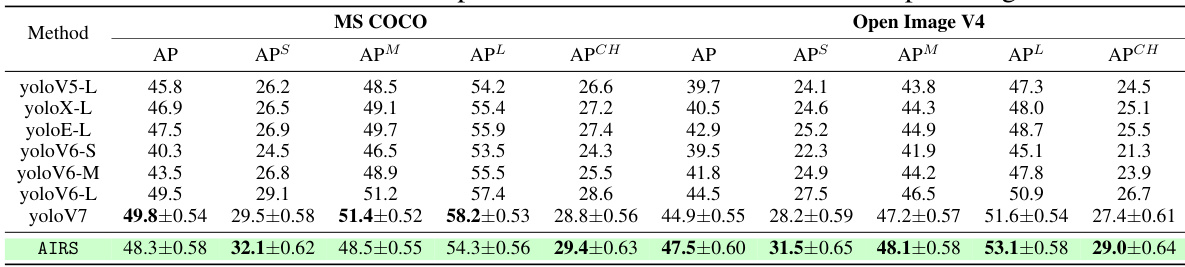
This table presents a quantitative comparison of the proposed AIRS model against several state-of-the-art (SOTA) object detection methods across three benchmark datasets: MS COCO, Pascal VOC 2012, and Google Open Images V4. For each dataset, the performance is evaluated using Average Precision (AP), and broken down further into AP for small, medium, and large objects (APS, APM, APL). Additionally, a challenging subset (‘CH’) of images is used for evaluation, focusing on more complex scenarios with smaller objects, object overlaps, and dense object arrangements. The results highlight the superior performance of AIRS, especially in the challenging subsets and small objects.
This table presents a comparison of the object detection performance of the proposed AIRS model against several state-of-the-art (SOTA) methods across three benchmark datasets: MS COCO, Pascal VOC 2012, and Google Open Images V4. For each dataset, the table includes results for the standard evaluation split and a challenging subset designed to evaluate the models’ robustness on more complex scenes. The performance metrics reported are Average Precision (AP), and its breakdown into AP for small (APS), medium (APM), and large (APL) objects and AP for the challenging subset (APCH).

This table presents a comparison of the Average Precision (AP) metric for GFocal and AIRS on two challenging datasets: an aerial parking lot dataset and a newly created subset of the MS COCO dataset. Both datasets are characterized by a high density of small, cluttered objects, making object detection particularly difficult. The AP, APS, APM, and APL columns represent the overall average precision and average precision for small, medium, and large objects, respectively. The results demonstrate AIRS’s improved performance, especially on these challenging datasets.

This table presents the ablation study results focusing on the impact of different base detectors on the performance of RL masks. It compares the Average Precision (AP), Average Precision for small objects (APS), Average Precision for medium objects (APM), Average Precision for large objects (APL), and Average Precision on a challenging subset (APCH) across three different one-stage detectors (RetinaNet, FCOS, ATSS). For each detector, it shows the results without RL augmentation, with RL augmentation trained on its own FPN, and with RL masks transferred from another detector. The results indicate the effectiveness of RL masks in enhancing the performance across all detectors and datasets.
This table presents a quantitative comparison of the proposed AIRS model against several state-of-the-art (SOTA) object detection methods across three benchmark datasets: MS COCO, Pascal VOC 2012, and Google Open Images V4. For each dataset, performance is evaluated using Average Precision (AP), and broken down further by object size (small, medium, large) and a challenging subset of images. The challenging subset contains images with complex scenes, significant object occlusion, and a higher proportion of smaller objects, designed to assess the models’ robustness in more difficult scenarios.
Full paper#