TL;DR#
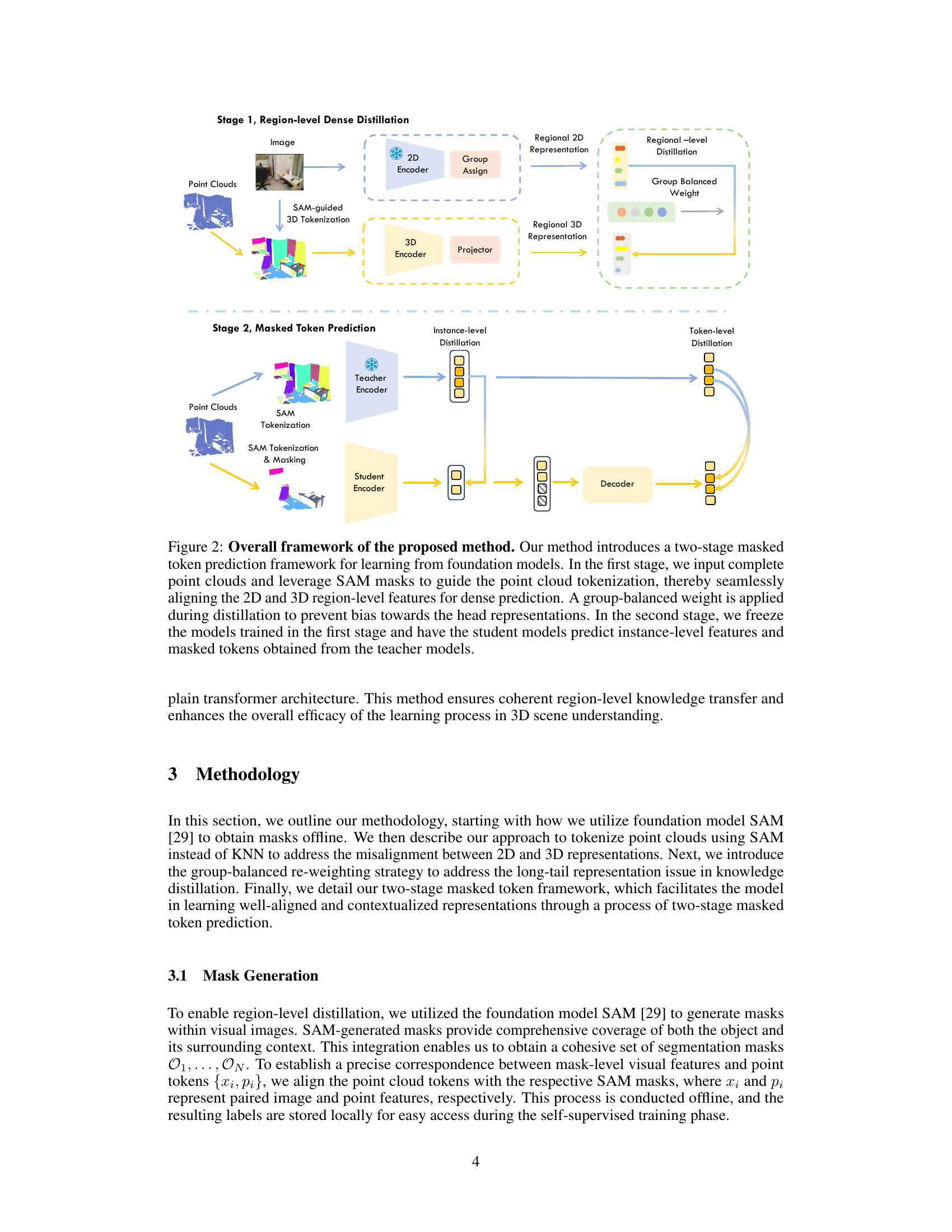
Current methods for 3D scene understanding face challenges like misalignment between 2D and 3D representations and long-tail distributions in 3D datasets, limiting the effectiveness of knowledge distillation from 2D foundation models. Traditional KNN-based tokenization methods also create conflicts during region-level knowledge distillation.
This research introduces a novel SAM-guided tokenization method and a group-balanced re-weighting strategy to overcome these challenges. The proposed two-stage masked token prediction framework incorporates a SAM-guided tokenization process and a group-balanced re-weighting technique to enhance dense feature distillation and address the long-tail problem. Experimental results across multiple datasets demonstrate significant improvements over existing state-of-the-art methods in 3D object detection and semantic segmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D scene understanding because it proposes a novel SAM-guided masked token prediction framework that significantly improves the accuracy of 3D object detection and semantic segmentation. It directly addresses the limitations of existing knowledge distillation methods by seamlessly aligning 2D and 3D representations and handling long-tail distributions in 3D datasets. This opens new avenues for research in self-supervised learning for 3D data, leading to more effective and robust 3D vision systems.
Visual Insights#
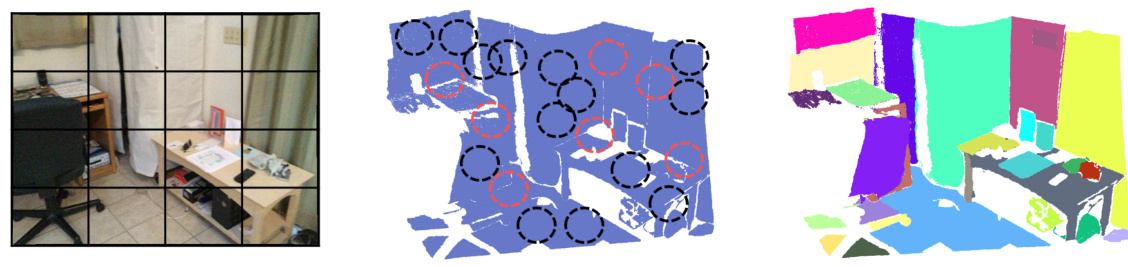
🔼 This figure compares three different tokenization methods for 3D point clouds: patch-based 2D tokenization, KNN-based 3D tokenization, and the proposed SAM-guided 3D tokenization. It highlights how the KNN method can incorrectly group points from distinct regions (as indicated by the red circles), while the SAM-guided method leverages segmentation masks to ensure accurate region-level alignment. This accurate alignment is crucial for effective knowledge distillation in 3D scene understanding.
read the caption
Figure 1: The comparison of tokenization methods. In Section 3.2, we present a detailed comparison of our proposed tokenization method to the previous KNN-based approach. As shown in the red circle, the KNN-based method may inadvertently group points from different SAM regions into the same tokens, leading to potential confusion within the 3D network. In contrast, our method effectively employs SAM masks in tokenization to ensure seamless region-level knowledge distillation, thereby avoiding these issues.
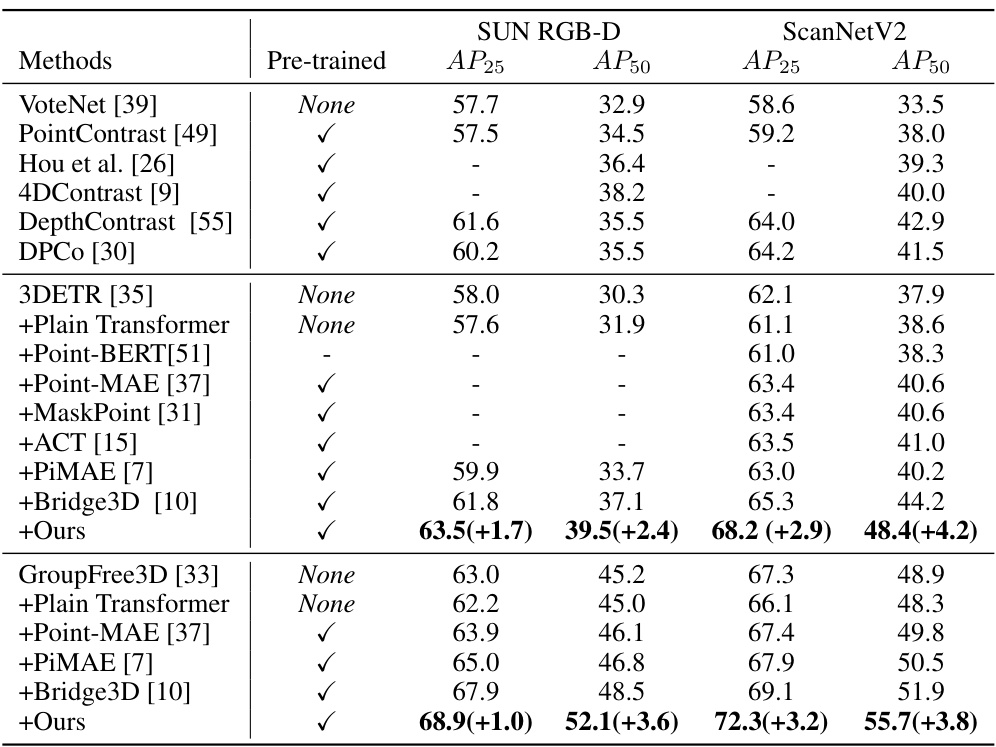
🔼 This table presents the results of 3D object detection experiments conducted on two benchmark datasets: ScanNet and SUN RGB-D. The performance of various methods, including the proposed approach, is evaluated using Average Precision (AP) at two Intersection over Union (IoU) thresholds (0.25 and 0.5). The table allows for a comparison of different approaches in terms of their accuracy in detecting 3D objects within the scenes.
read the caption
Table 1: 3D object detection results on ScanNet and SUN RGB-D dataset. We adopt the average precision with 3D IoU thresholds of 0.25 (AP25) and 0.5 (AP50) for the evaluation metrics.
In-depth insights#
SAM-Guided Tok#
The heading “SAM-Guided Tok” likely refers to a novel tokenization method in 3D scene understanding, leveraging the power of Segment Anything Model (SAM). This approach likely improves upon traditional methods like KNN by directly incorporating SAM’s region-level segmentation masks. This integration ensures a tighter alignment between 2D image features (from SAM) and 3D point cloud features, leading to more effective knowledge distillation from 2D foundation models to 3D models. The core idea is that the segmentation masks generated by SAM guide the grouping of 3D point cloud data into tokens, which are then used in a transformer-based architecture. This should significantly reduce information loss and improve the overall quality of 3D feature representations and downstream performance in tasks like object detection and semantic segmentation. A key advantage is the avoidance of potentially conflicting token groupings that can occur with KNN methods when regions overlap. The use of SAM thus provides more precise and semantically meaningful tokens, which are better suited for tasks involving region-level understanding. Consequently, a SAM-guided tokenization technique is a substantial improvement over existing approaches for 3D scene understanding tasks.
2-Stage Prediction#
A two-stage prediction approach in a deep learning context often signifies a staged process designed to improve accuracy and efficiency. The first stage typically involves pre-training or feature extraction, building a strong foundation for subsequent tasks. This could involve learning generalizable representations from large amounts of unlabeled data or creating robust feature embeddings. The second stage then uses the output from the first stage, applying specialized models or refinement techniques to tackle the specific prediction problem at hand. This refined approach is particularly effective for complex tasks, like 3D scene understanding, where it allows for a separation of concerns: learning robust features first, and then using them to tackle the prediction challenge. Computational efficiency could be another driver; simpler models are used in the initial stage, while complex and specialized models are employed later, leveraging the pre-computed representations. The approach is valuable because of its potential to improve accuracy by separating the feature learning process from the prediction process, allowing more efficient model training, and better generalization ability.
Long-Tail Handling#
Addressing the long-tail problem in 3D scene understanding is crucial for robust model generalization. Standard knowledge distillation techniques often fail to effectively transfer knowledge from 2D foundation models to 3D models because of the class imbalance present in 3D datasets. This imbalance leads to overfitting on common classes and poor performance on rare classes. Strategies to mitigate this include re-weighting the loss function, assigning higher weights to samples from under-represented classes. SAM-guided tokenization helps by ensuring consistent feature representations for similar objects across different regions, improving the quality of knowledge transfer. Further enhancement can come from methods that generate pseudo-labels for under-represented classes in a self-supervised learning setting, providing additional supervisory signals during training. A combination of these techniques, applied strategically, is often more effective than any single method alone. Future work could explore more sophisticated sampling or data augmentation techniques tailored to the 3D long-tail problem.
3D Foundation Models#
The concept of “3D Foundation Models” represents a significant advancement in 3D computer vision. It leverages the success of large-scale 2D foundation models by extending their capabilities to the three-dimensional world. Key challenges in this area include the inherent differences between 2D and 3D data representations, the scarcity of large-scale 3D annotated datasets, and the computational cost associated with processing 3D data. Addressing these challenges requires innovative approaches to knowledge distillation from 2D to 3D, efficient 3D data representation methods (e.g., point clouds, meshes, voxels), and the development of novel self-supervised learning techniques for pre-training 3D models. Successful 3D foundation models will likely rely on multi-modal learning, incorporating data from multiple sources such as images, point clouds, and text to improve understanding and generalization. Furthermore, the development of robust and scalable 3D foundation models holds immense potential for various applications, including autonomous driving, robotics, and virtual/augmented reality. Research in this field is actively exploring different architectures, training strategies, and evaluation metrics to overcome the limitations and unlock the full potential of 3D foundation models.
Future Directions#
Future research could explore enhancing the SAM-guided tokenization method by incorporating more sophisticated segmentation techniques or exploring alternative tokenization strategies to further improve the alignment between 2D and 3D representations. Investigating more advanced masked feature prediction methods, perhaps incorporating techniques from other cross-modal learning domains, could boost performance. Extending the framework to handle larger-scale 3D datasets and more complex scenes remains a challenge, requiring efficient data processing and model scaling strategies. Finally, exploring applications beyond object detection and semantic segmentation, such as 3D scene generation or manipulation, represents a promising area of future research. Addressing the long-tail distribution problem in a more robust and generalizable way is crucial for broader applicability of the proposed framework. This could involve developing new data augmentation methods or exploring alternative loss functions.
More visual insights#
More on tables
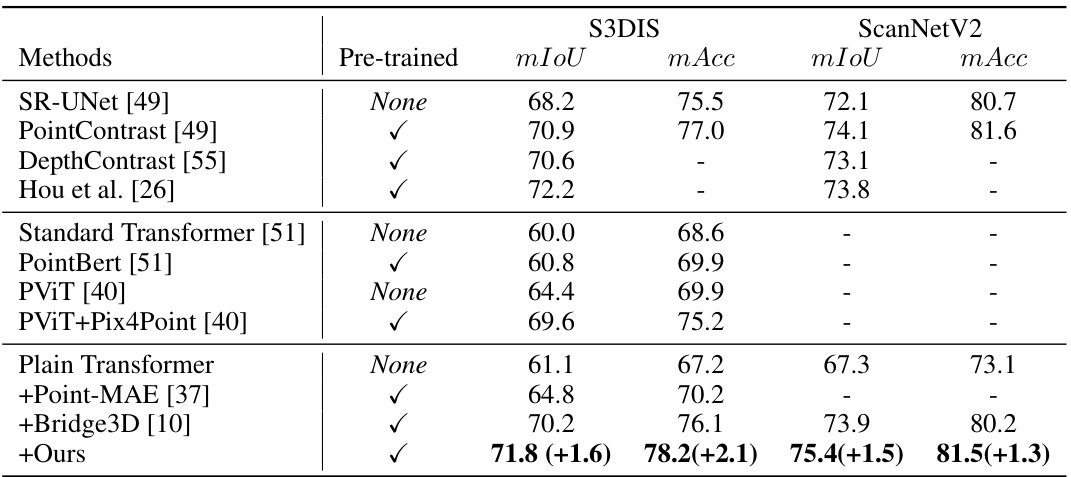
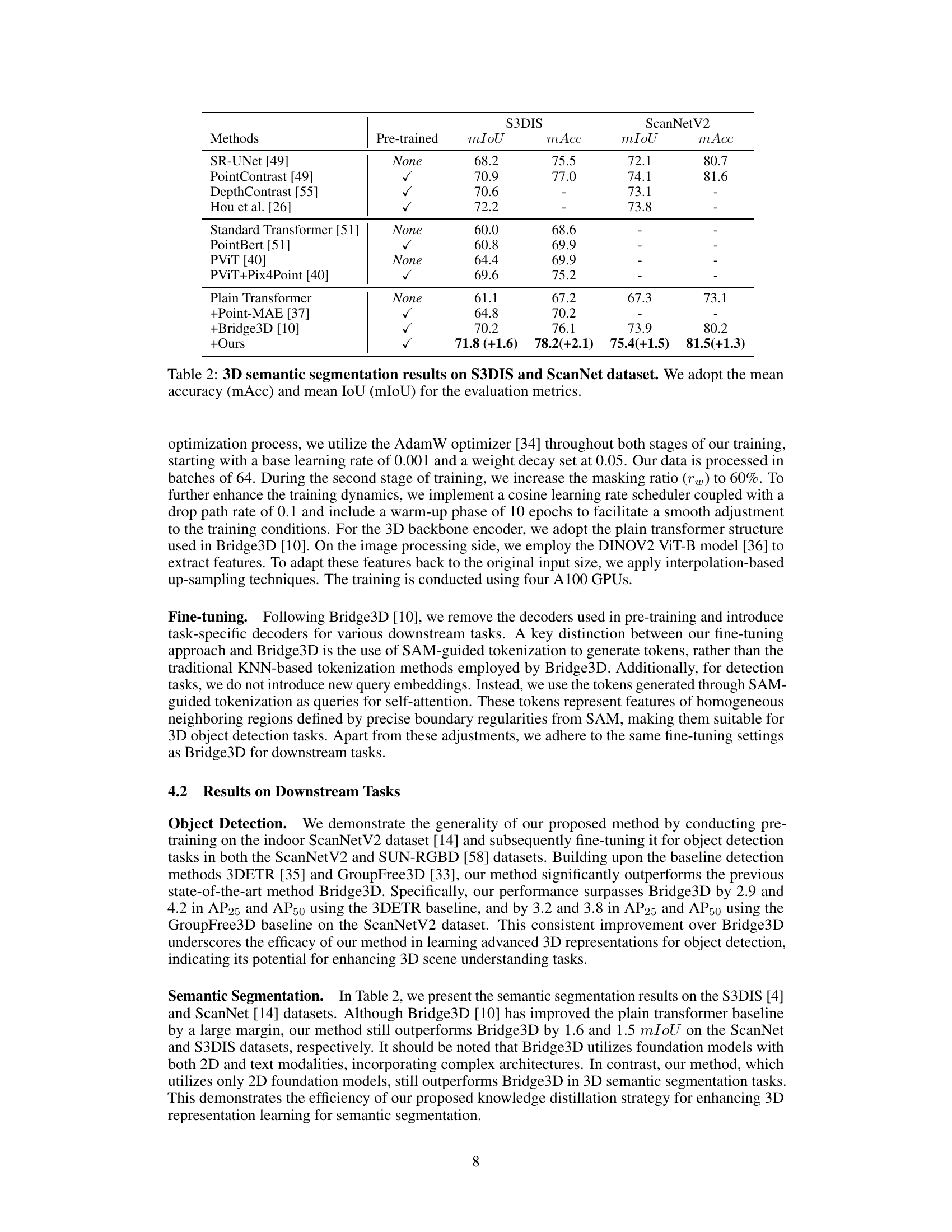
🔼 This table presents the results of 3D semantic segmentation experiments using different methods on the S3DIS and ScanNet datasets. The results are evaluated using mean Intersection over Union (mIoU) and mean accuracy (mAcc) metrics. The table compares the performance of various methods, both pre-trained and non pre-trained, highlighting the improvement achieved by the proposed method.
read the caption
Table 2: 3D semantic segmentation results on S3DIS and ScanNet dataset. We adopt the mean accuracy (mAcc) and mean IoU (mIoU) for the evaluation metrics.
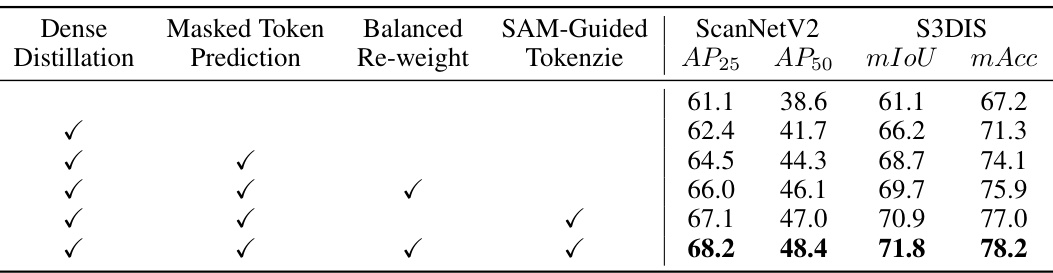
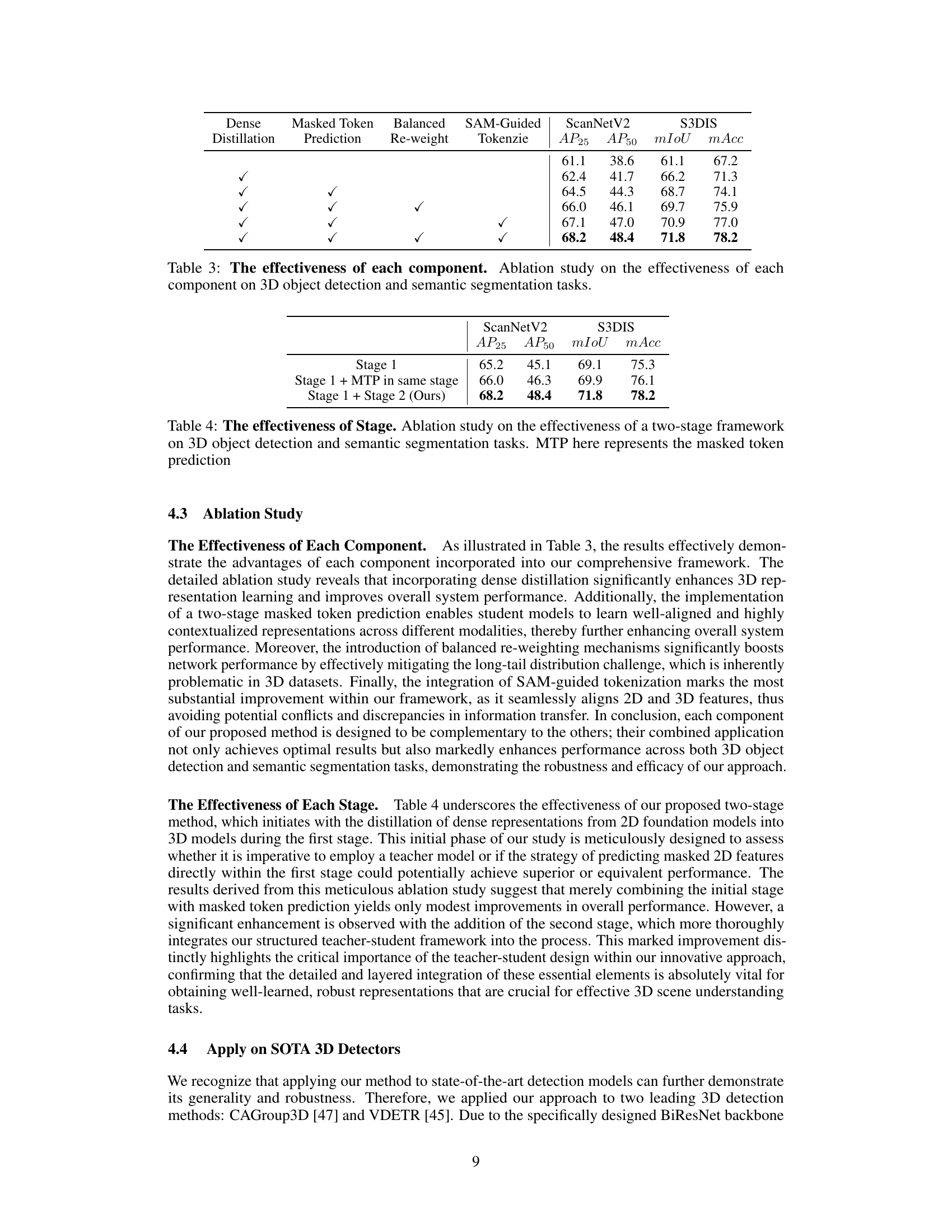
🔼 This ablation study analyzes the impact of each component (Dense Distillation, Masked Token Prediction, Balanced Re-weight, SAM-Guided Tokenization) on the overall performance of 3D object detection and semantic segmentation. It shows the individual and combined effects of these components on key metrics (AP25, AP50, mIoU, mAcc) across two datasets (ScanNetV2 and S3DIS). The results highlight the significance of each component and their synergistic contributions.
read the caption
Table 3: The effectiveness of each component. Ablation study on the effectiveness of each component on 3D object detection and semantic segmentation tasks.
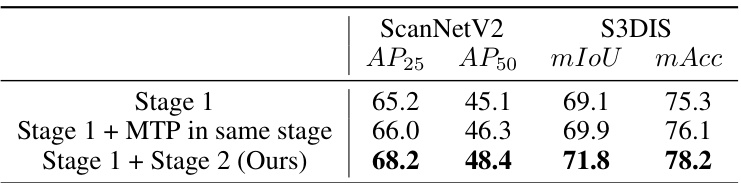
🔼 This table presents the ablation study results focusing on the effectiveness of the two-stage framework proposed in the paper. It compares the performance of using only the first stage (region-level dense distillation), the first stage with masked token prediction in the same stage, and the complete two-stage framework (ours). The metrics used for comparison are AP25, AP50, mIoU, and mAcc on both ScanNetV2 and S3DIS datasets.
read the caption
Table 4: The effectiveness of Stage. Ablation study on the effectiveness of a two-stage framework on 3D object detection and semantic segmentation tasks. MTP here represents the masked token prediction

🔼 This table presents the results of 3D object detection experiments conducted on the ScanNet dataset using two state-of-the-art detectors: CAGroup3D and VDETR. The results are shown with and without the application of the proposed method. The performance is measured using the average precision (AP) at two different IoU thresholds (AP25 and AP50). The table highlights the improvement in detection performance achieved by incorporating the proposed method into both baseline detectors.
read the caption
Table 5: 3D object detection results on ScanNet dataset based on CAGroup3D and VDETR.

🔼 This table compares the performance of the proposed method against other pre-training methods on the ScanNet dataset for both 3D object detection and semantic segmentation tasks. The results are presented using different evaluation metrics (AP25, AP50, mIoU) for each task, highlighting the performance gains of the proposed method over existing state-of-the-art approaches.
read the caption
Table 6: Comparison with other pre-training methods with different backbones on ScanNet dataset in 3D detection and semantic segmentation tasks.
Full paper#