↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current 3D generation methods struggle with creating realistic geometric details, resulting in overly smooth surfaces or inaccuracies in albedo maps. This is largely due to the scarcity of high-resolution geometric data in existing datasets, making it difficult for models to capture fine-grained details like stochastic patterns and bumps. This paper tackles this challenge by incorporating tactile sensing as an additional modality to improve the geometric details of generated 3D assets.
The researchers developed Tactile DreamFusion, a method that uses a lightweight 3D texture field to synthesize visual and tactile textures, guided by diffusion-based distribution matching losses. This ensures consistency between the visual and tactile representations while preserving photorealism. A multi-part editing pipeline allows for synthesizing different textures in various regions. The results show that Tactile DreamFusion significantly outperforms existing methods, providing customized and realistic fine geometric textures with accurate alignment between vision and touch.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to 3D asset generation that leverages tactile sensing to significantly improve the realism and detail of generated objects. This addresses a key limitation of existing methods that often produce overly smooth or inaccurate surfaces. The high-resolution tactile data provides crucial information for synthesizing fine-grained geometric details, leading to more realistic and customized 3D models. The method’s ability to incorporate multiple textures and its adaptability to both text-to-3D and image-to-3D tasks expand its applicability and potential impact on various applications.
Visual Insights#

This figure demonstrates the Tactile DreamFusion method. The left side shows the results of existing 3D generation methods from a text prompt (an avocado and a beanie), which lack fine geometric details. The right side illustrates how the proposed method incorporates tactile sensing to significantly improve the realism of generated 3D models by adding high-fidelity textures (avocado texture on a mug and phone case, woven texture on a beanie, toy flower, and miffy bunny). It highlights the ability to transfer these textures to different meshes and adapt to both text-to-3D and image-to-3D generation.

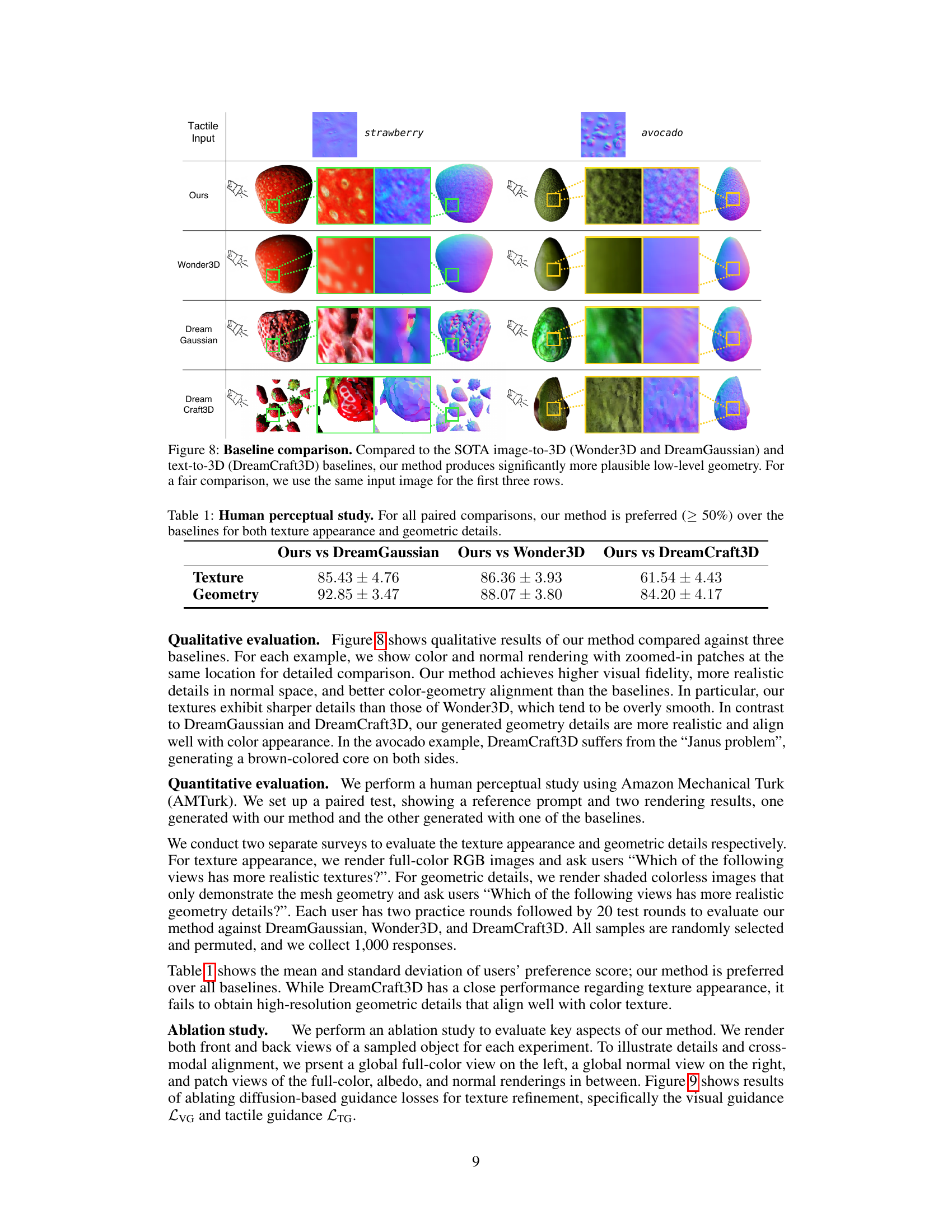
This table presents the results of a human perceptual study conducted using Amazon Mechanical Turk (AMT). The study compared the authors’ method against three baseline methods (DreamGaussian, Wonder3D, and DreamCraft3D) for both texture appearance and geometric detail. For each comparison, participants were shown renderings from two methods and asked which one was preferable. The table shows the percentage of times the authors’ method was preferred, indicating a strong preference for their method in both texture and geometry aspects.
In-depth insights#
Tactile 3D Synthesis#
Tactile 3D synthesis represents a significant advancement in 3D modeling, moving beyond visual cues to integrate the sense of touch. This approach offers the potential for greater realism and accuracy in generated 3D models, capturing fine geometric details often missed by purely visual methods. By incorporating tactile data, such as high-resolution texture information from tactile sensors, algorithms can generate models with realistic surface textures and geometry. This is particularly valuable for applications requiring high-fidelity representations, such as robotics, virtual reality, and medical imaging. Challenges remain in effectively fusing tactile and visual data, as well as in the efficient processing and representation of high-dimensional tactile information. Further research into innovative sensor technologies and advanced data fusion techniques will be crucial to unlock the full potential of tactile 3D synthesis, paving the way for truly immersive and realistic 3D experiences.
Diffusion-based Refinement#
Diffusion-based refinement leverages the power of diffusion models to enhance the quality of generated outputs. It refines initial results, which might be noisy or lack detail, by iteratively denoising them using a diffusion process. This approach allows for subtle adjustments and high-fidelity enhancements, capturing intricate details often missed by simpler methods. The process is guided by loss functions that ensure consistency with other modalities and input data. Multi-modal approaches can use information from visual or tactile data to further refine the results, improving alignment and detail. A key strength is its capability for incremental improvement – gradually refining the output, enabling detailed control and customization. However, computational cost is a factor to consider, and carefully choosing the noise schedule and loss function is vital for optimal results. High-resolution textures and geometric details are often achievable through this technique, though the success hinges on the quality of initial generation and the design of the refinement process. The effectiveness of diffusion-based refinement relies heavily on the underlying diffusion model and the quality of the training data.
Multi-Part Texture#
The concept of “Multi-Part Texture” in 3D generation signifies a significant advancement, enabling the synthesis of objects with diverse textures across different regions. This approach moves beyond the limitations of single-texture models by allowing for more realistic and detailed object representations. The core challenge lies in effectively segmenting the object into meaningful parts and aligning these segments with corresponding textures. Methods employing diffusion models and attention mechanisms show promise in achieving this, offering a way to automatically determine part boundaries based on input text or image prompts. The success hinges on the efficacy of these segmentation methods and the ability to seamlessly blend the resulting textures to produce visually coherent results. This technique opens doors to richer, more complex 3D model generation, exceeding the capabilities of traditional approaches that struggle with realistic fine-grained details. However, future research should focus on addressing the robustness and scalability of these methods, especially when dealing with intricate object geometries and a large number of texture types. Furthermore, considerations for computational efficiency and memory usage need to be addressed to make this powerful technique widely applicable.
High-Res Tactile Data#
High-resolution tactile data is crucial for achieving realistic 3D asset generation, as it allows capturing fine-grained geometric details often missed by visual sensors. The use of high-resolution tactile sensors, such as GelSight, is key, enabling the acquisition of detailed surface information at the millimeter scale. This data, comprising high-frequency texture information and precise depth maps, addresses the limitations of existing 2D and 3D datasets which often lack sufficient resolution or geometric detail. Preprocessing steps are essential, involving high-pass filtering to isolate high-frequency texture components and normal map conversion for seamless integration into the 3D pipeline. This tactile data serves as a powerful complementary modality, enriching the visual information to enable the generation of realistically textured 3D assets with unprecedented accuracy and detail. The high-resolution tactile data becomes the key to bridging the gap between visual appearance and physical texture.
Future Work: Alignment#
Future work on alignment in the context of this research paper could explore several key areas. Improving the alignment between visual and tactile data is crucial, as inconsistencies can lead to artifacts in the generated 3D models. This could involve developing more sophisticated registration techniques to ensure accurate correspondence between the two modalities. Another important area would be exploring different representations of tactile data, perhaps moving beyond simple normal maps to capture richer information about surface texture and material properties. Additionally, research into robustness and generalization is needed. The current approach relies on a specific tactile sensor; future work should investigate whether these findings generalize to other tactile sensors and varying surface types. Finally, extending the model to handle more complex geometries and multiple materials remains a significant challenge. Addressing these points will be critical for the future development of high-fidelity, realistic 3D generation with tactile feedback.
More visual insights#
More on figures

This figure illustrates the process of tactile data acquisition and pre-processing. It starts with using GelSight Mini to capture a tactile image from an object’s surface. The raw sensor output undergoes depth estimation using Poisson integration. High-pass filtering is then applied to extract high-frequency texture information. This filtered data is used for 2D texture synthesis using the Image Quilting algorithm, generating an initial texture map. Finally, the height map is converted into a normal map, providing both depth and surface normal information.

This figure showcases the TouchTexture dataset used in the Tactile DreamFusion paper. It displays six example objects from the dataset (avocado, strawberry, canvas bag, striped steel, corn, and rubber) along with their corresponding tactile normal maps and 3D height maps. Each image shows a GelSight sensor capturing a tactile patch from the object surface, illustrating the high-resolution tactile data collected. The normal maps highlight the fine-grained surface geometry details captured by the tactile sensor, while the 3D height maps provide a visual representation of the surface texture. The variety of textures shows the breadth of the dataset.

This figure provides a detailed overview of the proposed method’s pipeline. It starts with generating a base mesh using existing text-to-3D or image-to-3D methods. Then, it incorporates tactile data by training a 3D texture field to co-optimize visual and tactile textures using several loss functions. These losses ensure consistency between visual and tactile details, enhance photorealism, and maintain alignment between the two modalities. The process includes refining textures using visual and tactile guidance losses and utilizes a customized Texture Dreambooth to incorporate high-resolution tactile information.
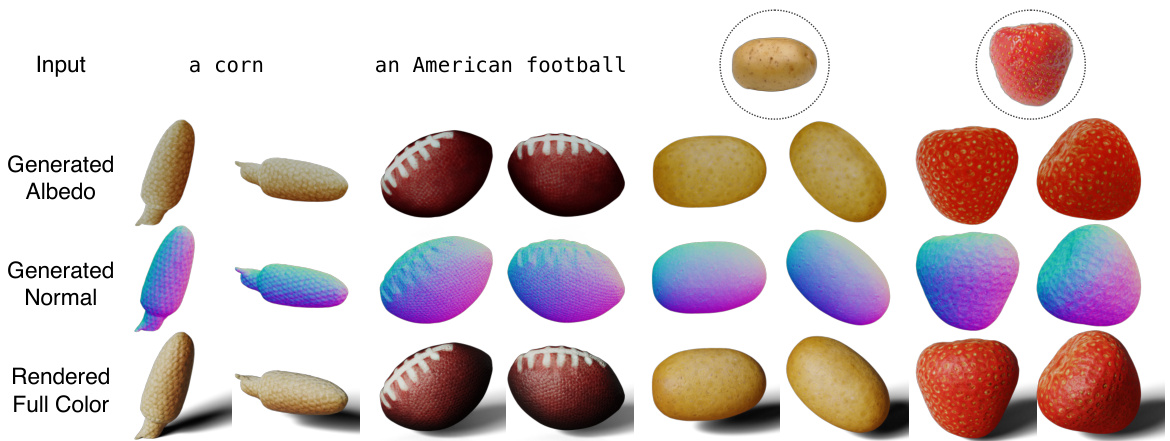
This figure shows the results of 3D object generation using a single texture, comparing the generated albedo, normal, and full-color renderings from two different viewpoints for four different objects (corn, American football, potato, and strawberry). The results demonstrate the effectiveness of the method in generating realistic textures and geometric details, and its applicability to both text-to-3D and image-to-3D generation tasks.

This figure shows the results of applying different tactile textures to the same 3D model of a coffee cup. The top row displays the generated albedo, normal maps, and full-color renderings from two different viewpoints for each texture. The bottom row shows the same renderings but with a more neutral color scheme, highlighting the geometry details generated from different tactile inputs. This demonstrates the ability of the Tactile DreamFusion method to produce diverse textures while maintaining the same underlying geometry.

This figure demonstrates the results of the proposed method’s ability to generate 3D objects with multiple textures assigned to different parts. Three examples are shown: a cactus in a pot, a goat sculpture, and a lamp. Each example shows the text prompt used (including the specification of textures for different parts), the generated albedo, the generated normal map, and the rendered full color image from two viewpoints. The zoom-in patches highlight the detail and consistency of the generated normal textures on each part of the objects. The color coding in the text prompts corresponds to the actual textures applied to the various parts of each object.

This figure compares the results of the proposed method against three state-of-the-art baselines for image-to-3D and text-to-3D generation. The comparison shows that the proposed method generates more realistic and detailed low-level geometric textures compared to the baselines, especially concerning fine-grained surface details. The same input images are used for a fair comparison in the first three rows.

This figure shows an ablation study on the tactile DreamFusion model. Three rows show results for the full model, a model without tactile guidance, and a model without visual guidance. The results demonstrate the importance of both visual and tactile guidance for generating high-fidelity geometric details and color alignment between visual and tactile modalities. Without tactile guidance, the resulting tactile texture lacks detail. Without visual guidance, there is a misalignment between the visual and tactile textures, indicating a lack of proper alignment between visual and tactile normal maps. The image highlights the impact of each component on the overall quality and realism of the generated 3D assets.

This figure shows an ablation study on the effect of tactile data preprocessing. The top row displays the results using the proposed method with preprocessing steps such as high-pass filtering and contact area cropping, which helps to generate realistic geometric details. The bottom row shows the results without preprocessing, demonstrating that the geometric details become flat and less realistic without these steps. This highlights the importance of proper preprocessing of tactile data for achieving high-fidelity 3D generation.

This figure demonstrates the importance of tactile input in generating high-fidelity 3D models with fine-grained geometric details. By comparing the results of the proposed method with and without tactile input, it highlights how the tactile information significantly improves the realism and accuracy of the generated 3D assets’ textures. The absence of tactile input results in overly smooth surfaces, lacking the intricate detail captured when tactile data is used.

This figure illustrates the process of multi-part segmentation using diffusion models. The input is an image of a cactus in a pot. The model processes the image using its attention maps to create two separate masks—one for the cactus and one for the pot. These masks are then used to guide a label field training process, allowing the model to generate different textures for each part of the object (cactus and pot).
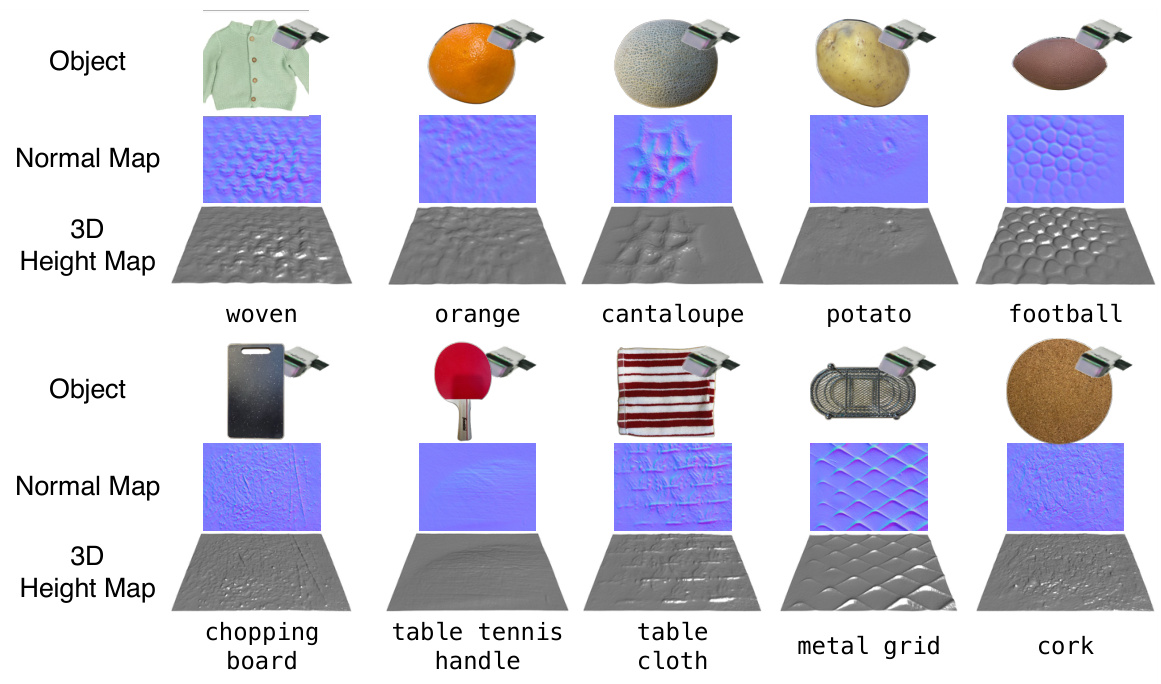
This figure shows 16 daily objects with their corresponding tactile normal maps and 3D height maps, showcasing the dataset used in the study called TouchTexture. Each object displays a different surface texture to highlight the diversity of tactile information captured. The dataset serves as input to the proposed method, enabling the 3D model to generate detailed surface textures and geometry.

This figure demonstrates the core idea of the Tactile DreamFusion method. The left side shows the limitations of existing text-to-3D methods, which produce overly smooth surfaces. The right side showcases the improvement achieved by incorporating tactile sensing, resulting in higher fidelity and more realistic geometric details in the generated 3D models. Both text-to-3D and image-to-3D applications are depicted.

This figure shows a comparison between the output of a standard 3D generation pipeline and the proposed method. The standard pipeline produces a smooth 3D model from a text or image input. The proposed method incorporates tactile data to generate a model with much finer details and more realistic textures. The method’s adaptability to image-to-3D generation is also showcased.

This figure shows a comparison of 3D object generation methods. The left side shows the results of a standard text-to-3D pipeline, resulting in a smooth object. The right side shows the results of the proposed method, which incorporates tactile sensing to generate high-fidelity geometric details. The figure demonstrates the method’s ability to generate realistic textures and its adaptability to image-to-3D tasks.
This figure shows a comparison between the traditional 3D generation pipeline (left) and the proposed method that incorporates tactile sensing (right). The traditional method often produces overly smooth surfaces, while the proposed method generates high-fidelity meshes with realistic geometric details by incorporating tactile information. The figure demonstrates the application of the method to both text-to-3D and image-to-3D tasks.
Full paper#