TL;DR#
Current multimodal large language models (MLLMs) fall short in understanding complex videos, especially when it comes to precisely describing specific objects or actions within a video (referential understanding). This is a problem because videos contain rich information that could be useful in various applications, but existing methods often rely on encoding the whole video holistically, failing to focus on user-specified regions of interest.
To solve this, the authors introduce Artemis, a new MLLM trained on the newly created VideoRef45K dataset. Artemis excels by extracting compact, target-specific video features using a novel three-stage training process. This approach results in significantly improved accuracy and descriptive capabilities compared to existing models. The authors demonstrate that Artemis can be successfully integrated with other video understanding tools to achieve even more sophisticated tasks, making it a valuable building block for future research in video-based referential understanding.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces Artemis, a novel approach to video-based referential understanding, a challenging task that current models struggle with. It offers a robust baseline for future research, and its efficient, three-stage training procedure makes it readily adaptable. The introduction of VideoRef45K, a new benchmark dataset, further enhances the value of this work for the community. This provides a foundation for finer-level video understanding, moving beyond superficial dialogue and unlocking deeper insights into complex video content.
Visual Insights#

🔼 This figure showcases Artemis’ performance on video-based referring tasks compared to other state-of-the-art Multimodal Large Language Models (MLLMs). It demonstrates Artemis’s superior ability to accurately and comprehensively answer complex questions about video content, highlighting its ability to avoid hallucinations and produce more complete descriptions than other models. The examples in the figure illustrate various aspects of video understanding including object behavior, movement and scene description.
read the caption
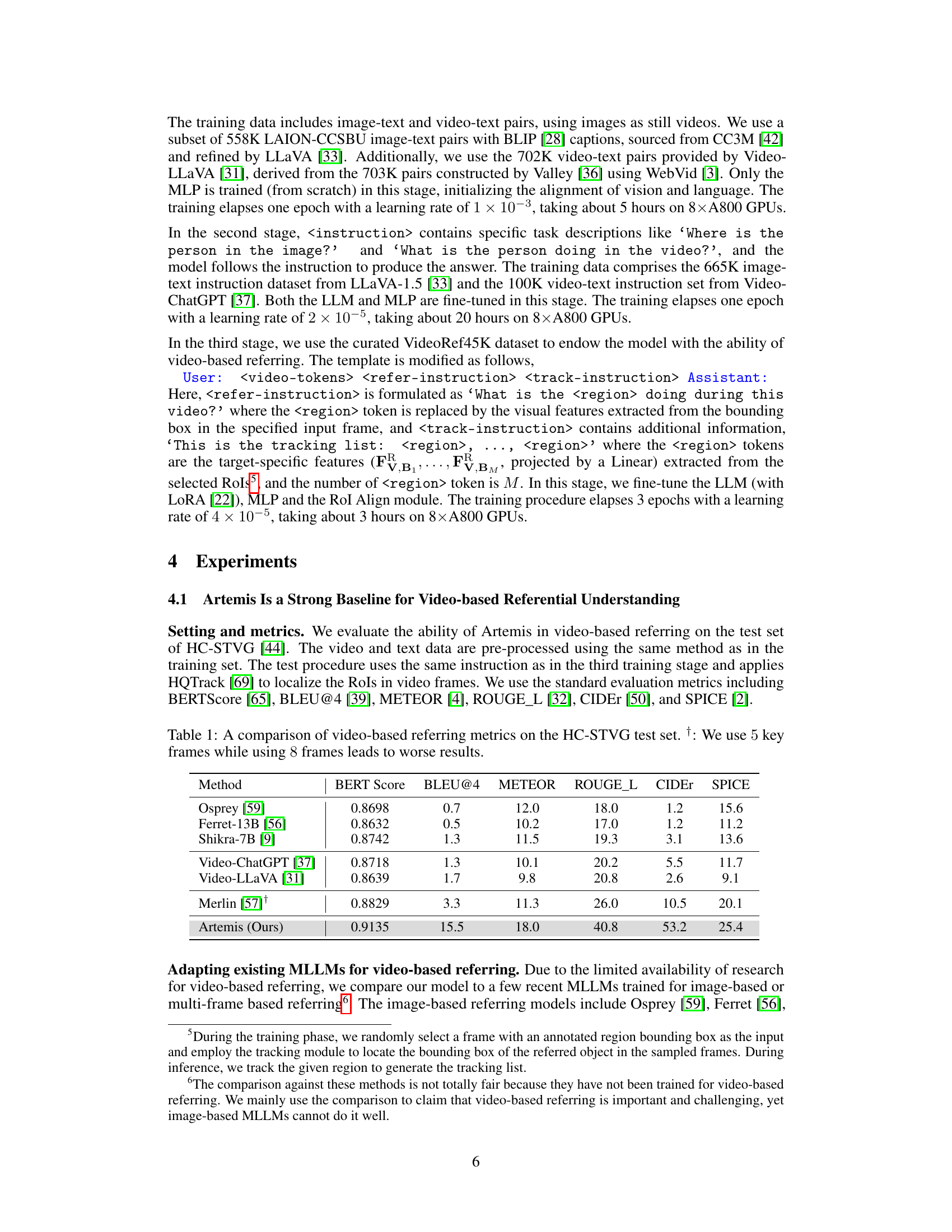
Figure 1: Artemis' ability in video-based dialogue. Notably, Artemis excels particularly in video-based referring, outperforming the existing MLLMs including Merlin [57] and Video-LLaVA [31] lacking comprehensiveness and Osprey [59] suffering hallucination.
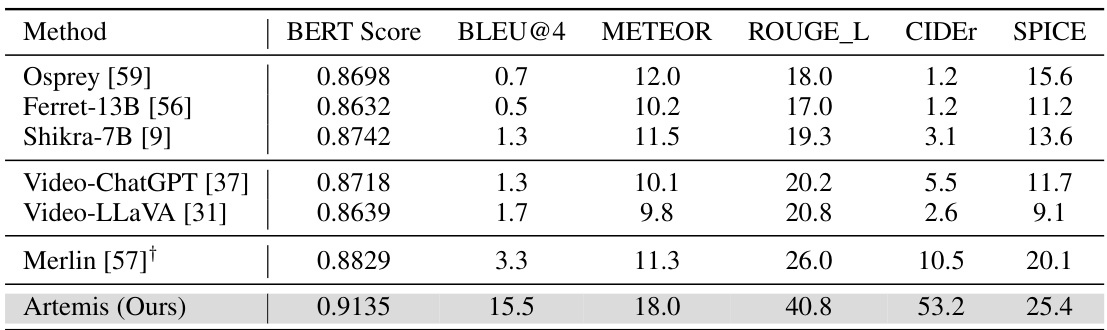
🔼 This table presents a comparison of the performance of different video-based referring models on the HC-STVG test set. The metrics used are BERTScore, BLEU@4, METEOR, ROUGE-L, CIDEr, and SPICE, which are common evaluation metrics for assessing the quality of generated text descriptions. The table highlights Artemis’s superior performance compared to other models, achieving significantly higher scores across all metrics. The † symbol indicates that the Merlin model uses 5 key frames for evaluation, as using 8 frames led to decreased performance.
read the caption
Table 1: A comparison of video-based referring metrics on the HC-STVG test set. †: We use 5 key frames while using 8 frames leads to worse results.
In-depth insights#
VideoRef45K#
The mention of “VideoRef45K” strongly suggests a novel dataset created for the research paper, likely focusing on video-based referential understanding. This dataset’s name implies it contains approximately 45,000 video-question-answer pairs, a significant scale for training and evaluating complex video understanding models. The “Video” prefix indicates that the data consists of video clips, and “Ref” likely refers to the referential nature of the task, possibly involving locating and describing specific objects or events within the videos using natural language questions. The dataset’s scale and focus indicate a commitment to rigorous benchmarking and substantial advancement in the field, likely addressing limitations of existing datasets that may be smaller, less diverse, or simpler in their video content. VideoRef45K addresses a need for more complex and comprehensive video understanding benchmarks, moving beyond simpler image-based or short video tasks. Its creation demonstrates a significant contribution to the research community, providing a valuable resource for future work in advanced video comprehension.
Artemis’s Design#
Artemis’s design is centered around efficiently extracting target-specific information from video data to enable accurate referential understanding. This is achieved through a three-stage training process that leverages a combination of spatial, temporal, and target-specific features. Instead of using raw video features directly, Artemis employs a Region-of-Interest (RoI) tracking and selection mechanism. This intelligent feature extraction ensures that the model focuses on the most relevant visual information, leading to enhanced performance and computational efficiency. The architecture utilizes an off-the-shelf tracking algorithm to pinpoint the target throughout the video and then employs K-means clustering to select a smaller subset of representative RoIs. This approach effectively balances compactness, diversity and computational cost. The model’s three-stage training strategy begins with video-text pre-training, progresses to instruction fine-tuning, and concludes with video-based referential understanding. This incremental approach allows the model to gradually acquire the ability to accurately answer complex video-referring questions. The framework’s design demonstrates an insightful strategy to address the challenges of processing high-dimensional video data in the context of visual language models.
Rol Tracking#
The effectiveness of Region of Interest (RoI) tracking is paramount for achieving robust video-based referential understanding. Accurate RoI tracking ensures that the model consistently focuses on the target object throughout the video, even amidst movement, occlusion, or changes in appearance. The choice of tracking algorithm significantly impacts performance; a high-quality tracker is crucial to maintaining precision and reducing false positives or negatives. Integration with advanced object detection and feature extraction methods can further enhance tracking robustness. Strategies for handling tracking failures, such as employing multiple trackers or re-initialization techniques, should also be carefully considered to improve overall system reliability. Finally, the efficiency and computational cost of the chosen tracking method should be evaluated, as real-time or near real-time performance is often desirable for interactive video applications. A well-designed RoI tracking module directly impacts the success and practicality of video-based referring models.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a research paper, they are crucial for understanding which aspects are essential for achieving the reported performance. A well-designed ablation study isolates variables, testing the impact of each feature in a controlled manner. For instance, if a model uses multiple visual features, an ablation study might evaluate performance when using only spatial, only temporal, or a combination of both. By observing performance changes after removing specific features, researchers can determine which features are critical for model success and identify potential areas for improvement. The results usually highlight the relative importance of different components and confirm the design choices made by showing the impact of removing particular parts. Furthermore, robust ablation studies strengthen the overall claims of the paper, showcasing the effectiveness and necessity of each proposed component. They also provide valuable insights into the model’s architecture and how different modules interact, leading to a deeper understanding of the underlying mechanisms. Without a well-executed ablation study, the results can lack credibility, limiting the significance of any conclusions drawn from the research. Thus, the section is crucial to verify and validate the proposed method.
Future Work#
The authors mention several promising avenues for future research. Improving the RoI tracking and selection mechanism is crucial, as current methods rely on readily available but potentially suboptimal techniques. Exploring more sophisticated methods, perhaps leveraging advanced video understanding models or incorporating information theory principles, could significantly enhance the accuracy and representativeness of selected video features. Developing more robust and efficient feature extraction techniques is another area of focus. While the current approach reduces dimensionality and computational burden, investigating alternative feature encodings or more advanced techniques for capturing spatiotemporal information in videos would improve overall model performance. Further development may involve exploring more advanced multimodal language models (MLLMs) for enhanced comprehension and response generation. The effectiveness of the proposed model relies heavily on the underlying MLLM’s abilities, suggesting the possibility of further performance gains by utilizing stronger MLLMs or fine-tuning the model on larger, more diverse video-text datasets. Finally, the benchmark dataset could be improved by introducing more varied and complex video scenarios. Expanding the dataset’s scope to include diverse action types, more intricate interactions between objects, and longer videos would present a more challenging and realistic evaluation of video-based referential understanding systems.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of Artemis, a multimodal large language model designed for video-based referential understanding. The left panel shows the overall framework, where the model takes a user query and video features (spatial, temporal, and target-specific) as input and generates a textual answer. The right panel details the RoI (Region of Interest) tracking and selection process used to extract the target-specific video features. This involves tracking a bounding box around the target object across frames, selecting key frames with relevant features, and then using a clustering method to obtain a compact representation. The different IDs in the right panel show the results of the clustering process.
read the caption
Figure 2: Left: the overall framework of Artemis, where an MLLM receives a text prompt together with spatial, temporal, and target-specific video features, and produces the answer. Right: the RoI tracking and selection mechanism to generate target-specific features. We use different IDs to show the clustering result. This figure is best viewed in color.
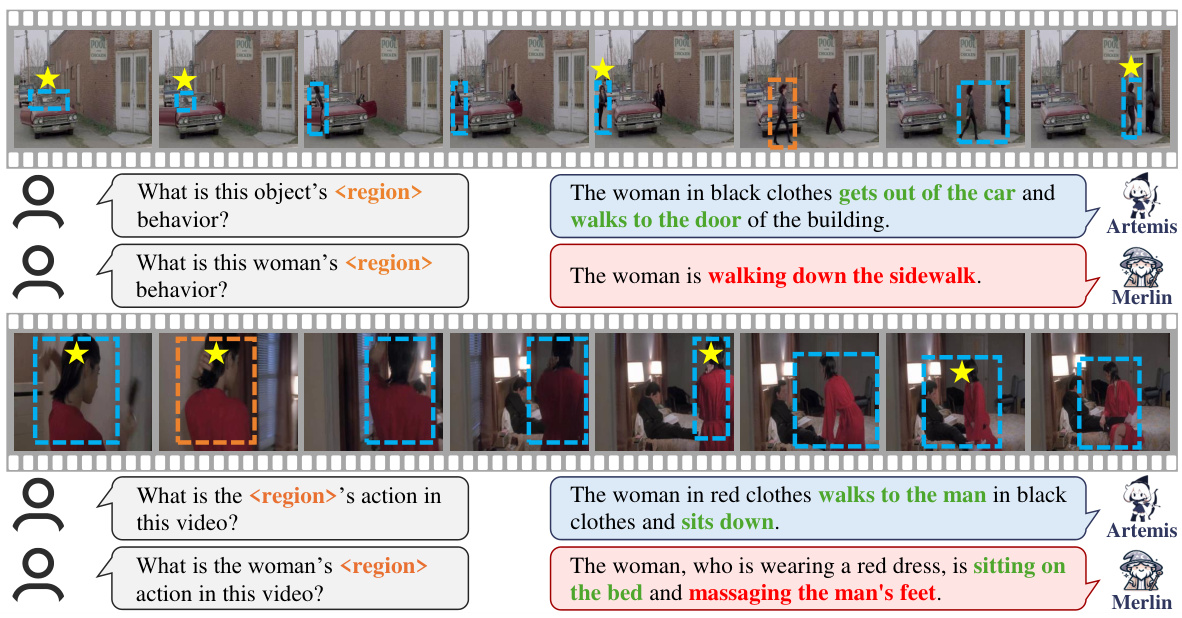
🔼 This figure compares the performance of Artemis and Merlin on video-based referring tasks. It highlights Artemis’s advantage in not requiring semantic class information about the target region, which is unlike Merlin. The figure shows examples where Artemis correctly answers the question about a target region’s actions in a video, while Merlin provides incorrect or less comprehensive answers. The visual components of the figure illustrate the process; input regions are marked in orange, tracked regions of interest (ROIs) in blue, and selected ROIs are highlighted with yellow stars. Correct and incorrect answers are noted in green and red, respectively.
read the caption
Figure 3: Artemis and Merlin for video-based referring. Note that Merlin needs the semantic class ofto be provided while Artemis does not. In each case, the orange rectangle indicates the input , blue rectangles are the tracked RoIs, and yellow stars label the selected Rols. Red and green texts indicate incorrect and correct answers, respectively. This figure is best viewed in color.

🔼 This figure shows the results of two experiments evaluating the impact of RoI tracking and selection methods on the informativeness and diversity of RoIs. The top panel shows that adding RoI tracking increases the information entropy of the RoIs, indicating that more information is captured. The bottom panel shows that using K-means clustering to select RoIs results in higher inter-frame RoI difference compared to using uniform or random sampling, suggesting that the selected RoIs are more diverse. Overall, this figure demonstrates that RoI tracking and selection improves the quality of the video features used for referential understanding.
read the caption
Figure 4: RoI manipulation increases the informativeness and diversity of RoIs. See Appendix D for details.

🔼 This figure shows an ablation study comparing three different RoI selection methods: only using the queried RoI, tracking and uniformly choosing 4 RoIs, and tracking & clustering to choose 4 RoIs. For each method, the figure displays example videos with the input
highlighted in orange, tracked RoIs in blue, and selected RoIs marked with yellow stars. The corresponding generated captions are given, highlighting the improved accuracy and comprehensiveness of the description when using tracking and clustering. read the caption
Figure 5: How RoI tracking and selection gradually improves the quality of video-based referring. In each example, the orange rectangle indicates the input, blue rectangles are the tracked RoIs, and green and yellow stars label the uniformly sampled and K-means selected RoIs, respectively. Red and green texts highlight the incorrect and correct outputs. This figure is best viewed in color.
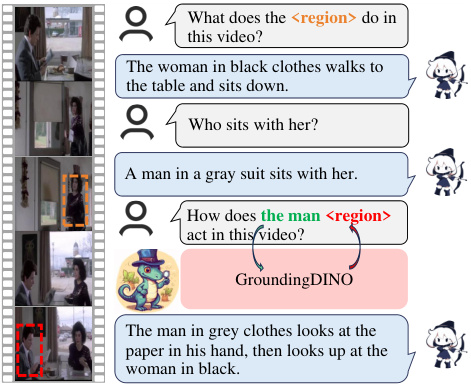
🔼 This figure demonstrates Artemis’s integration with GroundingDINO for multi-round video-based referring. The example shows a series of questions and answers, where Artemis provides the initial answer (referring to a specific region in the video), and GroundingDINO then locates the referenced entity in the video and presents it as further input to answer subsequent questions. This showcases the collaborative nature of these models in handling complex video understanding tasks.
read the caption
Figure 6: An example of multi-round, video-based referring by integrating Artemis with GroundingDINO [34].

🔼 This figure shows six example video clips from the VideoRef45K dataset. Each clip contains a sequence of frames showing an object performing an action, along with bounding boxes highlighting the object’s position in each frame. The accompanying text provides a concise description of the object’s activity in the clip. The purpose is to illustrate the diversity of actions and object types represented in the dataset, which consists of 45K video question-answer pairs.
read the caption
Figure 8: Some examples of VideoRef45K.

🔼 This figure compares the performance of Artemis with other image-based MLLMs (Osprey and Ferret) on a video-based referring task. The image-based models process the video frame by frame using image-based referring methods and then use GPT-3.5-Turbo to combine these results into an overall video description. The figure highlights Artemis’s superior ability to understand and describe the actions and behavior within a video compared to the combined image-based MLLM approach, demonstrating that Artemis is more effective at video-based referring than a frame-wise image-based approach followed by text summarization. The examples provided in the figure shows differences in the comprehensiveness and accuracy of the descriptions generated by each method.
read the caption
Figure 9: A comparison of video-based referring between image-based MLLMs and Artemis. GPT-3.5-Turbo is used to integrate the 5 independent outputs from the image-based MLLMs.
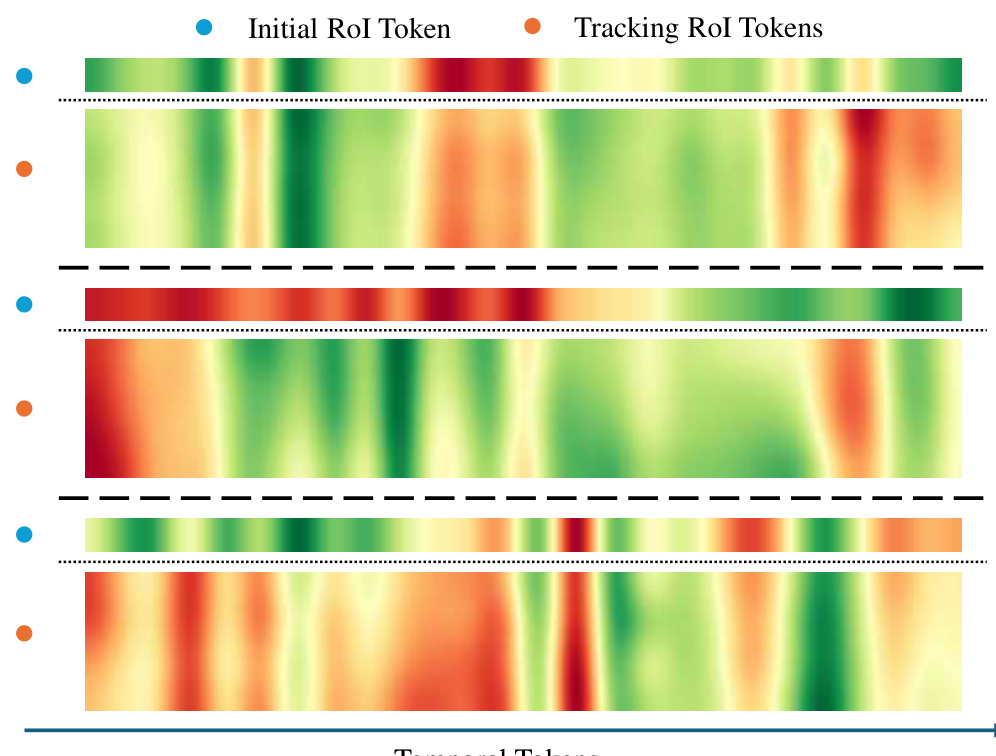
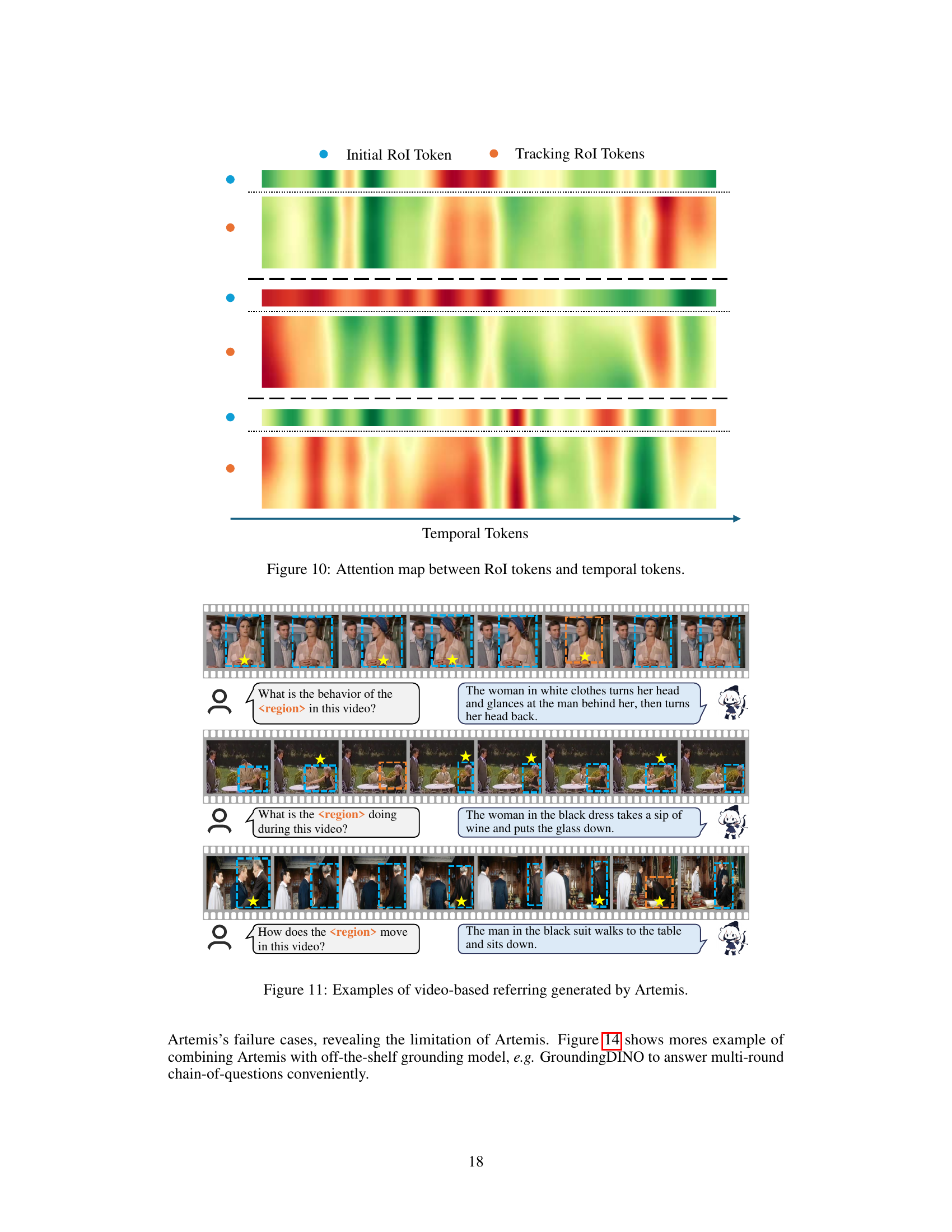
🔼 This figure shows the attention map between RoI tokens and temporal tokens. The attention map visualizes the relationships between the RoI features extracted from different frames of the video and the temporal features representing the entire video. It helps demonstrate how the model integrates spatial and temporal information to understand the video content. Warmer colors indicate stronger attention weights, suggesting stronger relationships between those features.
read the caption
Figure 10: Attention map between RoI tokens and temporal tokens.

🔼 This figure compares Artemis and Merlin’s performance on video-based referring tasks. It highlights Artemis’s ability to answer questions without requiring explicit semantic class labels for the target region, unlike Merlin. It demonstrates Artemis’s superior performance by showing its ability to identify and track the relevant regions of interest within the video and accurately answer questions regarding the target’s actions.
read the caption
Figure 3: Artemis and Merlin for video-based referring. Note that Merlin needs the semantic class ofto be provided while Artemis does not. In each case, the orange rectangle indicates the input , blue rectangles are the tracked RoIs, and yellow stars label the selected Rols. Red and green texts indicate incorrect and correct answers, respectively. This figure is best viewed in color.

🔼 This figure shows an example of Artemis performing long video understanding. The video is divided into four segments, and Artemis produces a description for each segment. These individual descriptions are then combined by Artemis to generate a comprehensive summary of the entire video’s events. The example showcases Artemis’ ability to not only understand individual actions within short video segments but also to combine these into a coherent narrative summarizing the overall events of a longer video.
read the caption
Figure 12: The example of long video understanding generated by Artemis.

🔼 This figure compares the performance of Artemis and Merlin on video-based referring tasks. It highlights Artemis’s ability to successfully answer questions about a target region in a video without requiring explicit semantic labels, unlike Merlin which does need this extra information. Each row shows an example, with the orange rectangle showing the initial target region; blue rectangles track the target throughout the video; yellow stars highlight selected keyframes; and red and green text indicates whether the model was correct (green) or incorrect (red).
read the caption
Figure 3: Artemis and Merlin for video-based referring. Note that Merlin needs the semantic class ofto be provided while Artemis does not. In each case, the orange rectangle indicates the input , blue rectangles are the tracked RoIs, and yellow stars label the selected Rols. Red and green texts indicate incorrect and correct answers, respectively. This figure is best viewed in color.
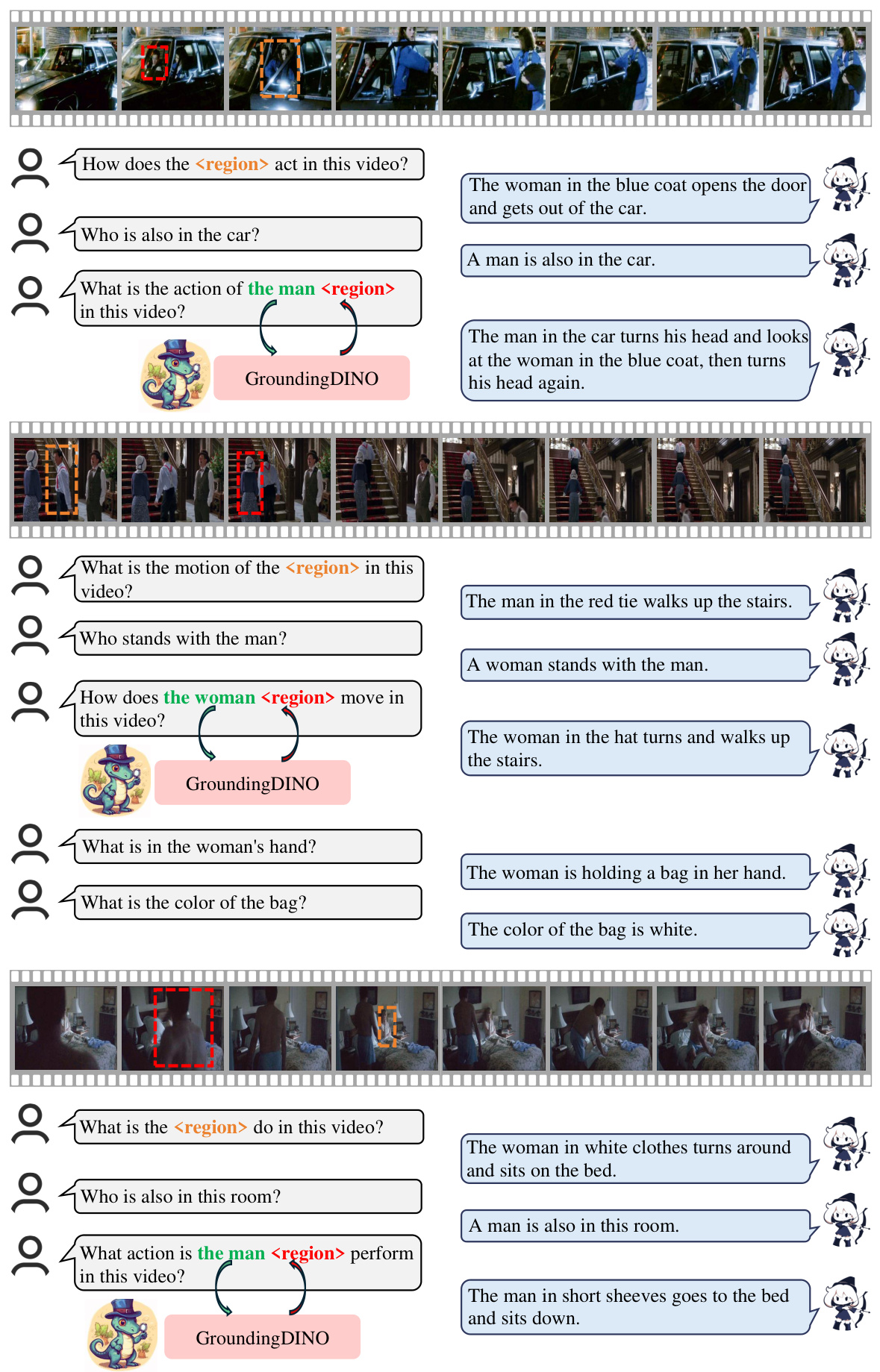
🔼 This figure compares the performance of Artemis and Merlin on video-based referring tasks. It highlights that Artemis does not require the semantic class of the target region as input, unlike Merlin. The figure shows example questions, model responses, and visual representations (bounding boxes) to illustrate the model’s ability to identify and describe target actions within a video.
read the caption
Figure 3: Artemis and Merlin for video-based referring. Note that Merlin needs the semantic class ofto be provided while Artemis does not. In each case, the orange rectangle indicates the input , blue rectangles are the tracked RoIs, and yellow stars label the selected Rols. Red and green texts indicate incorrect and correct answers, respectively. This figure is best viewed in color.
More on tables
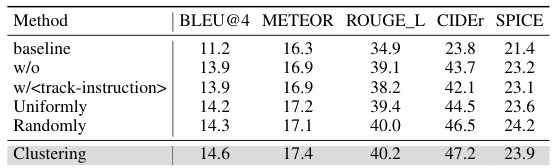
🔼 This table presents the results of an ablation study conducted on the HC-STVG dataset to evaluate the effectiveness of different RoI (Region of Interest) selection methods for video-based referring. The methods compared include a baseline (no RoI selection), removing tracking instructions, uniformly sampling RoIs, randomly sampling RoIs, and using K-means clustering for RoI selection. The table shows the performance of each method across various metrics, including BLEU@4, METEOR, ROUGE_L, CIDEr, and SPICE. The results demonstrate the superiority of K-means clustering in selecting representative RoIs that effectively capture the semantic changes throughout complex videos.
read the caption
Table 2: Ablation on different RoI selection methods. Results are reported on HC-STVG.
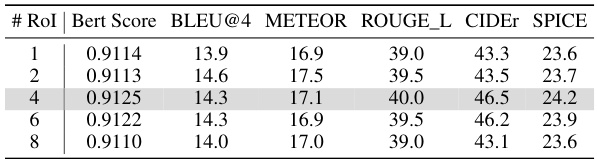
🔼 This table presents the results of an ablation study conducted on the HC-STVG dataset to determine the optimal number of selected Regions of Interest (RoIs) for video-based referring. The study varied the number of RoIs (1, 2, 4, 6, and 8) and measured the performance using several metrics: BERT Score, BLEU@4, METEOR, ROUGE_L, CIDEr, and SPICE. The results show that using 4 RoIs provides the best balance between performance and efficiency.
read the caption
Table 3: Ablation on the number of selected RoIs. Results are reported on HC-STVG.

🔼 This table compares the performance of different methods on the video-based referring task using the HC-STVG test dataset. The metrics used are BERTScore, BLEU@4, METEOR, ROUGE-L, CIDEr, and SPICE, which are common evaluation metrics for evaluating the quality of generated text. The table shows that the proposed Artemis model outperforms other existing methods on all metrics. The † symbol indicates that a different number of frames were used for the compared method.
read the caption
Table 1: A comparison of video-based referring metrics on the HC-STVG test set. †: We use 5 key frames while using 8 frames leads to worse results.
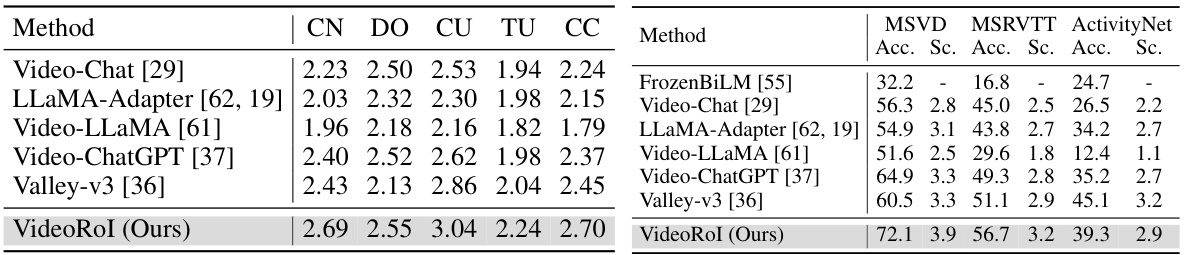
🔼 This table compares the performance of various models on the HC-STVG video-based referring task, using metrics such as BERTScore, BLEU@4, METEOR, ROUGE-L, CIDEr, and SPICE. It highlights the superior performance of the Artemis model compared to existing models like Osprey, Ferret, Shikra, Video-ChatGPT, Video-LLaVA, and Merlin. The use of 5 keyframes versus 8 is noted as affecting Merlin’s results.
read the caption
Table 1: A comparison of video-based referring metrics on the HC-STVG test set. †: We use 5 key frames while using 8 frames leads to worse results.

🔼 This table presents the composition of the VideoRef45K benchmark dataset, which is created by curating seven existing video datasets. It shows the number of video clips and question-answer pairs from each original dataset (HC-STVG, MeViS, A2D Sentences, LaSOT, VID Sentence, GOT-10K, MGIT), as well as the combined totals for the VideoRef45K benchmark.
read the caption
Table 5: Curated datasets for Video-based Referring.
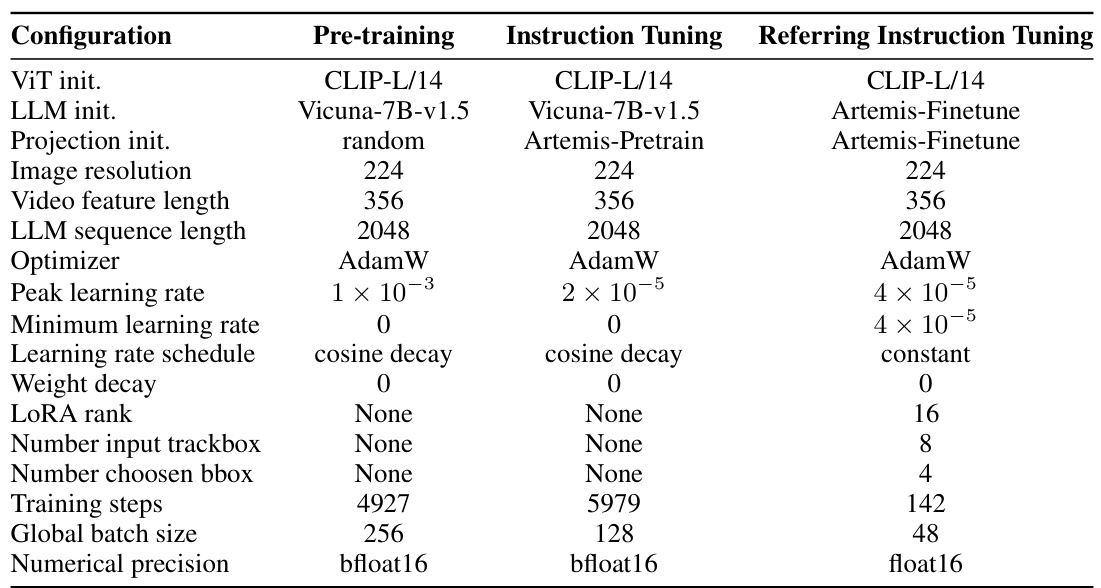
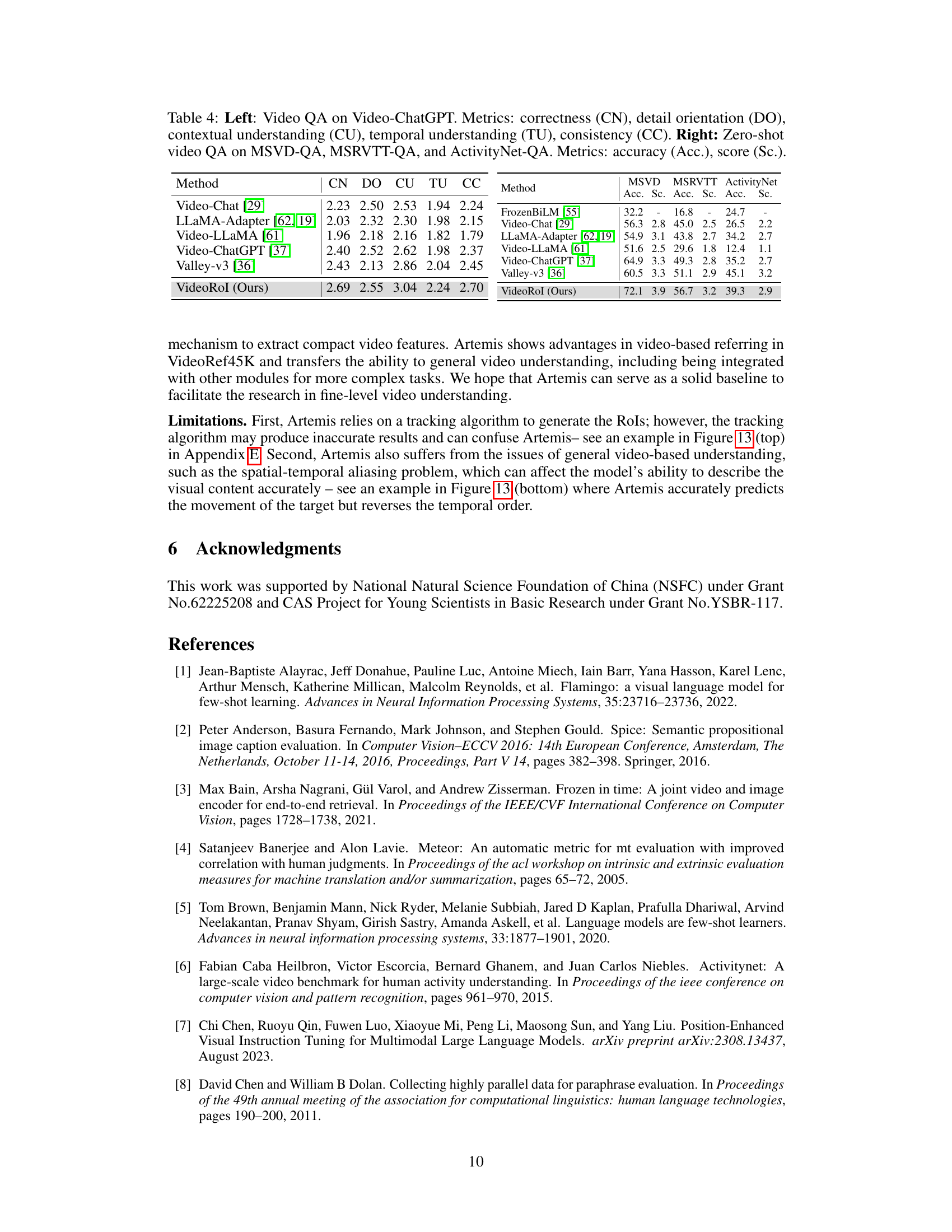
🔼 This table details the hyperparameters used for training the Artemis model. It’s divided into three sections representing the different training stages: pre-training, instruction tuning, and referring instruction tuning. For each stage, it lists the ViT initialization, LLM initialization, projection initialization, image resolution, video feature length, LLM sequence length, optimizer, peak learning rate, minimum learning rate, learning rate schedule, weight decay, LoRA rank, number of input trackboxes, number of chosen bounding boxes, training steps, global batch size, and numerical precision used.
read the caption
Table 6: Training hyper-parameters of Artemis.
Full paper#