TL;DR#
The rise of powerful LLMs necessitates methods to verify text authenticity and prevent misuse. Existing watermarking techniques either lack robustness to modifications or introduce bias, limiting their practical use. This paper aims to solve these challenges by developing statistically sound methods that preserve original text distributions while enabling accurate detection of watermarked text.
This work proposes a novel approach, combining randomization tests and change point detection, to identify watermarked sections in possibly modified texts. It demonstrates that the approach ensures Type I and Type II error control and provides an accurate segmentation of the text. The method’s effectiveness is validated using real-world data from Google’s C4 dataset and several LLMs, showing promising results. This contribution significantly advances the field of LLM watermarking and text segmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it introduces robust statistical methods for watermarking and identifying watermarked text, addressing critical issues of authenticity and misuse. It also offers a novel approach to segmenting texts into watermarked and non-watermarked sections, opening avenues for more sophisticated watermarking techniques and improved detection methods. The rigorous theoretical analysis and real-world evaluations add to the paper’s significance.
Visual Insights#
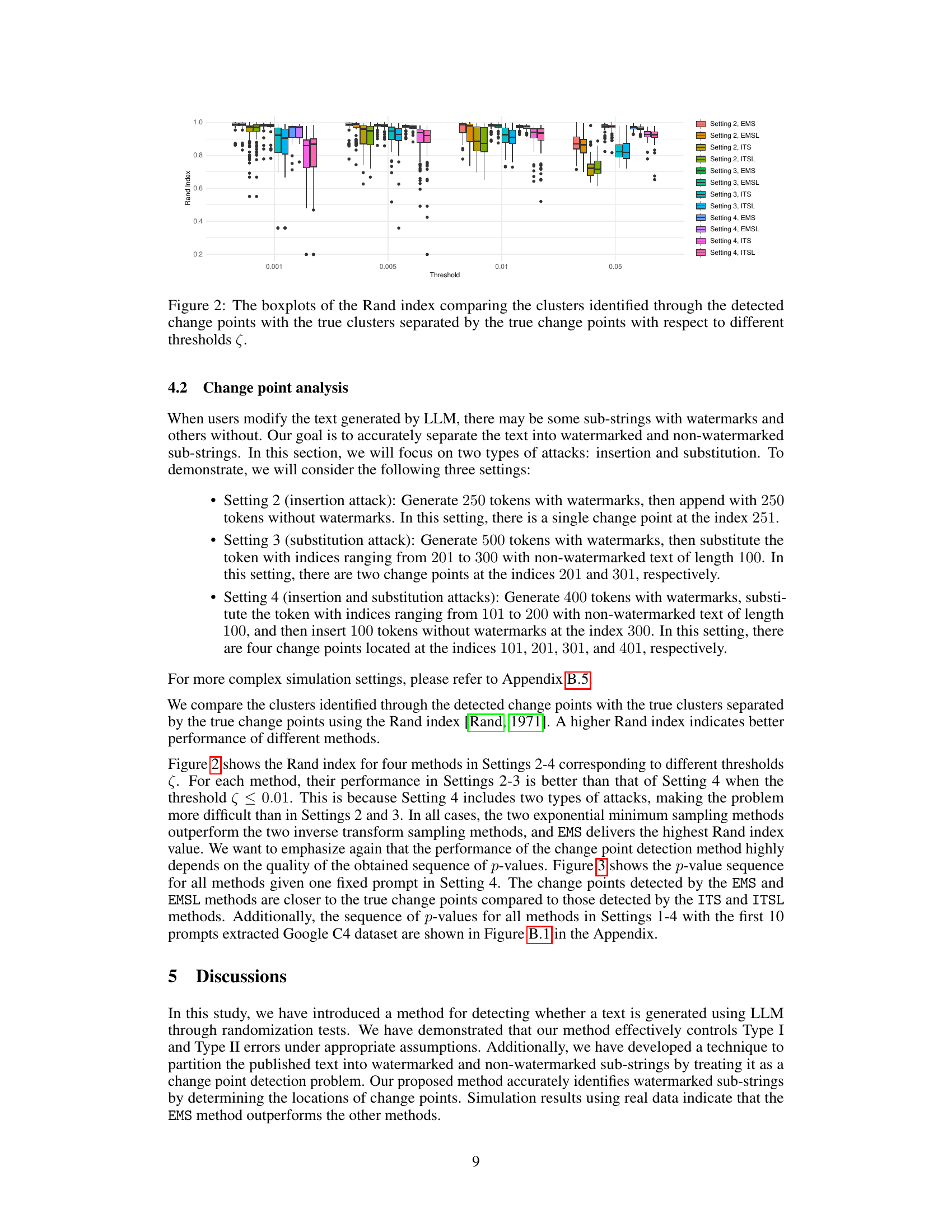
🔼 This figure shows the results of false positive analysis for change point detection. The left panel presents boxplots of false detection counts across different threshold values (ζ) for four different watermarking methods (EMS, EMSL, ITS, ITSL). The right panel displays the p-value sequences for these four methods, focusing on Setting 1 and Prompt 1 with a threshold of ζ = 0.005. The detected change points are highlighted with dashed lines, illustrating the discrepancy between the methods’ detection capabilities.
read the caption
Figure 1: Left panel: boxplots of the number of false detections with respect to different thresholds ζ. Right panel: sequences of p-values from different methods in Setting 1 for Prompt 1 with threshold ζ = 0.005. The detected change point locations are marked with dashed lines at the index 157 for ITS and 158 for ITSL, respectively.

🔼 This table presents the Rand index for different choices of window size (B) when the number of permutations (T) is fixed at 999. The Rand index measures the agreement between the detected change points and the true change points. A higher Rand index indicates better performance of the change point detection method. The results show that a window size of 30 yields the best performance in this experiment.
read the caption
Table C.1: Results for different choices of B when T = 999.
In-depth insights#
LLM Watermarking#
LLM watermarking presents a powerful defense against the unauthorized use and distribution of AI-generated text. By embedding subtle, statistically detectable signals within the text, it enables tracing the content back to its source, deterring malicious actors and protecting intellectual property. The core challenge lies in balancing the imperceptibility of the watermark with its robustness against text modifications. Techniques such as inverse transform sampling and exponential minimum sampling offer promising approaches, but require careful consideration of statistical properties to ensure effectiveness and avoid biasing the LLM’s output. Future research should focus on developing more robust watermarks resilient to sophisticated editing techniques and exploring the theoretical limits of watermark detectability. Furthermore, practical deployment necessitates efficient detection mechanisms and methods for segmenting watermarked from non-watermarked text. This field is rapidly evolving and has significant implications for trust, accountability, and copyright protection in the age of readily available advanced language models.
Statistical Detection#
In a research paper focusing on watermarking techniques for language models, a section titled “Statistical Detection” would delve into the methods used to identify the presence of watermarks within a given text. This would likely involve statistical hypothesis testing, where the null hypothesis would be that the text is not watermarked, and the alternative hypothesis is that it is. The discussion would encompass the choice of test statistic, which quantifies the difference between watermarked and unwatermarked text distributions, and the significance level for determining whether to reject the null hypothesis. A critical aspect would be the robustness of the detection method to various modifications of the text (substitutions, insertions, deletions) and the trade-off between sensitivity and specificity. The effectiveness of the statistical methods in correctly classifying watermarked and unwatermarked texts would be evaluated using metrics such as Type I and Type II error rates, and the power of the test under different types and levels of attacks might be analyzed. Furthermore, discussion of how the method addresses the presence of noise and other confounding factors in real-world text data would also be significant. Ultimately, a successful statistical detection method would reliably distinguish LLM-generated watermarked content, enhancing the security of such systems.
Change Point Analysis#
The heading ‘Change Point Analysis’ suggests a methodological approach focusing on identifying shifts or breaks in the statistical properties of a data sequence. In the context of watermark detection within text generated by large language models (LLMs), this likely refers to the process of identifying segments within a given text where a watermark is present (marked segments) versus where it’s absent (unmarked). The core idea involves analyzing a sequence of p-values (derived from a statistical test), each reflecting the likelihood of a watermark being present in a corresponding text segment. Change points would then correspond to locations where the p-value distribution shifts significantly, indicating a transition between watermarked and non-watermarked regions. The effectiveness hinges on the sensitivity of the underlying statistical test to subtle changes in text generated under the influence of the watermark. The accuracy of change point detection directly impacts the precision of isolating the watermarked portions of text, a crucial step in verifying the provenance of LLM-generated content. Methodological choices, such as the specific statistical test, window size for analysis, and change point detection algorithm used, are critical to the accuracy and robustness of this approach. Therefore, the ‘Change Point Analysis’ section likely details the specific methodology used, justifying its choices, evaluating its performance, and demonstrating its efficacy in correctly segmenting watermarked text.
Experimental Results#
A thorough analysis of the ‘Experimental Results’ section requires careful consideration of several key aspects. First, what specific metrics were chosen to evaluate the model’s performance? Were these metrics appropriate given the research goals, and were they clearly defined and justified? Second, how was the experimental setup designed? Were sufficient controls in place to isolate the effects of the proposed methodology and minimize confounding factors? Were the experiments repeated with different random seeds or using cross-validation techniques to ensure robustness and generalizability of the findings? Third, how were the results presented and interpreted? Are the visualizations clear and informative, accurately reflecting the trends in the data? Is there a discussion of the statistical significance of the results (p-values, confidence intervals, effect sizes), and is the discussion of the results supported by a clear and logical argument? Finally, how did the experimental results compare to previous work or established baselines? Was a comparison made, and if so, was this comparison meaningful and informative in demonstrating the novel contributions of the research? A thoughtful analysis will address these points.
Future Directions#
Future research could explore several promising avenues. Improving watermark robustness against sophisticated adversarial attacks is crucial, requiring more resilient embedding techniques and detection methods. Developing watermarking schemes for multimodal content (e.g., integrating text with images or audio) presents a significant challenge that could enhance practical applications. Investigating the legal and ethical implications of watermarking is vital to ensure responsible deployment and avoid misuse. Assessing the impact of watermarks on LLM performance and exploring methods to minimize any negative effects warrants further attention. Finally, developing more efficient change-point detection algorithms is needed to handle larger text datasets and complex watermark patterns effectively.
More visual insights#
More on figures
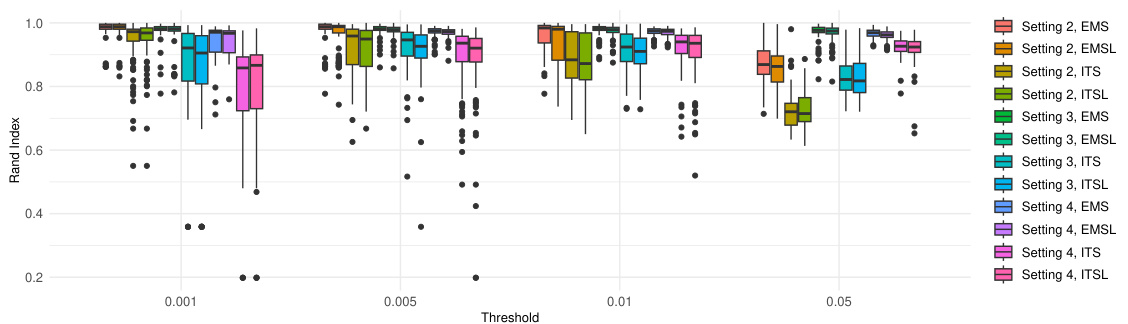
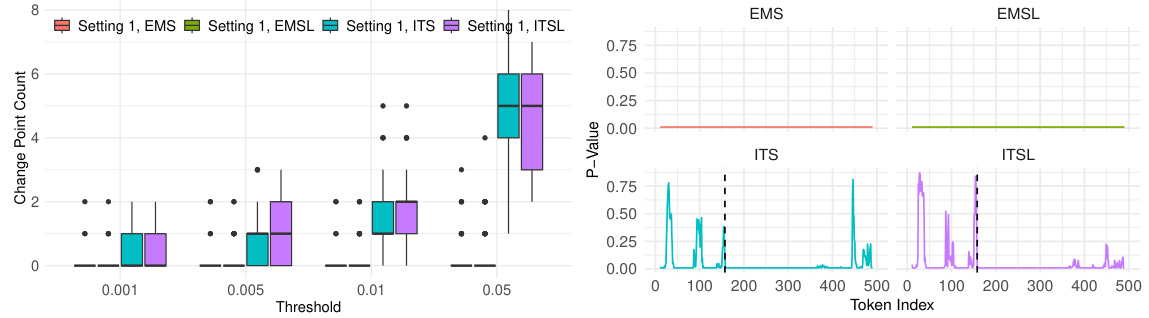
🔼 This figure presents the performance of four watermarking methods (EMS, EMSL, ITS, ITSL) in identifying change points under different attack settings. The Rand index is used to measure the similarity between the clusters of detected change points and the true clusters. The boxplots show the distribution of Rand indices across different threshold values (ζ) for each method and setting. The settings vary in the types and number of attacks applied (insertion and/or substitution) to the original watermarked text. Higher Rand indices indicate better performance in accurately identifying the correct change point locations. The figure shows that EMS generally performs better than the other methods.
read the caption
Figure 2: The boxplots of the Rand index comparing the clusters identified through the detected change points with the true clusters separated by the true change points with respect to different thresholds ζ.
🔼 The figure shows the results of false positive analysis. The left panel shows boxplots of the number of false detections for four watermarking methods (EMS, EMSL, ITS, ITSL) at various thresholds. The right panel displays sequences of p-values for the same methods for a single prompt. Dashed lines indicate the detected change points.
read the caption
Figure 1: Left panel: boxplots of the number of false detections with respect to different thresholds (ζ). Right panel: sequences of p-values from different methods in Setting 1 for Prompt 1 with threshold ζ = 0.005. The detected change point locations are marked with dashed lines at the index 157 for ITS and 158 for ITSL, respectively.
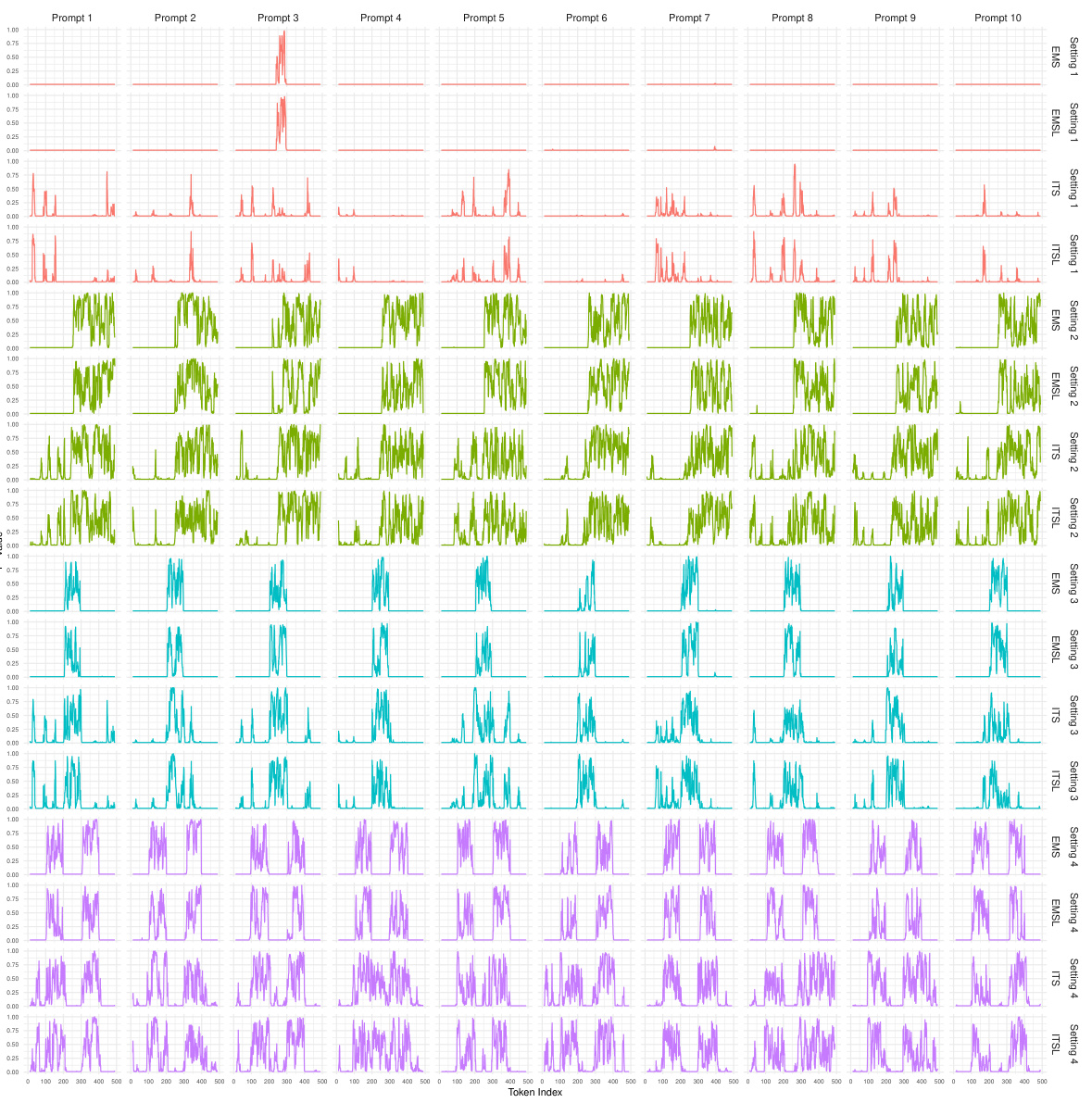
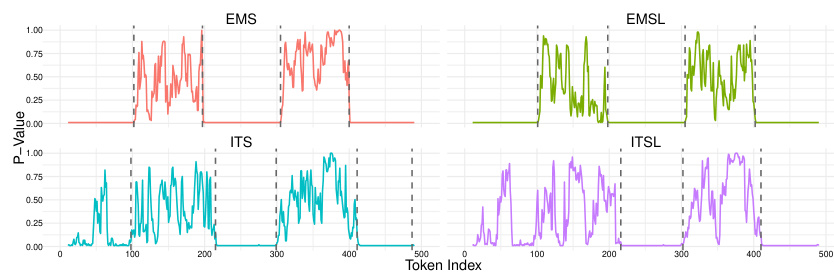
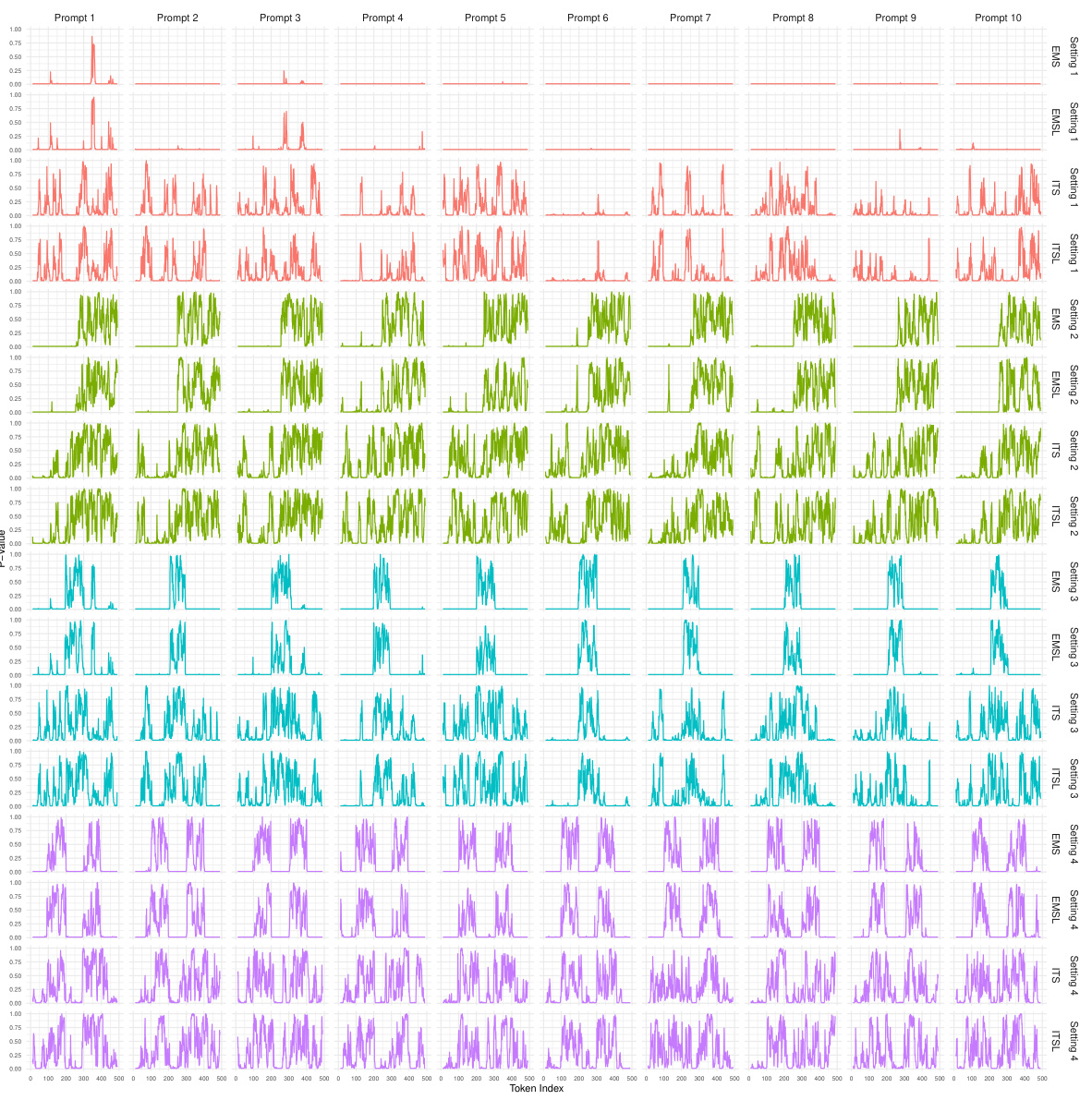
🔼 This figure shows the p-value sequences for the first 10 prompts from the Google C4 dataset using the openai-community/gpt2 language model. The p-values are grouped by four settings (representing different watermarking scenarios), each setting using four different distance metrics (EMS, EMSL, ITS, ITSL) to calculate the p-values. The plots visualize the distribution of p-values for each setting and metric across each prompt, providing insight into the performance of different methods under varied conditions.
read the caption
Figure B.1: Sequences of p-values for the first 10 prompts extracted from the Google C4 dataset for LLM openai-community/gpt2, organized into groups of four consecutive rows, each group corresponding to a distinct setting. Within each group, the rows represent p-values calculated using four different distance metrics: EMS, EMSL, ITS, and ITSL.
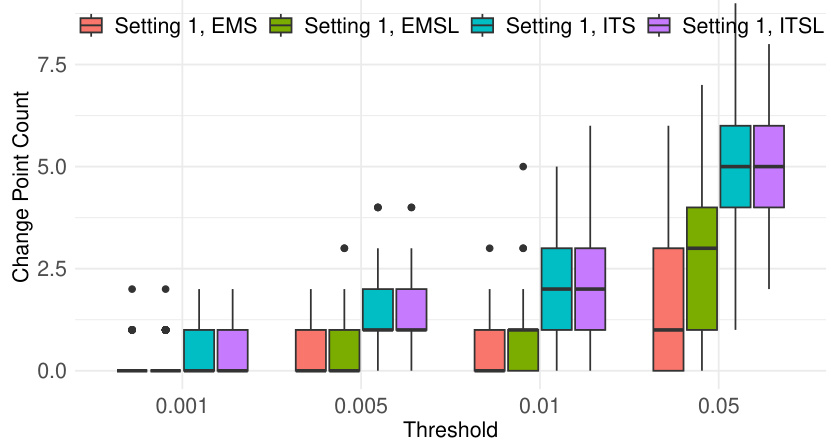
🔼 The figure contains two panels. The left panel shows boxplots of the number of false detections obtained using four different watermarking methods (EMS, EMSL, ITS, ITSL) at different p-value thresholds. The right panel displays the sequences of p-values for each method in Setting 1 (no change point) for Prompt 1 using a threshold of 0.005. Dashed lines indicate the detected change point locations. ITS and ITSL methods yield change points at indices 157 and 158 respectively.
read the caption
Figure 1: Left panel: boxplots of the number of false detections with respect to different thresholds ζ. Right panel: sequences of p-values from different methods in Setting 1 for Prompt 1 with threshold ζ = 0.005. The detected change point locations are marked with dashed lines at the index 157 for ITS and 158 for ITSL, respectively.
🔼 The left panel of Figure 1 shows boxplots of the number of false detections using different thresholds. The right panel displays the p-value sequences of four watermark detection methods under Setting 1 (no change point), using a threshold of 0.005. The dashed lines highlight the detected change points.
read the caption
Figure 1: Left panel: boxplots of the number of false detections with respect to different thresholds (. Right panel: sequences of p-values from different methods in Setting 1 for Prompt 1 with threshold ζ = 0.005. The detected change point locations are marked with dashed lines at the index 157 for ITS and 158 for ITSL, respectively.

🔼 This figure shows the performance of four watermark detection methods (EMS, EMSL, ITS, ITSL) in identifying change points in texts subjected to insertion and substitution attacks. The Rand index, a measure of cluster similarity, is used to compare the clusters identified by the methods to the true clusters. The boxplots summarize the Rand index values obtained at different p-value thresholds (ζ), representing different levels of strictness in change point detection. The results are displayed separately for three different attack scenarios (Settings 2-4) that vary in the type and number of changes introduced.
read the caption
Figure 2: The boxplots of the Rand index comparing the clusters identified through the detected change points with the true clusters separated by the true change points with respect to different thresholds ζ.

🔼 The left panel of the figure shows boxplots of the number of false detections for different watermark detection methods (EMS, EMSL, ITS, ITSL) against various threshold values (ζ). The right panel displays the p-value sequences for the four methods in Setting 1, using Prompt 1 and a threshold of ζ = 0.005. Dashed lines indicate where change points are detected.
read the caption
Figure 1: Left panel: boxplots of the number of false detections with respect to different thresholds (ζ). Right panel: sequences of p-values from different methods in Setting 1 for Prompt 1 with threshold ζ = 0.005. The detected change point locations are marked with dashed lines at the index 157 for ITS and 158 for ITSL, respectively.

🔼 The figure contains two panels. The left panel shows boxplots of the number of false detections for different methods (EMS, EMSL, ITS, ITSL) against various p-value thresholds. The right panel displays sequences of p-values obtained from four different methods (EMS, EMSL, ITS, ITSL) for a specific prompt (Prompt 1) in Setting 1, using a p-value threshold of 0.005. The detected change points are indicated by dashed lines at indices 157 for ITS and 158 for ITSL.
read the caption
Figure 1: Left panel: boxplots of the number of false detections with respect to different thresholds ζ. Right panel: sequences of p-values from different methods in Setting 1 for Prompt 1 with threshold ζ = 0.005. The detected change point locations are marked with dashed lines at the index 157 for ITS and 158 for ITSL, respectively.
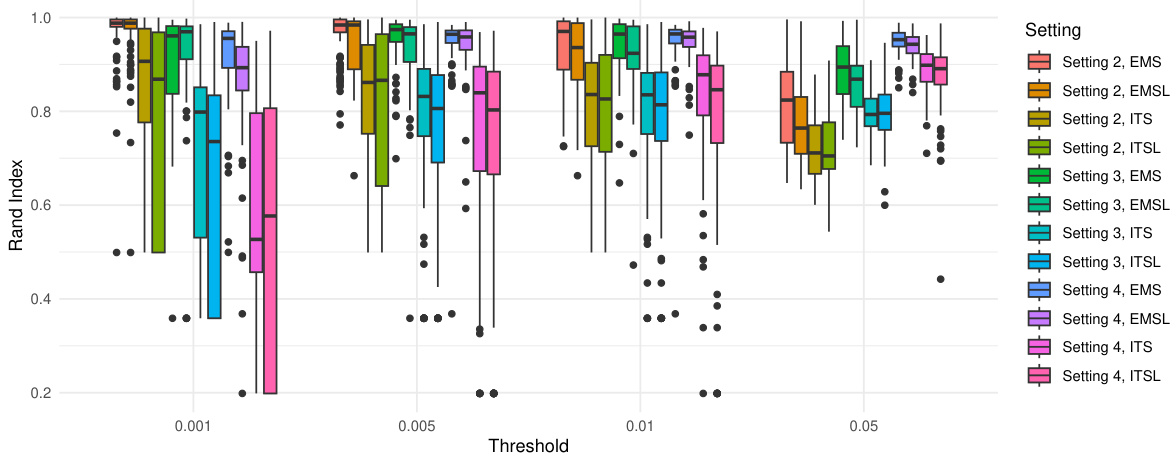
🔼 This figure compares the performance of four watermarking methods (EMS, EMSL, ITS, ITSL) in identifying change points in texts subjected to insertion and substitution attacks. The Rand index, a measure of clustering similarity, is calculated for each method across various threshold values (ζ). The boxplots show the distribution of Rand indices across different attack scenarios. Higher Rand indices indicate better performance in correctly identifying watermarked segments.
read the caption
Figure 2: The boxplots of the Rand index comparing the clusters identified through the detected change points with the true clusters separated by the true change points with respect to different thresholds ζ.

🔼 The figure shows the results of false positive analysis for different methods and thresholds. The left panel displays boxplots of the number of false detections for various thresholds, providing a visual representation of the performance of each method in identifying true change points. The right panel illustrates p-value sequences for different methods in a specific setting, highlighting the identified change points (marked by dashed lines) for comparison.
read the caption
Figure 1: Left panel: boxplots of the number of false detections with respect to different thresholds (ζ). Right panel: sequences of p-values from different methods in Setting 1 for Prompt 1 with threshold ζ = 0.005. The detected change point locations are marked with dashed lines at the index 157 for ITS and 158 for ITSL, respectively.
Full paper#